
基于信息检索与 K 均值聚类的化工产品精准推荐算法研究
2023-07-04 07:06:21高云梅张淑慧
粘接 2023年3期
高云梅 张淑慧


摘要:传统K均值聚类对客户聚类精度不高,直接影响化工产品精准推荐的质量。基于此,采用信息检索系统来确定K 均值聚类的初始聚类中心点,消除特殊消费者与数据中的噪声数据,提出了联合信息检索与K 均值聚类的化工产品精准推荐算法。将该算法和Top-N 算法分别应用于化工产品精准营销中,结果表明,提出的算法比Top-N 算法平均绝对误差低,准确率、召回率以及综合平均值高,能够为化工企业实施精准营销提供数据参考。
关键词:信息检索;K均值聚类;化工产品;精准营销;相似度
中图分类号:O213 文献标志码:A 文章编号:1001-5922(2023)03-0132-04
Research on precision marketing strategy of chemical products based on information retrieval andK-means clustering
GAO Yunmei1,ZHANG Shuhui2,3
(1. Yantai Vocational College,Yantai 264670,China;2. Shanghai Lixin Institute of Accounting and Finance,Shanghai 201620,China;3. Southwest University,Chongqing 400715,China)
Abstract:Traditional K-means clustering has low clustering accuracy for customers,which directly affects thequal? ity of accurate recommendation of chemical products. Based on this,an information retrieval system is used to deter? mine the initial clustering center point of K-means clustering and eliminate the noise data in special consumers and data,and a precise recommendation algorithm of chemical products based on joint information retrieval and K-means clustering is proposed. The algorithm and the top-N algorithm are applied to the precision marketing of chemical products respectively. The results show that the proposed algorithm has lower average absolute error than the top-N algorithm,and higher accuracy,recall and comprehensive average. It can provide data reference for chem? ical enterprises to implement precision marketing.
Keywords:information retrieval;K-means clustering;chemical products;precision marketing;similarity
近年来,伴随着国家产能机制的健全以及环境保护政策的有效落实,一些产能落后、污染严重的化工企业被淘汰。面对环境与技术的双重壁垒,化工企业要想在激烈的市場竞争中占据一席之地,就必须实施精准营销,通过精准定位客户,从而不断地提升自身的竞争实力。市场经济环境下,精准营销受到了学术界的广泛关注。研究对商品精准营销中聚类分析和关联规则分析的应用进行研究,指出通过聚类分析和关联规则技术的运用能够挖掘海量数据中隐藏的有用信息,更加精准地了解客户的需求,从而结合客户的需求来开展营销,提升客户对产品的忠诚度与依赖度[1]。通过研究指出企业实施精准营销能够有效降低营销成本,提高营销效率与市场竞争力,同时对关联规则、聚类技术、分类分析、估值与预测等数据挖掘技术在企业精准营销中的应用方法进行了分析[2]。对社会化商务中消费者感知推荐信任的聚类方法进行研究,将推荐信息转化为感知推荐信任,从社交网络中抽取感知推荐信任相似度和关系亲密度网络,并采用谱平分的方法来进行聚类,从而为营销平台制定精准化营销策略提供参考[3]。对化工产品市场营销组合策略进行研究,将化工产品和日用百货进行类比,剖析了营销过程中的洽谈技巧、客情关系,为化工产品的营销提供了借鉴[4]。从目前来看,学术界对化工产品精准营销的研究比较少且主要是定性的分析,缺乏定量化的研究。基于此,构建信息检索与K 均值聚类的化工产品客户识别算法,通过精准定位客户来高效开展化工产品的精准化营销。
1 信息检索系统
1.1 营销数据处理
影响消费者消费行为的因素是多方面的,如消费者的文化程度、可支配收入、工作环境等,不同消费者的行为具有一定的差异性,通过消费者信息的数据处理来获得营销数据检索结果。对消费者营销数据处理的流程如图1所示。
1.2 信息检索模型
信息检索系统是开展化工产品精准营销的关键,通过信息检索系统来精准、全方位把握客户需求,从而结合客户的需求来开展更具针对性的营销活动。由化工产品客户对产品进行评分,将评分结果写成矩阵的形式作为信息检索模型的输入。客户与产品之间的关系反映了客户对化工产品的需求,对于具有同样功能的化工产品,客户的选择也是多样化的。当客户和多个化工产品产生关联时就会产生一个多元化的网络模型。
在信息检索模型中,每一个节点的添加或删除都会对整个的模型产生影响,其具体包括3个方面的内容:首先是延伸,即每增加1个新节点,那么其均会和原有网络中的 m 个节点构建连接关系;其次是局域范围的界定,在网络的所有节点中随机选择 n 个节点,那么界定 LW 为与随机选择 n 个节点所在的范围;最后为考虑连接的优化,设 p为新增节点与范围内节点连接概率,1-p 为新增节点与范围外节点连接概率,得到节点连接之间概率关系为[5]:
式中:ki 为节点度。
基于局域范围的优先连接概率为:
式中:m0为初始网络中节点数量;t 为时间间隔;rij为节点i与节点8(j),公式:
式中:d 为消费者 i 、j 的共有邻域;R(-)i 和 R(-)j 分别为消费者 i 、j 的平均评分;Ri.d 和 Rj.d 分别为用户 d 对 i 和 j 的评分。
局域范围外的随机连接概率为:
2 信息检索与 K 均值聚类的精准营销模型
K 均值聚类是最常使用的无监督学习算法,通过 K 均值聚类来将具有同样需求的客户聚集在一起,划分为多个种类,从而对具有不同种类的消费者开展精准化营销。不妨设 U 为包含 n 个消费者节点的集合,那么任意2个节点i和j之间的相似度sim(i .j)为[6]:
式中:Ii为消费者i评价的产品集合;Ij为消费者j 评价的产品集合;Ri.j为同时被消费者i、j评价的产品集合。
根据相似度定义消费者i的节点加权度 Di 和加权聚集度 Ki ,即[7]:
式中:ui、uj、uk分别为用户i、j 、k 节点;E 为信息检索系统网络边集合;y 为一组节点对所构成的集合。
考虑到特殊消费者以及营销数据中的噪声数据对K 均值聚类效果所产生的干扰,常常是选择信息检索系统网络中节点综合特征值作为聚类的初始中心,节点综合特征值(CFVi)为:
K 均值算法无监督,通过反复迭代求解,具有易实现、易操作、聚类效果良好的优点,通过聚类分析结果将具有同样消费爱好的消费者聚集为一类,从而使得企业更高质量地开展精准营销。假设将原始数据簇划分为(C1. C2.…. Ck ),K 均值聚类的目标是使得平方误差 E 最小,即:
式中:ui 为簇 Ci 的均值向量,计算式为:
K 均值聚类算法是将原始数据中随机选择 k 个作为初始聚类中心,根据相似度计算公式计算其余数据与聚类中心的相似度大小,并对数据进行聚类划分。更新聚类中心,再次对数据进行聚类划分。通过反复迭代来更换数据的聚类中心,使得平方误差(E)最小,算法的流程如图2所示[8]。
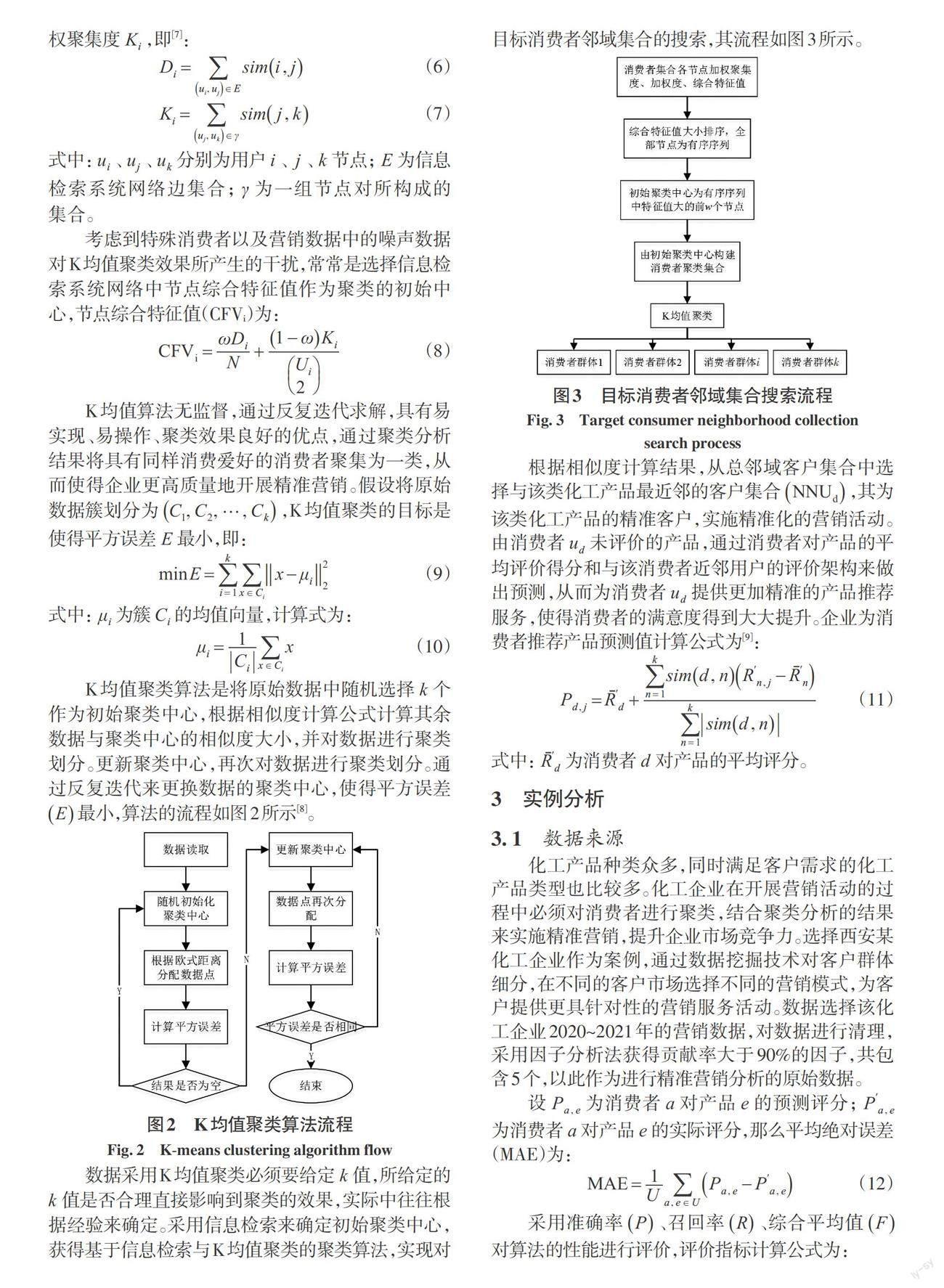
数据采用K均值聚类必须要给定 k 值,所给定的 k 值是否合理直接影响到聚类的效果,实际中往往根据经验来确定。采用信息检索来确定初始聚类中心,获得基于信息检索与K 均值聚类的聚类算法,实现对目标消费者邻域集合的搜索,其流程如图3所示。
根据相似度计算结果,从总邻域客户集合中选择与该类化工产品最近邻的客户集合(NNUd ),其为该类化工产品的精准客户,实施精准化的营销活动。由消费者ud未评价的产品,通过消费者对产品的平均评价得分和与该消费者近邻用户的评价架构来做出预测,从而为消费者ud提供更加精准的产品推荐服务,使得消费者的满意度得到大大提升。企业为消费者推荐产品预测值计算公式为[9]:
式中:R(-)'d 为消费者 d 对产品的平均评分。
3 实例分析
3.1 数据来源
化工产品种类众多,同时满足客户需求的化工产品类型也比较多。化工企业在开展营销活动的过程中必须对消费者进行聚类,结合聚类分析的结果来实施精准营销,提升企业市场竞争力。选择西安某化工企业作为案例,通过数据挖掘技术对客户群体细分,在不同的客户市场选择不同的营销模式,为客户提供更具针对性的营销服务活动。数据选择该化工企业2020~2021年的营销数据,对数据进行清理,采用因子分析法獲得贡献率大于90%的因子,共包含5个,以此作为进行精准营销分析的原始数据。
设Pa.e为消费者 a 对产品 e 的预测评分;P'a.e为消费者 a 对产品 e 的实际评分,那么平均绝对误差(MAE)为:
采用准确率(P)、召回率(R)、综合平均值(F)对算法的性能进行评价,评价指标计算公式为:
3.2精准营销算法性能
为了研究算法的有效性,将基于信息检索与 K 均值聚类的精准营销算法和基于标签的Top-N个性化推荐算法[10-15]进行对比,结果如图4所示。
从图4可以看出,精准营销算法相对于Top-N算法具有明显的优势。由平均绝对误差可知,不论是精准营销算法还是Top-N算法,均可以达到帮助企业实施精准营销的目的,但是精准营销算法的平均绝对误差更小,其实施经营的精准性更高。由准确率可知,2种算法的准确率均和最近邻域数量成正比。联合信息检索与K均值聚类算法将节点综合特征值作为初始聚类中心,能够有效解决孤立点及含噪声数据对聚类结果的影响,导致聚类结果的准确率更高。由召回率可知,2种算法召回率的波动均比较小,但是精准营销算法召回率始终处于比较高的水平,即该算法能够更加精准地推荐消费者感兴趣的产品[16-20]。由综合平均值可知,联合信息检索与K均值聚类算法具有相对较高的综合性能,为化工企业开展精准营销提供数据参考。
4结语
化工企业数量的增多使得企业竞争越来越激烈,同一功能的化工产品种类众多,这使得化工企业必须对客户实施精准营销,才能够达到提高客户粘性、降低营销成本的目的。针对传统K均值算法初始聚类中心选择困难、特殊消费者以及营销数据中噪声数据干扰导致聚类效果不理想的问题,采用信息检索系统来获取初始聚类中心,提出了基于信息检索与K均值聚类的化工产品精准营销算法。将该算法和Top-N 算法进行对比,该算法的平均绝对误差比较低,准确率、召回率以及综合平均值均比较高,对消费者提供的精准推荐服务质量更高。这对化工企业开展产品精准营销,提升企业市场竞争力具有一定的参考。
【参考文献】
[1] 范生万,刘放.商品精确营销中聚类分析与关联规则分析应用研究[J].华东经济管理,2019,31(5):182-184.
[2] 袁阳春,刘森.基于数据挖掘技术的虚拟企业审计风险评估模型[J].微型电脑应用.2021,37(9):103-106.
[3] 尹进,胡祥培,郑毅,等.社会化商务中消费者感知推荐信任的聚类方法研究[J].运筹与管理,2021,30(2):16-24.
[4] 吴小荣.化工产品市场营销组合策略研究[J].热固性树脂,2021,36(5):78-80.
[5] 王涛,刘星亮,王泓淇,等.于志军.基于机器学习的富硒茶评论文本消费者满意度感知研究[J].湖北农业科学.2022,61(1):146-152.
[6] 李辉,罗敏,岳佳欣.基于计算机视觉技术的水稻病害图像识别研究进展[J].湖北农业科学,2022,61(4):9-15.
[7] 陈源毅,冯文龙,黄梦醒,等.基于知识图谱的行为路径协同过滤推荐算法[J].计算机科学,2021,48(11):176-183.
[8] 钟志峰,李明辉,张艳.机器学习中自适应k值的k均值算法改进[J].计算机工程与设计,2021,42(1):136-141.
[9] 王粤,黄俊,郑小楠,等.基于用户兴趣和评分差异的改进混合推荐算法[J].计算机工程与设计,2021,42(10):2830-2836.
[10] 马闻锴,李贵,李征宇,等.一种基于标签的Top-N个性化推荐算法[J].计算机科学,2019,46(S2):224-229.
[11] 何昕雷.基于模糊 PID 算法的自动控制研究[J].粘接,2022,49(3):177-181.
[12] 谢桦,亚夏尔·吐尔洪,陈昊,等.基于支持向量机算法的配电线路时变状态预测方法[J].电力系统自动化,2020,44(18):74-80.
[13] 郑茂然,余江,陈宏山,等.基于大数据的输电线路故障預警模型设计[J].南方电网技术,2017,11(4):30-37.
[14] LI H J,HABIBI S,ASCHEID G. Handover prediction for long-term windowscheduling based on SINR maps[C]//2013 IEEE 24th Annual International Symposium on Per? sonal,Indoor,and Mobile Radio Communications(PIM? RC). London,UK:IEEE Press,2013.
[15] 王毅星.基于深度学习和迁移学习的电力数据挖掘技术研究[D].杭州:浙江大学,2019.
[16] DHIMISH M,HOLMES V,MEHRDADI B,et al. Photo? voltaic fault detection algorithm based on theoretical curves modelling and fuzzy classification system [J]. En? ergy,2017,140(1):276-290.
[17] 胡程平,陈婧,胡剑地,等.配电台区线损率异常自动检测系统设计[J].粘接,2022,49(5):188-192.
[18] 曹海红.基于双DSP的异步电机控制系统设计[J].粘接,2021,47(8):143-146.
[19] 李振璧,张坤,姜媛媛,等.基于变分模态分解与近似熵的输电线路两相接地故障诊断[J].科学技术与工程,2018,18(5):70-75.
[20] DOOSTAN M,CHOWDHURY B H. Power distribution system fault cause analysis by using association rule min? ing [J]. Electric Power Systems Research.2017,152(1):140-147.
猜你喜欢
中国化肥信息(2020年9期)2020-01-20 04:50:49
中国新通信(2016年22期)2017-01-13 08:22:08
计算技术与自动化(2016年4期)2017-01-11 14:04:00
商情(2016年43期)2016-12-23 14:26:47
中国科技博览(2016年25期)2016-12-20 20:02:30
中国市场(2016年35期)2016-10-19 02:16:47
电脑知识与技术(2016年21期)2016-10-18 23:20:17
今传媒(2016年9期)2016-10-15 22:08:05
科技视界(2016年10期)2016-04-26 11:40:14
中国化肥信息(2014年14期)2014-03-16 10:48:26
