
基于子树交换的神经机器翻译数据增强方法
2023-07-06 08:55迟春诚李蔓菁李付学
鞍山师范学院学报 2023年2期
迟春诚,李蔓菁,闫 红,李付学
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.营口理工学院 电气工程学院,辽宁 营口 115014)
近年来,神经机器翻译在许多场景下已经超过统计机器翻译模型,成为机器翻译领域的主流范式.特别是文献[1]中提出的Transformer模型,摒弃了传统的基于循环神经网络和基于卷积网络的方法,是一种完全基于注意力机制的模型结构,在众多神经机器翻译模型中性能先进.该模型沿用经典的端到端架构,仅依赖双语平行数据,通过注意力机制翻译知识,整个过程无需人工参与.许多研究发现[2-5],双语数据资源制约着神经机器翻译模型的性能,即使是数据资源丰富的语言对,在特定的垂直领域双语平行资源也是稀缺的.如中英语言对中的旅游行业数据,特别是在稀缺资源语言翻译任务方面,译文的质量下降非常明显.然而,收集和整理双语平行数据是一项非常耗时且成本高昂的工作.因此,稀缺资源语言的翻译成为研究的热点问题.
数据增强是深度学习领域缓解数据稀疏的一个非常重要的技术,它通过构建额外的训练数据或为已有数据添加噪声,进而增强模型的鲁棒性.数据增强已广泛应用在计算机视觉领域,如裁剪、翻转图像和调整图像大小等.然而,在自然语言处理任务中,由于自然语言的复杂性,即使细微的变化,可能也会影响句子的语义,甚至出现语法或句法错误.因此,不能简单地将应用于计算机视觉领域的数据增强方法直接用于自然语言处理任务上.特别是在机器翻译任务中,高质量的伪双语数据集难以生成,这给数据增强带来了巨大的挑战.针对机器翻译任务,众多学者提出了一些数据增强方法,开展了相关研究工作[3-5].针对稀缺资源语言对的翻译任务,本文提出了一种基于子树交换的数据增强方法.该方法在成分句法分析的基础上,运用子树交换算法,生成新的伪单语数据,再通过反向翻译模型为伪单语数据生成目标译文,构成伪双语平行数据.通过这种方式产生的新句子结构完整,符合语法规则,且无需借助额外的资源.
1 数据增强方法
数据增强(Data Augmentation)是指在机器学习中对原始数据集进行变换、扩展等操作,以产生更多、更丰富、更具代表性的数据集的方法.数据增强最早应用在计算机视觉领域,目的是增加训练数据集的多样性和覆盖范围,提高模型的泛化能力和鲁棒性,减少模型的过拟合和提高模型的性能.数据增强在神经机器翻译领域中的应用主要包括以下三种方式:一是对原始句子进行随机变换,如交换短语、替换同义词、增加或删除单词等,以增加训练数据集的多样性;二是在原始句子中引入噪声,如加入语法错误、打乱单词顺序等;三是利用双语数据中的对齐信息,将原始的句子进行切割和组合,生成新句子对.
数据增强的作用在神经机器翻译中主要有以下三个方面:一是增加训练数据的多样性和数量.通过数据增强可以产生更多的句子对,增加训练数据的数量和多样性,从而提高模型的泛化能力和翻译质量.二是提高模型的鲁棒性.通过引入噪声和随机变换,可以使模型在面对真实世界中存在的各种语言变化时更加稳健和可靠.三是通过数据增强可以降低模型的过拟合风险.在数据增强领域内,众多神经机器翻译研究人员通过研究和探索,提出了许多有效的方法,主要包含以下几类:
一类数据增强方法是基于反向翻译,利用引入单语数据来扩充机器翻译模型的训练数据集.对于使用源语言端单语数据,文献[4]提出了一种自学习方法,将源语言端单语数据翻译成目标语言以扩充训练集,提升模型性能.对于使用目标端单语数据,文献[6]提出了一种反向翻译的数据增强方法,该方法将目标端单语数据翻译成对应的源语言端句子以扩充训练集;文献[7]使用来自源语言端和目标语言端的单语数据进一步扩展了反向翻译方法.
另一类数据增强方法是基于词替换.文献[8-9]提出了在低资源语言中使用同义词替换作为数据增强的手段.文献[10]提出将源语言句子和目标端句子中的词替换为词汇表中的其他词.文献[11]提出了两种向句子中添加噪声的方法:一是用占位符随机替换句子中的单词,二是用词汇表中具有相似频率分布的其他词替换句子中的词.文献[12]提出随机交换句子中距离相近的词.文献[13]提出的上下文增强可以看作是一种新的方法,它通过利用语言模型将一些词替换为另一个词,虽然这种方法可以保持基于上下文信息的语义,但这种增强仍然有局限性,即需生成具有足够变化的新样本,需要多次采样.鉴于语言的词汇量通常很大,几乎不可能利用所有可能的候选词来取得好的表现.此外,由于序列的微小修改会导致其语义发生极端变化,因此,为神经机器翻译等一些艰巨的自然语言处理任务寻求简单的对应关系是一项艰巨的任务.文献[14]提出在句子中随机丢弃一些词,以通过编码器帮助神经机器翻译训练.文献[15]通过将目标端句子中的词与稀有词替换并修改源语言句子中所对应的词来改进神经机器翻译的训练样本.文献[16]提出了一种利用双向语言模型来替换词的数据增强方法.低资源数据的局限性使上述两类数据增强方法难以得到预期的效果.与上述方法相比,本文提出的数据增强方法与词交换的思想相似,可以通过设置子树根节点的成分属性值,进而在原有的基础上产生更多的样本数据.
2 神经机器翻译
2.1 神经机器翻译方法
自2013年起,神经机器翻译模型采用一种新型的端到端的架构,由编码器-解码器两部分组成.编码器-解码器分别由多层循环神经网络(Recurrent Neural Network)堆叠构成.长短期记忆网络(Long Short-term Memory Network)和门机制(Gate Mechanism)是循环神经网络的两个优秀变体,与传统的循环神经网络相比,这两种变体解决了多层循环神经网络梯度爆炸(消失)和长文本依赖问题.
编码器将输入的文本信息压缩成向量表示并传递给解码器,解码器通过向量生成对应的目标端文本信息.然而,不管输入的文本长度是多少,编码器都要将其压缩成一个固定长度的向量,这会给解码过程带来更大的复杂性和不确定性,尤其是输入为长文本时.为解决这一问题,神经机器翻译模型引入了注意力机制(Attention Mechanism),当解码器生成当前时刻句子中的词时,可以基于注意力机制将其动态成一个加权文本向量(Context Vector),进而通过此文本向量预测相应的词,显著提升了神经机器翻译模型的翻译性能.
2.2 Transformer模型
对循环神经网络相关的神经机器翻译方法而言,其模型对句子中的词只能逐词处理,训练速度较慢;而Transformer模型却可以将句子作为整体处理,加快了训练进程,提高了训练处理效率.Transformer模型架构图如图1所示.该模型仅仅通过注意力机制[17]和前馈神经网络便拥有强大的特征表示能力,并且通过注意力机制巧妙地解决了机器翻译中长距离依赖问题.因此,该模型非常适合处理语言文字序列这类任务.Transformer模型通过堆叠多个相同的网络结构,分别组成了编码器和解码器.

图1 Transformer模型架构图
自注意力(Self-Attention)机制是Transformer模型的重要组成部分,也是传统注意力机制的一种变体.自注意力机制相比于传统的注意力机制,减少了对外部信息的依赖,专注于捕获自身内部相关性,进而能够更精准地捕获词之间的句法特征或语义特征.在自注意力机制中,查询(Query,Q)、键(Key,K)和值(Value,V)均来自同一向量.计算自注意力要先对三个矩阵分别进行线性变换,然后进行缩放点积操作,公式为
(1)
多头注意力机制则采用h个注意力头表示输入信息,将多头注意力的输出拼接乘以权重矩阵得到向量输出,公式为
(2)
其中,
这里h代表多头注意力机制中头的个数.
编码器中每个相同堆叠结构都包含一个自注意力子层和一个前馈神经网络子层.为了能够更好地优化深层网络结构,Transformer模型在每个子层使用了层正则化和残差连接,公式为
LayerNorm(x+Sublayer(x))
(3)
相比于编码器,解码器同样堆叠了多个相同的网络结构.除了编码器中的两个子层,解码器还额外包含一个子层,一般称为编码器-解码器注意力子层.编码器-解码器注意力子层对编码器的输出向量再执行一次注意力加权操作,用于捕获当前翻译和编码的特征向量之间的联系.编码器提取源语言句子中的信息,进行多层的信息提取,最后顶层的输出便是编码端的特征表示.解码器和编码器类似,在每个子层后都包含层正则化和残差连接操作.此外,解码器的自注意力子层需要屏蔽未来的序列,因此一般称为带掩码的自注意力子层.
所谓掩码,是指自注意力加权计算过程中,在进行缩放点积操作之后,将表示未来位置部分的权重设置为-∞,这样在经过softmax函数归一化之后,未来位置的概率无限趋近于0.这样做的意义在于,遮挡部分序列的内容,使得解码器在解码的过程中,只能依赖当前的预测结果进行下一步预测.如果使用普通的自注意力机制,模型可以看到完整序列,也就是可以看到自己的预测结果,这样会导致训练解码不一致问题.因此,带掩码的自注意力层的引入有效解决了这个问题,同时,通过掩码操作,在训练期间模型也无法获得将来的信息,从而和解码阶段相匹配.
3 子树交换数据增强方法
基于子树交换的数据增强方法在原始数据集的基础上,无需引入额外的资源,通过子树交换算法生成新的伪双语句对,提升训练数据的多样性,增强模型的泛化能力和鲁棒性,降低过拟合的风险并提升翻译质量.该方法包含两个步骤:第一,通过子树交换算法产生新的目标端单语句子;第二,利用反向翻译方法翻译目标端句子生成伪双语句对.
3.1 子树交换算法
句法分析是自然语言处理中的基础性工作,句法树可以清晰描述句子的层次结构和词之间的相互关系.子树交换算法依赖于成分句法分析,该算法具体步骤如下:
(1)使用Stanford CoreNLP[18]在目标语言端构建成分句法树,遍历句法树,记录第一个叶子节点所在的层,将其标记为d,记录最深层叶子节点的深度为n.
(2)将d层中所有节点(叶子节点和非叶子节点)加入子树交换候选节点集合S,并且设置要交换子树的根结点成分属性NP.
(3)对遍历子树交换候选节点集合S的每个节点进行筛选和扩展,规则如下:
a)若集合S中存在两个成分属性为NP的节点,则交换这两个以NP为根节点的子树.
b)若集合S中存在两个以上成分属性为NP的节点,则交换前两个以NP为根节点的子树.
c)若集合S中不存在相同的成分属性为NP的节点,则清空集合S,将d+1层中所有节点加入集合S,重复步骤(3).
d)若子树成功交换一次,则算法终止;若当前层为(n-1)层且不存在符合交换的子树,则算法终止.
(4)子树交换后生成新的成分句法树,自左至右依次将叶子节点组合得到新句子.成分句法树样例如图2所示.
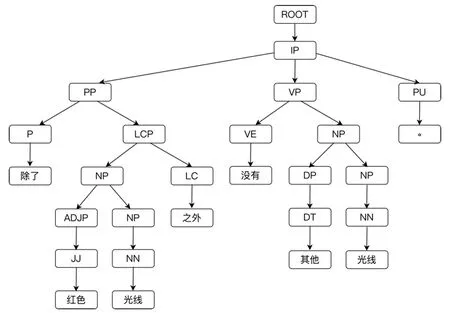
图2 成分句法树样例图
3.2 伪双语数据
使用子树交换算法生成单语数据后,需要生成其对应的译文.为了构造双语平行数据,使用原始的双语数据训练一个反向机器翻译模型,将生成的单语数据翻译,构成双语平行的句子,生成伪双语数据图,如图3所示.原始训练集和新生成的伪双语数据混合,能得到数据增强后的训练集.

图3 生成伪双语数据图
4 实验结果与分析
4.1 数据预处理与模型设置
4.1.1 数据预处理 为了验证本文方法的有效性,采用公开标准的IWSLT14和WMT18数据集进行实验.为了便于与已有的数据增强方法进行公平对比,将IWSLT14希伯来语-英语(He-En)和德语-英语(De-En)两个翻译任务的数据设置与文献[19]相同.在IWSLT14意大利语-英语(It-En)翻译任务中使用dev2014作为验证集,tst2014作为测试集,bpe编码合并次数限制在10 K.WMT18土耳其-英语(Tr-En)翻译任务的数据设置与文献[20]相同.需要注意的是,部分句子不满足子树交换算法的条件,各个训练集子树交换成功的句子数量如表1所示.

表1 目标语言端子树交换统计
4.1.2 模型设置 IWSLT14德语-英语采用标准的Transformer模型,其编码器和解码器两端堆叠层数为6,每一层8个注意力头,输入词向量维度设置为512,前馈全连接网络的输出维度为2 048.其他翻译任务则采用Transformer_small模型,其编码器和解码器两端堆叠层数为6,每一层4个注意力头,输入词向量维度设置为512,前馈全连接网络的输出维度为1 024.所有实验均采用Adam优化器进行模型优化[21],dropout设置为0.3,其他参数保持默认设置.在译文质量评价方面,我们使用译文测评工具BLEU对翻译任务进行评测[22],为保证结果的有效性,将波束搜索大小设为5.
4.2 实验与分析
4.2.1 多任务翻译性能 使用基于子树交换的数据增强方法生成伪双语数据后,与原始训练集混合,在IWSLT14德语-英语、希伯来语-英语、意大利语-英语和WMT18土耳其语-英语四个翻译任务上验证系统性能.实验数据如表2所示.从实验数据可以看出,本文的方法在所有翻译任务上均有提升,特别是在希伯来语-英语任务上BLEU得分提高了0.78,展现出良好的性能.

表2 多任务翻译性能
4.2.2 与其他数据增强方法对比 为了进一步展示本文提出的数据增强方法的有效性,使用该方法与其他现有的数据增强方法进行对比,结果如表3所示.为了公平比较实验结果,本文实验数据集的设置与数据来源(文献[19])保持一致.从IWSLT14 希伯来语-英语(He-En)的翻译任务可以看出,除了Smooth方法和SCA方法取得了较好的性能外,本文提出的方法优于其他方法,可以证明本文方法的鲁棒性.
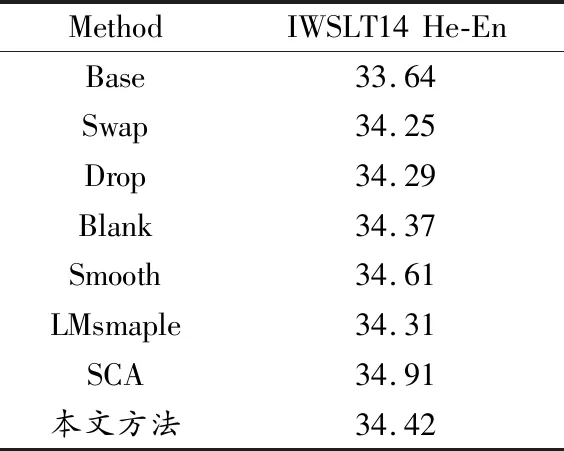
表3 与其他数据增强方法比较
4.2.3 源语言端子树交换 本文提出的方法是将子树交换算法应用于目标语言生成伪单语数据.为进一步验证方法的稳定性,本节将子树交换算法应用于源语言端,生成源语言的伪单语数据,需要首先训练源语言-目标语言的正向翻译模型,最终生成伪双语数据.本文使用WMT18英语-土耳其语(En-Tr)的翻译任务进行实验,实验结果如表4所示.从表4可以看出,使用子树交换算法作用于源语言端生成伪双语数据后,模型的性能依然明显提升(BLEU得分提高了0.4),从而进一步证实了本文提出的数据增强方法的有效性.
5 结论

表4 源语言端子树交换翻译性能
本文提出一种稀缺资源神经机器翻译数据增强方法,使用子树交换算法生成单语句子,再通过翻译模型生成对应的英文,构建伪双语数据.通过多个稀缺资源语言对翻译任务的实验结果看出,相对于基线系统,该方法显著提升了模型的翻译性能.在未来的工作中,可以将该方法应用于其他文本生成类的任务中,或继续探索基于句法分析的数据增强方法.
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
小学生必读(低年级版)(2021年10期)2022-01-18
曲阜师范大学学报(自然科学版)(2021年4期)2021-10-25
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
计算机与数字工程(2019年12期)2019-12-27
家庭影院技术(2019年8期)2019-12-04
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
计算机应用(2017年9期)2017-11-15
