
基于CiteSpace知识图谱分析的露天矿粉尘浓度预测研究进展与展望
2023-08-01 05:49肖双双马亚洁李卫炎
西安科技大学学报 2023年4期
肖双双,马亚洁,李卫炎,刘 锦
(1.西安科技大学 能源学院,陕西 西安 710054;2.浙江交通资源投资集团有限公司,浙江 杭州 310020)
0 引 言
露天矿产尘点多、粉尘量大、扩散范围广,影响职工健康,加速设备磨损,影响生产效率和生产安全,污染周边生态环境。露天矿粉尘职业危害已成为矿山领域最重要的职业健康问题,并产生较大的社会影响。在国家加快推进生态文明建设、大力推进绿色矿山建设的背景下,露天矿粉尘防控已成为亟待解决的重大行业问题[1]。为更精准高效的开展粉尘防治工作,需要对各产尘点的粉尘浓度进行精准预测,粉尘浓度预测是实施粉尘污染防治的前提,是指导各类防治措施的实施准则。如何从产尘环节中挖掘关键的特征因素,建立有效的粉尘浓度预测模型,近年来已经成为国内外的研究共识和热点。
国内外学者通过理论分析、现场监测等研究了温度、湿度、风速、风力、风向、剥离量、采煤量等因素对粉尘浓度的影响,选取风速、风向、温度、湿度、产煤量、剥离量等指标建立粉尘浓度预测指标体系,采用时间序列、线性回归、灰色理论、人工神经网络、支持向量机、求和自回归移动平均-广义神经网络回归(ARIMA-GRNN)组合算法、灰色-广义回归神经网络(GM-GRNN)组合算法等构建了多种粉尘浓度预测模型,能够对粉尘浓度的发展趋势做出大致预测。为提高粉尘浓度预测的准确率,一些学者在模型预测方法的研究中不局限于单一传统的数学算法预测,而是逐渐引入机器学习,采用生物智能优化算法结合机器学习建立粉尘浓度预测模型,如粒子群-BP神经网络(PSO-BP)组合预测模型[2]。但是随着各种方法模型的不断涌现,在粉尘浓度预测模型的研究现状与发展趋势方面的评述较少,预测方法的现状和演进趋势仍然不清楚。近年来文献计量分析已在多个学科中应用,发文量呈逐年递增的趋势,基于文献计量学分析露天矿粉尘浓度预测研究现状与展望,检索并梳理国内外相关研究进展,有利于充分了解露天矿粉尘浓度预测的研究现状,分析粉尘浓度与各类影响因素之间的关系,正确、有效的开展粉尘预测研究工作,帮助露天矿更好的制定粉尘防治策略。
因此,基于CNKI和Web of Science收录的526篇粉尘浓度预测相关文献,采用CiteSpace与VOSviewer知识图谱可视化软件进行统计分析及数据挖掘,揭示粉尘浓度预测的研究热点、研究方法和发展过程,系统归纳了露天矿粉尘浓度影响因素、指标体系的研究现状,梳理了粉尘浓度预测方法随时间的演进趋势,提炼出预测方法的4大类型,并分类展开详述,提出露天矿粉尘浓度预测研究展望,以期为露天矿粉尘浓度预测的深入研究提供参考。
1 基于文献检索的研究脉络分析
1.1 研究方法与数据来源
为对粉尘浓度预测的研究现状和发展趋势进行详细分析,通过对近40 a国内外粉尘浓度预测相关的文献进行检索,检索方法如下。
数据来源:中国知网(CNKI)、Web of Science(WOS)。
检索区间:1981年1月1日—2022年12月31日。
检索主题:SU=“粉尘浓度预测”+“PM2.5浓度预测”+“浓度预测模型”。
研究方法:计量学、可视化分析。
运行环境:VOSviewer、CiteSpace。
共检索到文献526篇(CNKI 389篇、WOS 137篇),研究“矿山粉尘预测”的相关文献共220篇(CNKI 40篇、WOS 180篇),研究“露天矿粉尘预测”的相关文献共48篇(CNKI 9篇、WOS 39篇),由于不同领域的粉尘浓度预测方法类似、指标体系不同,为全面归纳粉尘浓度预测方法发展动态,基于526篇文献,运用CiteSpace、VOSviewer软件从文献计量学的角度生成研究内容的高频关键词的聚类图谱和演化趋势图谱,对1981年—2022年的粉尘浓度预测相关研究热点进行可视化分析。
1.2 文献数量动态变化
国内外关于粉尘浓度预测的研究领域发表成果及发展趋势,如图1所示,2013年以前该领域研究论文数量较少,PM 2.5、粉尘浓度预测论文发表数量每年基本保持在1~2篇,2014—2018年该领域发文量开始增加,中英文文献数量分别维持在每年25篇左右,总体上论文数量呈上升趋势,随着计算机科学技术的迅速发展,人工智能、机器学习、大数据技术等的兴起,与计算机技术进行学科交叉的方法技术不断应用于各行业领域,自2019年起发文量显著增加,文献数量增长主要体现在基于机器学习的智能预测方法。
1.3 检索文献的计量分析
1.3.1 高频热点关键词
关键词代表着文献研究主题,利用VOSviewer对关键词进行统计分析,如图2、图3所示。图中不同颜色代表不同的研究主题,节点的大小代表该研究内容共现频率的高低,线条的粗细代表研究内容的关联强度。从图2、图3可以看出,在粉尘浓度预测方面,PM 2.5、预测模型、神经网络、机器学习、粒子群优化、组合预测等关键词出现频率较高,这些关键词体现了研究的热点主题。

图2 中文文献高频关键词共现网络Fig.2 Network of high-frequency keyword co-occurrence in Chinese literature
1.3.2 聚类主体分析
基于CiteSpace软件的K值聚类分析,设定参数K=10,提取10个聚类团,生成粉尘浓度预测研究关键词聚类图谱,如图4所示。

图4 粉尘浓度预测研究关键词聚类Fig.4 Keyword cluster in dust concentration prediction study
粉尘浓度预测研究大致可分为:环境影响因素、预测模型(时间序列、神经网络、灰色模型),模型优化(机器学习)、预测控制、结果影响(尘肺病)10大聚类团,基于机器学习的模型优化预测是该领域研究的主流。
1.3.3 关键词聚类的时区演化
运用CiteSpace可视化分析软件提取1~7个高频关键词,该时间轴主要针对该领域研究热点与发展趋势进行分析,从时间轴可看出,早期的研究方法主要为寿命表法、灰色理论、线性预测等传统方法。随着大数据、人工智能的发展,自1995年后,运用神经网络、支持向量机等机器学习算法预测粉尘浓度逐渐成为新的研究热点,从2005年起,基于粒子群算法、遗传算法、蚁群算法等优化算法的组合预测模型逐渐取代BP神经网络、支持向量机等单一的预测模型,如图5所示。
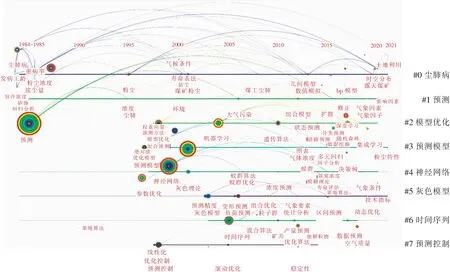
图5 粉尘浓度预测研究热点时间轴Fig.5 Spot timeline for dust concentration prediction
2 露天矿粉尘浓度预测研究现状
粉尘浓度预测过程主要是通过对现场监测到的数据进行收集和预处理,根据数据特征采用合适的预测算法建立粉尘浓度预测模型,确定其模型参数,分析影响粉尘浓度的关键因素,通过优化算法调整优化其参数,对结果进行修正,提高预测结果的准确率,如图6所示。粉尘浓度预测的核心包括选取粉尘浓度影响因素,构建粉尘浓度预测指标体系,建立粉尘浓度预测模型[2]。
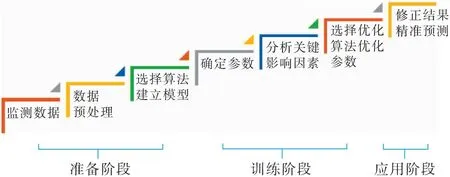
图6 粉尘浓度预测过程描述Fig.6 Description of the dust concentration prediction process
2.1 粉尘浓度影响因素和预测指标体系
露天矿作业的每个环节都伴随着粉尘的产生,露天矿作业环境敞露于地表,钻孔、爆破、采装、运输、排卸各环节都会产生大量粉尘,由此带来的粉尘污染更为严重。产尘量与所用机械设备类型、生产强度、岩石性质、开采方法以及自然条件等众多因素有关。目前,国内外学者通过理论分析、现场监测等研究了温度、湿度、风速、风力、风向、剥离量、采煤量等因素对粉尘浓度的影响。如WANG等对西北哈尔乌素露天煤矿的粉尘污染进行了分析,得出影响粉尘浓度的因素顺序为:产煤量>边界层高度>风速>温差>温度>湿度[3]。QI等在对影响PM浓度的重要性分析时,除当前PM浓度受前5 min PM浓度的影响外,其他影响因素顺序为:湿度>温度>噪声级>风速>风向[1]。LI等对TSP浓度预测时根据影响因素的重要程度分配权重,结果显示TSP在08∶00~09∶00期间最高,在15∶00~16∶00期间最低。分析其原因主要影响因素为:气象参数、正常作业以及逆温层[4]。霍文等分析特征变量重要性,认为环境影响因素中,湿度对粉尘浓度影响最大,其次是温度、噪声,风速、风力及风向影响较小,如图7所示[4]。CHINTHALA等通过结合风穿透效应,研究了风侵角和扩散系数对PM10浓度的影响,研究表明风侵角随露天矿深度的变化对PM 10截留有显著影响[5]。

图7 粉尘浓度影响因素重要性[6]Fig.7 Importance of factors affecting dust concentration
露天矿的生产尘源主要来自钻孔、爆破、采装、运输、排卸等作业环节。在钻孔作业下,粉尘颗粒由孔底高速喷出孔口而产生高浓度粉尘;爆破环节矿岩爆破瞬间会在爆区周围产生浓度极高的粉尘颗粒,污染周边环境。采装、运输、排卸等环节因矿岩间摩擦碰撞和道路运输产生大量的扬尘。一般认为剥离量和采煤量越大,即生产强度越大,产尘量就越大。
温度对粉尘浓度的影响主要由逆温现象导致空气流动性受阻,温度较低时,粉尘无法扩散,造成严重的空气污染。一般湿度越大空气中水分子含量越多,空气相对湿度对粉尘浓度预测结果有显著影响。风速、风力是粉尘扩散速度的直接影响因素,在露天矿采场内部,较小的风速也可能产生扬尘,增加空气中粉尘浓度。风向影响粉尘扩散方向,具有随机性和不确定性。
因此,生产强度大小决定了产尘量的多少,气象因素决定粉尘的聚集与扩散。根据影响因素选择预测指标,建立粉尘浓度预测指标体系是粉尘浓度精准预测的关键。目前,该指标体系主要分为气象类指标和生产类指标2大类。气象类指标包括风速、风向、温度、湿度等;生产类指标包括产煤量、剥离量、生产噪声等[7],如图8所示。
2.2 粉尘浓度预测方法
计量学可视化分析得出粉尘浓度预测方法主要是沿着早期的寿命表、宏观测算、经验类比法等传统方法发展为时间序列、线性回归、灰色理论等方法,再延伸至近年的人工神经网络、随机森林、支持向量机以及生物智能算法优化机器学习等组合方法的研究脉络发展的。基于可视化分析结果,将粉尘浓度预测相关方法进行归类,系统的分析对比各方法的特点和适用范围,将应用次数较高的预测方法和模型进行汇总,见表1。目前的粉尘浓度预测方法分为定性和半定量预测、线性回归预测、机器学习预测以及组合预测4大类。
2.2.1 定性和半定量预测
寿命表、宏观测算、经验类比法为传统预测方法。传统预测方法大致可分为定性预测和半定量预测2种,在定性预测方法的应用中,王美霞等采用职业卫生调查、类比法、经验法预测了拟建项目的噪声与粉尘职业病危害因素预期接触水平,根据预测结果采取相应防护控制措施[8]。韩磊等通过分析煤矿污染变化趋势、煤工尘肺患者发病特征、暴露水平与发病的关系,掌握煤工尘肺病发病规律,对煤工尘肺未来发病情况做出预警预测[9]。
在半定量预测方法的研究中,陈春生等在寿命表法的基础上增加了肺内石英粉尘负荷量估算法对铁路隧道工现场粉尘容许浓度进行了估算,并对该方法的数据处理部分稍加改进,将累积发病率取了逆正态分布函数后再建立的方程,使得结果更加符合实际应用[10]。沈阳等运用贝叶斯决策分析技术评估某高速公路隧道掘进工粉尘累计暴露情况,并估计决策分析最小样本数。得出该高速隧道掘进工暴露矽尘浓度超标严重,基于粉尘测定的贝叶斯决策分析技术可实现累计暴露预测及最少检测样本估算[11]。GHOSE等针对粉尘排放源展开研究,使用排放因子或预测方程对不同采矿活动粉尘排放进行量化,重点介绍了本研究在环境保护领域的重要性以及该研究可能产生的影响,得出结论:得以估计的产尘量可以适当评估对空气质量的影响,并制定适当的空气污染控制策略[12]。BALAGA等提出并开发一种基于幂函数的粉尘浓度预测算法功能模型,可针对不具经验数据的粉尘分布状态进行预测,建立PM10、PM4和PM2.5粉尘颗粒的分布特征,该模型适用范围广,不受粉尘粒径大小以及粉尘源距离限制,为矿山工作者提供更安全高效的粉尘防治策略[13]。TRIPATHY等重点介绍矿井不同作业区域的粉尘水平监测、不同来源收集的粉尘表征、粉尘的个人暴露情况,采用AERMOD软件对矿井不同位置和附近区域的粉尘浓度进行了预测[14]。传统方法如粉尘健康风险评估大多基于定性或者半定量的方法,缺少粉尘暴露的连续性监测,不能在风险概率的基础上进行定量评估,使得粉尘长期累积暴露评估客观性下降。以上宏观预测模型仅仅能够反映出预测对象的主要变动趋势,因此传统的预测方法在需求数据波动较大的复杂环境下逐渐被其他更好的方法取代。
2.2.2 线性回归预测模型
粉尘预报早期常用理论方法,包括函数解算法和图像查找法。随后有学者开始采用统计模型来预测预报,如张志伟等采用灰色理论的预测方法,建立了降尘含量的GM生成函数预测模型,对邯郸市工业居民混合区降尘含量历年的变化规律进行预测研究[15]。陈日辉等用粉尘浓度统计值建立GM模型,对原始数据进行了滑动平均处理,该模型预测结果相对误差较小[16]。曹玉珍等结合灰色预测模型以及模型的预测结果检验评估,以MATLAB语言编写为开源程序,对广州市降尘量进行预测分析,结果与实际情况相符,该程序可应用于不同指标或同一指标不同时段的建模和模型检验过程,为灰色模型在各个领域的广泛应用提供了帮助[27]。
GM灰色理论、直线回归等方法一般适用于线性趋势预测,因此,不适合对波动较大的数据进行预测;对于非线性和不稳定的数据,还需要预测模型具有较强的非线性映射能力。如王月红等以某矿粉尘浓度时间序列为基础,提出了差分自回归移动平均预测模型,建立ARIMA粉尘浓度预测模型,该模型适用于非平稳数据的处理。得到初步模型后,根据贝叶斯信息准则对比模型的优劣,选择最优模型提高预测精度[18]。毛炜峄等通过对常规的回归分析方法加以改进,综合滑动相关理论以及集合回归方法建立超级集合模型,利用反推法逐级寻找与沙尘日数序列有显著统计关系的前期环流因子,得出它们之间的关系,为塔里木盆地多发季节沙尘日数的预测提供依据[19]。矿井产量与粉尘排放量之间的线性关系较弱,采用非线性方法建立模型可以提高结果的准确率。
2.2.3 机器学习预测模型
在机器学习算法的应用中,任屹罡等建立了BP神经网络模型对郑州环境空气中粉尘浓度PM10进行预测,以平均气压、平均气温、平均相对湿度和平均风速这4类气象因子来预测,得到预测结果的准确率可达86.85%[20]。王布川采用LMBP神经网络对煤巷综掘工作面的粉尘浓度进行了预测,结果显示预测值误差在±10%以内,预测结果可靠[21]。李德根等通过分析各产尘因素对截割粉尘浓度的影响,建立基于熵权法的RBF神经网络模型,分析掘进工作面截割粉尘浓度的变化规律。结果表明:熵权法RBF神经网络可以准确预测掘进工作面粉尘浓度[22]。李明等在对粉尘影响因素分析的基础上,建立了粉尘SiO2含量、粉尘浓度、接尘时间与尘肺发病率之间的关系,运用人工神经网络技术来实现粉尘危害三因素与尘肺病发病率之间的剂量-反应关系,对数据进行训练学习,参数进行选择调整,建立了粉尘模拟和预测模型[23]。单纯用线性模型或非线性模型会导致信息源不广泛问题,合适的组合模型可更好地发掘数据的潜在关系,提高模型的预测精度和稳定性,如图9所示。
2.2.4 组合预测模型
人工神经网络算法虽然能够处理非线性、非平稳数据,但易陷入局部最优,且易导致过拟合现象。随着数据增加,冗余性问题也将制约预测精度和计算效率(图10)。在多种方法综合预测模型的研究中,王永斌等分别建立GM(灰色系统)模型、BPNN(反向传播网络)模型、GM-GRNN(灰色-广义回归神经网络)组合模型对我国尘肺病发病人数进行预测,并根据误差分析对比3种模型的预测效果,结果表明,GM(1,1)-GRNN组合模型的拟合及预测效果优于GM(1,1)模型和BPNN模型[25],也是首次将多种智能算法相结合使用。
卞子龙等基于求和自回归移动平均模型(ARIMA)与灰色模型GM(1,1)、广义神经回归网络模型(GRNN)的分别组合,构建适合江苏省尘肺病预测的组合模型。通过对比拟合分析ARIMA预测模型、ARIMA-GM组合模型、ARIMA-GRNN组合模型的误差值得出,在江苏省尘肺病新病例预测中ARIMA-GRNN模型误差最小,拟合效果最好[26]。周旭等采用时间序列和神经网络相结合的外因输入非线性自回归模型(NARX模型)来预测粉尘浓度和时间的关系,该模型适用于时序型数据,可以给不同时段的输入之间建立联系[27]。刘杰等提出了一种结合弱化缓冲算子优化的分数阶累加灰色(FGM)预测模型,对废气中烟(粉)尘排放浓度的变化进行预测和拟合,并对比分析GAWBO和AWBO以及WAWBO 3种弱化缓冲算子处理后得到的预测结果,发现运用WAWBO算法优化过的FGM模型预测的数据精度高、误差低,结果与实际烟(粉)尘排放情况更符[28],如图11所示。张易容通过建立传统回归、随机森林、LSTM循环神经网络预测模型,选取时间因子、气象因子及采装强度作为输入变量,预测哈尔乌素露天煤矿PM2.5浓度值,结果表明LSTM循环神经网络预测模型效果较好[29]。王雅宁采用决策树、马尔科夫等算法知识,构建了属于露天矿的随机森林-马尔科夫粉尘浓度预测模型,通过马尔科夫修正后的预测结果精度较高[30]。

图11 弱化后拟合值对比Fig.11 Comparison of the weakened fitting values
3 露天矿粉尘浓度预测研究展望
国内外学者对露天矿粉尘预测进行了大量的研究,取得了丰富的成果,为后续研究提供重要的参考。综合考虑露天矿粉尘产尘机理、物化特征、影响因素等,构建完善露天矿粉尘浓度预测研究体系,如图12所示,尚有以下问题需深入研究。

图12 露天矿粉尘浓度预测研究体系Fig.12 Research system of open-pit mine dust concentration prediction
1)矿山尤其是露天矿矿山产尘点多、产尘量大、粉尘浓度大、扩散范围广,影响粉尘浓度的因素众多,了解掌握影响粉尘浓度的主要因素是粉尘浓度精准预测的关键。根据气象理论、粉尘扩散机理,运用人工智能、大数据分析、机器学习的方法对粉尘浓度影响因素进行深入挖掘分析,揭示影响粉尘浓度的关键因素,构建科学的粉尘浓度预测指标体系。
2)影响粉尘浓度的因素众多,且数据波动较大,粉尘环境具有不确定性、时变性、非线性,仅使用现行的、单一的模型对粉尘浓度进行预测,难以获得最优解。将多种智能预测算法与优化算法相结合,构建粉尘浓度预测智能模型,并根据预测场景、数据特征进行参数优化,提高预测精度。
3)采用各种非线性的预测方法结合智能优化算法对模型的参数进行优化调整,检验模型预测效果,提高结果的可靠性,并增强模型的鲁棒性,以期获得更好的预测效果。
4)推广应用各类粉尘预测模型并评估其预测精度、优势及不足,为预测模型优化提供参考。
4 结 论
1)PM2.5、预测模型、神经网络、机器学习、粒子群优化、组合预测为粉尘浓度预测方面的研究热点,基于机器学习的模型优化预测是该领域研究的主流,基于优化算法的组合预测模型逐渐取代单一预测模型。
2)在粉尘浓度影响因素及预测指标体系方面,生产强度大小决定了产尘量的多少,气象因素决定粉尘的聚集与扩散。粉尘浓度预测指标主要包括气象类指标和生产类指标2大类。气象类指标包括温度、湿度、风速、风向等,生产类指标包括剥离量、采煤量等。
3)在粉尘浓度预测方法方面,基于可视化分析结果,将目前的粉尘浓度预测方法分为定性和半定量预测、线性回归预测、机器学习预测以及组合预测4大类,系统分析对比了各类方法的特点和适用范围。当下主流的预测方法为基于机器学习、生物智能算法优化的组合预测模型。
4)国内外在露天矿粉尘预测研究方面取得了丰硕的成果,相关理论方法不断革新,但仍存在粉尘浓度影响因素缺乏深度挖掘、粉尘浓度预测指标主观选取、预测方法单一不变等问题。应积极引入大数据、人工智能等新方法新技术,不断提升粉尘浓度预测的科学性和准确性。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
防爆电机(2021年6期)2022-01-17
有色金属(矿山部分)(2021年4期)2021-08-30
电子乐园·上旬刊(2021年8期)2021-05-16
作文成功之路·小学版(2019年9期)2019-10-17
资源节约与环保(2018年1期)2018-02-08
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中国煤炭(2016年9期)2016-06-15
