
基于双分支头部解耦和注意力机制的灾害环境人体检测
2023-08-01 05:50杨晨禄赵秋林孙曦子王海莹孙浩博吴瑛琦
西安科技大学学报 2023年4期
郝 帅,杨晨禄,赵秋林,马 旭,孙曦子,王海莹,孙浩博,吴瑛琦
(西安科技大学 电气与控制工程学院,陕西 西安 710054)
0 引 言
人体检测作为目标检测领域的一个重要研究方向分支,在智能监控[1]、道路交通[2]、紧急救援[3]等领域被广泛应用。自然灾害环境中,如地震、山地滑坡、洪水等,利用计算机视觉对受灾人员进行快速、准确定位是应急救援的重要辅助手段。然而,自然灾害的巨大破坏性往往使救援现场处于一个危险而又复杂的场景中,进而导致受灾人员肢体可能被部分掩埋,给救援的准确性和时效性造成一定影响。因此,面向复杂灾害环境下,探索一种快速、准确的人体检测方法可以协助救援人员迅速完成对受灾人员的搜救,对于智能化应急救援的实现具有重要意义。
目前,人体检测算法主要分为2大类:传统机器学习和深度学习[4]。传统机器学习主要是利用滑窗技术实现人工特征提取,并结合分类器实现人体目标检测,代表算法有HOG+SVM[5]、DPM[6]等。李闯等通过构造相交检测窗口对HOG特征进行了优化,并结合基于子单元插值法来提高人体目标检测精度[7]。戴植毅等使用DPM检测算法对人体检测,通过利用快速傅里叶变换和Soft Binning直方图降维对算法进行优化,从而在保证检测精度的同时提高人体目标检测速度[8]。杨鸽等提出一种基于HSV与RGB颜色空间的人体检测与跟踪算法,在RGB空间通过背景减除法实现人体目标检测,并在HSV空间对阴影进行去除从而消除因光照和人体形变等因素造成的干扰[9]。传统算法虽然能够在一定条件下有效检测人体,但人工设计的特征提取器在复杂的调参过程下,往往存在实时性欠缺、鲁棒性差等问题,且只满足特定场景下的检测要求,从而导致其泛化能力有限。
近年来,基于深度学习的检测算法已经成为目标检测领域中的一种主流方法,其通过从海量数据中自动学习、提取目标有用信息,从而实现目标的准确检测。基于深度学习的目标检测算法通过卷积神经网络可以有效完成特征提取、分类和回归,从而实现端到端的学习。深度学习算法可以分为一阶段检测算法和二阶段检测算法。其中二阶段算法包括R-CNN[10],Fast R-CNN[11],Faster R-CNN[12]等。贺艺斌等在Faster-RCNN算法框架下通过融合ResNet50网络来提高对多尺度人体特征的提取能力,但其对于光线昏暗的场所检测效果欠佳[13-14]。陶祝等在Faster R-CNN网络基础上利用空间金字塔池化层替换原有池化层,并通过试验证明该方法可以较好地解决大场景下人体部分遮挡问题[15]。虽然二阶段检测算法计算精度高但其检测速度较慢,难以满足复杂灾害环境下的实时检测需求。
一阶段检测算法只需提取一次特征即可实现目标检测,能够极大提高检测速度,其中SSD[16],YOLO系列[17]算法表现较为出色。李国进等为了增强卷积网络提取特征能力,在SSD网络中增加FPN结构对人体进行检测,并通过试验证明所提出的方法相比于原始网络具有更高的检测精度[18]。
YOLO系列算法能够保证检测精度的同时较好地兼顾算法的实时性[19]。李岩等在YOLOv3的基础上采用一种基于归一化层γ系数的模型剪枝方法,该方法能够在保证人体目标检测精度的同时提高模型的检测速度[20]。李挺等利用YOLOv4网络对人体目标进行检测,将原网络中CSPDarknet53替换为Mobilenetv2以减少参数量,并在网络中引入Bottom-up以连接减少浅层信息的丢失,最后加入CBAM注意力模块增强人体目标特征的表达能力[21],该方法能够准确检测人体目标的同时,具有良好的实时性。邹有成等在YOLOv5框架下将激活函数替换为SiLU激活函数来简化网络体系结构,从而提高重叠人体目标的检测精度[22]。
尽管YOLOv5目标检测算法具有模型体积小、检测精度高、速度快等优点,但是利用其进行灾害环境下的人体目标检测时,仍然存在以下3个问题:
1)基于YOLOv5的主干特征提取网络由于采用大量的卷积运算易造成部分小尺度目标特征在进行卷积提取特征时信息丢失,进而导致灾害环境下人体小目标检测精度受限;
2)受复杂环境干扰,人体目标可能受到部分遮挡造成目标特征无法准确表达,进而导致网络检测精度低;
3)人体在复杂场景中易被遮挡,进而造成检测网络获取的人体信息较少,最终导致预测框定位不准确。
针对上述问题,在YOLOv5的框架下提出一种基于双分支头部解耦检测器和注意力机制的多尺度人体检测网络。主要贡献和创新点如下:
1)为解决受灾人体目标受多尺度影响及小目标特征提取困难的问题,将原有的三尺度特征层拓展为了四尺度特征层,并将同一特征原始输入和输出节点间建立连接以增强网络多尺度特征融合能力;
2)为解决受灾人体目标特征易淹没于复杂背景中而导致检测网络精度下降问题,在C3模块后引入注意力模块以增强复杂灾害环境下人体特征显著性,同时抑制复杂背景干扰;
3)为精准定位目标位置,构建双分支头部解耦检测器分别用于人体识别和定位,以使预测框坐标更加精准;
4)为了进一步提高密集人体目标检测精度,在网络中引入Varifocal Loss优化网络参数,提升检测框定位精度。
1 YOLOv5算法理论
YOLOv5模型网络主要由输入层(Input)、主干层(Backbone)、颈部层(Neck)和输出层(Output)4个部分组成,其结构如图1所示。

图1 YOLOv5网络结构Fig.1 Detection framework of YOLOv5
Input:将输入图像缩放到640×640,再经过自适应缩放、mosaic数据增强,最后送入主干提取网络中,并计算不同训练集中的最佳锚框值。
Backbone:主干网络主要由CBS、C3以SPPF等组成,C3由3次卷积的CSPBottleneck模块组成,CSPBottleneck模块采用通道分离的思想,将输入特征图分为2个部分,分别进行不同的处理。其中,一部分通过一个卷积层进行降维处理,另一部分则直接进行卷积操作,最后再将2个部分的结果进行拼接。这种方式既能够增加网络的感受野和特征表示能力,又能够降低计算量和参数数量,从而提高模型的性能和效率。SPPF模块通过使用多个小尺寸池化核来取代SPP模块中的单个大尺寸池化核,指定一个卷积核,每次池化后的输出成为下一个池化的输入,从而提高网络运行速度。
Neck:使用FPN和PAN[23]相结合的方式从而加强网络的特征融合能力。
Output:主体部分使用3个Detect检测器对网络进行检测。
2 构建检测网络
所提出的基于双分支头部解耦检测器和注意力机制的多尺度灾害环境下人体检测网络框架如图2所示。所搭建网络框架主要实现步骤如下。
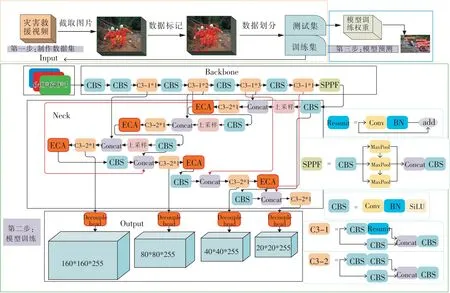
图2 改进的YOLOv5网络结构Fig.2 Improved detection framework of YOLOv5
Step1:选取灾害救援现场图像和图片数据制作数据集,其中2 624张作为训练样本,其余656张作为测试样本。
Step2:标注训练数据集并设置训练初始参数进行训练。
Step3:训练过程中构建颈部网络,扩充特征检测尺度,在融合注意力机制同时将同一特征原始输入和输出节点间添加连接,以增强网络对小目标特征提取能力和多尺度特征融合能力。
Step4:在输出层构建双分支头部解耦检测器分别用于人体识别和定位,使预测框坐标更加精准。
Step5:为了提升检测框定位精度,引入Varifocal Loss优化网络参数。
Step6:训练结束得到预训练权重文件。
Step7:将预训练权重文件在测试数据集上进行预测验证。
2.1 颈部网络重构
灾害环境中,受灾人员可能被废墟掩埋或被洪水淹没造成人体目标存在多尺度问题,从而造成传统人体目标检测算法难以有效检测。针对上述问题,在原YOLOv5的Neck部分添加浅层特征网络作为检测层以增强检测网络对小目标人体识别能力;同时,在特征金字塔结构中添加连接,提高网络多尺度特征融合能力;最后,嵌入轻量注意模型(Efficient Channel Attention,ECA)以抑制复杂背景干扰。
2.1.1 小目标检测层
在YOLOv5的网络中使用深度神经网络来提取目标的特征表示,原始图片的输入尺寸为640×640,颈部网络通过对原图片的多次采样操作,分别生成新特征图尺度,大小为80×80、40×40、20×20。但在实际灾害环境中,受灾人员的随机分布会造成人体目标存在多尺度问题,尤其是一些尺寸较小的人体目标,经过多次下采样其大部分特征信息会消失,从而影响最终检测效果。针对上述问题,在原YOLOv5网络基础上新增一层160×160的检测层,将原有的特征融合部分改为四尺度特征融合,进而能够捕捉更多小尺寸的人体目标信息。
2.1.2 特征金字塔重构
YOLOv5采用FPN和PAN相结合的方式来提取特征,如图3(a)所示。但PAN结构无法提取网络中的原始特征信息,会导致训练学习出现偏差,影响检测准确度。针对此问题,重构原有的Neck结构,在PAN结构的结点增加来自主干特征提取网络中原始特征层的输入,如图2红色箭头线条所示。在训练过程中获得原始特征信息,避免训练学习过程偏离预期,从而提高模型的准确性和可靠性,改进后的结构如图3(b)所示。

图3 特征融合结构示意Fig.3 Schematic diagram of feature fusion structure
2.1.3 ECA注意力模型
为了解决复杂背景干扰导致人体目标显著度较低的问题,引入ECA通道注意力模型,将其嵌入到特征金字塔的多个特征传递分支结构中来提升人体特征提取的能力,进而提高检测网络的检测精度。ECA通道注意力模块是对特征图进行特征通道自适应筛选,强调学习突出信息,采用一种不降维局部跨信道交互策略和自适应进择一维卷积核大小的方法,以极少参数量显著提升特征提取质量,其结构如图4所示。

图4 ECA结构Fig.4 ECA module
从图4可以看出,ECA通过全局平均池化,将输入的特征图从二维矩阵压缩为具有全局信息的1×1×C数列(C为特征通道数),然后通过大小为k的快速一维卷积,在不降维的情况下生成通道权重,进行局部跨通道交互,共享通道参数,获取各个通道之间的相关依赖关系,见式(1)
ω=σ(C1Dk(y))
(1)
式中ω为特征权重;C1D为一维卷积;k为该区域跨通道交互的覆盖范围;y为聚合特征。
由于通道维数通常是2的指数倍,所以采用以2为底的指数函数来表示非线性关系,计算公式如下
C=φ(k)=2(γ*k)-b
(2)
因此,确定通道维数C,卷积核的大小k通过以下的公式计算得到
k=ψ(C)=|log2(C)/γ+b/γ|
(3)
式中γ,b分别为缩放因子和偏置项,分别取为2和1。然后把所得到各个通道的权重加权到原来的输入特征图上。
文中在C3模块后引入ECA模型前后对比的结果如图5所示,其中红色部分表示显著度较高的区域,并且颜色越深表示显著度越高。

图5 加入ECA前后对比Fig.5 Comparison results before and after adding CBA
从图5可以看出,通过引入ECA,可以提高复杂背景下待检测人体目标的显著性,为后续进一步准确检测人体目标奠定了良好的基础。
2.2 双分支头部解耦检测器
受复杂灾害环境影响,受灾人员肢体可能被建筑、洪水等物体遮挡,进而造成人体目标检测难度增大。被遮挡的人体目标通常需要精确的定位信息来判断位置,然而,在基于深度学习的目标检测的分类和定位任务中,两者的关注点存在显著差异:前者更加关注如何将特征图与已知的类别进行比较,以确定最佳的匹配结果;而后者则更加关注如何通过调整边界框的参数来达到精确的定位。但通过同一个特征图进行分类和定位的效果不佳,会发生失调的问题[24]。
针对灾害环境中对被遮挡人体目标定位不准确的问题,文中将传统的耦合检测头分离成2个具有独立子任务的头部分支,将输入特征从空间维度进行解耦,分别用于分类和定位,以此来提升图像中人体目标对分类和定位的敏感性和精确度,如图6所示。

图6 解耦头结构Fig.6 Structure of decoupled head
图6中,H,W,C分别为着输入特征图的高度(Height),宽度(Width)以及通道数(Channel)。解耦检测器首先对输入特征图通过1×1卷积降低通道维数,以降低参数量的产生。特征图输出包括2条支路,一条支路负责分类,先使用2个3×3的卷积提取特征信息后,再通过1×1的卷积将特征图的通道维数调整至预测目标的类别数量,在该特征图上完成分类;另一条支路负责定位,通过3×3卷积层提取特征后,将特征图分为2个,一个根据获取目标的置信度分数确定了该点真实目标框与预测框的交并比,另一个则预测边界框的中心坐标以及框的宽度和高度{x,y,w,h}。相较于耦合头部网络,解耦头部结构可以使网络参数进一步降低,同时减少了特征共用,从而提升模型对人体的定位和分类能力。
2.3 变焦损失
在YOLOv5中使用的Focal Loss可以有效解决样本中类别不均衡问题,其中函数表达式如下
(4)
式中p为经过激活函数的输出,即预测样本属于1的概率;y为真实标签值;α为平衡正负样本的权重;(1-p)γ,pγ为调制每个样本的权重,减少容易分类的样本的权重,使得算法模型能够更加精细地识别复杂的样本,从而提升准确度。
Varifocal Loss通过继承Focal Loss的加权方法可以有效解决连续IACS(IoU-Aware Classification Score)中回归时类别不平衡的问题,并且可以更好地优化密集目标训练中前景类和背景类之间极度不平衡的问题,从而更好地预测IACS,有效提升检测目标的定位精度存在置信度和定位精度,Varifocal loss定义为
VFL(p,y)=
(5)
式中p为预测的IACS,代表目标分数。对于前景点时,将其ground truth类q设为生成的边界框和它的ground truth(gt_IoU)之间的IoU,否则为0,在对于背景点时,所有类的目标q为0。引入Pγ缩放负样本(q=0),同时将正样本与训练目标q加权,对gt_IoU较高的正样本,则它对损失的贡献将会较高。最后,为了均衡正负样本之间的比例,在损失函数中增加可调比例因子α,文中取为0.75。
3 试验结果及数据分析
试验环境配置参数见表1。

表1 试验环境配置参数Table 1 Configuration parameters in experiment
3.1 数据集采集
截取灾害救援场景如泥石流、洪灾等视频中的3 280张图片作为数据样本。试验中选取2 624张作为训练样本,其余656张作为测试样本。
3.2 网络模型训练
在模型训练过程中,将学习率设置为0.01,迭代批量大小设置为16。当训练达到100轮时,学习率降至0.001,损失函数和精度也趋于稳定,最终经过300轮模型迭代训练,得到模型的权重。
3.3 试验结果及分析
为了全面评估文中算法的性能,采用mAP@0.5、召回率Recall、准确率Precision和平均检测处理时间作为衡量标准,其相关参数计算公式如下
(6)
(7)
(8)
式中NTP,NFP和NFN分别为正确检测数、误检数和漏检数;AP为P-R曲线积分;N为检测类别数量。
所设计的网络模型与YOLOv5的平均精度值(mean Average Precision,mAP)、召回率(Recall)和准确率(Precision)曲线对比结果如图7、图8和图9所示。
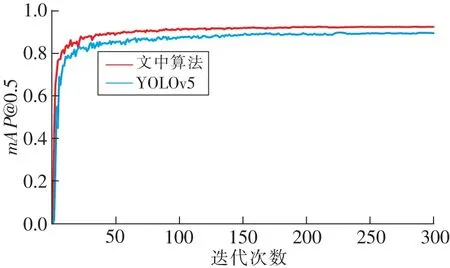
图7 mAP@0.5对比曲线Fig.7 mAP@0.5 comparison curves

图8 召回率对比曲线Fig.8 Recall comparison curves

图9 准确率对比曲线Fig.9 Precision comparison curves
从图7可以看出,随着迭代次数增加,文中算法和YOLOv5算法分别在迭代40轮和80轮时,mAP@0.5数值上升到0.85左右。算法通过重构颈部网络和引入解耦检测器,使得mAP@0.5值最终稳定在0.9以上,达到较高的检测精度。从图8和图9可以看出,算法的准确率和召回率也均高于YOLOv5算法。从图10可以看出,优化损失函数后,网络的损失值降低,最终稳定在0.044,文中所提出的检测模型达到了较好的训练效果。在融合浅层网络、ECA注意力模块、解耦检测器以及损失函数优化4方面进行改进,为了更好地评估各模块的效果,设计消融试验,其试验结果见表2。
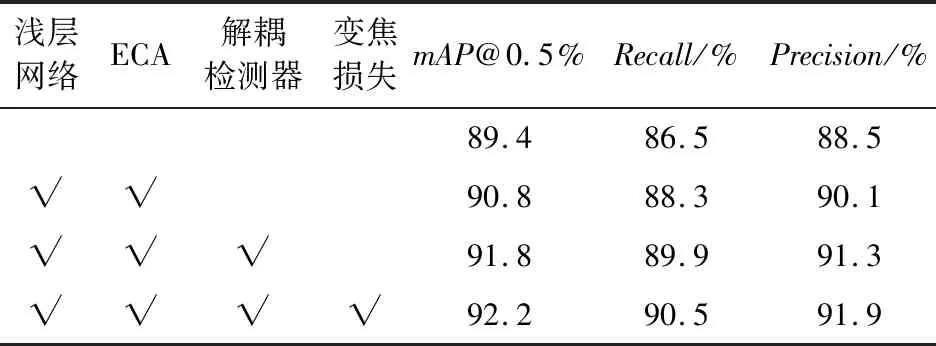
表2 消融试验结果Table 2 Ablation experiment results

图10 损失对比曲线Fig.10 Loss comparison curves
由表2可知,YOLOv5网络检测精度为89.4%,但在融合浅层网络、引入注意力机制、解耦检测器以及损失函数优化4个方面的改进后,文中算法的检测精度得到了提升,最终达到92.2%。为了进一步验证所提算法的优势,选取具有代表性的4种场景对模型进行验证,分别为:灾害环境或救援环境中存在多尺度目标、严重遮挡/小目标、部分遮挡以及复杂背景情况。将试验结果与其他常见检测算法进行比较,检测结果如图11所示。

图11 检测结果对比Fig.11 Comparison of test results
图11为人体被遮挡图像,图11(a)中为选取的4种灾害救援场景情况并标注其中待检测的人体,从左到右4组试验结果及分析如下。
第1组试验:待检测人体出现多尺度情况,从第1组对比试验可以看到,YOLOv3、YOLOv4、YOLOv5、SSD以及Faster RCNN对于多尺度目标有漏检情况发生,然而文中通过构建解耦检测器,有效提高了图像中人体目标对定位和分类的敏感性和精确度,能够检测出所有目标。
第2组试验:待检测人体存在严重遮挡和小目标情况,从第2组对比试验可以看到,原始算法、YOLOv3、YOLOv4、SSD以及Faster RCNN对于被遮挡的目标存在漏检的情况,而文中算法通过增加浅特征检测层,对微小人体目标的特征提取能力更强,能够检测出所有目标。
第3组试验:待检测人体存在部分遮挡情况,从第3组对比试验可以看到,原始算法、YOLOv3对于在复杂情况下的标检测能力有限,YOLOv4、YOLOv5、SSD以及Faster RCNN和文中算法可以检测出所有目标,而文中算法通过对损失函数的优化,相较于其他算法可获得较高的置信度。
第4组试验:待检测人体存在复杂背景情况,从第4组对比试验可以看到泥土颜色和人体肤色接近,使人体目标受到复杂背景冗余信息干扰,导致原始算法、YOLOv3、YOLOv4、SSD以及Faster RCNN对于被严重遮挡的目标存在漏检的情况,而文中算法通过嵌入注意力机制,提高检测模型对人体特征的特征表达能力,可以检测出所有目标,并且相较于其他算法检测框也更接近真实框大小。
为了更好地评估文中算法的性能,将其与SSD、Faster RCNN、YOLOv3、YOLOv4和YOLOv5检测网络进行了对比试验。在这些算法的训练过程中,采用相同的数据样本和参数,最终的检测结果见表3。
由表3可知,文中算法的mAP@0.5%明显高于其他算法,虽然检测速度略低于YOLOv5,但是相比于其他算法实时性较好。
4 结 论
1)通过引入浅层检测层并融合注意力机制可以使检测网络更好的学习小目标人体特征,进而提高样本小目标人体的检测精度。
2)通过在检测网络中构建解耦检测器可以有效提升目标在复杂背景下的特征表达能力,在一定程度上减少复杂背景所导致的漏检和误检。
3)利用灾害救援场景的所得到的数据进行测试验证,算法在多种不同复杂测试环境下,对灾害人体的平均检测精度可达92%以上,召回率可达90%以上,具有较好的实时性和鲁棒性,对于分辨率为640×640的图片检测速度可达35 fps。
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
基层中医药(2021年5期)2021-07-31
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
特别健康(2018年3期)2018-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
