
基于虚拟仿真与深度强化学习的作业车间集成调度
2023-08-22 07:47李昊谦
实验室研究与探索 2023年5期
王 亮,李昊谦,唐 堂,于 颖
(同济大学机械与能源工程学院,上海 201804)
0 引 言
在深度学习、强化学习、数字孪生技术等先进技术的支撑下,智能制造产业获得了蓬勃的发展。越来越多的高校新增智能制造工程专业以培养可满足新工科需求的创新性人才[1-2]。作业车间调度问题(Job-Shop Scheduling Problem,JSP)是根据生产车间的产品数据、加工数据、物流信息、生产调度和资源管理等信息进行整合,使车间可充分利用现有生产资源,合理分配生产工序,减少生产时间,优化生产目标。作业车间生产过程的不确定性、复杂性以及多资源相互协调等特点对生产排程优化提出了新的挑战,是智能制造中广泛研究的问题之一。
Plant Simulation作为一款生产系统仿真软件,可很好地进行生产模拟,辅助排程计划的制定。国内外学者也对其开展了大量研究。Guo等[3]提出一种基于工序编码方式在Plant Simulation仿真平台解决车间作业排序问题的优化设计方法,并运用传统的遗传算法对此类问题进行仿真优化。Xiu 等[4]利用Plant Simulation 仿真软件中的统一建模语言(Unified Modeling Language,UML)映射对作业车间调度仿真优化系统进行分析,并使用遗传算法对其模型参数进行优化,得到理想的调度方案。Tang 等[5]提出一种将Plant Simulation仿真模型嵌入遗传算法的联合求解批量调度的方法,该方法可缩短生产周期,提高设备利用率,更加适用于工业实际问题。Tian 等[6]研究了在Plant Simulation 建立仿真模型的关键技术,利用优化模块中内置遗传算法来优化作业车间调度,保证决策的科学性。Hugo 等[7]提出一种DFWA-VNS 算法,结合Plant Simulation平台解决JSP 问题。文笑雨等[8]基于Plant Simulation构建作业车间生产的不确定调度仿真模型,利用遗传算法对该模型进行求解。实例仿真说明方案能够有效降低不确定加工时间和随机机器故障对车间生产调度的影响。
此外,求解JSP需要有效的方法,比如精确计算、启发式算法与强化学习算法等。其中强化学习有着求解速度快、结果优异且稳定的优点,吸引了广大学者的探讨。Thomas等[9]将作业车间调度问题转为由智能体处理的顺序决策问题并使用各种确定的和随机的作业车间调度基准问题验证了方法的有效性。Li 等[10]提出一种基于深度Q 网络的深度强化学习算法。该方法结合了深度神经网络的学习能力与强化学习的决策能力,获得每个时间节点的最佳调度规则。Liu等[11]提出一种策略网络和评价网络并行训练方法,以简单的调度规划作为智能体动作,可有效求解基准JSP问题的静态与动态调度。Park 等[12]提出一个框架,使用图神经网络和强化学习来求解作业车间调度问题。文献[13-14]中设计了一个强化学习和仿真相结合的动态实时车间作业排序系统。
本文提出一种基于Plant Simulation的深度强化学习(Plant Simulation based Deep Reinforcement Learning,PSDRL)算法,用来求解作业车间调度问题,实现对车间生产排程计划的快速响应与优化。在近端策略优化(Proximal Policy Optimization,PPO)的强化学习算法的基础上,以Plant Simulation 平台搭建虚拟车间作为强化学习环境,优化每个时刻的可行工序选取策略,快速制定一个最小化完工时间的排程计划。本文旨在通过强化学习算法及离散事件虚拟仿真的集成,实现先进技术的综合应用,以新的实践教学方式激发学生的学习兴趣,并提高学生对智能制造生产与技术的认识。
1 问题描述与基本架构
作业车间调度问题是经典的组合优化问题,要求给定的一组工件J=1,2,…,n在一组机器M=1,2,…,m上加工完成,满足以下约束条件:
(1)每个工件在机器上的加工工序确定。
(2)每台机器在同一时刻只加工一个工件,工件加工时间是固定的且工序一旦开始不能被中断。
(3)每道工序必须等到其前置工序加工完毕后才能开始加工。
本研究中的PSDRL算法整体框架图如图1 所示,包括Plant Simulation仿真平台、案例信息、评价、动作等要素。策略网络每次会去读取案例的状态信息与奖励值,同时评价网络会去评判状态的好坏,并将这些信息存储到记忆库,以便后续更新参数使用。在该算法中智能体需要执行完一次完整流程后才会进行参数更新,每一步得到的奖励值都是真实观测到的值,价值函数不再具有预测功能。此外为增加算法的鲁棒性与泛化性,每次智能体需同时完成多个案例的生产排程计划,将所有案例的状态信息整合后完成一次神经网络的参数更新。
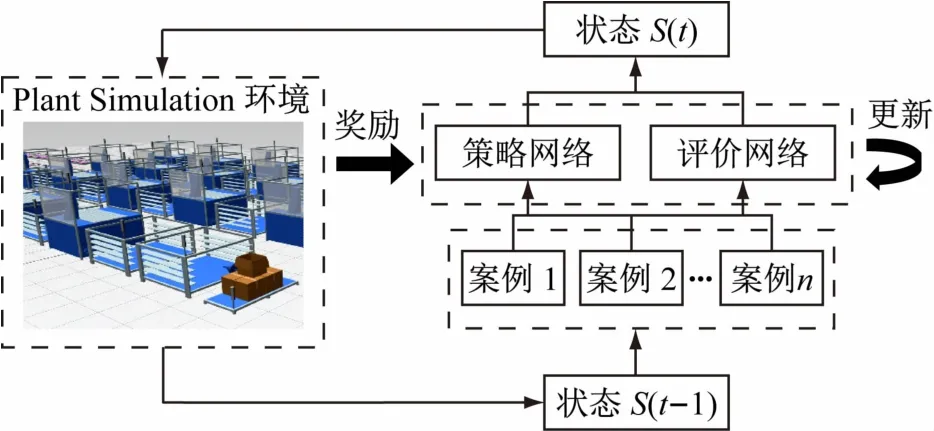
图1 PSDRL训练流程示意图
2 基于Plant Simulation 平台的强化学习环境构建
PSDRL环境是依靠Plant Simulation 搭建的,仿真平台可构建一个JSP 案例,以模拟车间的运行情况。Plant Simulation 平台自带遗传算法来优化生产排程,但由于其性能与局限性无法满足复杂车间排程需求,需引入其他算法以提升车间排程的质量与速度。
基于Plant Simulation 的强化学习环境主要由算法-环境通信部分、逻辑控制区、机器模型区与工件信息区组成。
本文采用套接字(Socket)作为算法与虚拟仿真环境的通信手段,以Python 的强化学习算法作为客户端,虚拟仿真环境作为服务端。要实现服务端与客户端之间的通信,需要在虚拟仿真环境服务端中打开socket对象的通信开关,如图2 所示,点击on 的复选框,并设置通信协议、通信地址及端口。由于socket通信只允许调用同一个函数,所以可设计一套标识符,实现工件加工信息导入、生产排程计划导入与奖励值返回这一套完整运行流程。
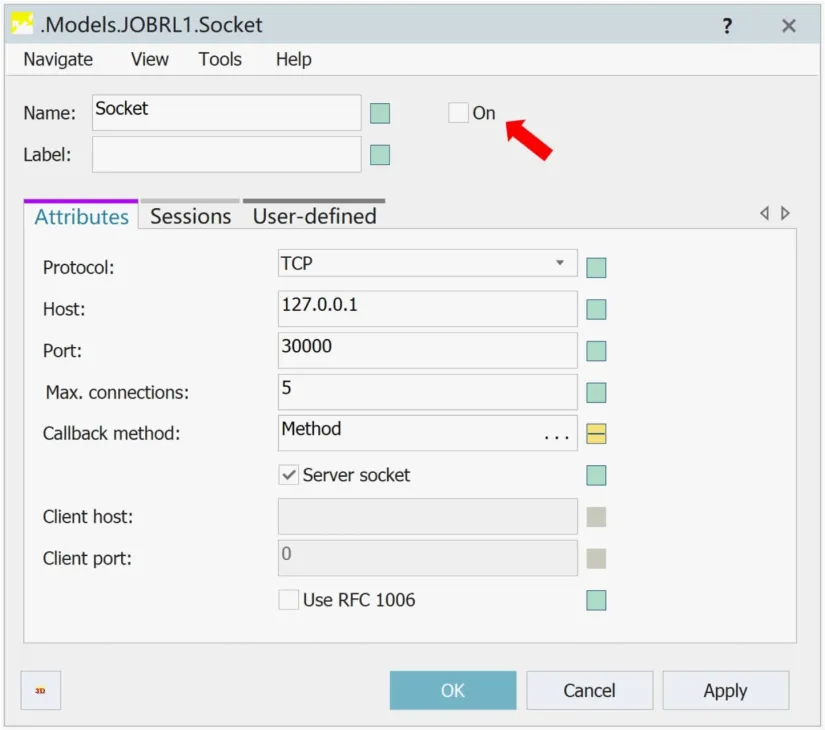
图2 Socket通信对象设置界面
逻辑控制区主要功能有:根据客户端生成的案例大小自适应生成相同规模的车间机器模型;将工件信息区的数据生成加工信息表;控制整个仿真系统的运行逻辑,保证生产调度的平稳进行。逻辑控制区如图3 所示。

图3 虚拟环境的逻辑控制区
机器模型区如图4 所示,是仿真运行的载体,其中包含物料生成对象、零件暂存区、机器设备、物料输出区。机器设备根据机器加工顺序表,同时依照逻辑控制区的调度规则,以实现模拟车间的生产流程的目的。

图4 虚拟仿真环境的车间机器模型区
工件信息区如图5 所示,该区域使用表格对象分解记录由算法客户端传送过来的等待加工工件信息及相应的工艺信息。加工信息包含工件的工序加工顺序、加工时长以及对应的加工机器序号。工件信息区在得到客户端传来的案例信息后等待逻辑控制区的初始化加工信息函数将其变为加工信息表,用以仿真环境的初始化。

图5 虚拟环境的工件信息区
3 基于Plant Simulation 仿真环境的深度强化学习算法
本文采用强化学习算法为PPO算法,其为目前效果最好的强化学习网络构型,包含了动作选择的策略网络和状态评价的价值网络,在训练过程中,依据奖励值与价值函数的误差不断迭代更新网络参数。包括强化学习算法的客户端读取案例信息并将信息传输给虚拟仿真环境,仿真环境生成加工信息表与机器模型。算法客户端会根据强化学习的调度策略生成工件生产计划,并将其发送给虚拟仿真环境。虚拟仿真环境作为强化学习中智能体交互环境的一个重要组成部分,用以验证动作策略给出的生产排程计划的有效性并记录下执行每个动作产生的奖励值,并将其返回给强化学习算法,完成一次策略参数的更新,直到到达最大迭代次数结束训练,最终生成一个良好的调度策略网络。可更加快速、稳定地得到案例优良的调度方案。
3.1 环境状态与动作空间
环境状态的定义是强化学习算法的基础。为表达JSP车间的环境状态,使用析取图进行表征。析取图存储信息的主要方式是节点信息与节点之间的邻接关系。
表达节点信息的节点特征为
式中:n为工件数;m为机器数;feature 为工序此刻的最长完工时间;mask为该工序是否完成加工。
表达工序节点间的加工顺序的工序邻接矩阵
式中:(vi,vj)为节点i与节点j之间的连线;E为析取图中边的集合。如果节点间具有邻接关系则adj相应位置置1,否则置0。之后使用图神经网络对析取图中包含的状态信息进行特征提取,完成状态的预处理。
强化学习智能体的动作集合在本系统中定义为强化学习策略网络在根据当前车间状态,判读出的可进行调度的工序序号合集。可进行调度的工序是指所有工件待加工工序中的第一个,该集合大小
式中,nmax为状态St时依然未完成全部加工工序的工件数,动作空间将随着工件工序的不断完工而减小。强化学习通过选择合适的工序将其排入生产计划表,其主要由随后动作选择的策略网络再根据ε-贪心算法,以一定概率ε从动作集合中随机选择动作,以1-ε概率选择奖励值最大的动作。
3.2 控制目标与奖励函数
本算法的目标是优化生产排程计划,使得案例中所有的工件最长完工时间(makespan)最小化。从生产排程计划来看,想要更短完工时间,需要提高机器设备的利用率,缩短机器的空闲等待时间,强化学习在选取加工工序时,应趋向于选择加工时间更长的工序,同时让最长完工时间更短。本研究中将奖励值定义为t时刻状态St下执行工序后的最长完工时间与执行此工序前的t-1 时刻状态St-1下的最长完工时的差值的负值,奖励值
譬如当执行工序后,此时最长完工时间等于未执行工序前案例的最长完工时间时,奖励值则为0,其余情况下均为负值。此外需要说明的是奖励值是从Plant Simulation仿真环境中获取的。
4 实验设计
为表明Plant Simulation虚拟仿真与深度强化学习集成优化算法的性能,选取经典的JSP 算例之一Taillard算例参与算法试验,包括ta10、ta20、ta30、ta40共4 种案例[15]。并与经典优先调度规则最短加工时间(Shortest Processing Time,SPT)、深度Q 网络(Deep Q-network,DQN)与遗传算法(Genetic Algorithm,GA)进行对比实验。在训练开始前,需设置实验的案例工件数、机器数以及强化学习网络初始参数。本研究中的PSDRL算法的训练参数如下:训练次数2 000 次、网络层数3、输入维度2、输出维度32、学习率2 ×10-5、ε取0.2。每个算法对于每个案例独立计算10次makespan并取平均值记为Aavg,同时运行时间记为tavg。实验结果见表1,其中:n为案例的工件数,m为案例的机器数,Cb为案例的已知最优解。

表1 实验结果对比
由表1 可见,虚拟仿真与深度强化学习集成优化方法综合来说优于对比算法。PSDRL 计算的makespan虽然无法到达案例的最优值,但是平均相差在30%左右,且高于其他的对比算法,是可用于车间的生产排程。同时该算法还具有运行速度极快,其计算速度远远高于GA 算法,且优于SPT 与DQN 算法,这让PSDRL具有快速应对动态事件的性能。
5 结 语
本文提出一种求解作业车间调度问题的基于Plant Simulation的深度强化学习算法。该算法通过图神经网络提取车间状态析取图的特征,以虚拟仿真平台搭建模拟车间,实现强化学习算法与虚拟仿真环境之间的交互,获取动作奖励值来更新动作选择策略网络与状态评价网络的参数,不断优化智能体的选择策略。通过对4 个经典算例的求解,说明了PSDRL 算法的有效性。可基于Plant Simulation构建虚拟仿真平台为智能制造工程或工业工程等专业的实验教学提供与时俱进的教学手段,激发学生的学习兴趣,并对提高实践教学质量起到了积极作用。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
智能制造(2021年4期)2021-11-04
石材(2020年4期)2020-05-25
建材发展导向(2019年10期)2019-08-24
制造技术与机床(2019年7期)2019-07-22
小学生学习指导(中年级)(2018年11期)2018-11-29
农村农业农民·B版(2018年11期)2018-01-28
智能建筑与智慧城市(2017年2期)2017-03-08
中国老区建设(2016年12期)2017-01-15
工程建设与设计(2016年1期)2016-02-27
