
基于PCA-ANN 的碱性电解水系统气体纯度预测
2023-07-07 10:20:42毕可鑫戴一阳李汶颖
华东理工大学学报(自然科学版) 2023年3期
黄 超,李 航,周 利,毕可鑫,戴一阳,李汶颖
(1.四川大学化工学院, 成都 610000;2.清华四川能源互联网研究院, 成都 610000)
氢气是石化工业的关键原料之一。近年来,由于新的燃料电池的应用,氢变得更加重要。现阶段化工工业制氢主要依靠化石能源的重整,方法有水蒸气重整、部分氧化、煤气化和氨解等[1]。随着我国提出2060 年达到碳中和的目标,绿氢技术开始在国内发展[2]。所谓绿氢,是指利用可再生的清洁能源产生电,再通过电解水得到氢气。绿氢技术将间歇性、不稳定性的清洁能源转化成为具有能量和物质双重属性的氢。
绿氢技术由于其在脱碳领域的优势[3-6],也会在未来的化工领域成为氢气生产的主要手段。一方面,随着天然气、煤等能源价格逐年上升,会造成化工原料制造成本的上升。而随着可再生能源发电价格持续降低,在未来原料氢的选择上,绿氢比其他氢更具有成本优势。另一方面,电解水的生产规模已经逐步扩大,现有碱性(AEL)、阴离子交换膜(AEM)、质子交换膜(PEM)和固体氧化物(SOEC)这4 种电解水技术[7-8]也愈加成熟。
对于化工工艺而言,用于化工生产的氢的产量必须达到吨级甚至万吨级以上,对应到电解氢的商业化规模要达到MW 级甚至GW 级。目前只有碱性电解水技术可以通过集群的方式达到该规模,并且该技术成本最低,设备寿命更长,无疑是化工领域制氢技术最好的选择。然而由于氢气的爆炸极限广(体积分数范围为4.0%~75.6%),碱性电解水技术操作弹性较低。在电解槽内,气体很容易发生扩散,尤其是氢侧的氢气更容易扩散。氧中氢(HTO)为氧气中氢气所占体积比,其决定了设备安全操作的边界。一般来说当HTO 值超过2%时,设备强制停机[8]。因此对于AEL 水解中HTO 值的预测是工艺生产的关键。
许多学者提出了用气体纯度模型去预测HTO值。Haug 等[9-10]将电解槽视为两个连续操作釜式反应器(CSTR),考虑了操作条件,如电流密度、电解液流速、浓度、温度以及工艺管理对于HTO的影响,提出了一个基于溶解度模型的碱水电解生产气体纯度预测模型,并通过自制的电解槽实验对模型进行了评价。Kirati 等[11]在温度(0~90 ℃)、压力(0~3 MPa)、电流密度(24~600 mA/cm2)等操作条件下,提出了气体纯度的经验公式。Sánchez 等[12]根据极化曲线、法拉第效率与电流密度的关系,在不同的温度、压力等操作条件下,以15 kW 碱性试验台的数据为基础,采用非线性回归的方法,用MATLAB 进行参数非线性拟合,建立了预测碱水电解系统电化学行为的半经验数学模型。
目前存在的气体纯度预测模型是经验或半经验的电解槽模型,没有考虑系统层面的影响(整个制氢工艺除了电解槽外还包括辅助设备)。对于绿氢装置还存在电源供给端功率变化幅度大、不稳定的问题,现阶段的模型不能描述在功率波动时系统的表现。在多变量耦合的电解水系统中,一个波动的影响往往伴随着多个参数变化,且对于不同电解槽设备,设备参数一旦发生变化,原有的模型很难反映真实的气体纯度。
HYSYS 模型[13]能够实现特定电解槽参数下的气体纯度预测,但模型的迁移能力较差,且建立HYSYS 模型步骤繁琐。为实现不同电解系统的气体纯度预测,本文在HYSYS 工艺系统生产数据的基础上,进一步发展了基于主成分分析-人工神经网络(PCA-ANN)的气体纯度预测模型。该方法使用数据驱动的方式,通过电解装置运行数据即可完成预测,可普遍适用于各种电解槽设备气体纯度预测建模。
1 碱性电解水Aspen HYSYS 模型
1.1 模型简介
图1 示出了一个典型的碱性电解水装置。碱性电解水制氢技术采用碱性电解质(KOH、NaOH)作为循环水,从电解槽阴阳两极出来的气液混合相通过分离器分离气体后经碱液循环泵混合回流到电解槽中。氢氧分离器气相出口处各有气体检测装置。
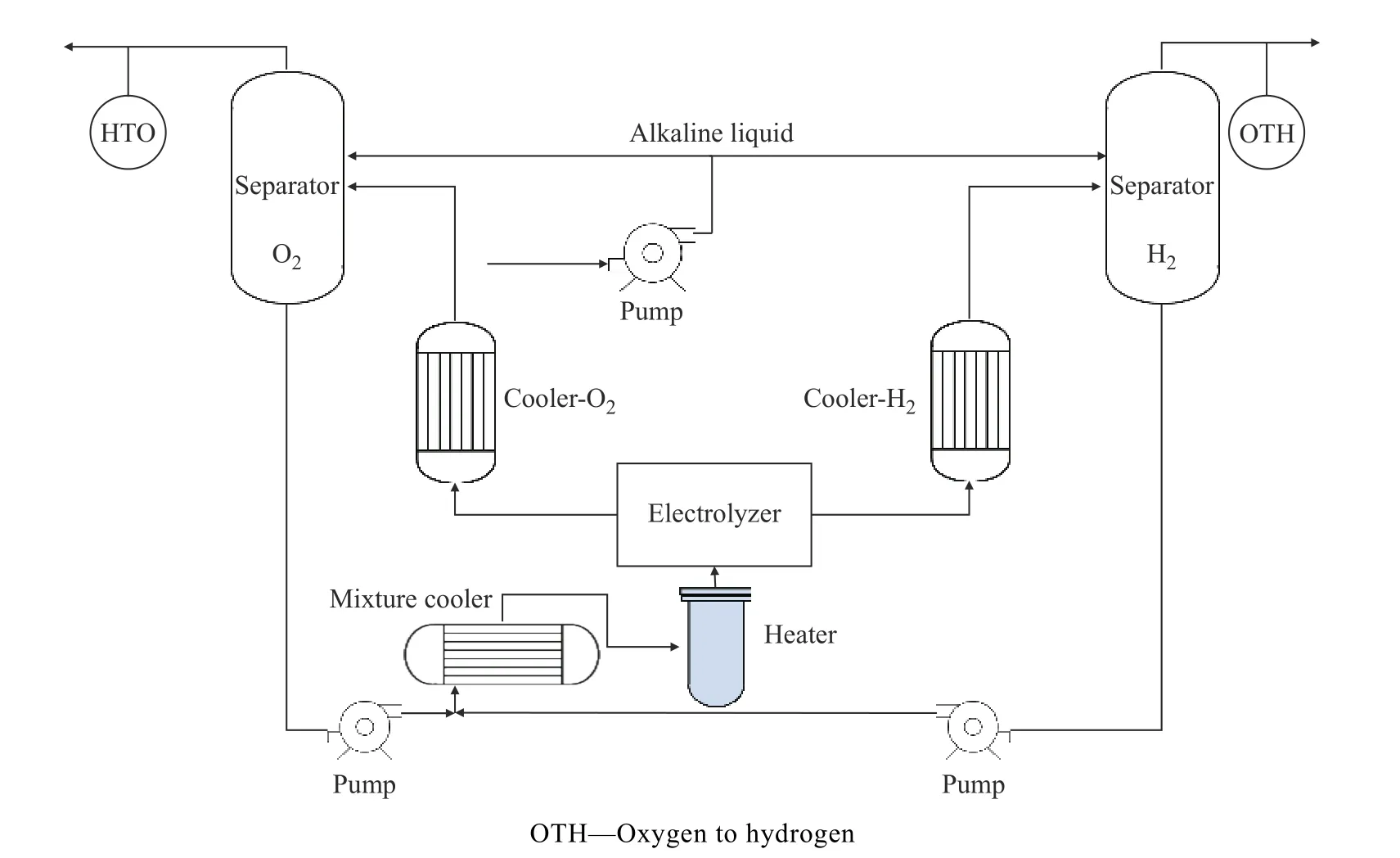
图1 碱性电解水装置Fig.1 Alkaline water electrolysis system
在碱性水电解中,OH-负责电荷交换,当电子转移系数为2 时,在电解槽阴阳极发生的反应如下:
根据实际碱性水电解装置流程搭建的Aspen HYSYS 模型如图2 所示。电解槽建模采用Aspen Custom Modeler (ACM)[14]工具搭建,其他装置如泵(PUMP)、分离器(SEP)、换热器(EXCHANGER)、混合器(MIXER)等均采用HYSYS 提供的内置模块单元。
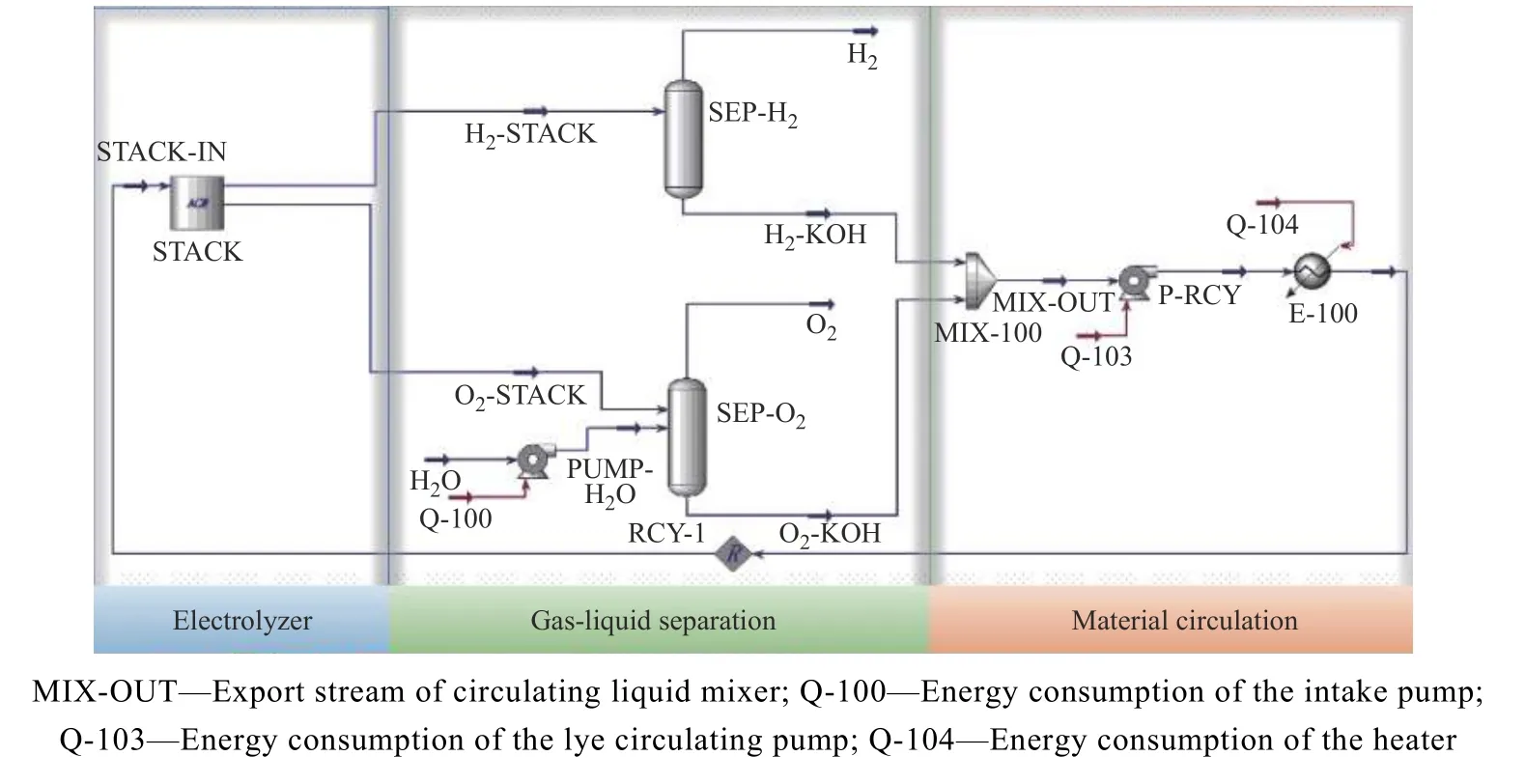
图2 碱性电解水系统Aspen HYSYS 模型Fig.2 Aspen HYSYS model of alkaline water electrolysis system
全流程模拟中,电解液(STACK-IN)进入电解槽发生电解反应,从电解槽(STACK)出口的阴极物流(H2-STACK)和阳极物流(O2-STACK)分别进入气液分离器SEP-H2和SEP-O2中并分离出其中的气相产品后,将剩余液相部分经混合器(MIX-100)混合后再经循环泵(P-RCY)回流。回流液温度通过E-100 换热器进行控制。电解消耗的水由补水泵(PUMPH2O)提供,以保证系统质量平衡。
1.2 电解槽模型
由于Aspen HYSYS 不包括用于碱性水电解池堆栈建模的操作单元,因此本文使用ACM 将碱性水电解池堆栈模型作为子程序集成到Aspen HYSYS中,ACM 允许创建自定义操作单元,再将单元堆栈模型合并到整个流程,如图3 所示。本文参考Sánchez[15]建立的电解槽模型,该模型包含了碱性电解小室的电化学模型和所有与堆栈中发生的质量和能量平衡有关的方程,能够预测碱水电解堆在不同操作条件(温度T和压力p)下的电化学行为。

图3 使用ACM 搭建的电解槽操作单元模型Fig.3 Operating unit model of electrolytic cell built by ACM
电解槽模型的必要输入参数包括电力输入、电池数量、电极的活性面积、堆栈温度和操作压力等。该碱性电解槽模型是半机理模型,基于与电解原理和一部分数据拟合的质量和能量平衡方程,以运行工况参数为因变量,计算出电解过程的极化曲线、法拉第效率以及氢气扩散量,得到最终输出阴阳两极气体的产量与纯度、电解过程中水的消耗量以及电解过程产热量与热损失量。
1.3 HYSYS 模型输入与输出
HYSYS 的输入包含物流和设备的输入。设备包括电解槽和其他辅助设备。ACM 模型电解堆栈由12 个表面积为1 000 cm2的双极碱性电解电池组成,电解液循环流速固定为15 L/min。电解槽的基本参数见表1。其他辅助设备参数见表2。电解液参数见表3。温度与压力均随设置的系统温度、压力变化。

表1 电解槽参数Table 1 Electrolytic cell parameters

表2 辅助设备参数Table 2 Auxiliary equipment parameters
通过HYSYS 模型运行,输出氢气产品和氧气产品的流量和组成(氧气产品组成中,HTO 为后续模型训练的关键指标值)。
1.4 HYSYS 模型评价与数据交互
设计装置工作压力为0.7 MPa,在模拟变工况生产时,为保证操作区间尽可能大,本文将操作范围适当扩大。电解水系统操作范围如表4 所示。

表4 电解水系统操作范围Table 4 Operating range of electrolytic water system
为保证模型产生的数据均匀覆盖工作点,本文通过Python Interface 操作HYSYS 模型,在恒定的工作功率下,调整系统的工作压力和温度产生数据,再变功率采集不同工作点位数据。
本文使用Sánchez[15]电解水装置生产的实验数据对模型进行评价,图4 所示为HYSHS 模型验证。如图所示,在55~75 ℃和0.5~0.9 MPa 下,HTO 随电流密度的变化符合实验测量数据点的变化趋势,可以得出该HYSYS 模型数据具有一定的准确性。
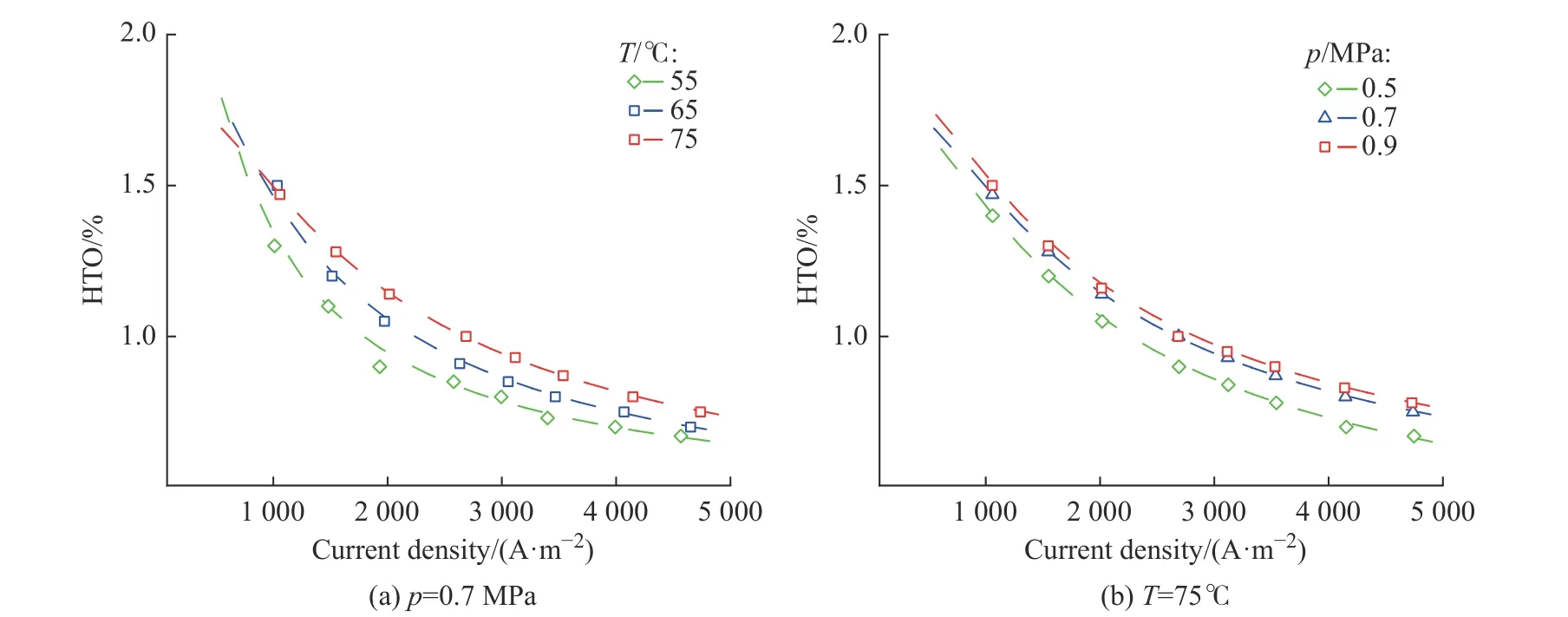
图4 HYSYS 模型验证Fig.4 HYSYS model validation
2 主成分分析-人工神经网络(PCA-ANN)
2.1 主成分分析(PCA)
PCA 是一种数据线性降维算法[16],最开始应用于人脸识别领域[17]。目前已经广泛应用于化学计量学和化学信息学[18-19]。它可以将高维的数据映射到低维空间中,以方差最大为信息量保留的标准,在降维的同时能够比较好地保证原始数据的信息量。
碱性电解水工艺是电-热-化学多变量耦合的系统,从HYSYS 模拟中提取的数据维度较高,许多变量之间存在耦合关系。因此使用PCA 先处理数据集,保证信息量的同时可以减轻模型的负担。
2.2 人工神经网络(ANN)
ANN 是对人脑或自然神经网络若干基本特性的抽象和模拟[20],通过神经元的简单连接计算,模拟人类大脑中神经系统的信息交互方式。目前ANN及其各种改进网络已经广泛用于工业、社科、分子研究等各种领域,可以用于策略优化、装置模拟、值预测等[21-26]。ANN 有强大的数据学习能力,本文将其应用于碱性电解水装置中HTO 值的预测,建立了气体纯度预测模型。
ANN 的结构如图5 所示。人工神经网络拥有输入层、隐藏层和输出层。输入的M个变量构成向量后输入隐藏层神经元进行计算并输出。对于输入的变量x∈R1×M,经过人工神经网络计算后输出变量Y∈R1×1。
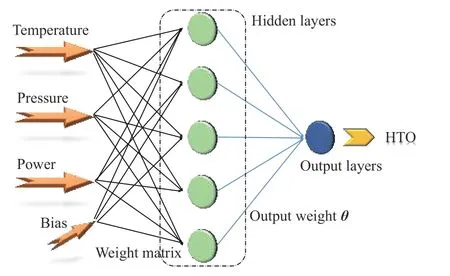
图5 人工神经网络结构Fig.5 Artificial neural network structure
本文输入变量为各种变化操作参数,如压力、温度、功率等。隐藏层含有N个神经元。对于一个输入向量x,在经过隐藏层时乘以矩阵w,w∈RN×M,再加上偏置单元b0,b0∈R1×N。
权重矩阵W(W=wT)连接输入层与隐藏层。在隐藏层的神经元接收到了向量z后,神经元进行激活函数的计算。
激活函数将非线性特性引入到ANN 网络中,让ANN 能够学习到非线性的数据特征。神经元激活后的向量z',同样需要乘以系数矩阵θ,再加上一个偏置单元b1,得到输出层y。本文中输出为电解水的HTO 值。
最终通过ANN 建立输入和输出的关系。
对于W、b0、b1、θ等参数则通过神经网络的训练得到。神经网络的训练方式为BP(Back Propagation)反向传播[27]。BP 反向传播首先通过ANN 的正向计算得到损失函数L,对损失函数反向求导,用梯度下降来调整参数。对于k组训练数据(xi,yi)i=1,2···k,以常用的平方和作为损失函数L来介绍反向传播过程。
其中:f代表ANN 正向计算函数。首先,需要对模型参数进行初始化,通过正向计算得到损失函数值。然后,求出误差函数关于神经网络自身变量(w,b0,b1,θ)的偏导数,反向更新模型参数,即梯度下降法[28]。
以上公式中的点表示矩阵点乘。当偏导数求出后通过式(11)更新模型参数。
其中:r为模型训练设置的参数学习率,其决定了ANN 的训练速度和质量。
3 PCA-ANN 模型整体架构
如图6 所示,本文模型主体部分是PCA-ANN 网络,它围绕PCA-ANN 模型迭代过程,涉及了数据传输、数据预处理、模型训练、模型评价这4 个步骤。模型的原始数据来源于碱性电解水工艺模拟装置,通过Python与HYSYS 服务器建立连接,将数据传输到Python。由HYSYS 模型模拟产生的原始数据经预处理后,将数据集划分为80%训练集和20%测试集,用于后续模型训练。训练后的PCA-ANN 模型使用模型评价指标对比分析,通过不断地更新数据评估模型性能,以此更新线上预测模型。
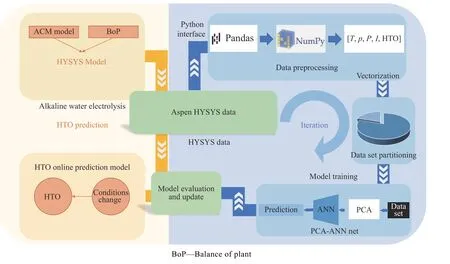
图6 PCA-ANN 模型框架Fig.6 Framework of PCA-ANN model
(1)评价指标。PCA-ANN 模型为数值类预测模型,属于回归模型,用于对连续的实数值进行预测,并且使用平均绝对误差(MAE)、均方差(MSE)、平方根误差(RMSE)、决定系数(R2)作为评价标准。
(2)模型训练。人工神经网络结构多样,增加隐藏层和神经元数量会影响网络估计数据的精度。本文通过PCA 前后训练效果和不同结构的ANN 对比分析,依据R2和MAE 值判断模型预测效果,同时结合学习曲线分析模型是否出现过拟合现象,最终筛选出用于建模预测HTO 人工神经网络的最优结构。
3.1 数据预处理
由于实际装置在运行的过程中HTO 不会超过4%,某些工作点位产生的数据会与实际数据存在差异,同时考虑到电解槽设计运行工况区间较小,而操作范围设置较广,在操作边界处可能会出现异常点和噪声数据,且当工业数据作为输入时预处理更加重要,因此需对HYSYS 生成的数据进行数据清洗处理。
(1)对于真实的输入数据,采用箱线图分析离群点数据,筛除整体HTO 分布中的异常数据(离群点数据在HTO 分布箱线图(图7)中以绿色方块表示)。
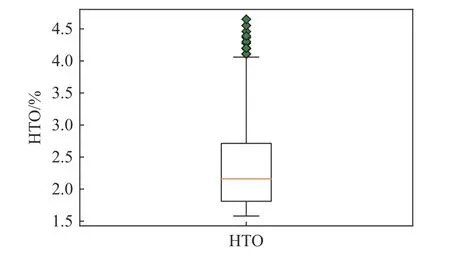
图7 HTO 分布箱线图Fig.7 Box plot of HTO distribution
(2)针对边界处的数据趋势进行分析并筛除边界异常点数据。选取边界条件p=0.1 MPa 时HTO 随温度的变化趋势进行异常点位分析,如图8 所示(图中TSTACK为装置运行温度),可以看到,当装置运行温度(TSTACK)为40 ℃时出现了HTO 异常值。采用边界条件趋势分析方法可以对边界条件数据进行数据清理。通过预处理后的数据再进入模型进行训练,能使模型具有更好的鲁棒性。
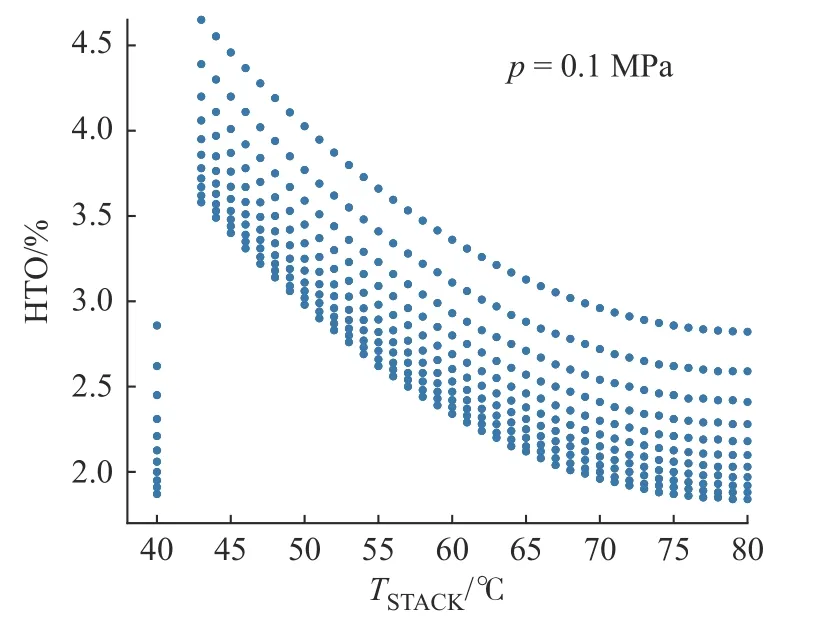
图8 HTO 随温度变化趋势Fig.8 HTO changing trend with temperature
3.2 PCA-ANN 模型输入参数选取
从HYSYS 流程中选取了12 个参数作为待输入的预选参数,主要包括:电解槽功率(PSTACK)、电解槽产热(QGEN)、电池电压(VCELL)、电解过程可逆电压(VREV)、电流密度(I)、装置运行温度(TSTACK)、循环泵功率(PRCY)、加水泵功率(PH2O)、装置运行压力(pSTACK)、氢气产量(FH2)、氧气产量(FO2)、换热器能耗(E100)。
用选取的12 个参数对HTO 进行皮尔逊相关性分析[29],分析结果如图9 所示。结果表明:(1)VREV、PH2O、QGEN对于HTO 的相关度为0,因此都可以忽略。(2)有两组变量(FH2和FO2,PRCY和TSTACK)相关性较高,存在多重共线性,为避免模型过拟合,每组中剔除一个变量。
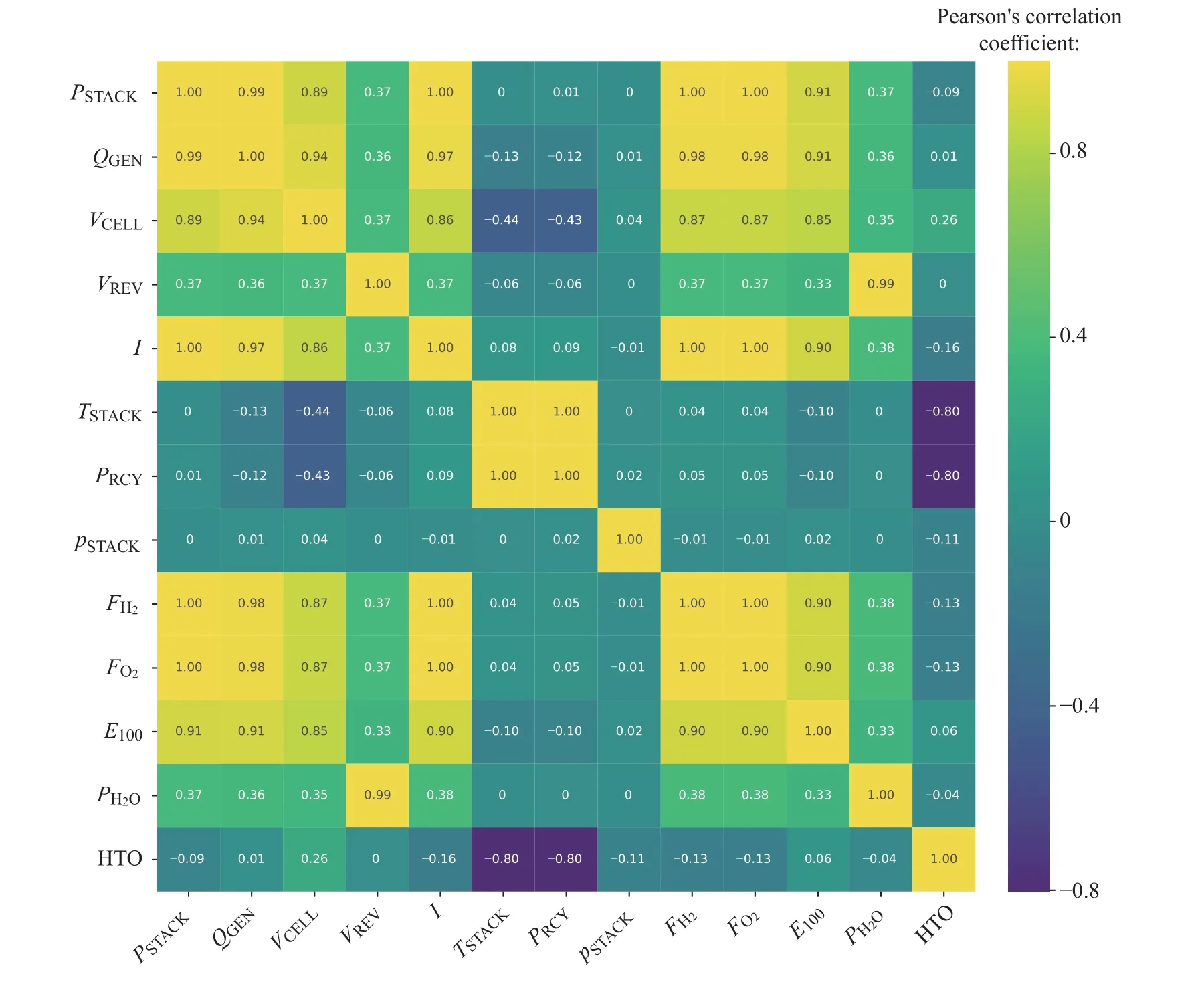
图9 变量相关度分析热力图Fig.9 Variable correlation analysis of heat map
根据相关性分析结果,最终选取装置运行温度、装置运行压力、电解槽功率、电池电压、电流密度、氢气产量、换热器能耗作为PCA-ANN 模型的输入参数。
4 实验部分
选取HYSYS 运行过程的12 870 条数据训练模型。将筛选出的变量作为输入,HTO 值作为输出。由于HTO值为连续的数值,采用Python 机器学习库Sklearn 提供的ANN 神经网络MLPRegression 进行回归训练。学习率选择为0.000 6,优化器选择SGD(随机梯度下降),正则化参数为0.001,损失函数为平方误差损失函数。
4.1 PCA 降维
首先对数据进行PCA 降维处理。原始数据为7 维的数据,采用PCA 算法进行特征累积贡献度计算,结果如图10 所示。当原始数据通过PCA将维度降低到4 维时,累积特征贡献度已经达到了99%。这表明通过PCA 将维度降到4 维已经能够最大程度保留数据特征,并减少训练参数量。
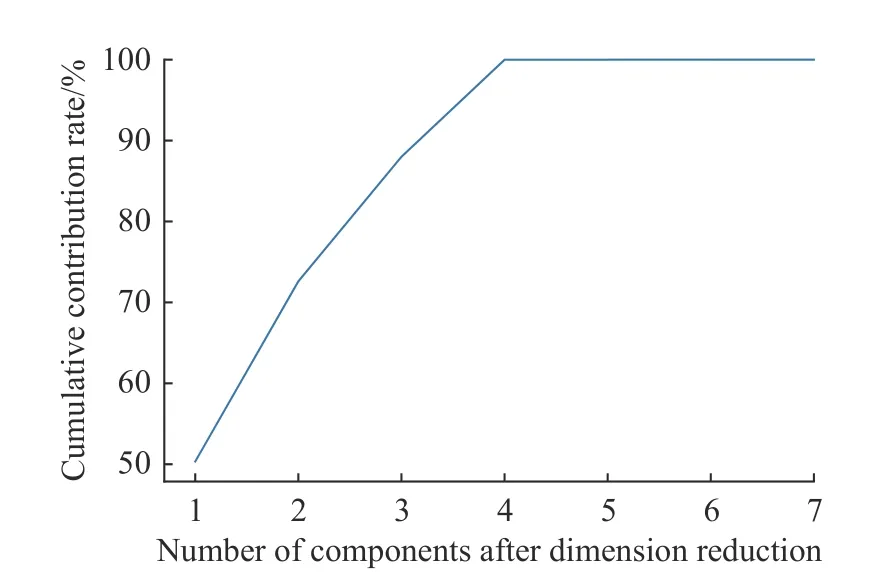
图10 PCA 特征累积贡献度曲线Fig.10 PCA feature cumulative contribution curve
对比分析了增加PCA 头部处理对神经网络性能的影响,结果如图11 所示。随机选择5 组训练数据进行对比,可以看到,增加PCA 头部后,R2有明显提升,说明PCA头部提取了有效特征,提升了模型的性能。
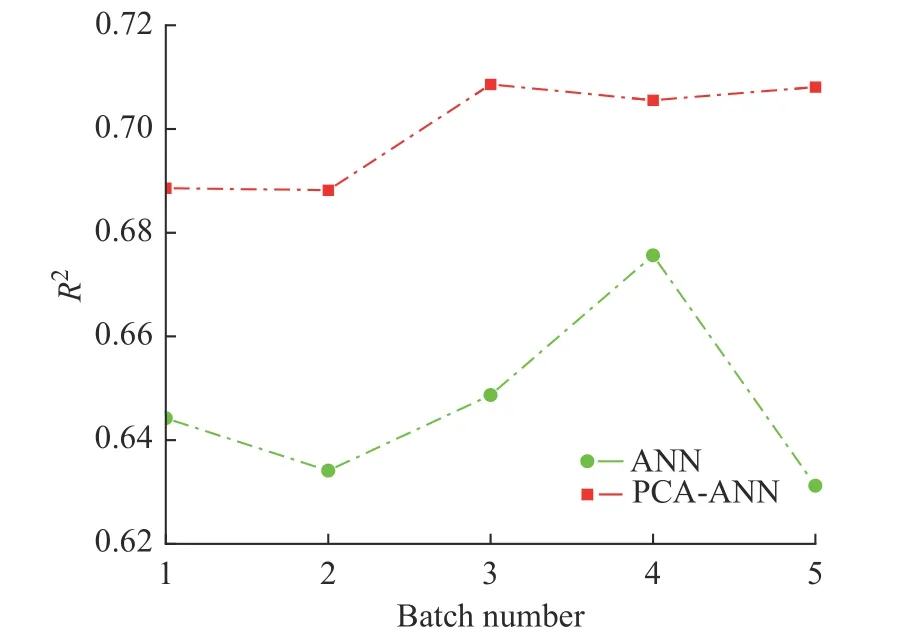
图11 PCA-ANN 与ANN 效果对比图Fig.11 Comparison of PCA-ANN and ANN effect
4.2 对比实验
首先对比分析了不同隐藏层下,不同结构PCAANN 模型的表现,其评价指标如表5 所示。
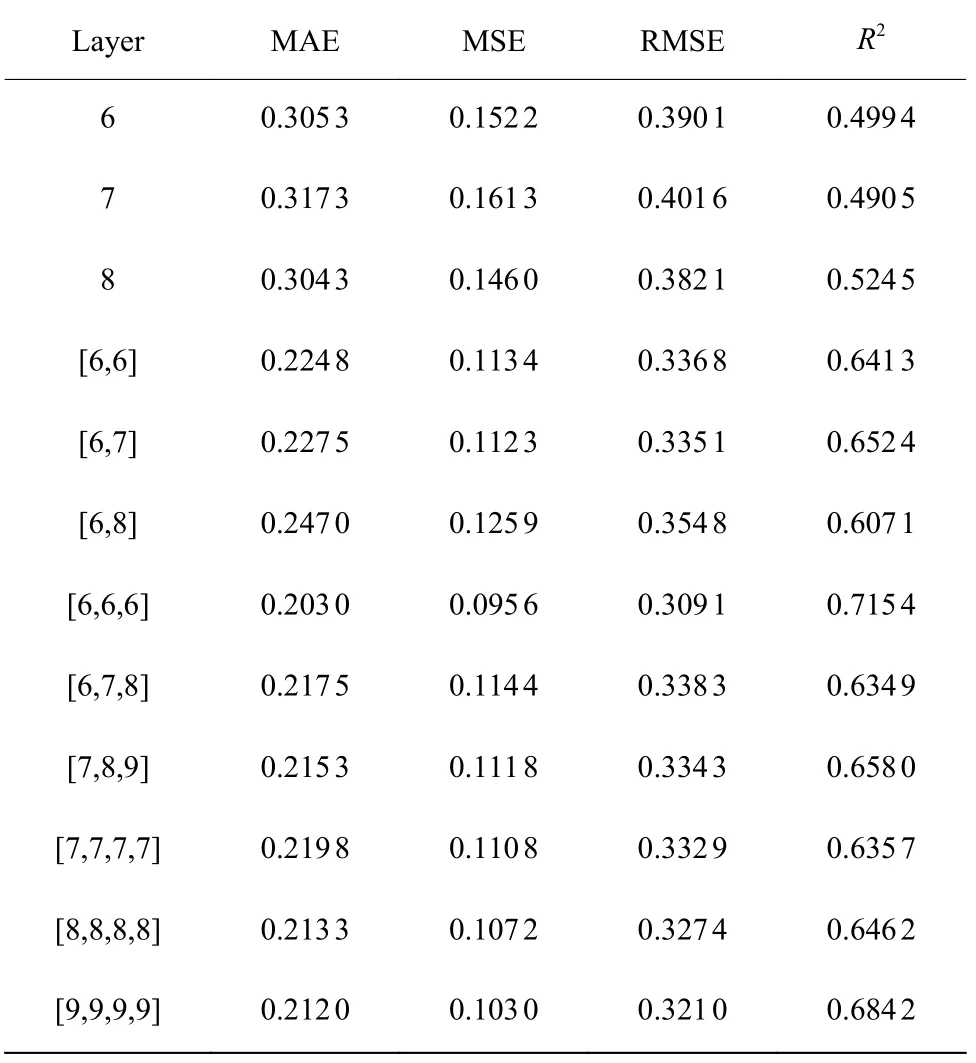
表5 不同隐藏层PCA-ANN 性能对比Table 5 PCA-ANN performance comparison of different hidden layers
对比模型深度对预测结果的影响,分别从隐藏层数为1、2、3、4 的PCA-ANN 网络中选出3 个不同网络进行实验,为防止随机性造成的影响,每个模型训练10 次取最优值。PCA-ANN 模型在只有1 层隐藏层时,R2仅为0.500 0 左右。当ANN 为2 层隐藏层时,R2明显提升,范围大约为0.600 0~0.660 0,MAE、MSE 值也有所降低。当模型深度加深为3 层时,模型的预测效果进一步提升,[6,6,6]网络的R2更接近于1.000 0。模型深度为4 层时模型整体表现依然稳定,但是与3 层模型相比,R2提升不够明显。综合以上的数据,选择参数较少且表现最好的[6,6,6]为预测模型。
4.3 损失曲线与交叉验证
模型的损失曲线与交叉验证如图12 所示。模型的损失曲线表明在样本量达到7 000,训练批次epoch 为70 轮左右时,模型已经收敛,MSE 值稳定在0.1 左右。交叉验证曲线中,训练集和交叉验证集Loss 值稳步下降,表明模型没有出现欠拟合和过拟合的情况。
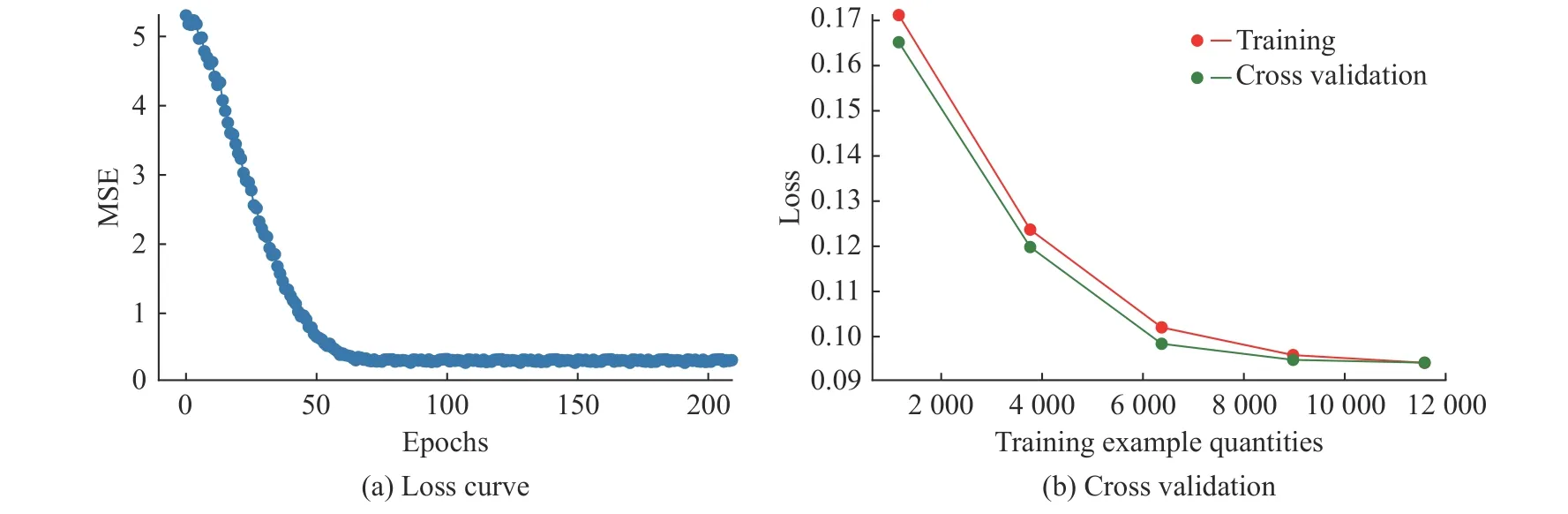
图12 模型的损失曲线与交叉验证Fig.12 Loss curve and cross validation of the model
4.4 数据预处理对PCA-ANN 的影响
当不进行数据清洗而直接预测时,随机选取了模型预测的2 574 个点与HYSYS 工艺数据进行对比,结果见图13。图中越靠近黄色直线的点表明模型的预测结果越准确。模型的预测结果表明,基于PCA-ANN 的气体纯度预测模型在大多数情况下可能会高估HTO 值,但误差不超过0.2%。这样的高估有助于避免安全问题的发生,因此使用PCA-ANN 进行预测的值是可以被采纳的。
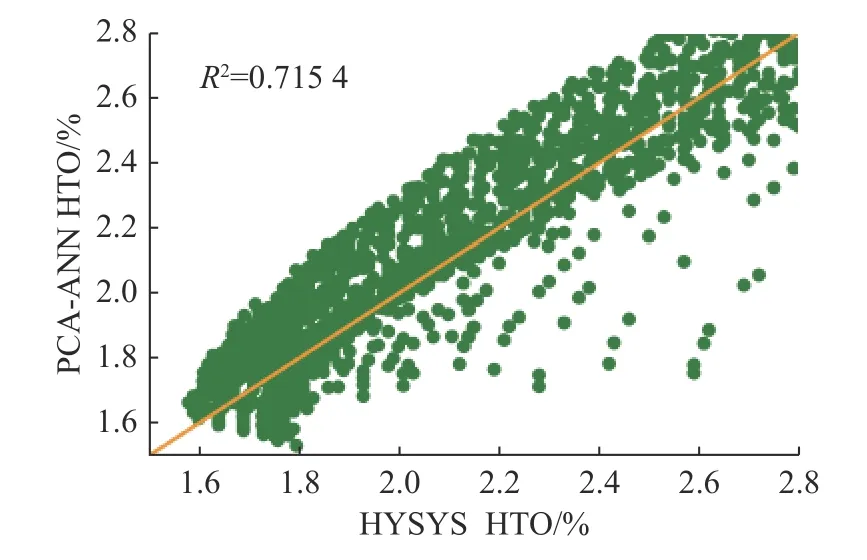
图13 HYSYS HTO 与PCA-ANN HTO 对比图Fig.13 Comparison of HYSYS HTO and PCA-ANN HTO
对边界处进行分析,在HTO 为2.2%~2.8%时,会有少数点位的HTO 值被PCA-ANN 低估,选择其中10 个预测较差点位进行分析,结果见表6。从表中可以看出,PCA-ANN 与HYSYS 模型产值误差较大时的点位均为压力等于 0.1 MPa 的边界工作点,而没有发现非边界压力条件下的异常预测点。分析结果表明,若不对HYSYS 模型在边界处产生的数据进行数据清洗,会导致PCA-ANN 在边界条件处预测效果差。筛除压力边界工作点的异常数据再次进行训练,预测结果如图14 所示,可以看出,模型的R2为0.950 7,较之前有明显提升。
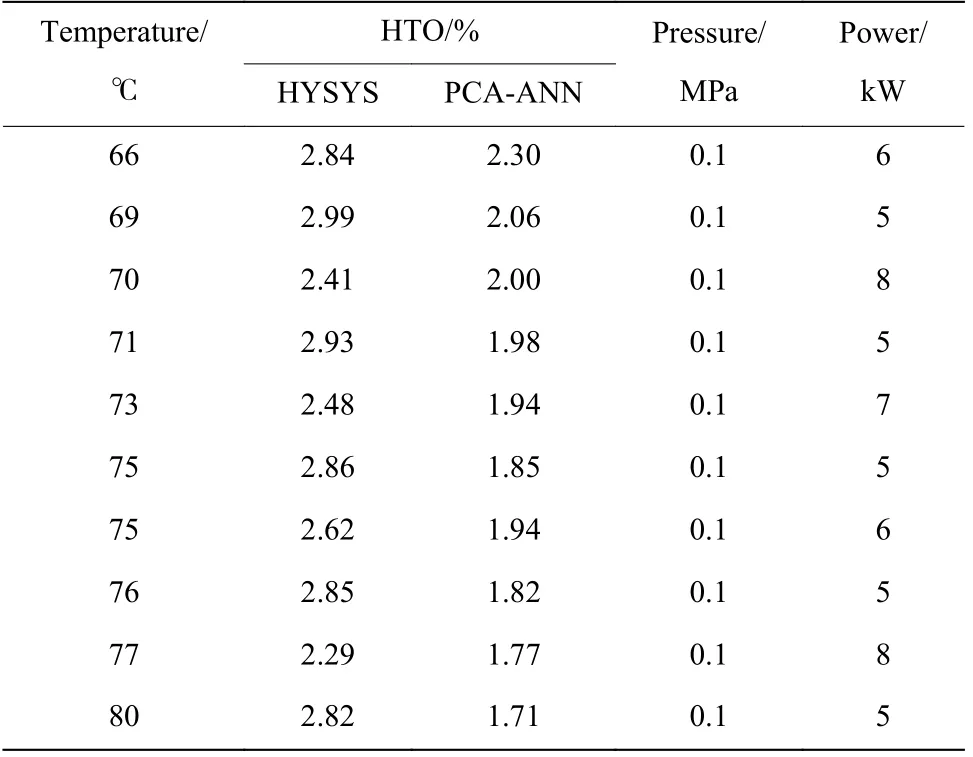
表6 预测较差点位的运行工况Table 6 Operation conditions with poor prediction effect
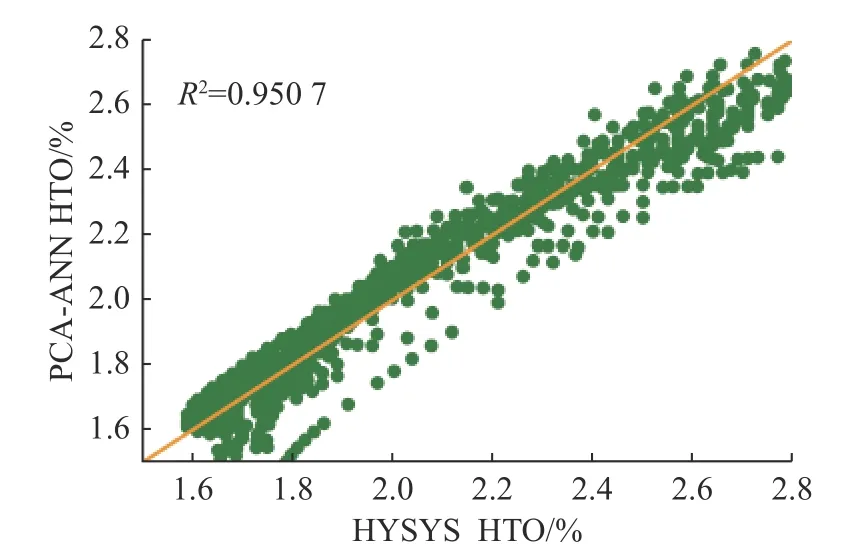
图14 数据清洗后HTO 对比图Fig.14 Comparison of HTO after data cleaning
5 结束语
通过建立基于PCA-ANN 的气体纯度预测模型,预测了碱性电解水制氢过程中的关键指标HTO,模型实验结果表明,机器学习算法对于碱性电解水系统气体纯度的预测结果比较准确,MAE、MSE 值小,因此,以机器学习模型去预测制氢过程中气体纯度是可行的。用PCA-ANN 对电解水制氢过程中HTO进行预测,若不进行数据清洗,则模型最佳决定系数R2大概介于0.490 0~0.720 0 之间,经过数据集数据预处理后能够达到0.950 7,模型表现良好。原始数据集质量决定了模型的上限。综上,对边界操作条件处的数据清洗极为重要。
原始训练数据的7 个变量与HTO 值为强相关关系,但HTO 值还受碱液循环量、分离器分离效率、操作策略等因素的影响,在本模型中没有对其他参数进行参数调整和研究。
猜你喜欢
石油石化绿色低碳(2022年2期)2023-01-06 23:16:35
长江蔬菜(2021年22期)2022-01-12 03:25:36
上海建材(2020年12期)2020-04-13 05:57:52
长江蔬菜(2018年22期)2018-12-25 12:37:22
长江蔬菜(2018年6期)2018-05-08 07:45:10
江西建材(2018年1期)2018-04-04 05:26:02
中国组织化学与细胞化学杂志(2017年1期)2017-06-15 20:27:45
浙江农业科学(2016年11期)2016-05-04 04:16:45
广州大学学报(自然科学版)(2015年4期)2015-12-23 11:50:10
电源技术(2015年2期)2015-08-22 11:27:56
