
基于强化学习的工业机械臂数字孪生与智能控制
2023-08-21 08:43王子琪严知宇王正方
科技创新与应用 2023年23期
王子琪,严知宇,武 辰,王正方*
(1.山东大学 控制科学与工程学院,济南 250003;2.山东大学 物理学院,济南 250003;3.山东大学 能源与动力工程学院,济南 250003)
如今,在中国制造2025 背景下,智能制造工程备受关注,数字孪生技术也正在成为受到关注和重视的工业热点话题,聚焦到工业机械臂问题上,在现实工业机械臂的应用中,示教法是大多数企业对于机械臂采用的控制方法。
当前数字孪生技术已经趋于成熟,在各个领域广泛适用且效果良好。由于数字孪生技术具有多物理、多尺度、多学科属性,因而能够实现物理空间与信息空间交互与融合[1]。在数字孪生技术发展方面,Li 等[2]基于几何、物理和顺序规则描述构建了一个多源模型驱动的数字孪生系统,用于对机器人装配系统进行精确的实时仿真。Malik 等[3-5]通过案例演示,探索了数字孪生在解决复杂协作生产系统中的应用。李浩等[6]对面向人机交互的数字孪生系统特征进行分析,提出了人机协作的安全控制技术以及孪生系统的态势感知和监测预警解决方案。鲍劲松等[7]面向人-机-环境共融的数字孪生协同技术,从环境和任务2 个核心来展开数字孪生协同的人机共融科学问题。在数字孪生技术应用方面,陶飞等[8]在数字孪生车间基础上探讨了基于车间孪生数据的车间物理世界和信息世界的交互与共融理论和实现方法。林润泽等[9]依托智能工厂流水线实验装置,构建了智能装配机械臂数字孪生实验系统,提出了一种基于多模型融合的数字孪生系统模型集成方法。
针对传统机理模型的非线性、不确定性问题,本文采用一种基于数字孪生技术的工业机械臂控制方法及系统,通过构建机械臂的数字孪生体实现对工业机械臂的实时、自动化智能控制。
1 工业机械臂的数字孪生体建模
1.1 Aubo-i10 工业机械臂的结构与参数
对Aubo-i10 工业机械臂进行建模,该机械臂的结构如图1 所示。
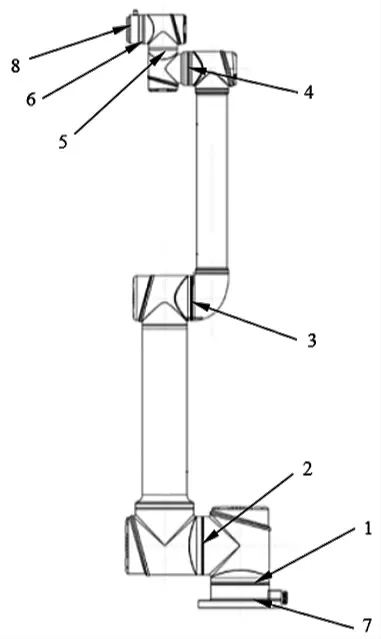
图1 Aubo-i10 工业机械臂的结构
该机械臂包括6 个旋转关节、5 个从动部件、基座和工具端。其中,每个旋转关节表示一个自由度,包括基 座关节1、肩部关节2、肘部关节3、第一腕部关节4、第 二腕部关节5 和第三腕部关节6;每2 个关节之间设有1 个由转动带动的部件即从动部件,共5 个从动部件,基座关节1 和肩部关节2 之间设置第一从动部件,肩部关节2 和肘部关节3 之间设置第二从动部件,肘部关节3 和第一腕部关节4 之间设置第三从动部件,第一腕部关节4 和第二腕部关节5 之间设置第四从动部件,第二腕部关节5 和第三腕部关节6 之间设置第五从动部件;除此以外,该工业机械臂还包括基座7 和工具端8,基座与基座关节1 连接,用于机械臂本体和机器人底座连接,工具端与第三腕部关节6 连接,用于机械臂本体与工具连接。
1.2 数字孪生体的建模
以上述六自由度工业机械臂为基础,利用数字孪生技术构建工业机械臂的数字孪生体模型,如图2 所示,该数字孪生体模型包括6 个旋转关节和5 个从动部件,以及固定的基座和机械臂末端的工具端,设置旋转关节和从动部件之间的父子逻辑关系。

图2 Aubo-i10 工业机械臂的数字孪生体
上述父子逻辑关系是指,当设置一个物体为另一个物体的子对象时,该物体即为子物体,另一个物体为父物体,子物体随着父物体的转动变化而变化,相对点位置不发生改变,而子物体转动变化时父物体并不主动跟随发生改变。一个父物体可以有多个子物体,但一个子物体只能有一个父物体,子物体可以再成为其他物体的父物体。
数字孪生体模型上述11 个部件(6 个旋转关节和5个从动部件)分别两两构成父子逻辑关系,具体为基座关节1 和第一从动部件为父子逻辑关系、第一从动部件和肩部关节2 为父子逻辑关系,以此类推,最终,基座关节1、第一从动部件、肩部关节2、第二从动部件、肘部关节3、第三从动部件、第一腕部关节4、第四从动部件、第二腕部关节5、第五从动部件和第三腕部关节6 按顺序依次两两构成父子逻辑关系。此外,该工业机械臂还包括基座和工具端,基座和基座关节1 构成父子逻辑关系,第三腕部关节6 和工具端构成父子逻辑关系。
在上述建模过程中,使用的数据参数还包括:基于工业机械臂的实际参数,设置该模型的基本参数,包括关节灵敏度、关节活动范围(在本实施例中为-175~175°)、各关节的线性速度和加速度的上限等,保证该数字孪生体模型的运动轨迹更贴近实际工业机械臂的运动。
2 实时数据的采集与传输
Modbus[10]是一种串行通信协议,其已经成为工业领域通信协议的业界标准(De facto),并且现在是工业电子设备之间常用的连接方式。允许多种电子接口,属于一种一主多从的通信协议。选择Aubo-i10 作为主机,Unity3D 平台中的数字孪生体作为从机。使用基于Socket 的Modbus-TCP 通信建立连接。在通信过程中,通过C#代码控制Aubo-i10 的运动,同时将运动参数发送至Unity3D 平台。在Unity3D 平台中的数字孪生体中,进行强化学习后得到最优参数,再返回至Aubo-i10实体。
3 数字孪生体的学习训练
强化学习是一种针对不同的agent(代指数字孪生体)采取相应动作的机器学习方法。动作at∈A 是基于状态st∈S 和当时的环境t 做出的选择,其中动作空间A 是给定环境中所有有效操作的集合,并且S 是一组状态,针对不同的选择,agent 会收到不同的奖励Rt,这取决于其导致下一状态的行为的影响st+1∈S,选择行动的策略称为策略π。agent 的目标是学习最优策略,即从长远来看使累积奖励最大化的策略。该原理基于马尔可夫决策过程(MDP)模型,该模型依赖于描述过程记忆缺失的马尔可夫特性,即未来状态的概率st+1 仅取决于当前状态和操作st和at而不是基于过去的状态和行为。
3.1 强化学习算法的选择
强化学习算法主要分为基于价值的算法和基于策略的算法。基于价值的方法通过优化动作值函数来确定强化学习算法的最优策略。基于策略的算法不是价值函数的近似,而是使用基于梯度的方法直接近似策略,因此是学习最优策略的更直接的方法。使用这类方法的算法包括普通策略梯度算法(VPG)、可信区域策略梯度算法(TRPO)和近端策略优化算法(PPO)。
这3 种算法具有相同的操作原理,但PPO 使用的技术解决了其他方法的一些缺点,如方差问题和计算复杂性。在基准任务集合上的PPO 方法优于TRPO 和VPG,并且更容易实现。
鉴于以上提出的与使用基于值的算法相关的各种缺点,本项目决定使用PPO 算法对数字孪生体进行学习训练。
3.2 PPO 算法的原理
PPO 算法是在TRPO 算法(PG 系算法)基础上进行的改进。TRPO 算法的每次迭代都尝试从当前的策略中选择一个合适的步长,使新策略得到的累计回报单调递增,其目标函数如式(1)所示
式中:Aπθ(st,at)=Qπθ(st,at)-Vπθ(st)是优势函数是重要性采样权重,πθ~(at|st)表示新策略的概率分布,πθ(at|st)表示旧策略的概率分布,st表示当前状态,at表示当前所采取的动作,π 表示策略,为关于状态s的函数,且在深度强化学习中,策略π 由神经网络构成,神经网络的参数为θ,表示为πθ,KL 表示KL散度。
在强化学习中,用π 表示策略,表示在当前状态下机械臂(agent)从动作(action)集合中选择一个动作的概率分布,进而期望存在函数f,当输入目前的状态(state)时,输出策略π,获取机械臂(agent)的下一步动作(action),即π=f(state)。若agent 的action 能够促进agent尽快到达目标值的动作,则需要增加这个action 获得更多被选择的几率,即增大奖励(reward);反之,则这个action 被选择的几率将会减少,即减少奖励(reward)。在以此构建的神经网络模型的基础上,估算出动作(action)的期望收益,通过上述目标函数求解更新模型的参数θ,使得期望收益更高,输出机械臂动作。
为了控制策略的更新幅度,PPO 算法采用了截断的代理目标函数,实现重复性采样,加快训练速度。该算法将新旧策略的比值kt(θ~)限制在一个区域中,通过控制区域的大小来限制更新的步幅。相比TRPO 中使用KL散度进行限制,PPO 中kt(θ~)的限制更加简单,也更容易实现。PPO 算法的目标函数如式(2)所示
PPO 算法还运用了优势函数估计方法和增加额外熵奖励的优化方法来进一步提升其性能。使用泛化优势估计构造优势函数能够降低方差,使算法不会产生较大的波动。泛化优势估计GAE 的计算式如式(3)所示
式中:δt=rt+γV(st+1)-V(st)。
将PPO 算法应用在策略和值函数共享参数的网络结构上时,除了截断回报之外,目标函数还加上了关于值函数估计的误差项以及策略模型的熵正则项,用于鼓励探索。因此,优化后的目标函数如式(4)所示
式中:c1和c2为2 个常数超参数;c1(Vθ(s)-Vtarget)2是状态值函数的均方误差,误差越小越好;H(s,πθ)表示策略πθ的熵值,熵越大越好。
利用PPO 算法,基于上述优化后的目标函数不断进行迭代,最终能够快速完成训练并输出机械臂当前状态下最优的策略,根据该策略执行相应的动作,通过自学习规划出数字孪生体模型运动的最优轨迹。
4 结束语
本文提出了一种基于数字孪生技术的工业机械臂控制方法,应用数字孪生技术构建机械臂的数字孪生体,连接数字世界和物理世界,使得物理对象与虚拟对象之间实现上下行的物理信息数据交互,解决传统机理模型无法解决的非线性、不确定性问题,大大提高了机械臂的实时性和泛化能力。通过强化学习训练使机械臂实现自学习自适应转动,解决传统机械臂运动过程不连续问题,实现对机械臂的智能控制,提高自动化程度和工业生产效率。
猜你喜欢
中老年保健(2021年5期)2021-08-24
中老年保健(2021年6期)2021-08-24
中老年保健(2021年7期)2021-08-22
中学生数理化·高一版(2020年1期)2020-02-20
上海医学(2019年1期)2019-04-13
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
制造技术与机床(2018年9期)2018-09-19
海外华文教育(2017年6期)2017-08-07
水电站机电技术(2016年1期)2016-02-28
科普童话·百科探秘(2015年4期)2015-05-14
