
基于谱聚类的重打包应用检测
2023-06-23 09:40:08蔡昆杰李吕牧之李帅常锦才
华北理工大学学报(自然科学版) 2023年3期
蔡昆杰,李吕牧之,李帅,常锦才
(华北理工大学 理学院,河北 唐山 063210)
Android操作系统已经是当今世界上最受欢迎、使用最广泛的移动操作系统,Android智能手机占全球智能手机中的一半以上。与此同时,Android应用(Applications,APP)的数量也在快速增长。在谷歌Android市场,Android应用程序从2018年9月的280万个激增至2021第一季度的340万个[1]。此外,根据卡巴斯基的安全恶意软件威胁报告[2],2020年第三季度,检测到大约35万个新的恶意应用。根据一项研究[3],Android恶意应用占所有智能手机威胁的98%,其中99%的恶意应用来自许多第三方市场。因此,Android应用的检测必须得到加强,特别是第三方应用市场。
Android系统是一个开源系统,因此,与其他操作系统相比,Android操作系统更容易受到恶意软件攻击。Android操作系统更容易受到恶意攻击的2个主要原因是:其广泛性和漏洞的数量的增加。其广泛性是指Android操作系统和Android应用广泛使用在日常生活中的各个方面,包括但不限于银行和社交网络在内的各种重要内容,涉及大量敏感和私人数据。因此,Android操作系统和应用程序已经成为剽窃者非常有吸引力的目标,目的是从应用程序中窃取隐私和敏感信息。另一方面,Android中的漏洞数量不断增加是其易受攻击的另一个原因,Android操作系统中的漏洞数量过去几年急剧增加[4],漏洞的增加可能会导致剽窃者更容易盗取用户的信息和更频繁地攻击Android系统。
在Android操作系统中,敏感信息(包括账号、密码、银行卡信息、个人照片和其他私人信息)存储在Android移动设备中,这使得剽窃者可以利用Android操作系统的漏洞获取用户的隐私。剽窃者使用多种方法来获取这些敏感信息,而重打包应用是最常用方法之一。因为Android市场上的大多数应用都可以免费下载,这使得剽窃者很容易获得想要的应用。在重新打包应用的过程中,剽窃者会在重新打包的应用程序中留下病毒或后门[5],以此获取用户的敏感信息。此外,随着Java逆向工程的发展,如果在发布应用前开发人员不注意反逆向,或者他们使用的反逆向工程技术落后,剽窃者可以很容易地对应用进行反编译,然后对其进行修改,例如插入病毒和广告,然后重新打包并发布应用程序。重打包应用就是未经开发人员同意就被修改,然后重新发布在应用市场上的应用。
由于重打包应用的成本低、难度小,它们在第三方应用市场上的数量逐渐增多。因此,加大重打包应用的检测力度是非常必要的。根据最近的一项研究[6],作者从6个第三方Android市场中抽取了22 906款应用,发现其中5%至13%是重打包应用。此外,通过对这些重打包应用的人工分析,发现这些应用主要是通过插入广告、植入后门和病毒来牟利。根据另一项研究[7],在分析的1 260个恶意软件样本中,作者发现其中1 083个是带有恶意病毒的合法应用的重打包版本。这一结果表明,重打包应用是恶意软件传播的有益工具,对重打包应用的检测和预防具有重要的研究价值和现实意义。首先,检测重打包的应用在一定程度上也等同于检测恶意应用,这对维护网络安全具有重要意义。其次,检测重打包的应用可以维护开发者的版权,这对于维护Android应用程序市场的公平性非常重要。最后,如果不重视重打包应用,不对重包装应用进行打击惩罚,将会有越来越多的重打包应用在Android应用程序市场上发布,这将不利于Android应用程序的开发或创新。
1方法
重新包装的应用程序在外观和功能上与原始应用程序非常相似[8],用户很难辨别。因此,检测重打包应用的工作应该由特殊的检测工具或算法来完成。现有的重打包检测算法根据检测过程中是否需要安装应用分为动态检测[9]和静态检测[10]。也就是说,在不运行Android的情况下对应用进行分析和检测的算法称为静态检测算法,其它算法称为动态检测。动态检测算法在分析重打包应用的具体行为和检测准确率方面比静态检测算法具有优势[11],而静态检测在检测速度具有较大的优势,该项研究讨论的算法主要是静态检测算法。
在检测重打包的应用时,静态检测算法是广泛使用的算法。静态检测算法主要是在无需或无法实际部署应用时,通过提取Android应用的特征来检测应用。因此,这项技术只需处理Android应用的APK文件,并通过分析文件内容来发现潜在的安全隐患。APK文件是Android应用的安装包,包含该应用的所有的资源文件,包括代码、图片、音频和其他资源文件,几乎所有的静态检测算法都是围绕APK文件开发的。目前,重新包装的应用程序检测研究取得了良好进展,著名的静态重打包检测算法有Androguard[12]、FSquaDRA[13]、SimiDroid[14]和DNADroid[15]等,这些算法都是通过两两比对的方式进行检测。例如,现有一个应用,疑是n个原应用(即合法应用,非重打包应用)中的某一个应用的重打包应用,则现有的重打包应用的检测方法是将这个应用与所有的原应用都进行一次检测,即要进行n次检测。显然,这n次检测中有很多次检测是无效的,也就是说如果可以通过有效的方法避免这些无效的检测,减少检测次数,便能在提高这类需要两两对比的检测算法的检测效率。

SpectDroid对所有的需要进行两两对比的重打包检测算法都有效。以Androguard检测算法为例,对SpectDroid的有效性进行详细分析。
1.1 Androguard
Androguard是一个用于处理Android文件的完整python工具,它提供恶意应用程序分析、重打包检测和其它功能。Android应用的代码由多个函数(或方法)组成。Androguard通过使用SHA256过滤相同的函数以及NCD(归一化压缩距离,一种计算二进制文件相似性的算法)[16]过滤相似的函数来检测重新打包的应用程序。图1所示为Androguard的检测过程。

图1 Androguard的检测过程
SHA256是一种哈希算法,常用于检校数据的完整性、快速查找和加密。该算法通过单向数学函数将任意长的输入消息映射到固定长的输出消息,也就是摘要。SHA256对于消息的变化特别敏感,当输入消息产生微小的变化,摘要就会产生非常大的变化,因此它可以过滤相同的函数。NCD是一个字符串的标准化值,常用于计算2个字符串之间的相似程度,因此可以用于查找功能相同的相似的函数。NCD可以通过计算获得,NCD与字符串的相似程度呈负相关,也就是说NCD值越小,字符串的相似程度越大。其计算公式如式(1)所示。
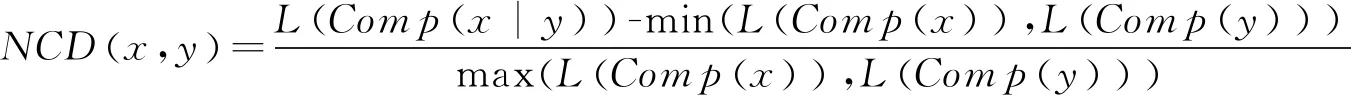
(1)
其中x和y是输入的消息,L(s)是消息的长度,Comp(x)将消息x进行压缩,Comp(x|y)是消息x和y一起的压缩,min(x,y)是取x和y中的最小值,max(x,y)是取x和y中的最大值。
在图1所示的步骤之后,Androguard根据其NCD值和SHA256值将应用程序的功能分为new、deleted、identical和similar这4类。具有相同SHA256值的函数被分类为identical。NCD小于0.4的功能将被归类为similar。app1剩余的函数被分类为deleted,app2剩余的函数被分类为new。然后可以通过式(2)获得2个应用程序的相似度值。
(2)
其中|x|是类别x的函数的个数,|base on option|是|deleted|或|new|。当其为|deleted|时,相似度结果为sim(1,2),当其为|new|时相似度结果为sim(2,1)。显然,sim(1,2)=sim(2,1)并不总是成立。对于同一对应用程序,如果输入顺序不同,结果也不同。
通过式(2)可以得到2个应用的相似度,若相似度大于阈值,则检测应用为重打包应用。阈值的大小需要通过实验确定。
1.2 谱聚类
聚类分析是机器学习领域中的一个重要分支[18],常用于挖掘一组表面毫无规律的数据集的潜在规律,从而挖掘出数据的潜在价值。该类算法通过样本之间的相似程度将样本划分为若干个互不相交的类簇,也就是每个样本只能映射到一个簇。同一个簇内的样本的相似性较大,差异性较小;不同簇的样本相似性较小,差异性较大。随着大数据的发展,越来越多的数据可以用图表示,因此关于图聚类的问题应运而生。谱聚类具有实现简单、聚类效果良好的优点,因此常用于解决图聚类问题。谱聚类算法的本质是谱图理论[19],能应用于任意形状的样本空间。
在谱聚类中,通常会根据数据集中各个样本之间的关系得到一个加权图G=(V,E)。其中,每一个顶点V都可以对应为数据集中的一个样本,两点之间的边E为对应相连顶点对应的样本之间的关系,样本间的相似度为E的赋权值W。在数据集转化为图之后,数据集的聚类问题就转换为图划分问题。图划分的最优结果是使得分成的所有子图中,任意一个子图的内部顶点的相似度较大,任意2个子图之间的相似度较小。因此,聚类结果与划分准则直接相关,好的划分准则聚类结果较好,反之亦然。常见的划分准则有Ratio cut和MNcut等[20]。
现有的求图划分准则的求解方法一般都是将数据集转化为相似矩阵或Laplacian矩阵,从而将其转换成求解相似矩阵问题或求解Laplacian矩阵的谱分解问题,所以这类方法统称为谱聚类,求图划分的NP困难问题也就转变为对图划分准则的逼近。虽然谱聚类的不同的具体实现方法使用不同划分准则和谱映射方法,步骤或有不同,但其大致的算法过程都可以归纳如下[21]:
(1)根据样本之间的关系得到表示样本之间关系的矩阵L;
(2)计算出样本关系矩阵L的前k个特征值与特征向量,构建特征向量空间;
(3)用其它聚类算法对特征向量空间中的特征向量进行聚类。
本文的谱聚类方法使用的矩阵是Laplacian矩阵,聚类方法是K-means。首先,计算Laplacian矩阵L=D-A,其中A是邻接矩阵,D是对角矩阵;然后计算L的k个最小特征向量,忽略矩阵L的第一个特征向量并使用剩下的特征向量创建包含特征向量v1,v2,...,vn的矩阵V,最后使用k均值将V中的行聚类为k个社区。k值因测试样本的不同而可能不同,该项研究通过实验获取最优k值。
2实验结果与讨论
涉及到的实验在华硕笔记本电脑[Windows 10 x64, RAM 8GB, Intel(R) Core(TM) i5-7300HQ CPU 2.50GHz]上进行。
2.1 Androguard阈值的确定
由1.1可知,Androguard主要通过计算可以得到2个应用的相似度,然后用这个相似度跟既定的阈值进行比较,如果相似度大于阈值,则待检测应用为重打包应用,否则不是。阈值的确定需要找到召回率和精确率的平衡点。召回率又名查全率,是指检索结果中真实为正例的样本中预测结果为正例的比例;精确率也叫查准率,为检索结果中预测结果为正例样本中真实为正例的比例。一般情况下,召回率与精确率呈负相关,高召回率会导致低精确率,反之亦然。因此,阈值的确定就是寻找召回率和精确率的平衡点。召回率和精确率的计算需要用到混淆矩阵的相关知识。
混淆矩阵也称误差矩阵,是机器学习中常用的一种可视化方法,特别用于监督学习,在无监督学习中一般叫做匹配矩阵。混淆矩阵通过用n行n列的矩阵来表示分类结果,能够简单直观地呈现出分类结果,对于后续的分类结果的好坏起到关键作用。在重打包检测中,可以通过阈值将实例分为正类、负类,结合分类的正确与否,有TP、FN、FP和TN共4种分类结果:
(1)TP:真正类,样本的真实类别是正类,并且模型识别的结果也是正类;
(2)FN:假负类,样本的真实类别是正类,但是模型将其识别为负类;
(3)FP:假正类,样本的真实类别是负类,但是模型将其识别为正类;
(4)TN:真负类,样本的真实类别是负类,并且模型将其识别为负类。
根据4种分类结果,便可以计算召回率和精确率,其计算公式如式(3)和式(4)所示。有时候准确率也会作为判定阈值的一个衡量标准,准确率的计算公式如式(5)所示。
(3)
(4)
(5)
分别使用了50对应用(21个原应用和50个重打包应用,一个原应用可能有一个或多个重打包应用)和100对应用(34个原应用和100个重打包应用),从1%~99%,以1%为增幅设置了99个阈值,准确率、召回率和精确率随着阈值(threshold)的增加的变化情况如图2和图3所示。

图2 50对应用的准确率、召回率和精确率的变化折线图
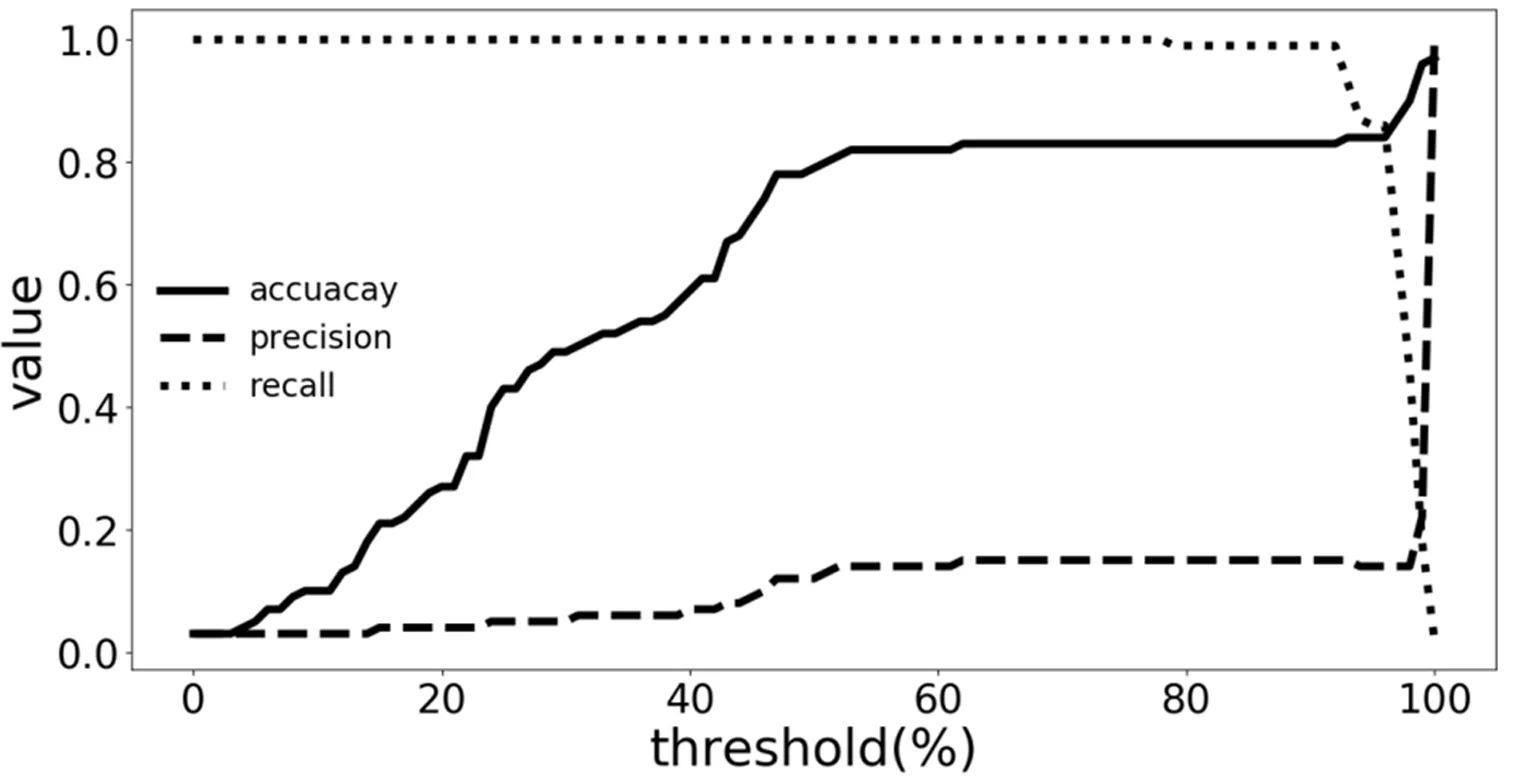
图3 100对应用的准确率、召回率和精确率的变化折线图
由图2和图3可知,准确率随着阈值的增加而增加,但召回率在阈值达到一定程度后会开始急剧下降,因此,准确率不适合用于作为阈值取值的衡量标准,阈值的取值应该取在召回率下降的拐点。为了综合考虑准确率和召回率,使用F-Score来权衡精确率和召回率。一般来说,精确度和召回率之间是矛盾的,这里引入F-Score作为综合指标,就是为了平衡准确率和召回率的影响,较为全面地评价一个分类器,F-Score越大说明模型质量更高,其计算公式如式(6)所示。
(6)
如果β=1,表示Precision与Recall一样重要;如果β<1,表示Precision比Recall重要;否则Recall比Precision重要。需要综合考虑Precision与Recall,因此取β=1。F-Score随着阈值的增加的变化情况如图4和图5所示。

图4 50对应用的F-Score变化折线图

图5 100对应用的F-Score变化折线图
当以50对应用作为样本时,F-Score在阈值为74%时取得最大值0.354 6,因此阈值可以定位74%,当以100对应用作为样本时,F-Score在阈值为74%时取得最大值0.259 1,因此阈值可以定为74%。
2.2 SpectDroid
使用1 000对应用(275个原应用和1 000个重打包应用,将原应用从1-199,以1为增幅设置了199个k值,准确率随着k值的增加的变化情况如图6所示。

图6 准确率随k值变化折线图

3结论
(1)Androguard的阈值为74%。
(2)SpectDroid具有较高的准确率和较快的检测速度,其准确率为81%,低于Androguard的97.3%,但计算量相对减少了74.18%。
(3)SpectDroid的准确率和检测速度呈负相关,较快的检测速度将会导致较低的准确率。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电脑报(2019年12期)2019-09-10 05:08:20
中国交通信息化(2018年5期)2018-08-21 03:37:40
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
电脑迷(2012年15期)2012-04-29 17:09:47
