
面向认知增强的国潮文化资源推荐策略
2023-07-01 12:44安璐陈苗苗郑雅静
图书情报知识 2023年3期
安璐 陈苗苗 郑雅静
1 引言
2018年国潮兴起。从字面解释“国”即中国,或者本土,“潮”即潮流或当下流行元素,国潮指在新兴潮流审美中注入本土传统文化元素,使传统文化与潮流审美结合,从而让人耳目一新的文化现象[1]。党的二十大报告多次提到中华优秀传统文化,指出“中华优秀传统文化得到创造性转化、创新性发展,文化事业日益繁荣,网络生态持续向好,意识形态领域形势发生全局性、根本性转变。”中华优秀传统文化不能停留在书斋和故纸堆中,要与现代社会相结合,实现创造性转化与创新性发展。本文沿用学者对于国潮文化的界定,即包括浓厚的中国特色元素,符合当下流行的审美和艺术设计手法的文化形态。“国潮”成为当下热词,传统文化元素不断被融入化妆品、服装、节目、游戏等[2]。例如,《唐宫夜宴》《只此青绿》等节目以独特的文化形态,利用创新手法保护和传承中国传统文化,一经推出便占据各大社交媒体榜首,成为文化热点。
在文化热点事件中,公众大多是在李普曼所述的“拟态环境”[3]中获取加工后的文化信息,海量的节目视频等构成了影响公众对国潮文化认知的主要刺激源。但是随着热点话题的生成,社交媒体中涌出的海量信息质量良莠不齐,且包含大量同质化信息(刺激源),容易导致公众文化内涵缺失,不利于文化传承发展。此外,由于个体认知系统的有限性[4],公众对于节目中包含的国潮文化信息的认知存在局限性,很难靠自身突破认知障碍。因此,有必要构建国潮文化资源推荐策略,向公众输入更广泛的认知层面的刺激源(文化资源),使公众增强对于国潮文化的认知,从而更好地学习、传承和发扬优秀的中华传统文化。
鉴于此,本研究的目标是通过文化资源推荐提升公众对国潮文化的认知,并提出以下三个子问题:如何构建国潮文化的文化分级大纲?公众对国潮文化的文化认知情况如何?如何构建国潮文化资源推荐策略,以便提升公众对国潮文化的认知?其中,文化分级大纲的构建为分析公众国潮文化认知特点和构建国潮文化资源推荐策略提供基础的文化分类依据;通过大数据实证研究分析公众国潮文化认知情况以揭示公众文化认知的局限性,从而为本文国潮文化资源推荐策略构建的必要性提供动机。
2 理论基础与相关研究
2.1 认知理论
认知是个体认识客观世界的信息加工活动。认知心理学将认知过程看成一个由信息的获取、编码、贮存、提取和使用等一系列连续的认知操作阶段组成的按一定程序进行信息加工的系统[5]。认知策略是指导认知活动的计划、方案、技巧,由于人脑的信息加工能力是有限的,因此需要借助一定的认知策略。但人在接收信息时,大多依靠经验或个人直觉筛选出形成印象的必要信息[6]。皮亚杰的认识结构理论将其称之为“认知图式”,指人脑对信息客体的选择、整合和理解的方式,或者是人们在认知某一事物时人脑中原有的认知框架。这说明人的认知不是对外部客体刺激而做出的简单心理反应。任何来自外部客体的刺激都必须经过“认知图式”,才能产生心理反应,并在此基础上形成主体的认知[7]。皮亚杰在提出“认知图式”的同时,也提出与之密切相关的“同化”和“顺应”概念。它们是主体反映客体刺激过程中必然产生的两种重要机能,刺激输入的过滤或改变叫做同化,内部图式的改变以适应现实叫做顺应[8]。在认知同化学习理论中,奥苏贝尔强调学习内容要对学生具有潜在意义、能够与学生已有的知识结构联系起来,并根据新旧观念的概括水平划分了下位学习、上位学习和并列结合学习三种认知同化模式[9],各模式概念解释如表1所示。
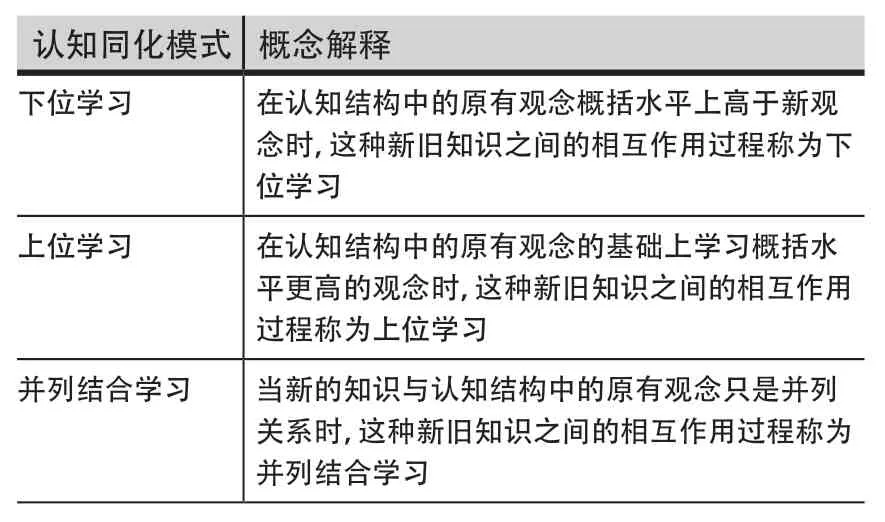
表1 认知同化模式及概念解释Table 1 Cognitive Assimilation Model and Explanation of the Concepts
2.2 文化分类
文化概念较为复杂,为了对文化进行系统性研究,学者们从宏观和微观两个视角探究了文化的结构和层次,以期建立架构清晰的文化分析框架。从宏观视角而言,文化层次构建是关键。其中,又以霍尔(Hall)所提出的公开的文化(物质文化)和隐蔽的文化(精神文化)的文化二分类为关键基础[10]。后续学者又从文化的不同内涵出发,逐步发展出文化分类三要素:文化知识、文化意识、文化技能[11],文化分类五要素:文化产品、文化实践、文化观念、文化社群和文化个体[12],以及文化核心层概念:文化表层、文化中层、文化深层[13]等文化层次分类大纲。尽管文化层次分类多种多样,但是目前国内主流的文化层次分类方式主要采用由冯天瑜先生所提出的文化四层面说,即将文化大纲分为物态文化、制度文化、行为文化和心态文化[14]。该文化层次分类从文化形态学角度将文化视作一个包括内核与若干外缘的不定型的整体,从外而内约略分为四个层次(即物态文化-制度文化-行为文化-心态文化),内层辐射外层,外层反映内层,越靠近内核,文化层次越高,其文化观念的概括抽象水平越高[15]。
从微观视角而言,文化分类主要是对文化大纲进行进一步扩展。例如,周小兵等人从3212册教材中提取五百万字的大规模语料,通过语料标注形成国情、日常、成就、实际、观念五个大类及后续46个子层级[16]。马新钦基于文化四层面说,依据文化的本质属性对“语言中的文化”进行细致分类,形成涵盖大类、小类、子类、文化点、内容举例五级列项树状结构的文化结构[17]。徐绪堪等人通过对红色文化知识元的分类,将红色文化分为本体类、时间类、空间类、事件类等知识[18]。这些研究成果为学者进行文化因素的研究提供了指导框架。
本文为探究公众对国潮文化所关注的不同文化热点,并为后续公众文化认知增强推荐做基础,构建关于国潮文化的“文化大类-文化小类-文化点”三层文化结构的文化分析框架。其中,文化大类主要基于冯天瑜所提出的文化四层面说,文化子类和文化点以马新钦提出的文化大纲为依据,并依照本文数据集进行适当扩展。文化大类层次的定义如表2所示。

表2 文化大类层次及定义Table 2 Hierarchy and Definition of Cultural Categories
2.3 文化资源推荐
尽管推荐系统广泛应用于许多领域,但公共数字文化领域的推荐系统还处于早期发展阶段。互联网中包含着大量的文化资源,包括百科、电子图书和数字博物馆等多类资源,而由于较少进行需求分析,这些文化资源未能充分地被精确推荐给个人。现有相关研究通常借鉴其他领域的推荐算法,一是以协同过滤推荐为基础,考量用户兴趣相似性或者基于用户社交图谱计算用户亲密度,向目标用户推荐邻居感兴趣但目标用户鲜少了解的数字文化资源[19-20];二是以内容过滤推荐为基础,通过建立文化资源数据库,匹配用户偏好和文化资源类型来进行文化资源推荐[21-22],或者利用LDA等语义模型构建标签体系,利用标签相似性进行推荐[23];三是以混合推荐为基础,利用两种及以上的推荐算法,提出如基于标签融合和时间加权的协同过滤推荐算法[24]、基于知识图谱的多目标跨域模型推荐方法[25]、融合多语言和多标准检索策略的语义移动推荐方法[26]等。
虽然关于文化资源推荐积累了若干成果,然而仍存在一些不足。一是对文化资源的推荐仅停留在表层,未涉及更深层次的内容,如用户文化认知。布鲁克斯认知观理论揭示,信息检索不仅是一种简单的物理或机械式的匹配活动,更需要从用户认知视角建立整合认知理论的信息检索策略。二是传统的推荐算法虽然提高了文化资源推荐内容的准确度,但是在一定程度上容易加速信息茧房效应的形成,不利于用户增强文化认知、提升用户文化素养。鉴于此,本研究提出面向用户认知增强的国潮文化资源推荐策略,即根据文化的分层结构,构建用户文化认知兴趣模型和文化资源信息表示模型,然后基于认知同化模式理论,借鉴三种同化模式构建相应的推荐策略,从而帮助用户有意义地学习,以增强其文化认知。
3 研究设计
3.1 推荐框架
本研究基于内容过滤算法,提出面向认知增强的文化资源推荐方法,总体推荐框架如图1所示。在采集并预处理多个社交媒体平台中关于国潮文化《唐宫夜宴》和《只此青绿》的文本内容后,推荐总体框架分为两部分进行:第一部分涉及国潮文化大纲的建立,即对来自所有平台预处理后的文本内容进行候选文化属性词抽取和文化属性词的确定,进而构建文化层次和文化主题的映射体系;第二部分涉及推荐方法的设计,以第一部分获得的文化大纲为基础,采用TextRank方法实现微博用户文化兴趣主题揭示和文化资源主题特征表示,并从匹配用户文化主题偏好和增强用户认知两个角度构建推荐策略。
3.2 文化层次—文化主题映射体系构建
文化是人类交流时普遍认可的能传承的意识形态,因此可通过语料了解到公众对于文化的认知程度。文化点,亦为文化主题,指能具体表现这些意识形态的客观反映,通过语言中的文化词汇可以找出涉及的文化点(文化主题)。从文化分类的微观视角,可以找到每个文化点所属的文化层次,进而揭示社交媒体中用户讨论的文化主题分布。本文以冯天瑜和马新钦的文化大纲为依据,利用各社交平台公众交流中涉及的文化词汇,构建关于国潮文化的“文化大类-文化小类-文化点(文化主题)”的文化层次—文化主题映射体系。该过程具体包括三个步骤:候选文化属性词抽取、候选文化属性词表示与聚类和文化层次—文化主题映射体系确定。
(1)候选文化属性词抽取
首先对文本内容进行分词和去除停用词处理。本文使用Jieba分词工具对文本做分词处理,并综合使用中文停用词表、四川大学机器智能实验室停用词表、百度停用词表、哈尔滨工业大学停用词表以及spacy定义的停用词表,去除文本中的停用词。
然后抽取候选文化属性词。在识别属性词时,研究者常采用从文本数据中抽取高频名词的方法[27-28],认为高频名词往往是真正的关键词汇。而在文化词汇的构成中,除了名词外还包含其他具有实际意义的词性类别,如动名词、形容词、时间词等[29]。因此本文利用Jieba词性标注和词频统计,抽取高频的名词、动名词、形容词、时间词作为候选文化属性词。
(2)候选文化属性词表示与聚类
为表征候选文化属性词,采用FastText对去除停用词后的所有词进行词向量训练,并利用训练好的模型对每个候选文化属性词构建高维向量。FastText模型相较于word2vec模型具有词向量表征生成速度更快的特点并能解决OOV(out of vocabulary)的问题[30],该模型是对skip-gram模型的进一步改进,能获得更加精细的词向量。
为了探究文化属性词所属文化点,本文采用AP(Affinity propagation,相似性传播)[31]聚类算法对候选文化属性词向量进行聚类。AP聚类是一种基于数据点间的“信息传递”图论聚类算法,主要优点是无需预设聚类个数、聚类效果较好并且适用于多种场合[32]。
Digital Cultural Services AP聚类依据的指标是数据之间的相似性,因此,首先利用余弦相似度计算候选文化属性词的相似度,构建相似度矩阵,然后再输入至AP聚类算法中,获取文化属性词聚类情况。
(3)文化层次—文化主题映射体系确定
在构建文化层次—文化主题映射体系时,首先过滤候选文化属性词集中的噪音。噪音包括:①非文化属性类簇,即整个类簇中的词均不是文化词汇;②文化属性类簇中的非文化属性候选词。获得文化属性词集{Cw1,Cw2,……,Cwi}及高频的非文化属性词集{UCw1,UCw2,……,UCwi}。然后为每个文化属性类簇进行命名并总结文化主题[33-34],再依据文化大纲将各个文化主题进行类别标注,在标注过程中可对文化小类进行扩充以适应国潮文化的体系。最终确定社交媒体中关于国潮文化的文化层次和文化主题之间的映射体系。
3.3 基于TextRank的用户文化兴趣建模与文化资源特征表示
传统用户兴趣建模方法多基于用户浏览行为、依赖用户评分信息。随着互联网的兴起,基于用户生成内容的用户兴趣建模技术已较为成熟。因此,本文利用基于文化属性词的权重向量空间模型表示方法,对用户文化兴趣和文化资源特征进行表征,为后续从认知增强的角度向用户推荐感兴趣且高质量的文化资源奠定基础。
为表征文化主题的权重,本文使用TextRank抽取文本中的关键词并计算词权重[35]。TextRank是一种经典的图模型算法,其借鉴PageRank算法思想将文本中词语看作节点,并利用词共现关系建立节点间的图模型。该算法依据文本中词汇的结构信息测度词项重要性,无需训练,简单有效,近年来得到广泛应用。由于用户文化兴趣建模和文化资源特征表示大部分步骤类似,因此本文以用户文化兴趣建模为例,具体步骤如下。
(1)首先聚合同一用户的全部微博博文,然后对文本进行分词和去停用词处理。利用TextRank算法从文本中抽取关键词,并计算每个关键词的权重,计算方法如公式(1)所示。
其中,W(vt)为用户i在关键词t上的兴趣权重,d为学习率(一般为0.85),vt、vs分别表示节点t和节点s,In(vt)表示所有指向节点t的节点,Wts表示节点t和节点s的链接的权重值。
用户的关键词偏好用K={(K1,W(v1)),(K2,W(v2)),……,(Kt,W(vt))}描述。其中,Kt表示第t个关键词,W(vt)为关键词Kt的权重。
(2)为表征用户文化兴趣主题偏好,根据词性对上一步得到的关键词进行过滤,抽取词性为名词、动名词、形容词、时间词的关键词及其对应的权重。然后根据3.2节构建的文化层次—文化主题映射体系,通过计算关键词Kt与文化属性词Cwi的余弦相似度Similarity(Kt,Cwi)来判断用户感兴趣的文化主题,具体计算规则如下:
①如果关键词Kt与文化属性词集中的词语Cwi相同,即Similarity(Kt,Cwi)=1,则将Cwi所属的文化主题作为该用户感兴趣的一个文化主题Tt。
②如果关键词Kt与非文化属性词集中的词语UCwi相同,即Similarity(Kt,UCwi)=1,由此判断该关键词不属于文化属性词,则去除该词。
③如关键词Kt不满足①和②两种情况,则需计算关键词Kt与文化属性词集中每个词语的余弦相似度,找到与关键词Kt最相似的Cwi,即MaxSimilarity(Kt,Cwi)。同样地,计算关键词Kt与非文化属性词集中每个词语的余弦相似度,找到与关键词Kt最相似的UCwi及MaxSimilarity(Kt,UCwi)。当MaxSimilarity(Kt,Cwi)的值大于0.5且大于MaxSimilarity(Kt,UCwi)时,则将Cwi所属的文化主题作为该用户感兴趣的一个文化主题Tt,否则去除该词。
(3)整合用户文化主题向量偏好,用户对第t个文化主题的兴趣权重Interestt计算过程如下:
①如果一个文化主题对应一个关键词,则将该关键词的权重作为该文化主题的初始兴趣权重。
②如果一个文化主题对应多个关键词,则将多个关键词的权重之和作为该文化主题的初始兴趣权重。
③使用最大最小标准化法对初始兴趣权重值进行归一化处理后得到兴趣权重Interestnorm,计算方法如公式(2)所示:
利用向量空间模型将用户文化兴趣表示为{(文化主题1,兴趣权重),(文化主题2,兴趣权重)...},如公式(3)所示:
其中,Tui为用户i的文化兴趣向量,Tt为用户i所关注的第t个文化主题,Interestt为用户i在文化主题Tt上的兴趣权重。
对于文化信息资源的文化特征表示可参考用户兴趣建模的过程,在数据清洗阶段对文化资源进行去重,去除文本长度过小和无价值的文化资源。然后利用TextRank对文本进行关键词抽取,重复步骤(2)和步骤(3)。最终文化资源特征表示为{(文化主题1,特征权重),(文化主题2,特征权重)...},如公式(4)所示:
其中,Dti为文化资源i的特征向量,Tt为文化资源i的第t个文化主题,Weightt为文化资源i在文化主题Tt上的特征权重。
特别地,根据文化主题所对应的文化层次,可进一步计算用户文化层次分布向量Dui和文化资源文化层次分布向量Pti。具体而言,用户文化层次分布向量Dui可表示为{(D1,DInterest1'),(D2,DInterest2'),……,(Dm,DInterestm')},其中Dm表示文化小类m,DInterestm'为该文化小类的权重,由属于该文化小类层次下的用户i感兴趣的文化主题{Interest1,Interest2,...,Interestn}兴趣权重加和后并用最大最小标准化法归一化处理后的值来度量,n为该文化层次下文化主题的数量。同理,文化资源文化层次分布向量Pti可表示为{(D1,DWeight1'),(D2,DWeight2'),…,(Dm,DWeightm')},Dm表示文化小类m,DWeightm'由属于该文化小类层次下的文化资源i的文化主题权重{Weight1,Weight2,...,Weightn}加和后并用最大最小标准化法归一化处理后的值来度量。
3.4 面向认知增强的国潮文化资源推荐模型
基于3.3节获得的用户文化兴趣主题向量(Tui)、文化资源文化主题分布向量(Dti)、用户文化层次分布向量(Dui)和文化资源文化层次分布向量(Pti),本文首先利用余弦相似性,计算用户文化主题偏好Tui和文化资源文化主题分布Dti的相似度(取值范围从-1到1),将相似度大于0的文化资源作为候选推荐列表。其次,基于认知同化理论从认知增强的角度向用户推荐文化资源,具体规则如表3所示。
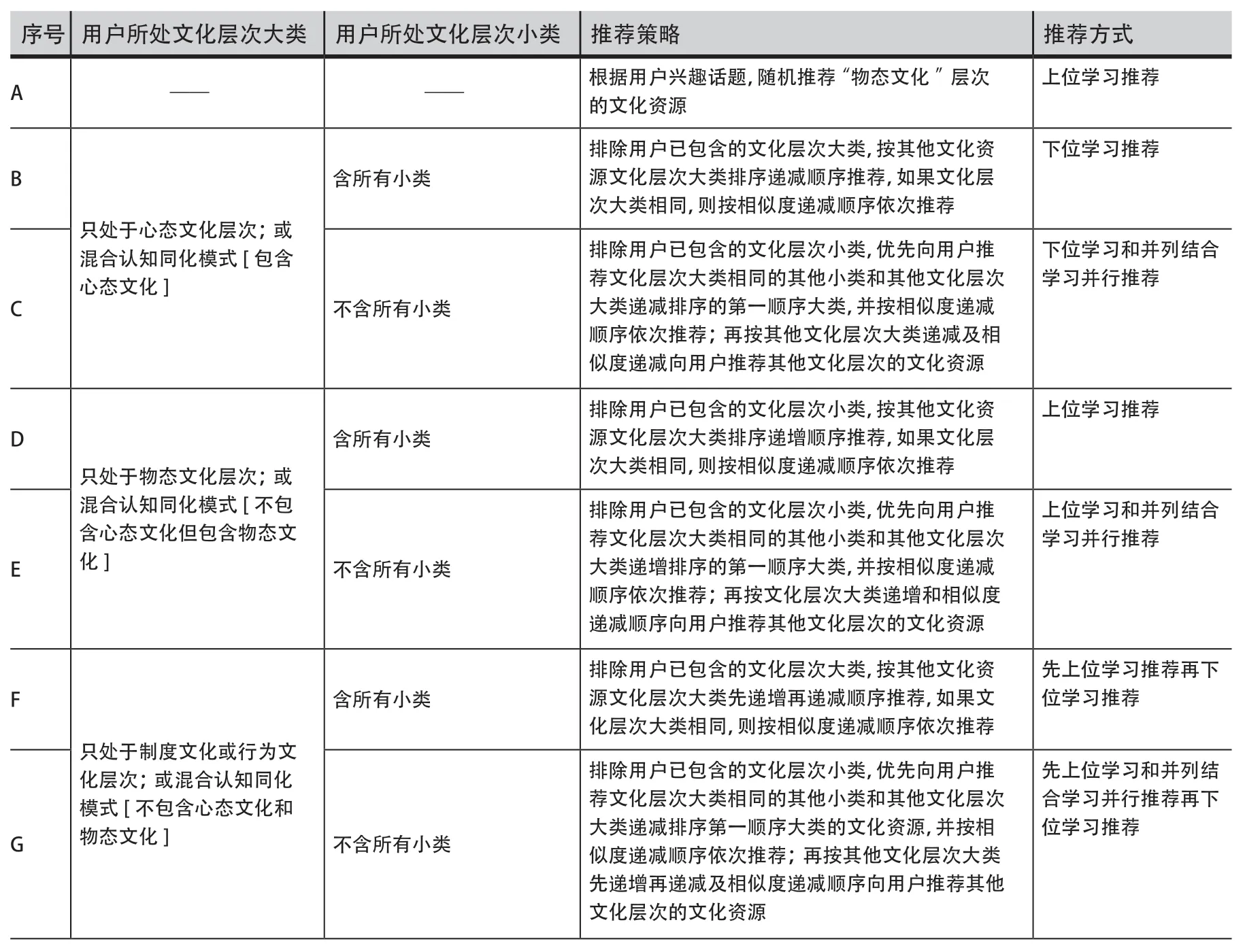
表3 基于认知同化理论的文化资源推荐策略Table 3 Cultural Resource Recommendation Strategy Based on Cognitive Assimilation Theory
需要注意的是,由于用户和文化资源具有不同权重的文化层次倾向(Dui和Pti),因此在向用户进行推荐时,本文考虑了用户及文化资源文化层次权重大于0.5的类别。以序号为B(如表3所示)的推荐策略为例,当用户只处于心态文化层次,即用户文化层次大类权重大于0.5的类别有且仅有心态文化层次,或者用户处于混合认知同化模式[包含心态文化],即用户文化层次大类权重大于0.5的类别至少包含两个大类且其中一类为心态文化时,判断用户所处文化层次小类是否包含其感兴趣的文化层次大类下的所有小类。①对于包含所有小类的,采取“下位学习推荐”方式,按文化资源文化层次大类递减顺序和相似度递减顺序,向用户推荐文化层次权重大于0.5的类别中其他文化层次的文化资源;②若用户所处文化层次小类不包含其感兴趣的文化层次大类下的所有小类,则采取“下位学习和并列结合学习并行推荐”的方式,优先向用户推荐文化资源文化层次权重大于0.5类别中包含文化层次大类相同的其他小类和其他文化层次大类递减排序的第一顺序大类下的任一小类,再按文化资源文化层次权重大于0.5类别中所包含的其他文化层次大类递减及相似度递减顺序推荐其他文化资源。
4 实验及结果分析
4.1 推荐有效性评估实验方案和实验环境
由于本研究主要从认知增强的角度向用户推荐国潮文化资源,因此推荐结果的丰富度和差异性是评估推荐策略有效性的重要指标。丰富度强调推荐结果的覆盖情况,差异性意味着推荐结果是否为用户提供更多认知以外的内容[36-37]。在本文中分别考量推荐结果文化主题丰富度Topical_richnessu i、文化层次丰富度Level_richnessui、文化主题差异性Topical_diあerenceui和文化层次差异性Level_diあerenceui。假设LN(ui)为用户ui的TOP-N推荐列表,四个指标的评估定义如公式(5)到(8)所示:
其中,N为向用户推荐ui的 文化资源个数,Num(Tm)为推荐的第m个文化资源所包含的文化主题个数,Num(T_lm)为推荐的第m个文化资源所包含的文化层次个数,Diあerece(Tm-Tu i)表示推荐的第m个文化资源所包含的文化主题与第i个用户感兴趣的文化主题不同的数量,DiあerenceT_lm-T_l u i表示推荐的第m个文化资源所包含的文化层次与第i个用户感兴趣的文化层次不同的数量。
本研究使用的基准推荐模型是基于余弦相似性排序的推荐算法,该算法计算用户i的文化兴趣向量Tui和每个文化资源文化主题分布向量Dti之间的余弦相似性,并将文化资源按照余弦相似性值的大小进行排序。
然后,利用统计学分析中的配对样本检验,通过比较基准模型所推荐结果的四个指标和本方法所推荐结果四个指标的差异变化,来检验本方法的推荐结果的有效性。如果样本中四个指标符合正态分布,则使用配对样本T检验,否则使用非参数检验方法Wilcoxon秩和检验验证推荐结果的差异性。
本研究的实验环境如下:①硬件环境。CPU处理器:12th Gen Intel(R)Core(TM)i9-12900K 3.20 GHz,内存:64.0 GB,硬盘:5T,操作系统:Windows 11专业版64位。②软件环境。本研究提出的研究方案和实验方案均使用Python语言编写,版本为3.9.12,编译环境为Jupyter notebook。
4.2 数据获取与处理
为尽可能多地获取语料,本文选取国内六大主流社交媒体平台,采集关于《唐宫夜宴》和《只此青绿》两类国潮文化节目的相关内容。采集时间设置为从相关节目第一条微博、视频或文章发布时间至爬虫运行时间。因此,《唐宫夜宴》数据集采集时间为2021年2月9日至2022年10月15日,《只此青绿》数据集采集时间为2021年12月30日至2022年10月15日。各社交媒体平台采集规则和获取的数据量如表4所示,最终获得原始数据约105万条。随后,对获取到的文本数据进行清洗,过滤掉文本中的表情符号、正文中的@及@的用户名、网址、#话题、多余空格等。
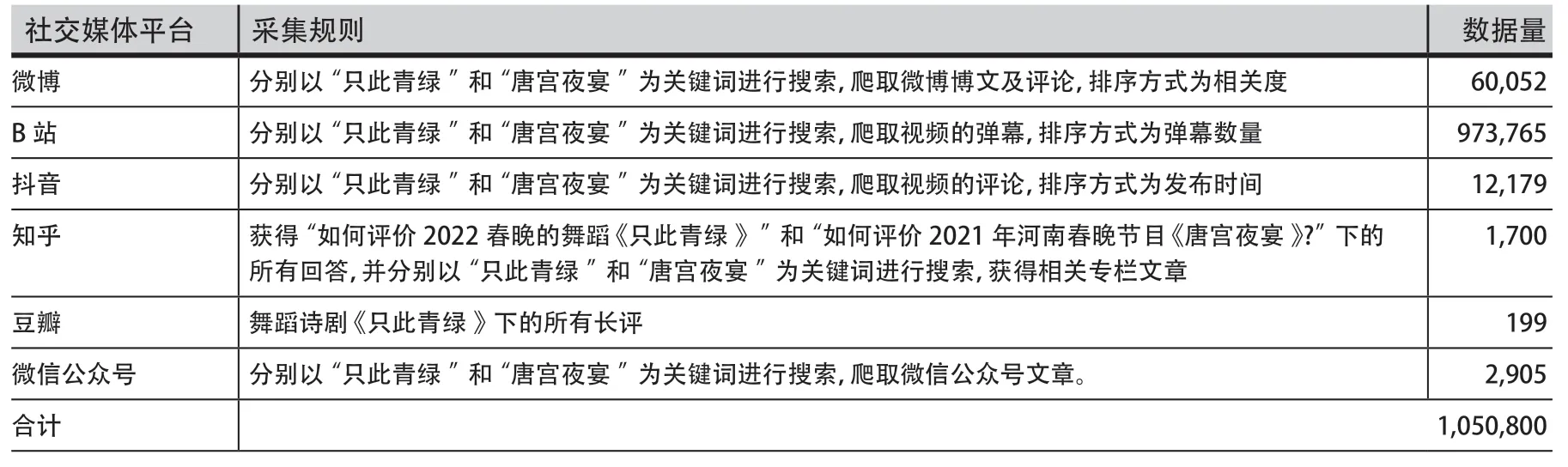
表4 各社交媒体平台及其数据采集规则Table 4 Data Collection Rules for Social Media Platforms
对于来自微博平台的数据,去除空值等无用数据条目,并聚合同一微博用户的博文内容,最终累计获得36,001个用户发布文本数据;对于文化资源数据(来自知乎、豆瓣和微信公众号),通过对文化资源进行去重、去除文本长度小于200且无价值的文化资源,最终获得来自知乎答案的数据242条、知乎专栏数据338条、豆瓣数据188条和微信公众号数据2282条,累计3,050条,然后其进行数值编号。对于来自B站和抖音的数据主要清洗其文本内容,包括去除表情符号、网址、空白符等,并将清洗后的文本作为本研究的补充语料库以训练词向量。
4.3 文化层次—文化主题映射体系
根据3.2节文化层次-文化主题映射体系的构建方法,我们对来自六大平台经过处理后的全部文本数据进行Jieba分词和去停用词处理。具体步骤如下:首先,抽取候选文化属性词。通过词性筛选,本文累计获得76,531个具有名词、动名词、形容词和时间词词性的词语,然后选择词频大于等于100的高频词作为候选文化属性词,累计获得6,868个候选文化属性词。为确保聚类结果,在这些候选文化属性词中筛出2,370个非文化属性词。
其次,表征候选文化属性词并对候选文化属性词聚类。本文对去除停用词的全部语料库进行FastText训练。训练过程中设置上下文扫描窗口为5、最小词频数为5、字符ngram的最小长度为2、字符ngram的最大长度为4、词向量维度为400维,最终获得训练好的FastText模型,并利用该模型表征4,498个候选文化属性词;继而利用余弦相似性构建词与词的相似度矩阵(4498*4498),然后使用AP聚类自动获得492个类簇。
最后,确定文化层次—文化主题映射体系。本文招募两名社交媒体分析方向的研究生对聚类结果进行噪音过滤和类簇命名与文化归类。在类簇命名与文化归类过程中,若存在由个人无法确定的类别命名,则请本领域的学者共同商定类簇命名与文化归类,若存在争议,则以少数服从多数原则确定类簇命名和文化归类。根据冯天瑜总结的“文化四层面说”及马新钦编制的文化大纲,最终确定适用于国潮文化的2,624个高频文化属性词、144个文化点(文化主题)及17个文化层次小类。高频词中不属于文化属性词的被归为非文化属性词集,累计4,244个词。文化层次-文化主题映射体系如表5所示,其中大类和小类中的数字表示编号。

表5 文化层次-文化主题映射体系Table 5 The Cultural Hierarchy -Cultural Theme Mapping System
4.4 用户文化兴趣分布与文化资源特征分布
本文根据3.3节对用户文化兴趣建模和文化资源特征表示的方法获得微博用户和文化资源的文化分布,为清晰展示用户文化兴趣分布和文化资源特征分布,绘制不同文化分类下微博用户和文化资源的数量及占比情况(图2)、微博用户文化主题关联网络(图3(a))和文化资源文化主题关联网络(图3(b))以及微博用户和文化资源包含文化层次小类数量的情况(图4)。其中图3圆点的大小代表含有该文化主题的用户数量或者文化资源数量,边的粗细代表文化主题在文本中共同出现的次数。
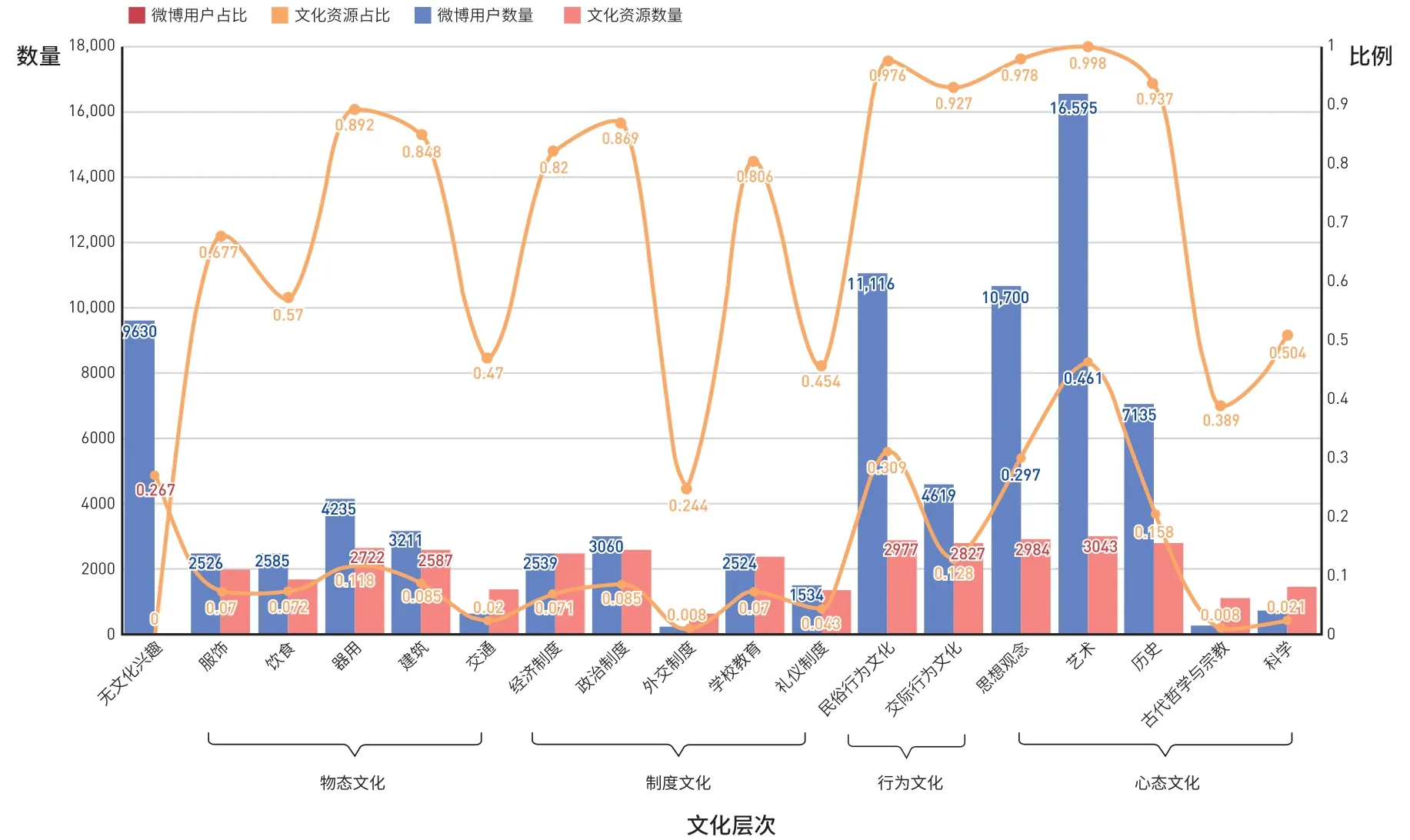
图2 不同文化分类下微博用户和文化资源的数量及占比Fig.2 The Number and Proportion of Weibo Users and Cultural Resources Under Different Cultural Categories

图3 文化主题关联网络(局部图)Fig.3 The Cultural Theme Association Network(Partial View)
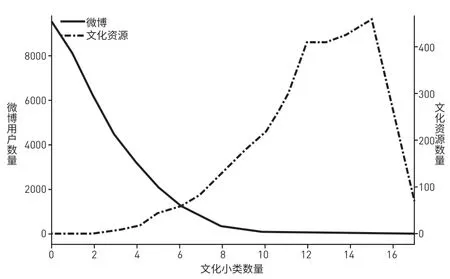
图4 各文化小类数量对应的微博用户数量和文化资源数量Fig.4 Number of Weibo Users and Number of Cultural Resources for Different Numbers of Cultural Subcategories
(1)用户文化兴趣分布特点
从图2中可以看到,①物态文化层次:微博用户对该层次下的文化小类的关注较少,主要关注集中在“器用”文化,占比约11.8%,只有2%的用户对该层次下的“交通”感兴趣;②制度文化层次:微博用户对该层次下的任一文化小类的兴趣都较弱,所有文化小类都仅有不超过10%的用户表现出兴趣;③行为文化层次:大多数用户对国潮文化的行为文化层次的关注远远高于物态文化层次和制度文化层次,有30.9%的用户对该层次下的“民俗行为文化”感兴趣,12.8%的用户关注“交际行为文化”;④心态文化层次:用户对该文化层次的内容极为感兴趣,但兴趣程度不一,约46.1%的用户对国潮文化心态文化层次的“艺术”呈现极为感兴趣,29.7%的用户对心态文化层次的“思想观念”感兴趣,只有0.8%的用户以及2.1%的用户分别对“古代哲学与宗教”与“科学”感兴趣;⑤无文化兴趣:有26.7%的用户展现出了“无文化兴趣”,即文本中不含有任何文化层次的文化点。
通过呈现各文化层次的用户文化兴趣分布情况,不难发现公众国潮文化认知的特点:微博用户对各文化层次的兴趣分布不均衡,相当一部分用户没有文化兴趣,近半数的用户对国潮文化的兴趣集中在较高层次的心态文化和行为文化层次。近半数的用户具有较高层次的文化感知,我们认为,一方面这在很大程度上与《唐宫夜宴》和《只此青绿》国潮文化以舞蹈节目向公众传达中国传统文博美学的呈现方式相关,例如从图3(a)中我们发现大部分用户对心态文化-艺术层次的“舞蹈”“创作”等文化点进行了评价。另一方面,这也体现了这类出圈的国潮文化对公众的教育意义,即激发公众概念水平较高层次的“行为文化”和“心态文化”意识的形成,但这同时也可能促成了同质化的信息环境。
进一步地,从图4不同文化小类数量下微博用户的数量曲线可以看到,随着文化小类数量的增多,微博用户数量呈现先骤减再趋向于平稳的状态,即微博用户对文化小类的关注通常包含0到4个,几乎没有任何用户感兴趣的文化小类超过8个。这印证了人类认知确实存在局限性[4]。因此,向用户推荐具有更广泛文化认知的文化资源以拓展用户对国潮文化关注的范围是必要的。
(2)文化资源文化特征分布特点
文化资源文化特征分布展现出不同特点。从图2看到,同微博用户文化层次兴趣分布相比,文化资源各文化层次类别分布相对较为均匀,尽管一些文化类别(如外交制度、古代哲学与宗教),相对于其他类别的文化层次,被提及得较少,但分别仍有24.4%、38.9%提及率,数量占比较多。特别是,心态文化下的艺术、思想观念和历史以及行为文化层次的民俗行为文化和交际行为文化,至少90%的文化资源都有提及。
从图3(a)微博用户文化主题关联网络和图3(b)文化资源文化主题关联网络可以看到,微博用户文化主题关联网络呈现浅灰色,文化主题连接比较稀疏,并且可以清晰看到一些比较突出的深灰色的线,意味着不同文化主题共现相对不均。相较于微博用户文化主题关联网络,文化资源文化主题的关联网络呈现深灰色,文化主题连接更为紧密,大多数文化主题共现的边展现出相近的灰色,意味着文化主题分布比较均匀。图4虚线部分从另一方面展示了文化资源在文化分布特征上的特点,大部分文化资源涉及的文化小类数量在11到15之间,意味着文化资源会从多个文化认知角度呈现国潮文化的内容,从而能够用于向用户推荐,以拓展用户文化认知关注点。
4.5 推荐结果
由于推荐结果较多,本文仅展示一个例子并显示前三个推荐结果。以某微博用户发表的内容:“《唐宫夜宴》将唐朝少女们的娇憨灵动表现得淋漓尽致,这样的文化输出就应该出圈的呀!看了这场节目,仿佛身临其境般地回到了过去,感慨盛唐的繁荣昌盛!”为例,该用户对国潮文化感知主要在4-15、4-13和3-12文化层次,即“心态文化-历史”“心态文化-思想观念”和“行为文化-交际行为文化”层次。因此将以推荐策略C向该用户推荐文化资源,推荐结果包括:①来自微信公众号的“《唐宫夜宴》出圈记:是谁复活了这群‘唐朝小胖妞’?”,该文章排名前五的主要文化层次包括“心态文化-艺术”“心态文化-历史”“行为文化-民俗行为文化”“心态文化-思想观念”“行为文化-交际行为文化”;②来自微信公众号的“一夜之间火出圈的《唐宫夜宴》,凭什么”,该文章排名前五的主要文化层次包括“心态文化-艺术”“心态文化-历史”“心态文化-思想观念”“行为文化-民俗行为文化”“物态文化-服饰”;③来自知乎答案的关于《唐宫夜宴》内容的评价(https://www.zhihu.com/question/514238732/answer/2331776083),该回答排名前五的主要文化层次包括“心态文化-艺术”“心态文化-思想观念”“行为文化-民俗行为文化”“心态文化-历史”“物态文化-器用”。
4.6 推荐有效性检验
根据4.1节推荐有效性评估方案,本文将推荐列表设置为5,计算基于相似度排序的前5个推荐列表和使用本文推荐策略进行推荐的前5个列表的文化主题丰富度、文化层次丰富度、文化主题差异性和文化层次差异性。由于“无文化兴趣”的用户占比较多,容易造成结果失真,因此在考量本文推荐策略有效性时,去除该类用户。然后利用SPSS软件中的K-S检验判断四个指标是否服从正态分布,结果显示其渐进显著性数值为0.00<0.05,说明四个指标均不满足正态分布,因此本文使用非参数检验方法Wilcoxon秩和检验计算推荐结果的差异性,检验结果如表6所示,其中S表示使用基于相似度排序的推荐策略,Q表示本文的推荐策略。

表6 非参数检验结果Table 6 Nonparametric Test Results
从表6看到,对于文化主题丰富度、文化层次丰富度、文化主题差异性和文化层次差异性四个指标,基于相似度排序推荐方法的均值、中位数始终小于本文面向认知增强的文化资源推荐方法的均值和中位数,而标准偏差则恰恰相反。同时,基于负秩的非参数检验的Z值均为负数且显著性水平0.000远小于0.05,表明相较于基于相似度的方法而言,本文所构建的面向认知增强的国潮文化资源推荐策略能为用户提供涵盖更全面丰富的文化主题和文化层次、更多差异化的文化主题和文化层次的文化资源,从而满足用户“有意义”的学习需求。
5 结论
本文收集和处理国内六大主流社交媒体平台关于《唐宫夜宴》和《只此青绿》两大国潮文化节目的约105万条文本数据,首先抽取高频名词、动名词、形容词、时间词作为候选文化属性词,利用FastText训练词向量及表征候选文化属性词,并基于词向量相似度结果进行词向量AP聚类,最终以冯天瑜和马新钦所提出的文化分类大纲为基础,通过聚类结果命名、筛选和过滤,构建关于国潮文化的“文化大类-文化小类-文化点(文化主题)”三层文化结构的文化层次-文化主题映射体系。
然后,利用TextRank建立用户文化兴趣向量模型和文化资源文化特征向量模型,对用户文化分布和文化资源文化分布进行可视化展现和分析。结果表明公众对国潮文化的认知广泛受到国潮文化呈现方式的影响,主要集中在心态文化和行为文化两大层面。这尽管体现了出圈国潮文化的教育意义,但公众对国潮文化的了解鲜少涉及国潮文化的外缘层面,如物态文化和制度文化等。其次用户文化层次分布不均且文化主题关联也不紧密,表明用户对文化的认知能力确实有限。此外,相当一部分用户表现出了“无文化兴趣”的特征。
最后,本文从认知同化理论出发,构建面向用户认知增强的国潮文化资源推荐模型,并使用非参数检验方法Wilcoxon秩和检验方法从丰富度和差异性两个角度证明了相较于使用基于相似度排序的方法向用户推荐文化资源,本文所构建的推荐策略能够向用户推荐更丰富和多样化的文化资源内容,从而能够帮助用户高效、高质地学习“有意义”的国潮文化,进而提升公众国潮文化认知水平。
本文的理论贡献在于构建基于社交媒体数据分析的文化层次-文化主题映射体系,根据用户文化认知特点,从文化认知增强角度提出用户文化资源推荐策略,丰富了社交媒体内容推荐的研究视角和研究内容。在实践价值上,本研究所提出的推荐策略可以将合适的文化资源推送给用户,方便用户在同质化信息环境中突破自我文化认知局限,从而整体提升用户文化素养,传承发扬中国传统文化。本文的局限性在于仅以两个国潮文化节目为研究对象,所获得的文化主题及构建的文化层次-文化主题映射体系可能具有局限性。未来将扩大国潮文化研究数据,细化文化层次-文化主题映射体系。
致谢:感谢武汉大学历史学院薛梦潇老师对本研究的指导,以及图书情报国家级实验教学示范中心提供的实验支持!
Digital Cultural Services
作者贡献说明
安璐:研究选题及思路制定,指导并修改论文;
陈苗苗:研究方案设计,数据获取、标注与分析,实验开展,论文撰写及修改;
郑雅静:参与研究方案设计,数据获取与标注,论文撰写。
支撑数据
支撑数据由作者自存储,E-mail:chenmiaomiao2020@foxmail.com。
1.陈苗苗.ModelFastNew.bin.FastText 词向量训练模型.
2.陈苗苗.高频词-492.xlsx.聚类结果分析及词集构建.
3.陈苗苗.resources.txt.文化资源文化特征分布结果.
4.陈苗苗.users.xlsx.用户文化兴趣特征分布结果.
5.陈苗苗.simWithProcessALL.xlsx.本文方法的推荐结果.
6.陈苗苗.similarity_withoutProcess.xlsx.基于相似度排序的推荐结果.
7.陈苗苗.图3(a).png.微博用户文化主题关联网络.
8.陈苗苗.图3(b).png.文化资源文化主题关联网络.
猜你喜欢
华人时刊(2023年1期)2023-03-14
吉林广播电视大学学报(2021年4期)2022-01-14
汉语世界(2021年4期)2021-08-27
汽车与驾驶维修(维修版)(2021年6期)2021-08-18
汽车与驾驶维修(维修版)(2021年6期)2021-08-18
汉语世界(2021年1期)2021-02-23
玩具世界(2020年5期)2021-01-14
作文成功之路·小学版(2020年5期)2020-06-11
小天使·一年级语数英综合(2018年11期)2018-11-23
物流技术(2017年4期)2017-06-05
