
多特征融合的驾驶员疲劳状态检测方法
2023-08-25 08:05方浩杰董红召林少轩罗建宇方勇
浙江大学学报(工学版) 2023年7期
方浩杰,董红召,林少轩,罗建宇,方勇
(1.浙江工业大学 智能交通系统联合研究所,浙江 杭州 310014;2.杭州金通科技集团股份有限公司,浙江 杭州 310014)
利用驾驶员面部图像进行疲劳状态分析具有非接触、易实现、低成本等优点[1-2].人脸关键点算法的应用较广泛,目前已有的人脸关键点算法包括MCTNN[3]、PFLD[4]、TCDCN[5]等,诸多学者在此基础上进行改进与应用.Chen等[6-7]提出利用人眼状态检测算法提取疲劳参数,开展多特征加权融合.Adhinata等[8]提出结合FaceNet算法与k-最近邻(K-NN)或多类支持向量机(SVM),计算眨眼频率.上述方法要求输入图像尽可能正脸向前,人脸的五官出现图像中,但驾驶员在行驶过程中会出现大幅度的转头、低头、仰头等姿势动作,人脸关键点算法针对此类图像无法精确定位眼睛、嘴巴区域,存在较大的偏移[9].在疫情防控下,服务行业的驾驶员要求全程佩戴口罩,例如公交驾驶员、出租车驾驶员,利用人脸关键点算法无法精确定位嘴部区域,导致后续疲劳参数计算失准,无法准确判断驾驶员的疲劳状态.
诸多学者提出其他面部疲劳状态识别方法,Liu等[10-11]提出基于卷积神经网络和长短时记忆的驾驶员疲劳实时检测方法,计算嘴部、眼部疲劳参数.Wei等[12]提出基于sobel算子的边缘检测,提取人眼状态信息.Noman等[13]提出利用支持向量机提取眼睛区域,使用CNN网络进行眼睛状态分类.Worah等[14-16]采用CNN模型检测眼睛状态,计算闭眼时间与眨眼频率.上述方法大部分采用多个模块检测,整体网络尺寸较大,导致检测速度较慢.为了解决检测速度慢的问题,目标检测网络广泛用于驾驶疲劳检测.Yu等[17-18]提出基于SSD的检测网络,检测眼部、嘴部疲劳参数.Xiang等[19-20]提出利用YOLOv3模型对人眼进行检测.该类方法未考虑驾驶员因扶口罩、揉鼻子手部动作导致的脸部特征遮挡,当前算法均无法在戴口罩时进行打哈欠检测,最重要的是单一或独立的疲劳特征检测方法无法综合评判驾驶员疲劳状态,误判率高.
针对上述问题,本文提出疫情防控下驾驶员多特征融合的疲劳状态检测方法.建立模拟驾驶平台,利用移动端设备采集佩戴口罩和未佩戴口罩情况下的图像数据.针对驾驶员头部姿势、手势遮挡的问题,对YOLOv5目标检测算法进行改进,提高被遮挡目标和小目标的检测精度.结合人脸关键点算法,对眨眼和打哈欠帧数进行补偿计算.融合多种疲劳参数进行归一化处理,开展疲劳等级划分.在公开数据集与自制数据集上,开展眨眼、打哈欠次数及疲劳状态等级的验证.
1 提出的方法
该方法主要包含3个部分,分别是改进的YOLOv5目标检测算法、疲劳参数补偿方法以及多特征融合的疲劳状态检测方法.数据集的采集及实验均在模拟驾驶平台上开展,该平台由六自由度汽车性能虚拟仿真实验平台、驾驶仿真系统及模拟驾驶软件组成.实验招募20位志愿者进行模拟驾驶,模拟驾驶时长为55 min.为了更加逼近实际服务行业驾驶员的驾驶情况,为模拟驾驶员设置多种内置场景及任务,例如模拟疫情防控期间乘客上车扫乘车码,敦促乘客规范戴口罩.
1.1 改进的YOLOv5目标检测算法
将YOLOv5目标检测模型作为基础网络,并在此基础上进行改进,改进后的模型结构如图1所示.图中,m为检测层的深度.从图1可知,模型结构由主干网络(backbone)、加强特征提取网络(neck)、检测网络(head)3部分组成.Conv模块中的激活函数选择Swish函数,将CIOU损失函数作为边界框回归损失.
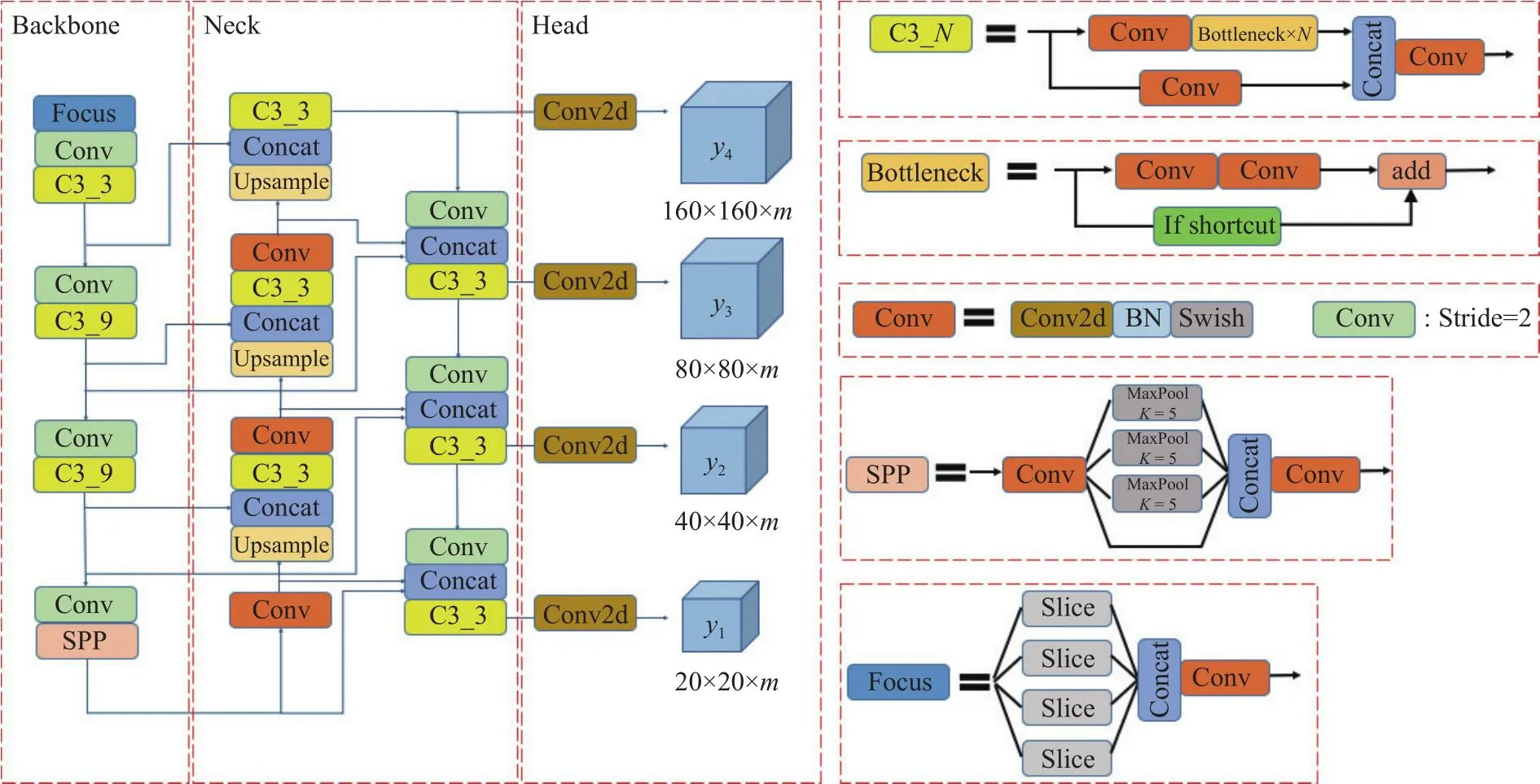
图1 改进后的YOLOv5网络结构Fig.1 Improved YOLOv5 network structure
1)自适应锚框:由于头部旋转及手部遮挡,会导致眼部、嘴部标签框形状多变,眼部标签框还会因为远近的原因导致两只眼睛的标签框尺度不一,采用自适应锚框方法,锚框即为标签框.在每次训练前,对数据集中的标注信息进行核查,利用遗传算法随机对锚框变异,计算该数据集标注信息与锚定框的最佳召回率,并进行反复迭代覆盖,当最佳召回率大于或等于0.98时,不需要更新锚定框.
2)增加检测层:不同驾驶员的驾驶习惯不同,会对座椅进行调节;在驾驶过程中身体存在前倾或后仰动作,会导致检测目标(人脸、眼睛、嘴巴)变大或缩小,需要提高模型多尺度(较大或较小)目标检测能力.通过增加结合层、卷积层、C3层的方法,整体分别多进行一次上采样和下采样,将主干网络中包含较多小目标特征信息的同尺度特征层输入结合层,进行特征融合操作,提高对小目标的检测性能.
3)BiFPN网络结构:在增加检测层后,C3层、结合层、卷积层数量增加,整体网络层数加深,但每一层网络都会在一定程度上造成特征丢失,因此对于不同层级进行特征融合尤为重要.当戴口罩时,打哈欠检测区域需要对挤眼、挑眉、口罩变化等细节进行特征提取,且该区域的特征变化细微.将主干网络多层计算结果一次或多次输入Bi-FPN加强特征提取网络,采用BiFPN自下而上的结构时,对2个同尺度特征层进行融合;采用自上而下的结构时,利用跳跃连接的方式对3个同尺度特征进行融合.利用BiFPN网络,使得预测网络对不同大小的目标更敏感,提升了整体模型的检测能力,降低了漏检率与误检率.
图像识别流程:输入图像会在主干网络进行特征提取,将获取到的3个有效特征层输入Bi-FPN加强特征提取网络,将不同尺度的特征层进行融合.在检测网络获得4个加强过的有效特征层,对特征图上的特征点进行判断,实现多尺度目标物检测,确定目标物的类别和位置.
1.2 疲劳参数的补偿方法
在目标检测数据集的标注过程中,将完全闭眼的图像数据标注为闭眼状态,其余数据均标注为睁眼状态.由于打哈欠是从闭嘴到张嘴打哈欠,再从张嘴状态到闭嘴状态,难以准确定义张嘴临界状态.取完整打哈欠过程中部X%的图像标记为张嘴.在实验过程中发现,驾驶员戴口罩时打哈欠会出现挤眼、挑眉、皱眉等神情,眼部附近区域会发现明显变化,伴随着口罩大幅度的张开.戴口罩的打哈欠图像数据从完整时间序列的角度,对图像的大面部撑开的口罩、眼部及附近区域进行标注,取完整过程中部Y%的图像标记为打哈欠.图像标签的制作方法如图2所示.
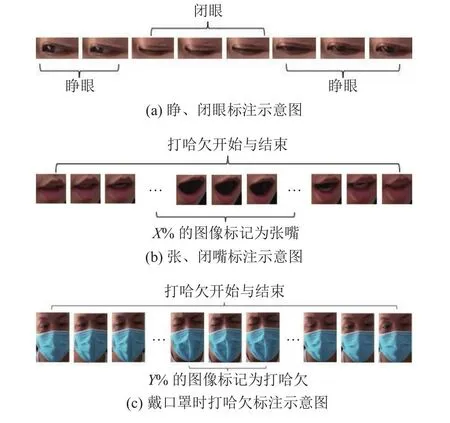
图2 图像标注的示意图Fig.2 Schematic of image annotation
研究表明,P80指标与驾驶员眼部疲劳特征的相关性最高,即根据人脸关键点算法确定眼部各个关键点并计算眼睑覆盖度,当眼睛瞳孔的整体面部被眼睑覆盖超过80%时认为眼睛是闭合的.嘴部根据关键点定义张嘴与闭嘴.由图像数据预处理方法的原理可知,当前闭眼、张嘴、打哈欠的图像帧预测数量相较于人脸关键点算法偏少,因此提出疲劳参数补偿方法.利用人脸关键点算法计算出驾驶员在正脸状态下闭眼、张嘴的帧数,与当前的数据预处理方法进行比较,根据比值进行补偿.
1)眼睛纵横比.EAR为眼睛纵向界标与横向界标之间的欧式距离比值,可以直接反映眼睛闭合程度.根据眼睛的6个关键点位置(见图3(a)、(b)),EAR的计算公式为
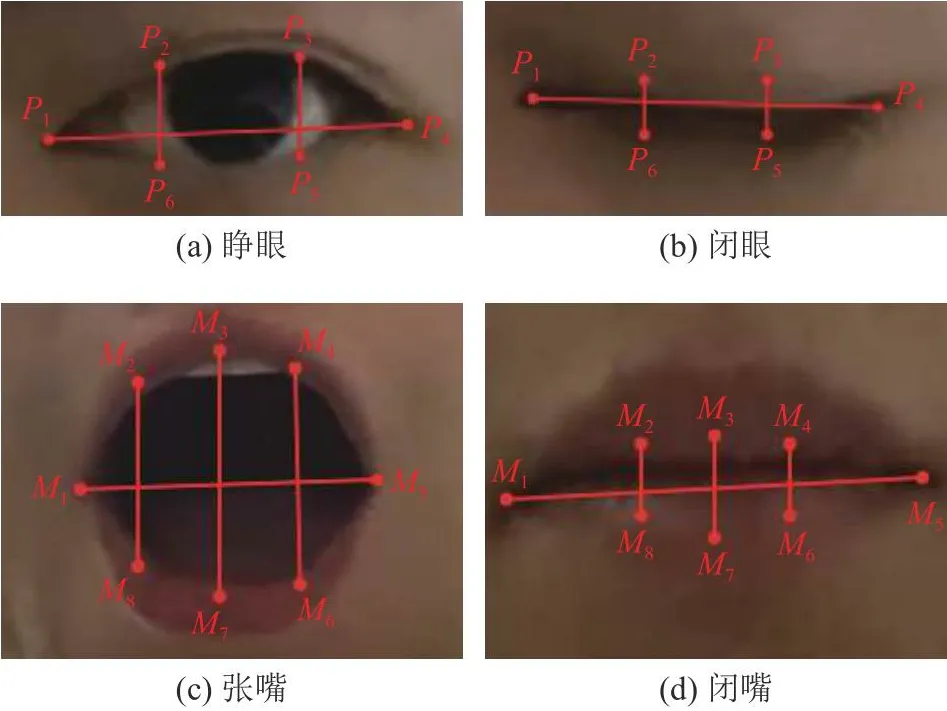
图3 人脸关键点位置的示意图Fig.3 Diagram of face key point position
当驾驶员眼睛睁开时,EAR保持动态平衡,即处于小幅波动.当驾驶员眼睛闭合时,EAR会迅速下降,并在眼睛再次睁开时迅速恢复到动态平衡.在结合P80标准后,EAR可以直接反映眼睛的睁闭状态.
2)嘴巴纵横比.参考眼睛纵横比的定义方法,根据嘴巴的8个特征点(见图3(c)、(d)),嘴巴纵横比MAR特征点的计算公式为
嘴巴纵横比由嘴部内轮廓的8个特征点计算所得,可以直接反映嘴部的张开程度.由于驾驶员会与乘客进行频繁交流,须设定MAR阈值区分打哈欠和正常说话时的嘴部张开幅度.
3)EAR和MAR阈值的确定.为了确定驾驶员正脸状态下EAR和MAR的波动范围,须计算驾驶员正脸状态下EAR和MAR的最大值、最小值.参考perclos中的P80指标确定EAR和MAR阈值,阈值的计算公式为
式中:X1为眼睑覆盖瞳孔面积占比,X2为嘴巴张开程度与最大张度的比值.
4)参数补偿.根据上述方法确定EAR和MAR阈值,完整截取驾驶员正脸状态下的眨眼、打哈欠(未戴口罩)图像序列帧.根据阈值确定闭眼和打哈欠帧数,将该帧数与目标检测算法标签设置帧数比较,计算比值.比值S的计算公式为
式中:F为目标检测标签帧数,f为P80指标下利用人脸关键点算法识别驾驶员睁眼或张嘴的帧数.
依次计算得出眨眼帧数补偿参数SE、张嘴帧数补偿参数SM.由于SM是未戴口罩情况,根据目标检测标签预处理方法可知,戴口罩情况下打哈欠帧数补偿参数SY的计算公式为
1.3 多特征融合的疲劳状态检测方法
结合上述方法,可以分析的数据包括眨眼帧数、眨眼频率、张嘴帧数、打哈欠次数.连续闭眼帧数超过2帧计为眨眼一次,张嘴或打哈欠识别结果连续帧超过20帧计为打哈欠一次.眨眼频率BF和打哈欠频率YF表示单位时间内的眨眼次数和打哈欠次数.定义ECN为连续闭眼帧数超过10帧的次数.
结合补偿参数,定义ECR为计算单位内闭眼帧数与总帧数的比例关系,能够反映眼睛闭合持续时间占检测时间的比值及驾驶员疲劳状态,公式如下:
式中:tE为眼睛闭合帧数,TE为单位时间的总帧数.
根据单位时间内打哈欠帧数占总帧数的比例关系,定义MOR表示未佩戴口罩情况下单位时间内的张嘴帧数占比,定义MORM表示佩戴口罩情况下单位时间内的打哈欠帧数占比,公式如下:
式中:tM为张嘴的帧数,TM为单位时间的总帧数,tY为佩戴口罩情况下的打哈欠帧数,TY为单位时间内的总帧数.
根据上述计算方法,可以得到BF、YF、ECN、ECR、MOR、MORM.由于得到的多个疲劳参数指标量纲不同,若将疲劳指标进行综合评判,则须对所得参数的结果进行标准化处理.利用最大最小标准化(min-max normalization)的方法进行数据归一化处理,转换公式为
式中:x′为归一化处理后的数值,xi为实际检测到的疲劳参数数值,xmin、xmax分别为驾驶员清醒状态检测视频中疲劳参数的最小值和最大值.
单一疲劳特征难以综合驾驶员的真实疲劳状态,易受个体差异的影响,导致疲劳等级误判.对各疲劳参数归一化后进行融合,将融合的值定义为综合疲劳指标Q,以此综合反映驾驶员的疲劳状态.综合疲劳指标Q的公式为
式中:Vi为归一化后的疲劳参数,Wi为各疲劳参数的权重.
2 实验结果与分析
基于pytorch深度学习框架,搭建改进后的YOLOv5模型.硬件配置如下:i5-12600KF CPU、GTX3070、32 GB内存.
2.1 数据预处理
数据集包括公开数据集NTHU及自制数据集.公开数据集NTHU整体上包含多个不同种族的受试者,受试者坐在座椅上,控制方向盘和踏板模拟驾驶汽车.视频记录多种光照条件下驾驶员正常驾驶、打哈欠、慢眨眼、入睡、大笑等模拟驾驶场景,对每段视频进行疲劳状态划分(清醒、疲劳、重度疲劳).取场景帧率为30帧/s的AVI格式视频.部分视频图像如图4所示.

图4 NTHU数据集的部分视频图像Fig.4 Partial video images of NTHU dataset
自制数据集是在模拟驾驶平台采集各类情况下的驾驶图像数据.建立的图像数据包括驾驶员工作期间的大幅度转头、低头、抬头、前倾、后仰、歪头情况下的睁眼闭眼和打哈欠图像,该类均包含戴口罩与不戴口罩的图像.为了提高驾驶员面部遮挡图像识别的准确性,采集驾驶员扶口罩、揉鼻子数据集.部分数据集的图片如图5所示.

图5 自制数据集图像的示意图Fig.5 Sketch of self-made data set image
在NTHU驾驶员疲劳检测视频数据集中截取数据样本3 300张,自制数据集共计包含8 700幅分辨率为1 920像素×1 080像素的图像数据.将其中10 000张作为训练集,1 000张作为验证集,1 000张为测试集数据集.利用标注工具,对数据集图片进行标注及归一化处理,避免与正常讲话交流状态混淆.在多次实验后截取驾驶员未戴口罩时的打哈欠图像中部的70%进行标注,将该段图像数据的嘴部区域标注为张嘴,其余均标注为闭嘴状态,即X= 70.由于戴口罩后嘴部区域特征被遮挡,在打哈欠的开始及结束部分图像,不再大幅度撑开口罩,面部神情开始恢复平静.观察驾驶员在戴口罩情况下的打哈欠视频流数据,截取戴口罩情况下打哈欠完整时间序列图像中部50%的图像数据,将该段图像数据标注为打哈欠,即Y= 50.
标签分别是未戴口罩(Um)、戴口罩(Ym)、睁眼(Oe)、闭眼(Ce)、张嘴(Om)、闭嘴(Cm)、打哈欠(Ya).将标签框参数定义为(C,rx,ry,L,S),其中C为类别ID参数,rx和ry为目标中心点的横、纵坐标,L为目标框的较长边,S为目标框的较短边.
2.2 算法改进效果比较
模型训练参数的输入尺寸为640像素×640像素,BatchSize设置为16,迭代次数为300,优化器选择随机梯度下降(SGD)法.采用One Cycle方法对学习率进行调整,初始学习率为10-5,呈余弦变化衰退到10-7.为了提高脸部遮挡情况下的检测能力及模型泛化能力,增加噪声数据,提升模型的鲁棒性,对输入图像数据进行Mosaic数据增强.对于传入图像进行随机翻转、缩放、裁剪等处理,将得到的图像进行依次拼接.
为了验证改进方法的有效性以及改进后模型与当前主流目标检测算法的优劣效果,将其余算法设置相同的训练参数进行验证.训练结果如表1所示,表中包括各模型参数量M、浮点运算次数FLOPs及各检测类别的AP.AP表示某一检测类精确率(precision)和召回率(recall)形成PR曲线下的面积,平均精度均值(mAP)是将所有类的AP求平均值.从表1可知,改进后的目标检测算法的平均精度最高,达到99.4%,表明该模型相较于其他模型具有更加理想的检测效果.Faster-RCNN模型在参数量、计算量上大幅度高于其他模型,平均检测精度未见明显的优势,但是在面部检测类别中对于是否戴口罩的检测精度最高,可见对于大目标物体检测具有优势,但是对于眼部、嘴部目标变化多样,尤其针对睁眼、闭眼类别的检测精度较低.YOLOv3-tiny、SSD、YOLOv5均为端到端类型的目标检测网络,YOLO系列网络的参数量和计算量更低,检测精度更高.在YOLOv5-S基础网络上分别增加检测层和BIFPN网络结构,开展消融实验,验证改进方法的有效性.从表1可知,在增加检测层后,对眼部、嘴部区域的检测精度明显提升,戴口罩情况下的打哈欠检测精度也有了提高,但戴口罩的检测精度有小幅下降.可见,在增加检测层后,对小尺度的目标检测性能和图像中的细节特征提取性能有所提高.在增加BIFPN网络结构后,模型的整体性能提升,尤其是对于戴口罩情况下的打哈欠检测,可见特征层融合后,更多的图像细节信息被保留下来.改进后模型的检测效果如图6所示.可知,该模型在驾驶员大幅度转头、低头、手部遮挡、戴口罩等情况下,均可对眨眼、打哈欠进行识别.
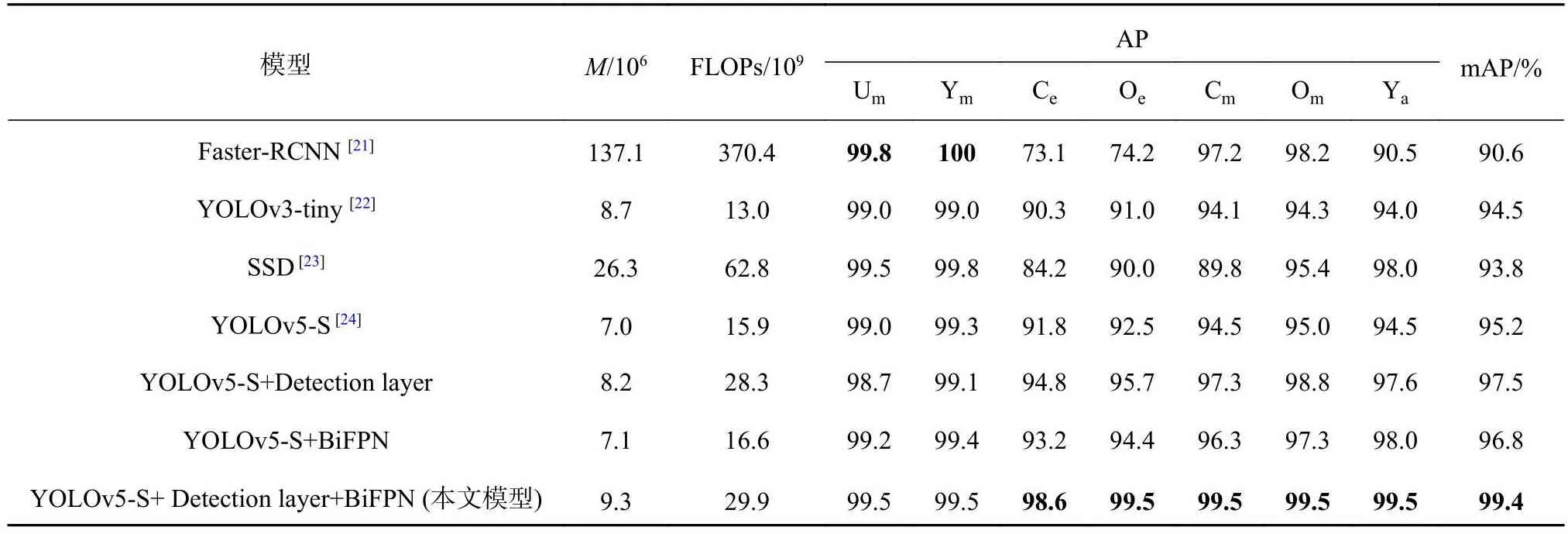
表1 不同模型的性能比较Tab.1 Performance comparison of different models

图6 本文改进后模型的检测效果图Fig.6 Checking effect chart of improved model
2.3 参数补偿计算
利用人脸关键点算法计算驾驶员在正脸状态下闭眼、张嘴的帧数,与当前的数据预处理方法进行比较,根据比值进行补偿.截取多位模拟驾驶员正脸状态下的眨眼、打哈欠图像,利用Dlib库中的人脸关键点检测器,计算驾驶员左、右眼的EAR并取均值.
结合式(3)、(4)计算,取X1为0.8,即表示眼睛闭合程度大于眼睑覆盖瞳孔的80%时视为闭眼.同理,X2取0.2,即嘴巴张开程度大于最大张度的80%时视为打哈欠动作.EAR的最大值和最小值分别为0.48、0.12,阈值为0.19;MAR的最大值和最小值分别为0.66、0.34,阈值为0.60.当EAR<0.19时视为闭眼,MAR> 0.60时视为打哈欠动作.
根据所得的阈值,结合式(5)计算各补偿参数S.闭眼帧数的统计如表2所示.表中,Ne为眨眼次数,NPe为利用关键点方法识别的闭眼帧数,NTe为眼部目标检测的标签帧数,Re为NPe与NTe的比值.分别统计了眨眼次数为100、500、1 000时的关键点帧数与目标检测标签帧数,SE为1.31~1.34.通过增加眨眼样本数量,可以提高SE的精准度,本次SE取1.32.
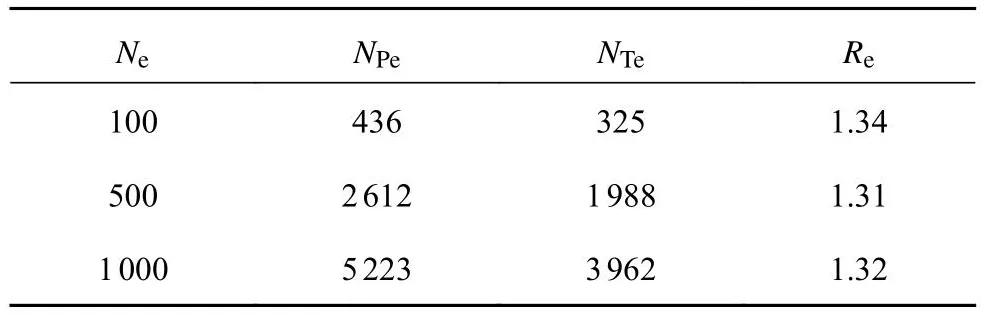
表2 闭眼帧数的统计Tab.2 Statistics of closed-eye frames
打哈欠帧数的统计如表3所示.表中,Nm为打哈欠次数,NPm为关键点方法识别打哈欠帧数,NTm为嘴部目标检测标签帧数,Rm为NPm与NTm的比值.分别统计20、40、100次关键点帧数与目标检测标签帧数,SM为1.210~1.220,本次SM取1.22.根据当前SM的计算结果可知,本次SY取1.71.
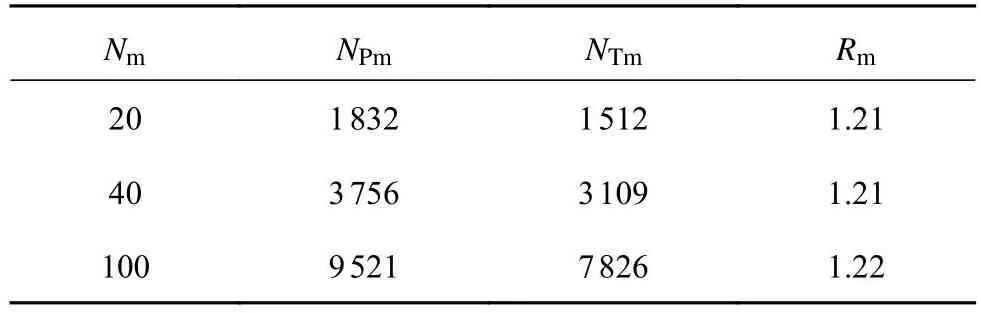
表3 打哈欠帧数统计Tab.3 Statistics of yawning frames
2.4 多特征融合方法验证
对模拟驾驶视频中的眨眼和打哈欠次数进行人工核验,与模型识别结果进行比较,结果如表4、5所示.表中,NDe、NDm分别为算法检测眨眼、打哈欠次数,NAe、NAm分别为眨眼、打哈欠算法检测与人工校验吻合次数,NFe、NFm分别为眨眼、打哈欠算法检测的误检次数,NLe、NLm分别为眨眼、打哈欠算法检测的漏检次数,Ae、Am分别为眨眼、打哈欠算法检测的准确率.准确率(Acc)的计算公式为
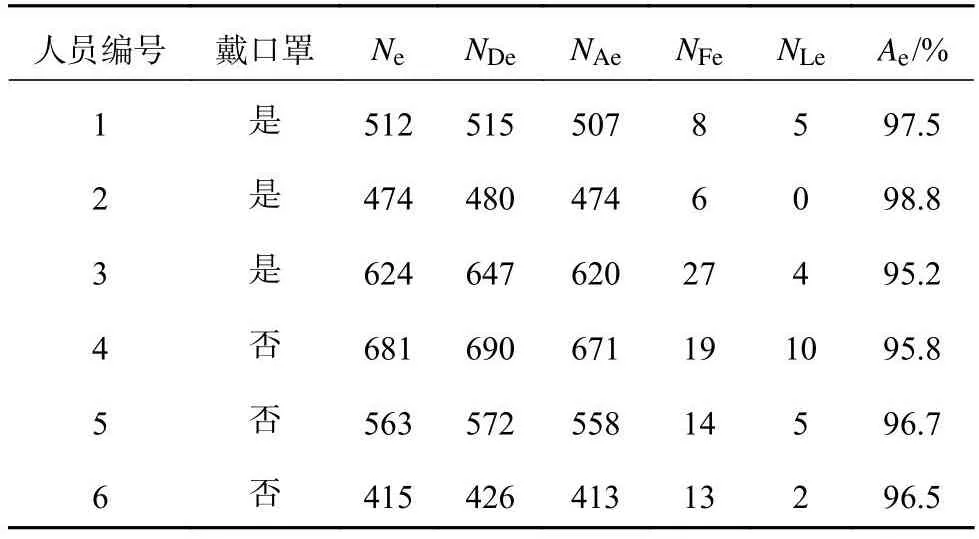
表4 眨眼计数分析Tab.4 Blink count analysis
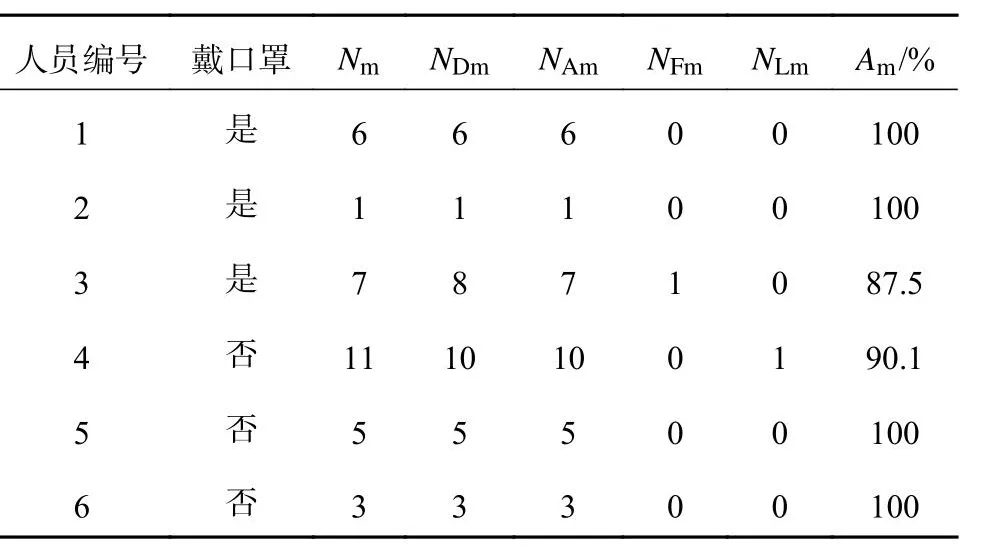
表5 哈欠计数分析Tab.5 Yawning count analysis
式中:TP为检测计数与人工核验吻合的次数,FN为检测计数的漏检次数,FP为检测计数的误检次数.
根据实验结果表明,利用该方法可以对戴口罩和不戴口罩的驾驶员进行眨眼和打哈欠计数检测,在目前驾驶任务中眨眼准确率大于95%,打哈欠计数错误至多为1次.在当前的硬件条件中,单帧图像检测仅需0.01 s,满足实时检测的需求.
结合式(10)可知,归一化处理后的数据均为无量纲的小数,且集中在[0, 1.0]区间内.各指标可以进行加权相加,综合反映驾驶员的疲劳状态.结合模拟驾驶中驾驶员不同疲劳程度下的各疲劳参数值以及现有研究中各参数指标反映驾驶员疲劳的可靠性程度,设置不同权重[25-26].NTHU驾驶员疲劳状态检测视频中清醒状态时的疲劳参数指标最小值和最大值及权重如表6所示,参数统计的时长为1 min.表中,Pmin、Pmax为疲劳参数的最小值、最大值,W为各疲劳参数的权重.若眨眼次数不在设定范围中直接计为1,其余参数指标低于最小值则直接计为0,高于最大值直接计为1.
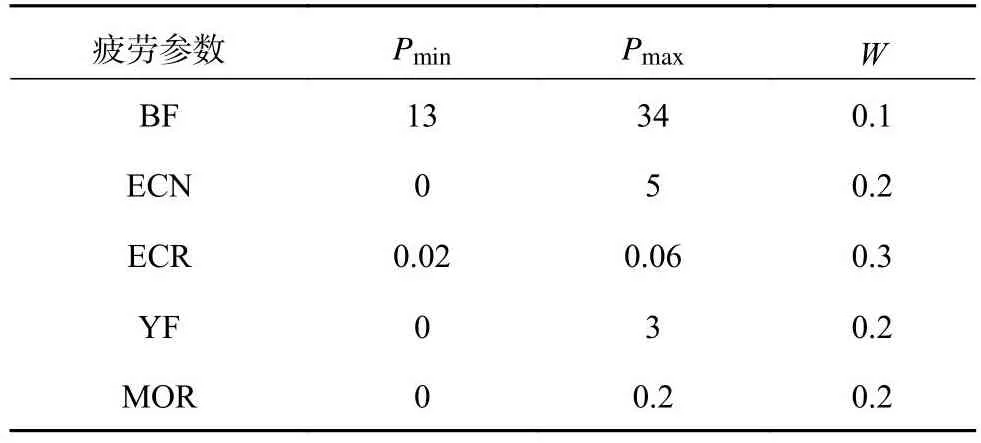
表6 综合疲劳参数的最大值以及权重Tab.6 Maximum value and weight of comprehensive fatigue parameters
Q的取值在[0, 1.0]区间内.根据Q的不同,将状态分为3个等级:清醒、疲劳、重度疲劳.综合疲劳指标的权重和疲劳等级,将特征参数加权值与疲劳等级相对应,根据对应关系能够判断驾驶员的驾驶状态.对应关系如表7所示.

表7 综合疲劳指标与疲劳等级的对应关系Tab.7 Relationship between comprehensive fatigue index and fatigue grade
为了验证模型识别及参数补偿方法的可靠性,利用NTHU驾驶员疲劳检测视频数据集中的部分数据进行验证.随机选取3组数据,每组数据均包含清醒、疲劳、重度疲劳状态.结合疲劳检测模型计算单位时间(1 min)下的疲劳参数,对眨眼、打哈欠识别帧数分别乘以参数补偿值,最终计算结果、综合疲劳指标以及对应的疲劳状态如表8所示.可知,利用提出的疲劳状态识别方法及定义的疲劳指标,可以有效地识别驾驶员行驶状况下的疲劳状态;识别结果与真实状态全部吻合,设置的阈值及划分方法均合理,识别效果良好.
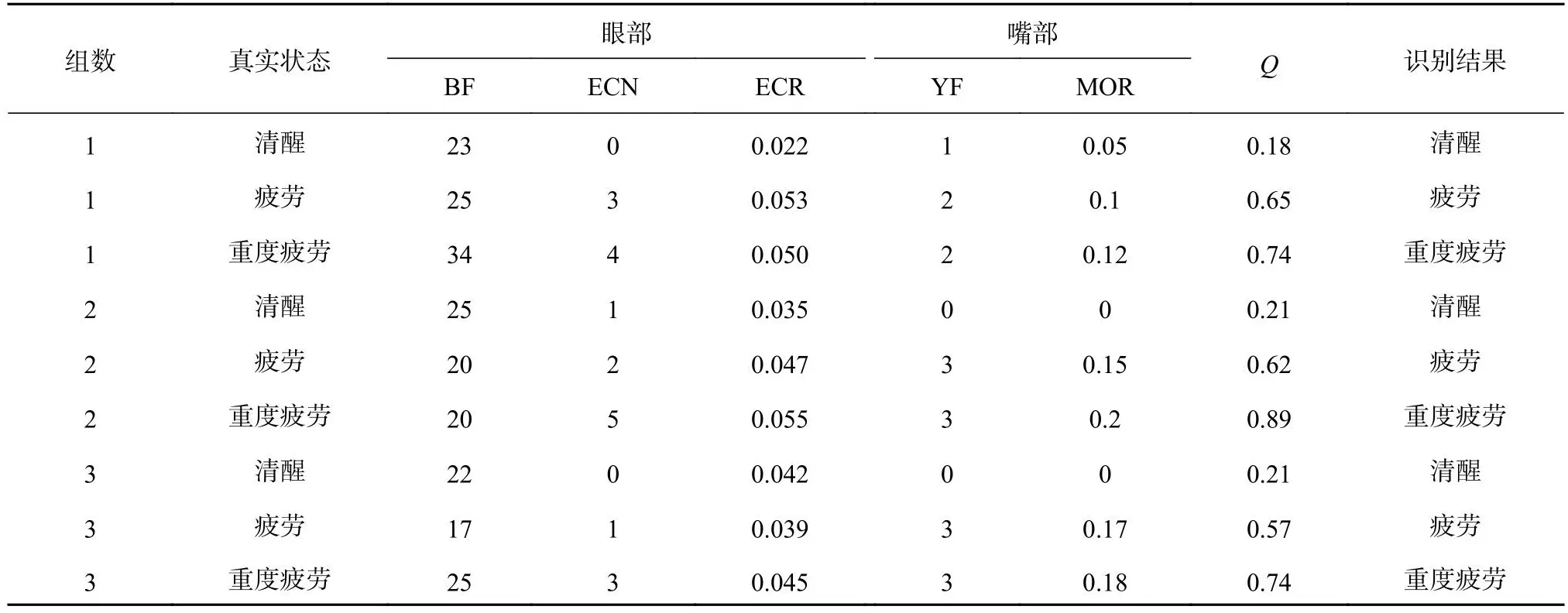
表8 NTHU数据集的不同疲劳状态识别结果Tab.8 Different fatigue state identification results of NTHU dataset
根据工信部发布的第346批车辆产品公示清单可知,公交车、出租车服务业车辆与私家车均属于M类.将上述方法及预警机制直接应用至本文的模拟驾驶.截取模拟驾驶实验中的多段视频,根据戴口罩情况分成2组,1组为未戴口罩,2组为戴口罩,计算单位时间(1 min)内的各疲劳参数.验证结果如表9所示.表中,真实状态由驾驶员的主观反应及行驶状态综合判定,其中MORM与MOR两者的差别仅为是否戴口罩,均为单位时间内打哈欠帧数占比,因此权重相同.从表9可知,识别结果与真实状态均吻合,验证了该综合疲劳指标与疲劳等级划分的鲁棒性和可行性,对于未戴口罩和戴口罩的情况均可以进行疲劳状态识别.
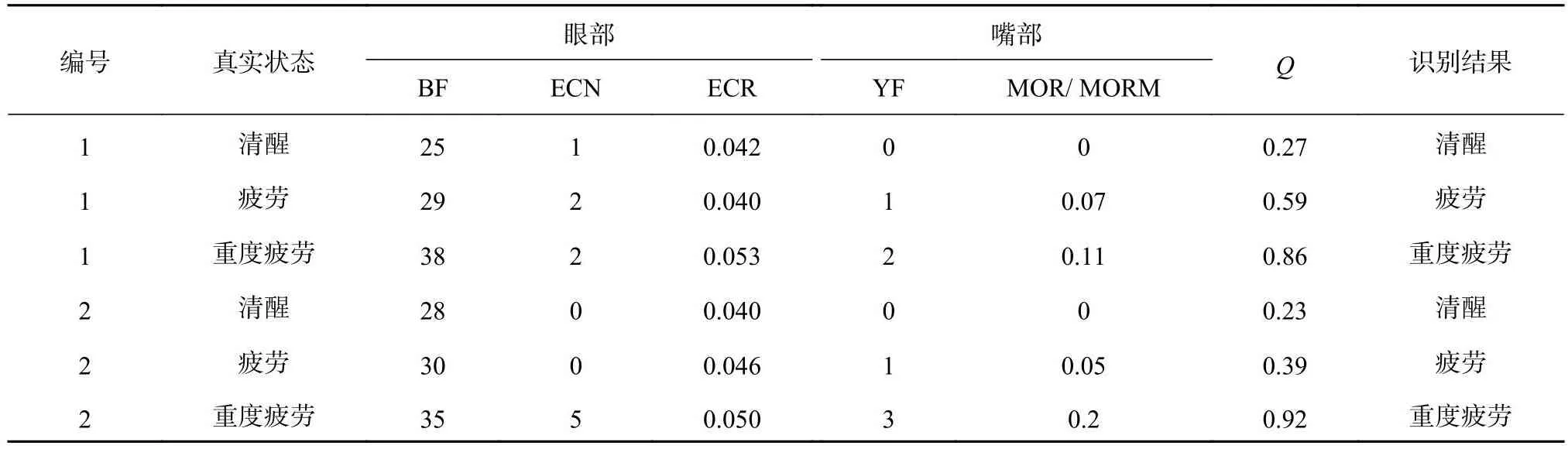
表9 模拟驾驶疲劳状态的识别结果Tab.9 Recognition results of simulating driving fatigue state
3 结 论
(1)针对服务行业驾驶员在实际工作中会出现的大幅度转头、遮挡、仰头、俯视等姿势变化导致的眨眼、打哈欠检测精度低及疫情防控下戴口罩后无法进行打哈欠检测的问题,提出利用改进后的YOLOv5目标检测算法对眨眼和打哈欠识别.通过增加检测层及多层次特征层融合的方式,提高对单帧图像眼部、嘴部区域及打哈欠检测区域的目标检测精度,将多帧检测结果放在连续时间序列中,利用逻辑方法进行眨眼和打哈欠计数.根据实验结果表明,利用该方法可以对戴口罩和不戴口罩的驾驶员进行眨眼和打哈欠计数检测,在目前驾驶任务中眨眼准确率大于95%,打哈欠计数错误至多为1次.在当前硬件设备中,单帧图像检测仅需0.01 s,满足实时检测的需求.
(2)结合人脸关键点算法对疲劳参数进行补偿,提高眨眼和打哈欠帧数的检测准确率.对多种疲劳指标进行归一化处理,赋予不同权重,综合判断驾驶员的疲劳状态.公开数据集与自制数据集验证结果表明,利用该方法可以准确判断驾驶员疲劳状态,对疫情防控下的驾驶员疲劳检测具有重要意义.
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
作文大王·笑话大王(2019年3期)2019-04-22
公民与法治(2016年4期)2016-05-17
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
