
基于改进生成对抗网络的书法字生成算法
2023-08-25 08:05李云红段姣姣苏雪平张蕾涛于惠康刘杏瑞
浙江大学学报(工学版) 2023年7期
李云红,段姣姣,苏雪平,张蕾涛,于惠康,刘杏瑞
(西安工程大学 电子信息学院,陕西 西安 710048)
书法作为中国文化的主要载体,其书写风格的多样性造就了汉字独特的艺术美感.由于古人手迹稀少且易被损毁,传统人工修复周期长,效率低,而汉字生成技术可以根据少量手迹生成同一风格的其他汉字,快速修复历史古籍文献.此外,设计字体库是一项费时费力的工作,利用汉字生成技术可以避免大量字形的调整,快速建立个性化字体库,解决字体库不完整的问题[1-3].
针对字体生成任务,Tian[4]提出Rewrite模型,生成的字体结构细节模糊.Tian在Pix2pix[5]网络的基础上提出zi2zi[6]模型,与Rewrite相比,zi2zi生成效果明显提升.Jiang等[7]提出DCFont,分别编码字体内容和风格特征,通过解码和特征重构生成字体.Chang等[8]提出DenseNet CycleGAN,将Cyc1eGAN[9]中的残差单元替换为密集连接网络,生成字体笔画错连、缺失的情况较严重.Ren等[10]通过引入自注意力机制及边缘损失,解决了已有模型生成汉字局部信息不明显、层级结构不鲜明的问题.Wu等[11]提出CalliGAN,利用汉字笔画信息,提升生成图像的细节特征.Park等[12]提出LFFont,学习局部组件风格,利用低秩矩阵分解组件级风格,但容易出现组件缺失,模型性能不稳定.Xie等[13]提出DGFont,引入特征变形卷积增强生成字体结构的完整性.Park等[14]提出MXFont,采用多头编码器特征提取,利用局部组件信息监督模型训练.Kong等[15]提出CG-GAN,设计组件感知模块,在字符组件级别进行监督.
为了减少生成字体笔画结构的丢失和细节模糊的问题,稳定模型训练,提高生成字体图像的质量,本文提出基于改进生成对抗网络的书法字生成算法.通过改进编码器卷积层结构,提高字体细节结构.通过自注意力网络捕获字体笔画间的关系,学习丰富的上下文信息,分配不同特征的权重,增强风格特征的表征能力,使得生成字体的风格更加接近目标字体.增加边缘损失函数,细化字体边缘信息,提高生成图像的质量.通过生成2种不同风格的书法字,验证本文方法的有效性.
1 zi2zi生成对抗网络
zi2zi网络结构如图1所示,该网络中的生成器(generator,G)包括编码器和解码器.生成器中的编码器提取图像特征,在编码器后嵌入风格类别标签,将编码后的字符图像特征和嵌入的风格特征共同输入解码器.采用AC-GAN[16]的类别损失,确保生成汉字的类别信息一致.生成器后级联的编码器,与生成器中的编码器参数共享.该编码器对源字体与生成字体编码,利用DTN[17]中的恒定损失,计算编码之后两者的损失,确保汉字内容正确,提高生成质量.
判别器(discriminator,D)判断输入图像是否真实,同时鉴别图像类别.在网络训练过程中,期望生成器生成接近目标风格的字体图像,达到欺骗判别器的目的.判别器能够判别生成的假字体图像,两者交替对抗训练,实现纳什平衡.
2 改进的生成对抗网络
以zi2zi为基本网络模型,针对网络训练稳定性低、生成图像质量差、生成字体结构不清晰的问题,改进生成器与判别器的结构,设计新的损失函数.改进后的网络整体结构如图2所示.该网络包括内容编码器Ec、风格编码器Es、解码器Dd、判别器D,内容编码器用来提取输入图像的内容特征fc,风格编码器用来提取风格特征fs.将目标风格字体图像的标签l转换为one-hot编码fl,如{“目标风格1”:0,“目标风格2”:1}编码为独热编码标签,表示不同风格的字体,并扩展到与内容和风格特征向量相同的维度.
结合编码后的l及内容编码向量、风格编码向量,将三者拼接成向量f=[fl,fc,fs],输入到解码器Dd中,经过解码得到生成图像.判别器D的作用有以下2点:1)判断输入图像是虚假生成图像还是真实目标图像;2)判断图像的风格类别.
2.1 生成器结构
生成器由内容编码器Ec、风格编码器Es、解码器Dd组成.内容编码器将256×256×1维度的输入图像映射到1×1×512维度的特征层空间,得到内容特征向量.zi2zi在内容编码模块中仅使用卷积提取特征,在特征提取过程中随着网络深度的增加,细节信息更容易丢失,提取不到图像较深层次的特征信息,生成的字体图像质量较差.
2.1.1 残差单元 为了捕捉字体图像更多的局部特征,在内容编码器中加入残差单元,扩充卷积结构,形成卷积-残差交替模块.内容编码器包括5层卷积层、5层卷积-残差交替编码结构,内容编码器的具体参数设置如表1所示.卷积单元Conv-IN-LRelu表示Conv卷积操作、实例归一化( instance normalization,IN )、LRelu激活函数,卷积核为4,strides为步长,filters为卷积核数.

表1 内容编码器的网络参数Tab.1 Network parameters of content encoder
汉字笔画线条的粗细、长短、书写方向等局部细节信息影响汉字的字形与风格.为了保存汉字细节的结构特征,减少参数量,使用1×1的卷积核,残差单元的结构如图3所示.

图3 残差单元Fig.3 Residual block
2.1.2 上下文感知注意力模块 为了使得模型生成的字体图像风格与目标风格保持一致,本文算法中额外引入风格编码模块,该模块在训练过程中更多关注字体的风格样式.风格编码器网络结构主要由6层卷积层和上下文感知注意力模块组成,上下文感知注意力模块如图4所示.风格编码器的输入只进行卷积操作,卷积核为7,步长为1.其他5层结构均为Conv卷积操作、实例归一化、Relu激活函数,卷积核为4,步长为2,卷积核数依次为64、128、256、256、256.
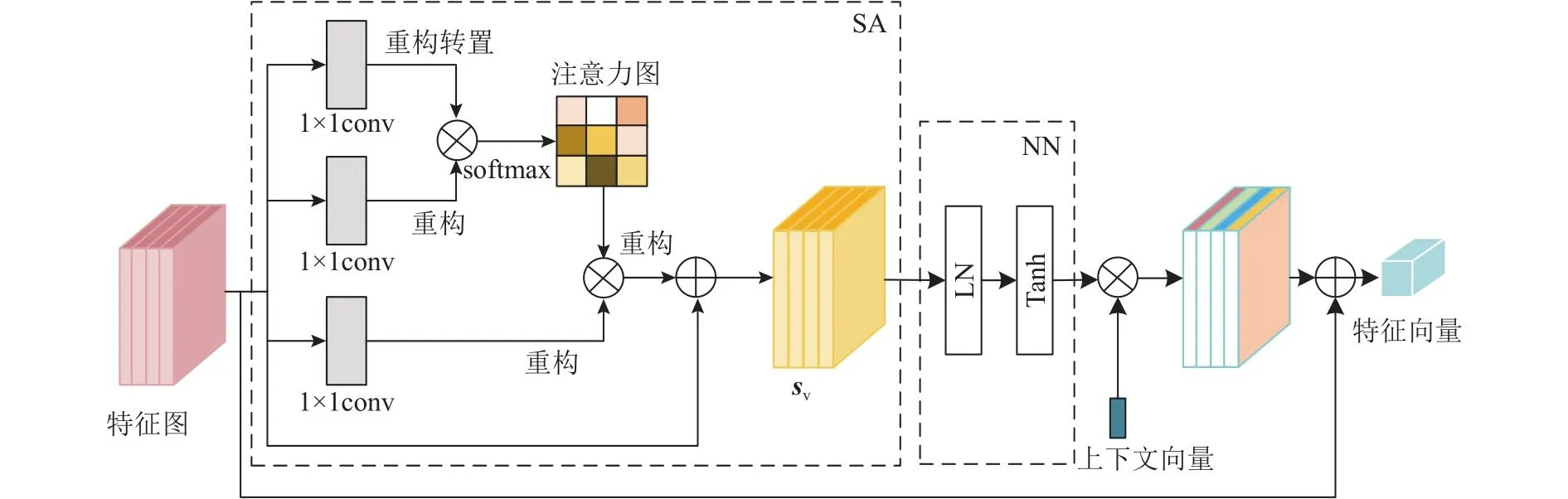
图4 上下文感知注意力模块Fig.4 Context-aware attention block
上下文感知注意力模块将最后1层卷积得到的特征图输入到自注意力网络( self attention, SA ),对特征图中的像素间结构建立联系,输出的新特征向量与原始特征进行像素加的操作,提高同一类别的紧凑性.此时的特征图sv能够建立全局关联性,包含全局上下文信息,不局限于当前感受野,而且包含其他区域的上下文信息,从而可以获取到与目标风格更相关的信息,增强全局特征的准确性.
为了增强特征图中不同区域的表征能力,自动感知上下文信息的特征权重,使用上下文向量cv来衡量特征权重.将特征向量sv输入到单层神经网络NN,如下所示:
式中:w和b分别为权重与偏置.比较输出的pv与可训练的随机初始化向量cv,得到注意力向量,通过softmax层对上述结果归一化,得到最终的注意力得分,如下所示:
通过像素乘操作,使得网络学习不同的特征权重.将上下文注意力特征聚合到每一个位置上,得到上下文注意力特征作用于特征图的结果.为了保留更多的空间细节信息,与原始特征图通过像素加操作进行不同层次的特征融合,得到特征向量fs.风格编码器将256×256×1维度的输入图像映射到1×1×256维度的特征层空间,得到对应的风格特征向量.
解码器的输入只进行反卷积操作,中间每层卷积层的结构为Deconv-IN-Relu,Deconv表示反卷积,最后一层进行反卷积操作.使用Tanh激活函数,解码器中的卷积核为4,步长为2,卷积核数依次为512、512、512、512、256、128、64、1.
考虑到生成的图像与内容编码器的输入图像的结构相似,解码器中使用跳跃连接,保留图像的不同尺度信息,将内容编码器中的不同特征层按照通道维度拼接到解码器对应的相同分辨率位置.通过将底层信息连接到对应的解码器层,最大程度地保留图像的底层信息,减少解码过程中位置和结构特征信息的丢失.
2.2 判别器的结构
在原始的zi2zi训练过程中,生成器与判别器的损失振荡比较明显,训练不稳定,判别器不能有效地指导生成器训练收敛.在判别器中,将实例归一化替换为谱归一化层(spectral normalization,SN),解决生成对抗网络训练不稳定的问题,加快模型收敛.
判别器的网络结构如图2(b)所示,由5层卷积层组成.前4层结构由Conv-SN-Lrelu单元堆叠而成,其中卷积核为4,步长依次是2、2、2、1,卷积核数依次是64、128、256、512;最后一层为卷积核为4、步长为1的卷积操作.
2.3 损失函数的设计
zi2zi网络损失函数包括对抗损失、像素损失、类别损失与一致性损失.利用改进的网络模型,增加了边缘损失,提高了生成字体轮廓的清晰度.对抗损失函数使得模型的生成结果尽可能与目标风格书法字逼近.在训练过程中,判别器D与生成器G需要最小化对抗损失函数.
式中:m、y分别表示源风格与生成的风格字体图像.
像素级损失函数采用L1范数计算图像之间的损失,如下所示:
式中:pdata为 目标图像域,pinput为源风格输入图像域.
风格类别损失函数通过优化损失函数,使得生成汉字的类别一致.
式中:x为目标风格图像,c为风格类别标签.
内容一致损失通过对源图像和生成图像内容编码,计算两者一致性损失,避免信息丢失,使得解码器尽可能地恢复正确的汉字.
式中:φ表示对源字体和生成字体编码,pgener为生成图像域.
与字体图像的背景及填充字体图像的像素相比,汉字边缘像素在决定汉字风格和语义信息时占有较大的比重,因此额外引入边缘损失来约束模型,生成更加清晰的轮廓.利用Canny算子提取边缘特征,用L1范数逐像素计算生成图像与真实图像的边缘像素:
式中:C为Canny算子.
最终生成器与判别器的目标损失函数如下所示:
式中:λL1、λstyle、λconst、λedge为对应损失函数的权重系数.通过设置不同的权重来平衡不同损失函数在目标损失函数中的权重,经过多次实验依次设置为100、1、15、100.
3 实验结果与分析
3.1 实验环境
实验环境为Ubuntu 18.04 LTS 64-bit操作系统,显卡为NVIDIA RTX 3060,基于深度学习框架pytorch,编程语言为python3.8.实验参数的设置如下:批处理大小batch size为16,迭代轮数为50,优化器为Adam优化器,参数β1=0.5,β2=0.999.初始学习率为0.001.在训练过程中,判别器先训练,生成器通过判别器的反向传递更新参数,交替训练.每迭代20轮学习率衰减为原始的一半,后面逐步衰减到0.000 2并不再变化.
3.2 数据集
针对手写体生成图像,目前没有公开的数据集.本文的目标风格图像为颜真卿楷书及赵孟頫行书风格的书法字体图像,从书法图像字库中爬虫获取,源风格字体为黑体,使用python中的Imagefont转换为字符图像.训练样本数开始设置为1 000,样本量较少导致过拟合;后面逐渐增加训练样本数,提升了模型性能,解决了过拟合的问题,且当数据量为3 000~4 000时模型性能稳定.随机选择4 413张颜真卿楷书作为训练图像,1 004张颜真卿楷书作为测试图像.赵孟頫行书的训练图像为3 861张,测试图像为1 060张.训练图像与测试图像中的汉字字符各不相同,数据集的样例如图5所示.在实验中,数据集采用单通道图像,大小均为256像素×256像素.

图5 自建的2种数据集样例Fig.5 Self-built samples of two datasets
3.3 评价指标
从主观和客观这2个方面对生成结果进行评价,其中客观评价指标包括峰值信噪比(peak signal-to-noise ratio, PSNR)、结构相似性(structural similarity index, SSIM)[18]、感知相似性(learned perceptual image patch similarity, LPIPS)[19].其中SSIM与PSNR越大表明生成效果越好,LPIPS越小,生成图像与目标图像越相似,更符合人类的视角.
3.4 实验结果与分析
为了验证提出方法的有效性,设计消融实验,分析不同模块对实验结果的影响.为了进一步比较改进算法的生成效果,选择CycleGAN、Dense-Net CycleGAN、zi2zi、EMD[20]、CalliGAN、LFFont、MXFont算法作为对比算法,比较不同算法的生成结果,验证不同源字体对改进算法生成效果的影响.
3.4.1 消融实验 为了验证残差单元、风格编码分支及边缘损失的有效性,依次在基本模型中添加不同模块,不同模块生成颜真卿楷书、赵孟頫行书的结果分别如图6、7所示,对应的评价指标如表2、3所示.图中,实线矩形框表示字体生成结构较差,虚线矩形框表示字体风格不佳,圆圈框表示书法字的边缘结构较差.
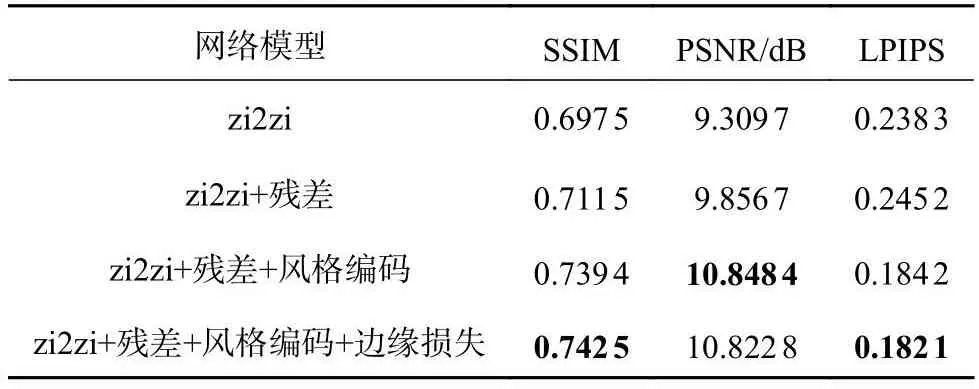
表2 消融实验的评价指标(目标字体:颜真卿楷书)Tab.2 Evaluation index of ablation experiment (target font:Yan Zhenqing regular script)

图6 不同模块的消融实验(目标字体:颜真卿楷书)Fig.6 Ablation experiments of different module (target font: Yan Zhenqing regular script)
从图6可以看出,zi2zi生成字体存在笔画不连贯缺失、粘连,如“仄”、“宗”字笔画缺失,后3个字出现笔画粘连.加入残差单元,生成字体的细节明显有所改善,减少了字体笔画缺失、模糊不清的情况,能够有效地提高模型的性能.比较3、4行有无风格编码的生成结果可以看出,添加风格编码使得生成字体的风格特征更加接近目标风格,如“仄”、“旬”字.边缘损失的对比结果如第4、5行所示,未使用边缘损失的笔画轮廓扭曲,如“仄”字的笔画“捺”、“旬”字的笔画“撇”、“英”字的笔画“捺”等.第5行生成字体的结构更加完整.笔画线条显得“遒劲有力”,笔画位置的关系更加准确,更加符合书法艺术字的特点.实验结果表明,本文算法的不同模块对于提高生成效果是至关重要的.
比较表2的实验结果,依次在原有模型上使用不同的结构,评价指标有所提高.与原始zi2zi相比,SSIM、PSNR分别提升了4.50%、1.51 dB,LPIPS降低了5.62%,证明能够提高模型性能.
从图7可以看出,原始模型生成的书法字笔画较粗,字体风格与目标风格相差较大.笔画结构的错误较多,如“印”字不连贯,“炸”字粘连,“元”字出现多余的笔画.残差单元能够减少笔画缺失、错连,如“印”、“元”字.对比3、4行可以发现,加入风格编码,能够明显地改善字体的风格.从表3可知,SSIM、PSNR分别提升了6.89%、2.41 dB,LPIPS降低了6.68%.对比第4、5行的结果可以看出,边缘损失进一步提升了字体结构轮廓,验证了边缘损失的有效性.表3的结果表明,利用本文算法中的不同结构,能够提升各项指标,与原始zi2zi相比,SSIM、PSNR分别提升了7.48%、2.36 dB,LPIPS降低了7.95%,模型性能有所提升.

表3 消融实验的评价指标(目标字体:赵孟頫行书)Tab.3 Evaluation index of ablation experiment (target font:Zhao Mengfu running script)

图7 不同模块的消融实验(目标字体:赵孟頫行书)Fig.7 Ablation experiments of different module (target font: Zhao Mengfu running script)
3.4.2 与其他算法的对比实验 利用本文算法与CycleGAN、DenseNet CycleGAN、zi2zi、EMD、CalliGAN、LFFont、MXFont算法生成颜真卿楷书、赵孟頫行书的结果分别如图8、9所示.不同算法在同一实验平台中完成,采用相同的数据集及评价指标.设置相同的初始参数与优化器,其中不同的是LFFont与MXFont算法使用不同的学习率训练生成器与判别器.为了合理地评估算法的性能,在对比实验中保持原算法的参数设置,生成器的学习率设置为0.000 2,判别器的学习率设为0.000 8.

图8 不同算法的生成结果(目标字体:颜真卿楷书)Fig.8 Results generated by different algorithms (target font: Yan Zhenqing regular script)
图8中,CycleGAN和DenseNet CycleGAN算法的生成效果最差,完全没有学习到目标风格样式,甚至丢失字体的笔画结构,可读性差.原始的zi2zi结构损坏,部分笔画存在扭曲的现象,同时笔画不连贯缺失,粘连的现象较严重.EMD方法具备内容编码与风格编码的结构设计,不同的是EMD在内容编码与风格编码时都只用普通的卷积结构去提取特征,生成的字体辨识度极低.CalliGAN生成的字体结构基本完整,可以学会目标字体的风格,但生成的字体图像模糊,产生较多的噪点,辨识度低,边缘结构不清晰.LFFont容易出现结构变形,如“用”、“胄”.MXFont生成的图像质量较高,但该模型的性能不稳定,部分字体结构丢失,如“崽”、“巡”.利用本文算法缓解了笔画丢失的问题,生成的字体图像几乎没有变形,可读性高,字体的位置关系相对准确,分布一致,更加接近目标字体.实验结果表明,本文算法的生成效果主观上优于其他7种算法.
与笔画较工整的楷书相比,行书字体形态丰富,书写更加灵活,结构更加不规则,因此生成任务更加困难.图9中,CycleGAN和DenseNet Cycle-GAN生成的字体笔画丢失,辨识度低.利用原始zi2zi算法生成的行书字体笔画粘连严重.EMD生成的字体难以辨认,丢失汉字结构和笔画细节的信息.CalliGAN生成的字体噪点较多,字体扭曲.LFFont容易出现结构丢失,如“圯”.MXFont生成的字体可识别性较高,但整体上笔画较粗,与目标风格字体有差距,利用本文算法生成的字体图像清晰,风格与目标字体最接近.

图9 不同算法的生成结果(目标字体:赵孟頫行书)Fig.9 Results generated by different algorithms (target font: Zhao Mengfu running script)
基于SSIM、PSNR和LPIPS评价指标分别对不同风格书法字的生成结果进行定量分析比较,评价结果如表4、5所示.

表4 不同算法的评价指标(目标字体:颜真卿楷书)Tab.4 Evaluation indexes of different algorithms (target font:Yan Zhenqing regular script)
表4中,利用本文算法生成颜真卿楷书的SSIM、PSNR分别比zi2zi高5.21%、1.57 dB,LPIPS比zi2zi低4.21%,SSIM、PSNR指标均高于对比算法,LPIPS指标均低于对比算法.表5中,利用本文算法生成赵孟頫行书的SSIM、PSNR分别比zi2zi高6.91%、1.76 dB,LPIPS比zi2zi低6.20%.本文算法的3种评价指标均优于其他算法,证明了算法的可行性与可靠性.
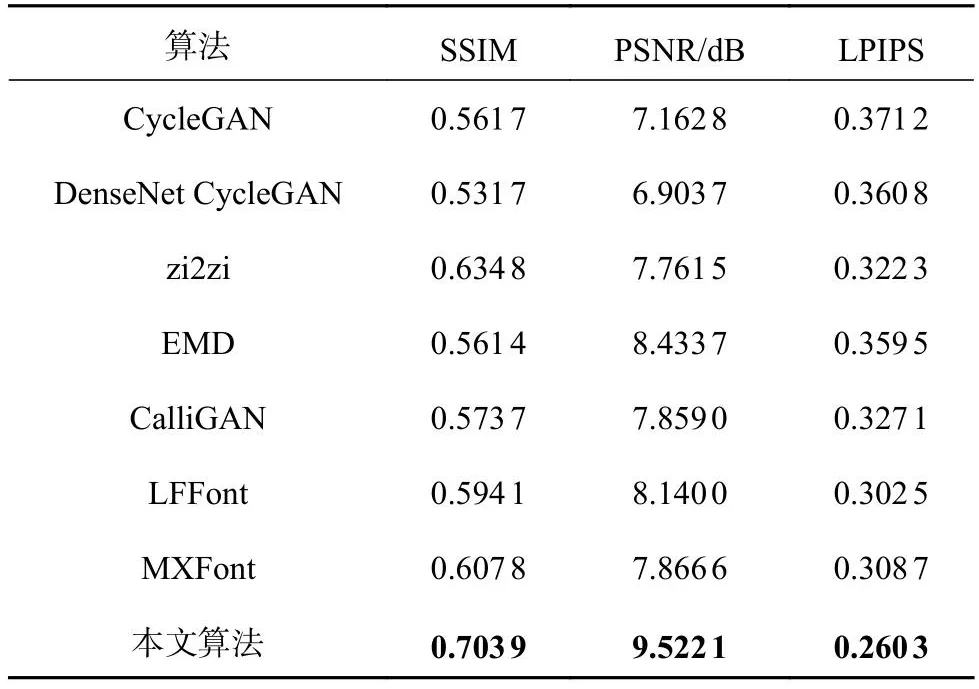
表5 不同算法的评价指标(目标字体:赵孟頫行书)Tab.5 Evaluation indexes of different algorithms (target font:Zhao Mengfu running script)
3.4.3 不同源字体的生成结果 上述实验均以黑体作为源字体,为了验证不同源字体的生成效果,分别采用楷体与宋体作为源字体进行实验.本文算法的生成效果如图10、11所示,评价指标如表6所示.

表6 不同源字体生成目标字体的评价指标Tab.6 Evaluation indexes of target font generated by different source fonts

图10 源字体为楷体的结果Fig.10 Results of source font in simkai

图11 源字体为宋体的结果Fig.11 Results of source font in simsun
图10、11中,利用本文算法生成的目标字体结构完整,细节鲜明,清晰度高,且风格与目标风格接近.从表6可知,改变源字体,评价指标SSIM与LPIPS波动幅度不超过3%,PSNR不超过0.6 dB,证明了本文算法的鲁棒性与普适性.
3.4.4 模型稳定性的分析 为了稳定模型训练,加速训练过程,在判别器中将实例归一化替换为谱归一化层.zi2zi算法与本文算法训练过程中的损失曲线变化如图12所示.图中,I为训练次数,LD、LG分别为判别器损失与生成器损失.相比于原始模型,本文算法的损失曲线更加稳定,振幅较小,收敛速度比原模型快.
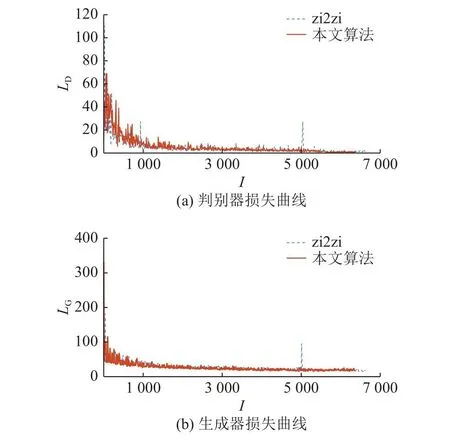
图12 训练过程的损失曲线图Fig.12 Loss curves of training process
4 结 语
本文提出基于改进生成对抗网络的书法字生成算法,有效提升了书法字的生成效果.在网络结构设计中,以zi2zi为基础网络,通过设计编码器结构,增强了网络的特征提取能力;通过添加上下文感知注意力模块,显著提升了生成书法字的风格效果.在模型训练中,设计损失函数进一步提升了生成字体的结构完整性,利用谱归一化增强了模型的训练稳定性.通过自建2种不同书法字体的数据集,验证了本文算法的有效性.实验结果表明,利用提出算法生成的字体细节清晰,结构完整,字体风格更加逼真,字体图像质量高.利用本文方法生成的颜真卿楷书与赵孟頫行书的PSNR分别达到10.63、9.52 dB,SSIM分别达到0.724 9、0.703 9,LPIPS分别达到0.186 8、0.260 3,生成效果较对比算法有明显的提升.本文算法生成的是单一风格字体,在接下来的研究工作中将优化模型,实现一对多风格的生成,增加模型的多样性.
猜你喜欢
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16
学生天地(2020年14期)2020-08-25
娃娃乐园·综合智能(2020年2期)2020-03-12
小天使·二年级语数英综合(2018年10期)2018-10-15
成都信息工程大学学报(2018年3期)2018-08-29
创新作文(小学版)(2017年5期)2017-05-13
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
小雪花·成长指南(2014年10期)2014-10-31
电测与仪表(2014年13期)2014-04-04
