
基于模糊测试和集成学习的XSS攻击检测方法
2023-06-23 09:34:36马征陈学斌张国鹏
华北理工大学学报(自然科学版) 2023年3期
马征,陈学斌,张国鹏
(1. 华北理工大学 理学院,河北 唐山 063210;2.河北省数据科学与应用重点实验室,河北 唐山 063000;3. 唐山市数据科学重点实验室,河北 唐山 063000)
引言
由开放式Web应用程序安全项目(OWASP)[1]最新发布的"十大最关键的Web应用安全风险"中,Web应用漏洞每年给国民经济造成巨大损失,在XSS攻击中,攻击者可以窃取受害者的会话cookie,进而收集到受害者的敏感数据,在浏览器中实现键盘记录器,从而损害了相关网站的声誉,因此引起了更多企业和组织对Web应用安全漏洞的关注。
随着网络安全知识的不断普及,Web应用安全成为国内外研究者的研究热点,现有基于过滤器、动态分析、静态分析、机器学习检测、深度学习检测等解决方案。黄文锋[2]提出了一种采用扩展的巴科斯范式构造XSS语义向量与网络二次爬虫相结合的方法来检测XSS,能够有效的绕过服务器端的过滤,但未制定反爬措施,仅限于开发者自己使用,局限性较大。倪萍等[3]提出了一种基于模糊测试的漏洞检测系统,通过爬虫技术提取注入点,根据攻击载荷的语法形式构造模糊测试用例,并根据网站响应调整权重,从而生成更加高效的攻击载荷,有效的降低误报率,在有监督学习上取得了较好的检测效果,但并不能单独作为一种检测工具来使用。文献[4]提出了一种基于多层感知器的模型来检测XSS攻击,他们从内容上提取了基于URL、基于HTML、基于JavaScript的功能,如URL长度和URL中的特殊字符,HTML标签、JavaScript事件,在检测攻击方面达到了99.32%的准确性,但不能实时检测到XSS攻击。
目前在XSS攻击检测识别上应用比较广泛的典型的机器学习模型有:支持向量机(Support Vector Machines,SVM)、随机森林(Random Forest)、朴素贝叶斯等方法。赵澄等[5]把具有代表性的五维特征向量化,使用SVM进行训练和测试。顾兆军等[6]通过对比朴素贝叶斯和支持向量机两种方法检测XSS攻击。结果表明,SVM取得了最佳性能,但攻击样本不够丰富,都是基于小数据集。文献[7]将攻击语句改为URL格式,将攻击语句划分单词,计算分类中出现的单词频率,通过基于word2vec的模型将单词转换成向量,对向量使用分类算法,结果表明SVM是检测的最佳过滤器,但存在着数据集不平衡问题。文献[8]开发了随机森林、KNN和SVM模型来检测恶意XSS代码,他们提取了包含恶意JavaScript中的一组特殊字符,把恶意JavaScript中使用的函数和命令作为行为特征,达到了99.75的准确度,但涉及的特征过少不能充分表示XSS攻击。文献[9]提出了一种基于深度的框架来检测恶意JavaScript,框架中包含逻辑回归、深度学习方法和稀疏随机投影,他们通过堆叠去噪自动编码器从JavaScript代码中提取特征,这些功能用于训练SVM或逻辑回归模型,通过逻辑回归对恶意代码进行分类,模型达到了94.9%的精度。丁雪川等[10]通过LSTM深度学习算法实现自动提取深层次特征,利用word2vec提取样本用向量表示,能达到99.5%的准确度,但没有设计可视化的XSS检测平台导致不能直观表示。朱思猛等[11]提出了利用循环神经网络生成恶意攻击样本,设计评分函数加固签名,加固WAF抵御恶意攻击从而降低安全风险、但没有根据WAF的反馈来强化神经网络的学习。
针对传统的XSS检测器存在测试用例过于冗余、不平衡数据集等问题,本文提出一种基于模糊测试和集成学习的XSS攻击检测方法,加入里安全向量生成器解决了不平衡数据集问题;通过模糊测试技术检测XSS测试用例,去除了冗余的无效向量进而提升检测效率;最后针对单分类器检测效率低的问题,采用了集成学习方法对XSS攻击进行检测。
1方法设计
1.1 XSS样本预生成
通过XSS Filter Evasion Cheat Sheet收集到XSS测试用例作为初始样本,XSS Filter Evasion Cheat Sheet是由OWASP[12]组织发布的XSS过滤备忘单,它记录了包括基于属性、事件、HTML标签、CSS、XML等各种类型的XSS测试用例,同时也包括了XSS测试用例加前缀、字母变换大小写、转编码等各种方式来实现服务器端的绕过。
随着网站过滤的机能逐渐强大,部分XSS测试用例在低版本的浏览器能够成功攻击,在高版本的浏览器中会被过滤掉,本文将通过模糊测试[13]的方法对无效的测试用例进行过滤,基于模糊测试和XSS测试集的XSS攻击样本生成的流程如图1所示。

图1 XSS攻击样本生成流程
模糊测试的步骤如下:
(1)输入初始XSS测试集(XSS Filter Evasion Cheat Sheet)作为模糊测试的测试用例;
(2)模拟攻击方式,将测试用例输入至网站中并执行操作;
(3)监测攻击结果,看是否有弹窗显示用来判断是否进行了XSS攻击,若判断攻击成功则保存XSS测试用例,作为XSS攻击样本,若攻击失败则遗弃;
(4)不断进行重复(2)、(3)步骤,直至XSS测试集中的测试用例全都检测完毕,算法结束。
目标程序DVWA用来检测Web应用是否安全,初始界面是一个具有留言簿的界面,如图2(a)所示,通过输入XSS测试用例,输入到"message"下,提交后得到新界面,不断输入XSS测试用例,判断浏览器是否弹出弹窗,弹窗如图2(b)所示,若未出现弹窗则证明此XSS测试用例无效,若出现弹窗,则证明此XSS测试用例攻击用例有效,直至模糊测试结束,最终得到预生成的XSS攻击样本X。
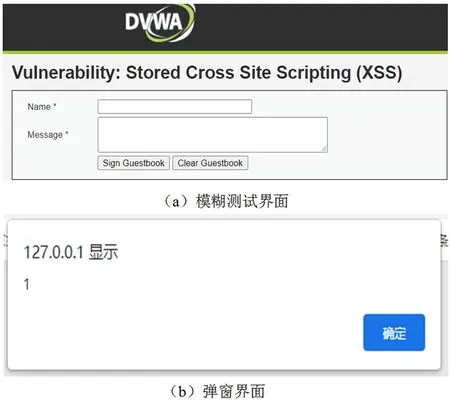
图2 模糊测试检测XSS测试用例
1.2 安全向量生成器
生成的安全向量保持在128个字符之内,其中的类型包括:
(1)仅包含大写或小写的字符串;
例如:kikDfuPLasVpSDqfKLMUTbyDAssjedEhphsOSPUnxO
(2)包含所有字母和数字的字符串;
例如:BqAoxOrvaovydRv8QuQmQvoAk6hUbTaUFx18al7jYZ
(3)包含所有字母、数字和特殊字符的字符串。
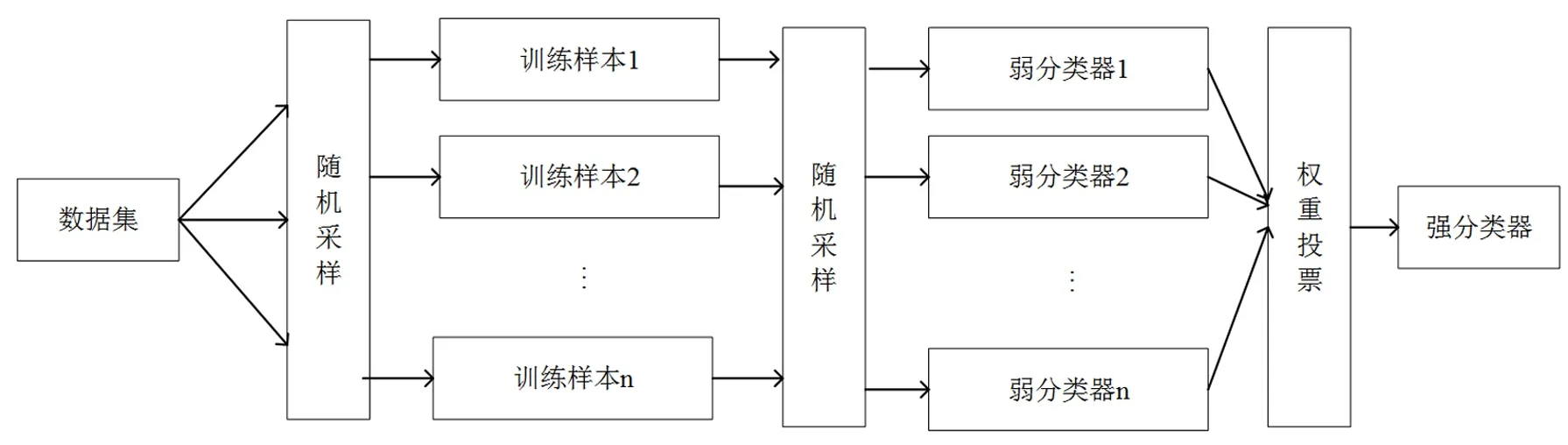
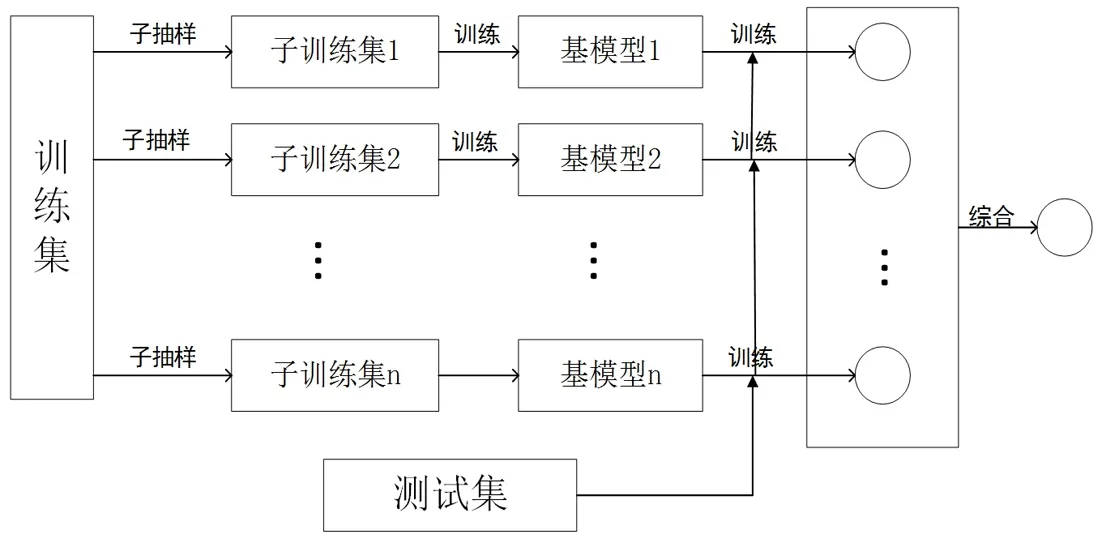
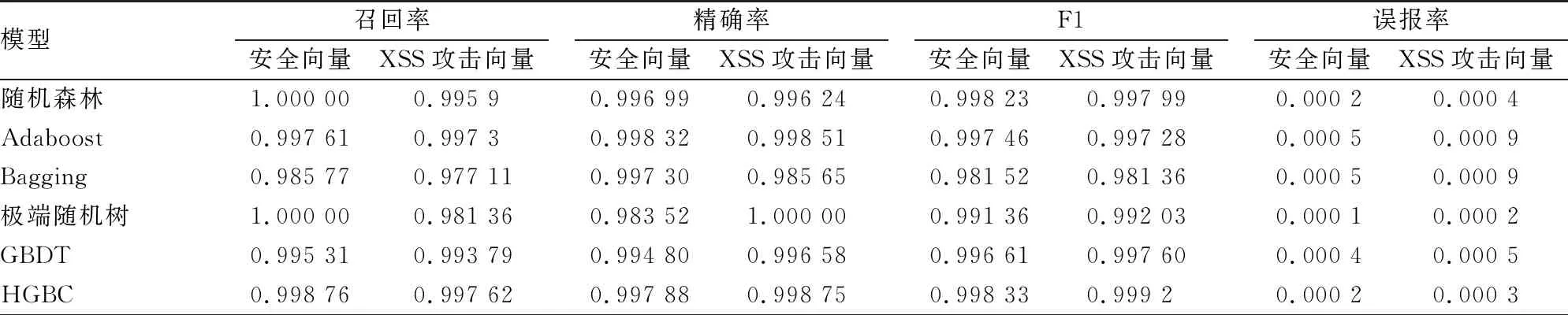
例如:>!d[;p02LzJ,`5"hVCqAPXonVtrQ]L9`JBD=8L 生成的安全向量取决于XSS攻击向量的个数,用来保持XSS和数据集的安全样本之间的平衡,平衡的数据集用于训练和测试模型。安全向量生成器如图3所示: 图3 安全向量生成器 在集成学习[14-15]中,基础模型有3种组合方式。Bagging: 在bagging (bootstrap聚合) 中,弱学习算法适用于小样本数据集,并对所有学习者进行平均预测,装袋将减少差异。Boosting: 它是一种迭代方法,在boosting样本权重的基础上根据前面的分类进行调整。Stacking:一个模型的输出作为另一个模型的输入,基于所使用的模型,堆叠将减少方差或偏差。 1.3.1基于随机森林的检测模型 随机森林是多重决策树集合的算法,采用决策树作为基学习器,每个决策树都是数据集的一个子集,通过对M个XSS攻击样本集和安全向量样本集中抽取m个特征和样本进行训练,共进行k轮抽取,形成K个学习器,每颗决策树的特征是由对当前决策树分类节点进行部分抽样而不是建立每颗决策树进行抽样,通过决策树算法对XSS攻击样本和安全向量样本进行训练。Sklearn的随机森林分类器依据"少数服从多数"的原则进行投票,采用大部分决策树得到的结果作为分类输出结果,随机森林模型的优点是不需要设置过多超参数,即可判断每个特征与预测标签的相关性,随机森林模型流程如图4所示。 图4 随机森林模型 1.3.2基于极端随机树的检测模型 极端随机树(Extremely randomized trees)是由于随机森林中出现随机有放回的取样导致样本不能被充分利用,从而引起各个基分类决策树之间的相似程度高。它与随机森林分类器相比,只是特征是随机选择的,极端随机树采取对全部数据集进行训练,在某种程度上比随机森林得到的结果更加好,因为该模型在每次分裂或分枝时都会随机选择一个特征子集进行分枝特征选择,而且该模型不需要选择最佳阈值,而是采取随机阈值进行分枝,这种增加的随机性有助于创建更多彼此独立的决策树。 1.3.3基于Adaboost的攻击检测模型 Adaboost集成学习算法是一种迭代算法,它是提升方法中最为广泛的一种形式,其核心思想是通过加权投票的方式把组合弱分类器起来,产生最终的预测进而构成一个强分类器。它通过对个体分类器有序地训练来进行提升,而且各个分类器地结果是互相关联的,后一个分类器的分类过程会受到前一个分类器的影响,所以每一个分类器的权重不一样,每一次推举迭代(boosting iteration)中,数据修改(data modifications)会把权重,分配给每一个训练样本。在迭代开始的时候,所有的样本权重都被设置Wi=1/N,这样第一步迭代就是在原始数据上简单训练一个弱分类器,在后续的迭代步骤中,样本权重会被单独修改,通过增加当前基分类器错分样本、比较难预测样本的权重,使得下一个分类器去关注错分样本和权重较高的难分样本上,从而提高集成分类器的精度,并支持向量机作为基分类器,通过Adaboost集成学习的方法检测XSS攻击向量,AdaBoost模型流程如图5所示。 1.3.4基于SVM的Bagging检测模型 本文使用SVM算法可以作为基学习器,支持向量机能够高效的实现训练样本和预测样本的结合,简化了分类问题,具有较高的鲁棒性。Bagging方法是采样生成n个训练集,每个训练集生成各个基学习器,n个训练集共得到n个模型,对分类算法预测,依据投票原则把n个弱学习器投票数最多的类或者类之一判定为最终类别,基于SVM的Bagging模型流程如图6所示。 图6 Bagging模型 1.3.5基于梯度提升树的检测模型 梯度提升决策树算法(Gradient Boosting Decision Tree,GBDT)是集成学习Boosting中的一种。该算法通过向前分布式迭代,把迭代中损失函数达到最小作为目标,每次迭代通过沿着负梯度方向调整回归树,逐渐减小残差值,不断对基学习器进行学习和调整对应权重,最终获取一个使得损失函数值达到最小的基学习器。 1.3.6基于直方图的梯度提升分类的检测模型 通过使用直方图,可以进一步调整树构造算法。把决策树作为HGBC的基分类器,HGBC可以处理缺失值,因此对缺失值(NaN)具有原生支持。在训练过程中,树种植者根据潜在增益在每个分割点学习具有缺失值的样本是应该去左子树节点还是右子树节点。在模型预测时,把缺失值的样本重新分配给左子树节点或右子树节点,更好的处理了缺失值的问题。如果在训练期间未出现相关特征的缺失值,则把相关缺失值的样本映射到具有更多样本的子节点。本文通过直方图梯度提升分类模型来进行建模,并通过网格搜索算法进行模型的调优,促使模型达到最优的效果,有效避免了过拟合。 XSS有效载荷比正常有效载荷长度更长,由于其中包含了恶意代码,因此敏感词、敏感字符和有效载荷的长度是识别XSS的重要要素,XSS有效载荷可能会利用重定向链接,将恶意代码隐藏在重定向界面里,通过识别重定向链接来跳转并执行恶意代码,一些协议可能会出现在一个负载中。包含7个维度:URL的长度,HTTP的个数,特殊关键词,闭合敏感符号,空格字符,大写字母,数字字符,攻击样本作为黑样本达打标为1,安全样本作为白样本,打标记为0。 表1 特征名称及说明 描述了获取XSS特征以及标签后,根据3.2特征选择采用不同的机器学习算法进行模型训练、测试。包含的集成学习模型有决策树、随机森林、支持向量机以及由基本分类器集成的极端随机树、AdaBoost、梯度Boosting、Bagging、直方图的梯度提升等。获取训练好的模型以后,混淆矩阵值用于比较和评估模型。通过使用混淆矩阵可以计算以下值: 精确率: (1) 准确率为分类的准确度,即: (2) 召回率为预测正的正样本占总正样本的比例,即: (3) 误报率为预测为正的负样本占总负样本的比例,即: (4) F1值是召回率与精确率的一个均和调值,是对召回率与精确率的一个综合评价,即: (5) 其中,FN是被判定为负样本的正样本的数量;FP是被判定为正样本的负样本的数量;TP是判定为正样本的正样本的数量;TN是判定为负样本的负样本的数量。 图7(a)和图7(b)代表了SVM分类器对XSS攻击样本和安全样本的特征分布情况,为了平衡数据集,安全样本的数量保持和攻击样本的数量一样。数据集包含了60 674个样本,其中是安全向量样本数量为30 337个,XSS攻击样本的数量为30 337个。总样本以8:2比例划分为训练样本集(24 270)和测试样本集(6 067)。 以下实验评估了集成学习技术中随机森林分类、极端随机树(ExtraTrees)、AdaBoost、以SVM为基学习器的Bagging、梯度提升(GBDT)、和基于直方图的梯度提升模型的XSS检测率。表2是所有模型中混淆矩阵的值,表3比较了所有模型的性能指标,表4比较了所有模型的交叉验证得分以及模型的交叉验证的平均得分。从结果可以得出结论,所有集成方法都表现良好,并且在所有模型中均达到98%以上的精度,表现最优的为基于直方图的梯度提升分类模型和极端随机树模型。 表2 模型中混淆矩阵 表3 性能指标的比较 表4 交叉验证分数的比较 为了避免不平衡数据集问题,设计安全向量生成器用来保持XSS和数据集的安全样本之间的平衡;通过模糊测试技术检测XSS测试用例,去除了冗余的无效向量进而提升检测效率;最后使用集成学习方法包括随机森林分类、极端随机树(ExtraTrees)、AdaBoost、以SVM为基学习器的Bagging、梯度提升(GBDT)和基于直方图的梯度提升模型检测XSS攻击向量和XSS安全向量,利用混淆矩阵评估这些模型的性能。结果显示所有的集成学习模型在检测XSS攻击和安全向量上都表现出较好性能。在基于直方图的梯度提升分类模型和极端随机树2个模型中,更是达到了最高的0.998 4的精度。但是研究仍存在不足之处,仍需要进一步的研究完善,未来将进一步丰富XSS攻击样本集,从而达到覆盖性更强的效果,并尝试扩展到检测其他Web应用程序攻击(例如SQL攻击、DDos攻击)。
1.3 基于集成学习方法的攻击检测模型
2实验与结果分析



3结论
猜你喜欢
铁道通信信号(2020年6期)2020-09-21 09:23:22
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
传感器与微系统(2018年7期)2018-08-29 00:44:18
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01 02:54:29
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
