
一种基于多特征的双阶段草图分类方法
2023-09-06 04:30顾飞杨
小型微型计算机系统 2023年9期
赵 琛,朱 明,顾飞杨
(安徽大学 集成电路学院,合肥 230601)
1 引 言
草图作为一种简单的交流和记录工具,一直被人们广泛使用.近年来,随着各种触摸设备的普及和分类技术的发展,草图分类问题受到了研究人员的广泛关注,相关的研究取得了很大的进展.
与普通图像不同,草图仅由稀疏线条组成.由于不同的人有不同的绘画习惯,即使是同一个物体也可能被绘制出完全不同的风格.有的绘画风格相对简单,只画最具代表性的部分,而有的则习惯于把所有的细节都描绘出来.此外,一些不同类别的草图具有很大的相似性,例如香蕉和月亮,很难区分它们.因此,草图分类是一个具有挑战性的问题.
随着深度学习技术的发展,许多基于卷积神经网络的方法被运用于草图分类[1-16],并取得了较好的效果.但是大多数现有方法仅使用一种或两种特征,对特征的利用不够充分,分类准确率不高.本文希望利用更多的特征来表征草图,提高分类效果.基于上述原因,本文提出了一种基于多特征的双阶段草图分类方法,该方法分两个阶段进行训练,初训练阶段,分别获得草图的粗粒度特征、细粒度特征与轮廓特征的单特征分类结果;再训练阶段,通过融合模块将各特征的分类结果进行融合,得到最终的分类结果.双阶段训练使得各特征的提取更加充分,融合模块使得各特征的分类结果更好地融合,最终得到更好的分类效果.本文的主要贡献如下:
1)建立了一个基于多特征的双阶段草图分类框架,通过双阶段训练更好地提取草图的每种特征.
2)引入双线性池化以获得更具有辨别力的细粒度特征,通过草图的轮廓图像获得草图的轮廓特征.
3)提出了一种分类结果融合模块,将草图的粗粒度特征、细粒度特征与轮廓特征的分类结果进行动态地融合,得到更好的分类效果;同时提出了一个正则化项,减缓该融合模块的过拟合.
2 相关工作
草图具有直观、简单的特点,受到许多研究者的广泛关注.以草图为研究对象,出现了很多研究方向,如草图分类[1-17]、草图检索和草图分割等,草图分类是其中一个重要的研究方向.与草图相关的研究最开始都面临一个共同的问题,即缺乏数据集.Eitz等人[17]收集了第一个大型草图数据集TUBerlin,每个草图都是由非专业画家完成的.该数据集是该领域常用的基准数据集,人类对于该数据集的平均识别准确率为73.1%.
从特征提取方法的角度来看,草图分类的研究可分为两类:基于手工特征的方法和基于深度学习的方法.基于手工特征的方法是从草图中提取某些手工特征,如SIFT(Scale-Invariant Feature Transform)特征、HOG(Histogram of Oriented Gradient)特征和形状上下文特征等,利用这些特征对草图进行分类.尽管这些特征可以从不同角度对草图进行有效地描述,但它们的分类准确率相对较低,远低于人类的平均识别准确率.随着深度学习技术的迅速发展,各种神经网络在图像分类领域取得了显著的成效,尤其是卷积神经网络,被广泛应用于图像特征的提取.近年来,受卷积神经网络在图像领域成功应用的启发,许多用于草图分类的卷积神经网络被提出.
Yu等人[1]设计了一个名为sketch-a-net的多通道卷积神经网络,将草图分成多个部分,以提取更多的特征,该方法的分类准确率首次超过了人类的平均识别准确率;随后,Yu等人[2]又提出了一种改进的草图分类网络“sketch-a-net2”,通过几种适合草图的数据增广方法对草图进行了数据增广;Sarvavavabhatla等人[3]提出了一种基于深度特征的草图识别框架;Yang 等人[4]设计了一个具有超大卷积核的神经网络用于草图分类;Sert等人[5]提出了一种基于迁移学习与特征融合的手绘草图识别方法;Zhang等人[6]提出了一种动态获取草图关键点的草图分类方法,以解决在特征提取过程中计算方式被完全固化的问题.Shi等人[7]提出了一种可变形卷积神经网络,能够识别草图的形变,从而在草图数据集上获得更高的分类精度;Zhang等人[8]提出了一种表亲网络,将从自然图像中学习到的知识转移到草图中以提取更多的相关特征;He等人[9]提出了DVSF(Deep Visual-Sequential Fusion)模型,以获得草图的视觉特征和序列特征.Zhang等人[10]设计了一个由a-Net和S-Net组成的混合卷积神经网络以获得草图的外观特征和形状特征.Kong等人[11]提出了一种采用深度可分离卷积的轻量级神经网络,在减少参数的同时,可针对草图的稀疏性对网络进行有效地调整.
以前的方法大多基于单一特征或者两种特征,本文提出的方法与以往文献中的方法有较大的不同,采用了更丰富的特征.此外,融合模块和双阶段训练方式使得特征的提取与利用更加充分.
3 本文方法
3.1 多特征联合模型总体结构与双阶段训练方法
本节将介绍用于草图分类的多特征联合模型总体结构与双阶段训练方法.如图1所示,该模型由轮廓提取模块、4个分支网络及分类结果融合模块构成.其中,轮廓提取模块用于提取草图的轮廓;细粒度特征分支网络1与细粒度特征分支网络2用于获得草图的细粒度特征分类结果;轮廓特征分支网络用于获得草图的轮廓特征分类结果;粗粒度特征分支网络用于获得草图的粗粒度特征分类结果;分类结果融合模块是一个可训练的模块,将各特征分类结果进行融合,得到最终的分类结果.
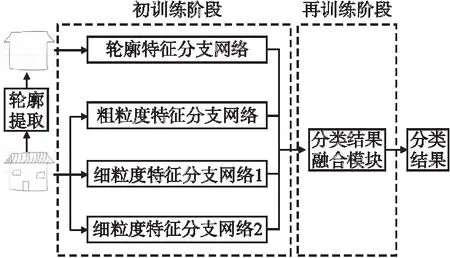
图1 多特征联合模型与双阶段训练结构图Fig.1 Structure diagram of multi-feature joint model and two-stage training
4个分支网络的主干网络为Resnet18或Resnet18的一部分.Resnet18是Resnet网络[18]的一种,包含4个残差块集合,具体如图2所示.残差块通过短路连接实现,短路连接大大加快了模型的训练速度,并且可以抑制梯度消失与梯度爆炸.

图2 Resnet18结构图Fig.2 Resnet18 structure diagram
对草图进行分类时,粗粒度特征、细粒度特征以及轮廓特征的结合可以极大地提高草图的分类准确率.在模型训练时,如果各分支网络一起进行训练,模型只会重点关注某类特征,并不能充分提取各类特征.因此,本文将每一个分支网络单独进行训练,分类结果融合模块的训练在分支网络全部训练完毕后进行.总体来说,本文采用一种双训练模式,在初训练阶段,对各分支网络分别进行训练得到各类特征的分类结果;在再训练阶段,固定初训练阶段所得的各分支网络参数,通过可训练的分类结果融合模块将各特征分类结果进行融合,得到最终的分类结果.双阶段训练方式将每种特征的提取分开进行,使得模型尽可能地提取该类特征,而不受其他特征的影响.融合模块将各特征的分类结果进行动态地调整及合并,可以充分利用不同特征的分类结果.
3.2 草图的粗粒度特征分支网络与草图的轮廓特征分支网络
将草图图像作为输入送入Resnet18中,通过全局平均池化可以直接得到草图的粗粒度特征,然后通过分类模块得到该特征的分类结果,具体如图4所示.其中分类模块由一个全连接层组成,将特征映射为分类结果.
草图的颜色单调,表达能力有限,某些不同类别的草图纹理极其相似,但是其轮廓依然有很大的差别;同时,卷积神经网络在某种程度上更关注于纹理特征,而忽略对草图轮廓特征的提取.如图3所示,篮子、羽毛球拍及汽车都具有一些相似的纹理,神经网络可能会出现误判,但是它们的轮廓具有明显的不同,将纹理进行剔除,通过轮廓图像更容易对它们进行区分.类似文献[23],本文通过设计的草图轮廓提取程序对草图进行轮廓提取,再将草图轮廓图像送入Resnet18,通过全局平均池化获得草图的轮廓特征,最后通过分类模块得到轮廓特征的分类结果,具体如图4所示.

图3 轮廓提取示意图Fig.3 Schematic diagram of contour extraction
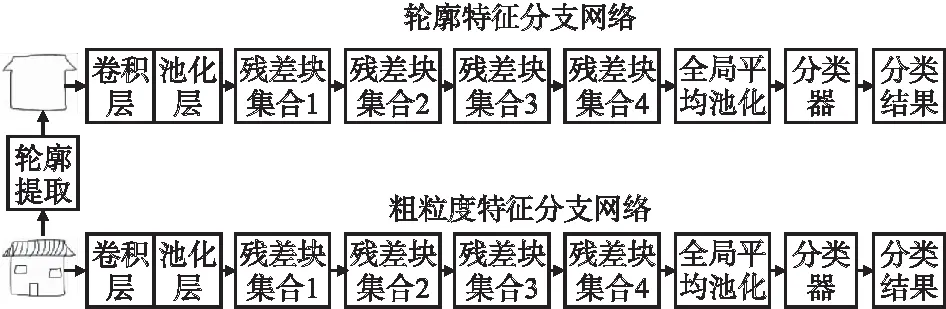
图4 轮廓特征分支网络与粗粒度特征分支网络结构图Fig.4 Structure diagram of contour feature branch network and coarse-grained feature branch network
3.3 草图的细粒度特征分支网络
由于手绘草图缺少色彩,仅靠线条表示物体,含有的信息较少,因此一些不同类别的草图具有很高的相似性,很难区分它们.比如香蕉与月亮,它们之间仅仅有些细节方面的不同,若想区分它们就需要提取更多的细节信息.为了解决这个问题,本文引入了细粒度特征分支网络.
由于细粒度特征属于局部特征,主要分布在浅层网络,而本文的主干网络为Resnet18,因此在Resnet18的前几层网络中提取细粒度特征,可以在Resnet18的第1层大尺度卷积池化层及残差块集合1、2、3进行细粒度特征的提取.由于第1层大尺度卷积池化层及残差块集合1的层数过浅,一些局部信息还没有被充分地提取,因此本文分别取Resnet18的第2个残差块及其前面的网络与第3个残差块及其前面的网络作为两个细粒度特征分支网络主干.此外,为了更好地在浅层网络中提取特征,引入了双线性池化[19]化,它是Lin等人提出的一种被广泛应用于细粒度图像分类的方法,可以简单理解为将两个特征通过外乘进行融合以获得更具有辨别力的特征,或者将单个特征通过外乘从一阶特征推广到表征能力更强的二阶特征,双线性池化在细粒度图像分类领域的有效性已经被证明,并被广泛应用.本文在细粒度特征分支网络中加入双线性池化以提取丰富的细粒度特征用于草图分类,具体如图5所示.
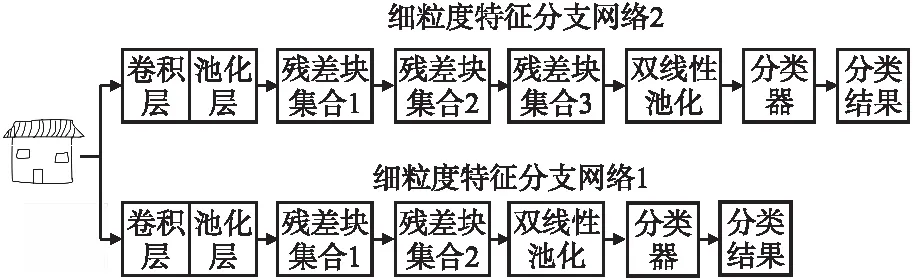
图5 细粒度特征分支网络结构图Fig.5 fine-grained characteristic branch network structure diagram
双线性池化可由表示B=(gA,gB,P),其中gA,gB分别表示两个特征提取器,P表示池化方式.如果gA和gB不相同,则被称为多模双线性池化,如果相同,则被称为同源双线性池化,池化方式又分为求和池化和最大池化.双线性池化通过将gA,gB两个特征提取器所提取的特征进行双线性融合与池化实现.
本文采用同源双线性池化,即gn与gB相同,将Resnet18的部分网络当作特征提取器,池化方式采用求和池化,具体实现方式如式(1)~式(5)所示:
bilinear(l,G,gA,gB)=gAT(l,G)gB(l,G) ∈RM×N
(1)
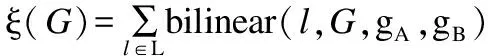
(2)
w=vec(ξ(G)) ∈RMN×1
(3)
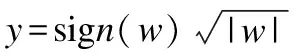
(4)
z=y/‖y‖2∈RMN×1
(5)
式(1)中,gA(l,G)与gB(l,G)表示特征提取器gA,gB在图片G,位置l处提取的特征,维度分别为C×M与C×N;bilinear(l,G,gA,gB)表示将通过特征提取器gA,gB在图片G位置l处提取的特征进行双线性融合,融合通过外乘实现,融合后的特征维度为M×N.式(2)中,ξ(G)表示将所有位置L处的特征通过双线性融合并求和池化后得到的输出特征,维度为M×N.式(3)中,vec表示将池化后的特征ξ(G)拉伸为一维,w表示拉伸后的特征,维度为MN×1.式(4)表示矩归一化操作,式(5)表示L2归一化操作,z为最终的输出特征,维度为MN×1.
3.4 分类结果融合模块
在深度学习领域,分类器大多采用全连接层实现,可分为线性分类器和非线性分类器,在本文中采用的分类器为一个线性分类器,由一个全连接层实现,具体如式(6)所示:
t=z×W+B
(6)
其中z为输入的特征W,B为全连接层的参数.如果z的特征为m维,分类类别为n类,那么全连接层的参数W为m×n为维,B为n维.输入特征通过该分类器,输出一个n维向量t,对应于n类的分类类别,可通过softmax获得输入属于每类的概率,某一维的数值越大表明输入属于该类的可能性越高,数值最大的维度对应的类别即为分类结果.
由于本文采用双阶段训练模式,在初训练阶段,已对各分支网络分别训练得到了各类特征的分类结果.为了在再训练阶段,更好地将各特征的分类结果进行融合,本文提出了一种可训练的分类结果融合模块.该模块可以动态地调整不同特征的分类结果在最终分类时所占的比重,提高分类准确率.分类结果融合示意图如图6所示.
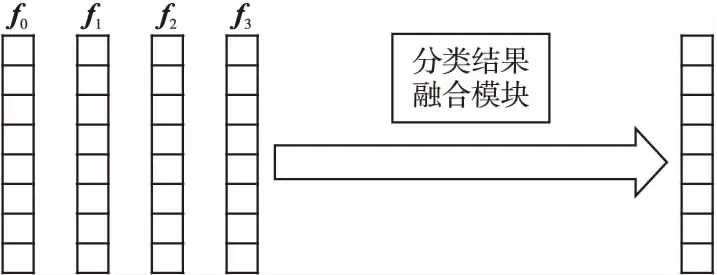
图6 分类结果融合示意图Fig.6 Schematic diagram of classification result fusion
分类结果融合模块可由式(7)表示:
fuse(f0,f1,f2,f3)=sum(cat(f0,f1,f2,f3)⊙S)
(7)
式(7)中f0,f1,f2,f3分别表示粗粒度特征、轮廓特征及两个细粒度特征的分类结果,cat表示拼接,S是一个可训练的融合矩阵,⊙表示点乘,sum表示求和.将f0,f1,f2,f3进行拼接产生一个合并矩阵,先将该矩阵与融合矩阵S进行点乘,然后按类别将预测结果进行求和,产生最终的分类输出.点乘⊙的具体过程如式(8)所示:
(8)
式(8)中,n为草图的类别数,fi,j表示第i个特征对草图是否属于第j类的判断值,与该特征对他类别的判断值相比,该值越大,草图属于第j类的概率越大.Si,j表示对fi,j的权重,可调整fi,j在最终判定时所占的比重,Fi,j是调整后的结果.
3.5 损失函数
交叉熵损失函数经常被用于分类问题,如式(9)所示:
(9)
式(9)中,D是样本总数,n是类别数,tk的维度为n,表示第k个样本在分类器(全连接层)后的输出或分类结果融合后的输出,yk表示第k个样本的真实类别.
本文在初训练阶段时,直接采用交叉熵损失函数;在再训练阶段时,为了减缓分类结果融合模块的过拟合,提出了一个正则化项,如式(10)所示,将其与交叉熵损失函数同时使用.
LM=∑j∈Jmax(std(Sj)-m,0)
(10)
式(10)中,std表示取方差,m为一个可设置的阈值,使得融合矩阵对每个特征分类结果的加权参数(每一列)保持方差稳定.在再训练阶段时,损失函数如式(11)所示:
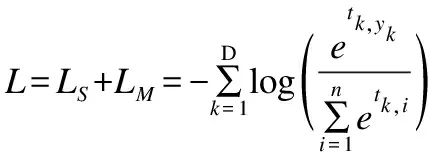
(11)
4 实 验
4.1 实验数据与实验设置
本文在TUBerlin数据集[17]上进行了实验,该数据集包含250个类别.每个类别包含80个草图,数据集中的样本总数为20000个.图7为TUBerlin数据集中的某些示例.

图7 TUBerlin数据集示例图Fig.7 Sample diagram of Tuberlin dataset
本文使用pytorch框架实现了该模型.在训练阶段,两次训练分别采用了Adam优化器与SGD优化器,学习率分别设置为0.0001与0.01,批次大小分别设置为32和50,并采用了水平翻转进行数据增广.在实验部分,将训练集和测试集按2∶1的比例划分,同时将训练集按9∶1的比例再次分成两部分,一部分用于初训练阶段各分支网络的训练,另一部分用于再训练阶段分类结果融合模块的训练.因此,初训练阶段训练集、再训练阶段训练集与测试集比例为9∶1∶5.为了便于同其他方法做对比,也进行了训练集和测试集其他比例的实验.此外,本文使用了在imagenet大型数据集上的预训练参数初始化网络.
4.2 不同特征分类结果融合的影响
为了验证不同特征分类结果融合的有效性,本文比较了不同数量的特征分类结果融合的效果,如表1所示.其中f0f1f2f3分别表示粗粒度特征、轮廓特征及两个细粒度特征的分类结果.
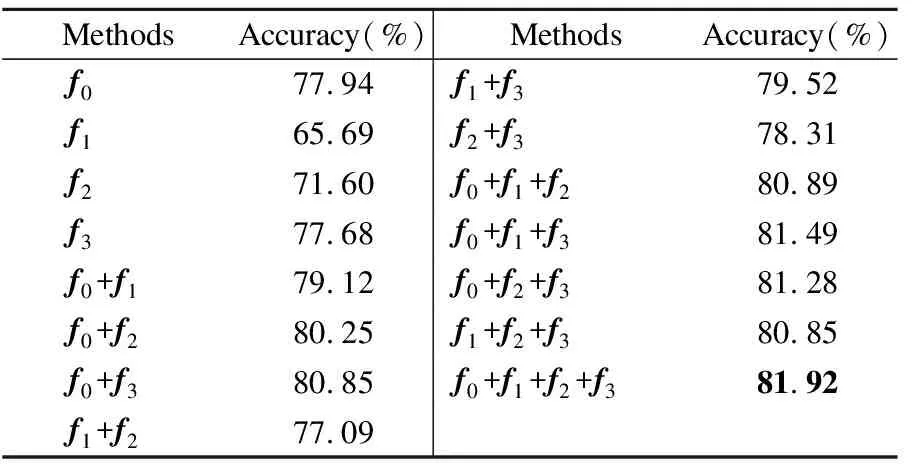
表1 不同特征分类结果及相互间不同融合的对比Table 1 Comparison of different feature classification results and different fusion between them
从实验结果可以看出,多个特征的分类结果融合比单个特征的分类效果更好,当采用4个特征的分类结果融合时,效果最好.这是因为多个特征分类结果的融合可以更好地利用草图的轮廓特征,细粒度特征和粗粒度特征,识别出一些难以区分的草图.
4.3 不同网络层提取细粒度特征的影响
为了比较从不同浅层网络提取的细粒度特征的分类效果,本文比较了使用主干网络Resnet18中第1层大尺度卷积池化层后的特征分类结果ffirst conv,第1个残差块集合后的特征分类结果ffirst res,第2个残差块集合后的特征分类结果f2及第3个残差块集合后的特征分类结果f3,实验结果如表2所示.

表2 不同网络层提取细粒度特征的分类效果对比Table 2 Comparison of classification effects of fine-grained features from different layers
从表2可以看出f2与f3的准确率明显优于ffirst conv与ffirst res.这是因为第1层大尺度卷积池化层与第1个残差块集合在网络中的层数过浅,特征还未充分提取.因此选择f2与f3作为细粒度特征的分类结果,从表1中也可以看出这种选择的有效性.
此外,本文也做了在已选择f2与f3作为细粒度特征分类结果的情况下继续增加ffirst conv与ffirst res的实验,实验结果如表3所示.完整模型表示同时使用细粒度特征分类结果f2、f3,粗粒度特征分类结果f0、轮廓特征分类结果f1.

表3 向完整模型继续添加其他特征分类结果的影响Table 3 Influence of add other features′ classification result to the complete model
从表3中可以看出,向完整模型继续添加第1层大尺度卷积池化层后的特征分类结果ffirst conv与第1个残差块集合后的特征分类结果ffirst res后,效果反而下降,这是因为它们对原有特征造成了干扰.
4.4 不同细粒度特征表征的影响
为了探究双线性池化与其他细粒度特征表征对分类效果的影响,本文比较了采用原始特征,及分别使用双线性池化,CBP[20],LBP[21],HBP[22]提取细粒度特征的分类效果.CBP与LBP相对于双线性池化,对原始特征进行了映射,精简了计算方法,HBP采用了跨层的特征融合,可以利用两层特征相互间的联系.实验结果如表4所示.其中,f2与f3表示单个细粒度特征分类结果,完整模型表示将细粒度特征的分类结果与其他特征的分类结果相结合后的最终分类结果.
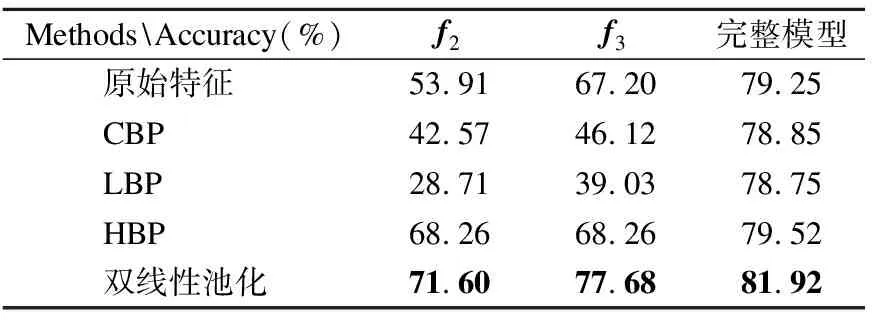
表4 不同细粒度特征表征的影响Table 4 Influence of different fine-grained feature representation
从表4中可以看出,对于细粒度特征表征,双线性池化的分类准确率高于其他方法,因为CBP与LBP方法在精简计算方式时对特征进行了映射,不能很好地反映原特征.而HBP方法在跨层融合时,由于草图在不同网络层间的信息相差过大,导致了部分有用信息的丢失.
4.5 损失函数中正则化项的影响
为了验证本文提出的正则化项的有效性,做了对比实验,LS为交叉熵损失,LS+LM为加入正则化的交叉熵损失,比较了在进行分类结果融合时,两种损失的不同效果,实验结果如表5所示.
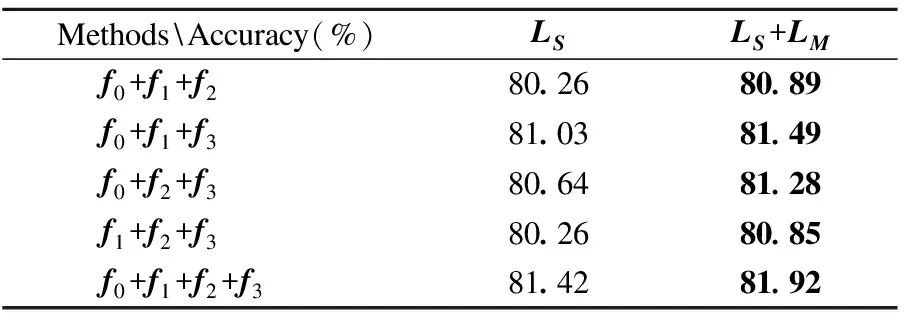
表5 加入正则化项的对比Table 5 Comparison of adding regularization parameters
从实验结果可以看出在损失函数中加入正则化项后,分类准确率提升.这是由于正则化项可以有效地减缓融合模块的过拟合.
4.6 不同融合方法的影响
为了验证本文提出的分类融合模块的有效性,将该模块和现有的一些类似的方法进行了比较.将不同特征的分类结果进行拼接放入支持向量机(SVM)、逻辑回归、决策树、随机森林进行分类训练,实验结果如表6所示.

表6 不同融合方法的对比Table 6 Comparison of different fusion methods
从实验结果可以看出,本文的融合方法优于其他方法.主要因为该融合方法可以动态地调整不同特征的分类结果在最终分类时所占的比重,更好地利用每一种特征的分类结果.
4.7 双阶段训练的影响
为了验证双阶段训练的有效性,本文做了共同训练与双阶段训练的对比实验,共同训练是将各分支网络与融合模块作为一个整体一起进行训练,训练集与测试集的比例设置相同为2∶1(双阶段训练的训练集被二次划分用于两个阶段的训练),实验结果如表7所示.
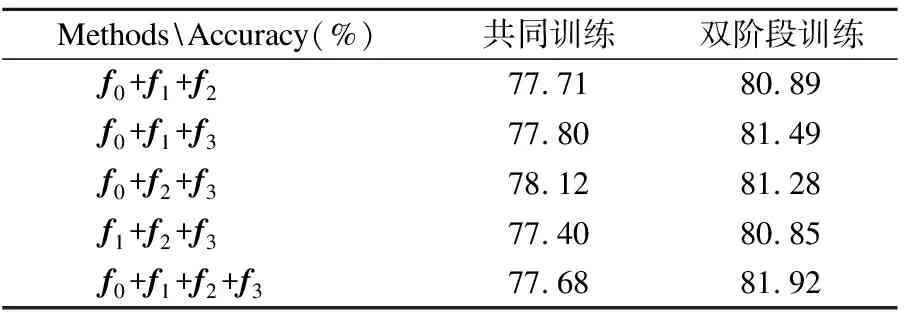
表7 不同训练方式的对比Table 7 Comparison of different training methods
从实验结果可以看出,双阶段训练的分类准确率明显高于共同训练.在双阶段训练中,每一个分支网络单独进行训练,模型对每部分的特征都会尽力提取,不会受到其他分支网络的影响.而在共同训练时,模型对各个分支网络的重视程度不同,导致特征的提取不充分.因此,双阶段训练优于共同训练.
4.8 与不同方法的对比
将本文方法与其他的草图分类方法做了比较,人类识别率[17]表示TUBerlin数据集上人类识别的平均准确率.HOG-SVM[17](Histogram of Oriented Gradient -support vector machines)和FV-SP[12](Fisher Vector-Spatial Pyramid)是基于手工特征的方法,HOG-SVM使用了BOF(Bag of Features)特征和支持向量机结合的方法,FV-SP使用了SIFT特征和Fisher特征相混合的方法.Sketch-a-Net1[1]、Sketch-a-Net2[2]、Transfer Learning[5]、Dynamic Landmarks[6]、Deformable-CNN[7]、CNG-SCN[8](Cousin Network Guided-Sketch Classification Network)、 Hybrid-CNN[10]、DeepSketch1[13]、DeepSketch2[14]、MAD[16](Mixed attention densenet)、SketchPointNet[15]和Double-Channel CNN[23]是基于深度学习的12种方法.为了便于公平比较,本文将训练集测试集的比例设置与其他方法相同,括号内为训练集与测试集的比例.MFRF(multi-feature result fusion )为本文所提出的方法,实验结果如表8所示.
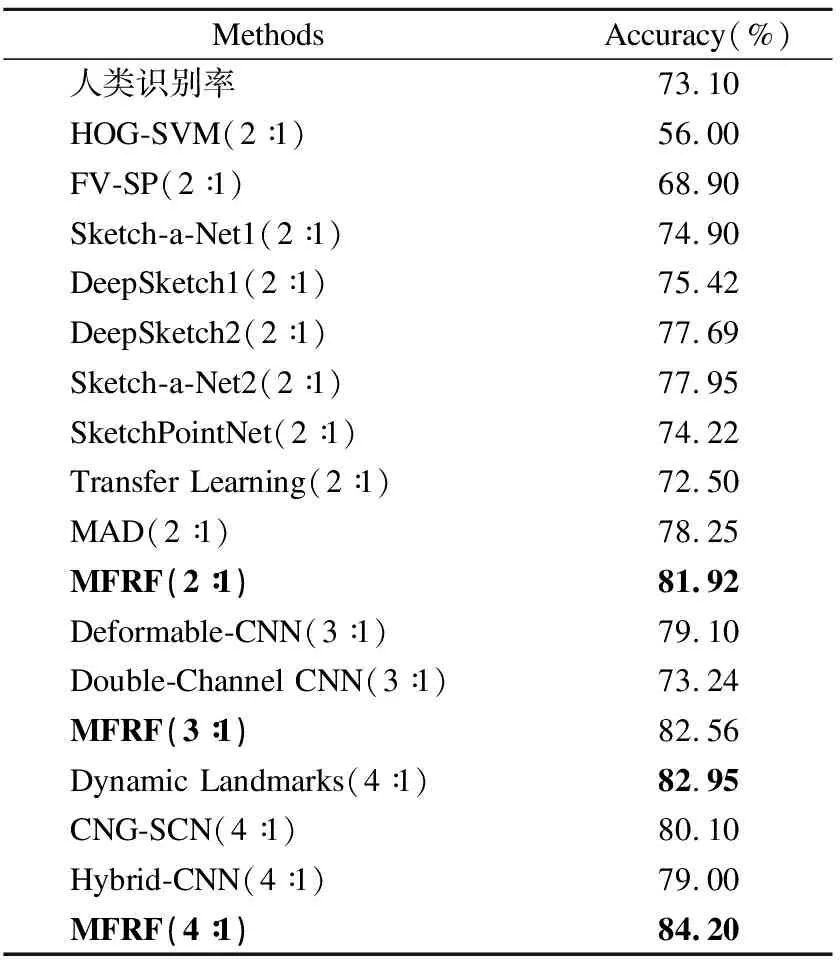
表8 不同方法的对比Table 8 Comparison with different methods
由实验结果可以看出,使用手动特征的HOG-SVM、FV-SP方法分类准确率较低,没有超过人类的识别准确率.深度学习方法的分类准确率更接近人类的识别准确率或比人类的识别准确率高.本文方法在训练集、测试集的比例为2∶1、3∶1、4∶1时分别取得了81.92%、82.56%、84.20的分类准确率.在训练集、测试集同等比例的情况下,较DeepSketch1,DeepSketch2,Sketch-a-Net1,Sketch-a-Net2,Transfer Learning,Dynamic Landmarks,Deformable-CNN,Hybrid-CNN,CNG-SCN、MAD和SketchPointNet方法提高了7.02%,6.50%,4.23%,3.97%,4.50%,9.42%,3.67%,3.46%,1.25%,4.10%,5.20%.这是因为本文方法采用了更多的特征,而其他方法仅采用了一种特征或两种特征,同时双阶段训练与融合模块的使用使得多特征的提取与利用比其他方法更加充分.
5 结束语
本文提出了一种基于多特征的双阶段草图分类方法,旨在减缓草图特征不能充分利用的问题.该方法分两个阶段进行训练,在初训练阶段,通过Resnet18网络获得草图的粗粒度特征分类结果;引入双线性池化获得草图的细粒度特征分类结果;提取草图的轮廓以获得草图的轮廓特征分类结果.在再训练阶段,提出了一种可训练的分类结果融合模块,将草图的粗粒度特征、细粒度特征与轮廓特征的各分类结果进行融合,并提出了一个正则化项,以减缓该模块的过拟合,进一步提高了分类性能.双阶段训练使得草图的粗粒度特征、细粒度特征与轮廓特征提取更加充分,融合模块使得各特征的分类结果可以更好地融合,极大地提高了草图的分类准确率.在与其他方法的比较中,也可以看出本文方法明显优于其他方法.本文也存在一些不足之处,由于各分支网络较多,模型的运行速度较慢,时间效率不高,因此下一步工作将考虑如何精简模型结构,提高模型的运行速度.
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
红外技术(2022年11期)2022-11-25
软件导刊(2022年3期)2022-03-25
高技术通讯(2021年1期)2021-03-29
计算机技术与发展(2019年1期)2019-01-21
电脑与电信(2018年11期)2018-02-16
信息安全研究(2016年3期)2016-12-01
福建中学数学(2016年4期)2016-10-19
中学生理科应试(2016年2期)2016-05-30
