
面向脚本事件预测的稠密事件图嵌入
2023-08-19 02:39:56宁佐廷贾明颐安莹段俊文
湖南大学学报(自然科学版) 2023年8期
宁佐廷 ,贾明颐 ,安莹 ,段俊文 †
(1.湖南警察学院 网络侦查技术湖南省重点实验室,湖南 长沙 410138;2.中南大学 计算机学院,湖南 长沙 410083;3.中南大学 大数据研究院,湖南 长沙 410083)
叙述性脚本由一系列事件组成,并描述这些事件之间的时间和因果关系.最近,从非结构化文本中自动归纳脚本受到了越来越多的关注,因为脚本蕴含了重要的现实世界知识,这对于常识推理至关重要.图 1 给出了针对用餐场景的脚本事件预测的示例.对于人类来说,凭借我们拥有的背景知识,我们可以很容易地推断出下一个事件为X离开了饭店[Leave(X,restaurant)].了解事件如何随时间演变有利于改善各种下游人工智能应用程序,例如推荐系统、用户意图理解和对话生成.然而,根据现有事件预测未来可能发生的事情仍然是一个具有挑战性的问题.
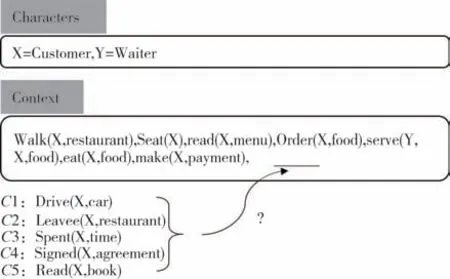
图1 脚本事件预测的一个示例Fig.1 An example forscript event prediction
本文遵循最近关于脚本学习的研究工作[1-2],其任务是根据现有事件从候选列表中预测最有可能发生的后续事件.在早期工作中[1-3],事件使用词袋表示,并且仅对成对关系建模,这不足以支持鲁棒的预测.早期的工作通过浅层的词汇或句法特征来表示事件,例如单词、词根、位置标签和依存关系[1,4].但由于它们的稀疏性,这种方法往往缺乏语义表示能力.
随着词嵌入表示方法的流行,许多方法开始将事件中的实体和参数语义组合成向量表示.然而,属性之间的丰富联系并没有得到充分利用.基于神经网络的模型的引入为这项任务带来了重大进展.Ding 等人[5]首先提出利用神经张量网络的表达能力来直接捕捉参数之间的相互作用.Weber 等人[6]提出了一个类似的网络来对事件的场景级语义进行建模.Grantorh-Wilding 等人[2]使用神经组合模型将事件组合成密集向量.Pichotta 等人[7]以及 Wang 等人[8]利用seq-seq模型来捕获事件链中的时间信息.
另一方面,如图 2(a)所示,现实世界中的事件可以自然地构成图形结构.这也使得图神经网络成为一个值得深入研究的课题.图神经网络最早由Gori 等人[9]和Scarselli 等人[10]提出,作为递归神经网络的推广.GNN 的递归性质允许更新其邻居的节点输出.这个想法后来被扩展到用GRU 代替递归神经网络[11-12]、卷积神经网络[13]和掩码多头自注意力[14].无监督方法通常依赖于图结构和节点连接性,Tang等人[15]通过一阶和二阶邻近度学习节点表示,Perozzi 等人[16]基于随机游走理论获得网络节点嵌入.然而,图神经网络的一个基本假设是图中节点之间的连接关系是已知的,这不适用于我们的场景.
同时,从事件图到事件对或事件链的转换有可能会丢失支持后续事件预测的重要结构信息,如图 2(b)和2(c)所示.为了克服这个问题,Li 等人[17]提出构建一个叙事事件演化图作为外部知识来支持脚本事件预测.由于语料库大小有限和信息提取工具的不完善,他们的图可能会丢失事件之间的重要联系并出现稀疏性问题,如图2(d)所示.
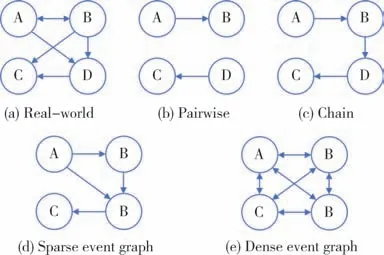
图2 针对事件建模的不同结构Fig.2 Different structures for event modeling
为了解决上述问题,本文提出使用稠密图[图 2(e)]来表示事件,其中节点是事件,边是它们的关系,事件彼此完全连接.使用一个可学习的多维邻接矩阵用于定义事件之间的关系及其对应的关系强度,该矩阵通过从数据中学习从而进行更新.与之前的邻接矩阵不同,多维邻接矩阵是每个事件对的密集向量,它可以在细粒度级别捕获事件之间的关系.
为了得到正确的答案,通常需要进行多步推理.然而,以前的工作仅利用一阶邻接点(直接连接的事件)的信息来更新事件表示,未能捕获高阶事件演化模式,因此不足以支持多步推理.为了克服这个问题,本文提出了一个嵌入稠密事件图(DEG)的通用框架,它允许来自更高阶事件的信息影响事件表示.
在benchmark 数据集上的实验结果表明,基于 DEG 的模型可以有效地利用丰富的图结构信息和高阶事件演化信息.本文提出的基于多维加权邻接矩阵和稠密事件图嵌入模型在此任务上实现了最新的性能.本文的主要贡献可以概括为:
1)本文提出利用事件之间的丰富联系构建稠密事件图并用于脚本事件预测任务的;
2)提出了一个稠密事件图嵌入框架,能够将高阶事件演化信息集成到事件表示中;
3)提出了一个可学习的多维加权邻接矩阵,它可以通过从数据中学习来更新,以在细粒度的特征级别上描述事件之间的关系强度.
1 问题定义
本节给出事件和脚本事件预测任务的正式定义.
事件:根据具体任务,将事件表示为两种不同的结构,即v(s,o,p) 或 (s,v,o),其中v是谓语动词,s、o和p分别是主语、直接宾语和介词宾语.它们合称为事件参数.例如,可以从句子he opens the door with the key中提取事件opens(he,thedoor,withthekey)或者(he,opens,thedoor),其中v=“opens”,s=“he”,o=“thedoor”,p=“withthekey”.这仅仅是每个任务中事件结构的其中一种形式.
稠密事件图:本文从语料库中提取了一组叙事事件链C={C1,C2,…,Cn},事件链Ci的每个事件均以的形式表示,取决于具体的任务.本文为每个事件链构建一个稠密事件图Gi=(Vi,Ai),其中Vi表示链Ci中的节点,Ai是含有m个事件的事件链的m×m有向加权邻接矩阵,它定义了事件之间的关系及事件之间的关系强度.
脚本事件预测:给定一个由m个上下文事件{e1,e2,…,em}和n个候选后续事件{c1,c2,…,cn}组成的事件链,任务是根据给定的条件预测合理的后续事件上下文事件.注意,在给定的候选后续事件中,只有一个候选事件是正确的.
2 模型
本文提出了一个稠密事件图表示网络(Deg-Net),它由事件表示模块、多维加权矩阵生成模块和稠密事件图表示模块三个主要模块组成.该框架的整体架构如图3 所示.基于该框架,本文进一步提出了DegNet 的两个变体,即 DegNet-G 和DegNet-R.两个变体之间的区别在于稠密事件图表示模块,其中DegNet-G利用了门控图神经网络,而DegNet-R结合了随机游走理论.
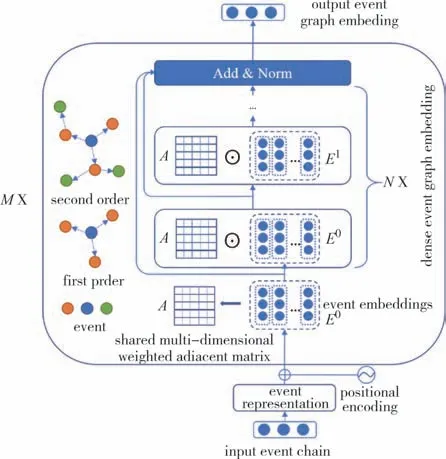
图3 本文所采用方法的框架Fig.3 The framework of the proposed architecture
2.1 事件表示
事件表示模块旨在学习事件元组的向量表示,用于初始化 DEG 中的节点表示.给定事件元组vi(si,oi,pi),本文首先从预训练的词嵌入矩阵中检索动词e(vi)和参数e(si),e(oi),e(pi)对应的词向量.然后学习一个映射函数f,它将词向量语义组合成事件表示ei=f(e(vi),e(si),e(oi),e(pi)).
本文使用具有非线性激活的连接组合,从而实现了最佳性能.同时也尝试了其他的事件表示模型,例如:
其中[:]表示向量拼接操作.在本文的其余部分将使用E来指代链中事件的向量表示,即E=[e1,e2,…,en].
事件序列的时间顺序对于叙事事件链建模非常重要.为了保留这些信息,本文采用与 Transformer[18][等式(2)]相同的位置编码策略,位置编码的每个维度都是根据它们的位置生成的.
其中d是事件嵌入的维度,位置编码嵌入在训练期间是固定的.
2.2 多维加权邻接矩阵 (MWDM)
加权邻接矩阵(WAM)描述了事件之间的关系及其对应的关系强度.对于指向事件ej的事件ei,它们的关系强度rij可以从两个角度来解释:1)从ei到ej的转移概率,2)ei和ej在语义上相互作用.
之前的工作[17]分别使用静态的动词-动词连接和共现频率作为事件-事件关系及其关系强度,存在“语义鸿沟”问题.例如,“throw”和“catch”经常同时出现,但是,如果采用“throw-catch”的共现频率来定义“he throws a ball”和“he catches cold”的关系强度,则会不合适.为了克服这个问题,本文建议从数据中自动学习加权邻接矩阵并动态更新矩阵的值.
事件关系建模的另一个挑战是多义现象.多义词是自然语言中非常普遍的现象,在事件中也存在.例如,事件“he went to the bank”中,“bank”可以指“riverside”(河堤),也可以指“financial bank”(银行).通常,不同含义的同一个词对应同一个词向量.但是词向量的特征(即每个维度)应该携带不同的句法和语义信息[19-20].受此启发,为了减少歧义并更好地表征事件之间的关系,本文提出了多维加权邻接矩阵,它从细粒度特征级别衡量事件之间的关系强度.
图4 说明了事件链E={e1,e2,…,en} 的MWDMA是如何生成的.
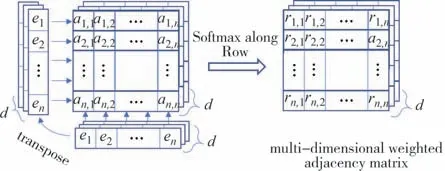
图4 事件链E={e1,e2,…,en}生成多维权重邻接矩阵A的示例Fig.4 Example for generating the multi-dimensional weighted adjacency matrix A for event chain E={e1,e2,…,en}
给定来自 DEG 的两个事件的表示ei,ej,首先将它们输入非线性矩阵并获得对齐向量ai,j∈Rd[等式(3)]:
其中Wa,W1,W2∈Rd×d,d是事件嵌入的维度,⊙表示逐元素乘法.然后沿着对齐得分矩阵ai,j的行执行softmax 以获得归一化强度ri,j.它们在第k维的关系强度可以建模为等式(5).
最终的多维加权邻接矩阵A∈Rn×n×d为等式(6).图4 说明了如何生成多维邻接矩阵.在本文的其余部分,为了便于理解,本文将忽略A中的特征维度k,并将A视为n×n矩阵.
2.3 稠密事件图嵌入
对于脚本事件预测,我们往往需要进行多步推理才能得出正确的答案.例如,“他打开冰箱”可以引发多个合理的后续事件,例如“他得到一瓶水”或“他得到一片面包”.然而,如果我们知道发生在“他打开冰箱之前的事件”,例如“他渴了”,那么可能的选择就会缩小到“他得到一瓶水”.整合来自与目标事件间接相关的事件的信息也将有助于完成任务.然而,邻接矩阵只保留一阶关系,即直接连接的事件的关系.
图5 给出了一个简单的示例,解释了什么是一阶和二阶关系.从节点1 到节点2 是一阶关系,因为它们直接相连,从节点1 到节点3、4 和从节点5、6、7到节点2 是二阶关系,因为节点1 需要穿过节点2 才能到达节点3、4.图5 只显示了一阶、二阶和三阶关系,然而,这个概念可以很容易地扩展到更高阶.尽管在本文提出的事件图中的节点是密集连接的,但高阶信息仍然有帮助,因为它允许在事件ej和ek存在的情况下计算出事件ei发生的可能性,即条件概率p(ei∣ej,ek).
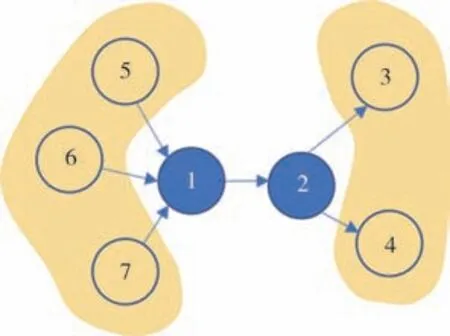
图5 展示事件图中一阶和二阶关系的一个简单示例Fig.5 An toy example illustrating the first-order and secondorder relations in the event graph
在获得链中的多维加权邻接矩阵A和事件表示E之后,下一步是学习一个利用A、E将上下文信息集成到事件(节点)表示中的函数f,即=f(A,E).图6 显示了DEG 嵌入模块中的单个层.在此详细介绍本文提出的DegNet-G 和DegNet-R 如何获得以下最终事件表示,图6中A为多维加权邻接矩阵,Et为当前事件表示.
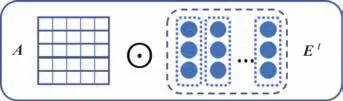
图6 DEG嵌入模块中的单层Fig.6 A single layer in the DEG embedding module
2.3.1 DegNet-G
DegNet-G涉及常用的门控图神经网络(GGNN)[11]用于嵌入图,如等式(7)中所定义.
其中σ和tanh 是非线性激活函数;W(*),U(*)是可学习的模型参数;⊙表示逐元素乘法,rt和zt分别表示重置门和更新门.基于门机制,GGNN 能够结合来自当前状态Et和先前状态Et-1的信息.
GGNN 依赖于关于图中节点关系的先验知识.为了适应本文的框架,采用MWAMA 替换了它原来的邻接矩阵,并添加了Layer-wise Normalization 层来捕获不同顺序的信息.
2.3.2 DegNet-R
DegNet-R 基于随机游走理论[21].对于具有转移矩阵M的连通图G,M定义图中从一个节点到另一个节点的转移概率.从节点v0开始的t步随机游走,可以生成一个序列{v0,v1,v2,…,vt}.在这个随机游走中可以到达的第t个节点vt的分布P(vt)被定义为P(vt)=(M⊤)tP(v0).
在本文的例子中,MDWMAA 定义了从一个事件到另一个事件的转移概率.因此,可以通过(A⊤)t到达第t阶节点.换句话说,影响可以从第t个节点传播到起始节点.
为了从一阶邻接点那里获得信息,有E1=A⊤E0.从这个角度来看,只考虑一阶节点相当于transformer[18]中的self-attention 机制,其中一个token考虑了序列中的所有token 来更新自己的表示.我们可以将这个概念扩展到更高阶.考虑一阶邻接点的一阶邻接点,即二阶节点E2=A⊤(A⊤E0),以此类推.为了从第t阶节点获取信息,可依据等式(8)运算:
其中Et代表第t阶节点,其他以此类推.
2.3.3 求和和分层归一化
为了整合不同顺序节点的信息,本文对每一层输出求和并执行逐层归一化:
其中Et代表第t阶节点,它也可以看作是来自每一层输出的跳跃连接[22].可以直接从最后一层传播梯度来更新每一层,从而避免梯度消失.
本文通过堆叠DEG嵌入模块来捕获更高级别的表示.在同一DegNet模块的层中,A在同一DEG 嵌入模块之间共享.它将根据最新的上下文感知事件表示在传递到上层堆叠模块时进行更新.
2.4 预测
在获得上下文中每个事件的最终上下文感知表示={,,…,} 后,就可以从候选事件{c1,c2,…,cn}中预测后续事件.首先计算每个候选事件与上下文中所有事件的相关性分数:
其中ci表示第i个候选事件表示第j个事件的上下文感知表示,g(·,·)表示计算相关性分数的函数.候选事件的最终得分是其与所有上下文事件的相关性得分的平均值.相关性得分最高的候选事件视为正确答案.在此本文使用简单的余弦相似度来衡量候选事件和上下文事件之间的相关性.得分最高的答案将被视为预测结果c:
2.5 训练细节
本文使用multiple margin loss 作为目标函数来优化.正确的黄金标签应该获得更高的分数以避免惩罚:
其中cgold表示黄金标签对应的候选事件,margin 为超参数.128维的词向量是从Li[17]等人发布的预训练词嵌入中初始化的.它在大型新闻专线语料库上进行训练,并在模型训练期间进行了微调.本文使用Adam[23]来优化参数,其初始学习率设置为0.000 5的参数.本文也使用了早停法(early stopping)和随机失活(dropout)[24]来避免过拟合问题,dropout 率设置为0.1.本文保留在开发数据集上具有最佳性能的模型,以供在测试数据集上进一步评估.
3 实验
本文在两个脚本事件预测数据集上评估了所提出的模型,即多选叙事完形填空(MCNC)和连贯多选叙事完形填空(CMCNC).
3.1 数据集
数据集统计如表1所示.

表1 数据集统计Tab.1 Statistics of the dataset
3.1.1 多选叙事完形填空(MCNC)
该任务由 Granroth-Wilding 等人[2]提出,用于评估叙事生成系统.数据集是根据 Gigaword 语料库的纽约时间部分自动构建的[25].为了保证事件链的连贯性,同一条链中的事件共享同一个主角.上下文中有八个事件,提供了丰富的信息.在五个候选项目中,只有一个是正确的.
本文遵循与Granroth-Wilding 等人[2]相同的管道方法进行事件提取和事件链构建.使用相同的文件进行训练、评估和测试,以便与以前的工作进行公平比较[2,17].数据集的总体统计数据如表1所示.
3.1.2 连贯多选叙事完形填空(CMCNC)
MCNC 数据集是自动构建的,它对常见事件(例如“说过”、“做过”)和预处理工具中的错误很敏感.为了解决这个问题,Weber 等人[6]手动构造了一个评估数据集CMCNC.CMCNC 与MCNC 的区别在于:MCNC的长度和所有的事件共享同一个主角.
3.2 基线和评估指标
本文与以下基线进行比较.遵循之前的工作[2,17],使用准确性作为评估指标.
Averaging:该模型将每个事件表示为来自预训练的 GloVe 嵌入的组成词向量的平均值[26].选择成对相似性得分最高的候选事件.
PMI:基于共现的模型[1].事件用依赖关系和谓词动词表示.每个候选事件的分数是通过将它们的逐点互信息分数与上下文事件相加来计算的.
Bigram:基于 skipgram[3]和二元概率对事件对关系进行建模.
LSTM:一个基于链的模型[7],它利用长短期记忆网络来表示事件链.候选事件用于网络的最后输入,输出隐藏状态用作预测的特征.
EventComp:利用成对事件连接[1].它是一个非线性事件组合网络,它使用孪生网络来计算成对事件相关性分数.
Predicate Tensor:通过将事件参数与谓词张量结合来获得事件表示[6].张量是根据事件中的谓词动态生成的.
Role Factor Tensor:使用两个张量分别捕获主谓和谓宾之间的交互[6],然后将它们组合起来形成事件表示.
PairLSTM:使用动态记忆网络[8].首先利用递归神经网络来捕获事件顺序信息,然后将候选事件视为寻找线索以预测后续事件的查询.
SGNN:构建了一个抽象的叙事事件进化网络作为定义事件之间联系的先验知识[8],然后应用门控图神经网络对事件交互进行建模.
3.3 结果与分析
3.3.1 MCNC 上的结果
MCNC 数据集的总体实验结果如表2 所示,最好的结果被加粗表示.可得到以下观察结果:
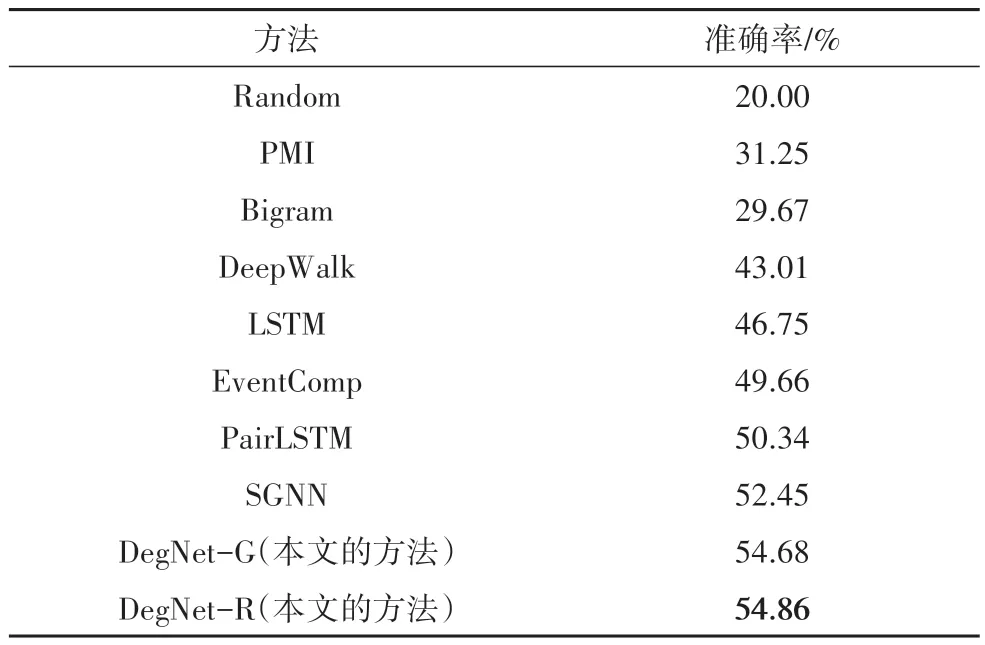
表2 基线和本文的方法在MCNC测试集上的表现Tab.2 The performances of baselines and our approach on the MCNC test set
首先,基于计数的方法 PMI 和 Bigram 与基于词嵌入的方法相比没有竞争力,因为它们依赖于稀疏特征表示和成对关系,这会丢失事件之间的结构和语义信息.
其次,在任务中引入词嵌入带来了显著的改进.然而,EventComp、LSTM 和 PairLSTM 的实验结果之间的比较表明,单靠词嵌入是不够的,事件链中的事件关系如何建模也很重要.
再次,DeepWalk 和SGNN 都是基于图嵌入的方法,但DeepWalk 是无监督的,而SGNN 是有监督的.两者之间巨大的性能差距凸显了有监督方法的重要性.
最后,DegNet-G和DegNet-R都大大优于最佳基线,最佳模型实现了4.6%的性能提升.这表明利用来自高阶节点的密集连接和信息有助于模型理解上下文中的事件.
3.3.2 CMCNC 上的结果
表3 报告了本文在CMCNC 测试集上的结果,最好的结果被加粗表示.表3 仅给出了本文提出的模型和基线在CMCNC测试集上的性能.
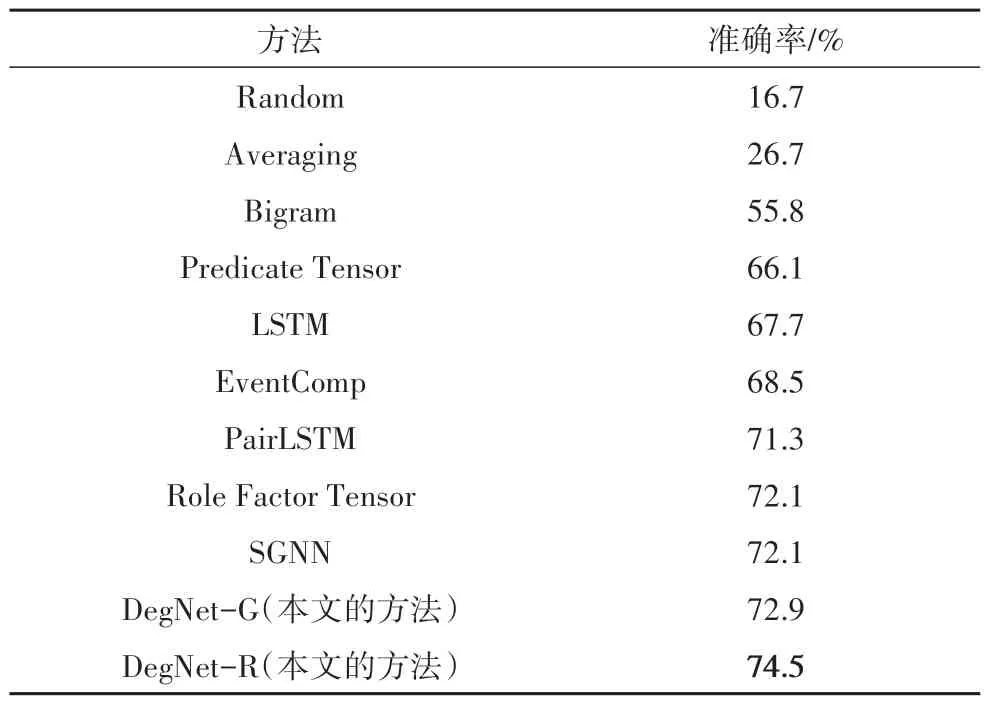
表3 基线和本文的方法在CMCNC测试集上的表现Tab.3 The performances of baselines and our approach on the CMCNC test set
观察结果与MCNC 类似,即基于计数的方法 Bigram 的性能大幅低于基于神经网络.Predicate Tensor、EventComp 和 Role Factor Tensor 是基于成对关系的方法,旨在学习更好的事件表示.Role Factor Tensor 使用两个张量来捕获主谓和谓宾交互,在数据集上提供更高的准确性并显示其语义表示能力.LSTM、PairLSTM 是基于链的方法,而PairLSTM 考虑成对关系和链时序.SGNN 和本文提出的DegNet-G、DegNet-R是基于图的方法.
3.3.3 模型融合
为了找出不同的结构(例如对、链、稀疏图)是否具有其独特的优势,本文进行了模型融合.使用简单的参数化线性组合来集成来自不同模型的预测分数(等式13).在开发集上对超参数λ进行了调整.
如表4 所示,可以发现融合模型DegNet-R+EventComp 可以将性能从54.86%提升到56.21%,表明它们具有互补的作用.然而,添加 PairLSTM 并没有带来显著的改进,表明两个模型的预测由于结构上的相似性而有很大的重叠.通过组合DegNet-R、EventComp 和SGNN 实现了56.53%的最佳性能.然而,添加SGNN 带来的改进很小,这证实了本文的直觉,因为SGNN也是基于图结构的.

表4 融合模型在MCNC测试集上的表现Tab.4 The performances of fused models on MCNC test set
3.3.4 层数的影响
DEG Embedding 模块可以有多个层来捕获不同顺序的事件关系.为了验证添加层是否对性能有影响,使用不同的层训练模块并测试它们的性能.结果如图7所示.
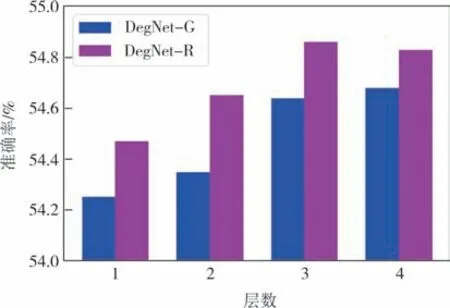
图7 不同层数的DegNet-G和DegNet-R在MCNC数据集上的性能Fig.7 The performances of DegNet-G and DegNet-R with different numbers of layers on MCNC dataset
可以观察到,具有1 层的DegNet-R 性能已经比最佳基线SGNN 提高了近4%.随着层数的增加,性能会提高,这表明它们可以从更高阶获取信息.然而,我们观察到当层数增加到4 层时,模型的性能开始出现下降的趋势.这表明随着层数的增加,网络模型的参数和计算复杂度不断提高,而数据集规模有限,会导致过拟合问题,使得模型效果下降.比较的结果表明,本文的模型可以利用多阶信息来提高模型性能.
3.3.5 事件表示的影响
Average、Concatenation 和Nonlinear 是之前工作中使用Average 最广泛的事件表示函数[2,8,17].Average对所有向量执行均值运算,Concatenation 将所有向量拼接成单个向量,而Nonlinear 通过非线性参数化加法导出事件向量.本文与上述事件表示方法进行了比较,结果如表5所示.

表5 不同事件表示模式在MCNC数据集上的比较Tab.5 Comparison between different event representation schemas on MCNC dataset
朴素的Sum 和Average 在事件组合策略以及它们在测试数据集上的最终表现上均没有显著差异.与Sum 和Average 相比,基于参数化加法和非线性激活的Nonlinear 在预测精度上有显著提高,显示了建模事件语义在文本理解任务中的重要性.本文使用的Concatenation 方法产生了最佳性能.一个可能的解释是事件元组中有很多缺失的字段,该方法连接而不是将动词和参数嵌入添加到单个向量中,从而减少了这些字段对最终事件表示的影响.
3.3.6 密集和稀疏事件图的影响
为了测试本文提出的多维加权邻接矩阵的有效性,将基线SGNN 进行复制并用 MWAM 替换了模型中的邻接矩阵.原始的 SGNN 模型利用自动构建的动词-动词图来定义链中的事件-事件关系.从表6中的结果可以发现,用DEG 替换稀疏事件图实现了近 2% 的性能提升,表明本文提出的MWAM 已具有捕获事件之间关系的能力.

表6 SGNN和本文的DegNet-R模型在MCNC数据集上的稀疏稠密事件图的表现Tab.6 Performances of SGNN amd our DegNet-R with sparse and dense event graph on MCNC dataset
尽管DEG 中的事件是完全连接的,但是可能会引入不存在的关系.然而,事件之间的关系强度是相对的,不存在的关系将被分配相当小的值,本文提出的MWAM 能够从细粒度的特征级别捕获关系强度.对稠密事件图有效性的另一种解释是,词嵌入被训练来预测其上下文.词向量已经包含了上下文事件.通过嵌入词向量的语义组合来衡量事件之间的关系是合理的.
3.4 案例分析
为了进一步分析本文的方法在数据集上的性能,在表7 中展示了一个案例研究.表7 中√代表正确答案,×代表错误答案.
对于案例1,人类可以很容易地从上下文事件中推断出C3是正确答案,但是对于模型来说,它已经将音乐家与钢琴家联系起来.
对于案例2,候选C6和C5共享同一主题实体knife,但C5给出的分数比C6高,表明事件中的其他参数也起着重要作用.这也表明本文的模型在这种情况下捕获了事件的语义.
对于案例 3,这是一个错误案例,本文的模型给出了错误的答案C5,而正确的答案是C4,得分略高.其他不相关的答案,如C1和C2得分很低.然而,本文提出的模型还是能够将victory和race的概念联系起来.尽管C4是人类注释的正确答案,但C5也显示出一定合理性.
从上述案例研究中,可以发现信息抽取仍然是一个很大的挑战,这限制了从非结构化文本中自动获取知识的效果.
4 结论
本文提出了一种稠密事件图嵌入模型,该模型利用稠密事件图进行脚本事件预测,使用多维加权邻接矩阵来表示事件之间的丰富联系及其在稠密事件图中的关系强度,该矩阵通过从数据中学习来更新.同时本文提出了一个通用框架,它可以将高阶事件演化信息集成到事件表示中.在benchmark数据集上的实验结果证明了本文所提出模型的有效性.
猜你喜欢
长春师范大学学报(2022年12期)2023-01-13 11:41:32
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
网络空间安全(2016年3期)2016-06-15 20:27:07
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
读写算·教研版(2015年13期)2015-07-28 07:13:11
