
有监督学习算法在材料科学中的应用
2023-08-25 01:08:14刘端阳魏钟鸣
数据与计算发展前沿 2023年4期
刘端阳, 魏钟鸣,2*
1. 中国科学院半导体研究所,超晶格国家重点实验室, 北京 100083
2. 中国科学院大学,材料科学与光电技术学院, 北京 100049
引 言
近年来, 随着实验科学的进步和材料计算科学的巨大发展, 研究者们对数以百万计的材料进行了实验合成,性能表征以及理论计算。在此基础上,已经建立了多种高质量的材料数据库, 例如Materials Project[1]、C2DB[2]、AFlow[3-4]、GDB-13[5]、和QM9[6]等。巨大的材料数据库为实现更多样化的材料功能提供了可能性, 但另一方面也提高了优化和筛选材料的难度。
与此同时,机器学习方法在计算机科学以外的许多领域中得到了应用,其核心是让机器自动从复杂的数据中学习到隐藏在其中的规律。因此,鉴于材料数据库越来越庞大,对材料的性能要求也越来越复杂,在材料科学的领域中,有相当多的学者在研究中引入了机器学习的方法[7-15]。从机器学习的分类来说,可以大致分为有监督学习、无监督学习和强化学习,前两者的主要区别是训练数据中是否有明确的目标标签。在目前的材料科学领域中,仍然是以有监督学习为主。本文主要介绍有监督学习在材料科学研究中的应用现状。
本文的结构如下:首先介绍机器学习的基本理论及其在材料科学研究中使用机器学习技术常用的流程;接下来对几种有监督学习技术及其在材料研究领域中的应用情况做了介绍;之后对有监督学习在这一领域的几个重点研究方向进行了叙述;最后对机器学习在材料科学中的应用进行简要总结,并展望本领域的一些研究前景。
1 有监督学习理论及其算法流程
机器学习的理论首先假定所有的数据都是在相同的隐藏统计规律下产生,同样的统计规律下产生了不同的数据样本点。特征是用于描述每个样本点的若干属性,不同的样本点其特征不同,为了使机器学习的效果更好,应提取到最能反映问题核心的样本特征;而模型则是通过样本特征映射到机器学习研究问题中关心的目标属性的一个映射或者说是程序中的函数,这些目标属性包括在分类问题中的所属类别,回归问题中的标签值等,应根据关心的问题类型选择适合的机器学习模型;而算法的选择要合理且有效,通过对训练数据的拟合,对模型参数进行优化,从而获得优化后可实用的模型。通常在有监督学习中,通过最小化损失函数来实现优化目标。
目前,大量的材料数据库为机器学习提供了丰富的训练数据,很多数据库都提供了材料的多种属性,如原子信息、晶格类型、空间群、晶格常数、能带带隙甚至其他各种材料物理化学属性。若以每种材料为一个样本点,这些属性都可以作为机器学习的样本特征或者标签。值得注意的是,很多时候需要挖掘出反映所关心问题的更深层的特征,往往需要搜寻相关其他的数据甚至对找到的一些原始特征进行转换。用于描述材料样本的原始特征可以分为以下三类:(1)原子信息,在这类特征类型中,不仅可以使用原子数目作为特征,还可以使用原子的其他属性,如电负性、香农半径等;(2)材料属性,例如晶格常数、空间群、吸收光谱等,这类特征类似于原子信息,既适用于分类又适用于回归;(3)原子配置,对于这种类型,原始特征是所有原子的类型和位置,往往不能直接用于机器学习模型,需要对其进行一定程度的转换。
机器学习的模型和算法往往是一体的,不同的模型对应着不同的优化算法,因此很多时候其含义与语境有关,例如当提到机器学习的几大算法时,是指某种模型和算法的整体。针对问题的不同,适用不同种类的模型和算法。常见的有两类问题:分类问题和回归问题,这也是材料科学中常见的两类问题。所谓分类问题,是指将样本归类到不同的种类中,更细致的还可以分成二分类和多分类问题,其学习目标是一个分类,为了使模型是连续函数,能够使用梯度算法,在实际模型和算法中往往使用One-Hot 型的学习目标,并使用交叉熵作为损失函数。而所谓回归问题,则学习的目标是一个标量,学习任务是使得模型得到的目标尽量准确,在训练数据集上则是要得到更为接近标签值。总体而言,需要根据问题的形式,选择一个合适的算法模型,其输入是样本点的特征,输出是分类或者回归的目标,然后按照问题的形式,选择一个合适、能够反映模型预测在训练数据集上优劣的基于目标的损失函数,按照特定算法和特定步骤优化模型参数减小损失函数,获得优化的模型。
根据以上有监督学习的理论,在材料科学中的机器学习的流程如图1 所示,按照流程顺序:(1)收集数据:要选择足够的合适的训练数据集,可以从现有的材料数据库中选择,也可以通过理论计算或实验自行产生;(2)特征工程与特征转换:根据需要对数据集中材料样本点的原始特征进行筛选或转换;(3)建立模型,该模型的输入是筛选或转换后的材料特征,输出是问题关心的目标数据的形式;(4)模型训练,即使用模型对训练数据集中的规律进行学习,优化模型参数;(5)使用模型,将优化好的模型用于目标任务。在实际过程中,流程并非完全按照上述顺序操作,例如特征工程的特征筛选工作往往是要借助于模型训练的结果;再如对模型的超参数进行优化时,也是需要根据不同超参数的模型训练结果的优劣对模型进行筛选。

图1 有监督学习流程的简略图示Fig.1 Simplified diagram of supervised learning process
2 几种有监督学习算法
自从机器学习于1957 年被提出以来,已研究出大量的机器学习算法。其中许多算法已经被应用于材料领域的机器学习中。选择合适的机器学习算法是机器学习研究中的一个重要问题。对于有监督学习,分类和回归问题有不同适用的算法。如果特征与目标属性之间的关系不是近似线性,简单的线性算法无法给出很好的结果。本文将介绍材料研究领域中一些流行的机器学习算法。
2.1 支持向量机
监督学习的任务大致可以分为两种类型:分类和回归。分类的算法大致分为两种类型:线性和非线性。支持向量机(Support Vector Machine,SVM)具有线性和非线性的算法[16]。SVM 不仅仅是一个经典的算法,其概念还启发了许多其他算法的发展,特别是在许多流行算法中使用的对偶算法和核函数的概念[17]。对于分类问题,SVM 是一个强大的工具,已被广泛应用于材料科学研究中。例如,SVM 被用于预测一种材料是半导体还是金属[18-20],一种半导体的能隙是直接的还是间接的[21],或者其他性质[22-23]。
2.2 核岭回归
核岭回归(Kernel Ridge Regression,KRR)是代表性的核方法[24]。如2.1 节所述,核方法的概念源自非线性SVM。在核方法中,核心是核函数,它隐式地将初始特征转换为一个新的高维特征空间。这将带来两个好处:更强地表达能力以及可以用在新特征空间中的线性拟合的方式实现在原始特征空间中的非线性拟合效果。为了避免复杂的计算,新特征并没有被显式计算出来,而是通过核函数计算它们的内积。基于这些新特征,可以应用线性分类或线性回归。显然,该方法的性能依赖于核函数,因此选择合适的核函数对于核方法非常重要。如果在最后的线性回归中添加岭项以避免不稳定的结果,那么就是KRR。通过合适的核函数,KRR 表现出优秀的回归性能,包括较小的误差和较高的稳定性。因此,KRR 被广泛应用于关于材料的机器学习研究中[25-28]。由于KRR方法需要一个N×N的格拉姆矩阵,其中N是样本点的数量,它更适用于系统较小或样本较少的问题,如有机材料[12,29-31]。
2.3 决策树
虽然决策树(Decision Tree, DT)算法CART[32]可以处理回归问题,但人们更倾向于使用决策树来解决分类问题。通过训练好的决策树,可以对新的示例进行正确分类。一个分类决策树的生成包括两个步骤的循环:根据某个规则选择一个特征,以及根据所选特征的取值集构建一些子节点。在流行的决策树算法中,ID3[33]和C4.5[34]使用信息增益或信息增益比作为选择特征的判断依据,因此它们更适用于离散特征。CART 算法使用基尼指数作为特征选择的判断依据,因此更自然地适用于具有连续特征的问题。为了避免过拟合,有必要对生成的决策树进行剪枝。在剪枝过程中,将某些子树缩减为其根节点,这可以被视为结构风险最小化。在生成决策树时,通过随机地从原始训练数据中选择一些数据,并在决策树每个特征选择的步骤中加上一定的随机因素,从而可以生成许多不同的随机决策树。如果需要对新示例进行分类,可以从每个决策树得到一个分类结果,最后可以使用多数投票来决定新示例的分类。这是随机决策森林(Random Decision Forest,RF)的著名算法[35]。RF 可以被看作是决策树的扩展。决策树和随机森林算法都被广泛应用于解决材料研究的许多问题,例如预测能隙[7,26,36-37],其他材料属性[22,23,38,39]。
2.4 人工神经网络
人工神经网络(Artificial Neural Networks,ANN)具有较强的表达能力,若其具有足够的节点或参数,就可以以任意精度逼近几乎任何函数。而且ANN 可以自动提取样本或输入数据的隐藏深层特征。由于这两个优势,ANN 被广泛应用于许多研究领域。在材料科学领域,研究人员将它们应用于形成能的预测[8,29,40],能隙的预测[26,31,39],其他材料属性的预测[23,41-42]等。
2.5 其他算法
除了SVM、KRR、DT、RF、ANN 之外, 还有许多其他算法被应用于半导体材料和半导体制造的研究中。受学术水平和文章篇幅的限制,无法在本节中介绍该领域的其他新算法。线性拟合方法是一组基础且有用的方法。虽然其可能不适用于某些具有非线性因素的问题,但具有计算复杂性低的优点。线性拟合方法已经用于预测能隙[19,26,38],磁性属性[11]等方面。提升算法可以改善某种学习模型的训练效果,因此它已经在材料研究的许多领域中得到应用[26,43-44]。主动学习是一种先进的算法,它允许在预测中改善已学习模型,因此被应用于处理一些在训练之前难以收集足够合适数据的问题,例如机器学习力场(MLFF)[14,45]。除了这些算法之外,材料领域的研究人员还使用了其他算法,如遗传算法(GA)[46]、朴素贝叶斯(NB)[47]、迁移学习(TL)[48]等。
3 有监督学习的应用现状
有监督学习技术的应用在材料研究领域中正经历快速发展的时期,并已经帮助研究人员取得了较大的进展。 除了一些比较特别的研究方向,如半导体晶体生长中的动力学模拟[49],通过自然语言处理(NLP)自动生成的带隙数据库[50]等,有监督学习方法在材料研究中主要用于三类问题。
3.1 材料发现与设计
一方面,通过分析大规模的材料数据库以及理论和实验的数据,机器学习可以预测材料的性质、优化材料的特定属性,并提供新的候选材料,有助于加快新材料的研发过程,节省时间和资源[8,21]。另一方面,分类是机器学习的一个重要类别,在材料领域,将不同的材料分类是一项重要的研究课题,这种分类对于新材料的发现具有重要意义。通过机器学习算法,可以根据半导体材料的特征和性质将其分为不同的类别。这种分类可以帮助研究人员系统地组织和理解大量的材料数据,为新材料的发现和设计提供指导和启示。
利用图卷积神经网络,麻省理工学院的研究人员预测了钙钛矿材料的能隙、形成能以及其他性质[8],且成功预测了这些钙钛矿材料的金属和半导体分类。图2a 展示了晶胞的原子位置信息和无向图的映射关系;图2b 展示了表示钙钛矿晶体的无向图如何作为神经网络的输入。该组的研究人员对9,350 个测试晶体进行了模型训练和验证,获得了高达90%的分类预测准确率。
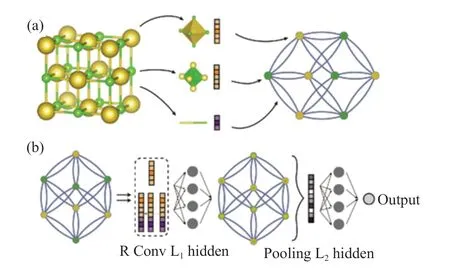
图2 钙钛矿的图神经网络[8]Fig.2 Graph neural network for perovskite[8]
3.2 物性预测
机器学习可以用于预测半导体材料的物性,如能隙、介电常数、热导率等。通过训练模型并利用大量的输入特征,机器学习可以提供高精度的物性预测结果,从而帮助研究人员更好地理解材料性质和优化材料性能[18-20]。材料科学的一个主要目标是预测不同材料的物理或化学性质,通过这种研究会对发现新材料有所帮助。已有许多研究报告了使用机器学习方法预测材料的各种性质,包括力学、热学、声学、光学、电学和磁学等方面。许多研究关注材料的电学性质,包括导电性、能带结构、载流子迁移率等。
郑州大学的一个课题组对纤锌矿GaN 的部分原子被不同 2,3,4 价金属离子替代形成的系列材料的带隙和替位原子种类及替位位置之间的关系进行了预测研究[19],采用了多种有监督学习方法,发现其中效果最好的是支持向量回归方法。支持向量回归方法的结果展示在图3 中,图中比较的是材料带隙相对于纤锌矿GaN 带隙的偏移值,横坐标是实际的数值,纵坐标是支持向量回归的预测值。图中的每一个数据点代表一种材料。青色的圆形代表训练集中的材料,黄色三角代表验证集中的材料,可见预测准确度较好。
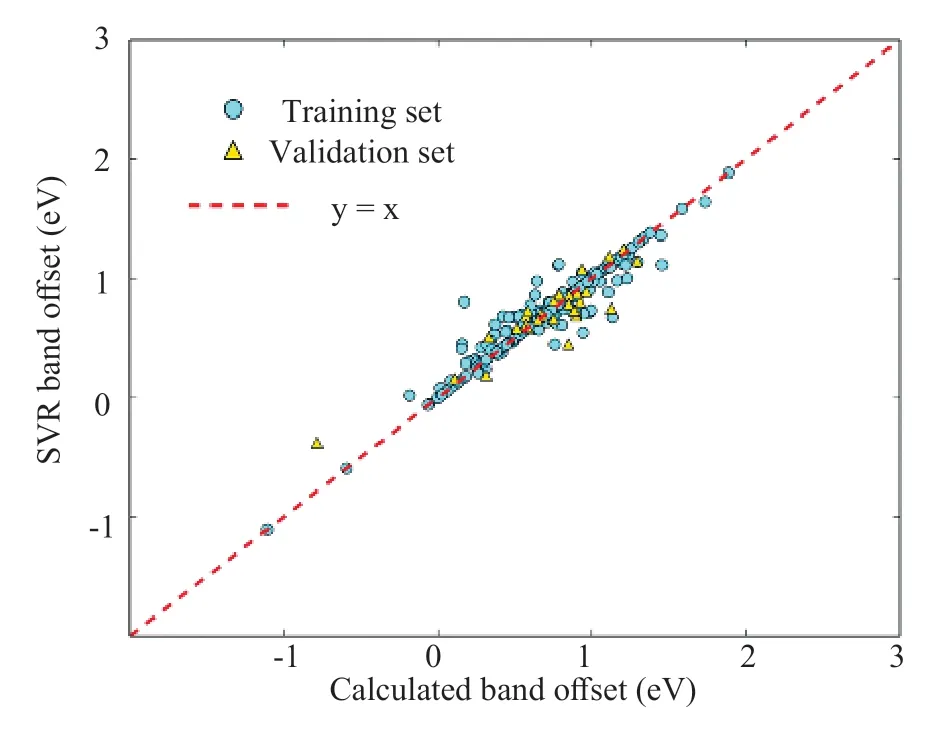
图3 纤锌矿GaN 原子替位后能带改变值预测[19]Fig.3 Prediction of bandgap offsets after atomic substitution in wurtzite GaN[19].
3.3 机器学习力场
与直接从描述符预测材料性质相比,机器学习力场(Machine learning force field,MLFF)是另一种方法。在MLFF 中,可以通过训练得到力场模型进行分子动力学(Molecular Dynamics,MD)模拟来预测材料的稳定性、热学性质和其他性质,尤其是材料的相变性质和表面性质。在这个领域中有大量的研究论文,而且研究论文的数量正处于快速增长阶段[13,25]。其中一些软件在此研究领域也应运而生,如DeePMD-kit[41]、Describe[51]、sGDML[52]等。
北京计算研究中心的一个研究小组应用MLFF方法来预测硅表面 (111) 的重构[15]。通过14,000 个小超胞的硅体材料和表面结构的第一性分子动力学模拟的数据来训练力场,然后利用训练的力场进行了较大空间尺度(17,000 个原子)和较长时间尺度(大约几纳秒)的硅表面 (111) 重构的分子动力学模拟。从这个模拟中,作者发现集体空位扩散是重构的关键过程。图4 展示了这个空位扩散过程。
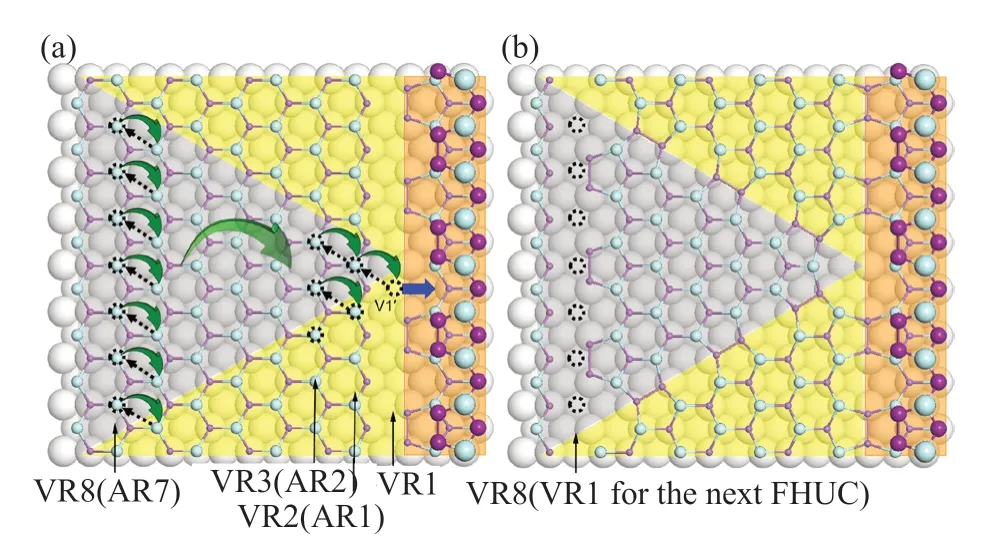
图4 硅111 表面的空位扩散过程[15]Fig.4 Vacancy diffusion process on silicon (111) surface[15]
4 总结和展望
本文介绍了机器学习的常见算法在材料科学中的一些研究进展。由于学术水平和主题的限制,仍有许多其他相关的高质量研究有待补充。
尽管在材料领域的机器学习应用中已经取得了一些成果,但仍然存在一些不足之处。(1)数据的不足,在材料科学领域存在大量数据,但很多时候对于机器学习的模型来说仍然不足,或者在一些研究中没有得到充分利用,这使得构建具有更大泛用性的通用模型存在一定的困难。这是因为模型越通用,则模型越复杂,包含的参数越多,也就需要更多的训练数据学习有效模型;(2)研究的统计验证有时尚不充分,该领域的一些研究结果缺乏对结果的统计分析。另外,对于材料的机器学习,有时很难保证训练数据和待预测实例之间的独立同分布条件。
材料领域的机器学习是一个活跃的研究领域,它有许多未被探索的方向和较大的研究前景。由于这个相对年轻的跨学科领域的蓬勃发展趋势,有理由相信材料领域的机器学习将成为材料研究的重要组成部分。对于相关的研究方向或机器学习模型,本文认为未来有一些方向值得更多关注:(1)主动学习。如前所述,在进行材料的机器学习之前,很难收集到合适和充足的训练数据,因为难以估计隐藏的统计分布。因此,主动学习算法的策略(即在训练过程中评估独立同分布条件及模型有效性,在必要时更新训练数据并重新训练直到模型合适)是一种有前途的方法。(2)图神经网络(GNN)。从原子坐标开始构建材料的描述符是材料科学中机器学习的一项重要基本工作,在这类描述符中,无向图自然满足位置的旋转、平移和置换不变性,符合物理要求。另一方面,在GNN 中有相对成熟的模型框架来训练无向图数据。因此,有理由相信GNN 会是本领域中的一个重要研究方向。(3)迁移学习。这种方法尝试预训练一个通用模型,然后在特定问题上进行微调。它与材料科学数据的结构自然契合。然而,预训练通用模型非常困难,因为涉及的数据和计算成本无法计数,但这将会是未来有前景的发展方向之一。相信在不久的将来,机器学习将帮助材料领域的研究在很多方向上取得突破性的成果。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
无机盐工业(2023年12期)2023-12-19 07:02:42
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
佛山科学技术学院学报(自然科学版)(2022年1期)2022-02-15 09:35:20
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
中国机械工程(2018年21期)2018-11-13 08:55:18
电子制作(2018年16期)2018-09-26 03:27:06
电影(2018年8期)2018-09-21 08:00:06
材料科学与工艺(2017年6期)2018-01-08 05:56:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
