
公共图书馆文本数据挖掘的著作权风险和出路
2023-06-25 18:06:35余祥聂建强
新世纪图书馆 2023年4期
余祥 聂建强

摘 要 图书馆文本数据挖掘存在侵犯著作权的风险,因此需要探索风险和出路。通过分类讨论法将挖掘过程分为采集阶段、输出阶段。采集构成侵权,根据输出内容是否包含原作独创性表达,使用行为分为“作品性使用”和“非作品性使用”,若“作品性使用”的输出内容包含原作少量独创性表达,属于合理使用,“非作品性使用”不侵权。为规避挖掘的侵权风险,可设置著作权例外规则、建立版权补偿机制、允许对未发表的作品实行“非作品性使用”。
关键词 公共图书馆;人工智能;文本数据挖掘;著作权;合理使用;转换性使用
分类号G258.2
DOI 10.16810/j.cnki.1672-514X.2023.04.005
Abstract Library text data mining has the risk of infringing copyright, so it is necessary to explore the risk and outlet. The mining process is divided into collection stage and output stage by classification discussion. Collection constitutes infringement, according to whether the output content contains original original creative expression, the use behavior is divided into “works use” and “non-works use”. If the output content of “works use” contains a small amount of original creative expression of original works, it is reasonable use, and “non-works use” does not infringe. In order to avoid the infringement risk of mining, copyright exception rules can be set up, copyright compensation mechanism can be established, and “non-published use” of unpublished works can be allowed.
Keywords Public library. Artificial intelligence. Text data mining. Copyright. Reasonable use. Transformative use.
0 引言
当前,通过人工智能文本数据挖掘(TDM)开展科研工作已成为一种必然趋势。TDM可以从海量文本数据中提取所用的信息,然后通过逻辑推导从原始文本数据中总结规律和提炼规则。公共图书馆存储海量的图书文献资源,实施TDM有天然的优势,可以通过TDM来发掘有价值的内容,进而提高智能化管理的水平,提升公共文化服务水平。实践中,图书馆借助TDM可以优化馆藏资源采购建设、评估借阅服务效率,调整馆员服务结构、向读者提供个性化服务。虽然图书馆实施TDM有重要意义,但在TDM过程中存在著作权侵权风险,对文本数据的抽取、复制、传输等涉嫌侵权,致使公共服务与著作权之间产生冲突。虽然图书馆主张利用TDM进行信息采集和分析是用来更好地服务社会公众,但版权方若坚持主张版权,则图书馆进行TDM就必须征求版权方许可。因此,如果不解决侵权问题,有关TDM的侵权纠纷未来或将频发,所以有必要探索图书馆TDM过程中的著作权风险。
1 图书馆TDM在不同阶段的侵权风险
TDM分为采集、输出两个阶段。采集是指人工智能采集、输入文本数据,并在机器中形成可被阅读的复制件,输出是指机器对文本数据进行处理并输出内容。
1.1 采集阶段的侵权风险
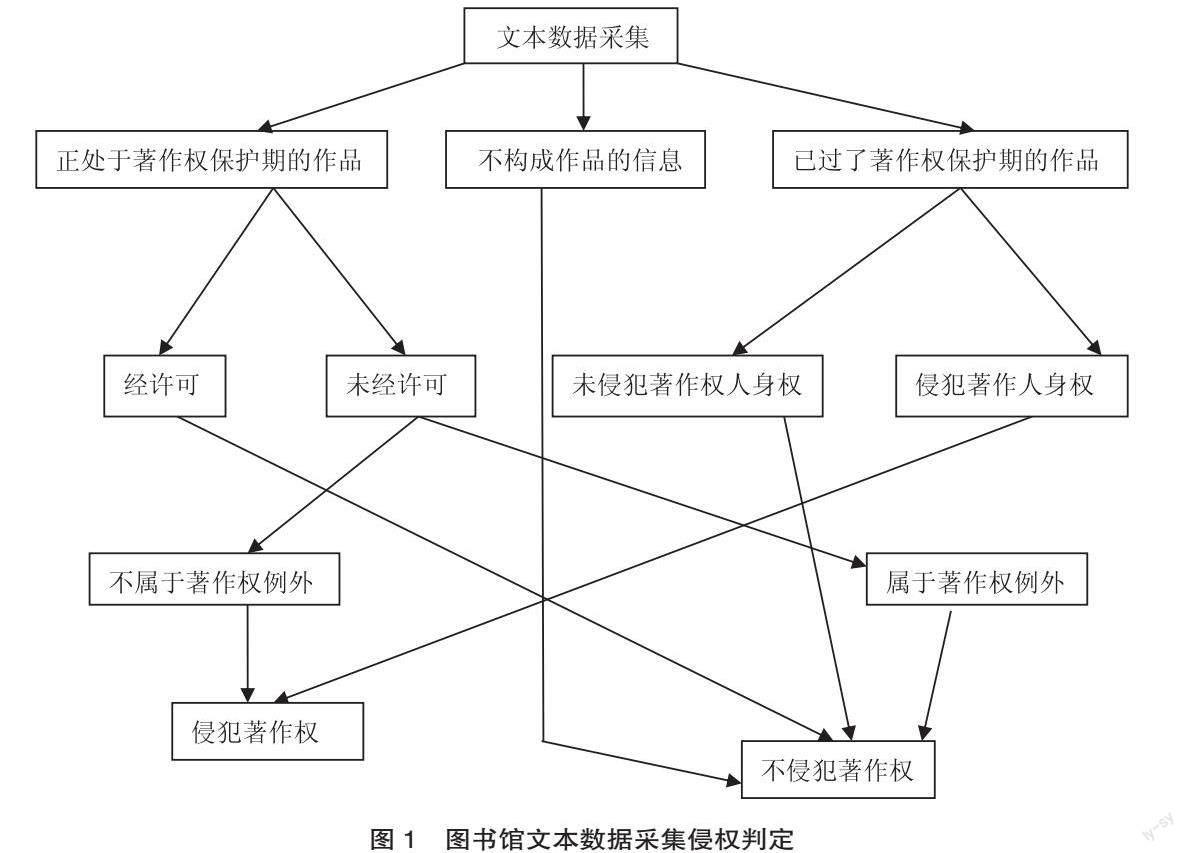
采集阶段的法律风险体现在网络爬取,其目的在于获取源文本数据。人工智能通过网络爬虫爬取网络书籍信息,比如电子书和文学网站,对于网站设置的版权保护装置,爬虫程序可以规避或破译而深入挖掘,然后复制源文本数据,以此实现对文本数据的阅读,进而实现数据训练。人工智能通常对获取的源文本数据进行数字化处理,并将数字信息按照一定模式编排,进而为输出奠定基础。未经权利人许可擅自抓取作品信息涉嫌侵犯复制权。文本数据采集的侵权判定如图1所示。
TDM实现了从“人力阅读”到“机器阅读”,对大量作品信息进行采集意味着对大量作品进行复制,进而实施批量化“阅读”[1]。如图1所示,采集阶段的“复制行为”可能涉及三类文本数据信息:第一类为正处于著作权保护期的作品;第二类为不构成作品的信息,即信息不属于著作权意义上的作品;第三类为已过了著作权保护期的作品。人工智能在采集大量的文本数據前,不太可能全部获得相关权利人的许可,否则会严重影响采集的效率,所以此类“复制”行为涉嫌侵犯复制权。那么这种“复制”是否属于临时复制?如果属于,则豁免侵权,因为临时复制属于豁免侵权的行为。临时复制实质上是短暂性的缓存,必须具备两个要求,即复制的时间很短且没有独立的经济价值,而文本数据采集很难满足这两个要求,因为被采集的信息在转码后会被机器长期存储,机器将来仍可以再次读取,信息也可以再现,此时复制已具备独立的经济价值。况且目前我国《著作权法》尚未将临时复制列为豁免侵权的行为。那么此种复制能否适用合理使用呢?
在2020年新修改的《著作权法》中,合理使用条款仍限于十二种具体情形,之后以“法律、行政法规规定的其他情形”作为兜底条款。当前国内法律予以明确的合理使用的范围有限,目前与采集行为初步符合的,只有该条款第一项或第六项,但仔细研究后发现并不完全符合。该条款第一项“为个人学习、研究或者欣赏,使用他人已经发表的作品”,该条款限定了使用主体,即用于个人,但图书馆进行文本数据采集属于单位行为,而非个人活动,而且进行文本数据采集是为了社会公众,具体来说是为了广大读者,并非为了个人,因此不符合该条规定情形。第六项“为学校课堂教学或者科学研究”必须为“少量复制”,且主体必须为“教学或者科研人员”,图书馆工作人员可视为科研人员,但其采集行为属于大量甚至整体复制,因此图书馆进行采集与该条款第一项和第六项规定情形不符。综上,图书馆进行文本数据采集在新修改的《著作权法》中无法找到合理使用条款作为豁免侵权的法律依据。所以,未经权利人授权的采集可能属于侵权。
1.2 输出阶段的侵权风险
输出阶段,是对文本数据进行处理并输出内容的过程。在此过程中,文本数据被深度开发,实现了知识的累积和价值增长,即知识增值。文本数据挖掘后产生的知识增值,可以被分为两种[2]。第一种为“作品性使用”,是指输出的内容包含原作品的独创性表达,这类使用的目的通常为方便读者检索和阅读或者保存、陈列图书文献。比如:图书馆将馆内图书封面做成缩略图,将馆藏图书进行数字化扫描后制作成图书检索软件,其主要目的在于方便读者进行图书检索,读者在搜索框输入特定词,可以知悉特定词在书中出现的频率,进而提高查找效率;为方便阅读障碍者阅读,图书馆会将原作品数字化扫描后转换为无障碍阅读格式文本;面对图书文献已损毁或濒临損毁、灭失等风险,图书馆会将纸质作品进行数字化扫描以便于存储。第二种为“非作品性使用”,是指基于科研或信息管理目的而对既有作品进行深度分析,挖掘出全新的价值,输出的内容不包含原作品的独创性表达,重在从信息中寻找结论或规律以辅助决策。比如,通过TDM探寻图书类型与图书借阅量数据的关联,预测采购何种类型书籍更受读者欢迎,进而避免采购的图书被闲置。
随着信息技术的发展,大量的文本数据被创造出来,越来越多的网络用户接触文本数据并使用,使得文本数据价值快速上涨,而知识增值行为的实质是基于新用途而不断发掘文本数据的新价值。TDM中产生的知识增值是累积的,文本数据被不同使用者利用,不同使用者对文本数据有不同的使用需求,文本数据在不断流通之中,其价值很难被开发殆尽。在使用文本数据时,使用者会考虑很多问题,如怎样使用该文本数据,为了解决什么问题等。由此,图书馆的“非作品性使用”可分为以下几种类型:第一种是文本数据的简单再利用,如图书馆通过借阅图书的登记数据来了解图书利用率;第二种方式为文本数据的关联,即对两种以上数据进行关联分析,进而得出结论,叠加重组后的数据价值会超过单一的数据价值,如将图书借阅量和图书馆开放时间的数据组合起来,进行关联分析,如果发现二者具有关联性,那么组合后的数据就是数据的关联;第三种是扩展文本数据用途,即扩展文本数据的其他用途,如图书馆中被经常借阅的现实题材的小说既可以用来了解读者的阅读偏好,也可以用来了解公众目前所关注的现实问题;第四种是挖掘文本数据的算法价值,即在用户进行网络搜索时,平台可以了解用户检索的全过程,如一些电商平台设置“排名算法”,消费者搜索某商品的频率越高,网站推荐栏目中该商品的排名越靠前。图书馆进行TDM,可以获得读者的习惯、偏好、特定需求,针对不同读者提供个性化的信息服务,比如信息推送。
输出阶段的知识增值是基于原作品而产生,与原作品存在一定关联,对于“作品性使用”来说,输出内容中包含原作的独创性表达,有可能涉及侵犯信息网络传播权和复制权;对于“非作品性使用”,输出的内容中不包含原作的独创性表达,不侵犯以上权利,但由于输出内容源于原作品,是否侵权演绎性权利,这仍然是一个需要探讨的问题。
(1)作品性使用。该类使用是指TDM后的输出内容中包含作品的独创性表达。未经作品版权人许可,输出内容中出现作品独创性表达会涉嫌侵权。为平衡版权人和社会公共利益,《著作权法》中第二十四条合理使用条款对著作权予以限制,可借鉴的条款为“为介绍、评论某一作品或者说明某一问题,在作品中适当引用他人已经发表的作品”,所以如果输出内容包含原作少量的独创性表达,那么符合该条款要求,可认定为合理使用,如果输出内容包含原作大量的独创性表达,需要考虑是否适用侵权豁免规则,如果不适用,则属于侵权。基于无偿向阅读障碍者提供无障碍阅读格式文本而对作品进行TDM所产生的复制适用侵权豁免规则,这基于《马拉喀什条约》所规定,图书馆为陈列、保存需要对已损失或濒临毁损、灭失等情形下的纸质作品进行TDM所产生的复制适用侵权豁免规则。例如,某图书馆利用人工智能对大量图书信息进行数据分析,生成图书识别软件,读者使用软件时通过扫描图书封面可以获得图书目录和序言。图书目录和序言相对于整本书籍来说,属于原作少量的独创性表达,所以该知识增值构成合理使用,但如果图书大量章节被展现在图书识别软件中,又不属于侵权豁免情形,则构成侵权。在王莘诉谷歌图书馆侵权案[3]中,法官判定被告谷歌图书馆构成侵权。该案中,被告未经原告许可对原告作品进行了电子化扫描,法官认为该复制行为会对权利人的经济利益造成“现实”损害和“潜在”危险。
从转换性使用角度,也可以判定该类型使用不构成侵权。转换性使用产生于1994年美国“Campbell诉AcuffRose音乐公司”案[4],现在已成为判定合理使用的重要准则,该案件涉及对原作品的戏仿,进而引出“转换性使用”的理念,转换性使用不再局限于对原作品使用数量和性质的限制,而是在所采用的内容表达、使用目的等方面具有创新性。转换性使用主要包含两种类型,即内容上的转换性使用和目的上的转换性使用。前者是对原作品进行再创作,并形成了新的表达,比如对原图片的风格、线条、大小、颜色、字体、形状进行改变,或对原作进行戏仿、评价。数字时代让使用者更加便捷地利用软件对原作进行编辑,如果编辑后的图片加入了大量独创性部分,使得原图片和编辑后的图片有明显区分,那么该二次创作行为则构成转换性使用。实践中,很多电影解说属于对原作的二次演绎[5],构成转换性使用,制作者从影视原作中剪辑很多片段后重组,然后加入大量独创性的部分,比如解说词、背景音乐、特效、文字字幕等,使解说作品与影视原作有明显区别,此类行为仍可被视为转换性使用。后者是指改变对原作品的使用目的,这种转换性使用未对原作品进行任何再创作,只是对原作品进行了不同的功能利用,这不会冲击原作品的市场利益,例如美国论文检测系统Turnitin,检测系统虽收录了大量论文数据,但其收录论文的目的在于检测论文,并非将论文原样呈现给读者,因此属于目的的转换性使用。转换性使用出现的根源在于权利人与大众使用之间利益失衡,这反映了市场的失灵,转换性使用是为了解决市场失灵和利益失衡的问题 [6]。国内司法实践中也开始借鉴美国的转换性使用理论。比如在黑猫警长海报案[7]中,法官认为被告海报中使用黑猫警长图案并非为了单纯彰显图案自身的艺术价值,使用的主要目的是为了说明问题,该图案被使用时呈现了新的价值和功能,其艺术价值和功能产生了较高程度的转换,由此可以看出法官在说理时借鉴了转换性使用理论的理念。
内容上的转换性使用不属于侵权,因为对原作使用后的新作品已形成了新的独创性表达,但目的上的转换性使用并未对原作进行新的创作,该情形下使用原作之所以属于合理使用,是因为有着独特的理论依据。著作权所设立的目的是为了激励作者创造创新,法律使作品权利人拥有专有权。若使用者未获得合法授权而使用作品,则会损害权利人的版权利益,进而降低作者的创造热情,这违背了知识产权的立法目的。所以对作品原有市场的保护是应当的,但是潜在市场是难以发现的市场[8]。对潜在市场的开发不应当由法律赋予著作权人所独有,因为原作品作者在创立作品时未曾预料到潜在市场的存在。对潜在市场的开发不会抑制原作品权利人的创作积极性。如果对作品的使用颠覆了传统的使用方式,开发出潜在的市场,就不会损害权利人原有的版权市场利益。目的上的转换性使用实质上将市場划分成了不同模块,每个模块有专属的消费者群体,如果消费者存在于不同的市场模块中,就不会损害原著作权人的市场利益。比如,翻译机器人对大量的文字作品进行机器学习,从而产生了翻译模型,用户只要输入语句,翻译机器人能够自动生成翻译。该例子中翻译机器人对大量的文字作品进行了二次使用,其受众群体是对翻译有需求的人,而原文字作品的受众是阅读原文字作品的读者,两个受众群体分属不同的市场模块,相互之间不会产生竞争,翻译机器人开发了一个潜在市场,不会削弱原文字作品作者的市场利益,因此构成合理使用。
在“作品性使用”中,如果输出内容包含原作少量的独创性表达,可被视为转换性使用,具体来说属于目的上的转换性使用。目的转换性使用是指在二次利用中未添加新的独创性表达,仅改变对原作使用的用途。随着技术不断进步,作品会不断涌现出新价值,如果由版权人享有原作全部的潜在价值,则会滋生垄断,进而导致高昂的许可费,这会削弱市场的创新性,况且对作品的利用与使用者的个人素质紧密相关,所以,版权人对原作进行充分开发的可能性很小。由版权人享有原作的全部价值,不利于调动后续使用者的创造积极性,将对作品的后续开发产生负面影响。所以,如果对作品的再次开发创造了新的市场领域,那么该使用行为可被视为合理使用,这有利于对作品进行全方位利用。TDM是重组信息和发掘知识的过程[9]。图书馆借助TDM开发的图书检索软件中,输出的内容少量使用原作的独创性表达,其目的在于方便读者检索,而非提供原作全部内容以供读者观看,这不会冲击图书销售市场,图书馆转换了使用目的,构成了目的转换性使用。当然,如果输出内容包括原作大量独创性表达,那么将冲击原作市场利益,如果不属于侵权豁免情形,则构成侵权。转换性使用是美国法院造法的产物[10],我国在对文本数据挖掘进行法律规制时,可借鉴其立法经验,以促进图书馆文本数据挖掘事业的发展。
(2)非作品性使用。这类使用是指对采集的文本数据进行深度分析,以得出结论或预测趋势,这彰显了TDM在科研领域的重要价值[11]。例如,图书馆通过TDM分析读者平均借阅期限信息,来设定图书馆借阅期限,避免读者借阅逾期之事频繁发生。又如,图书馆通过分析读者的阅读反馈和书评来判断读者对图书馆采购书籍的满意度。再如,图书馆通过对大量畅销书的内容进行TDM,来分析畅销书写作的风格。这类使用中,很多情况下其输出结果源于原作,与原作有一定联系,那么是否侵犯原作演绎性权利?演绎性权利可分为三种,即改编权、汇编权、翻译权。对原作的演绎通常遵循原作品的主要内容,但改变其表达方式,比如将小说改编为剧本,将很多单篇诗歌汇编成诗集。演绎行为基本沿袭原作内容,但通过新形式对原作进行呈现,因此演绎权被称为作品表达性使用的权利,演绎行为需要原作者的授权。“非作品性使用”的输出内容不包含原作的独创性表达,根据思想与表达二分法理论,此种利用并非复制或传播原作品,也与演绎行为不符,所以此类行为不涉及侵权。此类行为属于对原作品的深度信息挖掘,其挖掘依赖于图书馆的科研需求,挖掘后所形成的知识增值并未彰显原作的独创性表达,不会损害原作品的市场利益。比如,图书馆为了分析图书封面设计与图书借阅量之间的关系,使用人工智能对馆藏图书的封面和图书借阅信息进行数据分析,生成分析报告。该分析报告并未彰显图书封面的独创性表达,因此不涉及侵权。再比如,图书馆采取TDM对文献的主题和在线浏览量进行统计和分析,生成研究报告。该报告分析文献主题和在线浏览量之间的关系,其目的是用于馆内的科学研究,报告中并未彰显原文献内容的独创性表达,不会冲击原文献版权人的市场利益,所以不属于侵权。综上,图书馆TDM过程中的著作权侵权问题和判断方法如表1所示。
2 针对采集阶段的复制行为征收著作权许可费
上文已述,在TDM采集阶段,复制作品信息涉嫌侵犯著作权,那么针对侵权行为是否可以向图书馆收取著作权许可费?如果可以征收许可费,这无疑有利于补偿作品权利人的损失,从利益平衡角度来说,这对权利人更合理。
2.1 征收许可费的可行性
如果对使用者征收著作权许可费,将导致再创新的成本迅速攀升。如果征收许可费,面对海量的作品信息,图书馆在进行TDM之前难以完成与原作品权利人的一一授权,即便能完成授权,但面对巨额的使用成本,图书馆也难以承担。图书馆作为公益机构,服务于社会公众,由政府出资成立运营,如果巨额的使用成本由政府承担,不仅极大增加了社会公共服务的成本,而且也不具有合理性,毕竟图书馆进行TDM并非基于商业目的,而且未从中获得商业利益,其主要目的在于提高信息利用效率[12],以更好地服务社会公众,况且TDM通过“爬虫”程序复制作品信息,通常以高隐蔽、低成本方式实现,权利人难以追查TDM所使用的具体作品,这也不利于权利人维权和主张许可费。
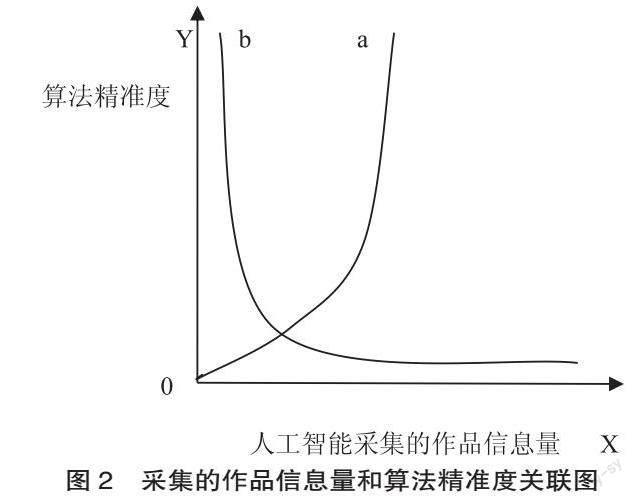
从社会福利方面来说,如果采集文本数据需要支付许可费,等于图书馆有了选择权,图书馆为了规避许可费,会对可供免费使用的作品信息进行挖掘。这会致使人工智能采集的作品信息具有选择性,算法会出现偏差,输入的信息越多,偏差越大,其最后输出的效果也会大打折扣,比如生成的分析报告判断失误。在TDM之前,人类通过对信息进行分析来做出决策,但人类的分析与机器的分析明显不同。人对作品的分析是阅读、理解作品的过程,人通过分析作品既可以满足主观需求,即获得新知识,也可以满足客观需求,即创造新知识。比如,学生阅读书籍,在阅读一本书后即使没有写作新作品,未产生知识增值,但是获得了精神的享受,那么此次阅读仍是有意义的,这也是读者需要向作者支付费用的依据。但是机器的分析却是单纯执行算法的过程。目前人工智能尚不具有人类的思维和精神,因此不能认定为机器的分析实现了机器精神的享受。人工智能分析作品信息只是单纯地利用原作品信息去创造新知识,即满足客观需求,无法满足主观需求。如果对TDM进行价值评价,只能评价其输出内容,如果输出内容违法或不具有科学性,那么该输出内容无法被使用,不具有任何价值,此次TDM就是失败的,这会导致社会资源的浪费。算法偏差不具有科学性,无疑会对决策造成负面影响,公众也无法享受TDM带来的便利。人工智能采集的作品信息量(X轴)与算法精准度(Y轴)之间的关系在图2中有直观展示。
表算法精准度,a线代表没有版权许可费情形下人工智能TDM情况,b线代表存在版权许可费情形下人工智能TDM情况。a线中,算法精准度随着采集的作品信息量的增长而快速上升,b线中,因为存在版权许可费,人工智能选择采集无版权费的作品信息,这样导致算法偏差,采集的作品信息量越多,算法精准度越低,双方呈现反比例关系。
2.2 免征许可费的合理性
从以上分析可以看出,对复制行为征收许可费是不可行的,那么免收许可费是否合理?图书馆进行TDM是为了提高图书馆智能化程度和工作效率,并助力科研取得一系列突破性成果[13]。如果文本数据采集豁免侵权,图书馆可以大规模使用TDM技术,这一定程度上促进了社会进步。另外,针对文本数据采集阶段的复制行为,豁免侵权虽无法律依据,但有学术理论证明其合理性,即“整体说”理论。该理论认为如果复制是一些合理使用情形的先决条件,那么此时复制可视为在先行为,合理使用可视为后行为,在先行为与后行为应作为一个统一体去对待,不应将在先行为单独分开看待。也就是说,在未获得权利人合法授权的情况下,如果为了后行为而实施了在先行为,该在先行为应被认定为后行为的必要组成。就TDM来说,前端的采集阶段应与后端的输出阶段融为一体,若输出阶段并不侵权,则前端的采集阶段也应豁免于侵权。前端行为属于后端行为的准备阶段,与后端行为紧密相关,若后端行为合法,准备阶段的行为也合法,“整体说”理论为TDM构成合理使用提供了学术理论依据。
3 域外相关的法律解决措施
3.1 美国
对于TDM的版权侵权,美国没有出台正式的法律文件,而是在判例中认可其行为构成合理使用,以个案裁判的方式将TDM行为合法化。美国很多司法判例中确认TDM复制行为构成合理使用[14]。在这些案件中,其典型案例为“作家协会诉Google”案和“作家协会诉HathiTrust”案。在前一个案例中,Google 公司开展数字检索服务,扫描图书馆的纸质书籍并将其数字化,通过TDM技术实现搜索与片段展示的目的,向读者提供数字检索服务。Google将扫描后的书籍的单个页面分成若干部分,读者键入关键词后可以展示少量带有关键词的片段,这个过程中使用了TDM技术。2005年作家协会起诉Google侵权,之后双方达成和解,但被法官否决。该案历经初审和巡回法院审判,最终法院判决Google的行为构成合理使用,片段检索不会对作品市场形成替代,不会实质损害版权人利益[15]。在后一个案例中,Hathitrust 是一家数字图书馆,读者输入关键词后可对图书馆数据库中的数字作品中实施检索,检索结果中会展现关键词所在位置和每页中关键词出现的次数。巡回法院最终判定作为被告的HathiTrust数字图书馆采取TDM行为属于合理使用[16]。以上案例中,法官引入转换性使用的理论,结合四要素判定法分析TDM行为的合法性,最后判定被告TDM行为构成合理使用。美国司法界通过判例将TDM行为予以合法化,但这不适用于成文法国家。
3.2 欧盟
2016年,欧盟颁布《数字单一市场版权指令提案》,明确了基于科研目的的TDM 豁免侵权。2019年欧盟颁布了修改后的《数字单一市场版权指令》,规定了基于文本与数据挖掘目的的TDM豁免于侵权[17]。对于“基于科研目的的TDM版权例外”,欧盟设置了一些需要满足的条件。一是采取TDM的主体须为科研机构和文化遗产机构。科研机构包含大学、研究中心等,文化遗产机构包含图书馆、博物馆等。二是须以合法方式获取作品内容,如果采取病毒入侵方式获得内容或者获取盗版材料,都不能豁免侵权。三是目的须基于科学研究。科学研究不仅指公益性的科学研究,研究机构承担企业的研究项目,即商业性的研究也适用此规定。四是使用限于“复制”和“提取”。“改编”“翻译”“汇编”是否豁免侵权,法律文件中未明确规定。五是TDM挖掘的信息须以安全方式存储,即存储挖掘的信息须采取技术措施,防止信息外泄,防止侵害权利人的合法权益。但是该例外规则仅适用于科研,不能适用于商业运营、公共管理机构决策等,而且TDM分析行为不能被纳入《2001年版权指令》中临时复制,而临时复制属于合理使用情形。所以后来设定了“基于文本与数据挖掘目的的TDM例外”条款。根据该条款规定,若权利人未禁止对相关信息进行使用,那么使用人可复制和提取通过合法渠道获取的信息,使用人不限于科研机构,使用目的可以为商业使用,以促进信息传播和科学文化再创新。
3.3 日本
2009年日本在版权法中加入了“为解析信息进行的复制等”著作权例外,依据此条款,使用计算机实施信息分析的行为适用该例外规则,这使得TDM行为合法化。该例外规则有以下特点: 一是适用客体广泛,包括文本、影像、声音等,但专用于信息解析的数据库作品被排除;二是适用的分析方法广泛,包括很多类数据分析方法,例如比较、分类等方法均被覆盖;三是使用方法广泛,包含复制和改编,即基于该作品生成的衍生作品的复制也可适用。但该例外规则也有短板,比如将用于信息解析的工具限定于计算机,这难以跟上时代发展,因为随着技术进步,其他新的设备也可开展TDM[18],但总体来说,该规则有重要的进步意义,数据挖掘的合法化使人工智能产业得以蓬勃发展。2018 年,日本再次修订《著作权法》,增设了“灵活的权利限制条款”[19],新条款实际上允许了高科技企业可以在未经权利人授权的情况下直接使用其作品,但不得明显损害权利人利益,该项规定扫除了再创新的障碍,迎合了人工智能机器学习的需求。
从以上可以看出,在人工智能崛起的背景下,域外主要发达国家和地区已意识到TDM的重要性,开始不断調整法律以促进TDM的发展。这些国家的著作权豁免规则各有差异,总体来说,有两种立法思路:第一,在法律中设置TDM著作权例外规则;第二,在个案中判定TDM是否构成合理使用。
4 图书馆TDM行为的出路
4.1 法律层面:针对图书馆TDM设置著作权例外规则
版权困境根源于复制技术的进步,这虽降低了作品传播的成本[20],但也带来了侵权风险。随着新技术的不断发展,对作品的深度开发成为普遍趋势,著作权由过去单一激励作者转变为激励对作品的多样性利用。人工智能的竞争力在于强大的信息分析能力[21],人工智能时代到来,TDM有广阔的应用空间[22],很多国家对人工智能分析作品持宽容态度,将其认定为合理使用。鉴于域外国家的法律应对,设定豁免例外规则已成为必然趋势。
我国目前《著作权法》虽没有针对人工智能TDM设置侵权豁免条款,但2020年修改后的《著作权法》增加了针对合理使用的概括式条款,为人工智能TDM纳入合理使用预留了空间。为推动人工智能产业的发展,我国可参照域外国家的法律,为TDM设定豁免规则以指导案件审判,避免法律适用的模糊性。人工智能将引领新的产业革命,文本数据也变得越来越重要,法律对文本数据的规制正从独自占有转向流通、深度开发转变,所以须将利益平衡纳入制度设计中[23],因此对人工智能TDM设置专门的侵权豁免规制很有必要,况且图书馆使用TDM并非基于商业目的,而是为了提高对信息的智能化管理,为社会公共利益所考虑,因此更有必要。但需要指出的是,豁免只适用于采集阶段,主要是对复制的豁免,对输出内容的侵权不能构成豁免,正如上文所述,如果图书馆使用TDM后的输出内容包含大量原作的独创性表达,则难以构成合理使用,属于侵权。另外,针对图书馆进行TDM,有必要设立数据保护制度,法律可规定图书馆须采取技术保护措施防止TDM过程中作品信息被外泄,否则可能侵权,因为作品信息被外泄可能导致权利人作品在网络快速传播开来,这无疑损害了权利人的著作权。
4.2 经济层面:针对作品版权人建立补偿机制
图书馆TDM牵涉三方利益。一是图书馆TDM豁免侵权,二是版权人作品被使用应获得一定收入,三是读者可获得技术进步所创造的红利。上文已论述针对图书馆TDM不应征收许可费,但如果图书馆自由使用他人作品信息而无需提供任何补偿,只迎合了图书馆公共服务的需求。对作品权利人来说,传播技术增加了权利人获得收益的渠道[24],作品在TDM中被使用,权利人理应获得一定补偿,这有利于维持三方利益平衡。权利人允许作品被TDM使用,解决了图书馆TDM要求许可的困境,作品权利人获得一定补偿,这可以激励权利人继续创作和出版,图书馆对权利人作品进行TDM,推动了图书馆信息管理水平的提高,进而更好地服务读者,读者也能从中分享科技进步带来的红利,这形成了一个利益共享局面[25]。
如上文所述,图书馆TDM的采集阶段需要大量复制作品,而且针对“作品性使用”来说,其输出内容中包含原作独创性表达,一定程度上影响了原作市场利益。除此之外,图书馆作为公益性文化场所[26],有义务向残障人士提供大量无障碍阅读格式文本,这会冲击原作的版权市场,从长远看会抑制创作者的创作积极性[27]。在此情况下,图书馆可针对作品权利人建立补偿机制。首先,针对作品被TDM使用的权利人,图书馆可为其提供VIP借阅服务以作为补偿。某作者的作品被图书馆TDM使用,图书馆可向该作者发放VIP借阅卡,使其可以享有一系列特殊权利,比如免押金借阅、享有借阅图书的优先权、享有更长的借期,除此之外,还可以优先参加图书馆举办的读书会、行业交流会等馆内活动。其次,针对作品被转换为无障碍阅读格式文本的权利人,政府可给予一定版权补偿。2022年5月5日,《马拉喀什条约》对我国生效,图书馆作为非营利实体,向阅读障碍者无偿提供无障碍阅读文本的行为豁免侵权,但提供此类文本一定程度上影响原作的市场利益,而且无障碍阅读文本尤其是有声读物存在被广泛传播的风险,所以给予原作权利人一定版权补偿费是合理的。图书馆由政府授权成立,按照“谁设置、谁投入”的原则,由政府来承担版权补偿费更合理。此类版权补偿费应远低于目前市场上的著作权许可费,否则会加大政府财政负担。如果无法找到原作品的版权人,可参考孤儿作品相关制度,图书馆向著作权行政管理部门或著作权集体管理组织等第三方机构备案使用情况,然后由政府将版权补偿费提存至第三方机构,如果日后作品权利人向图书馆主张权利,则由第三方机构转付版权补偿费。
4.3 应用层面:允许图书馆对未发表的作品实行“非作品性使用”
传统的合理使用只局限于已经发表的作品,对于未发表的作品,图书馆能否进行TDM?要解答这个问题,需要结合TDM的输出内容来分析。对于“作品性使用”,其输出内容包含了原作的独创性表达,因此侵犯了权利人发表权,对于“非作品性使用”,其输出内容不包含原作独创性表达,因此并未侵犯发表权,原作者依然可以将作品发表。对未发表的作品进行“非作品性使用”具有重要意义,千百年来,常识和经验是法律不断发展的前提[28],前人撰写但未发表的学术著作,还有其它未发表的作品具有重要的科研价值,比如未发表的旅行日记、文字手稿、绘画作品等,这些资料有助于了解一位名人,或者揭开一段历史事实,或者发掘重要遗址等。如果图书馆使用TDM对这些未发表的作品进行深度分析,有可能会输出一些重要的科研结果,因为训练数据的多寡决定了TDM输出内容的质量[29],未发表的作品中也可能含有重要的科研信息,具有科研价值。比如,某地区存在一座已遭受严重破坏的古建筑,某收藏家收藏了记载该古建筑外貌特征的手稿并且对该手稿拥有版权,该收藏家并未将手稿发表,但将手稿复制件交付某图书馆收藏,该图书馆可以未经该收藏家许可使用TDM对手稿内容进行深度分析,然后将该古建筑进行图像还原,因为手稿虽未发表,但为科学研究和文化保护而对该手稿进行TDM符合社会公共利益,此时对版权人权利进行一定限制是合理的。
5 结语
当前,TDM在图书馆中广泛应用,这有利于提高图书馆智能管理水平。但TDM过程中,大量作品信息被复制,这涉嫌侵犯著作权,所以有必要分析著作权风险并探寻出路。TDM分为采集阶段、输出阶段。采集阶段涉及复制作品信息,这会侵犯复制权,在输出阶段,作品信息被处理后会产生知识增值,根据输出内容是否包含原作独创性表达,该知识增值可分为“作品性使用”和“非作品性使用”,对于“作品性使用”来说,如果输出结果包含原作少量独创性表达,则属于合理使用,如果包含原作大量独创性表达,又不属于著作权例外情形,则属于侵权。“非作品性使用”不涉及侵犯著作权。针对图书馆TDM行为,法律上可设立著作权例外规则,针对作品版权人可建立补偿机制,為社会公共利益所考虑,可允许图书馆对未发表的作品进行“非作品性使用”。随着人工智能的发展,TDM将在图书馆信息资源管理中发挥日益重要的作用,未来的研究将集中于版权补偿机制的具体构建,比如版权许可费的设定,以实现版权人、图书馆、读者三方利益平衡。
参考文献:
吴汉东.人工智能生成作品的著作权法之问[J].中外法学,2020,32(3):653-673.
SOBEL B.Artificial intelligences fair use crisis[J].Columbia Journal of Law & the Arts,2017 (1): 45-98.
北大法宝.王莘诉北京谷翔信息技术有限公司等侵犯著作权纠纷案民事判决书[EB/OL].[2022-06-14].https://www.pkulaw.com/pfnl/a25051f3312b07f367503cea0c2c52ed2b4c49dd9d206508bdfb.html?keyword=%282011%29%E4%B8%80%E4%B8%AD%E6%B0%91%E5%88%9D%E5%AD%97%E7%AC%AC1321%E5%8F%B7#anchor-documentno.
黄汇,尹鹏旭.作品转换性使用的规则重构及其适用逻辑[J].社会科学研究,2021(5):95-104.
罗祥.影视解说视频合理使用的困境与出路:由首例“图解电影”案引发的思考[J].科技与法律(中英文),2021(4):81-89.
谢琳.论著作权转换性使用之非转换性[J].学术研究,2017(9):61-67.
北大法宝.上海美术电影制片厂与浙江新影年代文化传播有限公司等著作权侵权纠纷上诉案民事判决书[EB/OL].[2022-06-14]. https://www.pkulaw.com/pfnl/a25051f3312b07f3f41810a3df3b4a0da7a6b8d5169974f6bdfb.html?keyword=%282015%29%E6%B2%AA%E7%9F%A5%E6%B0%91%E7%BB%88%E5%AD%97%E7%AC%AC730%E5%8F%B7#anchor-documentno.
WordLII. American Geophysical Union, et al. v. Texaco Inc.60F. 3d913(2d Cir. 1994).[EB/OL].[2023-01-11].http://www.worldlii.org/us/cases/federal/USCA2/1995/843.html.
吳高,黄晓斌.人工智能时代文本与数据挖掘合理使用规则设计研究[J].图书情报工作,2021,65(22):3-13.
熊琦.著作权转换性使用的本土法释义[J].法学家,2019(2):124-134.
赵力.文本与数据挖掘著作权合理使用的域外实践与借鉴[J].图书馆,2022(3):63-69.
闫宇晨.我国智慧图书馆文本数据挖掘侵权风险与对策研究[J].国家图书馆学刊,2022,31(1):106-113.
贾引狮.人工智能技术发展对“发明人”角色的挑战与应对[J]科技进步与对策,2019,36(3):98-105.
罗娇,张晓林.支持文本与数据挖掘的著作权法律政策建议[J].中国图书馆学报,2018,44(3):21-34.
LexisNexis. Authors Gulid,Inc. v. Google, Inc.804F. 3d 202 (2nd Cir. 2015)[EB/OL].[2021-04-13].https://www.lexisnexis.com/.
LexisNexis. Authors Guild v. Hathitrust, 755F.3d.87(2nd Cir. 2014) [EB/OL].[2021-04-13].https: //www.lexisnexis.com/.
赵力.文本与数据挖掘著作权合理使用的域外实践与借鉴[J].图书馆,2022(3):63-69.
吴高,黄晓斌.人工智能时代文本与数据挖掘合理使用规则设计研究[J].图书情报工作,2021,65(22):3-13.
中国知识产权杂志.日本大尺度修改《著作权法》[EB/OL].[2023-01-13].http://www.ciplawyer.cn/rhbq/138657.jhtml?prid=185.
郭晶,王怡静.美国电子书版权保护实践及其对我国的启示[J].科技与出版,2021(10):148-152.
王文敏,高军.人工智能时代图书馆信息分析的著作权例外规则[J].图书馆论坛,2020,40(9):60-68.
周玲玲.欧盟文本与数据挖掘新策解析[J].图书馆建设,2017(7):19-24, 30.
陈全真.人工智能创作物的著作权归属:投资者对创作者的超越[J].哈尔滨工业大学学报:社会科学版,2019,21(6):26-32.
徐小奔,杨依楠.论人工智能深度学习中著作权的合理使用[J].交大法学,2019, 3(11):32-42.
王楷文.人工智能数据输入与著作权合理使用[J].文献与数据学报,2021(2):110-118.
袁丽华.东部地区地市级公共图书馆无障碍阅读服务研究[J].新世纪图书馆,2021(3):91-96.
刘友华, 魏远山.机器学习的著作权侵权问题及其解决[J].华东政法大学学报,2019,22(2):68-79.
袁建刚,王钰.法学理论和定量分析的关系[J].燕山大学学报:哲学社会科学版,2010,11(4):80-82.
万勇.人工智能时代著作权法合理使用制度的困境与出路[J].社会科学集刊,2021(5):93-102.
余 祥 武汉大学法学院博士研究生。 湖北武汉,430072。
聂建强 武汉大学法学院国际法研究所副所长,教授,博士生导师。 湖北武汉,430072。
(收稿日期:2023-01-03 编校:曹晓文,左静远)
猜你喜欢
新世纪图书馆(2016年9期)2016-11-15 02:00:49
南北桥(2016年10期)2016-11-10 17:24:59
企业导报(2016年20期)2016-11-05 18:57:19
文艺生活·中旬刊(2016年10期)2016-11-04 06:33:26
中国科技博览(2016年22期)2016-11-01 17:49:36
中国科技博览(2016年22期)2016-11-01 17:45:39
中国科技博览(2016年22期)2016-11-01 17:44:11
出版广角(2016年15期)2016-10-18 00:23:30
科技视界(2016年21期)2016-10-17 19:33:29
商(2016年27期)2016-10-17 06:34:33
