
一种基于注意力的两段式单像素对抗样本生成方法
2023-09-06 04:30王俪蓉关志涛
小型微型计算机系统 2023年9期
王俪蓉,关志涛
(华北电力大学 控制与计算机工程学院,北京 102206)
1 引 言
作为人工智能领域的重要分支,深度神经网络被广泛运用在自动驾驶[1]、智能安防[2]、人脸识别[3]、医学图像处理[4,5]等领域.而随着图形处理器的飞速发展以及计算机自身硬件能力的不断提升,算力得到了跨越式的提高,深度学习在计算机视觉领域的应用不再局限于分类任务[6],被逐步应用到目标检测[7]、图像分割[8]、图像融合[9]等复杂的图像处理任务,深度学习逐渐展现出其无可比拟的能力[10].深度学习的强大是由于其出色的表征及学习能力,深度神经网络能够从输入的样本中逐层提取特征,浅层网络提取图像表层的空间特征,深层网络提取高阶的语义特征,二者相结合共同表征图像所蕴含的特征[11].
虽然深度学习已经被证明具有十分卓越的数据处理能力,但其本身仍存在一些缺陷,影响了深度学习模型的安全性.2015年,Szegedy等人[10]发现,在被深度神经网络分类正确的干净样本上添加一点微小的噪声,生成一张人眼看上去与原图几乎没有差别的新图像,将其再次输入模型后却会得到错误的预测结果.这样被修改后的样本被称为对抗样本(adversarial samples),所添加的微量的噪声被称为对抗扰动(adversarial perturbation).2014年,Goodfellow基于对抗样本提出了对抗攻击的概念,即对原本能够正确识别干净样本的目标模型,输入修改后的对抗样本,虽然肉眼察觉不出变化,但模型却能以很高的置信度将其识别为错误类别[12].
在2018年,Jiawei Su等人提出了单像素攻击算法[13],限制修改的像素点个数,而对于扰动强度并不加以约束,从而实现用极少量的像素点实现高维空间上的攻击.不同于其他需要通过不断反向传播以对整张图像添加扰动来实现攻击的对抗攻击方法,单像素攻击是一种只修改单个像素点的前向传播算法.单像素攻击方法拓宽了图像对抗样本的探索边界,考虑了极限条件下的对抗样本生成,利用差分进化(Differential Evolution,DE)算法求解最优扰动,将扰动像素的空间坐标信息(x,y)及修改值RGB编码为五元组(x,y,R,G,B).单像素攻击的基本思想如公式(1)所示,其中x=(x1,x2,…,xn)表示原始输入样本,modelc(·)表示深度神经网络,向量e(x)=(x,y,R,G,B)表示所添加的扰动,分别表示原图上的目标扰动点坐标(x,y)以及该点处的RGB值.寻找对抗样本的过程就是在约束d下找到最优解e(x)*,此处限制扰动像素的个数d=1.
(1)
单像素攻击基于标准差分进化算法生成对抗样本,依据神经网络的反馈结果引导扰动的进化方向,直至扰动收敛或训练过程达到最高迭代次数[14].仅通过差分进化实现攻击使得单像素攻击方法无可避免的存在一些差分进化自身所具有的缺陷.进化算法对控制参数以及变异策略比较敏感,求解的优劣依赖于种群规模以及迭代次数的设定,为了能够求得全局最优解,需要在大规模的种群中进行多轮迭代搜寻,而计算量的增加会导致效率低下,造成求解速度慢.其次,由于进化算法局部搜索能力不足,导致求解过程容易陷入局部最优解,造成早熟收敛以及搜索停滞的问题[15].由于差分进化算法容易陷入局部最优解,且求解速度慢,而单像素攻击完全基于差分进化算法开展攻击,故存在差分进化算法所具有的弊端,攻击效率低下.
基于以上问题,本文提出基于注意力的两段式单像素对抗样本生成方法,主要贡献如下:
1)在单像素攻击中引入注意力机制,将暴力求解五维扰动的过程分解为两个阶段,避免单一使用搜索算法进行求解,提高了攻击效率.
2)首先利用类激活图生成方法确定候选扰动区域,在此基础上生成对抗样本,提高了单像素对抗样本的可迁移性.
3)本文在CIFAR-10数据集上针对3种深度学习模型分别进行攻击,并与单像素攻击方法进行比较,实验结果表明本文的方法在攻击成功率上有7.61%的提高.同时在隐蔽性上与其他类型的对抗样本进行比较,证明本文生成的对抗样本隐蔽性更好.
2 相关工作
自从对抗样本问世以来,越来越多对抗攻击方法被提出,深度学习的安全性受到威胁.对抗攻击能够有效实施的原因在于模型的训练集不可能覆盖所有可能的样本,所以训练得出的模型只能拟合极小部分已知的样本,导致模型拟合边界与所期望的真实决策边界有偏差,这部分偏差就是对抗样本所存在的空间[16].对抗攻击可以被形式化为有约束的最优化问题,基本思想如公式(2)所示:
(2)
其中f表示目标函数,x表示原始输入样本,e(x)为所添加的扰动.求解扰动的过程就是在获取使得模型f对样本分类错误的最小改变量.
对抗攻击按照攻击目标可以分为目标攻击和非目标攻击,目标攻击使得目标模型将输入误分类为指定类别,而非目标攻击只需要目标模型预测的类别与正确类别不同即可.快速梯度攻击算法(Faster Gradient Sign Method,FGSM)由Goodfellow提出[12],算法的主要思想是首先确定损失函数梯度变化最快的方向,即“梯度的梯度”,在此方向上添加噪声,导致模型分类错误.FGSM为后续基于梯度变化生成对抗扰动的方法奠定了基础,在FGSM之后,提出了一种迭代的FGSM方法——BIM(the Basic Iterative Method)[17],不同于FGSM只在梯度方向上添加一次扰动,BIM迭代的在梯度方向上添加小的扰动,每次添加扰动后都需要重新计算一次梯度,这样的方式带来了精度的大幅提高,但不可避免地带来了过量的计算代价.深度欺骗攻击DeepFool[18]也是一种基于迭代的攻击方法,每次为图像添加一个小的扰动向量,逐渐向模型拟合的决策边界靠近,直至原始输入样本被移动至边界的另一边,造成模型误分类.Papernot等人[19]提出了雅可比映射攻击(Jacobian-based Saliency Map Attack,JSMA),通过计算模型前向传播的梯度来确定输入图像的哪些像素点会对模型预测结果产生更大的影响,以此来确定需要扰动哪些像素点.
不同于以上仅针对单张样本寻找对抗扰动的方法,Mossavi-Dezfooli[20]等提出了通用对抗扰动生成算法(Universal Adversarial Perturbations,UAP),对为数据集中的样本生成通用扰动,使得所有样本添加相同的扰动之后都能成功实现攻击.
近几年随着生成对抗网络(Generative Adversarial Networks,GAN)[21]的兴起,因其强大的学习能力和迁移性,GAN逐渐被应用在对抗攻击方法中.Baluja[22]首次提出ATN方法,利用GAN生成对抗样本.Xiao等人[23]在基于神经网络生成的攻击算法中首次引入了GAN的思想,提出了包含生成器、鉴别器和目标模型的AdvGAN网络,将随机输入生成器的噪声经过鉴别器的不断训练,转化成可以实现攻击的有效的对抗扰动.扰动的隐蔽性由GAN中的对抗损失来约束.2020年,刘恒[24]等人将通用对抗扰动与生成式对抗网络结合,通过GAN的训练,使得生成器可以制作出通用性对抗扰动.在CIFAR-10数据集上实现了89%的攻击成功率.
此外,还有许多其他形式的对抗攻击方法.Xiao等人[25]提出了stAdv(Spatially Transformed Adversarial)方法.对局部图像特征进行平移、扭曲等空域变化.Athalye等人提出的BPDA(Backward Pass Differentiable Approximation)则针对破碎梯度策略来生成对抗样本.破碎梯度策略是一种用于防御FGSM等基于梯度的对抗攻击的方法,首先将输入样本通过一个不可微函数进行预处理,使得后续模型得到的结果也不可微,攻击者也就无从计算模型梯度.BPDA的主体思想是在反向传播求解梯度时通过一个可微的函数来近似梯度,生成对抗样本[26].
3 基于注意力的两段式单像素对抗样本生成
受针对注意力的攻击(Attack on Attention,AoA)[27]方法的启发,本文首次在单像素攻击中引入注意力机制.利用类激活图生成方法Grad-CAM(Gradient-weighted Class Activation Mapping)[28],提出一种基于注意力的两段式单像素攻击方法(Attention based Two-stage One Pixel Attack,ATOA),避免单像素对抗样本生成过程中单一使用差分进化,同时也使得对抗样本具有较高的可迁移性.
3.1 算法框架
本文所提算法ATOA的整体框架如图1所示,其中X为原始样本,L为样本真实标签,modelc表示训练好的目标分类模型,models表示类激活图生成模型,XS为所生成的类激活图,pos是坐标信息(x,y)的候选解集,为后续求解扰动划定候选区域,X′为候选对抗样本,在所有的候选对抗样本中进行选择,保留最优解进入下一次循环,X*为最终生成的对抗样本.
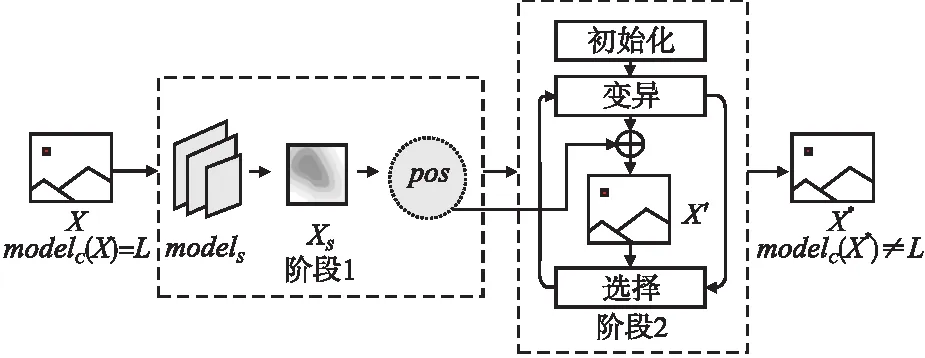
图1 方案框架图Fig.1 Framework diagram of the method
由图1所示的算法框架图可知,ATOA整体被分为两个阶段,第1阶段是基于注意力的候选区域求解算法,用以获取所有候选像素的坐标集pos;第2阶段是基于差分进化的求解算法,经过多轮迭代,搜索最佳坐标(x,y)及该像素上攻击效果最好的RGB值,最终输出最优对抗样本X*.两个阶段的具体求解过程分别在3.2节以及3.3节中详细展开.
3.2 基于注意力的候选区域求解算法
首先,为了获得像素坐标(x,y)的候选集,需要计算类激活图来筛选候选区域,以便缩小候选坐标范围.针对输入的原始样本,利用Grad-CAM生成该输入样本的类激活图Xs.
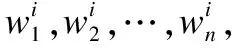
(3)
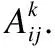
(4)
步骤2.将特征图的所有通道线性组合.
步骤3.将上一步组合得到的结果送入激活函数ReLU进一步处理.这是由于在计算类激活映射的值时,只希望得到与计算正相关的特征.故利用ReLU的特性去除负相关的部分,将步骤2、步骤3组合即获得公式(5):
(5)
在本文的方案设计中利用RGB三通道来表示每张图像.与常见的热力图(heat map)相似,可以认为图像上与类别相关度越高的区域,响应值就越高,在热力图中高亮显示.这一特性在类激活图上显式表示为该区域RGB3个通道中代表红色属性的R(Red)分量高.R分量高代表该像素点对计算得到高Sc起正作用.根据类激活图的这一特性,本文选择R分量作为像素重要程度的评判依据,将Xs中R分量最大的像素作为进入第2阶段进行迭代的候选点.但是大部分情况下,一张图像上并非只有一个R分量最高的点,所以对于每张输入图像,都将得到一个候选解集pos,用以保存图上所有R分量最大的坐标(x,y).
在此阶段,获得位置信息(x,y)的候选解集,长度大于等于1.
3.3 基于差分进化的求解算法
在第2阶段,利用差分进化的思想,第1步初始化,第2步变异,第3步选择,最终求得最优五维扰动解.
步骤1.初始化.首先随机生成候选值RGB的初始解集D.在RGB的搜索空间[min,max]范围内初始化一个容量为np的父代种群Dn(n=1,2,…,np),种群中所有个体向量的维度为3,分别代表RGB三通道的灰度值.初始化种群中每个个体Di的第j维,初始化过程如公式(6)所示:
Di,j=minj+rand(0,1)·(maxj-minj)
(6)
其中rand(0,1)表示0~1范围内均匀分布的随机数,在完成初始化后,得到了包含np个初始候选解的集合D.
步骤2.变异.首先定义变异种群为V.则第n轮种群Vn如式(7)表示:
Vn=Dn1+F(Dn2-Dn3)n1≠n2≠n3
(7)
F∈[0,2]是一个实常数因数,为变异算子.n1、n2、n3是用于确保生成变异解的父代各不相同的随机数.
步骤3.选择.从初始化和变异步骤分别生成的解集中选择更优者进入下一轮迭代.标准差分进化需要给出适应度函数,用以筛选候选解.在ATOA中,将分类模型modelc作为适应度函数,选择操作根据适应度值进行判断,在真实类别下的置信度越低,则适应度值越高,代表该候选解更符合对抗样本生成的要求.
步骤3的完整流程如算法1所述.
算法1.选择算法
(Selection Algorithm)
输入:X,modelc,pos,T
输出:X*
1.t←1(initialization); /*第一轮迭代*/
2.fort≤Tdo
3.iflen(pos)>1then/*判断pos的长度*/
4.fori=1tolen(pos)do/*轮询所有候选坐标*/
5.forj=1tonpdo/*轮询所有候选解*/
6.X′Di=X[xi,yi,Di];
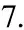
10.endfor
12.Di←Vi;/*则将初始解替换为变异解*/
13.endif
14.else/*pos长度为1的情况*/
15.forj=1tonpdo
16.X′Di=X[xi,yi,Di];
20.endfor
22.Di←Vi;
23.endif
24.t←t+1;
25.endfor
26.returnthebest(x,y,R,G,B),X*;
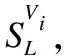
以上为第一轮迭代的所有操作,在经过T轮步骤2及步骤3的迭代后,可以得到在该点下的全局最优解(x,y,R,G,B),使得模型对X′分类错误(即modelc(X′)≠L),该X′即算法最终生成的对抗样本X*.
若长度大于1,则需要在pos集中轮询所有的候选坐标点,对每个点都进行上述3步操作.分别得到每个候选位置处的唯一最佳修改值后,再根据每个点的得分进行最优解的选择.经过两次嵌套轮询,首先确定RGB三维再确定坐标二维,求得完整的五元扰动编码(x,y,R,G,B),在原始样本X上进行修改即获得了最终的对抗样本X*.
4 实 验
在本文中为了验证基于注意力的两段式单像素攻击方法可行,且较原始单像素攻击算法更有效,在多个模型上进行了对比实验,从对抗样本的攻击效果、隐蔽性、可迁移性3个方面进行评估.实验环境是由Intel i9-10900K@ 3.70GHz以及Nvidia RTX3090组成的服务器,选用的数据集是CIFAR-10,该数据集包含10个类别,50000张训练集图像,以及10000张测试集图像,每张图像尺寸为32×32.本节所有的实验是在pytorch框架下实现的.
4.1 评价标准
4.1.1 攻击成功率(attack success rate)
攻击成功率表示目标模型被攻击后的分类准确率下降程度,即目标模型初始分类准确率与被攻击后的分类准确率的差值.对抗攻击方法的攻击能力与攻击成功率呈正相关,攻击能力越强攻击成功率越高.
4.1.2 精度(precision)
P值,即查准率,表示被判别为正例的正样本(TruePositives,TP)占所有被模型预测为正例的样本(predictedaspositive)的比例,所有被判别为正例的样本包括真正例TP以及被误判为正例的假正例(FalsePositives,FP).数据集所包括的每一类都如式(8)计算得到精度值.精度是针对目标模型的预测结果而言的,衡量的是被模型分类为正例的样本中有多少是真实的正例,即模型对类别的分类准确能力.精度越高表示模型分类正确的能力越强.
(8)
4.1.3 召回率(recall)
R值,即查全率,表示被判别为正例的正样本占所有真实正例(actualpositive)的比例,所有正例是指真正例TP以及被模型误分类为反例的正例(FalseNegatives,FN).目标模型对每一类样本的分类结果将分别用于计算得到该类的召回率.召回率是针对所有样本的真实标签而言的,衡量的是样本中的正例有多少被正确识别.召回率越高表示模型从所有样本中识别出正例的能力越好,其计算公式如式(9)所示:
(9)
4.1.4F1得分(F1score)
精度和召回率同为衡量模型性能的两个重要的指标,在评价模型时,在精度和召回率上都得到较高得分的模型性能更好.但事实上精度和召回率一般情况下是互相矛盾的,所以需要综合考虑这两个指标,求二者加权平均.在本节中认为P值和R值二者对于方案评估同等重要,故为二者赋予同样比例系数,即可得到F1得分如式(10)所示:
(10)
4.2 模 型
在本文的对比实验中,选择3种经典的CNN模型[29],分别为Alexnet[30],Resnet18[31],以及VGG16[32].这3种深度卷积网络的经典模型在图像分类任务上都取得了非常优异的成绩.它们的网络结构分别在表1、表2、表3中进行展示.

表1 Alexnet网络结构表Table 1 Structure of Alexnet

表2 Resnet18网络结构表Table 2 Structure of Resnet18

表3 VGG16网络结构表Table 3 Sturcture of VGG16
4.3 对比实验
针对CIFAR-10数据集,分别采用本文提出的基于注意力的两段式单像素攻击以及原始的单像素攻击方法对3种模型进行非目标攻击.输入的原始样本如图2所示,对应生成的类激活图效果如图3所示,为便于后续计算,对类激活图均上采样至原始样本的大小.
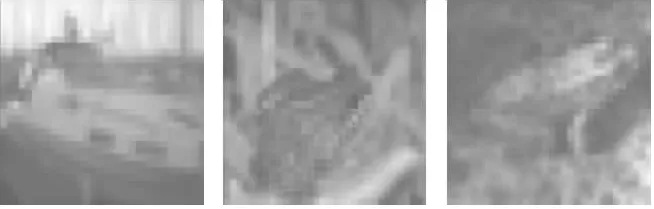
图2 原图Fig.2 Clean samples
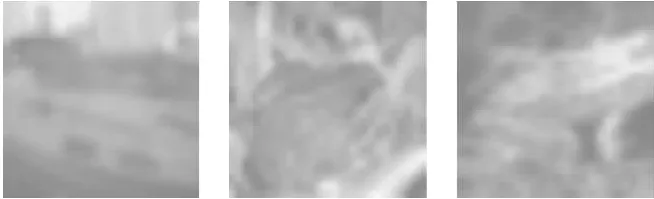
图3 类激活图Fig.3 Class activate mappings
这里需要注意的是,在实验时为了能在原图上清楚的进行展示对比,需要将计算得到的类激活图与原图进行叠加.在实验结果展示中为避免削弱原图的清晰度,指定类激活图的权值为0.3,原图权值为0.7,即:
Xs=0.3×Xs+0.7×X
(11)
另外,由于CIFAR-10的样本尺寸较小(32×32),为了便于观察将其等比例放大,不可避免地造成图像清晰度有一定程度的下降.后续所有图像展示均为将其放大至224×224尺寸后的效果.
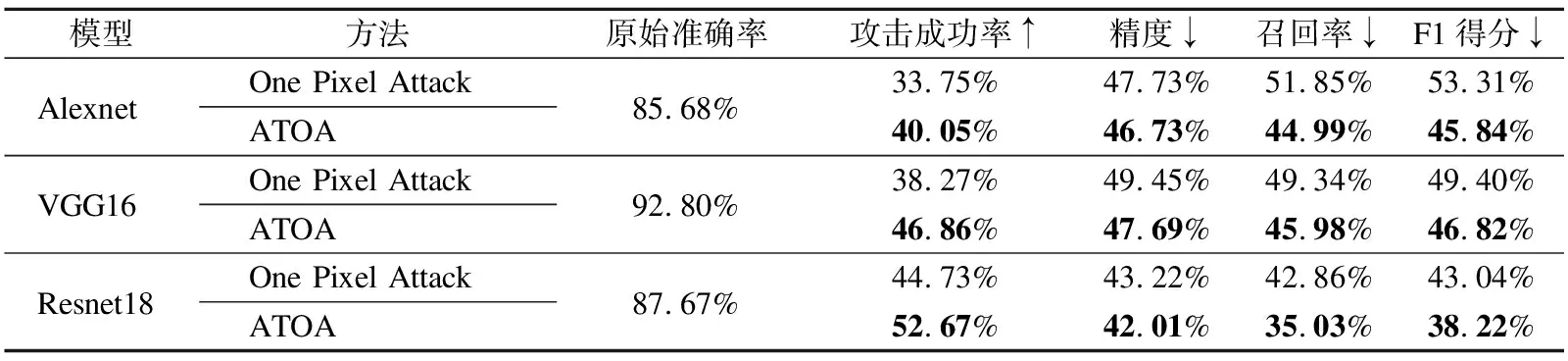
表4 原始单像素攻击方法与基于注意力的两段式单像素攻击方法在3种模型下的攻击效果对比Table 4 Comparison of the attack effect between the One Pixel Attack and the Attention based Two-stage One Pixel Attack method(ATOA)under the three models
从表4可以看出,在3个目标模型均已达到较高的分类准确率的前提下,在攻击成功率上ATOA相较于单像素攻击方法平均提高了7.61%,平均精度及召回率上也较单像素攻击方法有所下降,F1得分指标下,本文中的方法比原始方案平均下降了4.92%.综上可以证明,ATOA相较于单像素攻击方法,攻击强度更高,效果更好.
4.4 隐蔽性对比实验
单像素对抗样本最显著的优势就是其隐蔽性,单像素攻击方法只能修改单个像素点,所以其扰动程度远远小于很多其他对抗攻击方法.很多对抗攻击方法为了实现更高的攻击成功率往往会造成对抗样本的质量下降,对抗攻击算法需要在二者之间寻求平衡.为了证明本文的方法仍然保持优异的隐蔽性,依据图2中随机选取的原图,分别对应展示以VGG16为目标模型,ATOA与经典算法FGSM以及Deepfool所生成的对抗样本.可以明显看出,ATOA生成的对抗样本(如图4所示)与图2中的原始样本几乎没有差别,肉眼仍可分辨其类别.但是FGSM生成的对抗样本如图5所示有很大程度上的失真,与原图相差甚远,人眼可以很清楚的区分出对抗样本与原图.Deepfool生成的对抗样本如图6所示也存在这样的问题,生成的对抗样本甚至人眼已无法识别其所属类别.

图4 基于注意力的两段式单像素攻击对抗样本Fig.4 Adversarial samples in ATOA

图5 FGSM对抗样本Fig.5 Adversarial samples in FGSM

图6 DeepFool对抗样本Fig.6 Adversarial samples in DeepFool
4.5 可迁移性对比实验
此外,在迁移性方面本文也进行了对比.单像素攻击生成的对抗样本只能对其训练阶段所使用的目标模型进行有针对性的攻击.然而,利用同样的对抗样本对其他任意模型进行攻击则只能获得平均5%左右的攻击成功率.
而ATOA生成的对抗样本具有一定的迁移性,针对VGG16模型生成的对抗样本对Alexnet以及Resnet18模型仍能实现平均40%左右的攻击成功率.在Alexnet及Resnet18模型下的对抗样本同样可以有同等水平的攻击能力,均能达到40%~55%左右的平均攻击成功率.这是因为类激活图被证明具有较强的可迁移性[27].对于同一张图像,不同的分类模型生成的类激活图有很大的相似性,在类激活图上表现为高亮区域几乎完全一致.这说明了深度学习模型在完成分类任务时学习到的特征几乎都是相似的,它们都共享相似的语义特征.而本文所提出的ATOA是在类激活图基础上对全局最优解进行搜索的,所以生成的对抗样本也具有一定的可迁移性.
5 总 结
在本文中,针对原始单像素攻击所存在的一些问题,提出了一种基于注意力的两段式单像素对抗样本生成方法.为避免仅利用差分进化算法在全局范围内进行暴力求解,本文借助可解释性方法在透明性、特征可视化等方面的优势,引入注意力机制,缓解了单像素攻击方法对差分进化算法的过度依赖,充分利用类激活图.首先确定更精确的求解范围,避免对无关区域的过分关注,以此减少冗余解的数量,大大降低了计算量.本文所提出的方案在降低计算量的同时提高了攻击成功率,并兼顾了对抗样本的隐蔽性,在多个不同的目标模型上均能实现有效攻击.综上,本文所提出的基于注意力的两段式单像素对抗样本生成方法是一种卓有成效的对抗攻击方法,攻击效果在单像素攻击的基础上有了明显的改善.在本文的基础之上,后续工作将继续深入研究单像素攻击与不同注意力机制的结合方法.
猜你喜欢
艺术家(2023年8期)2023-11-02
数学物理学报(2022年4期)2022-08-22
小哥白尼(军事科学)(2022年2期)2022-05-25
新世纪智能(数学备考)(2021年5期)2021-07-28
数学物理学报(2019年4期)2019-10-10
红领巾·萌芽(2019年8期)2019-08-27
贵州师范学院学报(2016年3期)2016-12-01
CHIP新电脑(2016年3期)2016-03-10
电源技术(2015年11期)2015-08-22
信息安全研究(2015年3期)2015-02-28
