
HR-DCGAN方法的帕金森声纹样本扩充及识别研究
2019-09-09 03:38:42徐志京
小型微型计算机系统 2019年9期
王 娟,徐志京
(上海海事大学 信息工程学院,上海 201306) E-mail:wangjuan_y@foxmail.com
1 引 言
帕金森病(Parkinson′s Disease,PD)属于常见的神经系统退行性疾病,目前尚不能治愈[1].因此探讨PD的早期诊断对控制PD患者的病情,延长其生命具有重要意义[2].研究发现,90%的PD患者早期症状中存在声带损伤[3],经声学分析表现为高振幅微扰,高基频微扰,低谐信噪比,低基频[4].考虑患者的嗓音特点,可以通过提取语音信号中的声学特征进行PD的早期检测,此方法具有非入侵性,便利性,高效率等优点,被国内外居民广泛接受.
国内外学者主要采用传统的特征提取方法和机器学习算法,通过分析语音信号实现PD识别.Max Little等[5]在2009年收集持续的元音发声/a/作为首个语音数据库.随后,Max Little等证明元音足以进行PD检测[6,7].2013年,Sakar等分析了从PD患者收集的多种类型的语音用于PD诊断[8].为提高识别准确率,Benba等在Sakar提供的数据集上继续研究,分别利用梅尔频率倒谱系数(Frequency Cepstrum Cofficient,MFCC)及其一阶、二阶导数[9],平均值来压缩提取的MFCC[10],人因子倒谱系数(Human Factor Cepstral Coefficients,HFCC)[11]提取声纹特征参数,结合不同核函数的SVM分类器进行分类.MFCC、HFCC等存在对高阶音频的声纹特征表征能力差、参数阶数选择复杂及特征缺失或冗余问题,基于小样本的浅层机器学习分类器如SVM,k-最近邻分类器(k-Nearest Neighbor,KNN)以及球面聚类方法[12]调参困难且计算量大.
近年来,深度学习在语音处理中的应用如语音增强、情感识别和病理检测,取得了很好的效果,为通过声纹特征识别PD患者提供了基础.Lucijano Berus等[13]使用原始音频数据[8]输入到人工神经网络(Artificial Neural Network,ANN)微调后进行分类,但直接处理语音信号较复杂;师等[14]采用Alexnet对语谱图分类,在数据集[8]上达到86.67%的精确度.将语音信号转换为语谱图,可以利用神经网络识别并提取与研究目标相关的重要声纹特征以自动对图像进行分类.目前,最受欢迎的卷积神经网络(Convolutional Neural Network,CNN)VGGNets中的VGG16模型是用于图像识别和分类的主要工具.VGG16具有拓展性很强、泛化性好等优点,在其他领域的图像数据集上达到很好的效果,作为一种数据驱动模型,依赖大量样本.但现阶段用于帕金森研究的音频数据少且样本获取困难,导致深度学习算法过度拟合,达不到好的效果[15].因此,采用深度学习算法诊断帕金森病时,样本扩充是亟待解决的问题.
生成对抗网络(Generative Adversarial Network,GAN)被Goodfellow等[16]提出以来,产生诸多变体并被应用于半监督和监督学习领域的图像处理或合成等工作.目前成熟的GAN框架深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network,DCGAN)[17]通过合成或生成图像数据进行样本扩充,已经应用于半监督学习领域的高光谱图像分类[15],肝脏病变分类[18]以及合成人工脑电图信号(electroencephalographic,EEG)[19]等领域.但是DCGAN生成高分辨率图像时易发生模型崩溃,训练不稳定问题导致生成效果差.本文将DCGAN模型引入到声纹识别领域,提出了一种基于DCGAN和特征匹配方法的高分辨率深度卷积生成对抗网络(High Resolution Deep Convolutional Generative Adversarial Network,HR-DCGAN)模型.首先将语音信号转换为语谱图,利用语谱图联合时频分析方法,采用HR-DCGAN-VGG16混合模型对小样本扩充,并应用到帕金森患者的识别工作中,与无样本扩充相比,提高了小样本下的PD患者识别准确率,并比较了不同扩充系数下达到的识别效果.
2 小样本帕金森识别模型
利用HR-DCGAN模型扩充样本,VGG16提取声纹特征并进行分类识别,本文构建了小样本帕金森识别模型如图1所示.首先将原始语音信号转换为语谱图,经HR-DCGAN模型生成PD患者和健康人的语谱图,根据SSIM指标筛选语谱图用于扩充数据集,扩充样本和原始样本输入到VGG16模型进行分类,实现帕金森识别.
2.1 语音信号预处理及语谱图原理
由于环境背景噪声,发音器官与音频采集设备产生的混叠干扰、谐波失真等,采集到的语音信号质量参差不齐,因此对原始的语音信号进行预处理是必要的,且是影响识别准确率的重要过程.预处理包括预加重、分帧、加窗和端点检测四个过程[10].经预处理后,本文将语音信号转换为语谱图,作为二维图谱可以联合时频分析方法提取谱特征.像素灰度值表示对应时间和频率的语音能量信息,并且语谱图可以保留更多的高频信息并更好地呈现参与者的声纹,尤其是其中所包含的声纹特征信息如频谱,基音,共振峰等.另外,可直接提取语谱图中的声纹特征,解决了传统谱特征中相邻帧之间相关性被忽略及特征冗余问题.
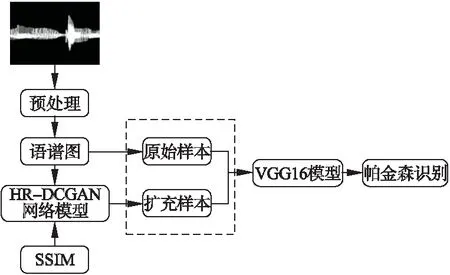
图1 小样本帕金森识别模型Fig.1 Parkinson′s Disease recognition model with a small number of samples
语谱图的生成过程步骤如下:
1)对预处理后的语音信号进行傅里叶变换[14],如公式(1)所示.
(1)
其中w(n)是窗函数类型,本文采用汉明窗.Xn(ejw)是关于w和n的函数.
2)令w=2πk/N,(0≤k≤N-1),N代表快速傅里叶变换(Fast Fourier Transform,FFT)的点数,对每一帧信号做FFT,得到短时傅里叶变换如公式(2).
(2)
3)计算短时功率谱Sn(ejw).
Sn(ejw)=Xn(ejw)·Xn(ejw)=|Xn(ejw)|2
(3)
其中:
Rn(k)为x(n)的短时自相关函数,Sn(ejw)为Rn(k)的傅里叶变换.n,w分别为横纵坐标,Sn(ejw)的值为点(n,w)的像素灰度级表示.
4)灰度图映射:依次连接每帧的灰度级表示,便生成灰度语谱图.为提高图像内容的可辨识度,采用Matlab2016a中的伪彩色映射函数colormap(map)(其中map为采用的伪彩色映射矩阵,默认为jet)进行功率谱伪彩色显示[20]便得到伪彩色语谱图.
为方便网络模型的处理以及更清晰地可视化语谱图的共振峰、基频和谐波的变化,本文采用分辨率为256×256×3的语谱图进行研究.图2为健康人和PD患者发出元音/a/时的窄带语谱图.健康人的语谱图其谐波的变化范围为(0,16000),基频区域纹理清晰,中高频区域噪声极少且谐波纹理规则.PD患者的语谱图其谐波变化范围为(0,6000),语音能量主要在基频附近和中低频区,高于2000Hz左右的高频区域谐波纹理分布不连续,出现断裂和消失,共振峰不完整,高于6000Hz的谐波基本消失.相比传统的时域序列或频谱特性,PD对声音系统造成的损伤更好的呈现在语谱图上.两者的明显区别在于谐波的范围,中高频区谐波分布是否连续有规则,共振峰是否完整,噪声是否增多.
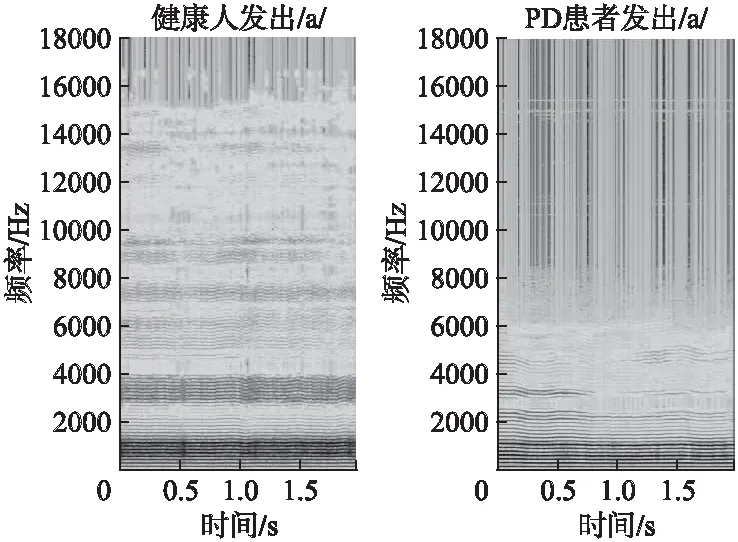
图2 健康人和PD患者发出元音/a/时的语谱图Fig.2 Spectrogram of healthy people and PD patients who are pronouncing the vowel /a/
综上,语谱图表现的不同特征信息对于PD患者和健康人有较好的区分度.另外,通过处理语谱图间接地处理语音信号,能够利用GAN强大的图像生成能力,并且避免GAN直接处理连续语音信号的复杂性难题.同时利用语谱图联合时频分析方法,以提取到时域和频域的声纹特征,比传统的MFCC、HFCC保留更多有用信息,保证较高分类精度.利用GAN擅长生成更注重纹理而没有结构限制的图像类别的优势[21],所以能更好的捕捉语谱图的纹理特征.
2.2 网络结构
2.2.1 GAN原理
GAN由生成器G和判别器D构成,根据对抗思想采用极大极小策略无监督的生成新图像.生成器的目的是输入服从概率分布Pz(均匀分布或高斯分布)中采样的随机噪声矢量z,不断学习真实训练样本x的分布,输出近似于真实样本潜在分布的假样本G(z).判别器的实质是分类器,输入G(z)或x,计算输入属于Pdata的概率,判断输入来自真实样本Pdata还是假样本G(z).两者对抗训练并交替更新D和G的参数,最大化D区分度的同时最小化G(z)和Pdata之间的数据分布误差,最终达到纳什均衡.当D无法正确估计出输入是来自于G(z)还是Pdata时,G能够拟合真实样本的分布.GAN的损失函数[16]如下:
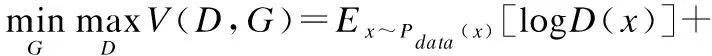
(4)
由于GAN在训练时不稳定,因此本文采用DCGAN模型.它具有特定的架构约束并且D和G均采用CNN结构,适用于图像处理任务.DCGAN能够无监督的学习表征,用于有监督学习[17].最初的DCGAN模型用于生成分辨率为64×64的图像,随后在分辨率为28×28的MNIST数据集以及分辨率为32×32的CIFAR-10数据集上能够生成高质量的样本.目前,DCGAN依据其结构优势能够为广泛的数据集提供相对稳定的训练.本文构建更深的DCGAN网络结构,结合特征匹配方法,提出HR-DCGAN模型,以构建更深入的生成模型,提高模型在生成高分辨率的语谱图图像时的生成能力和稳定性.
2.2.2 HR-DCGAN模型的网络结构
HR-DCGAN模型中G和D的架构设计是基于DCGAN模型结构以适应分辨率为256×256×3的语谱图.通过增加G的网络层数,逐层增加生成图像的尺寸,其变化过程为4×4→8×8→16×16→32×32→64×64→128×128→256×256,最终生成高分辨率的语谱图.D网络根据输入图像的大小,增加网络层数以适应解卷积过程中高分辨率图像的逐层下采样,其特征图的变化过程为256×256→128×128→64×64→32×32→16×16→8×8→4×4.为提高模型生成高分辨率图像时的稳定性,本文引入特征匹配方法.特征匹配指生成器产生的“伪”样本与真实样本通过判别器卷积层时输出的特征图尽可能相同[22].添加到生成样本的过程中,阻止D过度训练的同时,促进G捕捉语谱特征图中的纹理信息,生成与真实样本的统计数据近似的“伪”样本.
设f(x)为判别器网络中间层输出的特征图,最小化G和D特征图之间的误差,目标函数为:
min(w)=‖Ex~pdataf(x)-Ez~pzf(G(z))‖2
(5)
D的损失函数不变,按预设的方式最大化判别网络输出.G的损失函数变为训练时生成“伪”样本的误差和特征匹配过程的误差,公式如下:
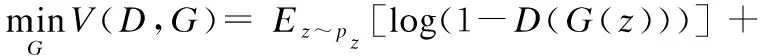
(6)
HR-DCGAN中的G和D的网络模型图如图3所示.本文采用伪彩色语谱图,所以G的输出和D的输入为三通道.另外,G和D在第一个卷积层的维度设置为64,在第一个全连接层的维度设置为2048.
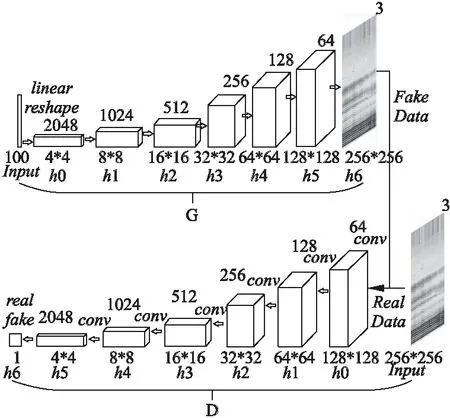
图3 HR-DCGAN的网络架构Fig.3 Network architecture of HR-DCGAN
如图3所示,G包含7层网络,将服从高斯分布的100维向量作为噪声z输入,用上采样到4×4空间范围的卷积表示,其具有2048个特征图,产生4×4×2048张量.h0~h5层为微步幅卷积层,包括5×5的卷积核大小,步幅为2,G的学习过程即进行空间上采样.经批量标准化(Batch Normalization,BN)后[17],每个隐层的单元都通过归一化为零均值和单位方差,以此来稳定学习过程,解决了因初始化不良导致的生成模型崩溃问题,使梯度能更深层次传播.然后采用Relu激活函数进行激活.每经过一个微步幅卷积层,生成的特征图的尺寸加倍,数量减半.h6层为tanh函数激活,最终输出256×256×3的语谱图图像,并作为D的“伪”数据的输入.
D包含7层网络,h0~h5为卷积层,采用5×5卷积核,步幅为2.所有层均有BN层和leakey Relu激活函数的非线性映射,D的输入层除外.卷积层对输入的语谱图进行特征提取,每经过一个卷积层进行下采样,特征图的尺寸减少一半,数目加倍.h6层利用Sigmoid激活函数判别真实样本和生成的“伪”样本,其输出表示输入图像是来自真实样本的概率.
本文的HR-DCGAN模型中G和D的网络层数加深,并添加了特征匹配项的约束.分别将不同类别的原始语谱图输入到HR-DCGAN模型,以适应其无监督式的训练过程,生成具有相似纹理特征的高分辨率样本扩充原始数据集.
2.2.3 分类器设计
PD患者的声纹识别过程包括声纹特征提取和分类,本文直接将原始语谱图样本和经样本扩充后的训练样本分别添加类别标签后输入到VGG16中,自动提取声纹特征并分类.本文采用的VGG16模型由3×3的卷积核和2×2的最大池化层构成,共13个卷积层和3个全连接层[23].相比8层的Alexnet网络,其采用较小的卷积核,堆叠多层卷积层增加了网络深度,以提取更深层次的声纹特征,增强网络的拟合能力.本文采用迁移学习的思想,利用基于ImageNet数据集预训练好的VGG16模型参数,保留前13层并释放后3层的权重,微调后进行特征提取和分类.本文的VGG16模型图如图4所示.
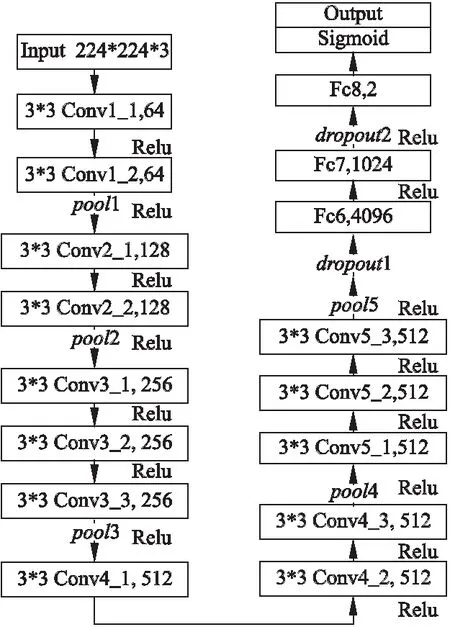
图4 VGG16模型结构图Fig.4 Structure of VGG16 model
为适应VGG16输入层的要求,采用python的pillow库中crop操作,设定固定的裁剪区域将256×256分辨率的语谱图统一裁剪为224×224,再输入到卷积层.具体方法如下:
已知pillow坐标系统的原点(0,0)位于图像的左上角,坐标中数字的单位为像素点.裁剪区域表示为(xmin,ymin,xmax,ymax),其中(xmin,ymin)为图像左上角的横纵坐标,(xmax,ymax)为图像右下角的横纵坐标.由于语谱图的基音频率、谐波等纹理信息都集中在中低频区即语谱图的中下部和底部区域,高频区域含有的有用信息较少,所以本文将裁剪区域设为(32,32,256,256).裁减掉位于语谱图顶端和左侧边缘区域的影响较小或无用的信息,保留语谱图底部区域有效特征信息,使裁剪后的语谱图最大化保留声纹特征信息,便于输入到网络的同时,也能对网络性能和输出准确率影响较小.
由于本研究进行二分类,修改VGG16的Fc7层的输出神经元个数为1024个和Fc8层的输出神经元个数为2个.由于训练的特征数量非常大,容易使训练出的模型过拟合.本文在最后一个池化层和Fc7全连接层后加入Dropout层[18],并将Dropout率设为0.5,改变网络架构以抑制过拟合问题.通过模型训练对前13层的权重进行微调,更新全连接层的权重,实现对语谱图的分类识别.
采用训练的VGG16模型预测测试集的标签,根据准确度(Accuracy,ACC),特异性(Specificity,SPE)和灵敏度(Sensitivity,SEN)指标[11],评估分类器的分类结果,从而评估所提出的算法的性能.通过HR-DCGAN样本扩充后,再利用VGG16分类识别的网络模型称作HR-DCGAN-VGG16混合模型.
2.3 样本扩充的选取标准
评估GAN生成的图像的质量是一项复杂的工作,且通过主观视觉评估和选取样本的方法实践困难、说服力差.本文将结构相似度(Structural Similarity Index,SSIM)指标作为生成的语谱图样本的选取标准,以判断是否用于扩充训练样本.
SSIM公式[24]如下:
(7)
其中,μx,μg,σx,σg分别为真实图像x和生成图像g的像素值的均值和方差,σxg为x和g的协方差.c1=(k1*L)2,c2=(k2*L)2是用于维持稳定的常数,L=255是图像像素值的最大值,k1=0.01,k2=0.03.
SSIM的值域为[0,1],其值的大小与两个图像在像素级别的相似度成正比.由于语谱图图像的像素间存在很强的相关性,这些相关性携带着与语音信号的能量以及共振峰、谐波等声纹特征相关的重要信息.因此,SSIM指标能够表示生成图像和真实图像的相似度.为选取高相似度的语谱图样本,本文设置SSIM的阈值为0.85,通过计算生成的语谱图和原始语谱图样本之间的SSIM,当SSIM指标的值大于或等于阈值时,可用作样本扩充,否则不用作样本扩充.
3 实 验
3.1 实验设备
实验环境配置如下,64 bit Windows10操作系统,CPU为Intel(R)Core(TM)i7-7800X 3.50GHz,内存16GB,GPU为NVIDIA GeForce GTX 1080 Ti,显存为11GB,CUDA 9.0和cuDNN 7.0加速包支持.软件要求:Python3.6.6,Tensorflow1.10.0框架,Matlab2016a.
3.2 数据集介绍及预处理
本文采用UCI数据集,由Sakar等人收集[8],训练集包括20名PD患者(6名女性和14名男性)和20名健康人(10名女性和10名男性)发出/a/,/o/和/u/三种元音的语音信号,共120个语音样本.PD患者的诊断时间介于0至6年之间,年龄在43岁至77岁之间.健康人的年龄在45岁至83岁之间.测试集包括28名PD患者发出/a/,/o/两种语音信号,共56个语音样本.患者的诊断时间介于0至13年之间,年龄在39至79岁之间.录音设备为 Trust MC-1500 麦克风.参与者的每个/a/,/o/和/u/语音样本中包含3次连续的发音,每次发音过程持续6s的时间.所有的语音记录都为立体声模式和wav格式.
数据集共计176个语音信号.分别将每次发音分割成时间为2s的语音片段,所以一个wav格式的语音文件可以分割为3个2s的语音片段,包括原始语音片段,可以将数据集初步扩大四倍.再对每个语音片段利用Matlab2016a进行语音信号预处理后分别生成256×256×3分辨率的JPEG格式的语谱图.已知语音信号的采样频率为44.1kHz,本文将NFFT点数设为2048,帧长为46.44ms,帧移为帧长的1/4,帧重叠部分取为帧长的3/4,此时生成的语谱图谐波纹理清晰且声纹特征明显,参数设置如表1所示.
表1 语音信号转换为语谱图的参数设置数据表
Table 1 Parameter settings data table for extracting speech signals into spectrogram
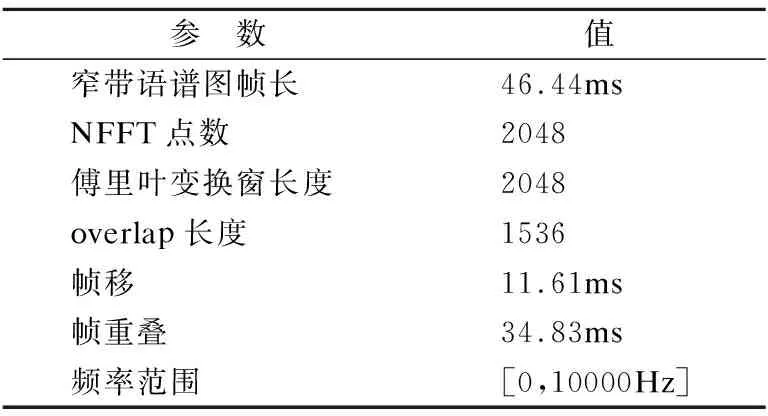
参 数值窄带语谱图帧长46.44msNFFT点数2048傅里叶变换窗长度2048overlap长度1536帧移11.61ms帧重叠34.83ms频率范围[0,10000Hz]
原始数据集共704张语谱图,并添加one_hot编码格式的类别标签.健康人和PD患者的语谱图对应的标签分别为“01”,“10”.
3.3 网络训练
3.3.1 HR-DCGAN模型的训练
分别用PD患者的语谱图样本和健康人的语谱图样本训练HR-DCGAN模型.均值为零,标准差为0.02的高斯分布作为G的输入并初始化网络权重,本文采用批量随机梯度下降算法(Stochastic Gradient Descent,SGD)训练,Batch size设置为16,Leaky Relu的斜率为0.2,用Adam优化器调节超参数,learning rate为0.0002,momentum termβ1设置为0.5时可以稳定训练.D训练两次,G训练一次,Epoch数目设置为600.每隔10个Epoch输出一次SSIM的平均值,作为选取扩充样本的标准.
3.3.2 VGG16模型的训练
本文首先按7∶3的比例将704张带标签的语谱图划分为训练集和测试集,Batch_size设置为16,迭代次数为1000,微调添加Dropout层的预训练模型VGG16以实现自动特征提取和分类.将选取SSIM值大于等于0.85的生成语谱图并添加标签,用于扩充训练样本.根据SSIM值首先取第110,150,200,220,240,300,320,350,400,450 Epoch下的生成语谱图将数据集扩大10倍后,按照7∶3划分训练集和测试集,统一裁剪后输入到VGG16模型进行识别和分类.
根据不同Epoch下的SSIM值,选取高相似度的生成语谱图,将数据集扩大不同的倍数分组训练VGG16模型,对比不同样本扩充系数对PD识别结果的影响.样本扩充系数在1~30倍之间,并比较分类结果.
4 实验结果与分析
4.1 可视化HR-DCGAN模型的生成结果
首先,本文可视化了HR-DCGAN模型训练的结果.对PD患者和健康人的语谱图训练过程中g_loss,d_loss前期出现震荡,最终分别稳定收敛到1.08027147和1.38497926,1.00317682和1.29376531.随机取不同Epoch下的生成图像,部分生成结果如图5、图6.其中(a)~(h)表示HR-DCGAN模型训练时Epoch的数字顺序.

图5 不同Epoch下生成的PD患者的语谱图Fig.5 Generated PD patients′ spectrogram after different epochs
由图5和图6可以看出,第 0 Epoch时,生成的全是噪声点和语谱图的色彩轮廓;第50 Epoch 生成基音频率和共振峰位置明显但纹理模糊的图像;第100 Epoch 时,基音频率和共振峰较清晰;第200 Epoch时,语谱图的谐波纹理清晰,基频和中高频噪声平滑;第300、400 Epoch时,可看出共振峰是否完整和各次谐波的分布,纹理更加清晰;第500、599 Epoch时,共振峰突出,谐波纹理较清晰.由不同Epoch下的语谱图可以看出模型收敛速度较快,肉眼可见生成的语谱图质量稳定提高.
然后根据SSIM的阈值选取高相似度的生成语谱图添加标签后用于扩充样本,由于训练前期网络的生成效果不好,所以前100 Epoch的生成图像不予考虑.100 Epoch后,PD患者和健康人的生成语谱图和原始语谱图计算得到的SSIM值范围为0.7835~0.9374,由于训练前期训练不收敛以及语谱图中共振峰和谐波等声纹特征的位置、范围和结构的多样变化,以及噪声的平滑化引起像素值的变化,导致SSIM值不稳定.随着网络逐渐稳定,SSIM值大多数处于0.85~0.90之间,表明HR-DCGAN生成的语谱图样本在纹理、颜色、色彩对比度等方面和真实样本相似.并且模型的测试结果显示纹理清晰且声纹特征明显的分辨率为256×256×3的语谱图.因此通过对抗学习和特征匹配不断提高特征的质量,能够较好的保留语谱图中的声纹特征,训练和测试结果表明HR-DCGAN模型在生成高分辨率语谱图的稳定性.

图6 不同Epoch下生成的健康人的语谱图Fig.6 Generated healthy people′s spectrogram after different epochs
4.2 分类识别
在分类训练和测试阶段,在相同数据集下,分别将VGG16网络直接处理语谱图提取声纹的特征提取方式与MFCC[10]、HFCC[11]对比,并与KNN、SVM、ANN[13]、Alexnet[14]分类器比较,最后进行有无样本扩充的对比;针对VGG16模型讨论不同样本扩充系数的对比.
当没有样本扩充时,传统的HFCC特征提取方法结合SVM分类器优于采用神经网络的分类方法,表明传统机器学习方法在小样本下的适用性,但分类性能取决于特征选择和分类器选择,而提取特征时倒谱系数的选择、分类器核函数或聚类中心k的确定过程复杂.而语谱图作为图像可直接被神经网络处理,同时提取到时频域的声纹特征并实现分类.由于初始样本有限且VGG16网络需要大量训练样本驱动,Dropout层在一定程度上抑制过拟合,仅达到77.5%的准确率,其低于利用ANN和Alexnet分类的识别准确率.样本扩充后,VGG16网络中的Dropout层达到一定的正则化效果,加快CNN的收敛速度,且精度较高,准确率增加到90.5%.因此本文的HR-DCGAN模型通过扩展训练样本的数量,加强了分类器的训练,进一步提高了模型泛化性能.通过与其他特征提取方式和分类方法对比,对有无样本扩充的语谱图分类发现,
表2 有无样本扩充的模型分类结果
Table 2 Model classification results with or
without sample augmentation

特征提取分类器ACCSENSPEMFCCMLP核SVM82.5%80%85%HFCCLIN核SVM87.5%9085HFCCKNN(k=5)73.75%75%72.5% ANN86.47%88.91%84.02% Alexnet86.67%90%83.34% VGG1677.5%80%75% HR-DCGAN-VGG1690.5%91%90%
HR-DCGAN生成的高分辨率语谱图图像进行样本扩充的有效性,VGG16自动提取语谱图的声纹特征的能力和分类性能在大量数据驱动情况下的优越性.不同模型分类性能对比以及有无样本扩充的分类器性能对比,如表2所示.HR-DCGAN-VGG16模型在不同样本扩充系数下进行训练和测试,对语谱图的分类识别准确率对比如图7所示.样本扩充系数为0~10倍时,随着训练样本的增加以及Dropout层的使用,逐步解决VGG16深层网络的过拟合问题,对PD患者和健康人的语谱图的分类结果得到显著改善.当扩充系数为10时,达到最高的识别准确率90.5%.继续增加训练集样本,当扩充系数为10~30倍时,识别准确率不再继续增加,达到饱和度约90.5%.由于有限样本中语谱图的特征有限,再添加更多的生成样本未能继续改善分类效果.

图7 HR-DCGAN-VGG16模型在不同样本扩充系数下的识别率的分布Fig.7 Distribution of recognition rate with HR-DCGAN-VGG16 model under different sample augmentation factors
实验结果表明,HR-DCGAN-VGG16混合模型能够对PD患者和健康人的语谱图实现样本扩充、特征提取和分类,获得最佳识别准确率为90.5%,其优于无样本扩充的ANN、Alexnet和其他传统的机器学习方法.所以在小样本情况下,一方面可以通过HR-DCGAN模型的对抗学习策略和特征匹配方法,提取语谱图纹理特征并生成高分辨率图像,结合SSIM标准作为一种样本扩充的方式,弥补采用深度学习方法进行PD患者识别诊断时音频样本的不足;另一方面,原始数据集进行特定倍数的样本扩充后,输入到深层的CNN如VGG16模型中提取特征并分类,有效防止过拟合的同时也能够提高分类精度和帕金森的识别率.
5 结束语
PD患者和健康人的语谱图具有显著性差异,对其采用联合时频分析方法解决了传统的特征提取方式参数选择复杂以及特征缺失和冗余问题.HR-DCGAN模型能生成高分辨率的语谱图样本且训练过程稳定,通过设置SSIM阈值保证了样本扩充的有效性.Dropout层优化VGG16模型改善过拟合的同时提高了网络收敛速度和泛化性能.实验结果表明,在小样本下,本文提出的HR-DCGAN-VGG16混合模型得到最佳的分类识别准确率,说明了PD数据集采用GAN进行样本扩充的可行性和有效性.此方法可有效改善小样本下声纹识别率低的问题,提高了帕金森筛查率.未来的工作将继续深入研究不同的样本扩充方法并改进分类识别方法,专注于改善在小样本下对帕金森病的识别准确率.
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
通信产业报(2018年32期)2018-11-24 10:37:58
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
东南大学学报(自然科学版)(2015年5期)2015-03-15 00:54:56
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:11
祝您健康(2009年4期)2009-04-08 09:36:06
