
视觉导引装配场景动态手势识别方法
2023-07-25 02:55梁钊铭段旭洋
机械设计与研究 2023年2期
梁钊铭, 段旭洋, 王 皓
(1.上海交通大学 巴黎卓越工程师学院,上海 200240,E-mail: lionski@sjtu.edu.cn;2.上海交通大学 弗劳恩霍夫协会智能制造创新中心,上海 201306;3.上海交通大学 机械与动力工程学院,上海 200240)
在产品制造过程中,零件装配是十分重要的一环。在面对部分工艺复杂、难以通过自动化方式进行装配的产品时,需要采取人工方式进行。为减少人工装配过程中的装配错误或装配缺漏,现有的一类解决方案采用机器视觉结合人工智能技术,对人工装配过程进行辅助与监督[1]。
现阶段的人工装配视觉监督场景中,主要使用的方法有如下几种思路。一种思路是对装配人员在物料拾取时的手部位置进行定位,通过识别手部停留的物料框判断是否拾取正确的装配零件[2],这类方法主要针对零件的错误拿取问题;另一种思路通过识别事先划定的锚框区域内是否有正确安装的零部件,对零件是否得到正确安装进行识别[3];上述两种思路分别从装配步骤的起始阶段即物料抓取阶段,以及结束阶段即零件装配完成阶段进行识别,有效地弥补了人工目视检查方式的不足,在人工装配视觉监督场景中取得了较好的步骤判定效果。但现有方法仍存在不足之处,例如在旋紧螺栓等部分装配工序中,装配零件较为细小,视觉组件在不干扰装配人员操作的安全距离外识别能力有限;其次,部分装配工序对于操作人员的特定操作流程有一定要求,例如螺丝拧动的动作方向以及圈数等等,这些无法通过上述的两种思路进行识别;同时,受限于相机安装的固定视角,对于一些安装后会受到遮挡的零部件,单纯使用锚框法难以识别,需要将操作人员的动态手势动作纳入考量,作为视觉监督中判断步骤是否正确完成的依据。
现阶段对于操作人员手势识别的研究主要集中于以下几个方面:首先数据采集方式主要分为数据手套式与计算机视觉式,前者在提升精确度的同时会对操作者的动作形成限制;后者不影响操作者的手部动作,但容易受到环境条件、拍摄角度及手部自遮挡的干扰[4]。崔虎等人使用Kinect设备采集RGB信息以及深度信息,结合卷积神经网络与卷积长短期记忆网络的方法提取动态手势的短期异步特征[5];于安钰使用调频连续波(Frequency Modulated Continuous Wave, FMCW)雷达进行动态手势的采集识别[6];赵雅等人结合Kinect设备与Leap Motion采集的信息使用XBoost算法对动态和静态的手势进行识别[7];郭放等人采用MEMS加速度传感器进行数据采集,以进行后续对手势的研究[8];以上手势识别的方法需要使用Microsoft Kinect、Leap Motion、传感器或数据手套等特定设备,基于经济性与使用便利性的考量,常见的二维工业相机相对具有更为广泛的应用潜力。就对采集到的动态手势数据使用的识别算法而言,谷学静等人采用串联CNN-LSTM的方式实现了对数据手套采集的简单手势的识别[9],将特定手部位置的加速度、角度等信息以及时序信息纳入考量;Yu等人提出了一种基于CNN与特征融合的手势识别方法[10],通过特征提取层识别特定点位;孙博文等人使用小型卷积对二值化手势数据进行训练,以通过指尖检测的方式检测手部并建立动作映射[11],但在面对手指距离较近时效果不甚理想。Hussain 等人使用迁移学习的方式,尝试同时对静态及动态的手势进行识别[12]。以上方法针对的动作往往较为简单,不涉及手部各部分或与零件之间的遮挡情况,在此场景下适应性有所欠缺。
本文对人工装配视觉监督场景下特定装配动作的识别方法进行研究,提出并比较了基于手部特征点空间位姿信息的动态手势数据集构建方法及结合手部特征点空间域与时序信息的动态手势识别方法,使用三种较为复杂的动作进行测试及验证,实现了以较低的部署成本、较高的精度及鲁棒性完成人工装配过程中特定动作的识别目标,为视觉监督步骤判断提供了新的可参考依据。
1 动态手势数据集构建方法
首先需要实现的是动态手势数据集的构建。本段内容将对人工装配视觉监督场景以及不同的数据采集与处理方法进行描述。
1.1 场景描述及原始数据采集方法
在人工装配视觉监督场景中,除常见的装配体与机器视觉采集设备保持相对位置固定的情形之外,亦存在部分涉及到拆卸、重新组装及体积较小、非固定相对位置的情形,例如筒形零件与轴状零件的互相组装过程,装配体位置不固定且内部的螺栓等零件存在遮挡。为实现成本控制以及减少对装配者操作的影响,本研究使用固定安装角度的二维工业相机对装配操作过程中的动态手势进行识别。二维工业相机采用俯视视角拍摄,视野需要覆盖装配台及装配员实际进行操作的区域。
为使数据更加轻量化进而降低模型尺寸及对运算能力的要求,原始手势数据考虑使用手部关键点的识别及提取方法。目前常用的手部关键点提取开源库有OpenPose[13]及Mediapipe Hands。鉴于后者不依赖躯干检测,故采用Mediapipe Hands进行关键点提取。

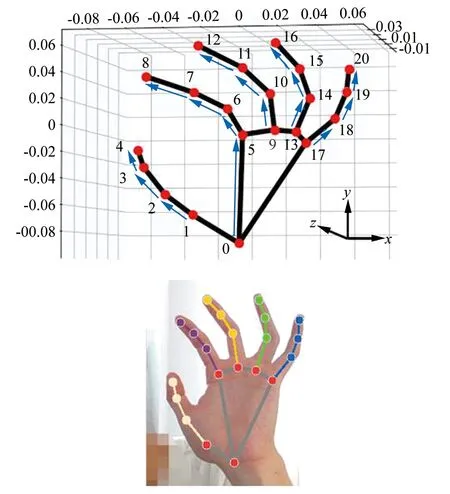
▲图1 手部关键点示意图
初步提取的原始数据中所包含的是如图1所示的21个特征点位在相机视野中的二维像素坐标[w,h]以及相对特征点0的深度估计值z;基于手部关键点的静态手势识别方法以及识别视野内平移等简单动作的方法通常直接对以上信息进行使用[14]。记为C:
(1)
为消除相机拍摄画面畸变对特征点位定位造成的影响,首先需要对相机画面的畸变进行处理:出于降低计算负荷的考量,此处仅考虑二阶及以下的径向畸变并忽略切向畸变。记[h′,w′] 为考虑上述畸变的像素坐标,r为像素点到图像中心点的距离,一阶径向畸变系数为k1,二阶径向畸变系数为k2,可得畸变模型为:
(2)
利用上述公式(2)即可求解每个关键点近似的实际像素坐标[w,h]。
1.2 基于掌根-端点特征的方法
在本场景下,为进一步提取出复杂动态手势中所包含的信息,需要对此原始数据进行进一步处理。首先需要将相机视野中的二维像素坐标[w,h]转换为以手部关键点0为原点的手部坐标系PHAND下相对坐标[x,y]。为此需要进行坐标系的转换。记相机内参矩阵为K,坐标变换矩阵为[R|T)],原始数据消除径向畸变后的坐标[w,h,z],手部坐标系下每个点位对应坐标[x′,y′,z′]:
(3)
由于原始数据消除径向畸变后的坐标[w,h,z]的z分量为相机坐标系PCAM下的估计值,即以关键点0的估计深度为参照原点,为便于表示及计算,设坐标变换矩阵如下:
(4)
其中:w0为手部关键点0在消除径向畸变后的横坐标,hmid为所有手部关键点消除径向畸变后的最大纵坐标与最小纵坐标之平均值:
(5)
在以[w0,hmid,z0]为原点的手部坐标系PHAND下,使用缩放矩阵S对每个点位的坐标进行处理,以消除手部相对相机距离变化以及不同装配者手部尺寸变化造成的影响
(6)
其中缩放系数Sx、Sy、Sz的计算方法如下:
(7)
转换完成后手部关键点的提取效果如图2所示。

▲图2 手部关键点坐标示意图与实际手势图片
以位于手掌根部的关键点0为出发点,以其余关节处的20个关键点为端点,如图3所示,通过坐标运算得到20个掌根-端点特征向量并组合为矩阵,记为:
Vtip=[Vtip,1|Vtip,2|…|Vtip,20]
(8)
(9)

▲图3 关键点6、7、8对应的掌根-端点特征向量示意图与实际手势图片

(10)
1.3 基于指节特征的方法
基于指节(指骨)的特征是手势识别的可利用特征之一[15]。在本场景中,为进一步提取原始数据中潜在的可利用信息,选取多对关键点之间的空间坐标差值向量,使用包括拧、抓取、握在内的多种动作进行了初步的观察。如图4所示,以顺时针拧动螺丝刀这一动作进行时3组指节之间夹角关系为例,发现各手指指节之间的相对夹角在执行特定手势时存在具有一定规律的波动现象。
为在提取上述关键点对间信息的同时避免将数据量由O(n)(n为关键点数量)上升至O(n2),采取如表1所示的16对关键点对纳入指节夹角特征的数据提取方法。

表1 纳入指节夹角特征的手部关键点对

▲图4 拧动动作指节夹角关系变化曲线示例
分别以上述表1中的16个指节特征关键点对为首末端点构成点集Σfingers,如图5所示,通过坐标运算得到16个指节特征向量并组合为矩阵,记为:
Vfingers=[Vf-1,2|Vf-0,5|…|Vf-19,20)]
(11)
▲图5 纳入指节夹角特征的手部关键点对构成的特征向量示意图与实际手势

(12)

(13)
1.4 基于掌面-指节夹角特征的方法
在上一提取方法的基础上,为进一步提取指节相对于手掌整体的弯曲程度信息,本文继续提出基于掌面-指节夹角特征的提取方法。
首先,如图6所示,将手部特征点0、5、17确定的平面设为手掌掌面参考平面,同时利用向量V0-5和V0-17向量外积提取掌面参考平面法向量Npalm:
(14)

▲图6 掌面参考平面法向量Npalm示意图与实际手势
在掌面参考平面法向量的基础上,考虑其与表1的指节关键点对之间的关系。由于指节向量与掌面之间的夹角一般情况下介于0°至180°,因此指节向量与Npalm的夹角一般情况下介于-90°至90°之间,因此使用向量外积的方式能通过正弦函数的性质较好地反映包含夹角在内的相互位置关系。因此,分别以上述表1中的16个指节特征关键点对为首末端点构成点集Σfingers,通过外积运算得到16个掌面-指节特征向量并组合为矩阵,记为:
Vpalm=[Vp-1,2|Vp-0,5|…|Vp-19,20]
(15)
(16)

(17)
2 动态手势识别方法
在动态手势数据集构建完成之后,需要对每个滑动窗口内的动态手势进行识别,以确定当前是否执行了特定装配动作。
由图4可见,针对部分动作进行时存在输出信号规律性波动的现象,首先考虑使用基于时序特征的阈值分割方法:对符合特定递增/递减阈值的特征向量进行周期性的模板匹配是其中一种思路[16]。然而,在本场景下此类方法存在以下不足:识别夹角变化较小的动作时,阈值可能难以被触发;并且针对不同的动作,需要人为对阈值进行调整以更好地契合实际的振幅及信号一阶微分范围。为提高识别模型针对不同动态装配手势的识别准确度及减少人工调整阈值的工作量,本节接下来主要探讨基于神经网络(Neural Network)的识别方法。
2.1 循环神经网络的构建
由于装配动态手势具有时间上的连续性,单一时刻的手部关键点及特征向量不足以反映动态的变化过程,为充分将时序信息纳入考量,可以引入循环神经网络(Recurrent Neural Network)对手势信息进行分类识别[17]。经典的循环神经网络结构包括长短期记忆网络(Long short-term memory,LSTM)及其改进版本的循环门控单元(Gated Recurrent Unit ,GRU)[18],利用隐藏层输出h向下一帧输入传递时序特征。本文构建的LSTM与GRU网络基本架构如图7所示。
为进一步探究特定动态手势中潜在的长期时序特征,对LSTM及GRU的模型深度进行增加[19]:在单层GRU/LSTM的基础上,分别对时序传递过程中的隐藏状态(hidden state)进行提取,作为传入第二层GRU/LSTM的输入数据;同理将第二层的隐藏状态作为输入传入第三层。其网络结构分别如图8、9所示。

▲图8 双层LSTM与GRU模块每层参数数量与基本架构图

▲图9 三层LSTM与GRU模块每层参数数量与基本架构图
2.2 卷积神经网络的构建
鉴于卷积神经网络(Convolutional Neural Network, CNN)在图像分类问题上的出色表现[20],本文基于手势识别中对结果分类的相似需求,将滑动窗口内的三维输入矩阵进行扁平化(Flatten),转化为二维的矩阵,输入卷积神经网络进行研究。
经典的用于图像分类的CNN模型包括:VGG (Visual Geometry Group)[20]、GooLeNet以及深度残差网络(Deep Residual Network, ResNet)[21]等。VGG的特点之一在于,卷积层均采用了相同的较小的3x3卷积核参数,池化层亦采用相同的池化核参数,堆叠为规整的模块,结构相对简单之余具有一定的深度,预期具有较好的拟合能力;GoogLeNet引入了Inception模块,使用不同尺寸的卷积核提取非线性特征,并利用中间层作为辅助分类器进行识别,并使用平均池化与Dropout替代全连接层的方式防止过拟合;ResNet根据拟合残差相对于拟合潜在映射更为简易的思路引入了残差块的概念,通过残差块的shortcut平滑误差曲面(error surface),使用卷积层的stride取代池化层、平均池化层替代输出端全连接层等方式,在易于修改与拓展的同时,取得了更好的性能表现。
对三维输入矩阵进行扁平化之后,本文针对输入矩阵相对传统图像维度较小的特点,对上述三种经典模型进行了一定程度的改进。其中,改进后的类VGG-13模型结构如下图10所示;将GoogLeNet中使用的Inception模块维度均调整为默认值的1/4;深度残差网络类别中,选用类ResNet-50的结构,并使用Bottleneck类型的残差块,同时在末尾的平均池化层使用2×2的小型池filter。

▲图10 改进的类VGG-13模型示意图
3 动态手势识别实验结果与分析
为对人工装配视觉监督场景下动态手势识别任务中章节1所建立的手势数据提取方法及章节2所讨论的识别方法的效果进行对比研究与分析,本节使用章节1中建立的三种数据集,分别随机分割为80%,20%作为训练集和验证集。
所有实验均在3.6 GHz CPU (Inter i7-6850k)、NVIDIA GeForce GTX 1080 Ti 显卡和16GB RAM 的台式电脑以单线程进行。实验基于Linux 系统,开发工具为VS Code,编程语言为Python,深度学习框架为Keras。
3.1 实验场景及数据采集
依据实际人工装配过程中常见的装配动作,本节选择了拧(screw)、握(grasp)、抓取(pick)三个动作作为识别对象类别;同时,为契合实际,采集一定数量的装配过程中常见的、与步骤判断无相关性的动作作为第四类其他动作(others)纳入数据集中。四类动作示例如图11 (a)-(d)所示。

▲图11 实验场景选择的4个动作类别示例
实验数据采集场景及装置如上图所示,使用海康MV-CS-050-10GC工业相机对上述四类动作的动态手势进行视频采集,采集帧率为为20 fps,每个样本包含连续30帧对应动作图像。样本包括单次动作和连续多次动作,动作执行的速度亦有一定差别。实验中的动态手势由5名不同操作人员完成,具有一定的代表性。剔除采集过程中由于环境干扰、动作偏离采集范围等原因造成数值异常的样本后,每个有效原始动态手势样本均分别经由章节2所述的三种方法进行处理并标签化,消除原始数据差异对数据处理方式的影响。
实验场景采集的有效原始数据样本类别及数量如表2所示:经乱序混合后,随机选择80%的样本(合计962件)作为训练集,剩余20%样本(合计240件)作为验证集。

表2 实验场景采集的数据样本类别及数量

表3 基于掌根-端点特征数据集实验结果

表4 基于指节特征数据集实验结果
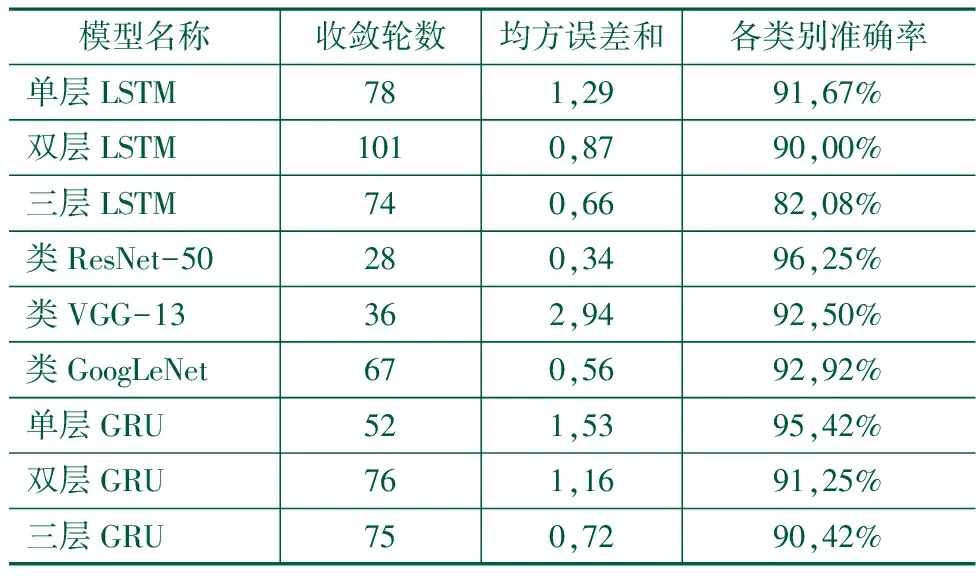
表5 基于掌面-指节夹角特征数据集实验结果
3.2 实验结果与分析
使用经章节1所述三种方法处理后的上述样本,分别使用章节2所述的3种LSTM算法、3种GRU算法、3种CNN算法进行实验。训练最大轮数(epoch)设置为200, 学习率(learning rate)为10-3,梯度剪裁范数(clipnorm)为0.1。各数据集各方法训练收敛所用轮数(训练时均值平均精度达到95%所需的epoch数量)、均方误差和(loss)、验证集上的各类别精度(categorical accuracy)如表3-5所示。
由上述实验结果对比可知,整体而言基于掌面-指节夹角特征数据的模型准确率优于基于掌根-端点特征或基于指节特征数据的模型;此场景下循环神经网络类模型的层数深度与准确率之间无显著关联;卷积神经网络类模型中最深的残差神经网络整体准确率优于其余两种模型。
准确率最高的动态手势数据采集方法与算法模型组合为掌面-指节夹角特征数据集-深度残差网络,其次为掌面-指节夹角特征数据-单层GRU。此两种方法的可训练参数数量及浮点运算数(FLOPs,Floating Point Operations)如表6所示。

表6 准确率大于95%的两种较优模型的模型复杂度对比
实验结果表明,利用图像分类思路将滑动窗口内逐帧矩阵展平导入卷积神经网络之中,可以有效实现动态装配手势分类的目标;而单层GRU模型在参数数量及前向传播所需算力远低于卷积神经网络模型的前提下,依然能充分提取不同动作类别在滑动窗口内各帧之间的时序特征关系,并取得相对较好的识别准确率。针对不同场景的不同手势重新训练模型时,如训练过程中或部署设备的算力或内存有限,结合基于掌面-指节夹角特征的动态手势数据采集方法与单层GRU循环神经网络亦可实现较高的手势识别类别准确率,基本满足该场景下视觉监督对手势识别的需求。
4 结论
针对在人工装配视觉监督场景下,依赖物料与装配体的识别方法视线易受遮挡、可识别装配步骤有限的问题,本文提出的三种基于手部关键点的动态手势数据采集方法均能较好保留动态手势的空间域与时序信息,其中基于掌面-指节夹角特征数据的模型准确率最高:结合单层GRU循环神经网络与改进型类ResNet-50卷积神经网络类算法,均能在装配场景采集视频流的连续时序滑动窗口中较好地识别特定装配动作,有效弥补依赖装配物料目标检测类型视觉监督方法存在的不足,相比现有方法将可进行视觉监督的装配步骤拓展到了拧转、抓握等操作手势及内嵌螺栓螺柱等视野受限的零件。但目前本文所用方法仅实现了特定动态装配动作识别的目标,针对可能的动态手势定量分析及与工装目标检测的结合将是未来的研究方向。
猜你喜欢
网络安全技术与应用(2022年5期)2022-07-26
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
中国设备工程(2017年11期)2017-06-29
小学阅读指南·低年级版(2017年6期)2017-06-12
创造(2016年5期)2016-02-01
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
