
基于数据挖掘技术的社区获得性肺炎患病风险预测模型的构建
2023-06-26 03:09苗若琪乔瑞萍ClementYawEFFAH郭诗琦原慧洁谭龙龙苗丽君吴拥军
郑州大学学报(医学版) 2023年3期
苗若琪,乔瑞萍,Clement Yaw EFFAH,郭诗琦,原慧洁,吴 艳,谭龙龙,苗丽君,刘 红,吴拥军
1)郑州大学公共卫生学院卫生化学教研室 郑州 450001 2)郑州大学第一附属医院呼吸内科 郑州 450052
肺炎是一种常见的急性呼吸道疾病,具有高发病率和高死亡率等特点[1],根据发生地点分为社区获得性肺炎和医院获得性肺炎。社区获得性肺炎是指在医院外罹患的感染性肺实质炎症,包括具有明显潜伏期的病原体感染性肺炎,入院48 h内发病的肺炎[2]。研究[3]表明,有许多因素导致肺炎发病率及死亡率增加,其中包括人口老龄化、免疫力下降、诊断不充分、病原体复杂多样和抗菌药耐药等。早期诊断和治疗是社区获得性肺炎的有效干预措施;因此,结合社区获得性肺炎的危险因素及其临床特征建立社区获得性肺炎患病风险预测模型具有重要意义。随着信息技术的快速发展,数据挖掘技术在医学领域得到了广泛应用。Logistic回归可以考察多个因素对因变量的影响并进行预测及判别,支持向量机(support vector machine,SVM)对小样本和高维模式识别数据表现出独特优势,人工神经网络(artificial neural network,ANN)具有良好的鲁棒性和较强的归纳能力,而C5.0决策树具有可读性、分类速度快等优点[4]。该研究拟将社区获得性肺炎常见的危险因素、临床特征及实验室检查指标相结合,分别采用SVM、ANN、C5.0决策树和Logistic回归模型构建社区获得性肺炎患病风险预测模型,并评价4种模型的性能,为社区获得性肺炎的早期诊断及治疗提供依据。
1 对象与方法
1.1 研究对象选取2019年10月至2021年5月郑州大学第一附属医院收治的年满18周岁且诊断为急性下呼吸道疾病的住院患者535例,其中社区获得性肺炎326例(肺炎组),支气管炎209例(支气管炎组)。社区获得性肺炎诊断标准参考《成人社区获得性肺炎基层诊疗指南(2018年)》[5],支气管炎诊断标准参考《急性气管-支气管炎基层诊疗指南(2018年)》[6]。排除标准:结核分枝杆菌感染;非感染性肺间质性疾病;肺水肿、肺不张、肺栓塞、肺部肿瘤、肺嗜酸粒细胞浸润症及肺血管炎等。
1.2 观察指标收集两组患者的资料,包括流行病学资料(疾病诊断、年龄、性别、吸烟史、饮酒史、近期手术史、入院前90 d内是否使用抗生素、疾病史),临床症状(发热、咳嗽、咳痰、呼吸困难、气管分泌物、听诊呼吸音减弱、心动过速、胸痛、胸腔积液)和实验室检查指标(白细胞计数、血红蛋白、红细胞比容、血小板计数、血清钠、血清钾、血清肌酐、总胆红素、C反应蛋白、降钙素原)。总数据集包括22个定性变量和11个定量变量,其中32个为预测变量,1个因变量为疾病诊断结果。变量赋值:支气管炎=0,社区获得性肺炎=1;性别:女=0,男=1;其他定性变量:否=0,是=1。
1.3 统计学处理应用SPSS 21.0处理数据。采用χ2检验或t检验比较两组患者基线特征指标的差异,采用两独立样本t检验或Mann-WhitneyU检验比较两组患者实验室检查指标的差异。检验水准α=0.05。
1.4 4种模型参数的设置和预测性能评价SVM模型的参数设置如下。Mode:Expert;Stopping criteria:0.01;Kernel type:RBF;Regularization parameter(C):3;Regression precision(epsilon):0.1;RBF gamma:0.1;Gamma:4.0;Bias:0.0;Degree:3。
ANN模型的参数设置如下。Method:Prune;Stop on:1.0 min;Set random seed:121;Optimize:Memory;Mode:Expert;Hidden layers:2;Layer 1:35;Layer 2:35;Hidden rate:0.15;Input rate:0.15;Persistence:100;Hidden persistence:6;Input persistence:4;Overall persistence:3;Alpha:0.9;Initial Eta:0.3;High Eta:0.1;Eta decay:30;Low Eta:0.01。
C5.0决策树模型的参数设置如下。Output type:Decision tree; Number of trials:2;Cross-validate:false;Mode:Expert;Pruning severity:70;Minimum records per child branch:2。
Logistic回归模型参数设置如下。Procedure:Multinomial;Model type:Main Effects;Mode:Simple;Multinomial Method:Forwards。
使用SPSS Clementine 12.0将535例患者按照7∶3随机分为训练集和测试集,随机种子数设为4 755 122,其中训练集375例,测试集160例。应用SPSS Clementine 12.0依据训练集数据建立4种预测模型,并对纳入变量的重要性进行排序。基于测试集数据,分别采用准确率、敏感度、特异度、阳性预测值和阴性预测值对4种模型的预测性能进行评价。
2 结果
2.1 基本情况两组患者基线特征和实验室检查指标的比较见表1、2。
2.2 输入变量的选择既往研究[7]提示白细胞计数和总胆红素为社区获得性肺炎的影响因素,故该研究将表1、2中差异有统计学意义的因素及白细胞计数和总胆红素共15个因素作为输入变量,建立社区获得性肺炎患病风险预测模型。

表1 两组患者基线特征的比较
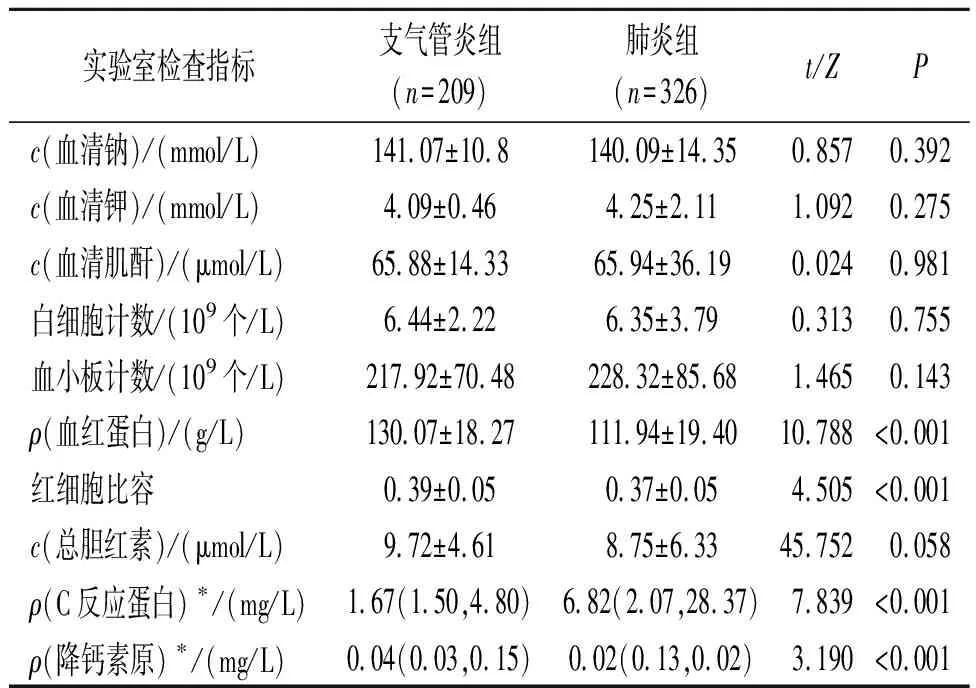
表2 两组患者实验室检查指标的比较
2.3 预测模型的构建和评价
2.3.14种预测模型的构建 4种模型训练集和测试集样本的分类结果见表3。4种模型的预测性能比较见表4。由表4可知,C5.0决策树模型预测性能优于其他3种模型。
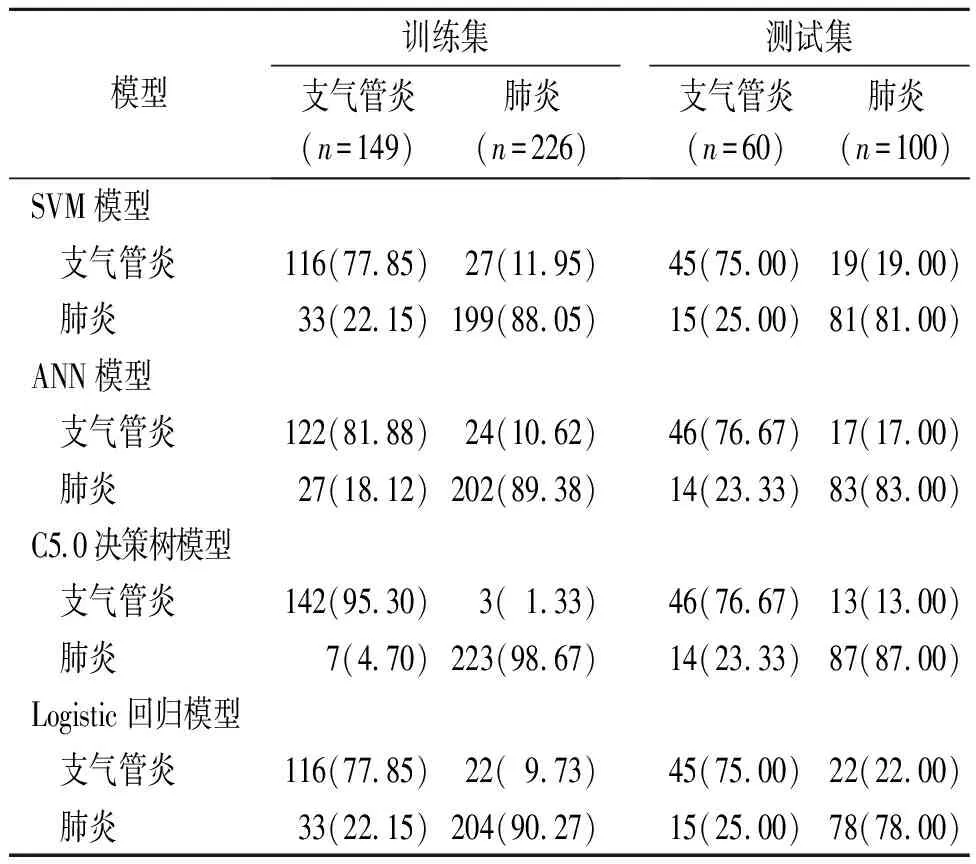
表3 4种模型对训练集和测试集的分类结果 例(%)
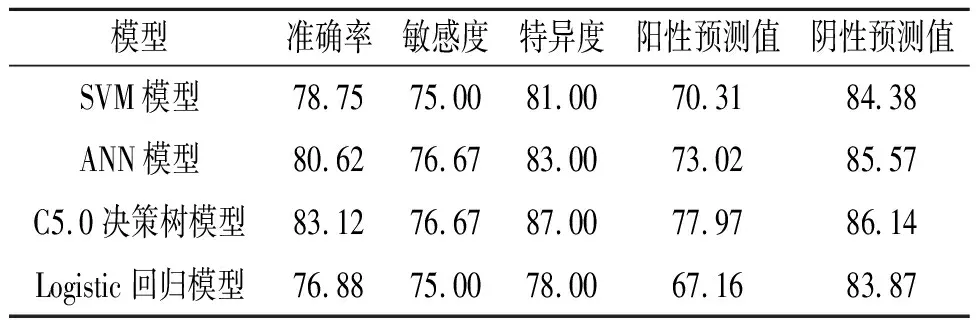
表4 4种模型预测性能的比较 %
2.3.24种模型纳入变量的重要性排序 见表5。
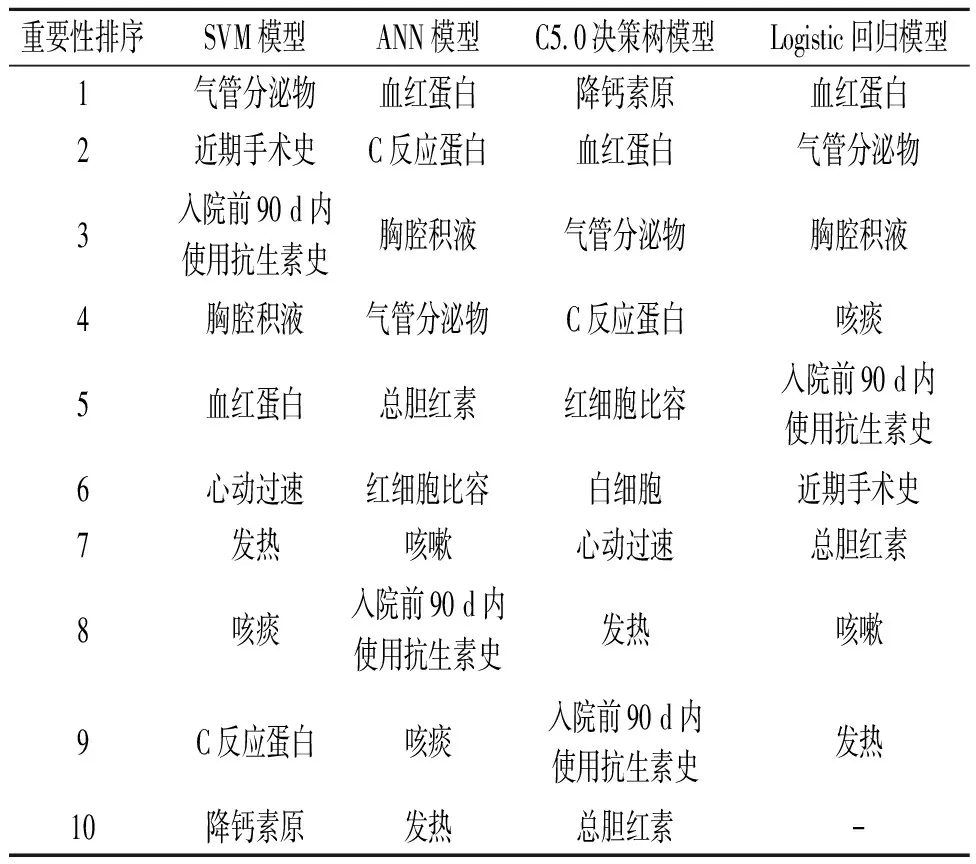
表5 4种模型纳入变量的重要性排序
3 讨论
肺炎是全球高发病率和高死亡率的疾病之一[1]。该研究筛选社区获得性肺炎的相关因素构建风险预测模型,为社区获得性肺炎的早期预防和治疗提供依据。
该研究结果显示气管分泌物、咳嗽和咳痰为重要影响变量。研究[8]表明,患者出现呼吸道症状,如咳嗽、咳痰或呼吸困难应考虑诊断为肺炎。另有研究[9]表明社区获得性肺炎患者伴胸腔积液使住院时间延长、病死率增加。C反应蛋白是细菌感染的标志[10],细菌感染时C反应蛋白水平升高。降钙素原水平升高亦提示存在细菌感染,与社区获得性肺炎患者的预后和疾病的严重程度有关[11]。血红蛋白也是重要的影响因素,既往研究[12]表明,血红蛋白水平随着社区获得性肺炎患者病情严重程度的增加而下降。本研究纳入变量的重要性排序表明气管分泌物、胸腔积液、C反应蛋白、降钙素原及血红蛋白为社区获得性肺炎的重要影响因素,与上述研究一致。
SVM模型主要适用于小样本数据和解决高维度问题,理论基础比较完善,被广泛应用于各个领域。ANN是一种模仿生物神经网络结构和功能的模型,经过训练,生成输入变量加权组合的输出结果,旨在解决各种分类或模式识别问题,具有良好的鲁棒性、高容错性和较强的归纳能力,可以确定潜在的预后影响因素。决策树模型是一种基于预测变量对数据分类的算法,通过分析预测变量得到有关目标变量的结论,可以同时处理分类变量和连续变量。C5.0是决策树模型的常用算法之一,适用于分类变量和大数据集。有研究[13]将C5.0决策树模型与其他模型进行比较,建立糖尿病风险预测模型,均得到C5.0决策树模型的预测性能最优的结果。本研究基于患者流行病学资料、临床症状和实验室检查结果,利用SVM、ANN、C5.0决策树和Logistic回归技术建立社区获得性肺炎患病风险预测模型,结果显示,C5.0决策树模型的预测性能优于SVM、ANN和Logistic回归模型,该模型预测社区获得性肺炎的准确率达83.12%。因此,建议利用C5.0决策树模型鉴别社区获得性肺炎高危人群,为社区获得性肺炎的早期诊断和早期治疗提供参考和依据。
该研究仍存在不足之处。首先,此次纳入研究的样本量还有待扩大;其次,该研究建立的模型仅有训练集和测试集样本,缺少临床样本验证集;再次,社区获得性肺炎的影响因素种类较多,如环境因素、感染细菌的种类、胸部CT等,而该研究纳入的变量种类相对有限。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
医学新知(2019年4期)2020-01-02
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国卫生标准管理(2015年3期)2016-01-15
数学年刊A辑(中文版)(2015年2期)2015-10-30
医学研究杂志(2015年3期)2015-06-10
郑州大学学报(医学版)(2015年1期)2015-02-27
