
一种基于分簇优化的VNDN数据转发方法
2023-07-04 02:51侯睿陆可
中南民族大学学报(自然科学版) 2023年4期
侯睿,陆可
(中南民族大学 计算机科学学院,武汉 430074)
近年来,随着智能交通领域的快速发展,车辆自组织网络(Vehicle Ad hoc Network,VANET)已经成为车联网发展的重要技术[1].在VANET中,车辆的快速移动对数据端到端通信产生了很大挑战,同时车辆之间的数据通信仍然停留在以车辆地址为中心的信息交互机制,增加了传输和处理时延.因此,亟需一种以数据信息为中心的资源共享方式,来提高VANET中数据的交互效率.
命名数据网络(Named Data Networks,NDN)是一种以数据内容为信息共享方式的新型网络架构,区别于当前基于IP地址的信息交互模式,NDN将网络中的信息实体赋予了唯一名称并以数据内容名称为索引,完成信息资源的交互,提高了数据共享效率,因而被认为是下一代互联网体系结构的有效方案之一[2].在NDN的驱动下,将VANET与NDN相结合,构成的车辆命名数据网络(Vehicular Named Data Networks,VNDN)对提升车辆间数据通信效率起到积极作用,因此被认为是未来智能车联网的发展趋势之一[3].
在VNDN中,由于车辆的移动性,会造成车联网拓扑结构时刻发生变化,进而造成基于耦合路由机制的数据交互模式出现通信链路断裂等问题,从而影响网络通信质量和用户服务体验.因此,对车辆移动的轨迹进行准确预测并据此优化数据传输路径,对保证VNDN中数据可靠传输起到关键作用.鉴于此,本文提出一种基于分簇优化的数据转发方法,该方法利用卡尔曼滤波预测车辆移动状态,计算与邻居车辆保持连接的通信时间,并根据邻居车辆数进行加权计算,将权值最高的车辆作为簇头,也就是邻居车辆多且尽可能长时间与邻居车辆保持通信的车辆容易成为簇头,这些簇头有助于簇的稳定性,同时引入网关车辆合理控制簇的大小保证相邻簇之间的通信,当数据返回时,簇头根据卡尔曼滤波预测簇成员位置,降低簇头和簇成员周期性交换信息的频率.该方法用簇头和网关车辆作为中间转发节点,建立一条稳定的通信链路,降低车辆移动对数据转发路径的影响,为大多数车辆提供相对稳定可靠的数据传输,提高数据包交付成功率.
1 国内外现状
近年来,针对VNDN中数据通信链路断裂问题进行了大量的研究,主要分为路侧单元(Road Side Unit,RSU)协助以及车辆与车辆(Vehicle-to-Vehicle,V2V)两类.
对于RSU协助方法,HUANG等[4]提出一种基于分簇的选择性协同缓存方法,该方法根据车辆的位置和速度选择簇头将车辆划分为不同的簇,并让RSU协助簇头缓存流行数据.该方法簇头要定期维护与簇成员之间的状态,开销较大.HOU等[5]提出一种基于分簇路由的VNDN中数据包回程预测方法,该方法使用全球定位系统(Global Positioning System,GPS)和凸规划位置算法获得车辆的定位信息,通过卡尔曼滤波模型预测车辆位置.PENG等[6]提出一种基于RSU辅助的Geocast方法,该方法利用四叉树模型在全局域内分解RSU,通过选择最佳的下一跳RSU将报文转发到目的地,但四叉树路由位置信息的维护会额外增加网络开销.HUANG等[7]提出一种基于移动预测分簇的协同缓存方法,该方法基于马尔可夫模型和链路过期时间模型进行移动预测,对具有相似移动特征的车辆进行分簇,但是该方法未考虑簇头之间的通信可行性且开销较大.
对于V2V方法,RONDON等[8]提出一种基于度中心的VNDN缓存发现协议,该协议优先将兴趣包(Interest Packet)转发给处于发送车辆通信边缘且邻居车辆数量较多的车辆. AHMED等[9]提出一种分布式Interest包转发选择方案,该方案在消费者(Consumer)的前后两个方向上选择合适的车辆转发Interest包.QIAN等[10]提出了一种基于延迟的Interest包转发策略,该策略根据与转发节点的距离,相邻节点获得不同的等待延迟,从而在不保留节点间信息的情况下选择最优的下一跳节点,并取消无用的转发.该方法降低了维护节点间信息的开销,减轻了网络中无效的转发.但以上三种方法都没有考虑车辆移动带来的影响.WANG等[11]提出一种基于移动预测的VNDN转发方法.该方法选择数据区邻居车辆作为备选结点,选择通信链路时间较长的车辆作为下一跳.LI等[12]提出一种基于最优和备份的Interest包转发策略,该策略综合考虑距离、相对速度、链路持续时间、信号强度和节点度,指定最优节点转发Interest包,当Interest包发生丢失时采用轻量重传机制.BURHAN等[13]提出一种广播风暴缓解策略(Broadcast Storm Mitigation Strategy,BSMS),该策略根据距离和相对速度计算邻居车辆优先级,选择优先级高的车辆作为下一跳.GUO等[14]提出一种基于贝叶斯的Interest包转发方法(Bayesian-based Receiver Forwarding Decision,BRFD),该方法基于贝叶斯模型选择转发的下一跳,当有较多的车辆适合时则选择距离上一跳最远且速度适中的车辆作为下一跳.以上三种方法虽然考虑了车辆移动性带来的影响,但是需要对邻居车辆信息进行实时维护,开销较大.
2 相关理论
2.1 NDN路由方式
NDN有两种包类型:Interest包和Data包.在NDN中Consumer为请求数据向网络发送Interest包,通过网络转发到达存储着对应数据的生产者(Producer),Producer将对应数据封装成Data包沿着Interest包的反向路径返回至Consumer.NDN中每个节点维持3个结构,分别是:待定转发表(Pending Interest Table,PIT)、内容存储(Content Storage,CS)、转发信息表(Forwarding Information Base,FIB).PIT记录节点已经转发但尚未被满足的Interest包及其接口信息,CS缓存节点转发过的数据内容,FIB用来向匹配数据的可能源转发Interest包.NDN处理数据包流程如图1所示:当用户想要获取特定数据内容时,发出Interest包,NDN节点收到Interest包后,先查询CS中是否有匹配的数据,如果有则直接返回对应的Data包;否则查询PIT,如果有匹配项,节点会在该项下记录Interest包进来的接口;如果没有,则查询FIB,若有对应项,则按照此类Interest包的转发规则进行转发,同时在PIT中加入该Interest包的转发信息,若没有对应项,则丢弃该Interest包[15].在Data包回传过程中,PIT查询是否有该数据的请求,如果有则给所有请求列表分发,同时CS进行缓存,若没有则丢弃.
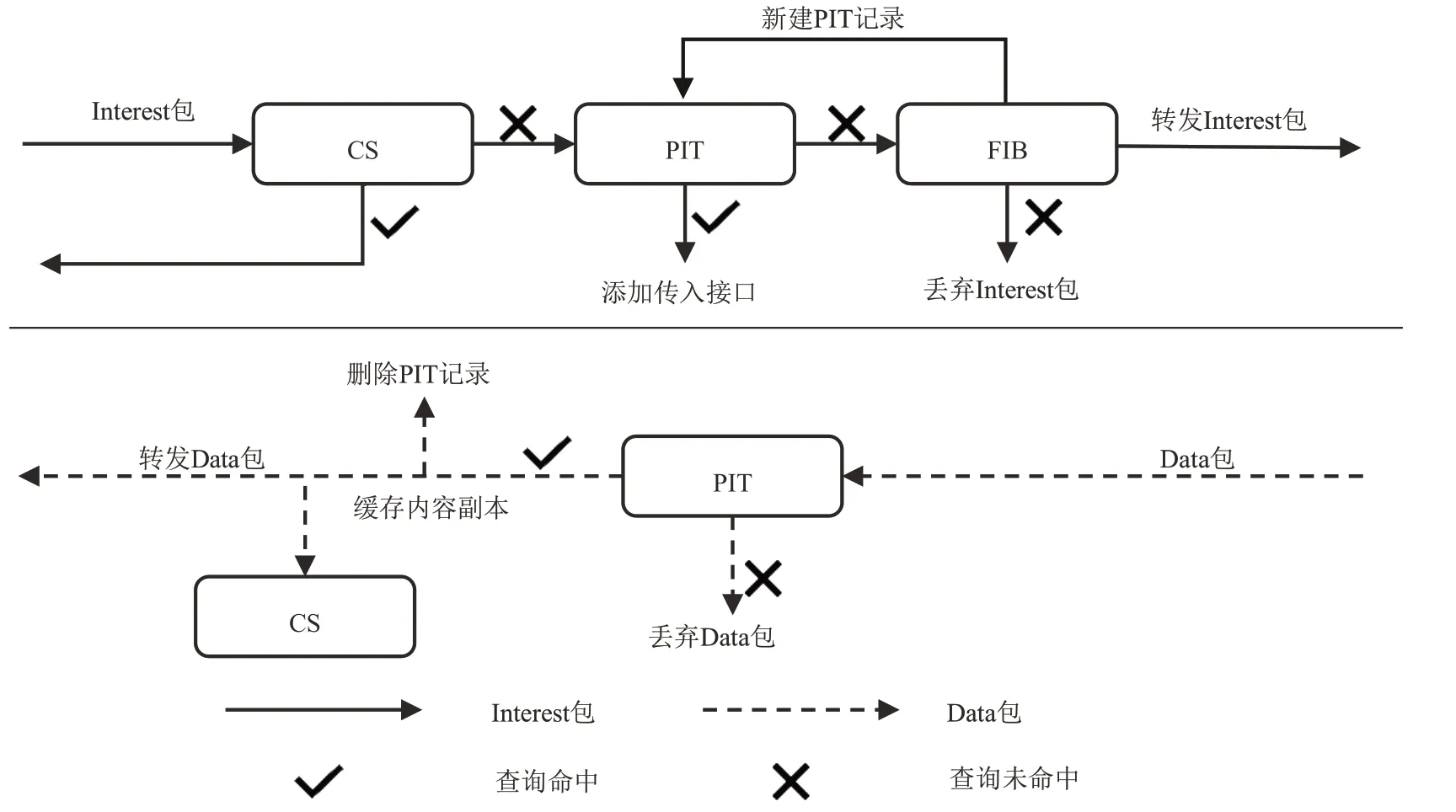
图1 NDN处理数据包流程Fig.1 The flow of NDN processing packets
2.2 卡尔曼滤波理论
卡尔曼滤波方法是一种最优化自回归数据处理方法,递归利用上一次最优结果预测当前值,并使用观测值修正当前值,得到最优结果的过程[16].
(1)预测状态方程.用t-1时刻最优值和模型输入计算出t时刻模型预测值
(2)预测协方差方程.更新t时刻真实值和预测值误差的协方差矩阵
式中,Pt-1为t-1时刻误差,Q为过程噪声方差.
(3)计算卡尔曼增益系数Kt:
式中,H为观测矩阵为协方差矩阵,R为测量噪声方差.
(5)更新此时真实值和估计值之间误差的协方差矩阵Pt:
式中,I代表单位矩阵.
3 基于分簇的数据转发方法
3.1 系统模型
在本文中,每辆车都装载GPS和车载单元(OBU),前者用于获取自身位置,后者保证与其他车辆正常通信.分簇状态见图2所示,每一个椭圆区域内都包含一个完整的簇结构,包含簇头(Cluster Header,CH)、簇成员(Cluster Member,CM)和网关节点(Gateway Node,GN).CH维护一张包含CM表和一张包含GN表,GN维护包含相邻两个CH表.车辆根据卡尔曼滤波预测方法分成不同的簇,通过选定的簇头缓存数据,建立簇内和簇间通信.CM只与CH进行通信,簇间通信需要CH将数据包转发给本簇的GN车辆,再由GN车辆将数据包转发给邻居CH.每辆车都处于以下四种状态之一:CH、CM、GN和孤立车辆(Orphan Vehicle,OV),其中OV是还未加入任何一个簇的车辆.
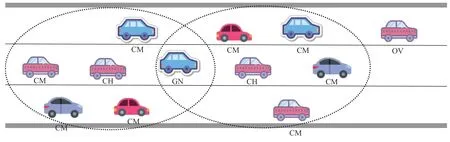
图2 分簇状态示意图Fig.2 Schematic diagram of the clustering statel
3.2 卡尔曼滤波预测
在本文中,基于卡尔曼滤波理论的移动预测模型,每个车辆节点都有一个预测模型来预测自己与邻居车辆的移动.在t时刻车辆通过GPS获取自身的位置信息和速度信息,形成一个状态向量Xt=(xt,yt,vxt,vyt)T,其中(xt,yt)是车辆在t时刻的位置坐标,(vxt,vyt)是车辆在t时刻的速度坐标.然后广播一个信标包,信标包携带发送方的身份信息、移动信息和状态信息,其中移动信息包括位置和速度信息.车辆根据信标包获取邻居车辆的移动信息,形成对应的状态向量.根据公式(1)~(2)预测自己和所有邻居车辆在t+1时刻的状态向量,车辆在t+1时刻获取实时位置,检查位置预测误差,如果误差超出阈值θ(θ=10,使用卡尔曼滤波预测时,87%以上的值的距离误差小于10 m,只有2.2%的值的距离误差大于50 m.因此,在VANET中应用对定位精度要求较高的情况下,可以选择θ值小于或等于10 m.)[16],车辆继续广播信标包,包含t+1时刻的位置和速度信息,然后车辆使用公式(3)~(5)更新预测模型.否则车辆将继续使用预测模型,并且不在广播信标包.
在预测模型中,考虑到实际情况,车辆的状态在△t内变化不大(△t=1 s,为采样间隔),vxt和vyt可以表示为△t内的平均速度,因此预测下一时刻状态方程为:
式中,wt为过程噪声,服从均值为零、协方差为Q的高斯分布.
在模型中,只需输出车辆的位置信息,所以观测方程为:
式中,x、y分别是车辆位置的横坐标和纵坐标,H为目标观测矩阵,vt代表观测噪声,服从服从均值为零、协方差为R的高斯分布.
3.3 分簇过程
3.3.1 欧式距离计算
式中,x1、y1、x2、y2分别代表V1,V2的x轴和y轴坐标.
3.3.2 权值计算
初始时所有车辆都处于孤立状态,选择簇头将车辆分成不同的簇.本文利用卡尔曼滤波预测与邻居保持通信连接的时间和邻居车辆数据进行加权,选择权值最高的车辆为簇头.车辆权值越大说明该车辆有较多邻居车辆并且与邻居车辆保持通信时间越长.如车辆Vi与其相邻的车辆Vj(j=1,2,3…)之间可以相互通信,每辆车都会向邻居车辆广播一个信标包,车辆Vi收到信标并收集相关信息后,计算其权重Wi为:
式中,Num为车辆Vi的邻居车辆数,Let为卡尔曼预测车辆与所有邻居车辆保持通信的平均时间,具体计算过程伪代码见算法1,且w1+w2=1;车辆Vi计算权值Wi后,记录权值,并将该值添加到下一个信标包中.
3.3.3 CH选择

网络刚建立时,所有车辆都处于孤立状态,每辆车向邻居车辆发送信标包,车辆Vi收到邻居车辆Vj(j=1,…|Nh|)的信标包后,利用公式(9)计算权值Wi,然后将权值加入到下一个信标包,Vi收到邻居车辆Vj(j=1,…|Nh|)的权值Wj(j=1,…|Nh|)后,与自己的权值进行比较.如果Vi的权值最高,则Vi成为簇头,状态信息在下一个信标包中从OV更新到CH,然后邻居车辆收到CH的状态信息,邻居车辆加入集群,状态信息从OV更新到CM.
3.3.4 GN选择
GN保证相邻两个CH之间的通信,因此GN与CH保持通信的时间越久,通信链路越稳定.CH根据公式(8)计算与CM的距离,CH选取簇边缘车辆中合适的车辆构建候选GN车辆候选列表£,如果CM与CH之间的距离满足条件D(VCH,VCM)≥0.7R,则将该CM加入£中,然后CH根据算法1(此时N=1)分别计算CH与候选GN节点的Let,选取Let最大的车辆节点为GN,此时被选择的车辆状态信息从CM更新为GN.
3.4 数据转发过程
3.4.1 Interest包转发过程
在Interest包转发过程中,Interest包被转发至带有对应数据的车辆,转发步骤如下:
步骤1:当CM发生数据请求时,向CH发送Interest包;
步骤2:CH接收到Interest包后先检查CS,如果有对应数据,当前执行簇内通信,CH直接返回对应的Data包,否则检查PIT.如果PIT有对应Interest包名称相符的条目,则在该项下记录Interest包进来的接口并转到步骤3.如果CS和PIT都查询不到,CH为该Interest包创建一个PIT条目并转到步骤3;
步骤3:CH根据维护的CM表和GN表,向本簇的CM和GN转发Interest包,然后根据以下情况进行处理:(1)CM接收到Interest包,检查自己的CS表,如果有对应数据,返回对应数据包,如果没有则丢弃该Interest包;(2)GN接收到Interest包,检查自己的CS表,如果有对应数据,返回对应数据包,如果没有执行簇间通信,GN根据维护的相邻CH表,向相邻的CH转发Interest包并转到步骤2.
如图3所示CH1中的成员CM1为请求数据向CH1发送Interest包,请求过程如图3中①,CH1检查CS,如果有对应数据,则直接返回对应的Data包,否则根据维护的CM表和GN表向本簇的CM2和GN转发Interest包,如图3中②③所示.当CM2接收到Interest包,检查CS,如果有对应数据,则直接返回对应的Data包,否则丢弃该Interest包.当GN接收到Interest包,检查CS,如果有对应数据,则直接返回对应的Data包,否则向CH2转发该Interest包,如图3中④所示.

图3 Interest包转发过程Fig.3 The process of Interest package forwarding
3.4.2 Data包转发过程
在Data包回传过程中,Data包沿着Interest包的反向转发路径转发至请求数据的CM,Data包回传步骤如下:
步骤1:当Interest包转发至有对应数据的车辆,如果该车辆是CM则转到步骤2,如果是GN则转到步骤3,如果是CH则转到步骤4;
步骤2:CM将Data包反向转发至CH;
步骤3:GN根据维护的相邻CH表将Data包转发至相邻的CH;
步骤4:CH缓存数据以备后续CM请求相同的数据,并删除PIT中对应的条目.如果当前CH不是请求数据CM的CH,则CH根据维护的GN表将Data包转发给GN,然后转至步骤3.当Data包回传至请求Interest包所在的CH时,CH基于卡尔曼滤波预测请求数据的CM位置,根据公式(8)计算与其的距离,判断该CM是否还在簇内,然后根据以下情况进行处理:(1)请求数据的CM在簇内.CH缓存Data包以便后续CM请求相同的数据,并将其转发给请求数据的CM,同时删除PIT中对应的条目;(2)请求数据的CM不在簇内.CH缓存Data包后向该Data包增添附加信息字段hopcount,hopcount表示跳数,并根据维护的GN表向本簇的GN转发Data包并转至步骤3,同时删除PIT中对应的条目.每转发一次Data包,hopcount=hopcount-1,当hopcount=0时停止转发,当CH接收到该数据向CM广播Data包.hopcount计算如下:
式中:D为基于卡尔曼预测CH与请求数据的CM的距离,R为车辆通信半径.
如图4所示,当Data包回传至所在的CH1时,CH1基于卡尔曼滤波预测请求数据的CM1的位置,计算与CM1的距离,判断CM1是否还在簇内,如果在簇内,则直接返回Data包,如图4中①所示,否则CH1向该Data包增添附加信息字段hopcount,并向GN转发,GN再向相邻的CH2转发,CH2接收到Data包后,向CM广播,直至hopcount=0,如图4中②③④所示.
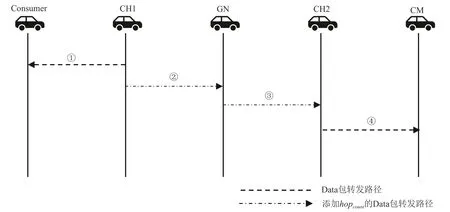
图4 Data包转发过程Fig.4 The process of Data package forwarding
本方法建立簇内(CM↔CH)和簇间(CH↔GN↔CH)通信,在一定程度上建立一条链路较为稳定通信路径,同时CH根据卡尔曼滤波对簇成员进行预测,降低CH和CM周期性交换信息的频率,提高数据包交付成功率.
4 实验结果与分析
4.1 实验参数
在仿真实验中,本文为基于分簇优化的VNDN数据转发方法(COVNDN),利用C++构建了一个仿真平台,并使用SUMO模拟城市道路交通场景,生成车辆的位置序列.实验中车辆的速度为30 ~50 km/h,实验参数如表1.实验考虑了不同Consumer数量和不同Producer百分比下,所提方法与BSMS、BRTF和传统VNDN在平均时延以及数据包交付成功率两方面下进行了比较,从而体现所提方法的有效性.

表1 实验参数Tab.1 Experimental parameters
4.2 仿真结果与分析
(1)平均时延.
平均时延:Consumer完成数据收发的时间与Consumer发送Interest包数量的比值.
图5和图6显示Consumer数量变化和生产者百分比变化对平均传输时延的影响.如图5所示,四种方案在不同Consumer数量下平均时延对比.随着网络中Consumer节点数目逐渐增多,四种方案的平均时延都逐渐增大,其中VNDN变化较为明显,本文所提方法变化较为平缓且平均时延比其他三种方法低.如图6所示,随着网络中生产者百分比的逐渐增大,四种方案的平均时延都逐渐降低,由于本文建立的簇间通信,使得数据在转发过程中经历较少跳数就可以达到目标节点,进而使得平均时延在四种方法中最低.总体来说,本文提出的方法在Consumer数量变化和生产者百分比变化下,平均时延明显低于其他三种方法.

图5 平均时延随Consumer数量变化Fig.5 The average delay varies with the number of Consumers

图6 平均时延随Producers百分比变化Fig.6 The average delay varies with the percentage of Producers
(2)Data包成功交付率.
Data包成功交付率:Consumer实际接收到的Data包的数量与Consumer发送Interest包数量的比值.
图7和图8显示Consumer数量变化和生产者百分比变化对Data包成功交付率的影响.如图7所示,四种方案在不同Consumer数目下的Data包成功交付率对比.随着网络中Consumer数目的逐渐增多,四种方案的Data包成功交付率都呈下降趋势,COVNDN与其他三种相比变化较为平缓,说明Consumer数量变化对COVNDN的交付率影响较小.如图8所示,随着网络中生产者百分比的逐渐增大,四种方案的Data包成功交付率都呈上升趋势,其中COVNDN低于VNDN,并且随着生产者百分比逐渐增大,越接近VNDN.COVNDN在平均时延和Data包成功交付率两方面均优于BSMS和BRFD这两种方法,虽然在Data包成功交付率方面略低于传统的VNDN,但是由于COVNDN在簇内和簇间建立了稳定的通信使得Data包成功交付率受外界条件变化较小,且在平均时延方面远远低于传统的VNDN,因此本文所提方法在平均时延和Data包成功交付率方面均表现出一定的优势.

图7 Data包成功交付率随Consumer数量变化Fig.7 The successful delivery rate of Data packages varies with the number of Consumers

图8 Data包成功交付率随Producers百分比变化Fig.8 The successful delivery rate of Data packages varies with the percentage of Producers
5 结束语
在针对VNDN中通信链路断裂问题,本文提出了一种基于分簇优化的VNDN数据转发方法,基于卡尔曼滤波预测机制进行分簇,并引入网关节点,建立稳定的数据链路,降低车辆移动性对通信的影响.仿真结果表明该方法在有效的降低通信时延的同时提高了数据成功交付率.此外,本文仅研究直线道路下车辆之间的数据传输,在后续的研究中应着重于环形交叉口、立体交叉口等复杂的道路场景.
猜你喜欢
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
小太阳画报(2018年3期)2018-05-14
北京航空航天大学学报(2017年9期)2017-12-18
阅读与作文(小学低年级版)(2016年12期)2016-12-22
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
电源技术(2016年9期)2016-02-27
汽车文摘(2015年11期)2015-12-02
电源技术(2015年1期)2015-08-22
