
一种基于注意力机制的YOLO 缺陷检测算法
2023-06-20 12:19于龙振李逸飞朱建华赵谦王志宪
青岛科技大学学报(自然科学版) 2023年3期
于龙振 ,李逸飞 ,朱建华* ,赵谦 ,王志宪
(1.青岛科技大学 经济与管理学院,山东 青岛 266061;2.九州工业大学 计算机科学与工程研究生院,福冈 北九州8 040000)
缺陷检测的深度学习算法主要可分为两种类型:基于分类的算法和基于回归的算法[1-3]。基于分类的算法以R-CNN 系列为代表,包括R-CNN、SPP-Net、快速R-CNN、R-FCN、Mask R-CNN 等。FAN等[4]、JI等[5]、ZHANG等[6]分别对木材、齿轮、金属等的表面缺陷进行了检测。由于采用两阶段处理,即特征提取和对象分类,所以R-CNN 算法一般需要较高的算力,故该算法检测速度相对较慢。而基于回归的算法的特点是只做一轮处理,即同时完成特征提取和对象识别,因此速度比较快。REDMON等[7]提出了YOLO(you only look once)算法,这是一个基于回归和端到端的算法。到目前为止,YOLO 已经发展成YOLOv1 至v5 的系列算法,而其他代表性的算法还包括SSD、Corner Net等。在上述基于回归的算法中,YOLOv3[8]是使用最广泛的算法之一,基于YOLOv3,JING等[9]、LI等[10]和DU等[11]分别对织物、PCB 板、路面等进行了表面缺陷检测。
本研究提出一种高效的缺陷检测算法,该算法对原版YOLOv3提升了注意力。其主要思路在于工业相机的拍摄角度和缺陷特征相对固定,而注意力机制的提出是基于在神经网络的输入和输出之间存在全局依赖的关系[12],这启示本研究将注意力放在相对固定区域缺陷检测上。本研究对原版YOLOv3从三方面提升注意力:首先是采用CZS算法,重新组合图像的缺陷区域并删除无用的识别区域;其次是采用裁减主干网络算法,裁减掉原版YOLOv3主干网络中不必要的识别尺度网络层;最后是采用数据增强算法,添加图像噪音和使图像旋转,扩增训练数据集。通过以上改进,使算法做图像识别和训练的计算量减少,使缺陷图像的检测效率得到提升,本研究并进行了实验验证。
1 算法
1.1 改进的YOLO 缺陷检测算法原理
与经典的深度学习物体检测算法相比,本研究解决的一类缺陷检测问题,其突出特点在于图像上的识别区域是可预测的。如图1示,图1(a)为正常焊接效果,图1(b)为缺陷焊接效果,两副图像拍摄角度是固定的。事实上,本研究只关心2张照片的红框缺陷检测相关区域,只需识别这个区域,就能确定该零件是否有缺陷,原始照片的其他区域可以被相应地删除。

图1 正常的焊接和带缺陷的焊接Fig. 1 Normal welding and defective welding
此外本问题来源于工业现场,而解决方案也要再应用于工业场景,因此有精度和效率的要求,要尽量的优化算法、提高精度和缩短检测时间。据此本研究提出基于注意力机制的YOLOv3缺陷检测算法整体框架如图2示。

图2 缺陷检测算法整体框架Fig. 2 Overrall framework of the defect inspection algorithm
该缺陷检测算法总体包括训练算法和推理算法两部分,此处只给出训练算法,推理算法主要步骤相当于训练算法的子集。本算法对YOLO 注意力的改进主要体现在CZS算法、裁减主干网络算法和数据增强算法这3个子算法。在数据预处理阶段调用CZS算法,能够将原始大图像转变成只留待检测区域的小图像,把图像上的无效检测区域提前处理掉了,能够提升注意力、节省算力、提升检测效率;在图像检测阶段,基于裁减主干网络算法,能够把通用型的原版YOLOv3网络转变成针对应用场景的精简网络,裁减掉不必要的检测尺度,能够有效减少网络复杂度,使训练的网络更专注于针对性的检测尺度,减少训练时间,也提高检测速度;在训练算法中还使用了数据增强算法,这对样本有限的网络训练格外重要,能够大大增加样本量和样本多样性,使训练的网络具有更强的甄别缺陷的能力。样本量的大幅增加,也会使网络训练时间大幅增加,而结合前述两个优化子算法,使YOLOv3网络训练压力在升降之间取得一定的折中。3个子算法的具体细节放在1.2到1.4节中依次介绍,而在后文第2节实验分析中,对添加这3个子算法是否必要,分别添加前后的总算法性能做了详细的数据对比分析,表明了改进注意力的有效性。
算法:对缺陷检测网络训练
输入:原始样本集{(ai∈A,bi∈B)},1≤i≤I。其中ai表示第i张图像,该图像对应的缺陷描述文档是bi,在bi上记录着ai上的待检测区域集Ki。A为图像集,B为缺陷描述文档集。
输出:训练好的YOLOv3模型。
1) 对任意ai∈A(1≤i≤I),反复执行:
1.1)读取bi,得ai的Ki。
1.2)对Ki执行CZS算法,得新图像a°i和对应缺陷描述文档b°i。
1.3)分别对ai、bi和a°i、b°i执行数据增强算法,合并得增强样本集a°°i、b°°i。
2) 根据研究情境,使用裁减主干网络算法,把YOLOv3的主干网络Darknet-53 裁减为Darknet-39。
3) 使用增强样本集{(a°°i∈A°°,b°°i∈B°°)},1≤i≤I,训练2)后的YOLOv3。
4) 当达到精度要求或训练迭代次数上限,则训练结束。得训练好的YOLOv3。步骤结束。
1.2 CZS算法
注意力机制主要是对系统的输入和输出之间的关系进行建模,不受距离的限制[12]。对于缺陷检测,工业相机的拍摄角度是相对固定的。因此可以预先定义可能的缺陷区域,只从特定区域提取特征。注意力机制的代表形式之一是自我关注机制,原义是指通过关联序列中的不同位置来计算序列语义表示。在YOLOv3的预处理中加入了相当于自我关注机制的图像预处理操作,称之为CZS 算法(cut,zoom and splice),如图3。蓝色方框代表切割区域,绿色方框和红色方框代表两种缺陷标记区域。左边的原始图像的1~8号区域对应右边的图像拼接区域。整个过程涉及3个步骤。从原图像中剪切出若干需检测区域,将各待检测区域缩放到相同大小,然后再将这些区域拼接成新的图像。

图3 CZS算法Fig. 3 CZS algorithm
α代表一个扩展系数,取值在1到2之间,意味着剪切区域的面积是缺陷标记区域的1到2倍。为了保证剪切区域能够包含缺陷标记区域,剪切区域应该比缺陷标记区域略大。三元操作符 (逻辑表达式)“? 真操作:假操作”意味着当缺陷标记区域接近图片的边界时,剪切区域左上角相应延长。
步骤2:缩放算法(zoom)。是将图像上的所有剪切区域缩放到相同的尺寸,以便能够被宽度和高度均为416像素的新图像完全容纳,这是YOLOv3输入图像的标准尺寸。如果已知图像上的缺陷标记区域的数量为Nl,那么新图像的一行或一列中可容纳的剪切区域的数量均为Nrow=Ncol=ceil(sq rt(Nl));剪切区域应被缩放的目标尺寸宽和高均为wz=hz=;而缩放系数为
步骤3:拼接算法(splice)。是将多个剪切区域经过缩放操作后组合成一张新图像。它主要涉及两种算法,第一种算法是将剪切区域映射到拼接区域;第二种算法是将标记区域映射到拼接区域。
对于第一种算法,首先根据xc值将剪切区域由小到大排列。如果两个剪切区域的xc值相同,那么按照yc值从小到大排列。假设一个剪切区域被排序为No,则计算中间变量nrow=(No%Ncol≠0)(No//Ncol+1):(No//Ncol)和ncol=(No%Ncol≠0)(No//Ncol):Ncol,那么在新图像中该区域左上角的宽度和高度均为wd=hd=wz、x坐标为xd=(ncol-1)×wz,以及y坐标为yd=(nrow-1)×hz。以上公式中//代表整除操作,%代表整除取余操作,“条件? 为真执行:为假执行”是条件三元操作符。
以上完成了CZS算法,如果生成的新图像还有空白区域,可把这些空白区域像素点填充为0处理。
1.3 裁减主干网络算法
对应CZS操作后的新图像,YOLOv3主干网络可进行裁减,以更有针对性地检测缺陷区域。图4为原版及裁减部分主干网络的YOLOv3算法,原版YOLOv3的主干网络包括53层,称为Darknet-53。YOLOv3的特征图有3 种检测尺度,尺度13×13像素对图像上的大尺寸物体的识别有更好支持,尺度52×52像素对图像上的小尺寸物体的识别有更好支持,而尺度26×26像素对图像上的中等尺寸的物体识别有更好支持。
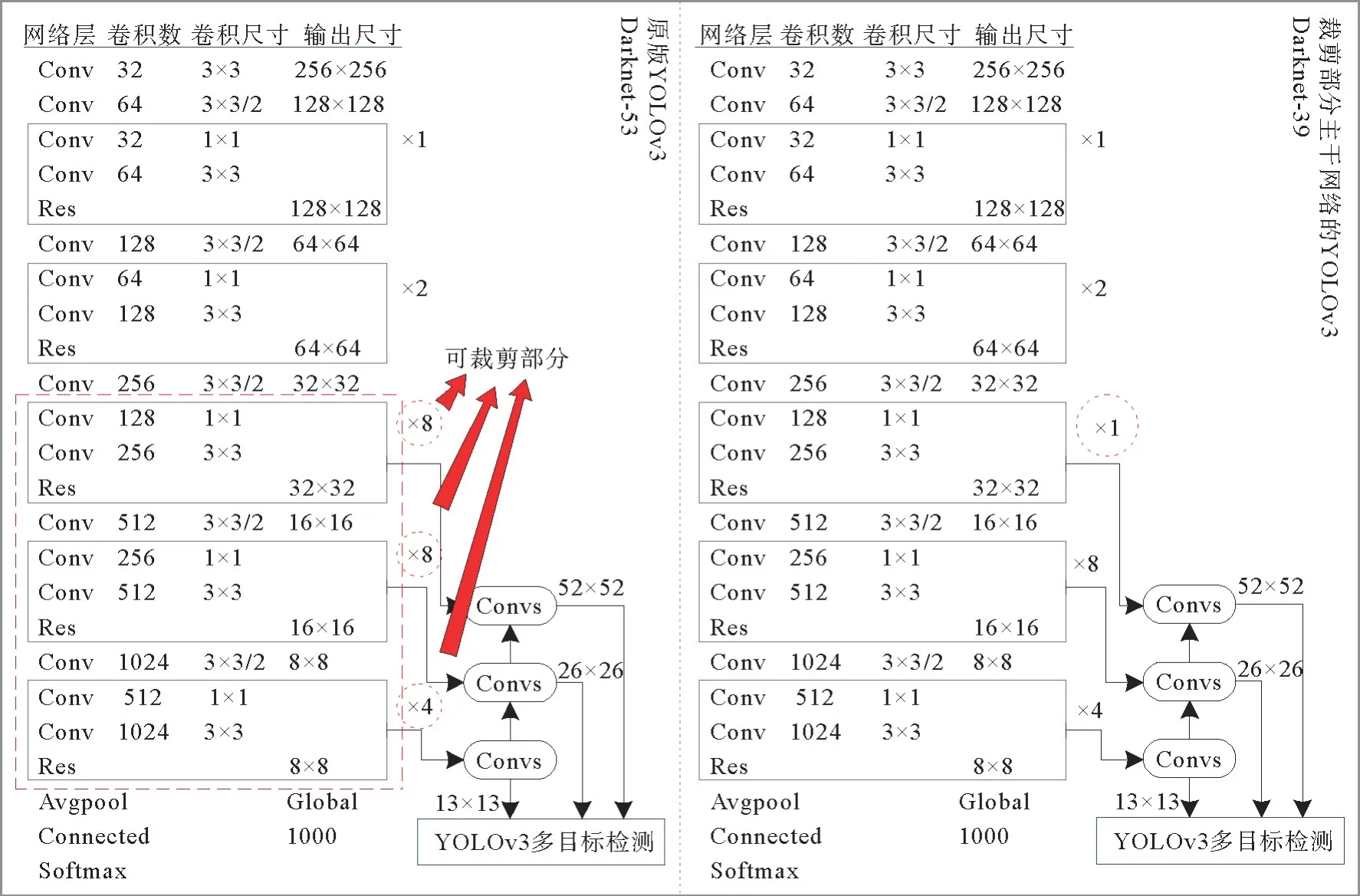
图4 原版YOLOv3 Darknet-53和裁减部分主干网络的YOLOv3 Darknet-39(实验情景)Fig. 4 Original YOLOv3 Darknet-53 and YOLOv3 Darknet-39 by tailoring parts of the backbone network (experimental scenario)
根据缺陷检测的案例背景,主干网络可以相应的进行裁减定制。以汽车橡塑件的缺陷检测为例,由于检测照片中橡塑件的缺陷尺寸适中,因此可以简化小尺度检测网络。再以PCB 焊点缺失检测为例,由于焊点细密,且布局合理,所以可以对大尺度检测网络裁减。综上,具体判断算法如式(1)和(2)。
tailor函数表示裁减网络的函数。52×52表示YOLOv3主干网络中的小尺度检测网络层,13×13表示YOLOv3 主干网络中的大尺度检测网络层,each函数表示取得每一个待检测标记区域,N表示图像上待检测标记区域的总数目。wi和hi分别代表第i个待检测标记区域的宽度和高度,而W和H分别代表图像的宽度和高度。
在第3节实验案例中,52×52小尺度网络层被裁减了。具体如图4所指,原版YOLOv3的第三步下采样层要执行8轮重复的卷积残差操作,而在本模型中,删除了其中7轮,即裁减掉了14个卷积层。因此主干网络从53层缩减为39层,变成Darknet-39。
1.4 数据增强算法
为了增强注意力,提高深度学习网络的识别精度,在原始训练数据集规模不大的情况下还需要实施数据增强算法,以扩大训练数据集,本研究主要基于以下2个步骤的算法。
步骤1:在原始图像的缺陷标记区加入随机噪声,将正常区域变为带噪声区域或故障缺陷区域。算法原理如公式(3),Ki,j代表第i张图像的待检测区域集中的第j个待添加遮挡区域(噪声)代表添加的遮挡,rd是取的0~1之间的随机数。则有遮挡1/3区域、遮挡当前整个区域、以及遮挡当前和下一个编号的2个区域,这3种添加遮挡的概率各占1/3。
如图5,用矩形遮盖模拟标记区域表面的噪声或缺陷。其位置、大小和颜色可以随机设置。图5(a)表示正常;图5(b)用矩形遮盖了一个标记区1/3区域,相当于增加了一些噪声,要保证网络训练能识别这样的正常标记区;图5(c)和(d)用矩形完全遮盖一个或两个标记区来模拟缺陷。基于该步骤,可以从1张图像扩增为4张图像。
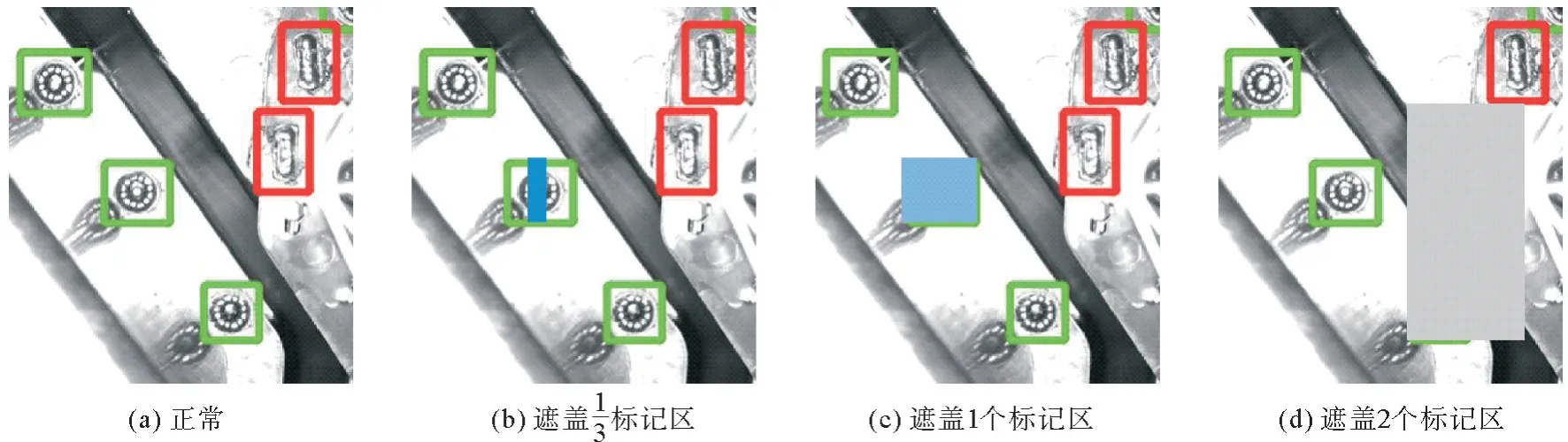
图5 添加噪声的演示效果Fig. 5 Demonstration of noisy or missing faults
步骤2:是将图像旋转90°、180°和270°,并水平翻转。这相当于从1张图像扩增为8张图像。算法原理如公式(4)表示对第i张图像进行旋转和翻转操作之后生成的图像集,rotate90°,180°,270°表示依 次旋转的角度,flip_horizontal表示水平翻转操作。
采用自动化数据集增强操作,可以提高训练质量,并有效减少人工作业。本研究案例初始只有630张样本照片。而通过脚本自动化的CZS算法和数据增强算法,训练和测试的最终数据集达到40 320张图像。
2 实验分析
2.1 实验设计
案例研究从某汽车橡塑件生产企业获得实验数据,该企业是国内多个知名汽车品牌的特级零部件供应商。因此该算法的成功实验将对同行业具有示范意义。借助于工业相机的10个固定拍摄角度,对若干种产品收集了630张原始样本照片,每个角度63张照片。每张照片都是1 600×1 200像素分辨率和8位深,共有16种类型的缺陷标记,正常标记和缺陷标记的比例约为9∶1。图6为对原始图像旋转和水平翻转的演示效果图。开展研究的深度学习工作站硬件条件包括NVIDIA RTX3090 24 GB GPU;AMD R9 3900X CPU,64 GB DDR4 内存和4 TB 机械硬盘。软件条件包括Ubuntu 18.04、CUDA 11、Python 3.8、Py Torch、Tensorflow 等。
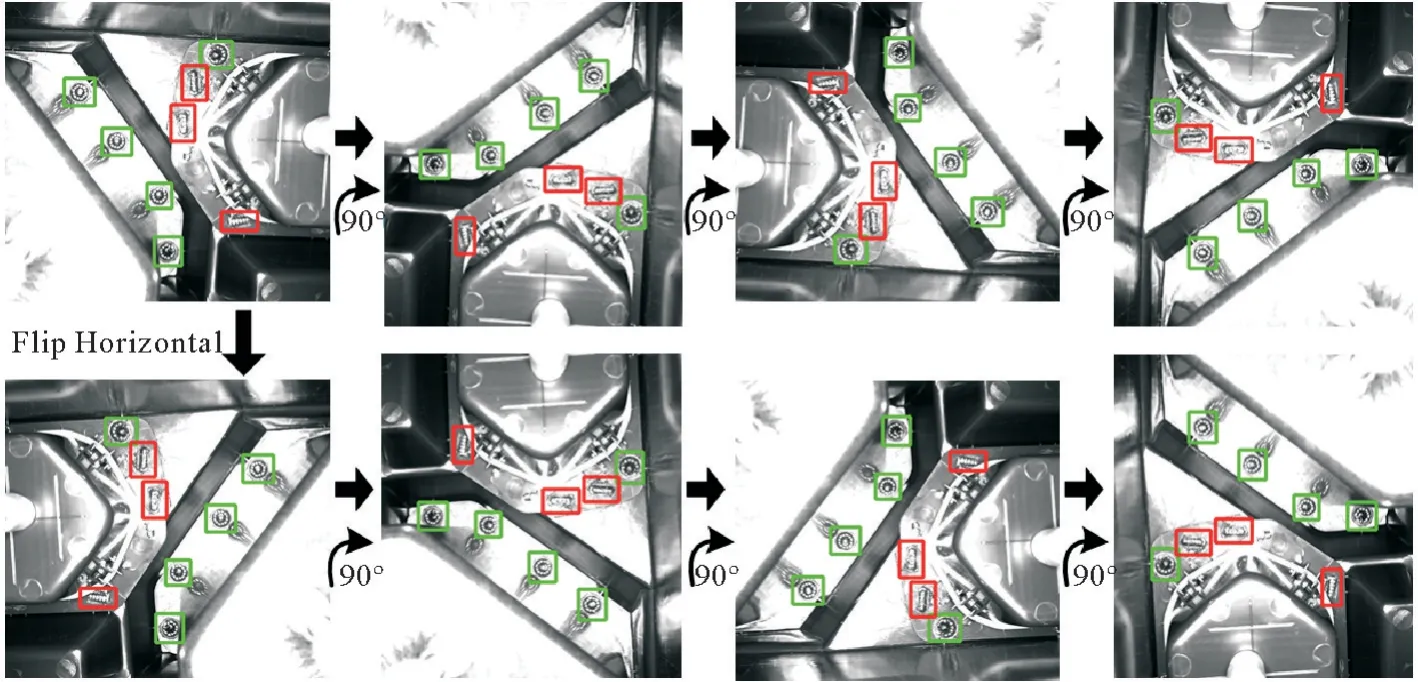
图6 对原始图像旋转和水平翻转的演示效果Fig. 6 Demonstration of rotate and flip horizontal the original image
2.2 算法性能
在深度学习工作站上对算法训练,设定训练最大次数为300轮。经过CZS算法和数据增强算法后,随机取样得训练集32 000张照片,剩下8 320张照片为测试集。训练过程比较漫长,一轮用时近17 min。但另一方面,精度收敛的非常快。当完成了300轮训练后,准确率超过了99%。
有了预训练的算法模型,随即在工作站上测试时间效率。所花费的时间主要分为两部分:一是Python库的加载时间约为1 s,二是检查时间约为0.01 s,如表1。Python库的加载过程非常耗时,可以将其做成一个守护程序,使其始终处于加载库状态,通过扫描检测图像的变化,实时待命检测。本算法较原版YOLOv3的检测时间缩短0.004 s,准确率提高4.2%。可见本算法实现了对原版YOLOv3的性能提升,达到了更好的性能。
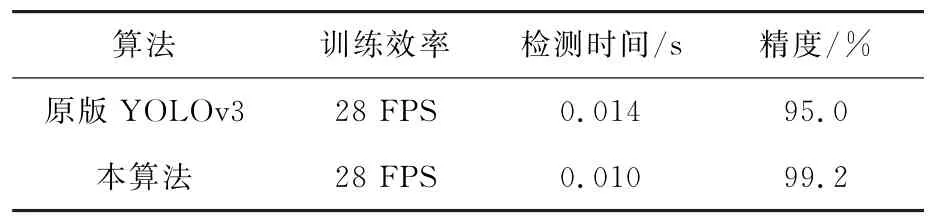
表1 本算法与原版YOLOv3的对比Table 1 Comparison between ouralgorithm and YOLOv3
2.3 综合对比
在本研究中,m AP(平均精度的平均值)和Io U(交并比)被用作主要的精度评价指标。计算16个缺陷类别的平均检测精度,然后将这16个平均精度的平均值作为m AP,m AP 越接近1越好。在训练之前,由手动标记的待检测区域即实际边界框,之后由算法推理得到的标记区域即预测边界框。Io U 是这两个区域的交集除以并集。Io U 越接近1越好,表明算法预测区域与实际标记区域一致。
本算法的优点是对YOLOv3提升注意力,对增加CZS算法和数据增强算法前后的算法进行了比较,效果见图7。没有CZS 算法的全局交并差(GIo U)出现过早收敛问题,无法找到最优解,如第二行左一图示。没有进行数据增强算法的精度收敛较慢并震荡,在训练期内没有达到理想的收敛效果,如第一行左四图示。综合对比,实施完整注意力改进的本算法,精度收敛更快、性能更稳定。

图7 对YOLOv3改进注意力的效果Fig. 7 Effect of attention on YOLOv3
本算法与以往一些精度较高的缺陷检测研究的对比如表2示。XIA[13]和GE[14]的研究代表得采用传统技术进行缺陷检测,PRAPPACHER[15]、HE[16]则采用了深度学习技术,JING[9]也采用了YOLOv3。从精度来看,本算法唯一超过99%;从运行效率看(1/FPS),本算法位居前列;而由于准确性(m APbbox)的数据有限,只列出了本算法的运行结果为0.991,该值取1为最好。应该看到,由于进行缺陷检测的具体问题域存在差别,所以并不能武断的就断定本算法更好。但总体肯定,本算法在固定摄像角度的工业检测情境下,具有一定先进性。
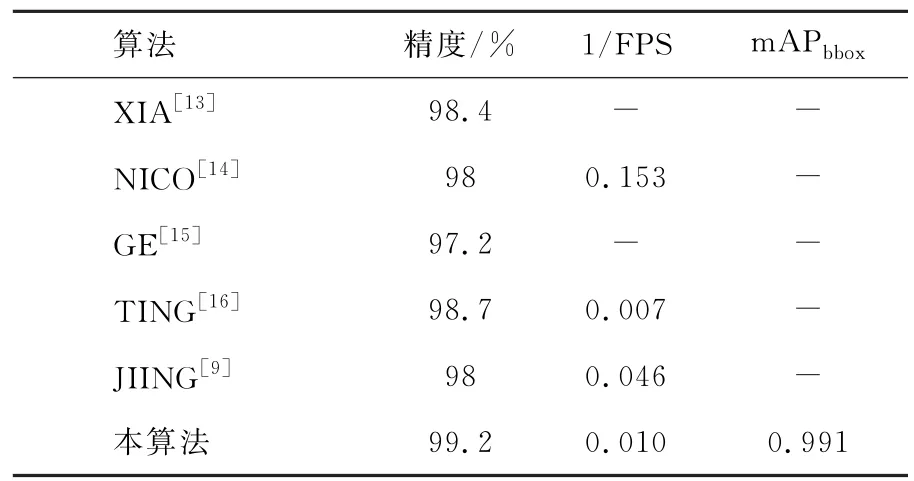
表2 本算法与其他精度较高的缺陷检测算法的性能对比Table 2 Performance comparison of this algorithm with other defect detection algorithms with higher accuracy
注意力机制对算法性能影响如表3示,该表是对图7的进一步解释。CZS操作和数据增强操作都是在图像预处理步骤增加的环节,裁减YOLOv3主干网络则是对算法结构的改变。发现数据增强操作对算法精度影响最大,原始图像只有630张,不足以对算法参数进行充分训练,精度只有75.3%;而经过数据增强后,精度达到95% 及以上。原版YOLOv3因为比本算法多了14个卷积层,需要更多的计算时间,所以检测效率打了折扣,只有73 FPS的效率;由于其待训练参数过多,其精度也有一定降低,只有95%。CZS操作使精度从98.3%提升到99.2%,看起来对算法性能影响并不是太显著;但要看到,在算法精度从0到1的逐渐提升过程中,改进后面的1%和改进前面的1%并不是对等概念,甚至截止目前,没有任何一种方法敢宣称其缺陷检测精度达到了100%,也就是说使精度从99%到100%是一个看来不可能完成的任务,反观从98%提升到99%,其实是克服了极大困难才能达到的目标,所以CZS算法非常有意义。

表3 注意力机制的性能影响Table 3 Performance impact of attention mechanism
2.4 进一步探讨
为了进一步验证算法的有效性,本研究还进行了其他一些相关实验并获得一些结论。
迁移学习。在训练本算法时,权重是全新训练的。已有研究认为,原版YOLOv3也可以通过迁移学习技术快速训练成型。因此考虑两种不同的训练方案。方案一是全新训练网络。方案二是基于微软COCO 数据集预训练的原版网络通过迁移学习快速训练。结果显示这两种方法的训练时间非常相似,都是48 h左右,而m AP 都是0.991左右,也就是说迁移学习并没有缩短训练时间。由于本研究的数据集与COCO 数据集之间存在较大差异,因此跨数据集迁移学习的效果并不明显。
精度分析。与原版YOLOv3相比,本算法减少了14个神经网络层。然而经过300轮的训练,精确率反而从95%提高到99.2%。这是因为优化版的待训练参数变少了,比原版更容易收敛。
误差分析。虽然该方法的识别准确率达到99.2%,但前提是现有只涉及10 个拍摄角度的图像。而当增加新角度图像时,即便还是同样批次零件,虽然要识别的缺陷类型没增加,但精确率达不到99.2%,说明该算法的自适应可扩展性能有限,还有必要通过其他技术手段再优化。
3 结语
本研究的问题来自于常见的一种工厂情境,即工业相机拍摄角度相对固定,这为设计一种基于注意力机制的高效缺陷检测算法提供了灵感。首先采用CZS算法,能去掉图像上无效检测区域,最大限度保留图像上缺陷检测相关区域。其次采用裁减主干网络算法,根据待检目标的相对尺寸,对YOLOv3的3种尺度的识别网络适当裁减。最后采用数据增强算法,通过添加图像噪音和修改图像角度两个策略而扩增图像集。实验结果表明,通过提升YOLOv3的注意力,算法精度达到99.2%,检测时间为0.01 s,可以更好的满足工业领域的检测需求。另一方面,本工作未解决问题:一是关于算法选择,目前已经发布了YOLOv5的第6个版本,亟需对新老YOLO 技术进行验证比较。二是关于使用情境,本研究训练和检测环境需要深度学习工作站,而从发展趋势看,分布式、自适应的边缘计算和雾计算等将是未来主流,需要将智能算法下沉部署到边缘芯片层。
猜你喜欢
广东教育·高中(2022年1期)2022-03-16
电子制作(2018年11期)2018-08-04
中华心脏与心律电子杂志(2017年2期)2017-10-20
测绘科学与工程(2016年5期)2016-04-17
小学生导刊(2016年34期)2016-04-11
新课程研究(2016年21期)2016-02-28
中国交通信息化(2015年2期)2015-06-05
电测与仪表(2015年5期)2015-04-09
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
