
基于PointNet++的机器人抓取姿态估计
2023-06-21 01:09阮国强曹雏清
仪表技术与传感器 2023年5期
阮国强,曹雏清,2
(1.安徽工程大学计算机与信息学院,安徽芜湖 241000;2.哈尔滨工业大学芜湖机器人产业技术研究院,安徽芜湖 241000)
0 引言
智能机器人在执行抓取任务时需要获取目标的位姿,而常用的位姿获取方法有经验法和深度学习方法。经验法可分为基于模型的方法和数据驱动的方法:基于模型的方法主要针对模型已知物体,即预知数据或者通过测量获得的3D模型[1-2],而在实际应用中很难了解物体精确的3D模型;基于数据驱动的方法[3-7]主要是利用监督学习获取目标特征,如V. Ferrari等[8]提出使用由k个连接的直线轮廓线段作为局部特征用于物体类检测,由于人工提取特征通常只针对特定场景,所以该方法的泛化性不够强。基于深度学习方法是通过大量图片数据集训练出映射模型,通过该模型可将图像数据映射到1个或多个抓取位姿表示,如康奈尔大学的I.Lenz等[9]设计了一个以RGB-D图像为输入的两级级联神经网络用于机器人抓取,以获取目标的最优抓取位置;华盛顿大学的J. Redmon等[10]将目标检测的one-stage思路引入抓取检测问题中,输入RGB图片后经过Alex-Net模型直接输出抓取框的位置;中科院自动化所的闫哲等[11]将目标检测引入Lenz的方法中,先获取图像中目标物体的类别和位置,再去获得物体的最佳抓取位置;文献[12]提出一种DenseFusion的通用框架,用于从RGB图像和深度图像中估计物体的6D位姿。这些方法将可能的抓取空间限制为平面抓取,而面向平面抓取会导致大量可能的机器人抓取和机器人的全运动学能力被忽略。考虑到从图像信息中获取物体的姿态再执行抓取时抓取位置的选择不当导致抓取失败,因此,本文提出基于点云[13-15]直接预测抓取姿态的网络,该网络从目标场景的点云出发,直接预测场景中物体的抓取姿态。由于直接对点云进行姿态估计的计算量较大,因此本文将7自由度的抓取姿态问题简化成4自由度问题解决,并实现直接从杂乱、部分遮挡的场景中估计物体的抓取姿态。
1 抓取姿态分析
在执行抓取任务中,获取目标场景中由物体的3自由度的空间平移、3自由度的空间旋转和抓取宽度所组成的7自由度抓取姿态是较为不易的,这是因为这种抓取分布是不连续、不平衡的,且由于物体之间存在相互遮挡的现象从而使得抓取分布不准确。
为了解决这个问题,本文的抓取姿态获取是利用二指夹具的抓取特点将抓取范围约束在一定范围内,再通过PointNet++[16]网络获取夹具与物体的接触点(p),夹具接近方向(m)、基线方向(n)和抓取宽度(w),从而将抓取姿态的7自由度问题转换成4自由度问题即p,m,n,w这4个方面的问题。通过确定p、m、n、w,来获取7自由度抓取姿态G=[g|||w],g为接触点对应的位姿。夹具的具体抓取表示如图1所示。

图1 二指夹具抓取表示
与估计抓取姿势的其他方法相比,由于将抓取姿态约束在二指夹具的范围上从而降低抓取的维度,简化了学习过程,进而使训练的速度变快,同时也提高了预测抓取姿势的精度。在测试时,我们可以通过采样覆盖场景或对象的整个可观察表面接触点来获取抓取方案,从而很好地预测7自由度抓取姿态。由于PointNet++网络具有有效的处理点云和在局部区域中按层次提取点及其特征的能力,且这种预测抓取方式可以与输入点云中的点相互关联,所以在进行抓取姿态估计时使用了这些功能。
2 抓取网络
面对由多个未知物体所组成的场景,从多个角度生成7自由度抓取的问题中,本文使用三维点云数据作为输入并生成相应的抓取姿态。由于需要对点云信息进行特征提取,故本文采用PointNet++网络作为主干网络,并提出了一种抓取姿态估计算法,该算法获取目标抓取姿态的4自由度信息从而计算出抓取姿态。接触点的思路借鉴了文献[17]提出的Contact-GraspNet并在其基础上进行了改进优化,本文在Contact-GraspNet的基础上将估计的抓取姿态和宽度加入到训练中进行优化。算法结构如图2所示。算法网络分成特征提取、特征维度调整、位姿获取。

图2 算法网络结构
2.1 点云特征提取
先对场景点云进行特征提取,其提取过程如下:首先使用最远点采样 (FPS)方法对目标点云数据进行采样,使用球分组方法对采样到的点进行分组,然后使用PointNet网络对每一组点进行特征提取,再将提取到的特征进行最大池化,从而获取目标点云的全局特征。
2.2 特征维度调整
将提取到的全局特征使用向上插值和拼接,使获取的全局特征传播到采样的点上,并使用多层感知器(MLP)调整输出的特征维度。
2.3 位姿获取
将采样得到的点作为p,并使用接触点对应的特征去预测m、n、w以及对应的成功抓取率(d)。先利用获取的m和n计算出抓取的旋转矩阵S,再利用获取的p、m、n计算出抓取的平移矩阵T,最后利用S、T、w来计算物体的抓取位姿。
计算抓取的旋转和平移矩阵的公式如下:
(1)
(2)
式中:p为夹具与物体的接触点;m为接近方向向量,|m|=1;n为基线方向向量,|||n|||=1;l为夹具基线到夹具底座的恒定距离。m和n的获取将在3.2节中详细阐述。
3 模型训练
3.1 数据集的生成
对于模型训练和测试的场景数据是由ACRONYM[18]数据集和ShapNetSem[19-20]网格数据集通过在随机稳定姿势下进行放置生成的10 000个桌面场景。
其中,ACRONYM数据集包含1 770万个平行夹具抓取,跨越262个不同类别的8 872个对象,每个对象都标有从物理模拟器获得的抓取结果;ShapNetSem网格数据集是一个注释丰富的大规模3D形状数据集由12 000个模型组成,分布在更广泛的270个类别中。本文所用的实验场景都是由数据合成而来,不是真实场景,且每个训练场景中的数据都包含夹具与场景中物体的接触点、成功率和抓取位姿等信息,用于后续的模型训练。
3.2 训练过程
抓取网络模型的训练在服务器(操作系统:Ubuntu 18.04 LTS,CPU:Intel Xeon 4210R 2.4GHz,GPU:NVIDIA GeForce A40)上进行。本文从随机生成的10 000个桌面场景中随机选择9 000个作为训练集,并使用Adam优化器在训练过程中对参数进行迭代优化,该优化器的优点在于实现简单、计算高效,对于内存的需求不大,且能够自动调正学习率,适合应用于大规模的数据及参数的场景。
训练过程中,优化器初始学习率为0.001,逐步衰减率为0.000 1,epochs为16。
将场景中的物体索引和ShapNetSem网格数据集中对应的网格模型渲染成点云集C={c1,…,cn},并给每个点赋予成功抓取率,
(3)
式中:pj∈C是非碰撞真实的抓取接触点;r=5 mm是接触点的最大传播半径。
由式(3)将点云集C分成两部分:负接触点C-={ci|||di=0},即在传播半径范围之外的点;正接触点C+={ci|||di=1},即在传播半径范围之内的点。对于正接触点C+可以得到每个点对应的旋转矩阵Si和平移矩阵Ti,公式如下:
(4)
式中j为距离正接触点最小距离的真实抓取点的索引。
使用PointNet++中的特征提取层和特征传播层来构建非对称的U型网络。该网络取20 000个随机点作为输入,为了确保GPU有足够的内存,所以仅从这些输入中预测2 048个最远点的抓取点,且预测的抓取点能够覆盖到整个场景中。该网络有4个输出分类,针对每个接触点输出d、a、b和k,根据4个分类的输出数据计算出所需的抓取表示。将预测的宽度w∈[0,wmax]分成10个等距抓取框k,用以抵消数据不平衡。wi由成功抓取率最高的k的中心值表示。已知m和n相互正交,使用施密特正交归一化将预测结果加入到训练中,其公式如下:
(5)
由式(5)可知,预测的m是与n正交的分量,并经过正交归一化进一步降低了预测抓取表示的维数,加快了对旋转矩阵的获取。
3.3 损失计算
使用二元交叉熵的方法来评估每个预测接触点c的成功抓取率d。对于抓取姿态的预测仅在正接触点C+处进行评估,将预测到的数据与7自由度抓取姿势G结合,因此定义了5个关于夹具的3D点O,并且考虑到夹具的对称问题,在取夹具的3D点时使0用对称和非对称的两种方法获取夹具的关键点,并对获取到的关键点使用式(6)进行变换得到真实和预测的抓取姿势,关键点如图2中圆点所示。
(6)
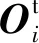
(7)
式中:x为正接触点C+的数量;并使用预测的d加权到每个预测抓取点到真实抓取点的距离。
在Contact-GraspNet的基础上还增加了抓取估计的损失计算,使用交叉熵损失函数对抓取姿态进行损失计算:
(8)
当d=1时,该抓取为成功抓取;反之,d=0时,为失败抓取;g为接触点对应的位姿。
训练过程中所使用的损失公式能够学习真实抓取分布的不同模式;由于d是对每个接触点进行加权使得将接触点分类和抓取姿态预测结合,只有当预测的抓取姿态接近真实的抓取姿态时接触点的成功抓取率才会增加;错误的抓取预测产生在远离真实抓取的区域,可以避免更大的损失产生。对于抓取宽度的预测上,使用加权二元交叉熵,将框的损失和大小成反比的关系加权到损失计算中。总损失为:
l=α(lm+ln+loff)+βladd-s+λlg
式中:α=1;β=10;λ=0.5。
4 实验结果和分析
在整个网络训练完成后,本文的算法和Contact-GraspNet算法的损失值变化如图3所示。
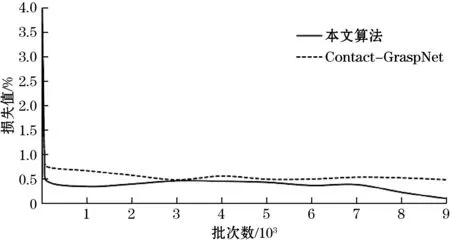
图3 训练损失对比
由图3可知,尽管本文的算法比Contact-GraspNet的初始损失要高,但是在训练过程中本文算法的损失收敛速度更快,损失值也更低。在训练完成后需要测试训练网络模型的优越性,此时从1 000个测试场景中随机选取500个场景进行测试,并比较每个场景中所有成功抓取率的平均值,结果如图4所示。

图4 平均成功抓取率对比
由图4可知,本文的算法在整个场景中所有抓取的平均成功抓取率比Contact-GraspNet更高。虽然本文算法的测试和训练所使用的场景数据都是通过模型合成的数据,但是在真实的场景进行测试时仍然可以有效生成抓取姿态。利用Kinect相机获取真实场景的RGB和深度图,再对现实场景中物体的进行抓取姿态预测。Kinect相机如图5所示,预测结果如图6所示。

图5 Kinect相机

图6 真实场景测试结果
在使用相同数据集的情况下,与其他抓取姿态估计算法进行现实场景中物体的成功抓取率对比,比较结果如表1。

表1 不同算法的物体成功抓取率 %
从表1中可以观察到,本文的算法与文献[17]、文献[21]和文献[22]相比明显预测的平均成功率更高,虽然本文的算法是在Contact-GraspNet的基础上改进优化而来,但由于将抓取过程中获取物体的宽度以及抓取的预测姿态加入到网络中,使得在训练过程中可以进一步对抓取姿态进行筛选使得对部分遮挡物体的抓取姿态获取结果更好。
5 结束语
在执行抓取任务过程中所遇到的物体杂乱分布、部分遮挡问题,基于PointNet++网络改进了一种抓取姿态估计算法。本文使用二指夹具来约束执行抓取任务的抓取空间,从而将获取7自由度抓取姿态问题转变成获取p,m,n,w的4自由度问题,加快了学习效率。本算法既可以直接对目标场景进行整体的抓取估计,也可以结合场景的实例分割实现不同物体的精确抓取估计。实验结果表明,本算法仅通过对合成数据的学习就可以直接迁移到现实场景进行测试,该算法可应用于家庭服务机器人的抓取任务,接下来的工作需要搭建机器人抓取平台进行实验用以验证算法的实时性和鲁棒性。
猜你喜欢
装备制造技术(2021年1期)2021-05-21
哈尔滨轴承(2021年4期)2021-03-08
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
制造技术与机床(2017年10期)2017-11-28
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
湖北工业大学学报(2016年5期)2016-02-27
机电产品开发与创新(2014年6期)2014-03-11
