
基于改进YOLOv5s的机坪特种车辆检测算法研究
2023-07-06 12:41诸葛晶昌
计算机测量与控制 2023年6期
诸葛晶昌,李 想
(中国民航大学 电子信息与自动化学院,天津 300300)
0 引言
机坪特种车辆检测是从计算机视觉技术出发,使用目标检测算法实现图像或视频序列中机坪特种车辆的检测。目前,大多数的航班保障任务依赖人工对特种车辆进行判别、记录。该方式消耗大量的人力且数据的随意性较大,不利于提升航班保障效率。因此,针对机坪特种车辆提出一种车辆细粒度分类的算法具有重要意义。
传统算法对于物体的检测通常包括区域选取、特征提取及特征分类这3个阶段。传统算法通常使用滑动窗口算法,在得到待测目标位置后,一般使用人工精心设计的提取器进行特征提取,如尺度不变特征变换[1]和类Haar特征[2]等。最后,对提取到的特征进行分类得到最终的检测结果。由于传统算法是人工设计的提取器,鲁棒性较差[3],因此无法达到实际应用的要求。
随着人工智能的发展和计算机算力的提升,基于深度学习的目标检测算法逐渐成为主流。深度学习的目标检测算法又可以分为基于区域建议的二阶检测算法和基于回归的一阶检测算法。
基于区域建议的二阶检测算法由Girshick等人[4]提出,之后发展出Fast R-CNN[5]目标检测方法,而Fast R-CNN由于候选区域提取的计算量过大,严重影响了检测的速度。Ren等人[6]在此基础上进行改进,提出了Faster R-CNN 目标检测算法,相较Fast R-CNN 算法而言在速度上优势明显。
王林等人[7]将Faster R-CNN 应用于车辆检测,但对于小型目标车辆的检测效果并不理想。Yang等人[8]基于Faster R-CNN 算法采用小区域放大检测的策略,进行道路车辆检测,但在实际检测场景下该算法计算量大实时性较差,且容易受到遮挡的影响。
YOLO 系列算法是具有代表性的一阶目标检测算法。最初的两代YOLO 算法在检测精度和速度两方面并没有较为亮眼的表现,直到采用Darknet 作为主干网络的YOLOv3[9]诞生才真正做到了检测精度与检测速度较好的平衡。在YOLOv3之后提出的YOLOv4[10]以及YOLOv5[11]又在此基础上进行了大规模的改进,成为了现阶段性能突出的目标检测算法。
马睿等人[12]使用YOLOv4算法实现水位的自动识别,叶树芬等人[13]针对电力线和杆塔应用场景使用深度可分离卷积技术降低YOLOv5的模型计算量,并改进NMS算法提升检测算法性能。在车辆检测研究方面,王银等人[14]在YOLOv4基础上使用MobileNetv2深度可分离卷积模块代替传统卷积,并将CBAM 注意力模块融合到特征提取网络中,解决了传统车辆检测算法检测精度低,小尺度目标识别效果差的问题。郭宇阳等人[15]针对路侧交通监控场景和智能交通管控需要,借鉴GhostNet结构,在YOLOv4基础上提出了轻量化车辆检测算法,在检测速度上有显著优势。
目前大部分的车辆检测算法研究面向交通监控场景,主要划分汽车、卡车、公交车三类,针对特定场景下的车辆细粒度分类研究较少。对此,本文提出了一种基于改进YOLOv5s的机坪特种车辆检测方法,主要有以下三个贡献:
1)将位置信息融入通道注意力中,使检测算法将注意力集中于感兴趣区域,扩大机坪特种车辆特征权重覆盖的范围,对特种车辆全局特征的把握能力更强。
2)在三尺度特征检测网络的基础上,提出了一种四尺度特征检测网络,对尺度差异较大的机坪特种车辆具有更好的检测效果。
3)针对多尺度特征融合中各输入对于最终输出贡献不同的问题,结合四尺度检测网络提出了一种双向加权融合结构。各节点根据输入分辨率的不同学习匹配相应的权重,使机坪特种车辆多尺度特征融合的结果更合理。
1 改进的YOLOv5s网络
YOLOv5s由Input输入、Backbone主干网络、Neck层及Detect输出四部分构成。本文在YOLOv5s中融合CA 注意力机制(CA,coordinate attention)[16],增强网络对不同特种车辆特征信息的获取能力;网络Neck部分增加第四层检测尺度,结合加权双向特征金字塔(BiFPN)[17]结构对路径聚合网络PANet[18](PANet,path aggregation network)结构进行改进,加强网络对目标特征更高层次的融合及网络对不同尺度特种车辆的检测能力,改进后的网络结构如图1所示。
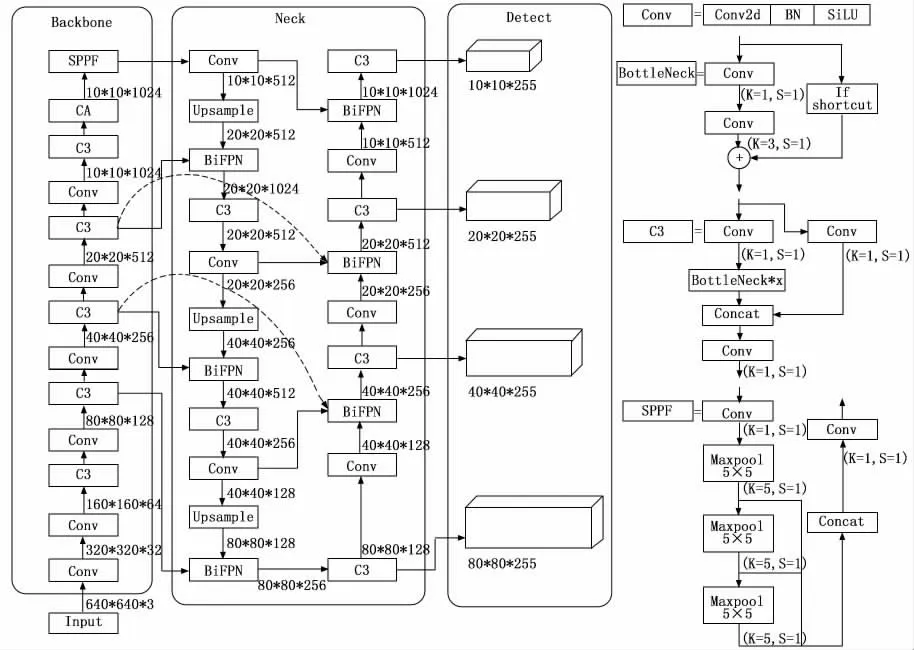
图1 改进的YOLOv5s网络结构
1.1 融合CA注意力机制
机坪特种车辆检测相较城市交通场景下汽车、卡车、公交车三类车辆的检测来说,车辆的种类更多,难度更大,需要检测算法对特种车辆特征有更高的分辨力。注意力机制的核心是让卷积神经网络更多的关注图像中重要的部分,而不是对图像中所有物体都进行关注。
传统的注意力机制包括SENet[19]、ECA[20]、CBAM[21]等。CA 注意力机制相较于传统的通道注意力,将位置信息融入注意力中,利用获取的位置信息更快的定位感兴趣位置,在几乎不额外消耗计算资源的同时对于算法性能的提升效果更好。
CA 注意力机制将两个通道注意力分解为两个一维特征编码,分别沿两个空间方向进行特征聚合。CA 注意力机制结构如图2所示。
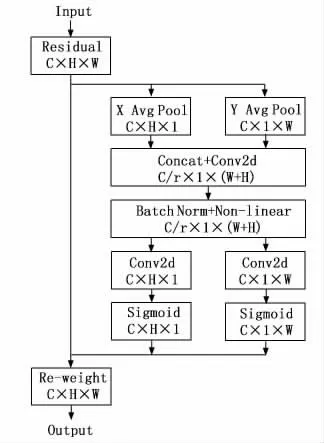
图2 CA 注意力机制结构
首先,是CA 注意力机制的嵌入,CA 注意力机制分别使用尺寸为(H,1)和(1,W)的卷积核沿着水平坐标和垂直坐标对每一个通道进行编码,其中高度为h的c通道输出表示为:
同理,宽度为w的c通道输出表示为:
上述两种变换分别沿两个空间方向聚合特征,得到一对方向感知的特征图。这两种转换允许注意力模块捕捉到沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,这有助于网络更准确地定位感兴趣的目标。
通过这两种变换后生成CA 注意力。在转换过程中,CA 注意力机制先将之前生成的两个特征图进行级联,用一个1*1的卷积进行F1变换,表示为:
其中:生成的f∈RC/r×(H+W)是空间信息在水平方向和垂直方向上的中间特征图,r表示下采样比例。
接着,沿着空间维度将f分为两个单独的张量fh∈RC/r×H和fw∈RC/r×W,经过两个1*1卷积Fh和Fw将两者变换到与输入相同的通道数,上述过程可以表示为:
其中:σ表示sigmoid激活函数。
最后,对gh和gw进行拓展,得到注意力权重。CA 注意力机制的最终输出可以表示为:
YOLOv5s网络各部分对输入特征的提取作用有所不同,Backbone网络对输入图像进行初始阶段的特征提取,SPPF模块将提取的初始阶段特征图转化为特征向量输出,Neck部分对输入提取深层语义特征图,并将Backbone网络提取的浅层语义特征图与深层语义特征图进行融合。因此,在特征提取的不同阶段融合CA 注意力机制效果会有一定的差别。
在YOLOv5s网络中融合注意力机制的方式通常有4种,如图3所示,分别为:融入Backbone网络的每个C3模块后(a)、单独融入Backbone网络的SPPF模块前(b1)或后(b2)、融入网络Neck的每个C3模块后(c)、将注意力机制融合进网络的Backbone(d)或Neck(e)部分的每个C3模块中。除此以外,也可以将上述方式进行组合。
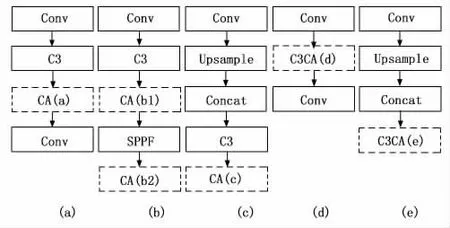
图3 注意力机制融入网络方式
其中,C3CA 模块是把CA 注意力机制融入C3 模块,具体实现方式如图4 所示,给C3 模块赋予一层注意力。C3CA 模块相较单独融合CA 注意力机制来说,不改变网络的总层数,且参数量更低。
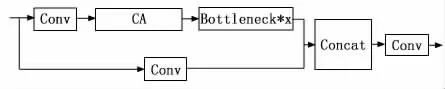
图4 CA 融入C3模块的方式
1.2 提出四尺度特征检测网络
YOLOv5s网络分别经过8倍、16 倍、32 倍下采样输出P3、P4、P5三个尺度的特征图。三个尺度的特征图分别适用于检测小、中、大三类目标。
考虑到机坪监控视角下特种车辆形态差异较大,以中、中大型目标为主的情况,在原始输出P3、P4、P5三个分别为80*80、40*40、20*20尺度特征图的基础上增加P6检测尺度,输出10*10的特征图。如图5所示,改进的四尺度的特征检测网络对于大、中、小型目标的检测精度均有一定程度的提升。
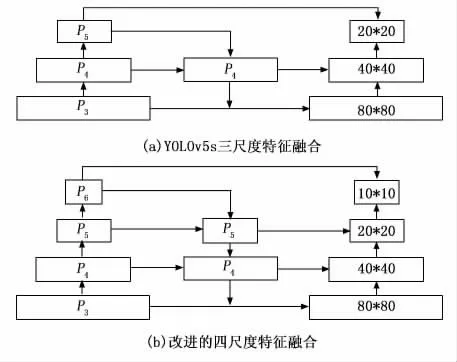
图5 改进的多尺度特征融合结构
1.3 改进多尺度特征融合结构
YOLOv5s的Neck部分采用的PANet结构是在特征金字塔[22](FPN,feature pyramid networks)的基础上增加了一条自底部向上的通道,虽然在一定程度上提升了网络对不同尺度特征融合的能力,但这种融合方式只是简单的相加。由于机坪应用场景对特种车辆检测精度的要求更高,因此,本文针对PANet结构进行改进。考虑到不同通道的输入对于最终输出贡献不同的问题,结合加权双向特征金字塔结构,改进Neck中通道连接结构,各通道节点采用加权融合的方式,改进的特征金字塔结构如图6所示。
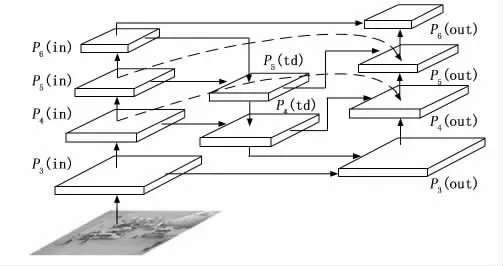
图6 改进的特征金字塔结构
改进的特征金字塔结构是双向跨尺度连接与快速归一化融合两者的结合,其中快速归一化融合相较Softmax融合来说,精度相近却有更快的速度。
加权双向特征金字塔的快速归一化融合可以表示为:
其中:ωi表示特征Ii对应的一个可学习权重且ωi≥0,为避免数值不稳定∈=0.000 1,其余的权重值在归一化后都介于0~1之间。以加权双向特征金字塔输出P5(out)为例,可以表示为:
其中:P5(in)表示P5特征层的输入节点,P5(td)表示P5特征层的第一个输出节点,P5(out)表示P5特征层的第二个输出节点,Conv表示卷积操作,Resize表示上采样或下采样操作。
改进后的特征金字塔结构在四尺度特征检测网络的基础上增加了P4(in)到P4(out)及P5(in)到P5(out)两条通道,在不占用更多计算资源的前提下,扩大了多尺度特征融合范围。改进后各节点可以根据输入特征尺度的分辨率不同,学习匹配相应的权重,使网络在多尺度特征融合过程中得到更合理的特征权重。
2 实验结果与分析
2.1 实验准备
鉴于通用数据集无法为机坪特种车辆检测提供数据支持,本文在实验前期构建了机坪特种车辆数据集。针对机场旅客航班保障工作中较为重要且暂无替代方式的车辆,包括飞机牵引车、行李拖车、客梯车、加油车、食品车及摆渡车共六类。数据包含白天、夜晚不同时间段及远近不同视角,示例如图7所示。其中,部分图片来自机坪视频数据筛选提取,又从网络上搜集了部分特种车辆图片进行补充,六类车辆共计5 022张图片。所有数据均采用Labelimg进行标注,其中4 472张作为训练集,500张作为测试集,50张作为验证集。

图7 数据集示例
使用k-means算法对自建的机坪特种车辆数据集进行重新聚类,结果如图8所示。聚类得到12个锚点框[29,52],[87,54],[57,106],[80,103],[73,197],[112,133],[140,176],[93,272],[229,155],[198,266],[353,355],[553,433],将其按先后顺序分为4组,分别适用于小、中、中大、大型四类机坪特种车辆的检测。
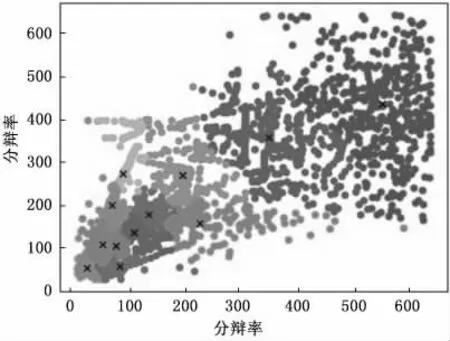
图8 聚类结果
本文实验均在Windows10 操作系统下进行,CPU 为Intel(R)Core(TM)i7-10700@2.90GHz,内存为64G。
GPU 型号为Nvidia GeForce RTX3080,实验仿真使用PyTorch深度学习框架,开发环境为Python3.7,CUDA 版本为11.0。
实验中输入图像的分辨率统一设置为640*640,网络的初始学习率为0.01,动量因子为0.937,训练epochs为300。
2.2 评价指标
为了对改进后的算法性能做出评估,本文选取了精确度(P,Precision)、召回率(R,Recall)、平均精度mAP0.5、mAP0.5:0.95、参数量Params及浮点计算量GFLOPs作为评价指标。
其中,mAP0.5表示IoU 阈值为0.5时所有目标类别的平均检测精度,mAP0.5:0.95 表示以步长0.05,计算IoU 从0.5到0.95的10个IoU 阈值下的平均检测精度,通常情况下IoU 阈值越高对于算法的回归能力要求更高;Params表示参数量,用于计算内存消耗;GFLOPs表示每秒10亿次浮点计算,是衡量训练复杂程度的重要指标。精确率、召回率以及平均精度的计算式如下所示:
其中:TP表示把正类预测为正类,FP表示把负类预测为正类,FN表示把正类预测为负类,Nc表示类别数。
2.3 不同YOLOv5模型对比实验
YOLOv5根据不同网络深度和宽度,划分出n、s、m、l、x五种模型,模型规模依次增大,检测精度也有所差异。其中,YOLOv5n网络深度和宽度分别为0.33 和0.25;YOLOv5s网络深度和宽度分别为0.33和0.50;YOLOv5m网络深度和宽度分别为0.67和0.75;YOLOv5l网络深度和宽度分别为1.0和1.0;YOLOv5x网络深度和宽度分别为1.33和1.25。
本文依据5种模型在机坪特种车辆数据集上的实验结果选择最为适合的模型进行改进,选择的依据主要是模型精度、参数量及计算量的平衡。
网络参数量的增大、模型计算量的提升会在一定程度上降低网络检测速度,训练所消耗的时间也有所增加。如表1所示,YOLOv5n和YOLOv5s是五种模型中相对较小的两种模型,在网络训练阶段二者所消耗的时间较为接近,远少于其余三种模型所需时间。YOLOv5x由于参数量和计算量均最大,因而训练所需的时间也最长。
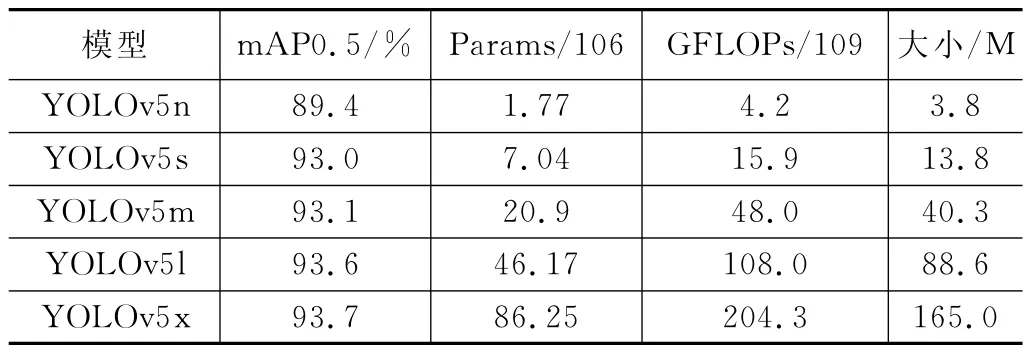
表1 不同深度和宽度的YOLOv5模型对比实验
网络规模最小的YOLOv5n在实验中由于网络深度和宽度的限制,精度与其余4 种模型有着较为明显的差距,YOLOv5s在参数量和计算量仅高于YOLOv5n的情况下,精度与网络规模更大的YOLOv5m 很接近,mAP0.5 仅低0.1%,参数量却减少了66.3%,计算量减少了66.9%。在与YOLOv5系列更大的模型对比中,YOLOv5s的mAP0.5仅低于YOLOv5l模型0.6%,而参数量和计算量分别只有YOLOv5l 的15.2% 和14.7%,与网络模型最大的YOLOv5x相比mAP0.5也仅低了0.7%。
此外,两岸流行音乐受众虽然都具有“怀旧”的审美偏好,但各自所偏爱的歌手及其风格截然不同。在台北与北京举办个人演唱会的“怀旧”歌手,无一相同。大陆流行歌手崔健及其所演绎的摇滚音乐,是北京乃至大陆流行音乐受众最为喜爱的“怀旧”流行音乐风格,但摇滚风格并非台湾流行音乐受众的“怀旧”点。而深受台湾流行音乐受众喜爱的闽南语歌曲,则在大陆缺乏市场。
结合实验结果,在考虑算法部署难易程度外,还应杜绝资源消耗与算法性能提升不匹配的情况。因此,本文选择网络参数量与计算量较低但精度表现尚佳的YOLOv5s作为改进的基础。
2.4 注意力融合位置及不同注意力对比实验
在YOLOv5s网络的不同位置融合CA 注意力机制的效果有较大差异,本文针对图3所述的YOLOv5s网络融合注意力机制的几个位置进行实验。
由表2的实验结果可以看出,CA 注意力机制并非在所有位置都能提升网络的检测性能。位置d,即对Backbone网络的C3模块融合CA 注意力机制的效果最差;位置a,即在Backbone网络的每个C3模块后单独加一层CA 注意力机制的效果也较差。
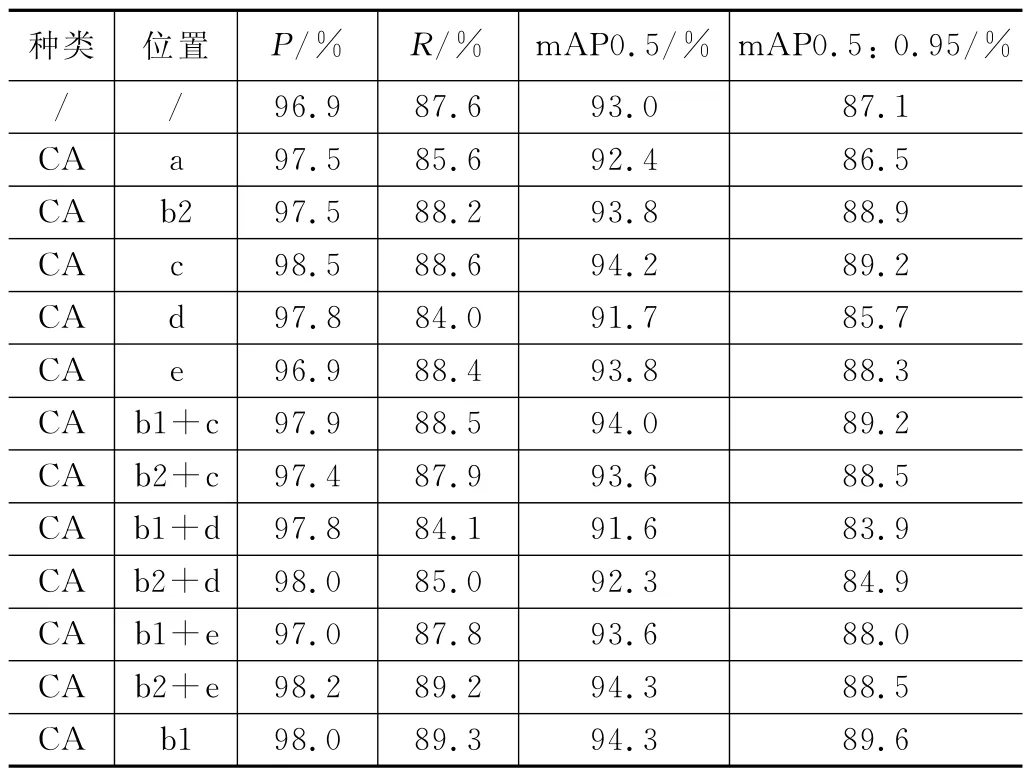
表2 CA 注意力机制不同位置对比实验
在b1、b2、c、e四个位置添加CA 注意力机制对原始网络有一定的效果,在四个有效位置基础上进行组合实验,注意力机制组合实验结果可以看出b2结合e的嵌入方式和单独在位置c进行注意力机制嵌入的方式效果是最好的。然而,比较P、R、mAP各项指标可见,上述两种注意力机制组合的提升效果还是不如在b1位置单独融合CA 注意力机制。
综上,在YOLOv5s网络的b1位置,即SPPF 模块前单独融合CA 注意力机制的实验效果最好。由此可见,在初始阶段特征提取结束,将提取的特征图转化为特征向量输出前,CA 注意力机制能够最大程度上地提升网络感受野,提升算法对特种车辆特征的检测能力。
为了验证CA 注意力机制与其他注意力机制相比对原始网络性能提升的优劣,本文对实验效果最好的b1位置,融合SE、CBAM、ECA 三种注意力机制进行对比实验,对比实验结果如表3所示。
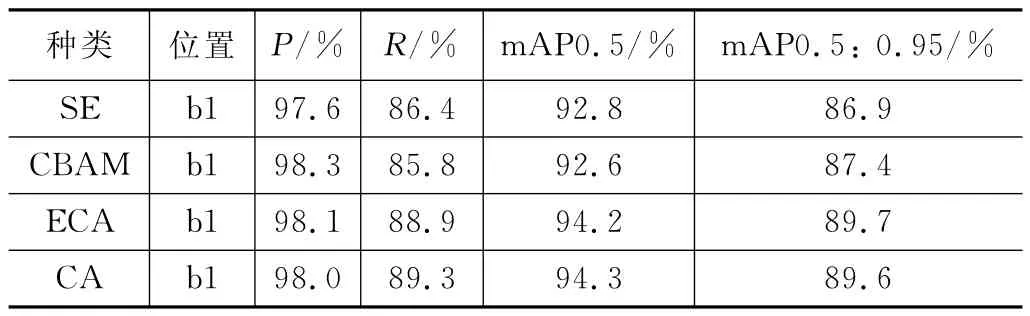
表3 不同注意力机制对比实验
从表3中可以看出,并非几种注意力机制都能够提升网络的检测能力,SE、CBAM 两种注意力机制只能对精确率有轻微的提升作用,其他几项如召回率和平均精度均低于原始实验数据。
为了评估算法在融合CA 注意力机制前后对特种车辆特征检测能力的差异,本文将改进后的算法与原始算法进行特征权重热力图对比。
由图9可以看出,原始网络对于机坪特种车辆的特征把握能力较弱,特征权重所占比例较低,而加入CA 注意力后的算法对于机坪特种车辆全局特征的把握能力更好,权重覆盖范围也更大。

图9 加入CA 前后热力图对比
2.5 不同算法对比实验
为了验证本文改进后的算法与其他检测算法性能的优劣,本文选取经典算法SSD[23]、Faster-RCNN、YOLOv3、YOLOv4-tiny[24]以及YOLOv4算法作为对照。此外,本文分别使用轻量化网络ShuffleNetv2[25]、MobileNetv3[26]替换YOLOv5原始主干网络,得到轻量化的YOLOv5-Shuffle-Netv2、YOLOv5-MobileNetv3两种检测算法。使用上述7种算法和本文算法进行对比,实验结果如表4所示。

表4 不同目标检测算法对比实验
从表4中可以看出:本文改进后的算法在参数量和模型复杂程度较低的情况下,取得了最高的mAP0.5。与参数量更低,模型复杂程度更低的YOLOv5-ShuffleNetv2、YOLOv5-MobileNetv3及YOLOv4-tiny 三种算法相比,本文算法精度优势明显;与参数量更大,模型复杂程度更高的SSD、Faster-RCNN、YOLOv3、YOLOv4算法相比,本文算法依旧具有优势。本文改进算法的mAP0.5高出对比算法中性能最优的YOLOv3 算法1.6%,而参数量却比YOLOv3算法少了79.6%,模型复杂度低了89.3%。
2.6 消融实验
为验证本文改进的CA 注意力机制、四层特征检测网络以及双向加权特征金字塔结构的有效性,进行消融实验,评估各个部分在相同实验条件下对本文检测算法性能的影响。消融实验以原始的YOLOv5s网络实验结果作为基准,实验数据如表5所示。

表5 消融实验
由消融实验结果可以看出:四尺度特征检测和三尺度特征检测相比,检测效果的提升是全面的。此外,无论是改进的双向加权特征金字塔结构还是融合CA 注意力机制都对算法的Precision、Recall、mAP 有显著的提升。与原始网络相比,Recall提升3.5%,mAP0.5:0.95提升了3.3%,mAP0.5有2.3%的提升,Precision虽有轻微波动也提升了1.6%。
将改进后的算法与YOLOv5s在机坪应用场景下的检测结果进行对比,由图10 可以看出,YOLOv5s算法在遮挡较大的场景下无法有效的对特种车辆进行检测,而改进后的算法对机坪特种车辆的特征检测能力更强,在面对部分遮挡时算法的鲁棒性更好。总的来说,改进后的机坪特种车辆检测算法在精度更高的同时,稳定性也更为出众。

图10 实际检测结果对比
3 结束语
本文提出了一种基于改进YOLOv5s的目标检测算法,旨在提升机坪应用背景下对常见航班保障特种车辆的检测能力。
首先,考虑YOLOv5不同模型大小和性能的差异,基于实验结果选择YOLOv5s 作为改进算法。之后,在YOLOv5s网络的不同位置融合CA 注意力机制,确定融合效果最佳的位置。为了验证CA 注意力机制性能的优劣,在效果最佳的位置上分别融合SE、CBAM、ECA 三种注意力机制进行对比实验。接着,提出了一种四尺度特征检测网络,在原始三尺度检测网络的基础上增加了10*10的输出尺度,强化了网络对不同尺度特种车辆的检测能力,并结合加权双向特征金字塔结构进行改进,改进后的算法对不同尺度特征的融合更为合理。此外,使用kmeans算法对机坪特种车辆数据集进行聚类,用聚类得到的锚框数据替换原始数据。在自建的机坪特种车辆数据集上的实验结果表明:本文提出的机坪特种车辆检测算法在Precision、Recall、平均精度mAP指标上较原始网络均有显著提升。
最后,需要指出本文在采用四尺度特征检测网络结构后,虽带来了更优的检测效果,但网络参数量和模型整体的复杂程度均有一定增加,与一些轻量化算法相比对设备性能的要求较高。因此,下一步将考虑如何将检测网络整体轻量化的同时依然保持较高的检测能力,便于在更低算力设备上的部署。
猜你喜欢
小哥白尼(军事科学)(2022年8期)2022-09-20
小雪花·成长指南(2022年1期)2022-04-09
小学科学(学生版)(2021年2期)2021-03-29
西安航空学院学报(2020年5期)2020-12-08
少儿美术(快乐历史地理)(2018年1期)2018-09-25
物联网技术(2018年4期)2018-05-15
农村百事通(2017年9期)2017-07-07
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
