
基于BERT-BiLSTM-CRF的中文分词和词性标注联合方法
2023-09-06 07:28袁里驰
小型微型计算机系统 2023年9期
袁 里 驰
(江西财经大学 软件与物联网工程学院,南昌 330013)
1 引 言
分词是语言信息处理的重要基础技术之一,其任务是把语言句子划分为多个词语.英语句子由多个单词构成,所以分词能够利用单词之间的分隔符进行划分.然而汉语句子的基本单位是字,不能像英文那样按分隔符来分割,因而汉语的分词比英语的分词要困难得多.汉语分词是许多汉语信息处理技术的根本,其正确率直接影响信息检索、机器翻译、信息抽取的结果.近段时间以来,汉语分词技术进展迅猛,然而因为自然语言处理的复杂性,汉语分词仍然是自然语言信息处理的困难之一.
当前大部分的分词算法都视汉语分词为一个序列标记任务,主流的序列标注算法有隐马尔可夫模型(HMM)、最大熵模型(Maximum entropy)、支持向量机(SVM)和条件随机场(CRF)模型.近年来,一些基于深度神经网络的汉语分词方法[1-5]不断被提出.Zhen等人[6]首次提出了利用深度神经网络模型的汉语分词方法;Chen等人[7]扩展了用于汉语分词问题的长短期记忆神经网络模型,解决了普通神经网络方法无法学习长距离依存关系的缺陷,并在分词中获得了良好的结果.Zhang等人[8]引入了一种利用词向量的神经网络分词方法,该方法将长短期记忆模型与卷积神经网络相结合,算法输入端的向量包括从预训练语料集中获得的单词嵌入和字符嵌入.结果表明,长短期记忆模型在序列标记问题中获得了良好的结果.Huang等人[9]首次将条件随机场模型与双向长短期记忆模型融合起来,在序列标记问题中获得了良好的效果.双向长短期记忆模型(BiLSTM)能够同时学习目标词的上下文信息,而条件随机场层能够通过训练和学习获得句子层的标记信息.BiLSTM-CRF算法鲁棒性好,对词嵌入的依赖较小.然而上述方法不能表示多义词.由于它们忽略了单词的语义或上下文,只集中在单词、字符或单词之间的特征提取上,提取的只是一个缺少上下文信息的静态单词向量.针对上述缺陷,Google团队Jacob Devlin等人[22]引入了BERT (Bidirectional Encoder Representation from Transformers)语言模型来描述字符向量或词向量.BERT是一种先进的预训练字符向量或词向量算法,改进了向量模型的泛化性能,全面描绘了字符级、词级、语句以至语句之间关系的特征,并且较好地表示了不同上下文中的语义和句法信息.近年来,张忠林等人[28]综合注意力机制、卷积神经网络和条件随机场,提出了注意力卷积神经网络条件随机场模型应用于中文分词.周慧等人[29]利用BIGRU-CRF模型,引入了一种基于Attention-BIGRU-CRF的分词算法,该算法不但继承了BIGRU模型能够使用相邻标记之间的相关性和双向上下文信息实施分词,它还利用了BIGRU层的输出和输入之间的联系,以大幅改进分词性能.
所谓词性标注就是根据句子上下文中的信息给句中的每个词一个正确的词性标记.词性标记是进一步自然语言处理的重要基础,在许多应用领域,如文本索引、文本分类、语言合成、语料库加工,词性标注都是一个重要环节.因此词性标记的方法研究具有重要意义.当前用于词性标记的语言模型包括统计模型[10-16]和规则模型.利用规则的标注系统与系统设计者的语言能力有关,其中规则集就直接体现了设计者的语言能力.不幸的是,要对某一种语言的各种语言现象都构造规则的话,将是一项很艰难也很耗时的任务.基于统计的方法相对比较主流,主要有最大熵模型(ME)、隐马尔可夫模型(HMM)、条件随机场(CRF)模型等.隐马尔可夫模型是广泛应用于词性标注任务中效果较好的统计模型.针对隐马尔可夫词性标记算法的输出状态独立同分布等不合理假定,在改进隐马尔可夫算法的基础上引进了树形概率[27]和马尔可夫族算法[10].马尔可夫族算法使用条件独立假定代替了独立假定,与条件独立假定相比,独立假定过于强烈,因此利用马尔可夫族算法的语言模型更近似语言现实.树形概率计算方法[32]与隐马尔可夫模型等链式概率计算方法的不同点在于链式概率计算方法里每个条件概率值都要与它前面的条件概率值相乘,但是在树形的计算方式上,只把那些与它在同一条路径上的条件概率值相乘,并且用根节点的条件概率值作为分母.在词性标记中成功运用马尔可夫族算法,词性标记实验数据证明,在相同测试情况下,马尔可夫族算法显著优于隐马尔可夫算法.
完成汉语分词和词性标记两个任务可以考虑两种方法:先分词再词性标记;分词和词性标记同时实施.通常的算法是分别进行这两个任务,然而词性标记的准确性与分词的准确性紧密关联,分词错误也许会制约词性标记的准确性.近年来,分词和词性标注联合模型方面的研究正大量涌现.Xinxin Li等人[30]提出了一种用于汉语分词和词性标记的神经模型,该模型对每个字符使用基于字边界的字符嵌入,并引入Transformer编码器来捕获序列中字符之间的长距离关系,最终标记序列由BiLST-CRF层预测.Binbin Shen等人[31]首次将基于转换的模型应用于韵律结构预测,在ELECTRA编码器的基础上提出了一个简单但有效的联合模型,该模型可以同时预测单词边界和词性标签.联合模型的使用能够大幅减少错误的传播,也有益于利用词性信息进行分词,将两者紧密融合能够帮助消除歧义和提升词性标记、分词的准确性.本文提出了一种基于BERT语言模型、双向长短时记忆神经网络模型、条件随机场的中文分词和词性标注联合方法,该方法将马尔可夫族模型(改进的隐马尔科夫模型)或树形概率的计算方法应用到分词、词性标签推断CRF层的转移概率计算中,大幅度提高了分词和词性标注的准确率.
2 基于BERT-BiLSTM-CRF的分词和词性标记联合算法
词性标记、汉语分词是许多汉语信息处理技术的基础,其正确率直接影响信息检索、机器翻译、信息抽取的结果.将词性标记和分词统一在一个联合模型架构中,能够大幅减少错误的传播,也有益于利用词性信息进行分词,将两者紧密融合能够帮助消除歧义和提升词性标记、分词的准确性.
汉语的词性标记和分词一般被当作是序列标记任务,每个字符在词中的位置和词的词性标记是由它们各自的标记决定的.汉语分词常用标记符号为{B,M,E,S},使用这4个标记来获得单词的边界信息,其中B、M、E代表词的开头、中间、结尾,S表示单字词.本文中文分词、词性标注联合方法采用的标注符号是{B,M,E-tg,S-tg},其中tg表示词性.基于BERT-BiLSTM-CRF的分词、词性标注联合算法由3部分构成:字符嵌入层,BiLSTM层和CRF层.
2.1 基于BERT的字符嵌入层
长期以来,语言模型的研究先后经历了one-hot、Word2Vec、ELMO、GPT和BERT.Word2Vec曾经是语言信息处理中应用最广泛的词向量训练模型,Word2Vec使得深度学习在语言信息处理中广泛应用,并且对语言信息处理的发展发挥了巨大作用.但Word2Vec自身是用于浅层结构的词向量训练模型,并且所获语义信息受窗口大小的影响,因此,一些学者后来提出使用长短时记忆(LSTM)语言模型对单词向量进行预训练,从而获得长距离依赖.普通的长短时记忆模型仅能单向获取信息.Peters[23]提出了语言嵌入模型(ELMo),ELMo模型某些程度上解决了仅能单向获取信息的问题.ELMo是两层双向长短时记忆结构,基于ELMo的语言模型能够获取句子左侧和右侧的上下文信息.此外,Radford[24]等人引入了GPT,GPT利用Transformer编码器当作预训练语言模型,并且可以在此基础上微调下游语言信息处理任务.与长短时记忆模型相比,GPT语言模型的优势在于它能够在更长的距离上获得语句上下文信息,然而它也是单向的.为了使用来自双向的上下文信息,2018年,google团队Jacob Devlin等人引入了BERT预训练语言模型,该算法获得了当时11;类语言信息处理问题的最好性能.BERT模型使用双向Transformer,其在所有层中的特征表示取决于左侧和右侧的上下文.该模型结合了其它模型的长处,抛弃了它们的不足,并在随后的语言信息处理的许多特定任务中取得了较佳的结果[25].
BERT语言模型使用双向Transformer网络模型作为编码器,因此预测每个字符能够双向引用文本信息.模仿中国英文测试中的完形填空测试,随机覆盖一些输入单词,并通过句子中的其它单词来推测被掩盖的单词.另外,句子级别的连续性推测任务被添加到模型训练之中[26].
应用神经网络模型解决汉语分词、词性标记任务,我们需要用向量的方式来表达文本,并利用给定维度的特征矢量来表示字符.字符向量能够描述字符之间的语法和语义相关性,作为字符特征输入神经网络.首先,以字符为单位分割语句,利用BERT模型预处理生成字符xi的含有上下文信息的字向量,得到d维字符向量,构成d×N字符矩阵,这里N代表训练数据中有效字符的数量.其次,对语句中的每个字符xi,设置长度为l=5的窗口(l的值是可改变的),获取xi的上下文字符序列(xi-2,xi-1,xi,xi+1,xi+2).对每个在窗口中的字符,由字符矩阵查找获得对应的向量.最后构造当前字符xi的嵌入向量ei.
2.2 BiLSTM层
循环神经网络(RNN)是一种使用隐藏状态存储历史信息来进行序列标记任务的成功模型.但是梯度消失使得RNN不能较好地处理远距离依赖问题.长短期记忆网络(LSTM)[17]基于RNN模型引进记忆单元记录当前状态信息,利用输入门、输出门和遗忘门三类门结构刷新记忆单元和隐藏状态.LSTM单元组成LSTM网络,一个LSTM单元由输入门、输出门、遗忘门和单元状态组成.输入门控制向单元状态添加新信息,输出门决定隐藏状态的输出,遗忘门决定前一时间单元状态的丢弃信息.设et代表时刻t的输入向量,ht-1代表LSTM单元在时刻t-1的隐藏状态输出,ct-1表示时刻t-1的细胞状态.LSTM在时间t的计算过程能够表示为公式(1)~公式(6):
it=σ(Wiht-1+Uiet+bi)
(1)
ft=σ(Wfht-1+Ufet+bf)
(2)
ot=σ(Woht-1+Uoet+bo)
(3)
(4)
(5)
ht=ot⊙tanh(ct)
(6)
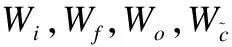
LSTM(长短时记忆网络)利用门机制捕获远距离的历史信息.因为需要同时获得上下文信息,选择了双向LSTM (BILSTM).双向LSTM模型有两个不一样方向的并行层:向前层和向后层.这两层从语句的前端和结尾分别运行,从两个方向存储语句信息,从而提升了词性标记和分词的性能.因此,BiLSTM模型中的输出(隐藏状态)ht计算如下:
(7)
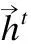
2.3 基于MFM(或TLP)的标记推测CRF层
在基于字符的词性标记和汉语分词问题中,必须考虑邻接标记之间的搭配关系.例如,B(开始)标记后面应当为M(中间)标记或E-tg(结束)标记,而M标记后面不可以是B标记或S-tg标记.因此,不能单独使用ht^来做出标记决策,而是利用条件随机场以联合建模标记序列.条件随机场模型是一种无向图模型,用于计算输入随机变量给定时随机变量输出的条件概率.它融合了隐马尔可夫模型和最大熵模型的特点,拥有处理重叠特征和远距离依赖的能力,可以很好地处理标记偏置问题,因而广泛应用于语言信息处理等领域.
给定句子X=(x1,x2,…,xn)和对应的预测标签Y=(y1,y2,…,yn),yt∈{B,M,E-tg,S-tg},其中tg表示词性.预测标签Y=(y1,y2,…,yn)包含分词信息和词性标注信息,可以分解为分词标签Z=(z1,z2,…,zn),zt∈{B,M,E,S}和分词条件下的词性标注标签p(tg1,tg2,…,tgm|w1,w2,…,wm),其中w1,w2,…,wm为给定句子X=(x1,x2,…,xn)在分词标签序列Z=(z1,z2,…,zn)下的词序列.假设在给定词序列条件下词性标注满足马尔可夫族模型(MFM)[10],即有下式成立:
(8)
对于给定句子X=(x1,x2,…,xn)和对应的预测标签Y=(y1,y2,…,yn),预测评估分数定义如下:
(9)
其中:A系一个分词标记转换得分矩阵,Ai,j计算分词标记i到j的得分;B系词性标记转变得分矩阵,Bk,l计算词性标记k到l的得分;Qi,yi计算字符xi在分词和词性联合预测标记yi上的得分.Qi定义如下:
Qi=Wsht+bs
(10)
其中:ht系BiLSTM模型中t时刻输入数据xt对应的隐藏状态;Ws系权值矩阵;bs系偏置向量.假设在给定词序列条件下词性标注满足树形概率(TLP),即有下式成立:
(11)
则对于给定句子X=(x1,x2,…,xn)和对应的预测标签Y=(y1,y2,…,yn),预测评估分数定义如下:
(12)
在CRF层,语句X被标记为序列Y的可能性概率计算如下:
(13)
深度神经网络训练时,损失函数定义如式(14)所示:
J(θ)=-∑ilog(P(Y|X))+αΩ(θ)
(14)
这里X和Y相应是训练数据中的句子和对应的标注序列,Ω(θ)是为了防止神经网络的过拟合而添加的正则项.
联合学习模型流程图如图1所示.
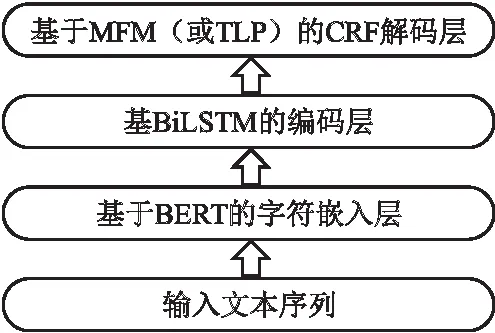
图1 联合学习模型流程图Fig.1 Flow chart of joint learning model
3 实验结果及分析
本文模型的主要设置如下:Transformer层数设置为12,隐藏层的维度设置为768,字向量的维度设置为128,增加维度并不能再提高效果.本文实验学习率取值0.001;实验采用了Dropout机制来防止神经网络过拟合,实验中Dropout设置为0.5.本文主要进行了分词和词性联合标注实验.
分词和词性联合标注实验使用的实验语料是PKU、MSR和CTB8(来自Chinese Treebank 8.0).PKU是由北大计算语言学研究所提供的语料库,该语料库是对人民日报1998年上半年的纯文本语料进行了词语切分和词性标注制作而成的.该语料库分词的一个特征是姓和名要分离,组织机构要直接在语法词典中标注出来,大多数短语词在组合之前应该被分割.MSR系微软亚洲研究院开发的语料数据库,它的分词特征是由比较多的命名实体组成的长词.宾夕法尼亚大学中文语法树数据库(CTB8)包含经过词性标记、分词、句法标记的语料,根据语句的内部结构形成语法树.
公式(9)、公式(12)中的分词标签转换分数矩阵A由语料集PKU、MSR和CTB8联合训练得到,其它模型参数分别在语料集PKU、CTB8上单独进行训练.分词性能采取召回率、准确率和综合指数F1来评估:其中准确率P表示推测正确的分词个数与推测分词个数的比值;召回率R表示推测正确的分词个数与测试集中正确的分词个数的比值;综合指标F1表示召回率和精确率的调和平均值:
(15)
实验结果表1列出了不同语料集的分词测试性能.
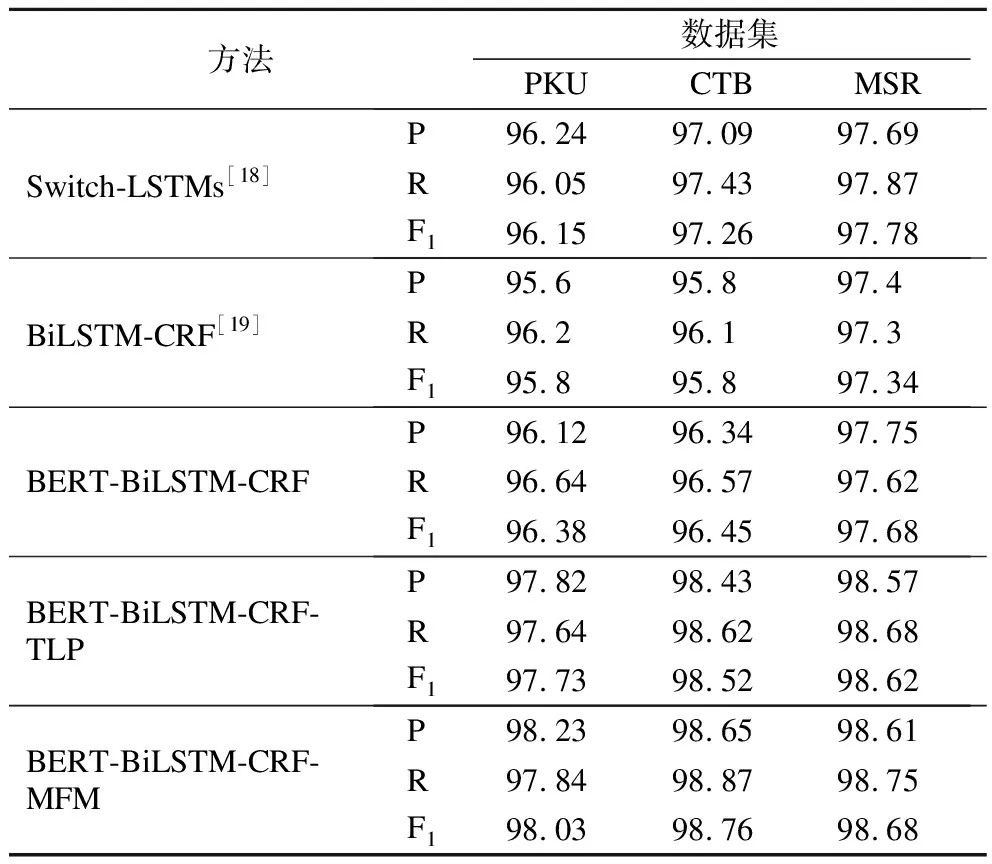
表1 不同方法在不同数据测试集上分词测试结果对比Table 1 Comparison of word segmentation test results of different methods on different test sets
本文应用马尔可夫族模型(MFM)、树形概率(TLP)进行词性标注,并结合BERT语言模型、双向长短时记忆神经网络模型(BiLSTM)和条件随机场模型(CRF)提出了中文分词和词性标注联合方法BERT-BiLSTM-CRF-MFM、BERT-BiLSTM-CRF-TLP.由表1分词标注结果中可以看出:本文提出的分词方法在基于字的BiLSTM-CRF中文分词模型基础上,利用词性标注信息实现分词,有机地将中文分词和词性标注结合起来明显提高了分词性能;在中文分词上,相比于BiLSTM-CRF分词模型、Switch-LSTMs分词模型,BERT-BiLSTM-CRF-MFM、BERT-BiLSTM-CRF-TLP方法分词效果有大幅度的提高,并且基于马尔可夫族模型(MFM)、BERT语言模型、长短时记忆神经网络模型和条件随机场模型的中文分词和词性标注联合方法BERT-BiLSTM-CRF-MFM取得了最佳的效果.
本文比较了几种中文分词和词性标注联合方法分别在语料集PKU和CTB8上的实验结果,具体如表2、表3所示.
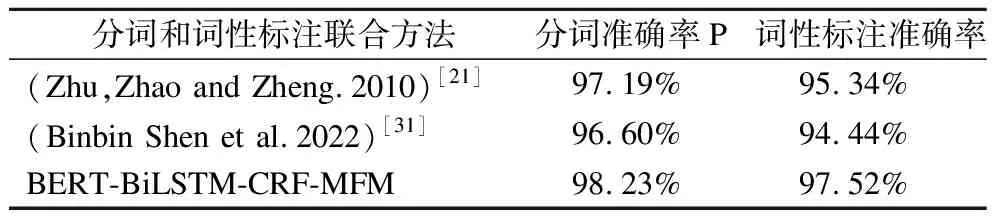
表3 不同方法在语料集PKU上的实验结果对比Table 3 Comparison of experimental results of different methods on the corpus PKU
实验结果表明,中文分词和词性标注联合方法BERT-BiLSTM-CRF-MFM能同时大幅度提高分词和词性标注效果.在基于马尔可夫族模型的词性标注中,目前词的词性不仅与前面一个词的词性关联,也与目前词自身关联.故而在一样的测试情况下,利用马尔可夫族模型的联合标记模型BERT-BiLSTM-CRF-MFM比常规的词性标注方法大大提高了词性标注准确率,这也验证了前面的假设.
4 结 论
针对中文分词、词性标注等序列标注任务,本文提出了结合BERT语言模型、BiLSTM、CRF和马尔可夫族模型(MFM)或树形概率(TLP)构建的中文分词和词性标记联合算法.利用隐马尔科夫模型的词性标记算法只利用到了词性到词的发射概率,弱化了词对词性的分布情况;而在利用树形概率或马尔可夫族模型的词性标记算法中,目前词的词性不仅和前一个词的词性关联,而且和目前词自身关联.通常词性标记和汉语分词是分别进行这两个任务,然而词性标记的准确性与分词的准确性紧密关联,分词错误也许会制约词性标记的准确性.将词性标记和分词统一在一个联合模型架构中,能够大幅减少错误的传播,并有益于利用词性信息进行分词,将两者紧密结合能够帮助消除歧义和提升词性标记、分词的准确性.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
校园英语·月末(2021年13期)2021-03-15
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
少儿美术(快乐历史地理)(2018年7期)2018-11-16
数学理论与应用(2016年3期)2016-05-17
核科学与工程(2015年3期)2015-09-26
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19
