
多信息辅助的U型轻量级显著性目标检测模型
2023-09-06 04:29卞叶童
小型微型计算机系统 2023年9期
卞叶童,孙 涵
(南京航空航天大学 计算机科学与技术学院,南京 211106)
1 引 言
近年来,显著性目标检测作为计算视觉领域的热点研究方向之一,引起了世界各地学者的热烈关注.其涉及很多其他计算机视觉任务,比如目标检测[1]、图像检索[2]、目标追踪[3]等等.虽然显著性目标检测的发展离不开对人类视觉机制的模仿和利用,但是由于相比人类还是缺乏相当一部分先验知识,在某些特殊场景下,前景和背景在颜色、纹理等低级信息较为相似时,传统的显著性目标检测方法甚至是一些具有语义信息的深度模型仍易被迷惑.由于传统模型只能够关注局部,所以在具有强大表征能力的全卷积网络被提出后,显著性目标检测领域就出现了一大批基于此的深度模型.伴随着深度模型中一次又一次的下采样,特征的感受野越来越大,蕴含的全局语义线索也越来越多,最终显著图的目标定位较传统模型有了明显的改善.
基于深度学习的显著性目标检测方法在蓬勃发展的同时,也带来了一些问题.常见的显著性目标检测方式是对像素进行二值化的分割[22].而深度模型中一层又一层的下采样之后,分辨率降低,全局信息丰富的同时削弱了细节信息.这使得深度模型预测出的显著图呈现出的边缘非常模糊,有的形状或狭长或蜿蜒的显著性目标区域甚至会因此被漏检.于是浅层细节信息开始被考虑进来,通过适宜的方式(比如U-Net[4])与深度特征进行融合互补,生成既具有细节又拥有完整结构的显著图.除此之外,有的方法还使用了边缘信息作为细节补充.充分利用浅层信息对显著边缘进行明确的建模,加入边缘特征提高模型对边界区域的敏感度和关注度.在融合方式上,若使用简单直接的相加、通道级联的方式,信息融合不充分,不仅没有将各种信息的作用发挥到位,还白白增加了冗余的特征.所以,在融合方式的创新上,又涌现了一批优秀的模型.
当各种补充信息被利用,融合方式达到了令人满意的效果,庞大的参数量、计算量以及内存消耗也随之而来.这显然限制了显著性目标检测作为其他计算机视觉任务中一环的发展应用.VGG[5]、ResNet[6]等优秀的骨干网络,虽然能够充分提取出原始输入中的特征,但是其规模高达几十兆、上百兆,加上其他部分的参数,一个模型常常有一百兆以上甚至几百兆.因此,现有的很多优秀的显著性目标检测模型基本无法满足在现实中生活中移动终端等设备上的投入使用.
如果对显著性目标检测框架特征提取的部分引入轻量级神经网络MobileNet[7],能够大大解放计算力,减少了小型设备中因为模型过大而导致的内存限制,提升了训练速度和检测速度.但是检测精度也会随之下降,边界的清晰度也再次陷入了瓶颈.如何在保持模型轻量的条件下,尽量维持模型的检测效果,是需要攻克的难点.
基于以上问题,本文提出了一个基于多信息辅助的U型轻量级显著性目标检测模型.该模型创新性地使用轻量级模型作为整体框架的骨干网络,并且使用深度可分离卷积代替传统卷积.为了防止模型参数骤减引起的性能下降,本方法引入了显著骨架特征和边缘特征对骨干网络提取出的特征进行补充,分别提高模型对边缘区域以及目标中心区域的敏感度.利用下采样平行融合模块,将最深层的特征进行不同感受野的融合交互,加强模型对图像整体结构的把握.
本文贡献如下:
1)设计了MUN模块(Multi-task U-shape Network),并以此作为解码器的模块单元.MUN模块能够帮助每一层级的特征和显著边缘特征、骨架特征进行多尺度的融合交互,提升模型对于目标边缘和定位的感知能力.
2)提出了DPM模块(Downsampling Parallel Module),可以帮助网络进一步提取不同感受野的深层特征,递进地掌握图像的语义结构.
3)在DPM和MUN模块的基础上,设计出了轻量级显著性目标检测模型LMUNet(Lightweight Multi-task U-shaped Network).该模型在规模和性能之间达到了一个良好的平衡.
4)在不同的数据集上做了大量实验,不仅验证了所提出模块的有效性,通过与其他模型的对比,也证明了LMUNet的优越性.
本文结构安排如下:第2节介绍显著性目标检测领域的研究现状,第3节着重介绍LMUNet和所提出模块,第4节描述所做的大量实验,并展示和分析实验结果,第5节进行全文总结.
2 研究现状
目前,显著性目标检测领域内主要有两个问题需要改善:1)边缘区域预测容易出现模糊不准确的情况;2)虽然深度神经网络可以提取到深度语义信息,但是当前景背景较为相似时,仍会出现目标定位不准确的情况.针对两个问题,Pang等人利用U型结构构建了MINet[8],来对深层特征和浅层特征进行多层次多尺度的特征提取和特征融合.其中,聚合交互模块可以通过相互学习有效地利用相邻层的特征,而自交互模块可以使网络自适应地从数据中提取多尺度信息,更好地处理尺度变化.除了结构上的创新,还有部分模型引入了边缘信息等帮助模型提高对边缘区域的敏感性.比如,Zhao等人提出了EGNet模型[9],在网络内明确建立互补的显著目标信息和显著边缘信息,以保持显著目标边界.同时,突出的边缘特征也有助于定位.通过让这两个互补的任务相互帮助,共同优化了这两个任务分支的表现,从而对显著图进行了明显改善.
多种信息的引入、融合方式的升级,导致了模型结构复杂、规模庞大,限制了显著性目标检测在实际生活中的投入使用.于是,关于轻量级显著性目标检测的模型研究开始了.Liu等人提出了一种新的立体注意多尺度模块,该模块采用立体注意机制进行有效的多尺度学习.以此模块为基本单元,提出了一种用于显著性目标检测的轻量级编解码器架构SAMNet[10](Stereoscopically Attentive Multi-Scale Network).几乎同时,Liu等人还提出了HVPNet[11](Hierarchical Visual Perception Network),其主要构成模块为层次视觉感知模块.该模块的设计灵感来源于灵长类的视觉系统,使用密集连接的结构来模拟视觉层次结构,并使用空洞卷积来模拟多尺度视觉信号在具有不同群体感受野的不同皮层中受到的分层处理.这些模型在达到轻量级的同时还保持了不错的性能.
3 LMUNet网络模型
3.1 总体结构
模型的主要框架分为解码器部分和编码器部分.编码器部分主要是由一个骨干网络和DPM模块组成.骨干网络用于从原始输入进行特征提取,这里使用的是MobileNet.当然,此处可以被替代为任何一个轻量级的骨干网络.根据MobileNet中的输出特征的大小,将其分成5个模块.最接近输入的模块的输出大小为112×112,输出随着模块的加深逐级减小一倍,最后一个主干网络模块的输出是7×7.其中,最浅层模块的输出和最深层模块的输出被共同送进多任务特征提取模块进行骨架特征和边缘特征的提取.如图1右上角所示,4个3×3的卷积被用于生成显著性的边缘,然后用显著性边缘标签对其进行监督.显著性边缘标签由原始标签通过梯度计算得到.同样地,显著骨架图也通过4个卷积层来获取.经过可行性分析,本文决定仅使用显著性目标的骨架进行额外的信息补充.用于监督骨架图生成的标签由原始的二值化显著标签得到.首先,对原始的显著标签使用matlab中operation为“skel”的 bwmorph函数,作用是移除显著目标的边界,但是不允许目标隔开,由此保留下来的像素就是显著目标的骨架.然后对得到的骨架进行腐蚀操作和膨胀操作,平滑骨架标签.最终得到的骨架标签就可以对骨架特征分支进行监督.由于不需要特别精细的边缘图和骨架图,也为了尽量减少模型的参数,所以此处对边缘特征和骨架特征的提取方式并没有采用特别复杂的结构.
骨干网络的最后一个模块的特征输出,已经是7×7大小的深层特征.从以往经验看来,7×7分辨率特征所具有的感受野仍然不能够在前背景相似的情况下将显著目标准确定位出来,所以此处,使用DPM模块进行更进一步的全局语义线索推理.
解码器部分由5个MUN模块来进行多任务特征融合以及分辨率还原.MUN的输入除了上一级MUN模块的输出,还有骨干网络中对应尺度的侧输出以及来自多任务特征提取模块的骨架特征和边缘特征作为补充信息.注意图1中,虚线表示对应尺度的侧输出特征流,而实线表示其他特征流.其内部结构针对输入的不同特点设计了一对一的融合方式,能够在减少大跨度信息扰乱的同时将各种信息进行妥善的过渡统一.MUN的输出除了被送进下一个MUN模块,还会通过一个的卷积层侧输出一个显著图,由原始显著标签进行监督.由于最底层的尺度过小,生成的显著图经过线性插值还原分辨率之后,非常模糊,并且误差会很大.对此显著图进行监督的话,不仅不能正确清晰的帮助模型掌握目标定位,反而会带来扰乱.所以参与监督的实际上只有4个中间预测显著图,并且四个显著图损失的权重依据分辨率从高到低的顺序依次削减.整个模型框架的最终输出是由4个中间预测图通道级联再压缩得到的单通道显著图.
上述结构看起来并不简单,模型参数量却只有2.70M,是因为在整体的结构上使用了一些轻量级的设计.前文中提到的所有卷积操作,使用的都是深度可分离卷积.深度可分离卷积大大减少了参数量,但是却几乎维持了标准卷积的效果,非常适合轻量级模型.除了卷积,本文还将解码器部分的通道数都通过3×3的深度可分离卷积压缩到64,这样有利于与补充信息进行融合,相较于使用128通道的模型也大大降低了整体规模.值得注意的是,MUN模块的设计虽然和整体框架形成一个嵌套式的U型结构,但是由于大部分操作是在多重下采样之后的特征上进行的,所以并没有带来大量的参数增加,在相对小的代价下,获得了相对丰富的多尺度特征.
3.2 多信息辅助U型模块
U型网络的优越性在于其深浅层信息的融合效力能够在特征被逐渐稀释的同时,为对应尺寸的解码层输送包含相对丰富细节的特征补充.但是,嵌套式的U型结构会导致参数规模指数级扩大,这就违背了最初的创新动机.为了能够发挥U型结构的特长,同时又能够尽最大可能减少参数量的增长,本文重新设计了一个U型的多尺度多任务特征提取模块.如图2左边部分所示,模块的主要组成部分是深度可分离卷积.深度可分离卷积主要分成两个部分,首先是对输入的图像进行分通道的卷积操作,每个通道对应一个卷积核.在针对通道的卷积操作之后,跟着一层BN层以及一层ReLU层进行归一化和激活.第2个部分针对像素进行的1×1卷积,这一步几乎等同于传统的1×1卷积,但是由于卷积核面积较小(面积为1),所以也没有带来很多额外的计算量.同样地,在这层卷积层之后,也跟随着BN层和ReLU层进行进一步的处理.编码器部分仍是通过一步步的下采样操作来获得更具全局视角的深层特征,解码器部分通过上采样操作来还原分辨率.每个MUN模块的输入和输出大小相同,通道数也被统一为64.

图2 不同版本MUN模块结构对比Fig.2 Comparison of different versions of MUN
MUN模块融合的信息种类包括边缘特征和骨架特征.这两种补充信息的特点各不相同,边缘特征富含细节,需要有较大的分辨率来承载;骨架信息偏向于结构化,其生成较偏重于深度信息,比较粗糙.图2左半部分所展示的第1种融合方式中,MUN将短连接从解码器传送过来的信息和骨架信息、边缘信息在MUN模块入口处就进行融合卷积.这种无差别对待的方式没有考虑到两种补充信息的特点.根据以往经验认为,骨架特征具有的语义线索更多,相对较深层的信息也是具有较多的语义信息,这两种特征的分布可能更为相近,且特点相似跨度较小.所以设计了图2右半部分的融合方式,在模块入口仅将边缘特征下采样到与骨干网络的侧输出特征相同大小,然后使用像素对齐相加的方式将该两种特征和上一MUN模块的输出特征融合成一个新的64通道特征.经过2~3次深度可分离卷积之后,将骨架特征加入.此时,MUN已经逐渐加深,得到的特征也开始具有结构性.加入的方式依旧使用像素对齐相加.在实验部分,对两种模块的表现进行了对比,实验结果表明第2版本的融合方式更加能够适应不同特征的不同特点.最终选用第2种融合方式作为最终网络的解码器模块.
3.3 下采样平行模块
在骨干网络中,特征的分辨率逐渐被下采样操作减小,其中蕴含的信息也从丰富的细节信息转换成了深度语义信息.如果将最浅层的特征和最深层的特征相融合形成新的特征,由于两种特征的分布差距过大,这种不一致性会导致融合效果下降.所以为了避免这种特征间跨度过大引起的融合失败,DPM模块采用了相邻特征平行融合的方式.
如图3所示,DPM模块对输入特征进行了不同的操作,生成了3个分支.首先,对输入分别做一次深度可分离卷积和空洞率为2的空洞卷积,这就形成了3个分支中的两个.两个分支拥有不同的感受野,但由于空洞率仅为2,所以特征分布仍较为接近.然后再对输入做下采样,以获得更具全局视野的特征,并对该特征进行一次卷积,形成了第3个分支.相邻分支特征分别进行点对点相乘,用于增强两个相邻特征中都检测为显著性的部分,削弱有任何一方认为是非显著区域的部分,并将该特征作为补充信息,加入第1阶段的特征融合.第1阶段的特征融合将相邻分支特征相加,并加入该两个特征的对齐相乘进行局部修正.至此,3个分支融合成了两个分支,分别对其进行一次卷积操作.第2阶段的融合将两个分支的特征进行相加,再进行一次卷积操作.最终得到的特征作为DPM模块的最终输出,参与解码器中的分辨率还原.

图3 DPM模块结构Fig.3 Structure of DPM
3.4 损失函数
LMUNet网络总共涉及到需要监督的有7处,其中,一处是边缘特征提取部分,需要对显著边缘图进行监督,还有一处是骨架特征提取部分,也需要生成一个对应的显著骨架标签来帮助建模.其余5处是作为网络最终输出的综合显著图和解码器4个MUN模块的侧输出,这4个侧输出经过线性插值和显著标签进行尺寸对齐,由原始显著标签进行监督.在本章节中出现的模型皆是在数据集DUTS的训练集上进行的.该数据集提供显著标签,但是不提供显著边缘标签和骨架标签.为了减少扰乱,仅使用显著性目标的边缘作为边缘标签.出于同样的考虑,骨架也仅使用显著性目标的骨架.显著性骨架标签基于原显著标签,将显著性目标的外圈像素逐渐腐蚀,但是必须保证连通的像素区域不增加,不改变图像欧拉数.由此得到的骨架图会因为有些边缘有些锐利而生成多余的骨架分支,不符合人类视觉机制对于目标骨架的定义.于是,在此基础上,也如同在文献[12]中的做法,对显著骨架标签通过腐蚀和膨胀函数进行平滑处理.最终效果图如图4第4列所示,其中第3列是基于显著标签得到的显著边缘标签.

图4 显著边缘标签(第3列)和骨架标签(第4列)Fig.4 Salient edge ground truth and skeleton ground truth
同文献[13]使用的边缘函数损失函数类似,使用的是针对边界的Edge Loss:
(1)
en代表是的显著边缘预测图中的像素值.W代表的是整个模型的参数.logPr(en=0|W)代表的是像素值en被计算为1的显著性像素的概率.E+表示的是显著性像素集合,E-表示非显著性像素集合.显著图的监督还使用了常用的二值交叉熵损失(BCE Loss:Binary Cross Entropy Loss)和交并集之比损失(IoU Loss:Intersection over Union Loss).此处骨架的损失函数也参考了文献[12],使用二值交叉熵损失.该损失函数可以被写成:
SkeletonLoss=-w(i,j)(p(i,j)log g(i,j)+(1-p(i,j))log(1-g(i,j)))
(2)
其中,w(i,j)是每个像素点的权重,默认是1.和p(i,j)和g(i,j)分别是位置(i,j)处的预测值和真值,即Ground Truth中对应的值.整体损失函数的公式为:
(3)

4 实 验
4.1 数据集和实验设置
模型的训练过程使用的是DUTS-TR,该训练数据集包含了10553张图片.使用的优化算法是随机梯度下降法,初始学习率为1e-2,冲量设置为0.9,权重衰减设置为5e-4,batchsize为16.由于MobileNet的参数已经经历过预训练,而其他部分的参数是经过随机初始化方法进行初始化的.所以在训练过程中,对骨干网络的参数和其他模块的参数使用不同的学习率以适应处于不同调整阶段的迭代.具体实现上,对骨干网络部分使用的学习率是其他部分的十分之一.训练完成之后,分别在5个数据集上进行了多项评估和比较.这5个数据集分别为,包含5019张图像的DUTS-TE数据集[14]、包含1000张图像的ECSSD数据集[15]、包含850张图像的PASCAL-S数据集[16]以及包含4447张图像的HKU-IS数据集[17].关于模型的评估,使用了4个评估指标从不同的角度去检验模型优劣,分别是平均F值(mF:mean F-measure)[18]、平均绝对误差(MAE:mean absolute error)[19],结构度量值(Sm:structure-measure)[20]以及增强匹配指标(Em:enhanced-alignment measure)[21].
4.2 消融实验
在本节中,将对前面提出的模块进行消融实验,以验证所作出创新点的有效性.
4.2.1 多任务U型网络模块
MUN的设计目的是为了将显著边缘特征和骨架特征融合进解码过程,对在编码器中被稀释的特征进行补充和修正.如表1所示,随着MUN的信息逐渐丰富,模型的整体性能也逐步提升.UN是单纯的U型网络,仅对编码器和上一个UN模块的输出做提取融合,但是由于在结构上对单层特征进行了多尺度的提取和交互,所以也展现出了不错的效果.是在UN的基础上,融合了边缘特征.边缘特征加入后,在DUTS-TE数据集上,mF提高了4.1%,MAE降低了1.3%.这说明边缘信息的补充起到了相当的局部优化作用,并且设计的U型模型能够正确地将边缘信息融入,发挥其作用.同时,能够反映结构预测准确性的Sm和Em分别提高了1.3%和3.3%.整体来看,边缘特征不仅帮助了边缘局部区域的预测,还对整体结构预测有改善.要注意的是MUN1和MUN2结构的不同,对边缘和骨架的融合方式区别在MUN的编码器中加入骨架Skeleton的时机,图2展示了这两种结构的具体区别.可以看到,当无差别地对待边缘特征和骨架特征,由于加入了辅助信息,性能还是有一定的提升.但是提升幅度逊于MUN2,这是因为没有考虑两者的区别,用同一种方式融入两种信息,导致骨架特征给浅层特征带来了一定的噪声和扰乱,从而影响模型的判断.由实验数据可以看出,MUN2由于考虑了不同特征分布的差距,将骨架特征的加入时机安排在较深层,所以在性能上表现更为优秀.MUN2较MUN1在mF上提升了1%,MAE降低了0.6%,而Sm和Em分别提高了1.4%和0.9%.而加上skeleton的MUN2方式相比只加edge的方法,整体评价指标也有提高,这不仅说明skeleton的加入对模型有辅助作用,而且MUN2的融合方式也是有效的.最终的对比实验中使用的是MUN2版本.
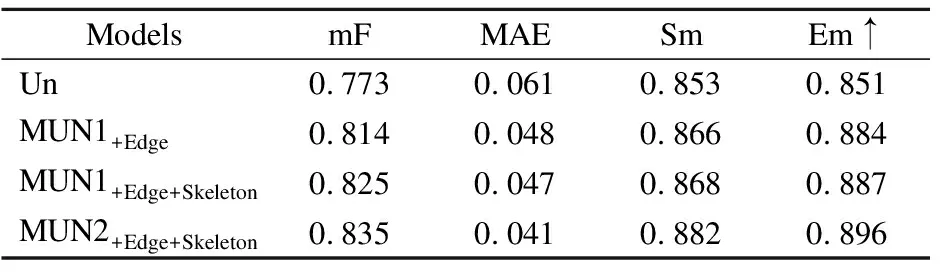
表1 基于DUTS-TE数据集的MUN不同版本模块消融对比Table 1 Comparison between different versions of MUN module on DUTS-TE
4.2.2 各模块消融实验
根据表1的结果确定使用MUN2作为解码器的主要组成模块,表2中展示了MUN2模块和DPM模块被逐渐加上之后模型的表现.Base模型是仅使用UN模块作为解码器组成、MobileNet作为编码器的模型.MUN2模块被加入之后,在图像局部预测与整体结构预测上都有了很大的提升.DPM被加入后,在两个数据集的各个指标上也都有进步,足以说明DPM的有效性.提升效果不如MUN2明显,猜测是因为使用的是轻量级网络MobileNet作为骨干网络去进行深度特征的提取,由于体量较轻,在最深层的时候可能提取到的深度信息没有其他非轻量级网络那么丰富.而DPM的进一步提取恰好建立在第5个最深的模块输出上.若后续有一些更优秀的轻量级模型被提出,可以灵活地应用在LMUN网络框架中,或许可以进一步发挥出DPM的优势.整体看来,网络本身的结构设计是高效的,MUN2模块和DPM模块的加入对模型的性能提升都有进一步的贡献.
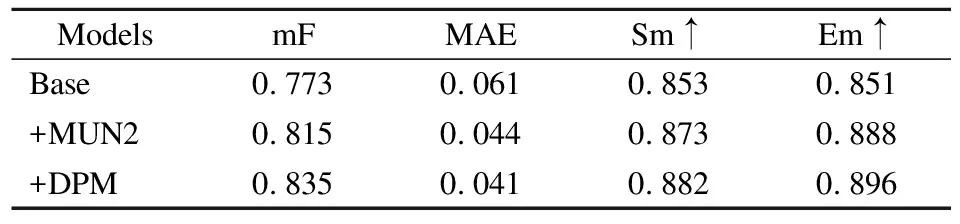
表2 基于DUTS-TE数据集的各模块消融对比Table 2 Ablation comparison of each module on DUTS-TE
4.3 对比实验
4.3.1 数据对比
为了验证LMUNet的优越性,本节中做了大量的对比实验.为了体现对比的公平性,所有的评估结果均来源于各个模型论文中所提供的各大数据集上的显著图,并且使用同一套评估代码.进行对比的SOTA(State of the Art)模型一共有9个.其中,非轻量级模型有7个,包括R3Net[23],PoolNet[24],EGNet[9],MINet[8],LDF[25],F3Net[26]和GCPANet[27].由于轻量级显著性目标检测的研究目前还比较少,所以用于轻量级模型对比的网络只有两个,即SAMNet[10]和HVPNet[11].
表3中展示了LMUNet与其他两个轻量级网络在DUTS-TE测试数据集上的计算时间对比.采用的单位为每秒帧率(FPS:Frame Per Second).可以看出虽然LMUNet虽然规模略大于HVPNet和SAMNet,但是在检测速度上明显超越了两者.

表3 LMUNet与其它轻量级模型的速度对比Table 3 Speed comparison between LMUNet and other lightweight SOD models
关于模型精度的对比在表4中给出,第2列展示了各个模型的参数量,单位为M.表4中结果显示,本文所提出了方法在精度上已经能够超越大部分非轻量级模型,但是整体效果仍略逊于F3Net和LDF,但是LMUNet的模型参数量只有两者的近十分之一.对比HVPNet,本文提出的模型在各个数据集上平均关于mF超过了4.98%,关于MAE下降了1.75%,而Sm和Em平均提升了2.38%和2.45%.虽然LMUNet的参数量为2.70M,略高于另外两个轻量级模型,但是也满足轻量级的要求,能够很好地应用在实际场景中.以上足以证明本文所提出模型在各个数据集上都达到了最优的性能.
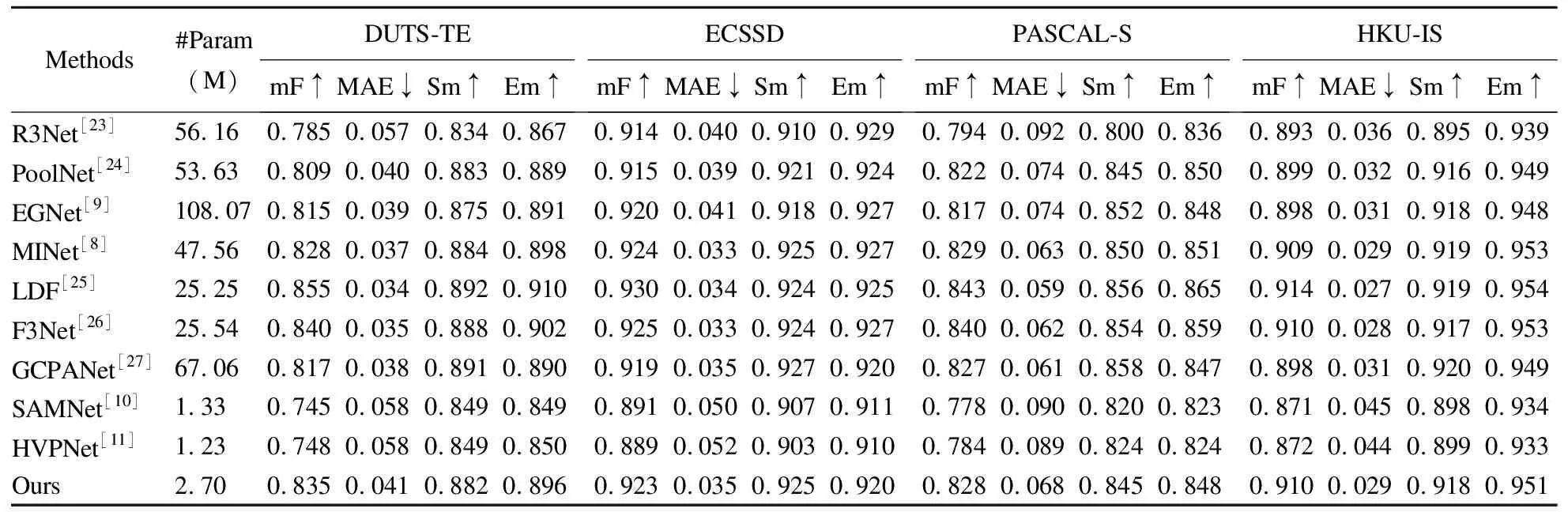
表4 提出模型与9种模型在DUTS-TE、ECSSD、PASCAL-S和HKU-IS数据集上的对比Table 4 Comparison between LMUNet and other SOTA models
4.3.2 可视化对比
图5中展示了LMUNet和一些SOTA模型的可视化结果对比.图5中第1列是原图,第2列是真值标签.第3、4列是两个轻量级模型SAMNet、HVPNet,最后一列是本文所提出的模型.其他是一些非轻量级模型.对比第1、3两行,LMUNet的显著图相较其他轻量级模型更为清晰、准确,在大量缩减参数的同时,还能达到和其他非轻量级模型不相上下的预测水平.对比其他4列,本文所提出模型在人类视觉系统的评判标准下不仅超越了其他轻量级模型,甚至优于一些非轻量级模型.综上所述,LMUNet在边缘区域和整体目标定位上都表现出了优越的性能.

图5 所提出模型与其他优秀模型的可视化结果对比Fig.5 Visualized comparison of the LMUNet and other SOTA models
5 总 结
本文提出了一种基于多任务信息补充的轻量级嵌套U型显著性目标检测网络,简称LMUNet.显著性目标检测作为一项涉及多种计算机视觉任务的研究,其速度和精度都需要达到较高水准.但是目前领域内几乎很少有轻量级模型的出现,庞大的参数规模限制了显著性目标检测在移动设备上的应用,也阻碍了和其他视觉任务的结合使用.所以LMUNet借鉴了目标检测轻量级网络MobileNet的部分结构作为骨干网络,同时使用深度可分离卷积代替普通卷积,减少参数量.为了防止轻量化后的模型表现严重下降,分别设计了MUN模块和DPM模块.MUN模块利用边缘特征对模块内的浅层特征作细节补充和边缘区域强调,利用骨架特征对图像特征的结构进行进一步的强化和修正.DPM模块中通过下采样操作和空洞卷积操作获得了不同感受野和全局性的特征,主要作用是为了对模型进行结构信息补充,改善目标定位.考虑到尺度相差过大的特征无法相互适应融合,DPM中使用平行结构进行相邻融合,逐渐将多个特征集成为一个特征.本文提出的方法在4个常用数据集上都获得了不错的性能,在模型大小和精度之间达到了进一步的平衡,与其他优秀模型的对比阐述了本模型的有效性及优越性.
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
中国新技术新产品(2020年5期)2020-05-06
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
通信产业报(2016年44期)2017-03-13
中国煤层气(2014年3期)2014-08-07
电视技术(2014年19期)2014-03-11
温州职业技术学院学报(2013年4期)2013-03-11
雕塑(1999年2期)1999-06-28
