
企业信用评级计算模型综述
2023-08-25 01:08:14田一擎程曦冯博靖
数据与计算发展前沿 2023年4期
田一擎,程曦,冯博靖*
1. 湖南大学,工商管理学院,湖南 长沙 410000
2. 中国科学院自动化研究所,北京 100190
引 言
企业信用评级是评估企业按照合同如期履行义务的意愿和能力,评级的目的在于评估企业作为债务人的违约风险大小。被评级企业主要分为非金融公司(如工商、建筑、交通、旅游等公司)和金融公司(如保险、证券公司等)。后者由于资金流转和组织架构的特殊性,其信用风险往往更大,评级工作更加困难。
目前,国际上最知名的信用评级机构有3 家,分别是标准普尔、穆迪和惠誉。标准普尔有160 余年历史,在行业内处于领先地位并扮演着领导者的角色,评级范围涵盖了全球126 个国家和地区。标准普尔在2019 年进入中国信用评级市场,按周发布对各国和各地区主权信用评级的更新。穆迪有120余年历史,由著名公司邓白氏拆分而来,评级范围涵盖了全球一百多个国家和地区,在2001 年进入中国市场。惠誉有100 余年历史,规模相较于标准普尔和穆迪稍小,评级范围涵盖了全球70 多个国家和地区,于2020 年获准进入中国市场。除了这3 家机构以外,中国的评级机构也在不断发展,如大公国际、中诚信、东方金诚等。不过中国的评级机构起步较晚,在完善程度、评级指标构建的科学性等方面还有很大进步空间。专家学者在构建信用评级模型时用到的数据库并不单一,表1 展示了常用的一些数据库。

表1 企业信用评级常用数据库Table 1 The main databases of corporate credit rating
虽然当下企业信用评级数据库不统一且缺乏统一的基准,然而大部分人工评级和算法评级方法都是基于常用的一些数据库构建企业信用评级指标,如WIND、Bloomberg 等。人工评级方法发展早且理论完善应用广泛。虽然当下主观评级方法综合了多方分析结果且经历多次迭代,但该方法主观性依然很强且受分析师个人偏好影响大,耗费大量人力物力,多次迭代耗时间长导致评级结果不能实时反映公司信用。而算法评级相对来讲实时性强成本低,评级结果客观可复现。但当下算法评级不能完全替代专家知识,对定性信息的理解也不充分,未来还有很大发展空间。
企业信用评级作为市场经济条件下的社会中介服务,在维护社会经济秩序中起了重要作用。企业应当建立在对客户信用状况充分了解的前提下发展客户。企业一味地追求大量订单难免会收到坏账。信用评级可以帮助金融从业者规避风险,为投资者和合伙人提供客观公正的资信信息,减小了企业的经营管理压力[1]。资本市场管理部门为了维持资本秩序的稳定需要对企业进行审查。企业信用评级提升了经济管理部门对企业的监管能力,弘扬了企业的社会知名度。
与企业信用评级相似的是债券信用评级。虽然二者都是为了促进资源的有效配置,减少评级对象和投资者之间的信息不对称,但其评级对象不一样,前者面向的是商业银行或相关监管机构,后者面向的是债券投资者。由于债券评级机构的评级耗时长,经历信息收集、处理、二次评级、跟踪评级等多个阶段,信用风险的变更往往反应不及时[2],建立一套自己的信用评级体系对金融机构来说非常重要。然而,评级机构做一次完整细致的评级需要耗费大量的人力物力财力和时间[3],这对于大部分企业以及金融从业者来说难以承担。所以构建精准的企业信用评级模型对于投资者来说很有价值。
当下已经有许多专家学者对企业信用评级模型做了细致的研究,但是关于这类模型的整体性综述却相对不足,对近年来基于神经网络的评级模型的综述更是寥寥无几。本文综合了传统的统计学模型、基于机器学习的模型以及近年来话题度很高的基于神经网络的评级模型对企业信用评级展开描述。
1 企业信用评级的统计学模型
在金融领域,大多数用于评估企业信用风险的传统模型都使用了基础的统计方法,由企业破产预测模型衍生而来。这类模型大部分基于企业财务指标(如资产负债结构、现金流量、盈利能力、资产流动性等)来构建评级指标体系,如表2 所示,之后用统计方法分析这些指标体系特征来完成企业信用评级分类。

表2 企业信用评级常用指标Table 2 The main metrics of corporate credit rating
常用的统计模型如下:
1.1 ZETA
ZETA 模型最初用来评估公司破产风险,之后在信用评级领域也有广泛的应用。评价指标体系基于资产收益率、收益稳定性、债务偿付能力、累计盈利能力、流动性、资本化程度和规模这7 个维度构建。文献[4]结合了判别分析算法,并引入先验概率进行了信用价值分析。然而ZETA 模型的7 个指标是固定不变的,不能涵盖所有评级要素。之后广泛使用的特征工程本质上就是在寻找适合描述评级问题的要素指标。
1.2 层次分析法
层次分析法(Analytic Hierarchy Process, AHP)是指将决策分解成多个层次从而进行定性和定量分析的方法,常被用于企业信用评级[5],目前被广泛用于确定参数的相对重要性。为了平衡AHP 方法的主观性,文献[6]结合了客观的数据包络分析模型(DEA)对信用水平进行评估。特别是对于难以完全定量分析的复杂系统,层次分析法的优势明显。然而层次分析法需要决策者对指标两两比较,判断其相对重要性,不仅引入了更多的主观要素,而且在指标数量多的时候很难人为判断。
1.3 多元判别分析
多元判别分析(Multiple Discriminant Analysis,MDA)是用一种根据数据集分析新的数据属于哪一类的统计方法,曾被广泛应用于信用评分模型[7]。按照判别准则不同,判别方法可以分为距离判别法、Fisher 判别法、Bayes 判别法、逐步判别法等。Reichert 等[8]指出,大部分MDA 模型都假定变量以多元正态分布。如果数据的真实分布显著偏离正态,分类结果会严重错误。Z-score 模型是基于MDA 创建的,最初被用来进行企业破产分析,后来也用于信用风险度量[9]。与前两种方法相比,可以发现MDA 方法更多地考虑了数据的科学性,更少地受到分析师主观的影响。然而MDA 的分类结果往往在数据集较小时更精确,难以招架如今日益增加的评级需求。此外,MDA 模型没有使用统计上独立于估计样本的数据来验证评级的准确性,导致验证结果出现偏差。MDA 模型假设所有类别的方差-协方差矩阵相等,这与现实不符。
1.4 多元自适应回归
多元自适应回归(Multivariate Adaptive Regression Splines, MARS)[10]也被用于信用评级。MARS是由逐步线性回归衍生而来。相比较于适合小数据集的MDA 模型,MARS 可以精确快捷地处理大规模企业信用评级问题。更可观的是,MARS 还能够捕捉变量之间的非线性和交互作用。不过相较于其他模型而言,MARS 在企业信用评级上用的并不多。
1.5 逻辑回归
逻辑回归模型(Logistic Regression, LR)是以线性回归理论为支持的非线性模型,常被用于处理二分类问题。Laitinen 等[11]使用逻辑回归和线性回归模型来分析公司信用风险。WEST 等[12]使用经典因子分析与多元逻辑回归相结合,构建了一个商业银行预警系统。LR 作为一个广泛使用的分类算法,在各领域都有应用,优点在于速度快,可以进行非线性分类,也常常与其他算法结合,用于信用评级问题。
1.6 其他统计模型
文献[13]同样将定性指标和定量指标相结合建立小企业信用评价指标体系,指标权重由增量聚类算法产生。实验证明了该聚类算法适合高维特征。Shi等[14]使用了Pearson 相关分析和F 检验显着性判别的方法,筛选关键特征,从而兼顾分类精度与计算时间。由于模糊优劣解距离(TOPSIS)方法的简单性和排序能力,该方法也被用作企业信用评级[15]。
关于统计学习方法,基于ZETA 模型由于指标固定,所以结果上鲁棒性高且可复现性强;然而AHP 方法由于引入分析师对指标重要性的排序,受人为因素影响大。MDA、MARS 和LR 等方法的优点在于理论体系较为完备,逻辑性强,得到的结论比较清晰,并且容易操作。但以统计学为基础的理论和方法都存在前提约束条件较多的缺点,在实际评级工作中,适用范围受到限制,具有局限性。
纵观整个基于统计的模型的历史可以发现,除了少数几个传统模型外,所有模型都擅长处理线性关系,而不是非线性关系。大型评级机构往往重视分析师在确定评级模型参数或直接信用评级时主观判断时的重要性。尽管这些传统方法基于对数据的统计和分析,但它们一直受到人为因素对企业信用评级的影响。此外,传统模型(如LR, KMV)在做评级任务时,往往对数据集的参数分布做了假设。这些假设可能与真实数据分布相悖,而机器学习模型对这些问题的解决提供了新的思路。
2 企业信用评级的机器学习模型
2.1 支持向量机
支持向量机(Support Vector Machine, SVM)是信用评级领域最常用的模型之一。Huang 等人[3]使用支持向量机对信用评级分析市场进行了比较研究,认为SVM 比LR 模型具有更高的准确性。研究证明使用小而准确的指标数据集对信贷结果进行评级,甚至比包含各种指标的金融数据集更准确。该研究还对美国和中国台湾省评级机构的相关数据指标进行了比较和分析。研究发现,前者更关注公司的规模,后者更关注公司的盈利能力。这与美国公司倡导高杠杆操作的方式不谋而合。与以往传统的统计学习模型不同,SVM 更强调评级方式的客观性,金融变量比机构分析师更能决定评级结果。特征工程的应用往往可以提升SVM 的准确度,这个特质拔高了SVM 的上限,但同时也限制了SVM 在信用评级领域的发展。
支持向量机最初是为二元分类而设计的,对企业来讲,信用评级并没有绝对的好与坏,简单的二分类并不适用于企业信用评级问题。模糊支持向量机[16]为正负类别的各个样本分配了各自的隶属度,从而使得SVM 具有更强的泛化能力。之后随着多类支持向量机的发展,“一对全”“一对一”和有向无环图SVM(DAGSVM)被用在多分类上。文献[17]使用以上3 种多分类SVM 的方法进行企业债券评级,得到了DAGSVM 性能最好的结论。为了实现非线性可分样本的分类,径向基函数(RBF)核函数被用来对样本升维。该工作[18]使用了带有RBF 核函数的SVM 进行企业信用评级分类。RBF 核函数的最优参数值通过网格搜索技术来寻找。实验表示[16],带有合适的核和隶属度生成方法的SVM 比标准支持向量机和模糊支持向量机在信用评级问题上的准确度更高。
然而企业信用评级不是一个简单的分类问题,评级结果是有高低之分的。文献[2]考虑到信用评级的独特顺序,提出了基于有序成对划分策略的支持向量机。为了解决模型参数优化问题,遗传算法也被引入SVM。GA-SVM[19]使用网格搜索设置模型参数并用遗传算法对参数进行优化。然而,SVM 始终是一个黑盒问题,理解SVM 的原理会提高模型的实用性。为了提高SVM 的可解释性,CRCR-SVM[20]结合了传统的规则学习方法,通过一致区域覆盖减少的规则进行SVM 学习。
此外,SVM 常被用来进行特征选择工作。由于指标之间互相依赖,所以特征选择的过程非常曲折。公司信用评级取决于多变量因素。Fisher 是常用的特征选择方法。该方法易于实现,执行快速,但没有考虑到变量和分类器之间的相互作用。另外的双样本独立性指标,如KS 检验(Kolmogorov-Smirnov test)和卡方检验,通常会获得与Fisher 得分相似的结果。为了避免特征排序方法所需的额外校准步骤,Maldonado 等[21]使用两种SVM 方法(l1-MISVM,LP-MISVM)来获取银行信用贷款数据的最佳特征子集。在构建分类器时,该方法会考虑所有变量交互作用。文献[17]提出特征选择可以进一步提升SVM 的泛化性能。相比较于遗传规划和决策树分类器,SVM 的输入精度对大量的输入特征的依赖性更低[19]。
2.2 决策树
决策树(DT)是一种可快速构建、可解释性强的算法。ID3 和梯度提升迭代决策树算法都用于企业信用评级,后者更有效[22]。结合了集成学习与决策规则方法,相关调整决策森林[23]平衡了模型的准确性与可解释性。该方法使用决策树作为基分类器,选择了18 个对于信用风险评级来说最重要的特征。穆迪的KMV 模型(Credit Monitor Model)基于金融理论和违约概率,是著名的信用评级分析模型。混合KMV 模型[24]将KMV 与RF 和粗糙集理论(RST)结合,以提高信用评级的准确率。RST 不对数据的分布做任何假设,适用于定量和定性分析。在决策过程涉及不确定的模糊数据时,RST 在解决决策支持问题方面成果显著。首先,混合KMV 模型使用KMV 来进行变量预测;其次,RF 选择变量作为RST 模型的输入;最后,模型以if-then 规则的形式生成结果,过程透明且易于决策者理解。但是该方法必须对一些参数进行优化,从而构成基分类器。然而可以发现,由于金融数据的高维性、稀疏性和强相关性,DT 模型的性能受到限制,在之后的研究中往往被作为信用评级模型的基线,或者与其他算法结合。
2.3 集成学习
集成学习不独立于其他机器学习算法,它是一种通过结合多个基学习器共同完成学习任务的机器学习方法。由于集成学习在分类任务上具有突出表现,所以该算法在企业信用评级方面也有了长足的发展。集成学习的基本思想是当我们做出重要决定时,需要参考从不同角度提出的多方面的意见。对多角度意见进行加权最终做出的决策往往比只参考单方面意见做出的决策更加合适。所以,基学习器在具有一定的准确性的基础上,彼此间应当具有多样性。当基学习器给出的意见达到互补时,集成学习算法通常可以取得更好的效果。Abellan 和Castellano 提出的信用决策树改变了处理不精确性的方式,使用不精确概率和不确定性度量来构建模型,使基分类器变得相对不稳定。不稳定意味着很小的训练数据的变化会使模型产生较大的差异,导致基分类器具有多样性,非常适合在集成学习中使用[25]。
近年来,神经网络方法结合集成学习,被很多专家应用在企业信用评级任务上。Donate 等[26]提出在企业信用评级任务上,集成了多个神经网络的模型优于只使用单个神经网络,对多个基学习器进行适应度加权的集成策略比非加权策略更具有准确性,证明了应用集成算法的神经网络方法的巨大潜力。为了保证基学习器之间的差异性,Yu 等[27]提出的模型在选择自适应神经网络(ANN)时采用了去最大相关性算法,再将单个基学习器的决策值从正负无穷缩放到0 和1 之间,之后分别使用最大、最小、中值、平均和产品策略将基分类结果集成。其中,产品策略的性能最好,其次是均值策略,导致该结果的原因尚待讨论。
集成学习常用的算法有多数投票、加权平均、Baggin、Boosting、Random Subspace、Decorate、Rotation Forest 等。多数投票算法最为常用,但是忽略了某些少数的神经网络有时确实会产生正确结果的事实,默认每个神经网络的置信度都相同。在公司信用评级任务中,可用的样本数据往往是有限的,而bagging 算法通过从原始训练集随机置换抽样子集的方法,对整体数据集在统计意义上生成更多的估计,一定程度上弥补了训练数据有限的缺陷,通常可以改进分类效果[27]。此外,企业信用评级数据类别严重不均衡,如图1 所示,等级很高或者很低的都相对较少。Brown 和Mues 提出随机森林(RF)和梯度提升算法在缓解该问题时性能较好。然而He等[28]提出在解决企业信用评级数据不均衡问题时,RF 和梯度提升算法的模型的参数有待进一步优化。他们扩展了级联平衡方法,基于训练数据的不平衡率生成可调的平衡子集,构建了以RF 和XGBoost作为基分类器的三阶段集成模型。使用叠加生成前一层的预测结果,作为后一层的新解释特征,基分类器的参数通过粒子群优化进行优化。特征工程也被用于神经网络集成学习方法[29]。考虑到历史财务数据和信用评级对当前信用评级的影响,Wang等[30]构建了一个经典的基于集成学习的并行神经网络(PANNs),扩展了特征空间,其中视差和绝对值波动率特征可以更好地预测企业信用评级。
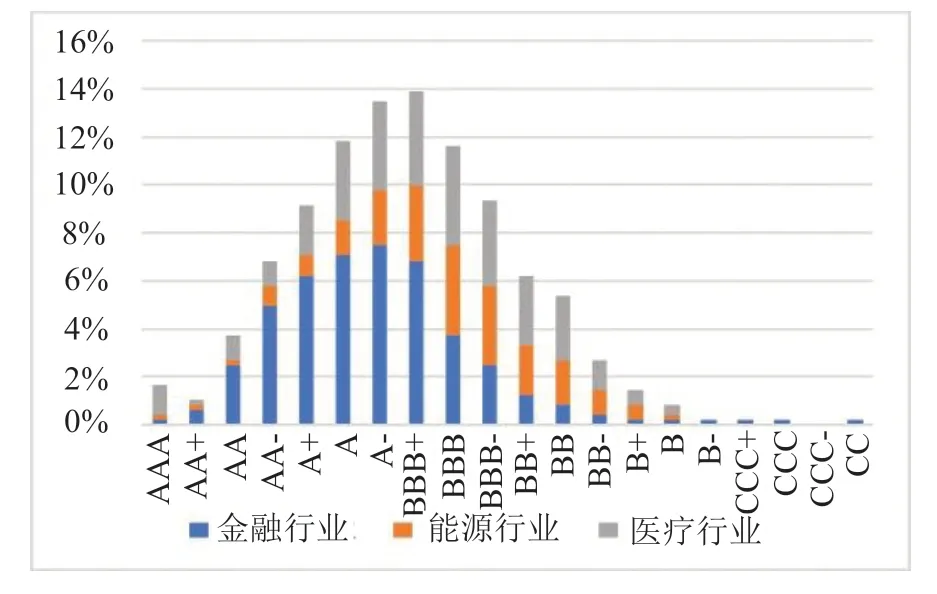
图1 典型行业的企业信用评级分布图Fig.1 Distribution of corporate credit rating
然而,如何决定集成学习方法中基分类器的个数和组合,使它更适合企业信用评级问题,依然有待研究。集成学习集合了许多基分类器,其训练时间也是指数级增长,基分类器的数量与训练时间的分配问题值得研究者们在未来权衡。虽然一定程度上结合了多个基分类器的模型可以从多方面考虑问题,但是集成策略也很难同时适合多种基分类器,如何提高包含多种基分类器模型的性能是未来集成学习方法的研究方向。Wang 等[30]的实验结果表明,有时候基于神经网络的集成模型效果不随着数据量的增加而显著增强,一种可能的解释是更多财务数据会引入更多的噪声。在今后的研究中,可以通过降低噪声得到更有用的数据集来提高预测精度。
2.4 其他机器学习模型
文献[31]基于知识生成决策规则,使用粗糙集实现两个混合模型,对全球银行业的信用评级进行分类。Chai 等[32]针对小企业进行信用评级,发现对小企业来讲,非金融因素的影响大于财务因素。在构建信用指标体系时,先使用三角模糊数将定性指标转化为数值,再采用偏相关分析(PCA)和概率回归算法消除冗余指标。该工作利用TOPSIS 算法计算信用评分,再使用模糊C-means 对小企业信用评分进行聚类。
在常用的信用评级机器学习模型中,决策树方法是一种非参数统计学习方法,其特点在于提升生成的分类树的鲁棒性和泛化能力。最近邻方法基于度量测度,特点在于将待评级企业归类于与其指标最相近的训练集中指标对应的信用等级。不需要评级指标数据的先验概率分布信息或假设信息是最近邻方法的显著优势。此外,基于特征选择、数据降维的主成分分析方法等在解决评级指标数据量的快速增加方面有很大优势。而集成学习得到的混合模型总体来讲比单一模型评级精度更好,其中一个可能的原因在于集成方法针对不同数据集采用不同的模型建模,一定程度上解决了评级中的不平衡问题。
纵观基于机器学习的模型可以发现,虽然这类模型相较于之前的统计模型来讲,更强调客观性,却也在一定程度上只利用了量化数据而丢弃了定性数据带来的信息增益。而企业信用评级问题中,定性数据如文本等包含了大量风险信息。此外,这类模型过于依赖特征工程,好的特征会给模型效果带来显著提升。神经网络模型对这些问题提供了新的思路。
3 企业信用评级的神经网络模型
3.1 早期的神经网络
关于企业信用评级问题,在神经网络被广泛应用之前,特征工程一直是金融工程的研究重点。在以前的机器学习算法中,使用特征工程获得新特征往往比仅使用原始特征得到的评级结果更准确。Chen 等[33]使用单方差分析的统计方法来选择特征。尽管统计方法会提高训练集的分类精度,但也会带来噪声并导致过度拟合。然而,神经网络在训练过程中赋予特征不同的权重,相当于选择了重要特征作为重点关注对象。Golbayani 等[34]发现,当使用所有财务变量作为输入,并在神经网络的训练过程中执行特征工程时,评级结果更准确。与统计方法和机器学习方法相比,神经网络不假设数据分布。
早期的神经网络(如多层感知器(MLP))需要手动调整学习速率,避免陷入局部极小值。与传统的机器学习方法相比,MLP 能够有效地处理高维数据和非线性关系。Brennan 等[35]利用财务报表中的信息建立了一个反向传播神经网络,对债券发行公司进行评级。他们发现,使用反向传播神经网络得到的结果比传统的统计方法准确得多。Huang等[3]用反向传播神经网络模型解释企业信用评级,并试图从该模型中分析不同的输入金融变量的相对重要性。Angelini 等[36]认为数据分析和处理以及参数优化是解决公司信用评级的重点难点。他们使用了经典的前馈神经网络和具有自组织连接的前馈神经网络来评估信用风险。后者由四层的前馈网络组成。输入神经元由3 个神经元组成,每组连接到下一层的一个神经元。然而,MLP 模型收敛速度慢而且训练过程不稳定。传统的神经网模型更适合于二值分类,但在多类分类中精度较低。此外,传统的反向传播神经网络算法在网络中训练大量参数,容易产生过拟合,训练时间长。文献[2,3,18-19]认为,传统神经网络在信用评级方面不如SVM。Choi 等[37]认为,这可能是因为SVM 在避免过度拟合问题方面更稳健,而且与神经网络相比SVM 参数更少。Du等[38]提出遗传算法可以对神经网络的参数进行修改和优化,提高企业信用评级的准确性。遗传算法信用评级模型一定程度上缓解了BPNN 训练时间长、收敛速度慢、陷入局部极小值可能性的问题。
关于企业信用评级问题,在经典的前向反馈网络模型的基础上,许多其他的神经网络模型也相继被提出。深层神经网络结构(DNN)由多个浅层神经网络组成。随着网络层数的增加,DNN 的梯度在训练中消失,优化函数越来越容易陷入局部最优解,训练效率大大降低。直到2006 年,Hinton 提出了分层训练受限玻尔兹曼机的方法,改善了上述问题。这种结构被称为深度信念网络(DBN)。Luo 等[39]首次使用DBN 对企业信用评分进行了研究,分类性能优于MLR、MLP 和SVM。此外,Kim 等[40]使用自适应学习网络(ALN)预测债券评级。文献[41]使用概率神经网络(PNN)对美国公司和市政当局进行评级。数据预处理阶段采用了基于相关性的方法和遗传算法。他们发现,概率神经网络比其他基准分类器,如传统神经网络(如前馈神经网络、RBF、数据处理多项式神经网络)、级联相关神经网络和统计方法(LR、MDA)有更准确的结果。PNN是径向基函数网络的一个分支,属于前馈网络。它将密度函数估计和贝叶斯决策理论相结合,使判断界面接近贝叶斯最佳判断界面。它具有学习过程简单、训练速度快的优点。
3.2 卷积神经网络
卷积神经网络(CNN)的出现是为了解决DNN的参数爆炸问题。事实证明,在各种金融问题上,尤其是在股票市场分析领域,CNN 明显优于传统的机器学习技术[42-44]。CNN 主要由卷积层、池层和全连通层组成,并采用反向传播算法进行训练。据本文所知,Golbayani 等[34]是第一个使用CNN 进行企业信用评级的。他们使用了包含dropout 和early stopping 算法的CNN 模型和二维卷积CNN2D 模型,这两个模型都由两个卷积层和两个完全连接的层组成。它们之间的区别在于,在CNN 模型中,卷积核只朝一个方向移动,而在CNN2D 模型中,卷积核朝两个方向移动。该研究还提出了一个双向方差分析模型,用于比较网络体系结构的多种性能。一个重要的事实是并非所有公司都能提供每年的信用评级分数或财务信息。与MLP 相比,CNN 由于可以有效地调整特征权重,在处理缺失数据方面取得了良好的效果。
各种基于CNN 的衍生模型广泛应用于计算机视觉和自然语言处理领域,但它们不适用于金融场景。以往的研究只能提取企业数据的一维特征,受计算机视觉领域对二维特征处理方式的启发,Feng 等[45]构建的CCR-CNN 模型为每个企业生成了一张包含每个二维财务信息的图像,该图像被输入CNN 结构并获得分类结果。该模型的优点在于捕捉了企业指标之间独特的二维关系特性和构图,这在以往的模型中是被忽视的。
然而,企业信用评级是动态的并与时间因素密切相关。对于建立基于连续时间的企业信用评级模型,循环神经网络(RNN)是一种合适的算法。
3.3 循环神经网络
尽管RNN 在时间序列问题的研究中取得了显著的成果,但反向传播算法引起的梯度消失和梯度爆炸给RNN 的训练带来了很大的困难。长短时记忆网络(LSTM)是RNN 的一种变体,它通过选通机制将短时记忆和长时记忆结合起来,在一定程度上解决了梯度爆炸和消失的问题。LSTM 具有较高的计算复杂度,RNN 的选通递归单元(GRU)可以节省计算成本,同时确保相当高的精度。注意机制可以进一步节省计算成本。其原理是通过分配权重,从大量信息中选择对当前任务更关键的信息。注意力分布是通过计算向量的相似性或相关性来实现的。目前,大多数基于注意力的模型都属于编码器-解码器框架内。例如transformer 的并行计算可以显著减少训练时间。此外,Bert、deep transformer 和transformerXL 等也属于该框架。
Golbayani 等[34]将CNN 与LSTM 进行了比较,并通过实验分析证明后者在处理企业信用评级问题上更为有效。他们用32 个LSTM 单元和两个全连接层构建模型。SMAGRU[33]是第一个将长期关注机制应用在企业信用评级的模型。SMAGRU 由6 个相同的模块堆叠而成,每个模块由多头自我注意机制和全连接的前馈网络组成。多头注意力类似于CNN 中的多个过滤器,有助于捕捉更全面的信息。该体系结构基于GRU,具有多头自注意机制,能够捕捉时间序列的特征。多头自注意机制通过增强时间特征提高了分类精度和收敛速度。此外,多头自注意机制和门控递归神经网络也能很好地适应高维稀疏数据,这对解决企业信用评级问题来说十分合适。
3.4 基于定性信息的神经网络
大多数评级方法使用定量数据(如财务信息和资本流动性),但定性数据(如公司的战略布局、舆论和管理效率)也对信用评级有重要影响。信用评级是为了指导投资者投资未来,但使用的财务数据是基于公司的历史运营情况。财务数据也不能完全反映企业的经济环境,标准普尔还使用报告和管理层访谈来补充评级模型。基于定性信息的神经网络使用文本数据挖掘方法,使得模型分类结果不完全依赖于定量数据分布,是对信用评级模型方法的重要补充。
将文本转换为嵌入向量的常用方法有词包模型(BOW)、Word2Vec 和Doc2Vec。BOW 最早被提出,它将文档视为一组单词,忽略了词序、语法和语法等元素。BOW 假设文档中的每个单词都独立出现。向量的每个维度都与语料库中的单词一一对应,维度值表明了单词的重要性。词频-逆文档频度(TF-IDF)是计算单词相对重要性最常用的方法。Word2Vec 假设在上下文中经常同时出现的单词具有相似的含义,并将单词嵌入到一个连续的向量空间中。训练神经网络的目的是根据输入的单词准确地预测目标单词。Word2Vec 有两种最常见的架构:CBOW 模型和Skip-Gram 模型。CBOW 模型使用相邻单词的一个热编码作为输入并预测单词。相反Skip-Gram 模型使用单词的一个热编码并预测其相邻单词[46]。Doc2Vec[47]为Word2Vec 添加了一个段落向量,可用于嵌入可变长度文本,如句子、段落和文档。
Choi 等[37]使用上述3 种文本嵌入方法获得向量,并将向量分别输入到ANN、SVM 和RF 模型中。实验结果表明,使用定量财务数据和定性文本数据训练的模型比仅使用定量财务数据和定性文本数据训练的模型具有更高的精度。模型精度从低到高依次为Word2Vec、Doc2Vec 和BOW。BOW 获得最高精度的原因可能是训练数据集很小。用于训练的管理层讨论与分析文本数据的长度很长,Doc2Vec 比Word2Vec 更擅长处理更长的文档。今后使用更大的数据集进行训练是提高Doc2Vec 精度的一种方法。Feng 等[48]对定性数据进行了一次热编码,然后使用嵌入层将定量金融数据与定性数据连接,输入网络进行训练。
3.5 图神经网络
当一个行业的市场不景气时,相关企业的评级结果往往也会变得很糟。企业之间的关系也是企业信用评级尚未探索的影响因素之一。然而,现有的大多数使用图神经网络的模型都是基于全球视角对企业进行研究。它们直接在企业之间建立网络,而不考虑单个企业内部特征的相互作用(例如债务和资本结构之间的关系)。
CCR-GNN[48]是第一个应用图神经网络(GNN)研究企业信用评级的模型。CCR-GNN 并不是简单地将企业视为一个节点,而是考虑到单个企业内部特征的交互作用,为每个企业构建一个图。CCR-GNN包括三层子神经网络:首先,根据特征之间的关系将每个企业映射为一个图结构;然后,这些特征通过图形注意层的交互来捕获局部和全局企业信用信息;最后,信用评级层根据这些企业信用信息输出类别。通过叠加多个图形注意层,CCR-GNN 可以清晰地探索高阶特征交互,特征节点的企业信用信息通过注意机制传输到相邻节点。
3.6 基于对抗和半监督的神经网络
中小企业的财务信息不足,而且没有足够的资金支持评级。因此,以往对企业信用评级的研究往往只考虑大型企业。然而,中小企业的财务数据也具有研究价值。半监督学习算法为解决这一问题提供了可能性。基于相似样本具有相似输出的假设,半监督学习同时使用标记数据和未标记数据来训练模型。对抗学习是指基于对攻击能力和攻击结果的理解,训练能够抵抗攻击的网络机器学习算法。实现对抗学习的方法是使两个网络相互竞争,其中生成器网络向样本中添加噪声来构造伪数据,判别器网络判断数据的真实性。通过反复对抗,生成器和判别器的能力将不断增强。
然而,Feng 等[49]发现,仅使用半监督学习会导致监督任务和半监督任务之间的表征错位问题。ASSL4CCR 中引入了编码器模块和对抗学习来缓解这种现象。ASSL4CCR 包括两个阶段,第一阶段是通过半监督学习获得伪标签;在第二阶段,编码器模块的映射将标记数据与伪标记数据结合起来,判别器模块用于区分数据来自真标签还是伪标签。
3.7 基于预训练和自监督的神经网络
除了集成学习外,自监督学习也可以在一定程度上缓解企业信用数据集的类别不平衡问题。在基于神经网络的方法中,半监督学习和自监督学习对标签的依赖性相对减弱,所以类别分布差异对该方法影响相对较小。自监督学习主要通过辅助任务从无监督数据中挖掘监督信息,下游任务的有价值表示是通过构建的监督信息来学习的。CP4CCR[50]将特征掩蔽和特征交换作为两个自监督的任务,对网络进行预训练。该工作提出,相对于其他常用的编码模块,企业信用评级模型更好的编码模块是transformer。
3.8 基于可解释性学习的神经网络
在金融领域,提高模型的可解释性至关重要,高解释性模型便于分析师判断哪些特征对评级更有显著性。相较于深度学习算法的黑匣子特性,基于可解释性学习的神经网络更适合解决这个问题。机器学习方法的可解释性可分为内在解释和事后解释。内在解释意味着模型本身是可解释的。事后解释意味着训练黑盒模型(如集成方法或神经网络),并在训练后应用可解释性方法[51]。文献[52]提出了一种基于企业信用评级的事后解释的稀疏算法。该工作通过稀疏算法对此问题做出了反事实解释。此外,该研究还发现,信用评级越高,企业提高信用评级的难度就越大。通过对模型进行解释,可以探索如何以最少的成本来达到提高信用评级分数的目的。这样的思想开辟了企业信用评级模型的新思路。
总的来讲,基于神经网络的模型对于特征工程的要求相对较低,考虑到评级信息时序变化的特点以及企业间关系,综合了机器学习模型难以捕捉的定性信息,缓解了数据分布不均的问题。这类模型逐年取代以往的统计模型和机器学习模型,成为信用评级的主流。然而神经网络更依赖于大量数据集,可解释性也不高,未来还有相当大的发展空间。
4 结论与展望
企业信用评级模型作为中国评级企业的卡脖子技术,近年来受到越来越多的关注。通过对以往文献的总结,本文系统地分析了企业信用评级的起源与发展。从传统的统计学习模型、基于机器学习的评级模型和基于神经网络的评级模型3 个层面深入地介绍了信用评级的方法。
当下信用评级模型已经非常丰富,企业信用评级领域取得了快速发展。时间与金钱成本被降低,新方法的提出打破了评级机构的垄断门槛,小微企业也可以获得相应的评级。此外,随着神经网络方法的引进,评级准确率获得了显著提升,模型中带有分析师个人色彩的主观性也被降低。
然而,目前在信用评级领域依然有很多待解决的问题。拥有全面的金融信息的依然是大型企业,小微企业由于缺少相应数据而评级困难。此外,拥有评级标签的企业大部分都是信用良好的企业,等级低的企业少之又少,数据集类别严重不均衡,给评级过程带来了很大的困难。现有模型所使用的数据集都是由研究者自己构建,缺乏开源统一而广泛使用的数据集。统一的数据集有助于比较不同模型的性能。在深度学习广泛应用之前,传统评级广泛采用定性与定量结合的办法。然而近年来发展迅速的深度学习方法大部分只使用了定量数据进行分析。
此外,信用评级问题多被深度学习模型视为分类问题,忽视了评级对排序的敏感性。基于神经网络企业信用评级模型的可解释性依然有待商榷,是金融从业者的心头之患。图1 展示了不同行业的企业评级的分布情况。由于不同行业之间差异比较大,企业信用评级模型需要考虑到不同行业间的经营特色,未来仍有改进空间。评级结果只能部分体现企业经营状况,如何帮助企业提高经营能力,提高信用评级等级,是未来该领域一个新的研究视角。
在企业信用评级的建模方面,图神经网络依旧是一个热点的方向,其集成了神经网络强大的表达能力和图结构数据的可解释能力,如何充分利用图神经网络建模是一个重要的研究方向,不论是从特征建图还是从企业建图都是很好的方法,异质图网络的引入可以将企业多种关系联合建模。此外,由于企业信用特征与信息是实时变化的,现有的图网络建模方法多是基于静态图,基于动态图网络进行评级的工作有相当大的空缺。动态图网络的建模方法也可以将时序信息引入,使评级涵盖因素更广泛。企业信用评级的研究前景广阔,还有很大的空间去探索。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
江苏安全生产(2022年6期)2023-01-15 03:02:21
江苏安全生产(2022年6期)2022-07-29 01:22:52
公民与法治(2020年20期)2020-11-27 01:44:42
中国外汇(2019年9期)2019-07-13 05:46:30
中国军转民(2017年6期)2018-01-31 02:22:13
中国军转民(2017年8期)2017-12-13 08:37:01
中国设备工程(2017年7期)2017-04-10 08:09:12
股市动态分析(2016年22期)2016-12-27 17:06:46
瞭望东方周刊(2016年45期)2016-12-07 16:03:39
IT时代周刊(2015年8期)2015-11-11 05:50:22
