
AOA-BERT:一种基于对抗学习的方面级情感分类方法
2023-09-06 07:28张华辉
小型微型计算机系统 2023年9期
张华辉,冯 林
1(四川师范大学 计算机科学学院,成都 610100)
2(莆田学院 新工科产业学院,莆田 351100)
1 引 言
方面级情感分类是一种细粒度的情感分析任务,旨在分出不同方面的情感.例如一条方面级评论性文本:“The food was good,but service was poor”,该条评论性文本中包含“food”和“service”两个方面,其中一个方面词“food”由情感词“good”修饰表达积极情感,另一个方面词“service”由情感词“poor”修饰表达消极情感,如何有效地识别海量文本中的不同方面情感具有一定的挑战性.
早期的方面级情感分类任务的研究方法,主要是基于传统的机器学习算法,该类算法一般有复杂的特征工程过程[1].如婉等人[2]提出融合改进Stacking与规则的文本情感分析方法,该方法基于特征工程过程,具有一定的有效性,但构建和对齐数据需要消耗大量的时间、精力,而且训练出来的分类器分类效果一般.黄等人[3]提出了一种情感分类集成学习框架,该框架采用词性组合模式、频繁词序列模式和保序子矩阵模式提取输入特征,该框架采用基于信息增益的随机子空间算法解决文本特征繁多,该框架基于产品属性构造基分类器算法判别评论的句子级情感倾向,工作量巨大.
近年来,随着算力和算法上的突破,深度学习领域迎来飞速发展阶段.通过图卷积网络、循环神经网络等深度网络模型解决方面级情感分类任务问题,取得了较大的进展.如王等人[4]提出一种基于图神经网络的方面级情感分类方法,该方法利用句法依存树和图神经网络增强情感词与方面词的联系,在多个公开数据集上取得较好效果.曾等人[5]提出一种基于双重注意力循环神经网络的方面级情感分类模型,该模型的第1层采用双向循环神经网络编码输入信息提取隐含层特征,并添加位置、方面词等辅助信息,将辅助信息与隐含层特征融合放入第2层双向循环神经网络提取深层特征,具有一定的可行性,取得的效果较好.Zeng等人[6]提出一种基于BERT的局部注意力机制方面级情感分类方法,该方法通过定义了一种以方面词为中心的局部注意力机制,根据不同词语相对方面词的距离,添加不同权重,该方法还附加了后训练任务,使模型可以学习到特定领域知识,该方法具有一定的新颖性,取得了不错的效果.
对比传统机器学习方法,深度网络模型不仅没有繁琐的特征工程过程,而且通过深度网络模型提取的文本特征分类效果往往较好.在方面级情感分类任务上,虽然图卷积网络、循环神经网络、BERT等深度网络取得了较大的进展.但是,大多数深度网络模型,仍然存在分类精度低,泛化能力较弱等问题.为此,提出基于对抗学习的AOA-BERT方面级情感分类模型,本文的主要工作有:
1)提出了一种基于AOA注意力机制的BERT网络,提取文本特征.
2)通过对抗学习算法生成和学习对抗样本,起到一种文本数据增强的作用,极大地逼近模型上界、优化模型的决策边界.消融实验结果表明,对抗学习策略有效,AOA-BERT通过对抗学习算法额外的学习对抗样本能一定程度上增强泛化性.
3)在Restaurant、Laptop和Twitter数据集上,AOA-BERT的准确率分别达83.66%、78.53%、74.86%,对比大多数基线模型,AOA-BERT分类结果有较好的提升.
2 相关知识
2.1 对抗学习
对抗训练是一种常见的对抗样本攻击的防御方法[7].通常情况下,基于对抗样本的模型优化策略是模型正常训练损失附加上对抗训练损失.其中,对抗训练损失[8]可以分为监督学习和无监督学习.
在监督学习中,对抗样本的标签是原训练样本的标签,对抗训练的模型损失为:
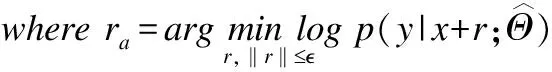
(1)

在无标签的环境下,对抗训练的模型损失为:
(2)
式(2)中,KL[·‖·]表示KL散度.
目前,比较有效的对抗训练算法有FGM算法[8]和PGD算法[9].其中,FGM算法是一种基于当前输入梯度L2范数缩放的一次性计算扰动算法,计算扰动公式为:
ra=·g/‖g‖2,whereg=∇xlogp(y|x;Θ)
(3)
式(3)中,g表示梯度,‖.‖2表示L2范数.
PGD算法基于某个步长的多次迭代优化扰动算法,其生成的对抗样本公式为:
xt+1=Πx+R(xt+α·sign(∇xL(Θ,x,y)))
(4)
式(4)中,R表示扰动集合,α表示步长,L表示损失函数,Πx+R表示以某个扰动阈值为半径的球上投影,如果迭代扰动幅度过大会投影回球面.PGD算法通过α步长迭代多次获得和学习对抗样本,再最优化内部损失和外部损失,公式如下:
(5)
式(5)中,D表示一种数据分布.
2.2 BERT模型
BERT模型[10]与以往的卷积神经网络和循环神经网络完全不同,完全采用Transformer[11]的编码器结构组成.其中,BERT模型注意力机制的一个核心组件是缩放注意力机制(Scaled Dot-Product Attention,SDA).其计算公式为:
(6)
式(6)中,Q、K、V是文本向量化后的查询、键、值矩阵.dk代表K的维度,dk使内积不至于太大,防止梯度消失.
BERT模型注意力机制的另一个关键组件是多头注意力(Multi-Head Attention,MHA),如图1所示,Q、K、V要先进行线性变换,再进行SDA操作,得到某一个头的计算公式如下:
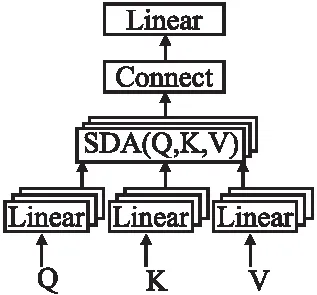
图1 多头注意力机制Fig.1 Multi-head attention mechanism
(7)
一次SDA计算操作是一种角度的特征提取,这种操作要进行多次,即多角度进行特征的提取,也就是多头注意力,然后把SDA提取的所有特征进行拼接和线性变换,得到多头注意力的表示如下:
MHA=(MHA1⊕MHA2⊕…⊕MHAh)·W*
(8)
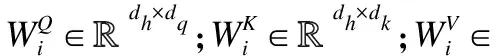
3 AOA-BERT模型
方面级情感分类任务是在一条评论性文本中识别出方面词的情感.假设任意文本表示为:context={w1,w2,…,wb,wb+1,…,wb+n-1,…,wm},文本对应的方面词表示为:aspect={wb,wb+1,…,wb+n-1}.其中,m代表文本的长度,n代表方面词的长度,b代表方面词在文本中的起始位置.那么,方面级情感分类任务可以函数描述为:F(context,aspect)→polarity,其中,polarity∈{1,0,-1},1表示积极、0表示中性、-1表示消极.
AOA-BERT的结构如图2所示,从下往上依次有4部分组成,分别是输入层、编码层、注意力层和分类层.其中,输入层接收两种固定格式的输入;编码层将输入进行编码,映射到不同的空间位置,同时通过对抗学习算法根据当前梯度生成对抗样本;注意层将样本依次放入AOA网络获得文本权重向量,并将权重向量与原始文本相乘获得文本特征向量;输出层将文本特征向量做交叉熵损失,回传模型参数.值得注意的是,对抗样本会模仿对应的训练样本经过其一样的注意力层和分类层网络结构.
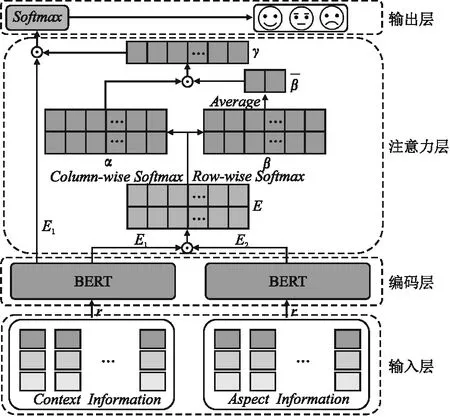
图2 AOA-BERT模型Fig.2 Model of AOA-BERT
3.1 输入层
以上文提到的文本“The food was good,but service was poor”为例.当这条文本的方面词为“food”时,将其预处理成:“[CLS] The food was good but service was poor [SEP]”和“[CLS] food [SEP]”分别用ContextInformation和AspectInformation表示.其中,“[CLS]”表示起始分隔符,“[SEP]”表示结束分隔符.
3.2 编码层
BERT编码过程如图3所示,需要依次经过:Input layer、Embeddings layer、Multi-Head Attention layer、Feed-Forward layer和Output layer.其中,Input layer主要依据BERT字典进行字符的替换、Embeddings layer主要根据“[CLS]”和“[SEP]”等标识进行不同信息的提取、Multi-Head Attention layer主要通过多头注意力机制提取文本的深层特征、Feed-Forward layer主要利用一些可学习矩阵进行必要的线性变换、Output layer主要将前面送来的向量表示多次重复送回前面的网络后直接输出.下面依次详解介绍上述的各个部分.

图3 BERT编码过程Fig.3 Encode process of BERT
3.2.1 Input Layer
将输入层送来的ContextInformation和AspectInformation信息,依据BERT字典一一匹配替换,假设匹配替换后的信息表示为ContextInformation_1和AspectInformation_1.
3.2.2 Embedding Layer
根据“[CLS]”和“[SEP]”等标识,提取关于ContextInformation_1的位置标记信息ContextInformation_2和分段标记信息ContextInformation_3,其三者之间的维度是相同的,最后将ContextInformation_1、ContextInformation_2和ContextInformation_3相加作为Embeddingslayer部分的输出,用X1表示.类似地,还有AspectInformation对应的Embeddings layer输出,用X2表示.
3.2.3 Multi-Head Attention Layer
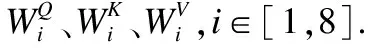
(9)
(10)
(11)
依据SDA公式有:
(12)
接着,对所有MHAi进行拼接转换并附加一个激活函数,得到Multi-Head Attention layer的输出O1:
O1=Tanh((MHA1⊕MHA2⊕…⊕MHAh)·W*
(13)
类似地,还有X2对应的Multi-Head Attention layer输出,用O2表示.
3.2.4 Feed-Forward Layer
在Feed-Forward layer中,O1要经过两次线性变换和一次Relu激活函数,公式如下所示.
FFL(O1)=max(0,(O1·W1)+bia1)W2+bia2
(14)
式(14)中,W1和W2是可学习和随机初始化的权重矩阵、bia1和bia2是偏置.此外,FFL(O1)还要经过随机失活和归一化操作.
类似地,还有O2对应的Feed-Forward layer输出,用FFL(O2)表示.
3.2.5 Output Layer
在Output layer中,将FFL(O1)和FFL(O2)重复6次放回Multi-Head Attention layer和Feed-Forward layer,即将上一过程的输出作为下一过程的输入.最后,FFL(O1)和FFL(O2)对应的最终输出分别用E1和E2表示,为了更好地表示编码层,特将E1和E2表示如下:
E1=BERT(ContextInformation)
(15)
E2=BERT(AspectInformation)
(16)
式中,BERT()函数表示BERT编码过程,ContextInformation和AspectInformation是来自输入层的预处理表示信息.
3.3 注意力机制层
在注意力层中,首先将E1和E2相乘得到交互矩阵,交互矩阵用符号E表示,模型图中以符号⊙表示相乘.然后,通过对交互矩阵E做列式和行式的Softmax,计算过程的公式如下:
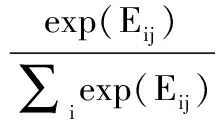
(17)
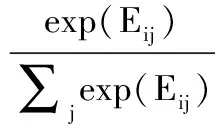
(18)
式(17)、式(18)中,αij表示交互矩阵E做列式Column-wiseSoftmax,βij表示交互矩阵E做行式的Row-wiseSoftmax.
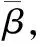
(19)
(20)
最后,将γ与E1相乘得到加权向量δ,再将δ通过一个线性网络得到注意力层的最终向量表示X.上述过程的数学表达如下:
δ=E1γT
(21)
X=δW+bia
(22)
式(22)中,W和bia分别表示随机初始化的可学习矩阵及偏置.
3.4 分类层
通过注意力层的最终向量X计算情感有:
(23)
式(23)中,Z表示样本情感的类别数,yi表示训练样本的情感预测.假设模型参数表示为Θ,那么模型的正常训练损失Loss1为:
(24)
式(24)中,y*表示真实标签的分布,ξ表示L2规范化系数.
特殊地,AOA-BERT附加了基于对抗样本的对抗训练,AOA-BERT通过输入层的ContextInformation和AspectInformation信息分别结合对抗学习算法策略(详见2.1小结),计算出基于当前模型的梯度微小扰动r1和r2,得到输入层对抗样本表示:ContextInformation+r1和AspectInformation+r2,再将对抗样本放入编码层,得到E1+r和E2+r向量,公式如下:
E1+r=BERT(ContextInformation+r1)
(25)
E2+r=BERT(AspectInformation+r2)
(26)
类似地,将编码后的对抗学习样本E1+r和E2+r放入注意力层,最终到达分类层,有对应的对抗样本对抗训练损失Loss2:
(27)
式(27)中,Yi为对抗样本的情感预测.
那么,模型最终的损失Loss为:
Loss=Loss1+Loss2
(28)
最后,分别依据Loss1和Loss2做梯度下降,分别更新模型参数.即在正常训练样本的基础上,生成和学习对抗样本,以优化决策边界.
4 实验及结果分析
4.1 实验数据集
本文采用SemEval2014任务4的Laptop、Restaurant评论数据集和ACL-14 Twitter社交数据集作为实验数据集,如表1所示.其中,Laptop数据集一共有2328条训练数据,积极、消极、中性数据的数量分别是994、870、464,Restaurant数据集一共有3608条训练数据,积极、消极、中性数据的数量分别是2164、807、737.Twitter数据集一共有6248条训练数据,积极、消极、中性数据的数量分别是1561、1560、3127.
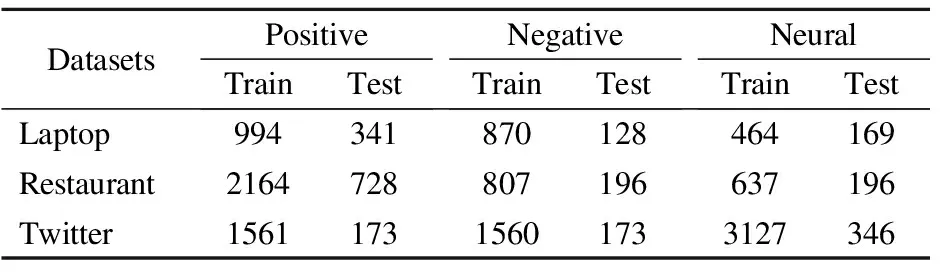
表1 实验数据集Table 1 Datasets of experiment
4.2 评估标准
准确率ACC:分类正确的样本占总样本的比例,公式如下所示.
(29)
式(29)中,Z表示样本情感类别数,T表示分类准确的样本,F表示分类错误的样本.
F1值:由精度和召回率表示,对模型进行综合衡量.精度表示查准的概率,召回率表示查全的概率,F1值的计算如公式如式(30)所示.
(30)
4.3 实验环境
在Linux操作系统和TeslaV100-32GPU下,基于PyTorch深度学习框架开展实验.模型损失的优化器为Adam,BERT词嵌入的维度为768、隐含层维度为300、学习率为2e-5、L2规范化的权重衰减率为0.01、batch-size大小为256、单个token的最大长度为85、采用Xavier正态初始化参数、从训练集中随机抽取20%数据作为验证集、dropout参数依据不同数据集灵活调整、对抗学习优化策略FGM算法扰动阈值为1、对抗学习优化策略PGD算法次迭代次数为3,扰动步长为0.3,扰动阈值为1.
4.4 对比实验
TD-LSTM模型[12],将文本的上文信息与方面词、方面词与文本的下文信息依次基于LSTM网络单独建模提取隐含层特征.
ATAE-LSTM模型[13],将方面词和每个文本单词后放入LSTM网络,将该网络的所有输出嵌入方面词,得到关于方面词的权重向量.
IAN模型[14],分别抽取出方面词和上下文向量单独放入LSTM网络,提取两种信息隐含层向量的平均向量,交互计算两部分权重,将其拼接计算损失.
RAM模型[15],一种基于记忆网络的多层注意力机制模型.
TNet模型[16],一种面向特征变换的中间组件的上下文保留机制模型.
AOA-LSTM模型[17],将方面词和文本在双向LSTM网络上分别单独建模,拼接两部分特征并提取行权重向量和列权重向量,融合两权重向量提取出最终的文本权重向量.将最终的文本权重向量施加在文本隐含层向量上,做交叉熵损失回传参数.
MGAN模型[18],在IAN模型的基础上添加了更多且更细粒度的注意力向量.在公开数据集上,取得了较好的效果.
BERT模型[10],BERT是一种通用预训练语言模型.在方面级情感分类任务上,BERT模型的表现好于大多循环神经网络模型.
CAJIN模型[19],杨等人提出的面向上下文注意力联合学习网络的方面级情感分类模型.
BIAN模型[20],Yang等人提出的基于BERT的交互注意力网络模型.
本文的AOA-BERT模型与上述所有基线模型的比对结果如表2所示.
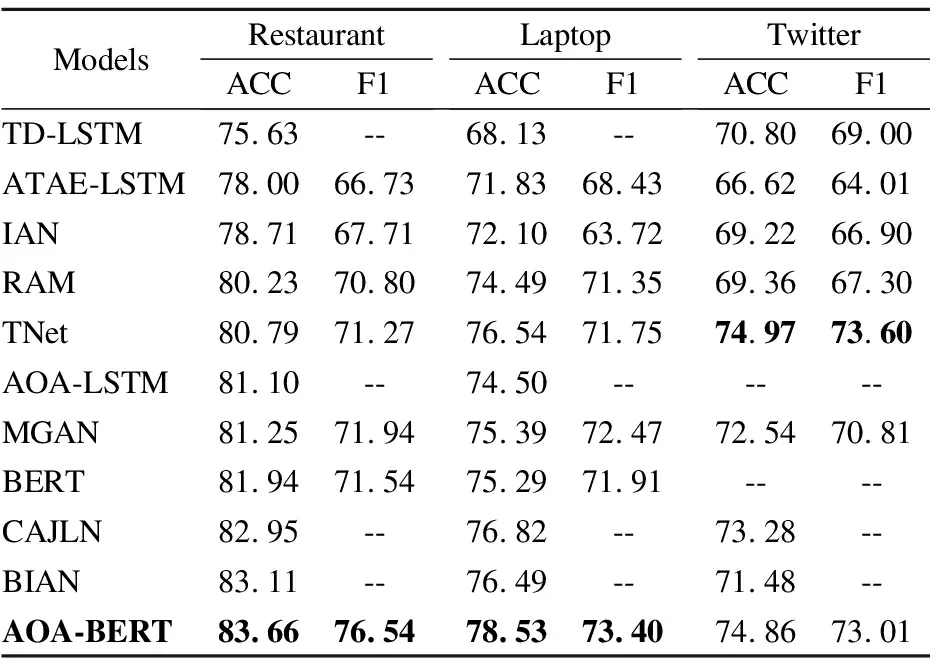
表2 对比实验结果(%)Tabale 2 Result of compared experiment(%)
数据显示,BERT模型在Restaurant和Laptop数据集上的表现好于大多数基于循环神经网络的基线模型,表明了通用预训练语言模型BERT具有优秀的特征提取能力.BIAN是一种基于BERT的IAN模型,在Restaurant、Laptop、Twitter数据集上BIAN对比IAN模型,BIAN的准确率分别提升4.4%、4.39%、2.26%,取得的效果不错,印证了BERT有优秀的特征提取能力.本文的AOA-BERT对比AOA-LSTM模型在Restaurant、Laptop数据集上准确率分别提升2.46%、4.03%,对比BIAN模型在Restaurant、Laptop、Twitter数据集上的准确率分别提升0.55%、2.04%、3.38%,实验结果表明AOA-BERT模型的效果好于大多数基线模型.
此外,ATAE-LSTM、IAN、RAN、TNet模型在Restaurant、Laptop、Twittr数据集上的准确率和F1值依次有规律地、有不同幅度的提升.然而,TD-LSTM和TNet模型在3个数据集上的准确率对比前后模型忽高忽低,证明其泛化能力不佳,提取的特征适合部分数据集.本文的AOA-BERT模型对比基线模型,在3个数据集上的准确率和F1值依次有规律地、有不同幅度的提升,证明了AOA-BERT泛化能力优秀.
综上所述,AOA-BERT模型的分类效果好于大多数基线模型,在不同数据集上的泛化能力优秀.
4.5 消融实验
在本小结中,将AOA-BERT模型进行结构上的拆分,以及对不同对抗学习优化策略的对比分析.其中,在模型不带任何对抗学习算法时,用AOA-BERT-Ⅰ表示;在模型使用FGM对抗学习算法时,用AOA-BERT-Ⅱ表示;在模型使用PGD对抗学习算法时,用AOA-BERT-Ⅲ表示;在模型先后使用FGM和PGD对抗学习算法时,用AOA-BERT-Ⅳ表示.
上述各种模型以及AOA-LSTM模型[14]的消融实验结果如表3所示.数据显示,没有任何对抗学习优化策略的AOA-BERT-Ⅰ模型对比AOA-LSTM模型,在Restaurant和Laptop数据集上准确率分别提升1.39%、1.83%,实验结果证明AOA-BERT-Ⅰ模型有效.持有不同优化策略的AOA-BERT-Ⅱ、AOA-BERT-Ⅲ、AOA-BERT-Ⅳ对比AOA-BERT-Ⅰ模型,在3个不同数据集大体上具有不同幅度的提升,证明了对抗学习的优化策略有效,能有效地优化情感分类决策边界.
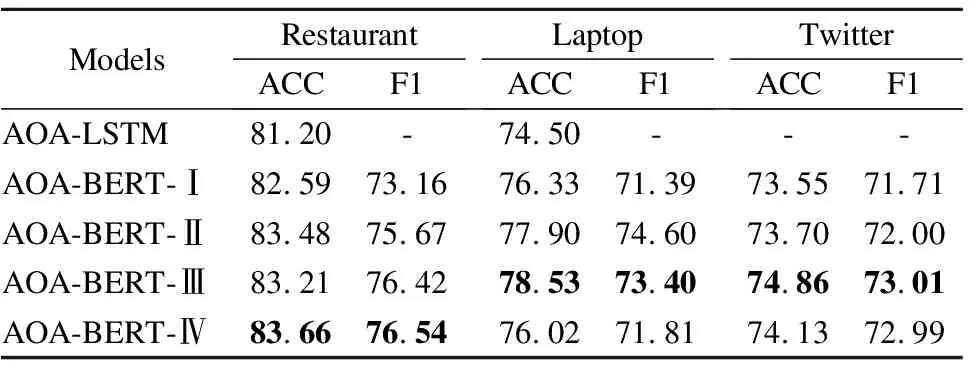
表3 消融实验结果(%)Table 3 Result of ablation experiment(%)
值得注意的是,AOA-BERT-Ⅳ模型在Laptop数据上准确率为76.02%低于AOA-BERT-Ⅰ模型0.31%,这很可能是由于不同数据集对扰动范围的敏感程度不一样,AOA-BERT-Ⅳ模型先后叠加了FGM和PGD两种优化算法,其扰动范围是AOA-BERT-Ⅱ、AOA-BERT-Ⅲ模型的两倍,AOA-BERT-Ⅳ模型在laptop数据集上很可能出现了“过扰动”现象,导致一定分类数据的错判.
5 总 结
早期的方面级情感分类任务大多依靠传统机器学习算法,这类算法往往会在特征工程上消耗研究者大量的精力.近年来,深度网络模型取得了突破性的进展,极大地减轻了研究者在特征工程过程上的消耗.然而,大多数深度仍然还是存在一些问题,如分类效果差、泛化能力弱等问题.为此,本文提出了一种基于对抗样本的AOA-BERT网络方面级情感分类方法,旨在通过BERT提取底层特征,再将底层特征送入AOA注意力网络提取高层文本权重分配特征.同时,为了最大程度地提升模型分类和泛化能力,AOA-BERT还引入了对抗样本,通过3种对抗学习算法生成和学习对抗样本极大地优化了模型的决策边界.
在3个公开数据集上,AOA-BERT基于准确率和F1值作为评价指标,对比10种不同基线模型的实验结果表明:AOA-BERT模型优于大多数方面级情感分类模型,在不同数据集上有优秀的泛化能力,AOA-BERT模型能有效地提取较好的文本特征.消融实现结果表明,AOA-BERT模型采用的对抗学习算法有效,模型结构设计合理.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
