
云环境下一种强隐私保护的安全Top-k查询方案*
2023-07-03 06:14崔韶刚周春光
吉首大学学报(自然科学版) 2023年3期
崔韶刚,尹 辉,周春光
(长沙学院网络中心,湖南 长沙 410003)
可搜索加密(Searchable Encryption,SE)[1]是加密数据的查询和检索技术.近年来,云环境下的SE技术是学术界和产业界的研究热点,目的在于不断提高查询效率和查询准确度,降低空间和传输开销,以及实现用户查询的隐私保护等.然而,现有的方案存在以下3个问题[2-3]:(1)将云作为唯一的威胁实体.(2)在大多数方案中,数据更新需要数据拥有者重建查询索引,这会产生频繁的索引重建工作,给云用户带来沉重的计算负担,大大降低系统的伸缩性和可用性.(3)没有一个真正安全和精确的查询结果相关性排序方案来实现云端的top-k安全查询.为了解决以上问题,笔者拟利用双线性映射和布鲁姆过滤器设计支持数据动态更新的安全索引和强隐私保护的高效查询方案,并利用全同态加密技术[4]和关键字在数据文件中的权重信息,对查询结果进行精确的相关性排序,以期在不泄露任何明文信息的情况下,让云返回与用户查询最相关的数据文件.
1 相关工作
1.1 对称可搜索加密
2000年,Song等[5]基于对称密钥环境,首次设计了一个实用的SE方案.因为此方案并没有建立查询索引,而是采用一种特殊的2层加密结构对文档中的全部词项逐个进行加密,所以在查询时,需要服务器对整个文档的每一个词项和用户提交的查询关键字进行比较.这种方案只能处理非压缩形式的文档类型文件,且无法抵御词典攻击.Goh[6]对文献[5]中的查询效率和安全性作了改进,利用布鲁姆过滤器和伪随机函数为外包文件建立安全索引,极大地减少了查询的比较次数.Curtmola等[7]利用倒排索引技术构造了一个高效的单关键字对称可搜索加密(Searchable Symmetric Encryption,SSE)方案,并给出了SSE机制的定义.但该方案存在预定义的全局词典,导致文件更新需要用户重建所有加密的倒排索引,不适合多用户的云计算环境.Wong等[8]利用矩阵和向量的对称加密运算,通过比较2个加密向量点的欧几里得距离实现了加密数据库的安全k-近邻(k-Nearest Neighbor,k-NN)计算.
1.2 非对称可搜索加密
2004年,Boneh等[9]基于加密邮件查询的应用场景,首次提出了基于公钥加密的关键字查询(Public-Key Encryption with Keyword Search,PEKS)方法.在PEKS方法中,邮件发送者利用邮件接收者的公钥加密邮件和建立相应的查询索引;邮件接收者查询时,他利用自己的私钥加密查询关键字后发送给邮件网关,让邮件网关执行秘密查询.Golle等[10-12]基于公钥密钥体制设计了加密文件的多关键字安全查询方案.由于公钥密码加解密存在计算开销,因此这些方案不适合大规模数据集下的安全查询场景,而且文件和索引若采用公钥加密,则一个具有强大计算资源的敌手(如云)可以对其进行字典攻击和统计攻击.
1.3 云环境下的Top-k安全排序查询
Wang等[13]在SSE方案的基础上,利用关键字在文档中的权重和保序对称加密(Order Preserving Symmetric Encryption,OPSE)[14]技术实现了云环境下相关性排序的对称可搜索加密(Ranked Searchable Symmetric Encryption,RSSE)方案.但OPSE技术固有的缺陷,使得RSSE方案不能很好地抵御已知背景知识下的统计攻击,以及无法适应数据分布动态变化的云环境.2013年,Cao等[15]基于安全k-NN计算[8],首次提出了云环境下的加密数据多关键字排序查询(Multi-Keyword Ranked Search over Encrypted Cloud Data,MRSE)方法.该方法以查询关键字是否包含在文件中为依据进行相关排序,排序结果不能准确地反映文档与查询之间的相关性.Li等[16]使用编辑距离来量化字符串的相似度,并利用同一字符串的不同编辑距离实现云环境下的模糊查询.但该方案需要的存储和通信负载比较大,且不能对查询结果进行相关性排序,准确率误差较大.Liu等[17]通过对用户和查询进行分级,利用Paillier密码系统的同态属性,实现了按用户等级返回一定百分比数量的文件给用户,大大减少了网络传输开销.但该方案需要一个完全可行的第三方查询汇聚和分发层作为中间件,同时需要一个预定义的全局词典.
在以上相关工作中,对于用户查询隐私,都将远程服务器作为唯一的威胁实体,而没有考虑潜在的内部攻击者,如一个恶意的数据拥有者或一个妥协的数据使用者.在文献[15-16]中,用户的查询内容以明文的形式暴露给数据拥有者,数据拥有者直接掌握用户查询内容.在文献[5-7,13,17]中,虽然数据使用者自己加密查询关键字,但加密密钥是数据拥有者授权提供的,数据拥有者掌握密钥信息,用户无法抵御数据拥有者的恶意探查和分析查询隐私的攻击,也无法保证数据拥有者不将用户查询信息或密钥泄露给第三方敌手,因此用户的查询隐私面临更大的泄露风险.另外,一个妥协的数据使用者也可以向远程服务器泄露其他用户的查询隐私,因为当他们使用相同的查询关键字时具有相同的查询陷门形式.在公钥环境下,用户通过自己的私钥加密查询关键字,远程服务器无法合谋恶意的数据拥有者或妥协的数据使用者攻击用户的查询隐私,但因为文件和索引采用公钥加密,所以用户无法抵御云的字典攻击或统计攻击.
2 问题陈述与相关知识
2.1 问题陈述
如图1所示,云环境下基于隐私保护的多用户查询架构中,主要包括3种实体,即多个数据拥有者、多个数据使用者和云服务提供商.

图1 云环境下强隐私保护的排序查询架构Fig. 1 Sorting Query Architecture with Strong Privacy Protection over Cloud Data
为了保证数据的机密性,对于外包给云的数据集合F={F1,F2,…,Fn},数据拥有者采用语义安全的对称加密算法Encek()加密文件Fi,采用单向哈希函数H计算文件Fi的文件标识号IDFi,用Wi={w1,w2,…}表示文件Fi的查询关键字集合,用户通过Wi中的关键字查询文件Fi.为了能够让授权的数据使用者查询加密文件,数据拥有者利用文件Fi的查询关键字集合Wi为Fi建立一个安全索引Ii,要求敌手不能通过Ii推测出任何有关Fi和Wi的明文信息.最终的密文集合用C={Ci=Encek(Fi),H(IDFi),Ii|i=0,1,…,n}表示,Ci表示文件Fi的密文.最后,数据拥有者将C外包给云服务提供商存储.
当数据使用者查询文件时,为了保护隐私,他加密查询关键字生成查询陷门TRDu后提交给云服务提供商.云服务提供商接收到授权用户提交的TRDu后开始执行查询,并对结果进行相关性排序,根据请求的文件数量返回top-k个密文给数据使用者.数据使用者用解密算法Deek(·)在本地进行解密,最终得到明文文件.整个过程中,云服务提供商仅仅知道哪些密文作为结果被返回,除此之外云无法获取文件和查询的任何明文信息.
2.2 威胁模型
云环境下,典型的基于隐私保护的密文查询架构中,云服务提供商作为诚实而好奇的半可信敌手模型,原则上它遵循数据托管和安全协议,正确合理地处理数据,但无法排除其恶意推测外包数据内容和恶意分析用户查询请求的可能性.本研究除了讨论云服务提供商这种典型的敌手模型,还将考虑具有更强攻击能力的合谋攻击模型,即云服务提供商勾结一个恶意的数据拥有者或一个妥协的数据使用者对其他数据使用者的查询关键字进行合谋攻击,达到秘密探查授权用户查询隐私的目的.图2示出了2种攻击模型.在攻击方式上,采用广泛使用的已知密文攻击和已知背景知识攻击方式[13,15],且整个系统要求达到已知背景知识攻击下的安全性.
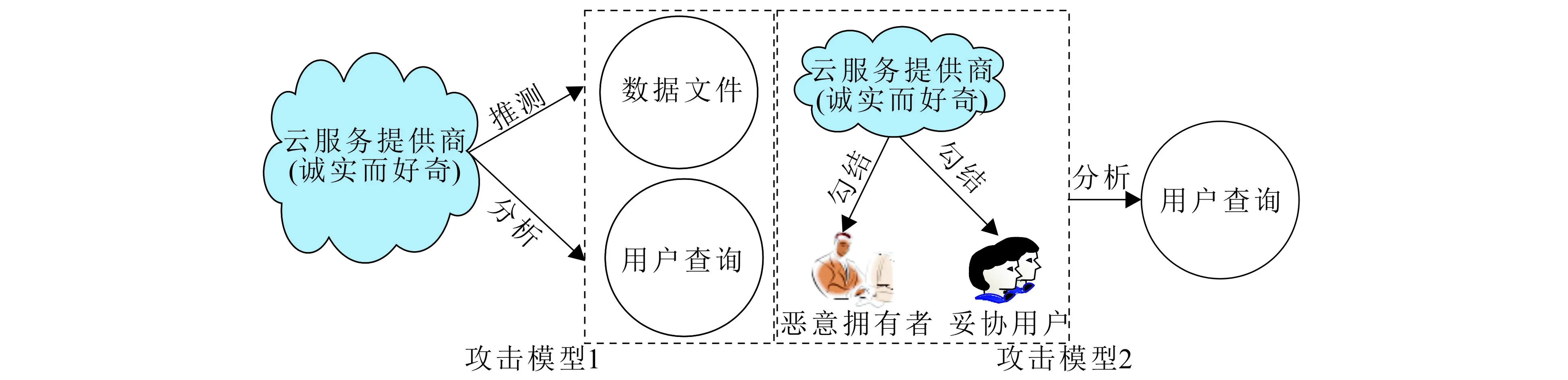
图2 威胁模型示意Fig. 2 Threat Model
2.3 相关知识
为了实现合谋威胁模型下的强隐私保护安全查询方案,需要2个基本安全知识,即双线性映射和双线性Diffie-Hellman问题(Bilinear Diffie-Hellman Problem,BDHP)困难性假设.
(1)双线性映射.
若G1和G2是阶为大素数p的乘法循环群,映射e:G1×G1→G2为双线性映射,则e具有如下性质:
(ⅱ)非退化性.若g是G1的生成元,则e(g,g)是G2的生成元.
(ⅲ)可计算性.对于∀V,U∈G1,总是存在一个有效的多项式时间算法计算e(V,U)∈G2.
(2)双线性BDHP困难性假设.

3 基于关键字权重的加密排序方案
要实现top-k查询,就要确定查询结果的相关度排序机制.笔者根据查询关键字在数据文件中的权重进行排序,权重越大说明文件和查询关键字的相关度越高,越符合用户查询需求.一方面,数据使用者提交查询请求给云,云查询所有满足要求的加密数据文件后,根据权重值在云端进行相关性排序;另一方面,若关键字权重以明文的形式存储在云端,则攻击者在已知背景知识的情况下,可以利用这些权重信息发起统计攻击,达到获取文件内容的目的.因此,权重信息需要作为敏感信息加密以后再外包给云服务提供商.但是,加密数值将失去数值的比较功能,给数值排序带来麻烦.保序加密是一个解决方案,它可以使加密后的数值保持顺序关系,但在具有大量重复数值时,密文无法抵御统计攻击且不适合数值分布动态变化的云环境.笔者将基于一个全同态加密方案实现基于加密数值的排序机制.
3.1 关键字权重的计算
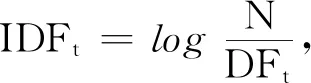

3.2 全同态加密方案
Dijk等[18]提出了一个全同态公钥加密方案FHEnc=(KeyGen,FHE,Evaluate,FHD).这里:KeyGen是公私钥生成算法;FHE是明文空间为{0,1}加密算法;Evaluate是同态运算算法;FHD是解密算法.FHE在计算上能同时满足加法同态
FHE(m1)+FHE(m2)=FHE(m1⊕m2)
(1)
和乘法同态
FHE(m1)×FHE(m2)=FHE(m1×m2)
(2)
的有效运算.
因为FHEnc的明文空间为{0,1},所以可利用FHEnc方案构造一个明文空间为{0,1}*的数值加密方案FHEncS=(KeyGen,FHES,FHDS),且加密后的数值具有比较功能.设整数M∈{0,1}*,用l位二进制表示为M=(m1m2…ml)2,mi∈{0,1}(i=1,2,…,l).算法KeyGen保持不变,FHES和FHDS分别表示为
FHES(M)={FHE(m1),FHE(m2),…,FHE(ml)},
FHDS(M)={FHD(m1),FHD(m2),…,FHD(ml)}.
3.3 安全定义

(ⅰ)挑战者X运行算法KeyGen(k)产生公私钥对(sk,pk),将pk交给敌手A,sk秘密保留.
(ⅱ)敌手A对密文C进行解密查询时,挑战者运行FHD(sk,C)进行应答.当A决定结束查询时,他输出消息m0和m1交给挑战者.
(ⅲ)挑战者随机选择一个比特b∈{0,1},计算密文C*=FHE(pk,mb),C*作为挑战密文返回给敌手A.
(ⅳ)敌手A继续进行解密查询,但不能询问C*的解密结果,最后A输出一个比特位b′.
(ⅴ)若b′=b,则游戏的输出为1,否则为0.
定义1全同态公钥加密方案FHEnc=(KeyGen,FHE,Evaluate,FHD)是满足IND-CCA的公钥加密方案,对于任意的概率多项式时间的敌手A,对给定的安全参数n,存在可忽略的函数negl,满足
3.4 加密数值的比较算法
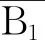
ri-1=ai×bi∨(ai⊕bi)×ri,
(3)
ci=ai⊕bi⊕ri.
(4)
从i=l,rl=0开始,循环求出B1,B2各个二进制位相加的结果ci和进位ri-1,直到i=1时可得(c1c2…cl)2,最后计算r0并让进位c0=r0.
给定任意比特位b1,b2∈{0,1},它们逻辑或(∨)、按位异或(⊕)和乘法(×)运算的值见表1.利用表1构造等式b1∨b2=(b1⊕b2)⊕(b1×b2),于是(3)式变换成

表1 2个比特位的逻辑或、异或和乘法运算Table 1 Logical OR,XOR and Multiplication of Two Bits
ri-1=ai×bi∨(ai⊕bi)×ri=((ai×bi)⊕((ai⊕bi)×ri))⊕
((ai×bi)×((ai⊕bi)×ri)).
(5)

(ⅰ)用FHE加密(4)式.根据(1)式,有
FHE(ci)=FHE(ai⊕bi⊕ri)=FHE(ai)+FHE(bi)+FHE(ri).
(ⅱ)用FHE加密(3)式.根据(1),(2),(5)式,有
FHE(ri-1)=FHE(ai×bi∨(ai⊕bi)×ri)=FHE(((ai×bi)⊕((ai⊕bi)×ri))⊕
((ai×bi)×((ai⊕bi)×ri)))=FHE((ai×bi)⊕((ai⊕bi)×ri))+
FHE((ai×bi)×((ai⊕bi)×ri))=FHE(ai)×FHE(bi)+
(FHE(ai)+FHE(bi))×FHE(ri)+FHE(ai)×FHE(bi)×
((FHE(ai)+FHE(bi))×FHE(ri)).
提取最高位有效位FHE(c0),若c0=0,则FHES(B1)≥FHES(B2),否则FHES(B1) 对于一个查询Q和用户需要云返回的文件数量Request_Num,利用Q在文件中的权重实现文件的相关性秘密排序,并利用秘密排序函数Sec_Rank实现排序功能.将排在前Request_Num位的数据文件返回给用户,且不会向云端泄露任何关键字权重和数据文件的明文信息.Sec_Rank的主要实现细节如下: 对于查询Q,若文件F1和F2是Q的查询结果,则从F1和F2的安全索引中分别提取它们关于Q的加密权重值,用FHES(W1)和FHES(W2)表示,然后执行如下操作: (ⅳ)V=FHD(FHE(w0)). (ⅴ)若V=0,则将文件F1排在F2的前面,表示F1相对于F2对Q更相关;若V=1,则将文件F2排在F1的前面. (ⅵ)内存销毁. Sec_Rank经编译以后,供云服务商调用完成排序. 强隐私保护的安全top-k查询方案(Secure Top-kQuery Scheme with Strong Privacy Protection,STQSSPP),由以下5个概率多项式时间算法组成:SetUp是整个查询方案的参数初始化算法,由系统调用完成;数据使用者调用KeyGen生成公钥和私钥对;数据拥有者调用BulidIndex为外包数据文件建立可查询安全索引;Trapdoor算法由授权用户调用,加密查询关键字达到隐私保护的目的;云服务提供商接受用户提交的查询陷门运行Query,实现在云端的top-k安全查询,并将查询结果返回给最终用户. STQSSPP的实现细节如下: (3)BulidIndex(Wi,FIDi).数据拥有者为数据文件Fi建立安全索引,Wi表示文件Fi的查询关键字集合,FIDi表示文件Fi的唯一标识号. (ⅰ)数据拥有者生成大小为m的数组BFi和SFi,BFi作为布鲁姆过滤器用于插入Fi查询关键字,SFi存放各个查询关键字在Fi中的加密权重.初始,它们的所有位被置为0. (ⅱ)对Wi中的每一个查询关键字w作如下处理: (a)利用哈希函数H3和双线性对运算e编码w,计算e(H3(w),g1). (b)将编码后的关键字w和Fi进行关联,计算Iw=H2(e(H3(w),g1))⊕H2(FIDi). (c)插入Iw到位数组BFi中,利用哈希函数族H中的k个哈希函数计算h1(Iw),h2(Iw),…,hk(Iw),再将数组BFi的这些相应位置为1. (d)计算w在文件Fi中的权重并转化为正整数SFi,w,用FHES加密算法对SFi,w进行加密得到FHES(SFi,w),将它存储到数组SFi的(h1(Iw)⊕h2(Iw)⊕…⊕hk(Iw)) modm位置中,即 SFi((h1(Iw)⊕…⊕hk(Iw)) modm)=FHES(SFi,w). (ⅲ)将BFi和SFi共同作为Fi的安全查询索引,即Ii=(BFi,SFi),对F中的所有文件做以上处理后,将密文数据集合C={Ci=Encek(Fi),H2(IDFi),Ii|i=0,1,…,n}外包给云服务提供商. (5)Query(TRDu,Request_Num).云接收用户提交的查询陷门TRDu后进行查询,并将查询结果按关键字在文件中的权重排序,返回与查询最相关的前Request_Num个文件给用户. (ⅰ)云接收TRDu后,对每一个密文Ci作如下查询操作: (a)将查询陷门TRDu和Ci的标示号H2(IDFi)进行异或运算,即 (b)利用哈希函数族H计算h1(Qu),h2(Qu),…,hk(Qu),若位数组BFi上所有的这些相应位都为1,则Ci是Qu的一个查询结果.若Ci是查询结果,则需要访问数组SFi,取出Qu中的关键字w在文件Ci的权重,以便在云端进行文件相关性排序.用SFi,Qu表示查询Qu中包含的关键字w在数据文件Fi中的密文权重,它的值可以从数组SFi中获取,即SFi,Qu=SFi((h1(Qu)⊕…⊕hk(Qu)) modm). (c)将Fi的密文和SFi,Qu加入到结果集合中:Result←Result{Encek(Fi),SFi,Qu}. (ⅱ)对Result中的任意2个数据文件{Encek(Fi),SFi,Qu}和{Encek(Fj),SFj,Qu}调用排序函数Sec_Rank(SFi,Qu,SFj,Qu)进行排序,将权重较大者排在前面,表示它与查询Qu的相关性更大. (ⅲ)云将前Request_Num个文件返回给用户,用户利用数据所有者授权的加密密钥ek在本地解密,获取明文文件. 定理1假设用户提交的TRDu中包含的查询关键字为w,若文件Fi的查询关键字集合中存在一个关键字w′,满足w=w′,则STQSSPP能正确返回密文Encek(Fi). 证明已知w′是Fi的一个关键字,数据拥有者为Fi构建索引时,先计算Iw′=H2(e(H3(w′),g1))⊕H2(FIDi),再利用哈希函数族Η将Iw′插入到位数组BFi中去.当云收到TRDu后,云执行运算 并利用Η的各个哈希函数计算Qu,再检查BFi所有的这些位置是否都为1. 若陷门TRDu中的查询关键字为w,且满足w=w′,则文件Fi是查询的正确结果,因为云收到TRDu后执行如下运算: 若w=w′,则Iw′=Qu,从而云根据Qu在BFi上执行查询后能正确返回密文Encek(Fi).证毕. 根据(1)式,有 从索引构造算法和查询陷门生成算法的实现方式可知,在已知密文攻击模型下STQSSPP是安全的.但在已知背景知识的攻击模型下,H2是一个确定性单向哈希函数,敌手利用领域知识、关键字统计信息、历史查询结果等背景知识就能对安全索引进行字典攻击和统计分析,为了弥补这一安全缺陷,可以采用伪随机函数PRF:{0,1}*×{0,1}rk→{0,1}s代替H2,而不会影响查询的正确性.此时,外包给云服务提供商的加密数据集C={ci=Encek(Fi),PRFrk(IDFi),Ii|i=0,1,…,n}.如果采用PRF函数,那么数据拥有者需要将密钥rk和文件解密密钥ek一并发送给授权用户,数据使用者提交如下查询陷门让云执行秘密查询操作: 在实际应用中,用HMAC-SHA1或HMAC-MD5实现伪随机函数PRFrk(·).另外,数据文件的安全性由语义安全的对称加密方案Enc和密钥ek保证,不是本研究的重点,故不做论述. 现利用文献[7]中的证明方法来证明STQSSPP的语义安全性.在证明之前,先给出几个基本概念: (ⅰ)历史(History)H:一个历史H可以看成是在文件集合上的一次查询请求序列,如数据使用者提交一个具有q个查询关键字的集合Wq={w1,w2,…,wq},在文件集合F上执行查询,表示成一个历史H={F,Wq}.文件集合F中的文件包括的信息有数据文件本身、文件标识号FID及文件F的查询索引I. (ⅱ)视图(View)V(H):一个历史H的视图V(H)可以理解成H的密文形式,敌手只能看到H的视图V(H),而不能掌握H的任何明文信息.用C(F)表示F和所有文件标识符的密文集合,用C(I)表示F的密文索引集合,用C(Wq)表示Wq的密文,于是历史H的视图表示为V(H)={C(F),C(I),C(Wq)}. (ⅲ)踪迹(Trace)Tr(H):一个历史H的踪迹Tr(H)可以看成关于V(H)的一个查询结果.用Ci表示文件Fi的密文,于是Tr(H)={(Ci,|Ci|)|wj∈Fi∧wj∈Wq,i=1,2,…,n,j=1,2,…,q},云执行查询后仅仅知道密文及其长度. 根据文献[5],假设存在一个概率多项式模拟者S根据V(H)模拟另一个与V(H)具有相同踪迹的集合V*(H)={C(F)*,C(I)*,C(Wq)*},若对于任意的概率多项式敌手不能区分V(H)和V*(H),则STQSSPP是语义安全的. 定理2若PRFrk(·)是伪随机函数,则查询陷门是语义安全的,具有陷门不可区分性. 定理3若PRFrk(·)是伪随机函数,则STQSSPP中的可查询索引是语义安全的,具有索引不可区分性. 证明要证明索引C(I)是语义安全的,只要证明对于模拟者S构造的C(I)*,敌手无法区分C(I)和C(I)*. 因为数据拥有者在构建索引时采用的是伪随机函数PRFrk(·),所以敌手无法获取密钥rk,PFRrk(·)的伪随机性保证没有任何的概率多项式敌手能够区分C(I)和C(I)*.证毕. 定理4令PRFrk(·)是伪随机函数,假设某个数据拥有者将密钥rk泄露给云或云勾结一个妥协的数据使用者,对授权用户的查询隐私发起合谋攻击,则在这种强大的内部攻击模型下,查询陷门仍然是语义安全的,具有陷门不可区分性. 输出C(Wq)*={C(wi)*,i=1,2,…,q}.只要数据使用者u秘密保存私钥sku,u的查询隐私在云掌握rk或勾结任一个妥协的数据使用者的情况下都是语义安全的,这是因为即使给定映射e,H3(wi)sku和aqu=g11/sku·g2,由于BDHP的计算困难性,敌手无法计算密钥sku,所以除了数据使用者u自己之外,其他任何实体都无法获取wi的明文信息.因此,随机的sk*保证了C(Wq)和C(Wq)*是不可区分的.证毕. 定理5若FHEnc是IND-CCA安全的加密方案,则加密方案FHEncS也是IND-CCA安全的,保证了关键字权重的语义安全性. (ⅱ)X从M0和M1中随机选择一个向量Mb,计算密文C*=FHDS(pk,Mb),C*作为挑战密文返回给敌手A. 游戏的其他部分保持不变. 要证明FHEncS是IND-CCA安全的,只需证明对于任意的概率多项式时间的敌手A,对给定安全参数n,存在可忽略的函数negl(n),满足 (6) 证明在游戏中,最终输出的b可能为0或1,根据条件概率和FHE,有 (7) 和 易知当i=0时, 当i=l时, 根据(7)式,有 从而(6)式得证,FHEncS加密方案是IND-CCA安全的,保证了关键字权重在已知背景知识攻击下的机密性.证毕. 所有的文档采用高级加密标准(Advanced Encryption Standard,AES)加密后进行存储,伪随机函数使用HMAC-SHA1.双线性对操作的实现采用JPBC函数库[21],它是基于配对的密码库 (Pairing-Based Cryptography Library,PBC Library)[22]的Java版本,提供所有基于线性对操作的Java接口和函数.实验采用阶为160位大素数的type A椭圆曲线群,它是一个能提供80位安全强度的对称双线性环境. 为了评估STQSSPP的查询执行时间效率,笔者实现了经典的云环境下外包数据查询方案RSSE和MRSE-2.为RSSE预置系统词典且建立加密的倒排索引;在MRSE-2方案中,将每个文件作为一条有d=60个属性的数据,生成一个d′×d′=80×80的密钥矩阵和一个d′=80位的位向量,且生成d′-d=20个随机数作为填充数据向量的元素. 客户端的配置为Intel Core 2 Duo CPU 2.26 GHz,3 GB内存的Windows 7操作系统;服务器端是Intel Core 2 Duo CPU 2×2.394 GHz,有8 GB内存的虚拟机环境,操作系统为centos 5.8. 因为RSSE,MRSE-2和STQSSPP方案在索引构建上机制差异较大,所以无法对它们的索引构建时间效率进行对比.RSSE基于SSE方案采用倒排索引技术,对词典中的每一个关键字建立链表,链表的头节点是预置词典中的一个关键字,链表中的每一个节点包含的信息是文件标识号、保序加密权重及下一个节点的解密密钥等.MRSE-2基于安全k-NN方案构建索引的计算主要包括矩阵转置、取逆及数据向量的生成.STQSSPP为每一个文件建立一个索引,索引中的信息是文件的查询关键字.图3给出了STQSSPP的索引构建时间效率. 图3 密文索引构建时间Fig. 3 Construction Time of Ciphertext Index 从图3(a)可以看出,密文索引的构建时间随着数据中的查询关键字个数呈线性增长,当文件包含60个查询关键字时,构建一条密文索引的时间大约为3.7 s. 从图3(b)可以看出,当文件数量仅为2 000时,整个密文索引集合的构建时间就达近1 h,随着文件数量的增加,这似乎是非常耗时的过程.但其实在许多实际的应用场景中,数据拥有者可以对收集的文件定时定期动态上传,如数据拥有者对每天收集的文件在非工作时间定时上传,这个数据集的规模一般不是很大,实时性要求也不高. 查询时,数据使用者在客户端加密查询关键字后提交给云.图4显示了3种方案的查询构建时间. 图4 查询陷门生成时间Fig. 4 Query Trap Generation Time 从图4可以看出:RSSE和STQSSPP方案的查询陷门生成时间都与查询关键字个数呈线性增长关系,但在相同数量的查询关键字情况下,STQSSPP方案的生成时间高于RSSE,因为1次双线性对操作的计算时间高于2个伪随机函数的加密时间;虽然MRSE-2方案的查询陷门生成时间不受关键字个数的影响,但是当关键字少于20时,该方案的生成时间高于其他2种方案.一般地,数据使用者用12~16个关键字足以表达他们的查询需求.当关键字个数达到20时,STQSSPP的查询加密时间大概是3.2 s,这对数据使用者是可以接受的. 图5(a)示出了当用8个关键字查询时,3种方案在不同文件规模下的查询时间;图5(b)示出了当文件数量为2 000时,3种方案在不同查询关键字个数下的查询时间. 图5 查询执行时间Fig. 5 Query Execution Time 从图5(a)可以看出,MRSE-2方案的查询时间高于STQSSPP.这是因为MRSE-2在查询时要进行相对比较耗时的矩阵和向量内积运算,而STQSSPP只有简单的异或和哈希运算.RSSE方案是一个单关键字排序查询方案,在单关键字查询的条件下,它的运算主要由一个线性查找、一个异或运算和链表中所有节点的解密运算组成.为了实现多关键字查询,需要对每一个关键字进行分别查询,得到多个结果集合,再对这些集合取交集.从图5(a)还可以看出:当文件数量少于600时,RSSE的查询时间优于STQSSPP和MRSE-2,因为当文件数量较少时,每个链表中的节点数量较少,与8个查询关键字对应的结果集合中,包含的文件数量也较少且有可能是空集;而当文件数量不断增多时,RSSE的查询时间将超过STQSSPP和MRSE-2. 从图5(b)可以看出:MRSE-2方案的查询时间不受查询关键字个数的影响,一直保持在155 ms左右;STQSSPP和RSSE方案的查询时间与关键字的个数呈线性增长关系,当使用少于5个关键字进行查询时,RSSE的查询效率最好,但随着查询关键字的增多,RSSE的查询时间将大大超过STQSSPP和MRSE-2;当查询关键字的个数超过16时,STQSSPP的查询时间也将超过MRSE-2. 在进行top-k查询时,为了评估返回给用户的k个查询结果是否都真实反映了查询与文件的相关程度,设Na为结果中应该排在前k位的实际文件数量,Nu为用户需要的文件数量,于是可用 A=Na/Nu (8) 定义相关文件排序机制的准确性.(8)式分子部分表示在查询时有部分应该排在前k位的文件,受排序机制的影响并没有排在前k位,而被排在第k位以后的一些文件取代了. 单关键字查询时,RSSE和STQSSPP方案依据查询关键字在文件中的实际权重值从大到小进行排序,它们总是能返回与查询最相关的前k个文件给用户.当进行多关键字查询时,RSSE使用保序加密方案,无法综合考虑多个关键字在一次查询中的权重,而STQSSPP利用同态加密特性可以实现查询集合中各个关键字密文权重的重新运算,以更精确的数值表示多关键字查询权重.MRSE-2根据查询关键字向量和文档向量的内积值进行排序,这个内积值仅仅反映查询关键字集合中的元素是否包含在文件中,而没有反映关键字在文件中的出现频次或重要程度,所以查询时将导致大量与查询更相关的文件并没有包含在返回的k个文件之中. 根据用户需要返回的不同文件数量进行分组实验,每组实验都在规模为2 000的数据集合上完成同一个多关键字查询,查询包含8个关键字.查看每组实验返回的结果,并与实际应该返回的文件进行对比,然后计算rank值,得到top-k查询准确率(图6). 图6 Top-k查询准确率Fig. 6 Top-k Query Accuracy Rate 从图6可以看出,STQSSPP总是能正确返回前k个最相关文件,RSSE中包含的相关文件随着用户需要返回文件数量的增加而线性减少,MRSE方案在定义的查询权重下总是只能返回近50%的最相关文件. 表2给出了STQSSPP的正确率(Precision Rate,用P表示)和召回率(Recall Rate,用R表示),它们是信息检索领率中使用最广泛的2个检索评价参数.正确率是返回的结果中相关文档所占的比例,定义为P=N/M,其中N表示返回结果中相关文档的数目,M表示返回结果的总数.召回率是返回的相关文档占所有相关文档的比例,定义为R=N/K,其中K表示所有相关文档的数目. 表2 查询正确率和召回率Table 2 Query Recall Rate and Accuracy Rate % 从表2可以看出:(1)随着查询关键字的增多,查询的正确率有所下降.查询关键字越多,布鲁姆过滤器产生假阳性的可能性就越大,但合适的哈希函数数量可以保证假阳性的概率达到最小.(2)召回率一直保持100%.布鲁姆过滤器不会产生漏判现象,它总是返回数据集合中所有与查询相关的文档. 基于云环境下的数据外包服务模式,笔者设计了一个用户隐私增强的加密数据查询方案.除了典型的半可信威胁模型外,进一步考虑了用户查询的隐私性,构建了攻击性更强的合谋攻击威胁模型,并证明了在此模型下用户的隐私是安全的.STQSSPP方案构造的安全索引具有多项式时间内不可区分性,且支持文件的动态更新,非常适合开放和数据频繁更新的云环境.为了增强用户的查询体验,减少网络传输带宽,设计了IND-CCA安全的数值密文比较方法,实现了能抵御已知背景知识攻击的密文相关性排序机制,满足用户个性化top-k查询的需求.STQSSPP方案不足之处在于,随着查询关键字的增多,密文索引的构建时间随着查询关键字个数呈线性增长,查询的正确率也有所下降.因此,笔者接下来将在满足查询安全性、查询结果的相关性排序的同时,进一步提高查询效率.3.5 相关文件加密排序函数Sec_Rank


4 强隐私保护的安全Top-k查询方案
4.1 方案的设计
4.2 方案的实现
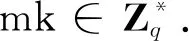
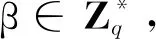

4.3 方案正确性分析
4.4 多关键字Top-k安全查询

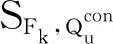
4.5 假阳性分析
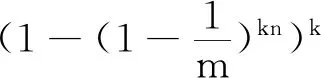
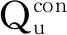
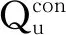
5 安全分析与证明

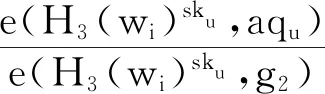





6 实验分析
6.1 实验环境

6.2 索引构建时间效率

6.3 查询陷门构建时间效率
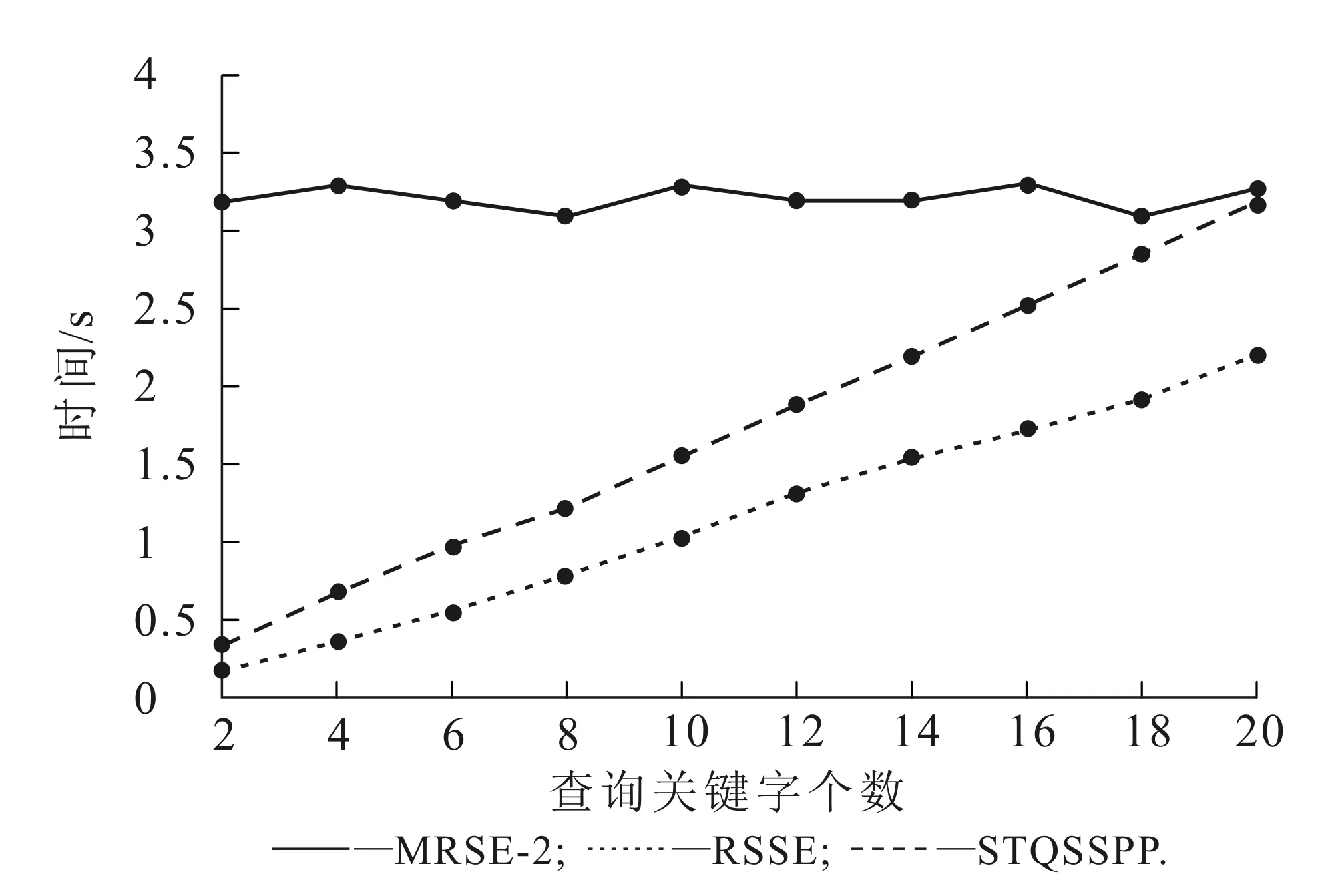
6.4 查询执行时间效率

6.5 查询正确性分析


7 结语
猜你喜欢
华人时刊(2022年1期)2022-04-26
黑龙江大学自然科学学报(2022年1期)2022-03-29
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
计算机仿真(2021年10期)2021-11-19
科普童话·学霸日记(2020年1期)2020-05-08
动漫界·幼教365(大班)(2019年10期)2019-10-28
小天使·一年级语数英综合(2019年2期)2019-01-10
信息安全与通信保密(2016年10期)2016-11-11
深圳大学学报(理工版)(2015年5期)2015-02-28
环球时报(2009-11-25)2009-11-25
