
基于Sine-SSA-BP算法的建筑物制冷量预测
2023-07-03 08:54姚浩然李成鑫郑秀娟
计算机仿真 2023年5期
姚浩然,李成鑫,杨 平,郑秀娟
(四川大学电气工程学院,四川 成都 610065)
1 引言
建筑制冷系统作为建筑物的重要组成部分,能耗占建筑物总能耗的40%~50%[1]。在“碳达峰、碳中和”提出的背景下,提高能源利用效率刻不容缓。研究建筑制冷系统负荷变化趋势,并建立合理的负荷预测模型,是进行能源调度和提高能源利用率的基础[2]。目前,有关建筑物冷负荷预测的方法可分为两类:基于物理模型的预测方法和由数据驱动的预测方法[3]。物理预测模型主要是根据建筑物有关信息,基于热动力学知识,使用EnergyPlus、BLAST、DEST等仿真软件模拟出建筑物内部的能耗。此类方法需要大量建筑物内部的信息,耗时耗力,非常不便。
数据驱动法无需了解建筑物内部复杂的物理机理,只需使用建筑物的历史负荷信息和相关影响因素,通过算法建立两者之间的映射关系来预测未来时刻的负荷。常用的数据驱动预测模型有ARIMA[4]、SVM[5]、BP神经网络[6,7]等。ARIMA模型对平稳性强的序列具有很好的预测效果,但对复杂序列预测精度较低;SVM对于小样本数据有很好的非线性拟合效果,当数据量过大时处理速度缓慢;BP神经网络具有强大的学习功能和良好的非线性函数逼近效果,被广泛应用于冷量预测问题中,但存在过早收敛导致预测精度不高的问题[7]。已有文献提出使用粒子群算法(Particle Swarm Optimization,PSO)[8]和遗传算法(Genetic Algorithm,GA)[9]解决此类问题,取得了一定效果,但仍存在陷入局部最优、收敛速度较慢的问题。
麻雀搜索算法(Sparrow Search Algorithm, SSA)是于2020年提出的一种新型启发式算法,与PSO和GA相比,具有速度快,精度高,参数少等优点,有很强的工程应用潜力[10]。已有文献将SSA应用于图像分割[11]、分布式电源配置[12]、轴承故障诊断中[13],均取得了不错的效果。关于SSA和BP神经网络的结合,现有文献还未有研究。本文提出一种基于SSA优化BP神经网络的冷量预测模型,使用SSA优化BP神经网络的权值和阈值,使其避免陷入局部最优,提高预测的精度;针对SSA存在的种群均匀性不佳的问题,引入Sine混沌映射对SSA的初始种群进行优化,增加解空间的遍历性和稳定性,提高初始解的优度。使用广州某酒店建筑实测冷负荷数据进行实验,并与单一BP模型,PSO-BP和GA-BP对比,验证所提方法的优越性。
2 相关算法
2.1 BP神经网络
BP神经网络[7]是一种多层前馈神经网络,算法通过前向传播得出预测值,再将预测值与实际期望值之间的误差反向传播,不断对权值和阈值进行更新修正,使得预测值逐渐贴近期望值,直至满足精度要求。其从结构上可以分为含单个隐含层的三层结构,以及含多个隐含层的多层结构。隐含层数的增多虽然会一定程度上提高模型的预测精度,但同时也会增加学习的难度和训练时间。基于实际情况,本文使用单隐含层结构,保证精度的同时节约模型训练时间。在确定了隐含层数的前提下,需要确定最佳隐含层节点数,常用如下经验公式确定

(1)
式中l,m为输入和输出层神经元个数,a为1到10之间的常数。在此经验公式的基础上,通过多次实验,取使得训练误差最小的一次实验的隐层节点数作为最佳节点数。
2.2 麻雀搜索算法
2.2.1 标准麻雀搜索算法
麻雀搜索算法启发于麻雀的觅食行为[10]。麻雀群在觅食的过程中分工明确,有寻找优质食物的发现者和尾随其后的加入者。与传统的发现—跟随者模型不同的是,麻雀算法增加了侦察预警机制,选取种群中一定比例的麻雀作为报警者警惕攻击和夺食行为,发现危险则放弃当前食物。通过在D维解空间内不断更新各类麻雀的位置,比较适应度值来寻求更好的位置即求解目标函数的最优解。
其中发现者位置更新如下
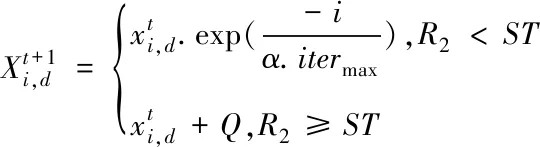
(2)

加入者位置更新描述如下:

(3)
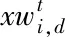
每代种群都会抽取一定比例的个体为报警者,报警者更新描述为
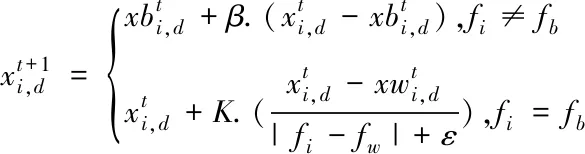
(4)
式中β为服从高斯分布的随机数;fi为当前个体适应度值,fb为当前种群中最优个体适应度值,fw为最差个体适应度值;K为取值-1到1之间的随机数;ɛ为一极小且不为0的数。容易发现,若报警者位于当前最优位置时,其会向最优位置附近逃离,若其不处于当前最优位置会逃至最优位置附近。
2.2.2 Sine混沌映射改进的SSA
包括麻雀算法在内的典型智能启发式算法在初始化种群的过程中均采用随机生成的方式,然而这种随机方式会导致种群内个体的分布缺乏均匀性,不能很好的布满整个解空间,遍历性较差,因而会影响到初始解的质量。混沌系统具有内随机性、普遍适用性和不可预测性,比随机分布方式进行搜索更有优势[14];采用Sine混沌映射对种群进行初始化,其结构简单,易于实现,公式描述为[15]:

(5)
式中,xk为第k个混沌数,k为迭代次数。图1为取a的值为3,进行100次迭代得到的在0到1之间值的分布图。
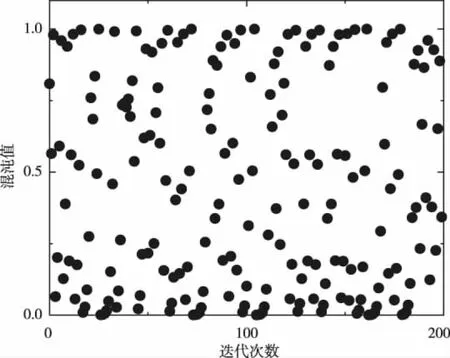
图1 Sine混沌序列分布
可以发现混沌映射后的值分布均匀,因此加入混沌映射能增强个体的遍历性,使得后续搜索寻优过程范围更广,避免过早的陷入局部最优,进而有助于获得更好的初始解,提升算法的精确性和稳定性。
3 模型设计与实现
3.1 模型的输入特征
影响建筑物冷负荷的因素有很多,天气的冷热变化,时间的昼夜交替都会对冷负荷产生影响,此外历史时刻的冷负荷也是参考的关键因素。结合文献[7]和美国能源局在负荷预测时提供的气象参考参数,本文确定的输入特征及其描述如表1所示。表中1-6为气象因素;7-8为历史负荷因素;9-17为时间因素,对各典型日以及一天的各个典型阶段进行One-Hot编码来表征时间的影响。
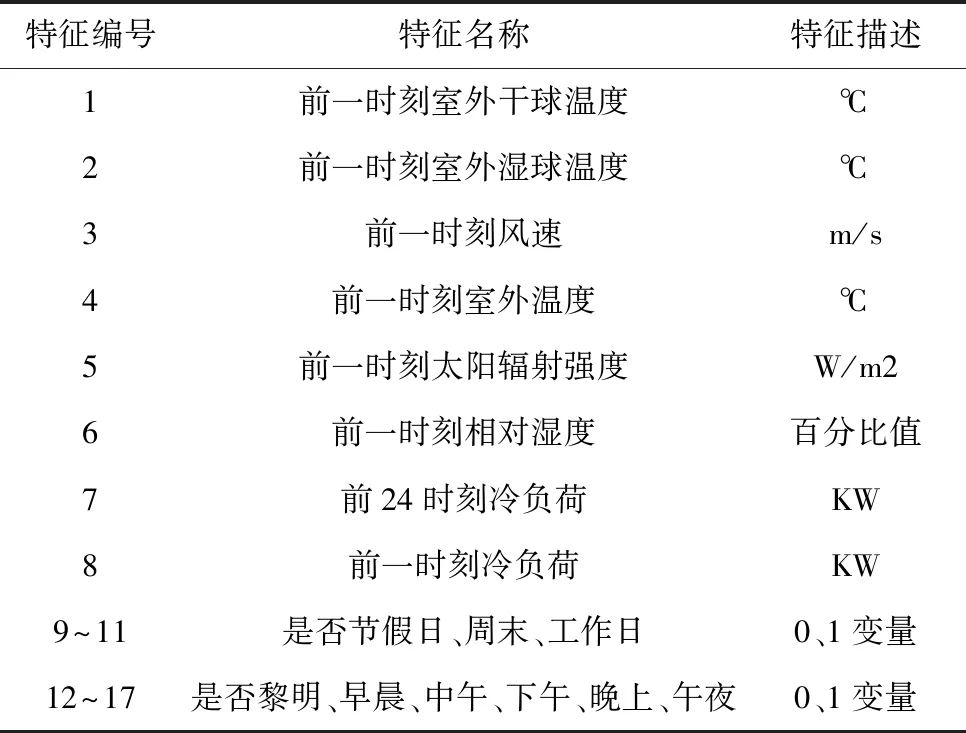
表1 输入特征
3.2 Sine-SSA-BP预测模型
使用Sine-SSA-BP算法对建筑冷负荷进行预测,实际上是利用SSA算法良好的寻优性能迭代寻优,选择适应度最好、精度最高的BP神经网络的权值和阈值。图2为模型的预测流程。
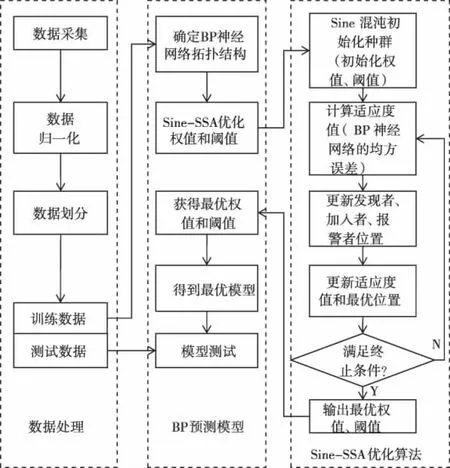
图2 Sine-SSA-BP预测模型
具体步骤为:
1)将归一化后的数据划分为训练集和测试集,根据训练集的训练误差确定神经网络的拓扑结构,并初始化权值和阈值。
2)将权值和阈值作为麻雀算法寻优变量,初始化SSA相关参数,采用Sine混沌映射对麻雀种群位置进行初始化,通过不断更新发现者、追随者的位置找到满足终止条件时适应度最优的一组权值和阈值。
3)BP根据确定的最优权值阈值,构建最终的预测模型,并使用测试集进行验证。
3.3 评价指标
针对构建好的预测模型,基于美国空调与制冷学会ASHRAE所制定的标准[16],采取以下三种指标评估模型预测的精度
1)决定系数

(6)
2)平均百分比误差

(7)
3)均方根误差变异系数
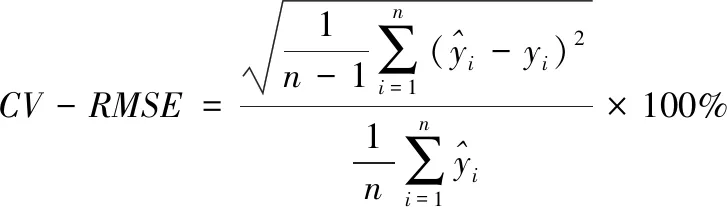
(8)
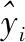
4 实验结果与分析
本文采用广州某大型酒店2020年5月至8月共95天的冷负荷数据,采样周期为1h。该酒店制冷设备包含变频水冷离心式冷水机组2台,水冷螺杆式冷水机组2台,冷冻水泵4台,冷却水泵4台,方形冷却塔8台。预测所需气象数据采用酒店附近气象站的逐时数据。将2280个样本划分为含2100个样本的训练集和含180个样本的测试集。算法运行环境为MATLAB 2019a,各对比实验BP的学习率均设为0.01,麻雀种群数量设置为40,最大迭代次数设置为50,报警者所占比例设为0.2。
4.1 神经网络最佳隐藏节点数。
根据1.1节中经验公式,分别采用不同个数的神经网络隐藏节点进行训练,各次训练误差如表2所示。可以看出当隐藏节点数为11时,训练均方误差最小,因此确定最佳隐藏节点数为11。
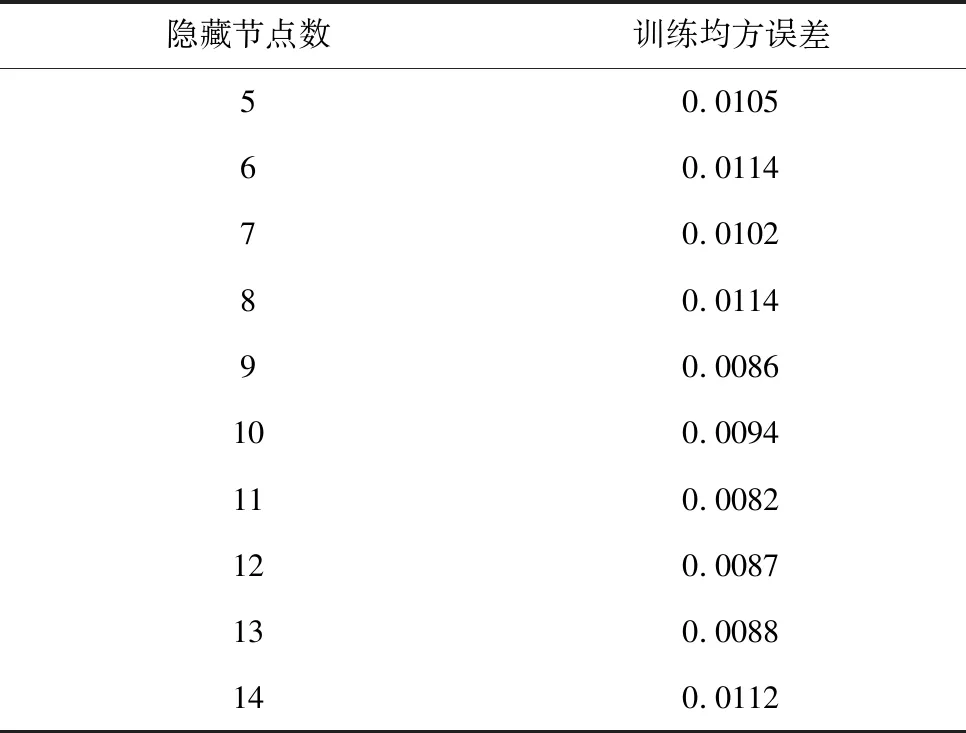
表2 不同隐藏节点数的训练误差
4.2 预测结果分析
分别使用标准BP算法,SSA-BP,Sine-SSA-BP三种算法对该酒店制冷量进行预测,预测结果如图3所示。
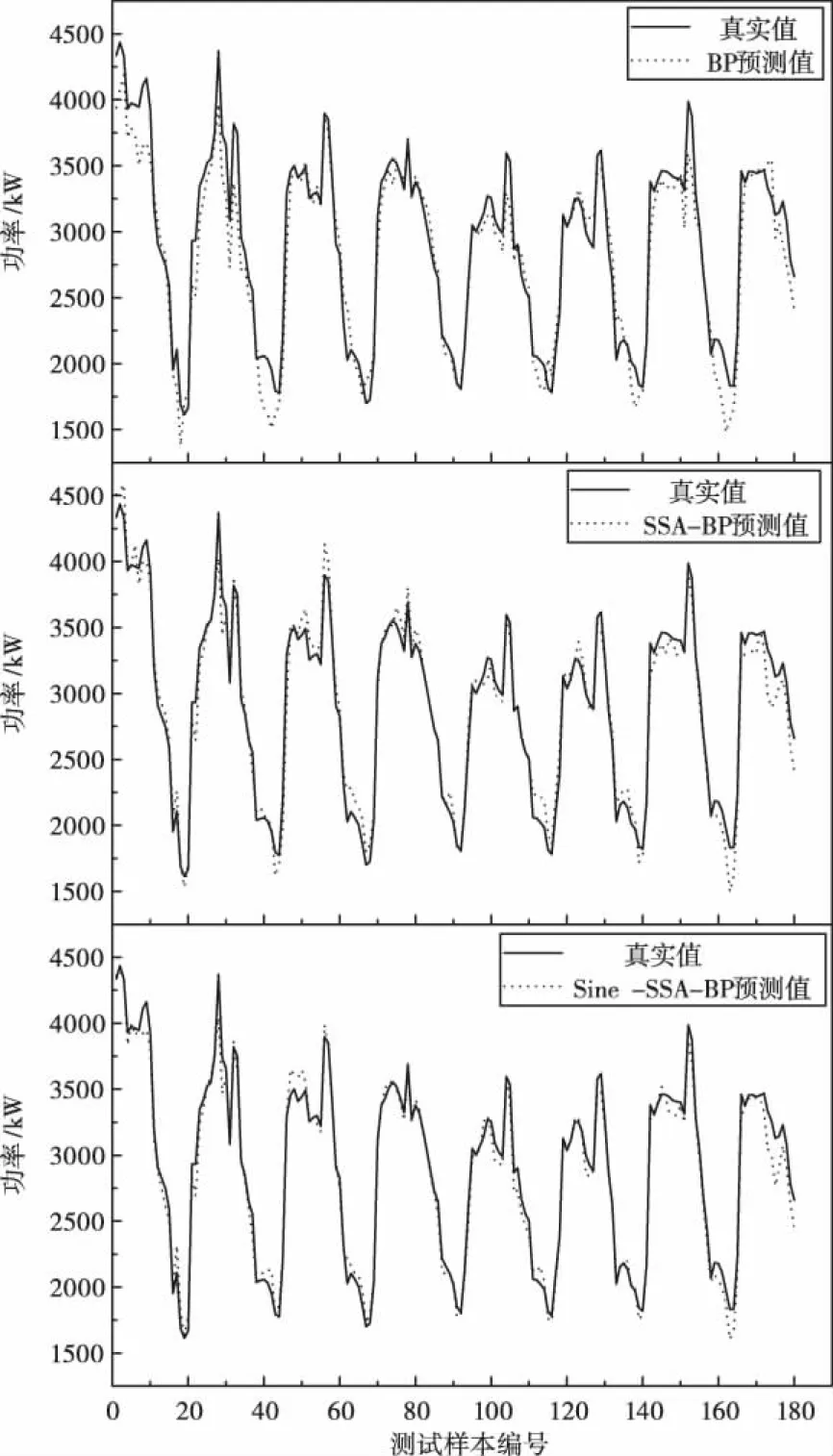
图3 各模型预测曲线与真实曲线对比
由图3可以发现,三种模型的预测结果与该酒店实际制冷量之间的趋势基本一致。标准BP模型预测曲线与真实值曲线之间存在一定的偏差,经SSA优化后的BP模型预测曲线与真实曲线贴合度明显提高,Sine-SSA-BP模型的预测值与真实值则更为接近。
模型的预测误差如图4所示,通过观察误差分布散点图可以发现,标准BP模型误差分布最广,误差最大;Sine-SSA-BP模型误差分布最集中,基本都集中在0刻度线附近,误差最小。观察误差箱型图可以发现,与其它两种模型相比,Sine-SSA-BP模型预测误差箱体最小,误差的下四分位数与上四分位数之间距离最短,表明其预测的稳定性最好,SSA-BP模型次之,标准BP模型最差。
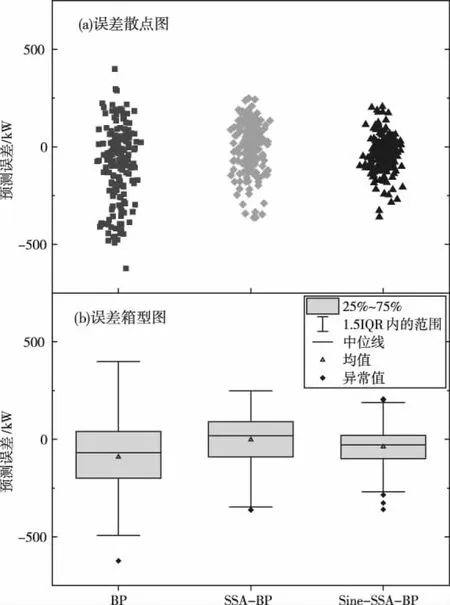
图4 各模型预测误差对比
4.3 模型性能对比
将本文所提模型与遗传算法优化的BP模型(GA-BP)和粒子群算法优化的BP模型(PSO-BP)进行对比,使用3.3节所提评价指标对各模型在测试集中的预测结果进行评价,评价结果如表3所示。可以发现,与标准BP模型相比,PSO-BP、GA-BP、SSA-BP三种模型的预测效果均有提升;其中SSA-BP模型性能为三者中最好,其R2值与标准BP模型相比提高了约0.056,MAPE和CV-RMSE分别降低了2个百分点和1.25个百分点,说明SSA的寻优结果优于PSO和GA。与其它四种预测模型相比,使用混沌改进的Sine-SSA-BP预测模型性能最好,其R2为五种模型中最高,相比PSO-BP和GA-BP,分别提高了约0.021和0.019,与SSA-BP相比,提高了约0.011,表明其拥有更好的拟合优度;此外,Sine-SSA-BP模型的MAPE和CV-RMSE均为五种模型中最低,说明其具有更好的预测精度。

表3 模型评价指标对比
4.4 收敛情况对比
使用优化算法对BP的权值和阈值进行优化时,采用BP模型的均方误差作为算法的适应度值,适应度越小表示解的位置越优,绘制各算法的适应度随迭代次数的变化曲线如图5所示。可以发现,与PSO和GA相比,SSA和Sine-SSA收敛速度更快,最终收敛的精度也更高;PSO、GA、SSA的初始适应度值很大,说明其初始解较差;而Sine-SSA使用混沌映射初始化种群,获得了更优的初始解,并且最终收敛的精度也更优。说明加入Sine混沌映射的SSA能够一定程度上提高初始解的质量和最终收敛精度。

图5 收敛特性对比
5 结论
建筑物制冷量的准确预测是建筑能源高效管理的基础。本文在BP神经网络预测模型的基础上,使用混沌映射改进的麻雀搜索算法优化BP神经网络,构建了一种基于Sine-SSA-BP的冷量预测模型。得出如下结论:
1)与单一BP预测模型、PSO-BP、GA-BP相比, SSA-BP预测模型预测精度更好,鲁棒性更好。
2)加入Sine混沌映射的麻雀算法与粒子群算法、遗传算法、标准麻雀算法相比,遍历性更强,初始解的质量更好,最终收敛的精度更优,具有一定的工程应用价值。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
今日农业(2022年15期)2022-09-20
作文小学中年级(2019年10期)2019-11-04
新世纪智能(高一语文)(2018年11期)2018-12-29
红土地(2018年7期)2018-09-26
趣味(语文)(2018年2期)2018-05-26
中国塑料(2016年11期)2016-04-16
山东青年(2016年1期)2016-02-28
当代畜禽养殖业(2014年10期)2014-02-27
教育与职业(2014年16期)2014-01-19
