
一种基于混合页面的磁盘缓存去重策略
2019-09-09 03:45:10邓玉辉
小型微型计算机系统 2019年9期
斯 雷,邓玉辉,2
1(暨南大学 信息科学技术学院,广州 510632)2(中国科学院 计算技术研究所 计算机体系结构国家重点实验室,北京100190) E-mail:tyhdeng@jnu.edu.cn
1 引 言
缓存机制在计算机各级存储系统中广泛存在,主要是利用数据的时间局部性和空间局部性缓解高速和低速存储设备间的性能差异[1].磁盘内部的缓存,表现为磁盘控制器上的一块RAM芯片,在磁盘低速盘片和高速外部接口之间起到缓冲的桥梁作用.研究表明,磁盘缓存大小设置为磁盘容量的0.1%至0.3%时,能够达到最好的效果[2].缓存命中率是衡量缓存好坏的重要指标,通过改变页面大小,最大化磁盘缓存的命中率具有重要意义.传统内存及磁盘缓存的页面大小多为固定的4K大小,而随着计算机的发展,许多处理器和操作系统已经能够完全支持混合页机制.例如,X86平台能够支持2M和1G的巨页大小,ARM平台能够支持1M和16M的巨页大小(1)http://en.wikipedia.org/wiki/Page(computer_memory).
巨页的引入,一方面能够使相同容量的快表(TLB)容纳更多的内容,增加TLB命中率,极大地减少了由于TLB未命中而带来的性能开销.研究[3,4]表明,TLB未命中是导致虚拟化系统和裸机之间性能差异的主要原因,也成为了内存访问的主要瓶颈之一.另一方面,页面大小也是影响缓存命中率的重要因素,巨页能够扩大传统缓存的页面大小,最大化缓存的命中率.巨页是由固定数量的连续基页组成,例如在X86 64位系统中,2M大小的巨页是由连续的512个4K大小的基页组合而成.随着页面变大,页表项变得更少,相同大小的TLB就能容纳更多的内容,从而提高TLB命中率.在虚拟环境中,对于TLB未命中所产生的二维页表遍历,随着巨页的引入,能够将其最大引用次数从24减少到15[5].Guilherme[6]提出一种节能型组相联结构的混合快表MIX TLBs,通过巨页分配机制能够同时支持多种页面大小,并提高性能达10%-30%.
传统基于LRU算法的缓存系统,并不能感知磁盘缓存中的重复数据,导致缓存中存在大量的冗余数据块,这对于磁盘中宝贵的缓存空间而言是巨大的浪费.Castro[7]提出采用数据压缩的方法,减少内存交换频率以节省缓存容量.然而,对于压缩算法而言,其本身就需要大量的计算开销,当压缩率很低的时候不仅无法节省空间还会引入许多额外的计算和时间开销.CacheDedup系统[8]采用重复数据删除技术对缓存进行去重操作,在缓存中只保留唯一的数据块,大大节省了缓存容量,并进一步提出了去重感知的D-LRU、D-ARC缓存替换算法.
值得注意的是,巨页对于去重也有一定的影响.传统针对基页的完全去重能够消除磁盘缓存中的冗余数据,但随着页面变大,完全重复的巨页将变得越来越少,去重率将会变得越来越低.为了实现有效的去重,当前许多操作系统主要采用主动去重方法ADA(Aggressive Deduplication Approach),该方法主动地将巨页拆分为基页,然后在基页之间进行去重操作[9],例如Linux系统中的KSM.文章[10]实验结果表明,ADA方法能够节省13.7%~47.9%的内存空间,而以巨页为单位的去重仅能节省0.8%~5.9%的空间.虽然ADA方法节省了更多的存储空间,但对于拆分的巨页进行访问会显著减少TLB的命中率,降低了访问性能.并且,当前许多操作系统并不支持对已拆分巨页进行重构.Fan Guo等人提出了一种基于混合页的内存去重方案SmartMD[10],此方案通过利用去重技术最大限度节省内存容量,同时保持了内存的高访问性能.
针对上述问题,本文提出了一种基于混合页面的磁盘缓存去重策略.首先,在磁盘缓存中引入混合页机制.在保留基页的同时,引入巨页,自适应地调整巨页的大小以使缓存命中率最大化.其次,对基页和巨页进行动态转换.设置监视程序动态检测巨页的冷热程度,将重复率高的冷巨页拆分为基页,以提高缓存去重率,最大限度节省缓存容量;同时,当拆分后的巨页变热时,对其进行重构操作,以提高缓存的命中率以及访问延迟,使命中率和去重率均达到相对最优.最后,利用去重技术对缓存进行去重操作.将LRU缓存替换算法与重复数据删除技术相结合,对基页和巨页分别进行去重操作,在缓存中只保留唯一的数据块,进一步节省缓存容量.
本文剩余内容组织如下.第二部分,介绍了相关背景知识,主要包括混合页机制和缓存去重的相关概念.第三部分,详细描述了本文所提出的基于混合页面的磁盘缓存去重系统整体设计架构.第四部分,通过对真实数据trace进行仿真实验,得到相关实验数据并进行评估与分析.第五部分,得出结论并进行总结.
2 背景知识
2.1 混合页机制
页面大小是由所用处理器体系架构决定的,传统的系统架构通常只具有统一的页面大小,例如为4K大小.然而随着计算机的发展,现在的体系结构大多都能很好地支持多种页面大小,如表1列举出了常见体系结构下的混合页面大小.系统的页面大小越小,则页面的个数就越多.例如,对于32位的虚拟地址空间映射到4K大小的页面,则虚拟页面个数为220(232/212),而当页面大小调整到64K时就只需要216(232/216)个页.程序每次访问内存,从虚拟地址转换为物理地址,需要先访问TLB,而TLB未命中造成的二维页表遍历的代价异常高,达到6倍的页表查找和内存访问,并且随着主存容量的增加代价越来越高[11-14].混合页机制引入巨页后,增大了页面大小,使得相同大小的TLB能够存放更多的页,映射到更多的内存空间,极大地提高了TLB的命中率.并且混合页机制能够自适应地调整缓存中的页面大小,从而使缓存命中率达到最大.
表1 常见体系架构下的混合页面大小
Table 1 Page sizes among architectures
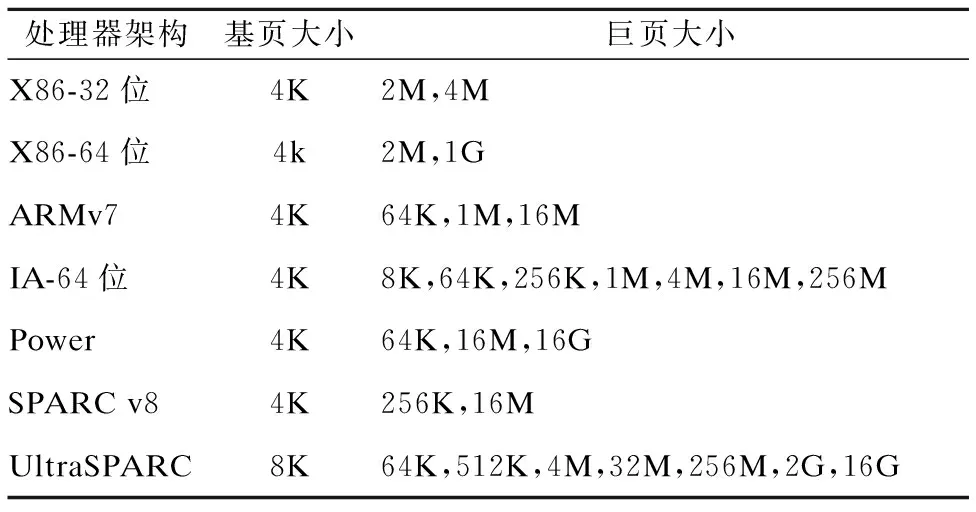
处理器架构基页大小巨页大小X86-32位4K2M,4MX86-64位4k2M,1GARMv74K64K,1M,16MIA-64位4K8K,64K,256K,1M,4M,16M,256MPower4K64K,16M,16GSPARC v84K256K,16MUltraSPARC8K64K,512K,4M,32M,256M,2G,16G
2.2 缓存去重操作
消除缓存冗余数据的主要技术手段是数据压缩[15-17]和重复数据删除[18,19].数据压缩主要是针对原始数据采用更少的位对其进行重新编码,以达到优化存储空间的目的,常见的主流压缩算法有LZ77、LZSS、LZ78和LZW四种.但当页面压缩率很低的时候,由于引入了大量额外的计算开销从而导致不仅无空间节省的收益,反而付出了巨大代价.
重复数据删除技术则避免了这一弊端,通过对缓存空间进行去重检测,筛选出完全相同的数据块并进行删除操作,在缓存中只保留唯一的副本,从而消除缓存中的冗余数据,节省缓存空间.去重技术按照去重粒度可分为字节级去重、块级去重和文件级去重,其中字节级去重主要是利用Delta编码来识别重复数据,而块级和文件级则主要是利用哈希算法(如MD5和SHA-1)来识别相应的重复数据块.去重过程主要包括数据块切分、指纹计算和数据块检索,首先将数据按照固定大小分割为数据块,并为每个数据块计算指纹,然后将指纹作为关键字进行Hash比对,若匹配成功则为重复数据块,最后进行去重操作.
传统基于LRU替换算法的磁盘缓存系统,并不能有效识别缓存中的重复数据,导致缓存中存在大量冗余数据.在这种情况下,文章[8]提出了一种新颖的缓存去重方案,将数据缓存与去重元数据(包括源地址信息和数据指纹信息)相结合,有效地对这两个组件进行管理.并在此基础上提出了去重感知的缓存替换算法,显著提高了缓存命中率并降低了延迟.
3 系统结构设计
3.1 核心思想
本文提出的混合页磁盘缓存去重策略,其主要思想是在磁盘缓存中引入混合页机制,这种缓存中的混合页一方面能够很好地适配大规模应用程序所采用的巨页机制,另一方面能够针对不同的应用负载自适应地动态调整缓存页面的大小.最佳的页面大小能够提高缓存命中率,该缓存系统通过混合页机制动态调整巨页大小,使页面大小调整为一个合适值,从而让缓存命中率达到最大.其次,将混合页机制与重复数据删除技术相结合,去除缓存中的冗余数据,提高缓存利用率.
我们在传统的磁盘缓存中增加了巨页产生器、页面监视器以及去重组件.巨页产生器主要用于生成巨页,将连续的基页进行合并,生成相应巨页.页面监视器用于检测巨页和基页的冷热程度,并决定是否将巨页进行拆分或将已拆分的基页进行重构.去重组件在缓存写入磁盘之前进行去重操作,在缓存中只保留唯一的副本
3.2 详细设计
图1给出了混合页磁盘缓存去重系统的详细设计图,整个系统的关键技术在于两个方面.其一,如何在基页与巨页之间进行动态转换.基页大小由操作系统所决定,巨页大小需要根据实际的应用负载进行调整,而巨页、基页之间的转换则需要实时地监测页面的冷热程度.其二,如何将混合页机制与重复数据删除技术有效地结合.加入混合页机制后,去重难度将进一步增加,巨页、基页都需要进行去重操作才能最大限度节省缓存空间.
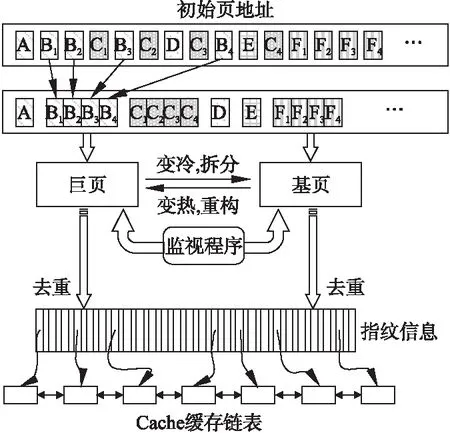
图1 混合页磁盘缓存详细设计图Fig.1 Detailed design of mixed page disk cache
为了解决以上问题,混合页磁盘缓存去重系统主要分为如下三个部分:
1. 将连续基页合并为巨页.
2. 监视基页和巨页,并进行动态转换.
3. 将调整后的基页和巨页进行去重操作.
首先,根据初始页地址,将地址连续的基页合并为大的巨页.巨页的大小是统一的,主要根据应用程序负载情况动态确定,例如当巨页大小设置为2M时,一个巨页是由512个地址连续的4k大小基页合并而成,若存在超过512个连续的基页则进行合并,否则保持原有基页.然后,监视程序开始工作,检测巨页和基页的冷热程度.将那些访问频率低的冷巨页拆分为基页,这样有利于对拆分的巨页进行去重操作,提高去重率.同时,当这些拆分的巨页变热时,再对其进行重构操作,以提高缓存命中率和访问延迟.最后,对调整后的基页和巨页分别进行数据指纹的比对,以确定是否为重复的数据块,从而进行重删操作
3.3 混合页动态转换
混合页机制中有巨页和基页之分,它们的各字段也不尽相同.标志位tag用1个bit位来表示,用以标识该页是基页还是巨页,当该页为巨页时tag等于1,否则tag为0.start_addr字段表示巨页的起始地址,size字段表示巨页的大小,基页并没有此字段,这是因为基页在程序执行前就已经由操作系统决定,是一个固定值,在我们的实验中该基页大小为4K.巨页由连续的基页组成,并且内部对每个基页都进行了编号.基页地址转换并未变化,因此对于组成巨页的每个基页,可以通过编号计算出页内偏移量,然后利用巨页起始地址得到巨页内部每个基页的地址.
在巨页产生器生成巨页后,监视程序开始工作,对巨页和基页进行冷热检测.基页和巨页都含有一个degree字段,初始值为0.某页被访问时degree进行自加,当degree大于1时表示该页被重复访问,将其视为热页,否则即为冷页.
算法1.混合页的相互转换
输入:Pagei∈InitialPage,i=0,1,2,…,n
1.fori=0;i≤n;i++ do
2. ifPageiisHugePagethen
3. ifPageiiscoldthen
4.BasePage←HugePage;//巨页拆分为基页
5. else
6. continue;
7. else
8. ifPageiishotthen
9.HugePage←BasePage;//基页重构为巨页
10. else
11. continue;
12.end
算法 1 描述了巨页和基页的动态转换过程.当所检测的页为巨页(由tag标志位决定),并且该页的访问频率较低时(为冷巨页),则将该巨页拆分为若干个连续的基页,并对每个拆分后基页的各个字段进行相应内容的填充,而当该页为热巨页时,则保留不进行操作.同理,当所检测的页为拆分后的基页,并且该页的访问频率变得越来越高时(变成了热页),则又将这些拆分后的连续基页进行重构操作,合并为巨页.值得注意的是,我们的程序并不是对每一个拆分的热基页都进行一次重构,而是将这些连续的热基页进行统一的重构操作,这样进一步提高了程序的效率,避免了多次冗余的重构操作
算法2.巨页大小自适应调节算法
输入:InitialHugePageSize;Pagei∈InitialPage,i=0,1,2,…,n
输出:HugePageSize;
1.whilehit_ratio>max_ratiodo
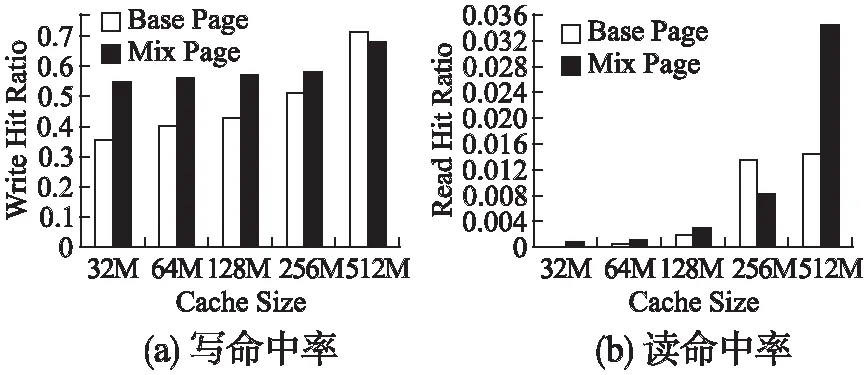
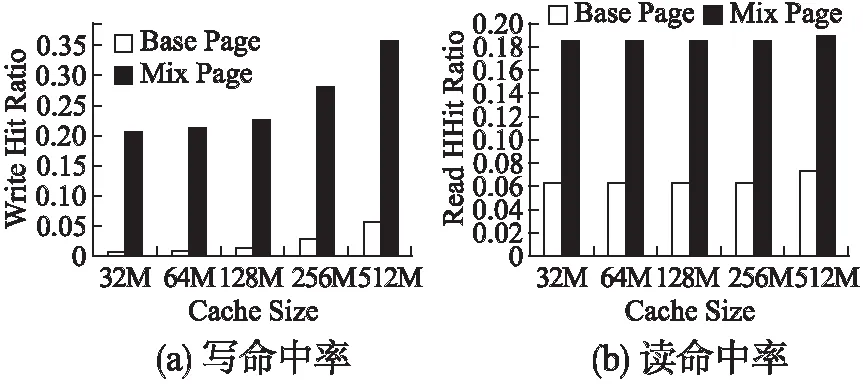
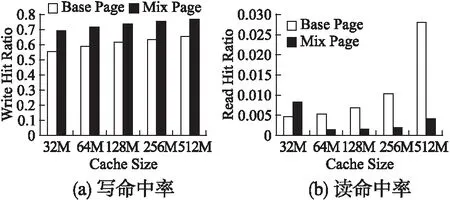
2. whilei 3. ifPageiisHugePagethen//巨页 4. whilej 5.Pagei[j].operator(); 6. //统计巨页命中率,并记录 7.j++; 8. end 9. else //基页 10.Pagei.operator(); 11. //统计基页命中率,并记录 12.i++; 13. end 14.HugePageSize*=2; //调整巨页大小 15. max_ratio=hit_ratio; //调整最大命中率 16.end 算法 2 描述了巨页大小的自适应算法.程序由初始页序列开始,若该页为巨页,则对组成该巨页的所有基页进行遍历,统计这些页的命中情况;若为基页,则无需遍历,直接统计该基页命中情况.之后根据命中数据,计算缓存命中率,并将该命中率与最大命中率进行比较.若该命中率就是最大命中率,则程序结束;否则继续调整巨页大小,使之成倍数增加.最终得到最佳的巨页大小. 为了消除混合页中的冗余数据,提高缓存利用率,我们将重复数据删除技术与混合页机制有效结合在一起.虽然传统基于LRU替换算法的磁盘缓存,实现简单,开销也很小,但却无法识别缓存中的冗余数据块,导致了对宝贵缓存空间的浪费.增加去重操作后,原来的地址映射关系从一对一变成了多对一,不再是源地址到Cache地址的一一映射,同一数据块将映射到多个源地址. 首先,我们采用固定分块的重复数据删除方法,利用MD5算法对数据块进行指纹计算,相应指纹对应于页面的hash值.其次,为了方便有效地对缓存数据进行管理,系统维护了两个缓存链表,分别是数据缓存(Data Cache)链表和元数据缓存(Metadata Cache)链表.其中数据缓存链表用以保存去重后的唯一数据块,而元数据缓存则用以保存页的访问顺序.当连续的基页合并为巨页后,该巨页所对应的hash值采用所有基页hash的均值表示.一方面,可以有效识别巨页,识别巨页利用标记位和hash值共同决定;另一方面,降低了hash值逐一比对的计算开销.数据缓存与元数据缓存通过指纹索引有效联系,当识别到重复数据块后,指纹索引计数器开始累加,以统计相同数据块出现的次数.对于多次出现的相同数据块,将其指向数据缓存中相应的唯一数据块,达到去重目的. 缓存中所采用的是较为简单的LRU页面替换算法,将最近最久未使用的页面替换出去.由于该实验主要与传统LRU磁盘缓存作对比,可比性较高,并且开销较小,易于实现.对于巨页和基页两种不同的页面信息,为了进一步提高缓存整体的去重率,使去重达到最好的效果,我们将其分别进行去重操作.当巨页、基页的拆分和重构操作完成后,去重工作开始执行.一方面,将冷巨页进行拆分后再执行去重,去重的粒度相对变小,能够识别更小粒度的重复数据页,提高去重率.另一方面,将变热的基页进行合并后再进行去重,避免了对每一个基页的单独操作,保证去重率的同时,减少了时间开销. 我们使用CentOS系统的服务器作为实验平台,其内核版本为Linux release 7.2.1511,处理器为Intel(R) Xeon(R) CPU E5-2403的4核CPU,主频大小为1.80GHz,内存为10GB,500GB大小的硬盘空间. 表2 实验数据集特征 名称工作集大小(GB)总I/O大小(GB)写/读比例唯一数据大小(GB)测试所用I/O数WebVM2.154.53.623.4185210Homes5.967.331.544.41961599Mail57.117418.1171.320382880 选用美国佛罗里达国际大学(FIU)收集的系统IO作为我们的测试数据集,表2列举了这些Trace数据的特征.其中WebVM收集于管理学院在线邮件代理和在线课程网站,Homes来自研究工作小组的日常活动(包括开发、测试、实验、绘图等操作),Mail则是从学院的电子邮件服务器收集得到.通过这些真实Trace记录,利用程序模拟了基于混合页磁盘缓存的工作过程.分别测试不同的磁盘缓存大小(如:32M,64M,128M,256M,512M)以及各种巨页大小(如:8K,16K,32K,64K等)下缓存的读写命中情况、延迟时间等参数.最终针对这些数据进行分析和处理,得到相应结论. 我们分别在三种不同类型的应用负载下测试了巨页大小对缓存读写命中率的影响.图5(a)给出了在不同磁盘缓存大小下(如:32M,64M,128M,256M,512M),各种巨页大小(如:8K,16K,32K,64K,128K,256K)所对应的写命中情况.对于实验所采用数据集类型,其巨页大小普遍偏小,在未达到MB级别情况下,命中率已经能够最大化.总的来说,随着缓存大小逐渐增加,缓存命中率呈现递增的趋势,在512M的缓存大小时达到最大命中率.同时,随着巨页大小逐渐增加,缓存命中率呈现先增加后减小的趋势,均会在某一个巨页大小命中率达到最大值.此时的巨页大小,就是程序自适应调节的最终结果,也是使命中率最大的最佳巨页大小.例如,对于WebVM Trace数据集,其巨页大小调节为16k;Mail Trace其巨页大小为64K;Homes Trace巨页大小为32K. 图5(b)呈现的是在不同磁盘缓存大小下,各种巨页大小相对应的读命中情况.总的趋势与写命中类似,但由于所选用的数据集中读请求相对写请求少得多,因此读命中率也相对较小.值得注意的是,对于同一个数据集,当写命中达到最大时,读命中并未达到最大,因为数据集中写请求起到主导作用,我们选择适应写命中.例如,对于Mail Trace数据集,最佳巨页大小任然为64K,此时读命中虽然并非最大化,却也最接近最大值. 命中率是衡量缓存优劣的重要指标,在磁盘缓存中引入混合页机制后有效提升了缓存的命中率.一方面,缓存命中率会随着缓存大小逐渐递增;另一方面,对于不同的巨页大小命中率也具有一定规律.我们对于三种不同的工作负载(WebVM、Mail、Homes),分别在最佳巨页大小的情况下,测试其读写命中率(如图2所示),并将其与传统只具有基页的磁盘缓存进行对比分析. 图2 不同巨页大小读写命中率的变化情况Fig.2 Changes in the hit ratio of different huge page sizes 图3 WebVM数据集,传统页与混合页读写命中率对比Fig.3 Comparison of hit ratio between base and mix page(WebVM) 图3表示的是对于WebVM数据集,混合页模式与传统磁盘缓存,在不同缓存大小下,其读写命中率对比情况.总的来说,混合页模式的磁盘缓存命中率均比传统磁盘提高许多,并随着缓存大小的增加呈递增趋势.例如,图3(a)中,其写命中率最高可提升53.6%;图3(b)中,其读命中率最高可提升2.36倍.此外,也具有一定的特殊情况,例如对于写命中率,当缓存容量增大至512M时,此时混合页模式的磁盘缓存写命中比传统磁盘略低,主要是因为对于512M的缓存大小,此时的巨页大小并非为最佳值,而是采用的近似值16K.而对于读命中率,当缓存大小增大到256M时,此时混合页模式的磁盘缓存读命中率略低.原因主要在于,采用混合页将连续基页合并为巨页后,合并的巨页并未命中,反而导致整体的命中率降低.另一方面,WebVM数据集容量偏小,其中读请求所占比例更小,导致合并后的巨页难以命中,读命中提升效果不明显. 对于Mail Trace数据集,混合页模式的磁盘缓存命中率的优势进一步凸显.如图4(a),对于传统磁盘写命中率极低的32M、64M、128M缓存大小,混合页模式磁盘缓存其写命中率提升了15.04至30.08倍.其主要原因在于,一方面,将基页合并为巨页后大量巨页直接命中,而总页数因为合并而减少,缓存命中率随之提高.另一方面,重复数据删除技术的使用进一步扩展了有效的缓存容量,使命中率进一步得到提升.而对于256M和512M的缓存大小,其写命中率也能相应提升6.47倍和3.42倍.对于读命中情况,如图4(b).总的来说,读命中率随着缓存大小的增加,其变化幅度并不大,均维持在2.6倍至2.97倍之间. 图4 Mail数据集,传统页与混合页读写命中率对比Fig.4 Comparison of hit ratio between base and mix page(Mail) 对于Homes Trace数据集,其命中率的总体趋势与上面两种数据集类似,如图5所示,其写命中率提升了17.75%至24.12%.而对于读命中来说,混合页磁盘缓存的效果并不总是很好,然而这并不影响总体的命中率提升.一方面,对于Homes Trace数据集,其读请求所占比例十分小,写请求总数达到读请求总数的31.5倍.另一方面,其读命中率在0.01的数量级,可以忽略不计. 针对上述传统磁盘缓存与混合页磁盘缓存的对比分析,可以看到基于混合页面的磁盘缓存去重策略能够极大提升磁盘缓存的命中率.通过自适应调整巨页的大小,使缓存达到最佳的页面大小,从而最大化缓存命中率,使其写命中率最大提升30.08倍,读命中率最大提升2.97倍. 图5 Homes数据集,传统页与混合页读写命中率对比Fig.5 Comparison of hit ratio between base and mix page(Homes) 磁盘访问延迟时间也是评价磁盘缓存设计优劣的重要指标,通过对三种不同应用负载在128M缓存大小下延迟时间的测试,我们将基于混合页面的磁盘缓存去重系统与传统基于LRU替换算法的磁盘缓存进行了详细的对比分析.磁盘访问时间Taccess的计算方法如公式(1)所示: Taccess=Hcache·Tcache+(1-Hcache)·Tdisk (1) 其中Hcache表示磁盘缓存命中率,Tcache表示缓存的访问时间,而Tdisk则表示磁盘的访问时间.一般现代磁盘其缓存访问时间在7至10ns之间,我们这里假设为10ns.那么对于访问512字节(1个扇区),具有64位芯片的缓存数据,其缓存访问时间Tcache计算如公式(2)所示: (2) 对于磁盘访问时间Tdisk,主要由寻道时间Tseek,盘片旋转延迟时间Trotate和数据传输时间Ttransfer组成.其计算方法如公式(3)所示: Tdisk=Tseek+Trotate+Ttransfer (3) 其中盘片旋转延迟时间Trotate计算方法如公式(4)所示: (4) 我们假设平均寻道时间Tseek为3.7ms,RPM值为15000,并且磁盘内部传输速率为1129MB/s.则盘片旋转延迟时间Trotate和数据传输时间Ttransfer计算如公式(5)和公式(6)所示: (5) (6) 因此,磁盘访问时间Tdisk=3.7+2+3.63×10-3=5.7ms. 通过模拟实验并由上述公式,我们计算了传统只具有基页的磁盘缓存以及混合页磁盘的访问时间,得到图6所示图形. 针对不同的工作负载(WebVM、Mail、Homes),基于混合页机制的磁盘缓存均能节省大量的延迟时间.主要是因为磁盘缓存中引入混合页机制后,通过对巨页大小的自适应调整,使缓存页面达到一个最佳值,从而使缓存命中率达到最大.由公式(1)可知,缓存命中率Hcache越大,相应的磁盘访问时间Taccess则越小.如图6所示,在缓存大小设置为128M时,对于WebVM数据集,混合页磁盘缓存共节省延迟时间达25.61%;Mail数据集能够节省访问延迟21.86%;而对于Homes工作负载,则达到了31.72%. 图6 传统页与混合页访问延迟对比Fig.6 Comparison of access time between base and mix page 本文提出了一种基于混合页面的磁盘缓存去重策略,在基于LRU替换算法的传统磁盘缓存中引入混合页机制,通过自适应调整巨页的大小,使缓存页面大小达到最佳值,从而使缓存命中率最大化.同时,利用重复数据删除技术对磁盘缓存进行去重操作,在缓存中只保留唯一数据块,节省磁盘缓存,提高缓存利用率.实验结果表明,对于多种工作负载,混合页磁盘缓存写命中率最大提升30.08倍,读命中率最大提升2.97倍,访问延迟最大节省31.72%.3.4 混合页去重
4 实验结果及分析
4.1 实验环境
Table 2 Feature of experimental data set
4.2 巨页大小调整
4.3 命中率

4.4 访问延迟

5 总 结
猜你喜欢
英语文摘(2022年5期)2022-06-05 07:46:26汽车与新动力(2019年5期)2019-11-07 05:20:54电脑爱好者(2019年2期)2019-10-30 03:45:31中国生殖健康(2019年11期)2019-01-07 01:27:44长江丛刊(2018年31期)2018-12-05 06:34:20网络安全和信息化(2018年2期)2018-11-09 01:16:18海峡姐妹(2017年7期)2017-07-31 19:08:21NBA特刊(2017年8期)2017-06-05 15:00:13网络安全和信息化(2017年3期)2017-03-10 07:45:51网络安全和信息化(2016年8期)2016-11-26 06:42:50
