
信息抽取赋能地质调查发展综述
2023-07-10 00:04:34张云飞郭俊杰
电脑知识与技术 2023年14期
张云飞 郭俊杰

关键词:自然语言处理;信息抽取;知识服务
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)14-0102-04
0 引言
在地质学领域当中,长期以来由于技术方法及研究方向的多样性已经积累了海量的地质资料。从数据的组成结构上来说,海量的地质资料数据包括大量结构化的数据及非结构的数据特别是文本数据及其地质图件数据[1-2]。地质大数据时间上横跨大,空间概念强,各种地质作用相互影响因素较多,包含各类不同的地质调查数据、相关的矿产勘查数据及长期的地调工作者工作与科研过程中产生的海量数据,从数据形式上包括文本数据、音视频数据、图表等形式多样化类型,数据的来源也是多样化的,包括各个级别的图书馆、各类矿产勘查当中的资料数据、发表的文献数据及中国地质调查数据库等[3-4],其中主要以非结构化数据居多。而且非结构化数据是非常重要的地质信息来源及非常有潜力的人机交互手段,是地质学家认知结果的一种自然语言的表现形式[5-6]。因此,面对大量地质调查报告、文献等非结构化数据的增长与地质资料中蕴含丰富知识信息未被有效利用之间的矛盾,从地质文本当中挖掘知识已是地质信息科学迫切需要解决的问题[7-8]。
当前中国地质调查局“地质云”平台完成资源管理、业务系统等信息化建设工作,但在数据量的应用仅是基本解决大量非结构化、半结构化的地质数据进行平台组织、存储和快速发现[9]。全国地质资料馆馆藏地质资料共245.191万档。这些海量的地质资料包括传统的纸质资料已经完成了数字化的工作,其中数据量已经达到120TB以上,面对海量的地质调查数据资料,需要进一步树立大数据思维、定量思维及获取“地质资源”和形成核心“地质数据知识”的新思维方式,以数据密集型工作方法为基础,进而实现地质数据高效便捷地集成与融合[7-8]。
英美等国家地质调查局结合地质社会需求,以问题作为研究的主线,设置与完成了地质大数据相关的研究及其利用的计划。美国地质调查局颁布与制定了《美国地质调查局核心科学体系科学战略(2013-2023)》,在这一文件当中非常明确地建立了地球科学领域当中研究的大数据体系与架构,对地球科学领域当中的核心体系进行了进一步的强化,期望能够通过这种大数据的相关理论与方法来进一步地提升地质大数据中的搜集、数据的挖掘与分析[10]。
1 地质信息抽取关键技术
面对海量的数据信息,如何在此基础上构建分学科、分场景的形式的智能化地质知识挖掘,从更多维度展示地质数据资源,一直是地质与其他行业关注的重点问题。随着数据体量不断增长,基于深度学习的方法兴起对海量的信息内容进行自动分类、提取和重构,转换,改进现有的基于机器阅读理解的实体关系框架,便于构建知识图谱或者能直接查询的结构化信息[11]。可见信息抽取在机器翻译、图像识别与分类、语音识别等许多自然语言处理应用中崭露头角[12-13],然而地质领域中非结构化数据还未得到充分的利用与挖掘[14]。
信息抽取作为分析、抽取、管理文本知识的核心技术和重要手段,自诞生以来就得到了学术界与工业界的广泛关注,是自然语言处理领域的重要研究方向之一,也是人工智能领域极具应用价值的核心研究课题。从非结构化文本中抽取出以结构化形式存储的信息,可以被计算机直接处理和利用,实现让机器能够像人类一样阅读文本,进而完成查询和推理等功能,一直是信息抽取追求的目標。现如今,信息抽取系统可应对海量非结构化文本,在各领域都有广泛的应用。
1.1 地质实体识别与关系抽取联合学习
地质实体识别(geology Entity Recognition)与关系抽取(Relation Extraction)属于信息抽取两项子任务,采用自然语言处理技术(NLP)定位非结构化地质文本中的实体,并抽取出三元组自动构建实体之间关系类型,是信息抽取中的关键。
在以往的研究中,实体关系抽取大多采用流水线方法[15-17],流水线的框架工作虽然易于执行,但其具有误差传播和信息丢失的缺点。为了解决这一问题,采用联合抽取方法可有效解决了流水线模型的不足并获得了三元组抽取领域最先进的性能。联合学习方法将实体识别与关系抽取联合建模,使两个子任务在一个模型中共同优化,以实现子任务之间相互促进的目的。传统的联合抽取模型[18-20]都是基于特征向量的,这些方法需要人工参与构造特征。为了减少人工工作,基于神经网络的联合抽取方法[21-23]获得了人们的关注。但是,现有的很多神经网络联合模型[24-25]是基于共享编码层实现的。这种方法只是简单地共享两个子任务的编码层,为了获得关系三元组,其仍然采取的是先识别实体后提取关系的方法。所以,这不被认为是真正的联合抽取。Zheng等人[26]提出了一种新的全局标注方案,其直接对三元组进行建模实现了真正意义上的联合抽取。该方法使用了BiLSTM和具有偏置损失的LSTM对输入数据进行联合编码,解决了错误累积的问题,但其采用的就近合并原则忽略了重叠三元组问题。Zeng等人[27]首先引入了重叠三元组问题,其给出了重叠的三种不同形式并提出了带有复制机制的Seq2Seq模型来解决此问题。Fu等人[28]提出了一个端到端的实体关系抽取模型GraphRel,模型使用关系加权的图卷积神网络有效考虑了实体和关系之间的相互作用以及可能重叠的三元组,在解决三元组重叠问题上取得了良好的效果。尽管以上方法取得了很大进展,但是这些方法都将关系看作是映射到实体对象的离散标签,使得关系识别成为一个简单的分类问题。为此,Wei等人[29]基于BERT提出了一种级联二级标记框架CASREL,该方法将关系视为从头实体映射到尾实体的函数,模型只需要识别出在不同关系下与头实体对应的尾实体,显著提高了对重叠三元组的提取能力,达到了当时的最优水平。但其在标注过程中只是简单地将各词向量输入分类器,忽略了实体的上下文信息和抽取的实体长度。
1.2 事件抽取
事件抽取任务是一种比较复杂的信息抽取任务形式,可以看作实体识别和若干关系抽取任务的总和,也是信息抽取领域最具有挑战性的任务之一,在阅读理解、文本摘要、问答系统等领域得到了广泛的应用。领域事件抽取的时间类型是需要针对某一特定领域进行预定义,而且基于中文事件抽取由于中文语言特性问题,面临着较大挑战,使得研究更具有意义。
国内外对于英文事件抽取的研究展开较早,技术也较成熟。对于中文的事件抽取起步较晚,例如Feng 等人提出使用双向长短期记忆网络(Bi-LSTM)和卷积神经网络来进行事件抽取[30];Chen和其他相关研究人员于2015年,提出了一种基于动态多池化卷积神经网络(DMCNN)的事件抽取模型[31],可以捕获语句中包含的多个事件信息;虽然也取得了一定的成果,但是距离英文还有一定的差距。国内外的事件抽取研究大多数都是围绕ACE会议及其相关测评语料展开的。从ACE2005评测情况来看,参加英文事件抽取评测的单位比较多有BBN Technology、LockheedMarting、IBM 等公司以及荷兰阿姆斯特丹大学。唯一参与中国赛事测评的机构是BBNTechnology,同时该机构在英文事件抽取的评测中获当年最佳成绩[32]。
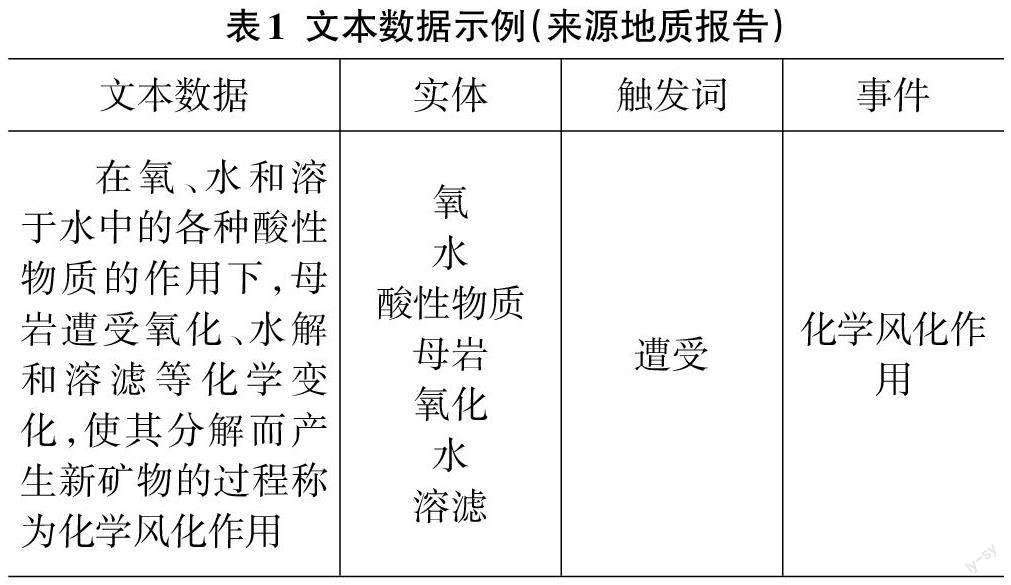
地质的事件关系反映了之间的一种语义关系,可以为地质文本数据的深层理解提供关键线索[33],事件关系抽取的目的则是提取一段文本内容中两个事件可能存在的关系[34],例如表1其中事件“化学风化作用”对氧、水和溶于水中的各种酸性物质、母岩、氧化、水解和溶滤、存在因果关系。
在当前事件之间存在多少种关系类型仍然是一个有争议的问题,目前事件关系抽取主要研究共指关系、因果关系和时序关系,此外关系文本的多样性和隐含性使得从文本中识别不同类型的事件关系面临巨大挑战。
1.3 指代消解
地质报告或其他文本的日常用语当中,在下文采用简称或代称来代替上文已经出现的某一词语,语言学中把这种情况称为指代现象。指代现象能够避免同一词语重复出现所造成的语句臃肿、赘述等问题;但也因为这种省略造成指代不明的问题。
通常人们将指分成两种:回指和共指。回指表示当前的,对应词语与在前文出现的词语之间有着紧密的含义联系,在地质文章中这个情况也十分常见,由于本文中通常使用简称表示地质体的,因此在图二的“该区”“该地层”本身并没有意义。这种共指称方法取决于语境含义,代词共指代,它在不同的话语情境中可以表示为不同的实体。而共指是指某两个。
词语、名词短语或代词等指称的都是真实世界中的同一个实体,因此这些指称关系即使在断章取义的情形下也成立。下面,我们就把本文中的各种名词短语、或代词等统称,作为对命名实体的一次提到(简称提及)。共指和代指这二种概念虽有一定的重叠,但相互之间并不彼此涵盖。通过单纯的语言方法和模式很难处理全部的指代问题,所以必须针对不同的指代问题加以研究。共指和回指这两种概念之间虽存在着一定的交集,但并不彼此涵盖,所以通过简单的理论方法和语言模式很难以解决全部的指代问题,所以对于不同的指代问题需要分别进行深入研究。
最初,像其他信息抽取问题一样,共指消解方法研究渐渐从启发式规则演化为机器学习方法。这种转变主要归功于统计自然语言处理以及MUC国际性会议标注了带有指代关系的MUC-6(1995)和MUC-7 (1998) 语言资料库,并公开化。从此,基于机器学习的共指消解进入科研人员视野。但传统的机器学习研究精度不高、语义理解不够,随之引入一系列基于神经网络的模型[35-39],应用到指代消解上去取得了更好的效果,同时具有更高的计算效率,避免了传统共指消解模型的若干问题。
1.4词义消歧
理解词义是正确理解句子或全文的基础,而判断词义离不开语境、语言背景、上下文关系。机器要像人类一样自动评估和选择词义是一项艰巨的任务。
词义消歧的发展历程中,涌现了大量的解决办法。例如,传统的基于知识的词消歧,结合机器学习的监督词消歧等。前者的实现效果虽然出色且稳定,但强烈依赖于知识源的完备性,而现有语义知识源的缺乏性和静态性极大地阻碍了此类消歧方法的改进。后者中最有效的策略之一是基于Word2Vec embedding的词消歧模型,与传统方法相比有所改进,但缺乏标注数据也限制了模型的灵活性和泛化性[40]。在当前出现的双向长短期记忆网络模型,借助于Bi-LSTM特性捕获上下文中的语义信息和词序信息,可以很好地表示目標词的意义特征。[41]在此基础上,额外添加了一种注意力机制(Attention)来了解上下文窗口中不同词对目标词的影响[42],是当前学术领域的先进技术之一。
2 总结
地质非结构化数据抽取技术的研究,一方面可以便于地质工作者对专业信息需求,和现在以及未来的结构化、系统性的研究,从而可以在需求上大大提高了数据获取、计算、数据分析准确率,各研究部门与人员协调配合决定实施与调整的效率。另一方面也丰富了地质学科的各类数据库,为今后的科学研究,包括地质学科信息图谱的建立、找矿行动的建立等提供较为专业而易于利用的信息来源。本文先后调研了多篇严格筛选的国内外具有创新性的学术论文,并对此类成果的主要技术、模型方法等进行了对比总结,发现传统的规则抽取需要具备一定的语言学水平,并且对特定领域有深入的理解和认知;机器学习则无法理解语句中的语义关系。目前来说,主要依靠深度学习技术的BERT处理模型在未来一段时间内,仍会成为人们关注的焦点。加之中国地质资料的信息抽取研究起步相对较晚,所以各种数据库的工具资料都比较匮乏,对各种资料的格式也没有统一的规范,同时也因为中文与英文的语言特点不同,在实际应用中的资料处理方式也多种多样。
上述一些原因在一定程度上影响了有关科学研究的进行。所以,除了探索各种有效的建模方法,解决其中实际面临的困难也成为当务之急。在标准和规范的帮助下,地质非结构化资料的信息提取这一研究方向将会获得更好的发展,从传统地质调查转向人工智能的“寻金之路”。
猜你喜欢
计算机应用(2016年12期)2017-01-13 01:24:36
环球人文地理·评论版(2016年5期)2017-01-03 04:36:05
现代情报(2016年11期)2016-12-21 23:34:35
现代情报(2016年11期)2016-12-21 23:32:05
现代情报(2016年10期)2016-12-15 11:41:13
商情(2016年39期)2016-11-21 09:55:26
新世纪图书馆(2016年9期)2016-11-15 02:08:04
电脑知识与技术(2016年10期)2016-06-16 21:16:32
求知导刊(2016年10期)2016-05-01 14:09:25
电脑知识与技术(2016年5期)2016-04-14 11:12:38
