
面向战场环境下的语种识别
2023-08-08 14:56:08华英杰刘晶邵玉斌朵琳
兵工学报 2023年7期
华英杰, 刘晶, 邵玉斌, 朵琳
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650500)
0 引言
语种识别(LID)是将一段未知的语音音频文件输入到语种系统端,提取其中的语种信息特征与训练好的语种模型进行判别,输出语种类型[1]。随着各国频繁的进行联合演习,各国军队之间的通信也成为一大关键问题。军队通信往往伴随着军用设备噪声源,导致各国军队无法很好地进行军事联合作战,也影响海陆空多兵种之间的配合。目前,语种识别技术在高信噪比和平稳噪声环境下已经取得了不错的进展。然而军用设备噪声具有非平稳性和噪声大的特点,导致识别性能不佳。
传统的语种识别主要基于声学层特征和音素层特征。基于声学层特征是通过对语音进行预处理再提取声学层特征,采用多分类模型或统计模型。目前主流的声学特征包括梅尔频率倒谱系数[2](MFCC)、滑动差分倒谱[3]、感知线性预测系数[4]、伽玛通频率倒谱系数[5](GFCC)。主流的识别模型包括支持向量机[6]和混合高斯模型-全局背景模型[7]等。基于音素层特征主要考虑的是不同语种有不同的音素集合[8]。主流模型包括并行音素识别器后接语言模型[9]等。
近年来,深度神经网络[10](DNNs)模型在语种识别领域得到快速发展。Jiang等[11]考虑到DNNs强大的特征抽取能力,提取了深度瓶颈特征。随着图像识别被引入到语种识别领域,Montavon等[12]提取线性灰度语谱图特征(LGSS),将语种识别转为图像识别,取得了很大进展。Lopez等[13]将特征提取、特征变换和分类器融于一个神经网络模型,后续在此基础上又研发出不同的神经网络,包括延时神经网络[14]、残差神经网络[15](ResNet)等。Wang等[16]将注意力机制模型结合长短时记忆循环神经网络搭建的端到端系统也取得了不错的效果。Jin等[17]从网络中间层中提取LID-senone特征。同年Cai等[18]提出了一种基于可学习的字典编码层的端对端系统,从底层声学特征直接学习语种类别的信息,摒弃了声学模型,也取得了较优的识别性能。Deshwal等[19]提出了一种基于混合特征提取技术和前馈反向传播神经网络分类器的语言识别方法。Li等[20]提出了基于多特征和多任务模型的深度联合学习策略的识别方法。Bhanja等[21]提出了基于自动声调和非声调预分类的语种识别方法。
目前,针对战场环境下进行语种识别研究鲜见报道。本文基于国内外语种识别技术和图像处理技术进行研究,提出了一种基于语谱图灰度变换的战场环境下的语种识别方法。本文的主要贡献有3个方面:
1)根据语音和噪声信息在频率上分布的规律,提出一种带通滤波的处理方法,在尽可能减少信息丢失的情况下,一定程度上抑制高频段噪声的影响。
2)提出模拟人耳听觉特性的对数灰度语谱图特征,增强了特征的抗干扰能力。
3)目前语音学的方法对复杂噪声信号的抑制不理想,导致低信噪比环境下的语种识别率不高。本文提出了一种基于语谱图灰度变换的噪声抑制方法,通过自动色阶算法对对数灰度语谱图的语音信息部分进行增强,对噪声部分进行抑制。实验结果表明,本文方法对于战场环境下的语种识别效果良好。
1 模型构建
本文搭建了主流的图像识别网络作为语种识别系统:基于ResNet的语种识别系统,是一种卷积神经网络,由微软亚洲研究院He等[15]提出。以美国俄亥俄州立大学Nonspeech公开噪声库中的噪声来构建不同噪声源下不同信噪比的语料库。
1.1 ResNet模型
普通的卷积网络是非线性的,即每层卷积连乘。而ResNet向前过程是线性的,即原始输入加上这层残差结果作为下一层的输入。ResNet的最大特点就是解决了梯度爆炸和梯度消失问题,而且与普通卷积网络相比误差更小,在图像识别领域的误差只有3.57%,比人眼误差小1.53%。
1.2 带噪语音生成模型
本文研究战场环境下的语种识别问题,采用Nonspeech公开噪声库中的9种不同噪声源:白噪声(WN),驱逐舰作战室背景噪声(DORBN),军用车辆噪声(MVN),高频信道噪声(HFCN),粉红噪声(PN),车内噪声(VN),F16座舱噪声(F16CN),掠夺者战斗机驾驶舱噪声(BFCN),机枪噪声(MGN),构建信噪比SNR为-10~25 dB的语料。平均信噪比定义如下:
(1)
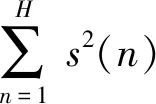
2 语种特征提取
本文提出的基于语谱图灰度变换的特征提取处理方法流程如图1所示。首先将语音信号进行带通滤波,得到中低频段的语音;之后提取中低频段语音的对数灰度语谱图;最后将对数灰度语谱图通过自动色阶算法进行图像增强处理,得到噪声抑制后的对数灰度语谱图。

图1 特征提取流程
2.1 语种信息和干扰信息的分布特性
语音学研究表明,语音中低频信息能量高、高频部分能量较少,而且人耳对高频信息分辨率不高[22]。图2包括Nonspeech公开噪声库中9种不同噪声和一段4 min、采样率为fs=8 000 Hz、单通道的wav格式的语音信息和噪声信息功率密度随频率的分布图。

图2 语音信息和噪声信息功率密度随频率分布图
由图2可知,语音信息集中在中低频部分,有6种噪声的能量在高频部分超过语音信息,有8种噪声能量在极低频部分高于语音信息。因此采用带通滤波器滤掉高频部分和极低频部分。滤波只会使得语音略显低沉,稍微降低语言的清晰度,但是保留了大部分语种信息,滤除大量噪声信息,间接提升了信噪比。本文采用的是巴特沃斯带通滤波器,实验结果表明通带带宽B的范围为1 000~1 500 Hz,滤波器阶数为4阶时效果较好。
下面以高斯白噪声为例,因为WN均匀分布在各个频率段上,滤波后噪声损失的能量大于语音损失的能量,所以滤波后信噪比计算公式为
(2)
(3)

2.2 基于听觉感知的灰度语谱图
语音的时域分析和频域分析是语音分析的两种重要方式,时域分析目前有共振峰、短时平均能量等,频域分析有MFCC、GFCC等[23]。两种单独分析方式都有一定局限性,时域分析没有对频域进行直观了解,而频域分析又没有分析语音信号随时间的变换关系[24]。因此本文引入一种既包含频谱图的特点也包含时域波形图的特点的三维频谱图,即语谱图。语谱图具有语音频谱随时间变化的信息,还包含了大量与语种相关的信息。由于耳蜗的构造决定了频率的空间分布不是线性的,而是接近对数的,采用对数灰度语谱图可以更好地模拟人耳的听觉特性,增强语谱图可辨识度[25]。语谱图是采用二维平面表达三维信息,横轴为时间,纵轴为频率,任意给定频率成分在给定时刻的强弱用相应点的灰度来表示。
对数灰度语谱图生成步骤包括分帧加窗、离散傅里叶变换、计算能量密度谱,并生成对数灰度语谱图。具体流程如下:
1)分帧:对带通滤波的语音信号x(n)分帧,实验取帧长256,帧移128,分帧后的第i帧信号为xi(n)。
2)加窗:对第i帧信号xi(n)进行加窗处理,实验使用的是汉明窗,加窗后的第i帧信号为si(n)。
3)离散傅里叶变换:将第i帧信号si(n)进行短时傅里叶变换,定义如下:
(4)
式中:Si(k)为信号si(n)的短时傅里叶变换,k为频谱系数;N为采样点数。
4)能量密度谱:是一个二维的非负数实值的函数,定义如下:
Pi(ω)=|Si,t(k)|2
(5)
式中:Pi(ω)为第i帧能量;Si,t(k)为信号在t时刻和频率k处的复数振幅。
5)能量密度谱对数化:将能量谱分贝化,
(6)
6)频率对数化:将频率对数化,从而模拟人耳听觉构造,公式如下:
ω1=log2(ω)
(7)
式中:ω1为频率的对数化。


图3 线性灰度语谱图和对数灰度语谱图
2.3 基于语谱图灰度变换的噪声抑制算法
为了在传统的噪声抑制信号处理中取得好的效果,需要确保所做的假设符合该场景,而且滤波采用的统计量也要估计正确,但这些假设在真实的噪声环境下很难准确做到。目前,研究人员采用深度学习算法进行噪声抑制,然而该类方法需要大量的训练数据集,不然鲁棒性极差,可能在某个环境下性能良好,换个环境则性能急剧下降。而且深度学习方法的性能和优化指标很有关系。针对上述问题,本文提出了一种基于语谱图灰度变换的噪声抑制方法。采用图像处理方法进行战场环境下噪声信号的抑制。对数灰度语谱图上噪声信息的像素值和大部分语音信息的像素值相差明显,因此采用自动色阶算法进行图像增强,以降低噪声的影响、增强语种信息。
自动色阶算法[26]主要利用直方图统计各个像素值,将像素值高于高阈值的像素点设为255,低于低阈值的像素点设为0,最后将像素值经过线性量化重新分配像素值,这样既可以使其他部分噪声像素值变小,也增强了图像的可辨识度。算法流程图如图4所示。

图4 自动色阶算法流程
阈值定义如下:
Tmin=max (u1),u1(n)=u0(n),1≤n≤K×α
(8)
Tmax=max(u2),u2(n)=u0(n),1≤n≤K×(1-β)
(9)
式中:Tmin为低阈值;Tmax为高阈值;u0为直方图统计的总像素值从小到大的向量;u1为低于低阈值的向量;u2为低于高阈值的向量;α、β为可控的色阶因子;K为像素点的总个数。
本文采用线性量化方式得到最终增强的图像,将像素值在高低阈值之间的像素值通过线性量化重新分配像素值,量化公式如下:
(10)
式中:R为量化后的像素值;Rs为高低像素阈值之间的像素值;s为每个通道得到的最小值;l为每个通道的最大值。
在9种不同噪声源下,5 dB语音原始图像和经过自动色阶算法增强的图像如图5所示。从图5中可以看到,经过自动色阶处理的图像相对于原始图像更加清晰,噪声掩蔽信息的效果也减小,使得语种信息更加凸显,图像更具辨识性。

图5 不同噪声源下5 dB原始语谱图(左)和增强语谱图(右)
3 语种识别实验
3.1 实验设置
1)训练集:语料库采用中国各大广播电台的广播音频,共包含5个语种:汉语、藏语、维吾尔语(简称维语)、英语、哈萨克斯坦语(简称哈语)。每个语种包含600条、采样率fs=8 000 Hz、单通道的wav格式、时长10 s的音频文件。采用Nonspeech公开噪声库中的WN作为背景噪声,每个语种包含信噪比等级SNR=[5 dB,10 dB,15 dB,20 dB,25 dB]的语音各100条,以及未加噪的语音100条。
2)测试集:语料库采用区别于训练集的其他广播电台的广播音频。每个语种171条,分别与Nonspeech公开噪声库中的9种噪声源,构建9种不同噪声源的语料库,每种语料库包含信噪比等级SNR=[-10 dB,-5 dB,0 dB,5 dB,10 dB]的音频,从而构成45个测试数据库。

(11)
式中:Ap、Az、Aw、Ay、Ah分别为不同语种的识别正确个数;A为总识别个数。
F1分数定义如下:
(12)
(13)
式中:V为语种个数;F1n为每个语种的F1分数,
(14)
Precisionn和Recalln为每个语种的精确率和召回率,
(15)
(16)
TP表示预测为正确的正样本,FP表示预测为错误的正样本,FN表示预测为错误的负样本。
3.2 实验结果与分析
3.2.1 可控色阶因子参数选取
表1给出了可控色阶因子α、β不同数值在测试和训练都是WN环境下的识别率。由于WN相对更加平稳,在所有类型噪声中相当于中间值,当调节好WN信号所适合的色阶因子后,其他非平稳噪声信号就可以在这个基础上得到相对较好的噪声抑制效果。从表1中可以发现,当α=0.45、β=0.35时效果最佳。

表1 α、β不同数值时的识别率平均值
3.2.2 语种模型构建与参数选取
本文构建的Resnet模型主要由多个残差模块堆叠实现,图6为ResNet的语种模型基本结构单元。

图6 ResNet模型的基本结构单元
在基本结构单元中,s为输入,relu为激活函数,σ如下:
(17)
F(s)为结构单元在第2层激活函数之前的输出。最后残差单元的输出是经过relu激活后得到的激活值σ(F(s)+s)。非线性映射过程F(s)为
F(s)=λ2σ(λ1s)
(18)
式中:λ1和λ2分别为第1层和第2层卷积的权重。
本文搭建的网络主要由一个卷积层、一个最大池化层、8个残差模块、一个平均池化层和一个全连接层组成。采用交叉熵作为损失函数、Adam作为优化器,未采用预训练模型。针对本文搭建的语种模型,调整模型的层数、学习率及迭代次数。根据实验过程中的识别正确率及损失函数值,最终本文采用的模型层数为18层,学习率为0.000 1,迭代次数为30次。
3.2.3 战场环境下的语种识别实验
为验证9种战场噪声环境下本文方法的有效性及鲁棒性,并分析其优劣的原因,设计了8组实验。
实验1:提取文献[27]中64维的梅尔尺度滤波器能量(Fbank)作为语种特征。
实验2:提取文献[12]中的LGSS作为语种特征。
实验3:提取文献[11]中的DBF特征作为语种特征。
实验4:提取文献[28]中的FRSCIRT特征作为语种特征。
实验5:提取对数灰度语谱图(TGSS)作为特征训练识别,验证对数灰度语谱图的有效性。
实验6:提取滤波对数灰度语谱图(FTGSS)作为语种特征,验证滤波可以消除部分噪声的影响。
实验7:提取图像增强的滤波对数灰度语谱图(FTGSSE),验证本文最终方法的有效性及鲁棒性。
由实验1~实验5可知,在WN环境及5种信噪比等级下,TGSS特征均优于Fbank特征和LGSS特征。由于TGSS更好地模拟了人耳的听觉效应,抗干扰能力更强。在较高信噪比下相对于DBF特征有所不足,DBF特征经过多层神经网络减少了说话人信息的干扰,但是信噪比较低时DBF特征不能通过网络层数滤除噪声信息,导致识别性能不佳。与FRSCIRT特征相比,TGSS特征识别性能不佳,尽管FRSCIRT特征很好地解决了说话人信息的干扰,又融合了抗干扰能力强的特征,但是在低信噪比下,识别性能依然不佳。
对比实验5、实验6可知,FTGSS特征相对于TGSS特征,识别性能有了些许提高,由于FTGSS特征引入了带通滤波,将高频和极低频部分的大量噪声滤除,从而间接提高了信噪比。
对比实验4、实验6、实验7可知,FTGSSE特征相对于FTGSS特征在识别性能上有了大幅度提升。由于FTGSSE特征对FTGSS特征进行了图像噪声抑制,间接增强语种信息,使得语种之间的特征区分度更高。相对于FRSCIRF特征,在5种信噪比下,分别提升了23.5%、15.8%、6.5%、4.3%和2.2%。由于FRSCIRF特征没有从根本上对噪声进行抑制,导致低信噪比下识别性能不佳。在较高信噪比下,FTGSSE提升不明显,是由于一部分语种信息被抑制了。
根据表2所示其他8种噪声环境下的实验结果可知,在训练集背景噪声为WN的情况下,对不同背景噪声的测试集进行测试,本文提出的FTGSSE特征在大部分场景下具有明显的优势,而且保持较高的识别性能和高鲁棒性。在VN源和MGN源环境极低信噪比下,识别性能不如FTGSS特征,是由于噪声集中在低频部分,导致采用图像处理方法不能很好地抑制掉噪声,反而语种信息被抑制掉一部分。从表2中可知,本文提出的TGSS特征在所有场景下都优于LGSS特征,是由于TGSS特征模拟了人耳的听觉特性,从而具有更好的抗噪性能。FTGSS特征相对于TGSS特征在所有场景下识别性能也取得了一定的提升,由于FTGSS特征滤除了高频和极低频部分,间接地提升了整段语音的信噪比,识别性能有所提升。
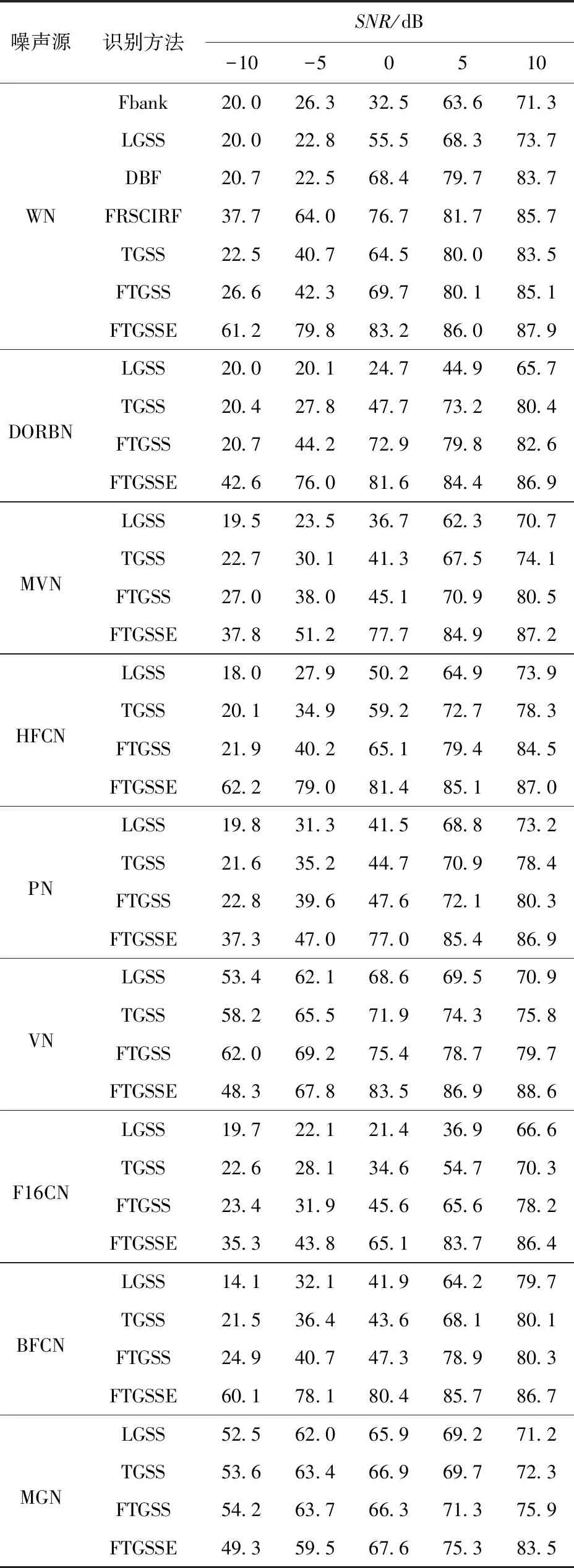
表2 不同噪声源和不同信噪比下的语种识别正确率
根据表3所示实验所得的F1分数可知,本文提出的FTGSSE相对于LGSS,在保持较高识别正确率的前提下,依然具有较高的召回率和精确率,表明本文提出方法的鲁棒性高。图7为不同噪声源在信噪

表3 不同噪声源和不同信噪比下的语种识别F1分数

图7 不同噪声源0 dB下FTGSSE方法的混淆矩阵图
比为0 dB环境下的语种识别混淆矩阵图,从中可知,除了汉语外,其他4种语言在4种噪声环境下都保持较高的识别精度。
图8为9种噪声环境下,采用FTGSSE特征和LGSS特征的平均识别正确率。从图8中可知,在9种噪声环境下,FTGSSE特征平均识别正确率都高于LGSS特征,分别提升了31.5%、39.2%、25.3%、32.0%、19.8%、10.1%、29.6%、31.8%和2.8%。而且在训练集为WN的情况下,测试其他噪声依然保持较高的识别正确率。由理论和实验结果可知,本文提出的FTGSSE特征具有较高的鲁棒性和识别性能。平均识别正确率的定义如下:
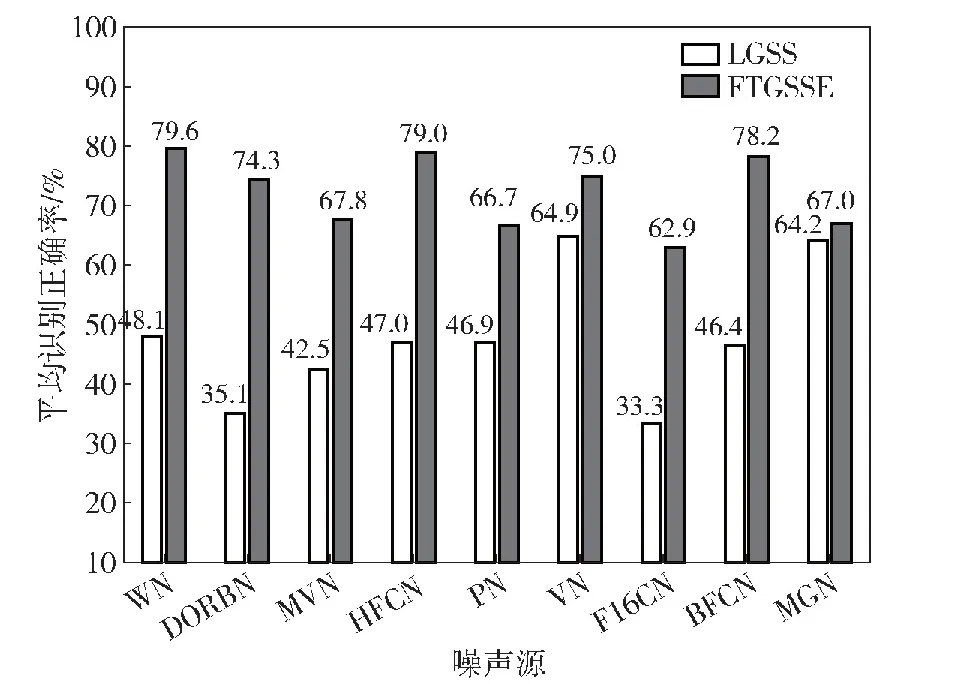
图8 不同噪声环境下的平均识别正确率
(19)

4 总结
本文针对战场环境下噪声类型复杂多样性,导致目前语种识别方法很难在战场环境下很好地应用,提出了FTGSSE特征解决战场环境下的语种识别问题。在训练集背景噪声为WN、测试集为9种噪声环境下,FTGSSE特征依然保持较高的识别性能和高鲁棒性。后续考虑对模型进行改进,引入注意力机制及多任务学习机制,实现对不同噪声环境下采用不同的噪声抑制方法。
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:06
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
时代邮刊(2021年8期)2021-07-21 07:52:44
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
中学生数理化·高一版(2018年10期)2018-11-08 11:06:56
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:05
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
东南大学学报(自然科学版)(2015年5期)2015-03-15 00:54:56
