
基于深度学习的人脸图像加密算法研究
2023-07-06 12:42辛君芳
计算机测量与控制 2023年6期
鲁 瑞,张 南,辛君芳
(1.澳大利亚国立大学 计算机与工程学院,堪培拉 2600;2.北京工商大学 计算机学院,北京 100048)
0 引言
随着大数据与人工智能时代的悄然到来,人们可以轻松地利用社交平台分享自己的生活。据中国互联网络信息中心发布的《中国互联网络发展状况统计报告》显示,截至2022年6月,我国网民规模为10.51亿,互联网普及率达74.4%。据文献资料统计,约95%左右的网民会将自己的上网时间分配给社交平台[1]。图片作为信息的重要载体,与通过文字表达信息相比更加直观、形象和生动,人们将图片上传到社交平台的现象非十分普遍。但是,这在给人们的生活增加趣味的同时,也带来了隐私信息泄露等安全风险。因此,对图像中关键信息,特别是人脸等隐私部位进行选择性加密非常必要。当前,人们一般通过手动加密或打马赛克的方式对网络上发布的图片区域进行加密,此方法不仅需要花费时间和精力,还很容易被破解。
随着隐私问题越来越被人们重视,图像加密问题受到学术界的广泛关注。通过研究发现,传统密码学对图像数据加密的加密方法在信息量大,像素之间相关性强的图像中效果不好。而基于混沌系统的加密算法具有初值敏感性、不可预测性等特点,使其可以更好地与密码学相适应,在此基础上,其易于实现,因此其被学者们应用于图像加密领域。混沌系统主要包括Logistic映射、Henon 映射以及Chen混沌系统[2]。其中,Logistic混沌系统源于人口统计动力学系统,是加密系统中的常用系统。当Loginstic函数的初值与参数满足条件时,Logistic函数工作于无法预测且无序的混沌状态,可以生成混沌矩阵对原图矩阵进行处理,达到加密目的。Logistic系统比传统图像加密方法更安全,在图像加密领域具有很好的发展前景[3-5]。因此,本文采用Logistic混沌系统进行图像的加密。
值得注意的是,图像加密大多是对整幅图进行加密,但是在军事和医疗等方面的应用中,并不强制加密整个图像。比如,在包含罪犯的图片中只需要将图片中的人脸进行加密,因此针对图像的特定目标部分加密的研究十分重要,有学者指出可以先提取包含主要信息的目标区域,在此基础上对图像的目标区域进行加密工作,从而实现针对目标区域的图像加密[6]。对于图像解密部分,有文献表明,解密结果可以与原始图像有些许差别,因为人类本身对图像具有感知特性,只要图像内容不受影响,解密结果在一定的范围内出现小的失真现象是被允许的,为了实现针对人脸区域的图像选择性加密,需要对人脸进行准确地定位[7]。目前采用的人脸定位方法主要包括基于知识、基于特征与基于表象三类传统人脸定位技术和基于深度学习的人脸定位技术[8-10]。陈小梅[11]等人先对人脸图像进行识别,然后对其进行预处理去除噪音,最后通过灰度投影获得主要特征点为人脸进行定位。有文献指出采用和迭代过程识别图像中可能存在的人脸轮廓区域,之后利用Snake算法对可能存在的人脸区域进行精炼细化,以获得最终的目标结果[12]。
深度学习凭借其高准确率、高效率的特性被广泛应用于计算机视觉等各个领域。其中,级联卷积神经网络等网络结构在人脸检测问题上被深入研究与应用,并取得了不错的效果。文献[13]提出级联的CNN 网络结构进行人脸识别,为了更精准地定位人脸区域此方法设计了一种边界校订网络,并可以进行多分辨率解析,因此成为当时识别效果和速度最好的算法。文献[14]依照实验级联CNN 模型,提出了MTCNN 模型,此模型级联的多任务框架,对人脸检测和关键点对其两个认为进行级联。并对三个卷积神经网络P-Net、R-Net、O-Net进行串行,从而可以精确的预测人脸的位置坐标和面部特征点坐标。目前,有不少学者提出了通过haar级联和神经网络混合的方法构造分类器对人脸区域进行识别[15]。也有一些学者提出不使用级联结构进行人脸检测的深度学习算法。其中,文献[16]采用单个基于深度学习的卷积神经网络模型对多方位的人脸进行检测,该方法使得输入图像的大小不受限制,跟类能力较强,而且不需要对面部姿势等内容进行注释。
通过对上述模型方法的研究,本文研究了一种通过深度学习算法自动检测人脸的关键区域,并对其进行定位和选择性加密的方法。此方法可以有效保护人们的肖像等隐私安全,使得人们可以更放心、安全、自由地享受互联网带来的便捷与快乐。
1 深度学习及图像加密方法介绍
1.1 MTCNN算法
2016年,中国科学院深圳研究院提出了用于人脸检测的多任务卷积神经网络(MTCNN,multi-task convolutional neural network)深度学习模型,它是一个多任务人脸检测算法[14],可以同时进行人脸检测、人脸区域定位和人脸特征点标注三个任务。MTCNN 是一个进行多次单目标检测的多目标检测网络模型,它级联了3层卷积神经网络PNe、R-Net、O-Net[17-18],模型通过上述三层卷积神经网络对人脸图像逐步精化,以得到最终的人脸框坐标和关键的人脸特征点(眼睛、鼻子以及两个嘴角)的坐标。本文试图先得到人脸区域的坐标以方便下一步的加密过程实现,而不需要得到人脸的特征点的坐标。因此,本文的具体实现过程,主要针对网络的人脸检测和人脸定位两个任务进行训练和测试。
1.1.1 MTCNN 算法实现过程
将输入图片分割为不同尺寸的图像,将其构造为形如金字塔的结构,称为图像金字塔。将图像金字塔输入P-Net以获取含有人脸的候选框,通过NMS对候选框进行过滤,去除冗余的候选框得到最终的人脸候选框。然后将所有包含人脸的候选框输入到R-Net中,通过更为严格的脸部特征点标准,对候选框进行进一步细化,去掉错误判断,通过Bounding-Box Regression和NMS对结果进行优化,获得置信度高的人脸候选框。最后,上一步结果输入O-Net中,定位最终人脸候选框坐标以及确定5个特征点的位置坐标。MTCNN 算法的工作流图如图1所示。在本文中,由于没有运用MTCNN 算法人脸对齐的任务,所以不会做地标标注。
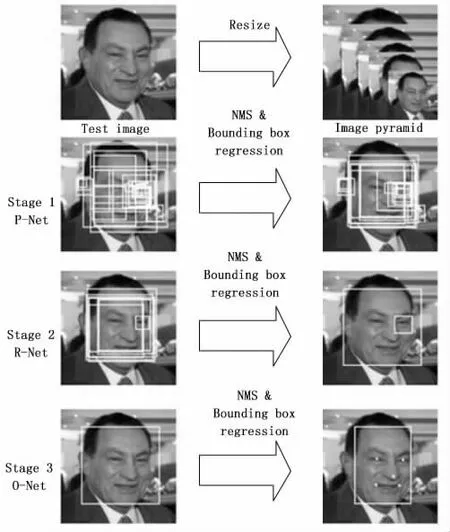
图1 MTCNN算法的工作流图[14]
1.1.2 MTCNN 算法的网络结构
P-Net全称为Proposal Network,是一个包含3个卷积层的卷积网络,他的主要作用就是判断图像中是否包含人脸,并输出人脸候选框和关键点的位置坐标。如图2所示,首先,P-Net对输入图像进行卷积操作的卷积核是一个大小为3*3,步长为1的卷积核,在此基础上,对其进行最大池化,其中进行范围为2*2,步长为2,从而可以得到一个大小为5*5,通道数为10的特征图。之后,将上一步得到的特征图继续与一个大小为3*3,步长为1的卷积核进行卷积,得到大小为3*3,通道数为16的特征图,之后将其再进行上述卷积操作得到一个特征图。最后,将上一步得到的1*1*32的特征图继续进行卷积操作生成最终的特征图并将其用于人脸分类预测、人脸边界框预测与人脸地标预测。
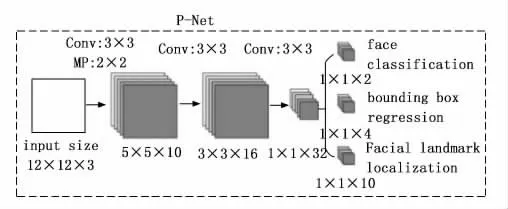
图2 P-Net的网络结构图[14]
R-Net也就是Refine Network,是一个卷积神经网络,其在P-Net的基础上增加了一个全连接层,对上个阶段的输出进行进一步细化。如图3所示,它与P-Net相比参数不同,而且R-Net增加了全连接操作。全连接层允许更精细的处理,消除大量错误的候选区域。R-Net有规定的输入大小限制,为24*24,它可以在图像经过P-Net产生候选框后对其进行筛选、排除,得到更加精确的人脸区域。
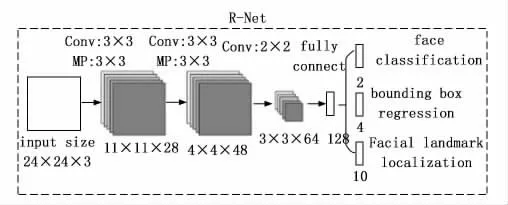
图3 R-Net的网络结构图[14]
O-Net全称Output Network,如图4 所示,它也是一个卷积神经网络而且比R-Net更复杂,它又比R-Net多一个卷积层。O-Net的输入大小为48*48,它可以对经过RNet人脸区域进一步过滤,得到最终的输出结果。

图4 O-Net的网络结构图[14]
通过对上述三个卷积网络的了解可以看到MTCNN 级联的三个网络的结构都比较简单,训练起来比较容易,通过对这三个网络逐步精化,了以得到较为准确的检测结果。因此,MTCNN 在检测速度和检测率上表现都比较好。
MTCNN 算法模型包括交并比和非极大值抑制两种工具,用其判断候选区域和加块区域识别速度。交并比实际表示两个识别框之间交集和并集的比值,它用于表示两个识别框之间的相似程度。除此之外,在生成训练数据时,交并比可以判断样本属于正样本、负样本还是部分样本,或者在非极大值抑制过滤候选框时,判断去除与其余候选框相似度高的候选区域。非极大值抑制用于抑制不是极大值的元素,并搜索此区域内的极大值。非极大值抑制以得到的候选框的置信度(为人脸区域的概率)为标准进行排序。检测每个网络时,可以通过非极大值抑制去掉置信度较低且与其他候选框区域交并比较大的候选框区域。通过非极大值抑制对候选框进行筛选,可以将效果较好的人脸候选区域进行筛选,从而减少下一个网络中输入的候选框数目,以此来提高 人脸区域的检测速度。
1.2 Logistic图像混沌置乱加密算法
混沌是指确定性动力学系统表现出的看似随机、却无法预测的运动[19]。混沌系统凭借其初值敏感性、随机性等良好的混沌特性,可以很好地提高图像加密的效果。Logistic系统是一种经典的混沌系统,在图像加密领域得到广泛应用。Logistic映射的系统方程如式(5)所示:
式中,Xn为迭代结果,X0为初值,Xn∈(0,1);U为参数,U∈(0,4]。当X0∈(0,1),当U∈(3.569,4]时,Logistic映射工作处于混沌状态。如图5所示,当参数满足设定的条件时,对初值进行迭代获得的序列是没有周期性的,即使参数发生微小改变,迭代的结果也会发生巨大变化。
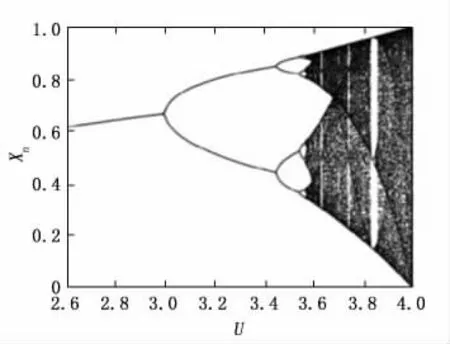
图5 Logistic映射迭代图[20]
将参数U设定在指定区间,使Logisic函数工作于混沌状态,对其进行若干次迭代,便可获得一组混沌序列。在计算机中图像通过矩阵形式进行存储与处理,因此可以将图像的矩阵表达形式与生成的混沌序列进行运算对图像进行加密,由于图像像素值处于0~255之间而生成混沌序列值位于0~1之间,因此对混沌序列按照0~255的范围进行归一化处理从而得到新的混沌序列。在此之后,将新序列转化为二维矩阵,与原图进行异或操作,得到加密后的图像,以上便是图像的Logistic混沌置乱加密流程,设定的参数U和初值X0即为秘钥。
2 FIIE算法
本文提出了FIIE 算法模型对人脸图像进行识别和加密,该模型首先对输入数据进行分类,识别出目标图片是否包含人脸以及识别出的区域是否是人脸区域,然后对人脸所在区域进行预测,识别出人脸预测框并计算其与真实数据之间的偏移量,以确定人脸边界框的最终范围,最后,通过Logistic加密算法对上述结果进行加密,完成目标图片的最终加密结果。FIIE(face image information encryption)算法实现过程如图6所示。
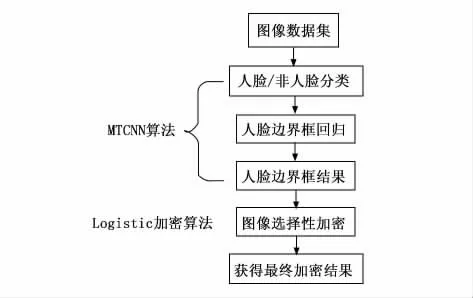
图6 FIIE算法结构图
FIIE算法融合了MTCNN 网络模型的重要部分及Logistic加密算法思想,运用人脸/非人脸分类、人脸边界框回归、人脸边界框检测结果可确定识别人脸标记框,再通过图像选择性加密算法实现对标记框中的人脸进行准确、安全加密。
2.1 增强人脸边界精确表示
MTCNN 网络模型可以进行人脸/非人脸分类、人脸边界框回归和人脸关键点定位三个任务的训练,本文则提出采用增强人脸边界精确表示算法,只需对人脸进行识别并通过边界框标记,无需对人脸关键点进行标记,因此本文只加强了前两个任务的训练。
2.1.1 人脸/非人脸分类任务
该任务的学习目标是一个二分类问题,以此来解决人脸和非人脸区域的问题,此问题用交叉熵损失函数:
式(1)中,pi为网络模型输出候选样本是人脸的概率;表示样本的真实标签,其取值为0或1。
2.1.2 人脸边界框回归任务
MTCNN 网络将其视为一个回归问题,将上面人脸非人脸区域的分类结果进行标出,得到一个人脸候选框,此问题采用均方误差损失函数:
2.1.3 多任务训练
综合上述两个任务的损失函数为:
式(3)中,N为训练样本数目;αj为权重值,表示每个任务的重要性,其中,分类任务的权重αdet为1,边界框回归任务的权重αbox为0.5;为上述的损失函数;为样本类型,其值为0或1。
2.2 Logistic混沌加密算法
现有对图像加密的研究主要是使用Logistic混沌加密算法对整幅图进行加密,本文为了达到对区域进行选择性加密的目的,对此算法进行了改进,在图像不失真的情况下大大增强图像加密的安全性。不同于传统算法中将由混沌序列生成的图像二维矩阵与需要加密的图像进行异或操作从而得到加密图像,本文先利用前一步骤得到的人脸区域坐标生成所需掩码,通过掩码过滤掉图像中与人脸不相关的区域,使其不参与运算,从而减少运算成本,之后将其与混沌序列生成的二维矩阵以及需要加密的图像进行异或操作,完成对图像的人脸区域进行加密的任务。具体操作过程如图7所示。
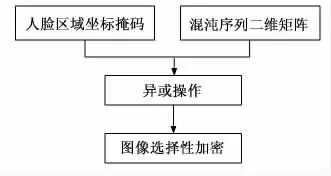
图7 Logistic加密过程图
3 实验
3.1 数据集准备及数据预处理
本文使用了WIDER FACE 数据集在对MTCNN 模型进行训练。WIDER FACE数据集包含32 203张图片,一共包含了393 703个人脸数据,如图8所示,根据这些图片场景的不同,改数据集又分为了Parade、Handshaking、Rescue、Ceremony等61个类,并将每个类别以4:1:5的比例划分为训练集、验证集和测试集。在实验中,本文从训练集中随机选取了中的3 069张图片对模型进行训练。
图8 WLDERFACE数据集
官网中的关于图像标注的文件有MATLAB存储格式和文本格式两种,本文主要采用文本格式的标注文件。如图9所示,在图像标注文件中,第一行代表每个图片的名称,第二行表示此图片中标注的人脸个数,接下来的每一行依次表示图片中标注的边界框的左上角点x、y坐标、边界框的宽、高、人脸的模糊程度、做出表情的程度等10个详细信息。本文主要利用与人脸边界框位置相关的4个信息。

图9 标注文件格式
为了简便后续实验操作,本文对原始的标注文件内容进行了修改,如图10所示,修改后的标注文件一行代表一张图片,每张图片的信息以图片为首,除此之外的其他数据每四个为一组来表示此图片中所有标注过人脸的边界框的左上角点以及右下角的点x、y坐标。修改后的标注文件就可以直接用于MTCNN 模型进行训练。

图10 修改后的数据集标注文件格式
3.2 训练数据准备
在对MTCNN 网络模型进行训练时,需要分阶段依次对P-Net、R-Net和O-Net网络进行数据准备。
在准备P-Net的数据时,需要对训练集的图片进行截取,将截取的正方形区域与标注文件中的人脸边界框进行IOU 的计算,根据得到的结果对截取的区域进行分类。当IOU 小于0.3时,则表明此区域没有人脸的图像,将其分类到负样本中;如果IOU 大于等于0.4但小于0.65,则表明此区域含有局部人脸图像,属于部分样本;如果IOU 大于等于0.65,表明此区域含有一张完整人脸,分类为正样本。在训练P-Net时,其输入都是12*12*3的图像,所以要将这些样本调整大小为12*12,之后分别保存到如图11所示的negative、part、positive文件夹下。

图11 P-Net训练数据的目录
通过上述操作可以得到本实验的训练样本,在此之后制作这些样本的标注文件。如图12~14所示,用代码0表示负样本的标签样本类型;用代码1 表示正样本的标签样本类型,其中正样本标签中包含图片对于真实人脸边界框的偏移量,偏移量是通过真实框左上角点和右下角点的坐标值与建议框对应的坐标值相减并除以建议框的尺寸所得到的;部分样本的标签用类型代码-1 表示,其也包含它对于真实人脸边界框的偏移量。将这三个标注文件完成后,将其整合到一个文本文件中,便于后续训练网络使用。

图12 负样本的标注文件

图13 部分样本的标注文件
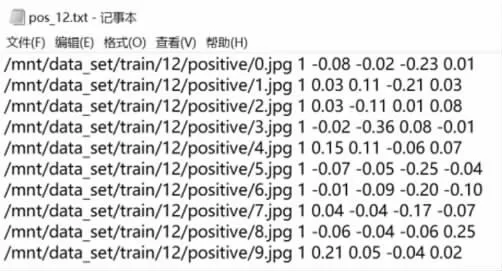
图14 正样本的标注文件
正样本和负样本用来训练人脸分类任务,正样本和部分样本用于训练人脸边框回归任务。
R-Net的训练样本需要用P-Net训练好的网络来生成,并将生成的样本调整大小为24*24。生成样本之后,对样本的分类方法和标注文件的格式与P-Net都相同。同理,O-Net的训练样本需要R-Net训练好的模型来生成,此部分大小需调整为48*48。
将网络训练好之后,对训练好的网络进行测试,测试结果如图15所示。
通过实验发现,即使实验图片中包含较多的人脸数目时,MTCNN 算法也能有效地检测并定位人脸位置,并且该算法可以识别拥有较多人脸信息的侧脸。不过,对于一些面部大量被遮挡的图片信息以及与人脸十分相似的图片信息,MTCNN 网络模型在检测过程中也会出现检测不出或者过度检测的情况。但是,对于大多数的图片结果,此算法模型还是可以输出较好的检测和定位结果。
通过对Logistic加密算法的创新,得到如图16所示的加密结果。
由图16可以看出本文使用的加密方法对加密图片中部分区域有比较不错的实现效果,由此可见,通过创新后的Logistic混沌置乱加密可以解决保护图像中面部区域隐私问题。
4 结束语
本文研究了一种针对图像的面部区域进行选择性解密的算法模型,实现对图片中的人脸隐私部位的有效保护。该方法融合了人脸检测算法、人脸对齐方法及图像加密算法,对图像中的人脸信息进行加密保护。通过对WLDER FACE数据集的标注数据进行修改,并用此数据集以及修改后的标注文件对MTCNN 模型进行训练。此外MTCNN网络模型级联了P-Net、R-Net、O-Net三层卷积神经网络,并对上述三个网络分别依次进行训练。将三个网络模型训练好后,通过训练好的模型对图片数据集进行人脸检测和定位,便可得到图片中人脸区域标记的矩形框的坐标。通过得到的矩形框坐标可以生成掩码,利用掩码对Logistic混沌序列和原图片进行OpenCV 位运算,然后对得到的区域进行加密从而获得加密后的图像。后续将在检测速度或较多遮挡情况下的人脸隐私等方面展开进一步的研究。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
少儿美术·书法版(2021年9期)2021-10-20
计算机工程与科学(2021年4期)2021-05-11
太原科技大学学报(2019年3期)2019-08-05
动漫星空(2018年9期)2018-10-26
火力与指挥控制(2018年3期)2018-04-19
信息安全研究(2016年10期)2016-02-28
电子设计工程(2015年17期)2015-02-27
发明与创新(2015年33期)2015-02-27
