
基于YOLO v5-Lite的自然环境木瓜成熟度检测方法
2023-06-20 04:40熊俊涛韩咏林李泽星陈浩然黄启寅
农业机械学报 2023年6期
熊俊涛 韩咏林 王 潇 李泽星 陈浩然 黄启寅
(华南农业大学数学与信息学院, 广州 510642)
0 引言
随着科学技术的快速发展,农业信息化与智能化水平得到了较大的提升,基于深度学习实现果蔬的视觉检测,识别精度高,提取特征丰富[1-2]。近年来,越来越多的学者将计算机视觉与农业结合起来,将其应用于作物培育、采摘、收获等[3-6]。深度学习已经和计算机视觉紧密融合,在水果成熟度检测领域的研究也逐渐深入。
由于大多数水果在生长过程中具有成熟期不一致、分批成熟的特点,所以果实成熟度判断是采摘中的一个重要环节,同时,精准检测和统计树上果实成熟度有利于采收计划调度和水果产量估计等工作。目前我国对果实的成熟度判断主要依赖于人工辨别,自动化程度低。随着计算机视觉技术迅速兴起,水果成熟度检测技术也迅速发展,计算机视觉技术能实现对果实的精准识别和成熟度判断。基于机器视觉的水果成熟度识别与判断方法也日益成熟,对提高农业生产效率有很大的应用价值和很强的现实意义[7-10]。
目前,国内外关于木瓜成熟度的研究主要是化学方法、物理方法和光谱方法等,如孙思盛等[11]利用1-甲基环丙烯处理不同成熟度的木瓜果实,根据色泽、果肉糖、酸相关生理的变化来判断木瓜成熟度。BRO等[12]采用敲打番木瓜然后分析共鸣音频的方法,对番木瓜成熟度进行分级。BRON等[13]采用叶绿素荧光分析技术,对番木瓜成熟度分级进行了研究。利用计算机视觉方法来检测木瓜成熟度的相关研究还较少。对其它水果成熟度的视觉检测研究,主要基于传统颜色特征和统计学习相结合的方法。如PRABHA等[14]使用香蕉图像中的R、G、B分量的一阶矩到四阶矩特征识别香蕉成熟阶段。刘阳泰等[15]通过图像的R分量和H分量设计了香蕉成熟度的评定指标,人工设置合适的阈值从而判别香蕉的成熟度等级。毕智健等[16]对番茄的14个颜色分量组合后,使用线性判别分析法对番茄成熟度进行检测,平均准确率达到 90%。叶晋涛等[17]利用R-G分量对哈密瓜区域进行分割,在RGB和HSV空间下提取8种颜色分量均值,构建SVM分类模型,预测准确率达97.2%。周文静等[18]将红提葡萄果穗用KNN模型从背景中分割出来,再运用圆形Hough变换提取出葡萄果实,提取果实的H颜色分量值,设置特定的颜色阈值对单个果实成熟度进行判定,经过统计后再判断整个果串的成熟度等级。由于上述机器学习进行果实检测仍存在检测精度较低,检测时间较长等问题,而随着神经网络的发展并在各种视觉任务中有较好的检测效果,一些学者开始利用深度学习对水果成熟度进行识别分类。如HABARAGANUWA等[19]利用卷积神经网络对温室草莓进行识别和成熟度判断。NASIRI等[20]利用卷积神经网络VGG16对枣果实成熟度分类,总体分类准确率达96.98%。刘振[21]利用YOLO v3对番石榴的成熟度进行识别分类,总体检测效果达94.8%。熊俊涛等[22]将YOLO v3的骨干网络替换为DarkNet53,结合残差网络和密集连接网络,提出了一种夜间柑橘识别的方法,最终夜间对柑橘检测精度达97.67%。
综合所述,深度卷积神经网络在目标检测中具有较大的优势,能够快速且精准地实现检测任务,从而识别复杂环境中果实的成熟度[23]。目前大多数研究主要在自然光环境下进行水果成熟度检测,适用于强光和弱光等环境的相关研究较少,同时对于遮挡、拍摄距离等问题研究也相对较少。此外,现有水果成熟度检测研究的对象主要集中在葡萄[24]、芒果[25]、番茄[26]、枣类[27]、油棕榈[28]等作物,而木瓜作为结果快、可食用阶段多的经济类水果作物,其相关研究反而较少。
YOLO v5-Lite作为YOLO v5改进后的算法,具有检测效率高、准确率高、模型占用内存小等特点,同时可以在整体配置较低、算力较弱的边缘设备上进行部署,为果园智能采收设备提供视觉支持。本文获取不同自然光条件下、不同拍摄距离以及不同遮挡情况的木瓜图像,基于YOLO v5-Lite深度学习算法模型进行木瓜成熟度检测,以期为农业生产中水果选择性采收的视觉检测提供技术支持。
1 数据集与预处理
1.1 数据采集
对果实成熟度的判定和识别是进行机械智能化收获的必要条件,果实的成熟度会影响其用途和采摘时间,因此需要进行选择性采摘。
木瓜是蔷薇科木瓜属植物,未成熟的木瓜果实外观是青色的,果肉相对坚硬、酥脆,成熟的木瓜果实外表皮一般为黄色或者是橘红色。由于木瓜属于典型的呼吸跃变型水果,在常温下运输贮藏容易腐烂变质。利用木瓜的该特点,果农会在木瓜处于未成熟或半成熟时,根据运输距离来采摘相应成熟度的果实,从而达到运输过程中果实不腐烂的目的,保证木瓜最大的销售价值。所以,为了采摘到最合适运输或销售的木瓜,对木瓜进行准确的成熟度判断是非常重要的。本文的木瓜成熟度主要以颜色为判断依据,根据感官评价法[29-30]、表皮相比例法[31]以及人工采摘专家的经验,将木瓜果实成熟度分为3类:未成熟全绿木瓜、半成熟半黄木瓜和成熟全黄木瓜。如图1所示,未成熟果实表皮颜色为全绿或有轻微黄色,具体性状表现为果实表面的绿色区域面积占比超过3/4,半成熟果实表皮颜色逐渐发黄但仍有大面积绿色,具体性状表现为果实表面的黄色区域面积占比介于1/4和2/3之间,成熟的果实表皮颜色呈黄色或带有少量绿色,具体性状表现为果实表面的黄色区域面积占比超过2/3。本研究所用木瓜图像数据采集自广州市从化区罗洞工匠小镇木瓜采摘基地,基地的木瓜采用规范化种植方式。同时,为了增强数据,加强模型的鲁棒性、适用性和泛化性,采集图像的设备采用佳能EOS-750D 型相机与iPhone12手机,相机图像分辨率为4 000像素×6 000像素,手机图像分辨率为4 032像素×3 024像素,图像最终保存格式为.jpg。

图1 3种成熟度的木瓜图像Fig.1 Images of papayas of three maturities
由于果园智能采收设备是在果园中作业且作业能力是有范围的,按照作业的逻辑顺序,先是远距离检测,然后靠近目标采摘。所以在其有效作业范围内,需要对不同距离的果实进行识别和成熟度检测,以便设备规划下一步动作。因此,为了满足果园智能采摘机器设备的作业能力和范围,需要保证数据集的多样性,所以数据集中不仅要有不同拍摄距离、不同光照情况以及不同遮挡情况的木瓜果实,每幅图像中还需要存在不同成熟度的多个果实。在拍摄距离上,考虑到果园中果树的种植间隔与设备的作业范围,拍摄距离选择在0.2~2.0 m之间,其中,近、中、远3种拍摄距离分别对应拍摄设备与果树距离0.2~0.8 m、0.8~1.4 m、1.4~2.0 m;在光照条件上,根据照度分为强光与弱光,在室外阴天时,照度为50~10 000 lx,算作弱光条件;在室外晴天时,照度为10 000~100 000 lx,算作强光条件[32]。数据集拍摄为远、中、近距离和强光、弱光的随机组合,可以满足选择性收获作业。共采集1 386幅RGB图像用于模型数据训练及测试,部分图像如图2所示。

图2 不同拍摄条件下的木瓜图像Fig.2 Papaya images under different shooting conditions
1.2 数据集制作
数据集在不同光照条件与不同拍摄距离组合拍摄获得,具体数据集分布情况如表1所示。为了保证数据参数的准确性,在模型训练前使用标注工具LabelImg对数据进行人工标注,采用PASCAL VOC标注格式,其中,全绿木瓜标注为immature_papaya,半黄木瓜标注为semi_papaya,全黄木瓜标注为mature_papaya。标注时要将整个木瓜的最小外接矩形作为真实框,以此减少框内背景上的无用像素。标注完成后,生成.xml类型的标注文件。然后将1 386幅木瓜图像,按照比例8∶1∶1分为训练集、验证集和测试集,最终训练集1 108幅图像,验证集139幅图像,测试集139幅图像。训练集与验证集用于模型训练以及在单次训练中对结果进行评估,测试集用于最终模型的检测效果评估。
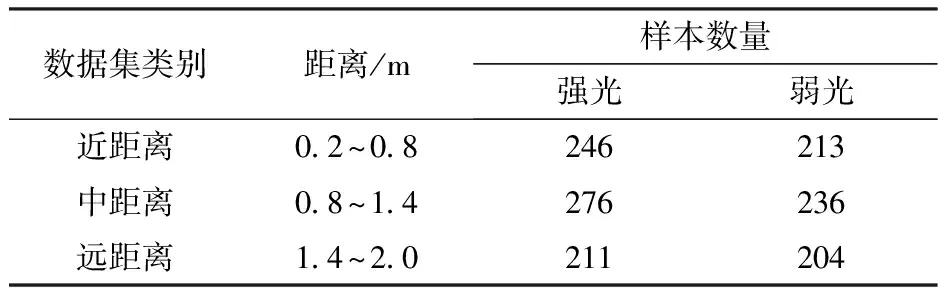
表1 不同条件下数据集及其数量Tab.1 Data sets and their quantities under different conditions
2 网络模型
2.1 YOLO v5目标检测网络
YOLO v5算法是YOLO系列算法最新提出的算法之一,它是在YOLO v4算法基础上进行改进得到的,YOLO v5可以获得准确、实时、高效的检测结果。相较于YOLO v4,在保证准确性的前提下,实现了模型轻量化。YOLO v5网络模型检测精度高,推理速度快,最快检测速度可达140 f/s。YOLO v5体系结构包含4种结构,分别命名YOLO v5s、YOLO v5m、YOLO v5l和YOLO v5x。它们之间的主要区别在于特征提取深度和宽度不同,YOLO v5整体结构可以分为4个模块:输入端、主干(Backbone)、颈部(Neck)和输出层。
在主干网络中,YOLO v5采用CSPNet结构,从输入图像提取丰富的图像特征,解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,有效减少了模型的参数数量,在保证模型准确性的同时,减少了模型尺寸。与YOLO v4不同的是,YOLO v5基于CSP设计了2种结构:CSP1、CSP2,并将CSP2用于Neck,能够深层次提取目标特征信息。
在颈部网络中,延续了前代YOLO v4采用路径聚合PANET网络结构,进行不同层级的位置与语义信息融合,利用FPN自上而下方式对特征进行上采样,利用PAN结构自底向上方式进行下采样,通过低层级和高层的特征信息融合,改善识别检测效果。
此外,YOLO v5还新增了Focus结构,其对原始输入进行切片分割,减少计算量,加快网络速度,其采用GIOU_Loss作为Bounding box的损失函数,且采用加权极大值抑制(NMS)对GIOU_Loss进行非极大值抑制,能快速选择最佳的预测框,具有准确度高和识别检测速度快的特点。YOLO v5目标检测网络模型的权重文件较小,仅为YOLO v4的10%,同时其检测精度高、占用内存小,检测速度快。
2.2 改进的YOLO v5-Lite网络
YOLO v5-Lite体系结构包含4种结构,分别命名为YOLO v5-Lite-e、YOLO v5-Lite-s、YOLO v5-Lite-c和YOLO v5-Lite-g。它们都是基于YOLO v5网络进行改进得到的,主要区别在于特征提取深度和宽度不同,与其他3种结构的版本相比,由于YOLO v5-Lite-g在满足精度高、速度快的同时,模型也较小,综合网络的各项指标后,本文研究选择YOLO v5-Lite-g版本。
2.2.1去除掉Focus层
由于Focus层频繁的图像切片操作,会对芯片造成很大的负荷,加重计算处理的负担,对模型进行部署时,Focus层的转换也比较繁琐复杂。不同于YOLO v5,在YOLO v5-Lite中,使用更加快速的卷积操作替代Focus层,并且获得了更好的性能,在减少计算量的同时释放了内存的占用,使得模型更加快速。
2.2.2使用ShuffleNetv2
ShuffleNet是旷视科技公司提出的一种轻量级深层神经网络,它通过逐点群卷积和channel shuffle两种操作,使模型既能保持很高的精度,又可以减轻模型的计算量。在此基础上,进行了Channel Split的操作,同时创建了ShuffleNetv2。其主要有2个优点:①把ShuffleNet中1×1的组卷积改成了普通的卷积,通过减少组卷积的使用降低了计算量。②将分支上的普通卷积,更改为深度可分离卷积,大大减少了计算量,增加了计算效率。
2.2.3减少使用C3 Layer以及高通道C3 Layer
C3 Layer是CSPBottleneck改进版本,它更简单、更快、更轻,在近乎相似的损耗上能取得更好的结果。但C3 Layer采用多路分离卷积,测试证明,频繁使用C3 Layer以及通道数较高的C3 Layer,会占用较多的缓存空间,减低运行速度。
2.2.4剪枝FPN+PAN
FPN+PAN源于CVPR的PANet,经过拆分后应用到YOLO v4中,大大提高了特征提取能力。但是YOLO v5-Lite在此基础上,对其进行通道剪枝,同时改进了YOLO v4中的FPN+PAN的结构,如图3所示,具体改进为:①选择使用相同的通道数量,从而最优化了内存访问和使用。②选择使用原始的PANet结构,还原YOLO v4的cat操作为相加操作,进一步优化了内存使用。
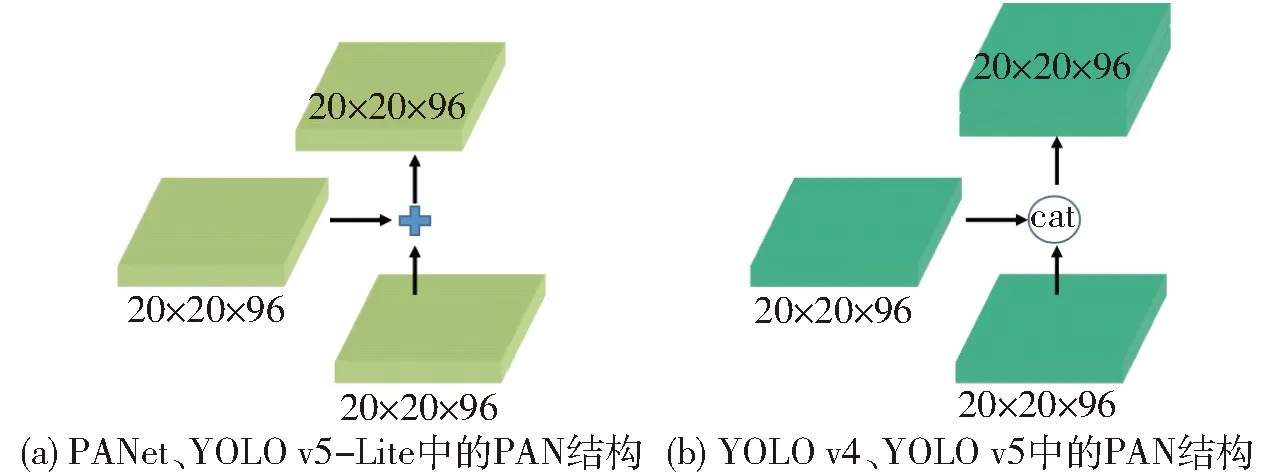
图3 FPN+PAN结构Fig.3 FPN+PAN structure
2.2.5YOLO v5-Lite网络模型
YOLO v5-Lite网络模型如图4所示,采用Mobilenetv3作为主干特征提取网络替换原来的CSPDarknet53,而主干特征提取网络替换的实现思路就是将3个具有相同的初步有效特征层进行对应替换。为了进一步减少参数量,在加强特征提取网络中使用深度可分离卷积代替普通卷积。
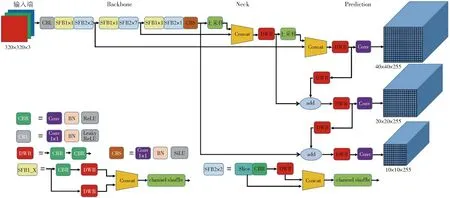
图4 YOLO v5-Lite网络结构Fig.4 Network architecture of YOLO v5-Lite
2.3 评价指标
为评估训练所得模型的检测效果,采用准确率(P)、召回率(R)、平均精度均值(mAP)、检测速度(FPS)与模型内存占用量(weights)。准确率表示识别正确的木瓜数在识别目标中所占比率,召回率表示在所有木瓜中被识别出来的比率。这2个指标越高,表明训练所得模型检测性能越好。准确率和召回率是一对矛盾的度量标准,准确率越高,召回率一般会偏低,反之亦然,准确率越低,召回率则一般会偏高。
mAP为各类准确率P与召回率R构成P-R曲线下面积的平均值,是衡量目标检测模型性能的重要指标,值越大,检测效果越好。通常性能较好的算法以上指标都较优,因此综合分析上述指标可以较好反映其性能。
3 实验结果与分析
3.1 实验环境与参数设置
本文实验的软硬件平台硬件配置:CPU为Intel Core i7-11700K,六核十二线程,最大主频率为3.6 GHz,GPU为NVIDIA 3090,拥有10 496个CUDA核心用于模型的加速训练,内存32 GB,主板为华硕B85M-F。软件配置:操作系统采用Ubuntu 16.04系统,网络模型以Python 3.8编程语言实现,软件平台为PyCharm,搭配环境CUDA 11.3、Cudnn 7.6,采用Pytorch深度学习框架进行训练。
考虑在实时检测及采摘机器人上的部署需求,能够更好识别到目标果实,本文采用YOLO v5-Lite模型为主要框架与预训练权重,设置初始学习率为0.01,设置输入图像尺寸为640像素×640像素,以128幅图像为一个批处理量,最大迭代次数为300次的模型参数,进行随机梯度下降法(SDG)网络训练。YOLO v5-Lite参数具有快速收敛的特点,能够在较小的迭代次数获得较好的训练结果。
3.2 训练过程与结果
在训练过程中记录模型的损失函数、准确率P、召回率R以及P-R曲线如图5所示。由图5可以看出,损失函数在训练初期下降速度快,整体波动较小,且训练到第200轮左右时损失值达到了0.027,经过300轮训练后,损失值完成收敛,损失值为0.025。最终模型准确率为89.7%,召回率为85.5%,mAP(重叠率0.5)为92.4%。
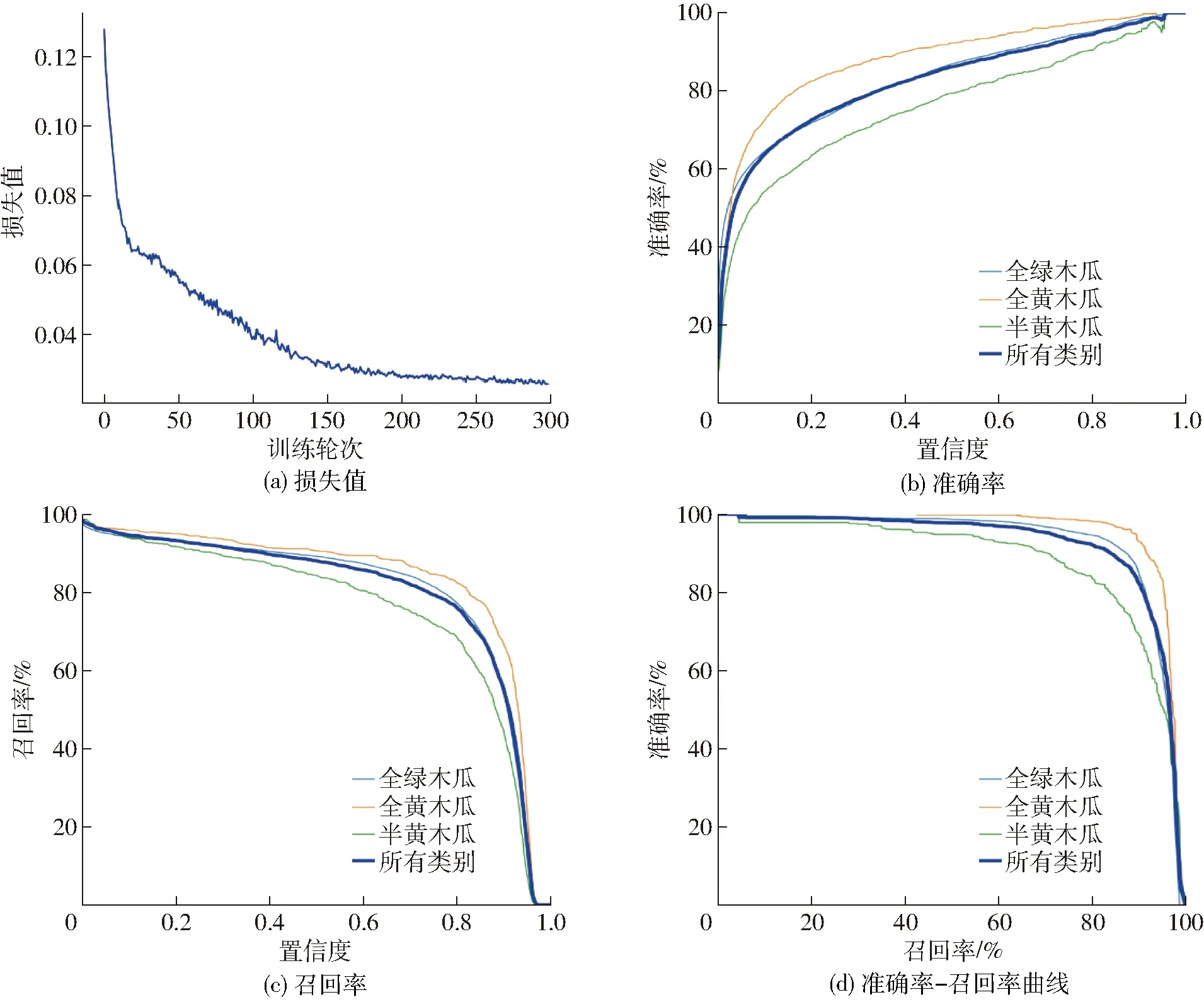
图5 训练过程中损失函数、P、R、P-R变化曲线Fig.5 Loss function, P, R, P-R change curves during training
3.3 检测效果
3.3.1不同光照程度的木瓜检测效果
YOLO v5-Lite模型在强光与弱光不同光照条件下的检测效果如图6所示,可以看出在强光条件下,YOLO v5-Lite对检测任务完成较好,对于一些遮挡严重的果实也有很好的检测效果;而在弱光下,一些本身为绿色的果实由于遮挡严重导致光照强度的较弱,在图6b中木瓜表皮的颜色特征由绿色变为较深的深绿或黑色,导致模型对于该种情况果实学习的效果较差,从而导致小部分果实存在漏检和误检的情况。

图6 不同光照程度的木瓜检测效果Fig.6 Detection effect of papaya under different illumination levels
3.3.2不同拍摄距离的木瓜检测效果
为了探究在不同拍摄距离下模型对木瓜检测的效果,考虑到果园中果树的种植间隔与设备的作业范围,根据实验需要,选用了3种不同拍摄距离的图像数据。将训练好的YOLO v5-Lite模型,用在不同拍摄距离的木瓜时,检测效果如图7所示,可以看出当模型检测近距离和中距离图像中的木瓜时,无论是对木瓜果实的识别还是对木瓜成熟度的判断,都有非常好的检测效果。而当木瓜处在较远距离拍摄时,模型则出现误检漏检的问题,同时还会误判果实的成熟度。

图7 不同拍摄距离的木瓜检测效果Fig.7 Detection effect of papaya under different shooting conditions
3.3.3不同遮挡情况的木瓜检测效果
为了探究遮挡情况对模型的影响程度,采用3种不同遮挡情况进行测试。在面对无遮挡和轻微遮挡的木瓜图像时,如图8所示,模型仍可以保持很好的识别精度,在特征明显的情况下,不会出现漏检误检的情况。而当出现较严重的遮挡时,由于果实间生长不规律构成较多的缝隙,该种情况所漏出的特征不能给模型足够的信息去做出正确的判断,所以会出现较多的漏检情况,错检情况极少出现。同时,由于受遮挡影响导致的部分弱光环境,也会使树干表皮成为误判因素。
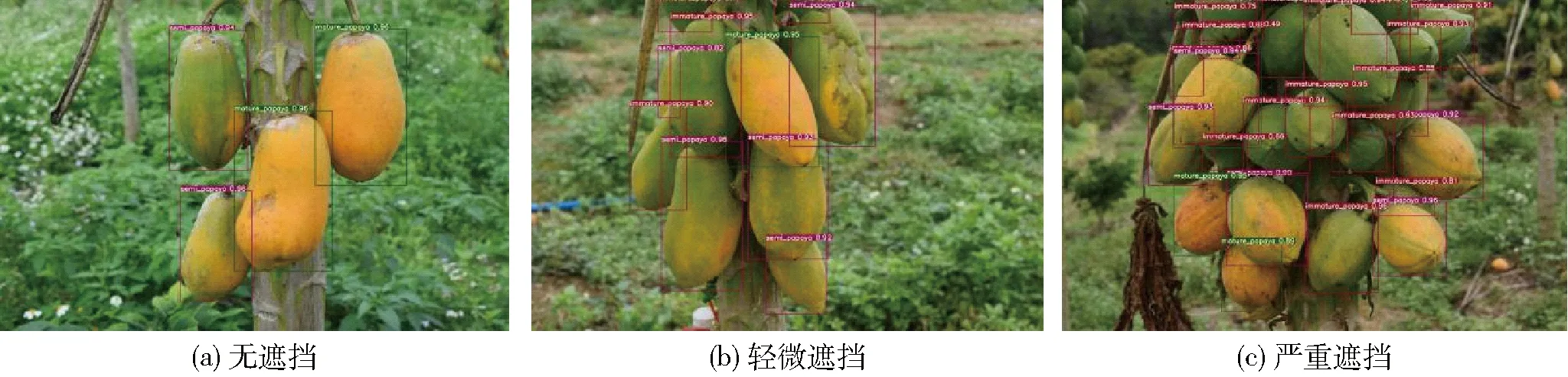
图8 不同遮挡情况的木瓜检测效果Fig.8 Detection effect of papaya under different occlusion conditions
3.3.4不同算法检测能力对比
YOLO v5-Lite模型与其他模型在验证集上对不同成熟度木瓜检测的实验结果如表2所示。由表2可知,YOLO v5-Lite模型在检测中的总体平均正确率比YOLO v5s、YOLO v4-tiny和Faster R-CNN分别高1.1、5.1、4.7个百分点,且检测速率也较高。其中,YOLO v5s的检测精度较高,但容易出现漏检误检的情况且检测速度较慢;YOLO v4-tiny模型检测速度最快但检测精度较差且容易出现漏检错检多检的现象,同时所需内存较大且训练时间较长;Faster R-CNN模型作为两阶段算法,模型所需内存最大且检测速度最慢,在检测精度效果上表现也较为一般。因此,综合对比可以看出,YOLO v5-Lite模型在检测木瓜各种成熟度的精度与速度上都有更大的优势。
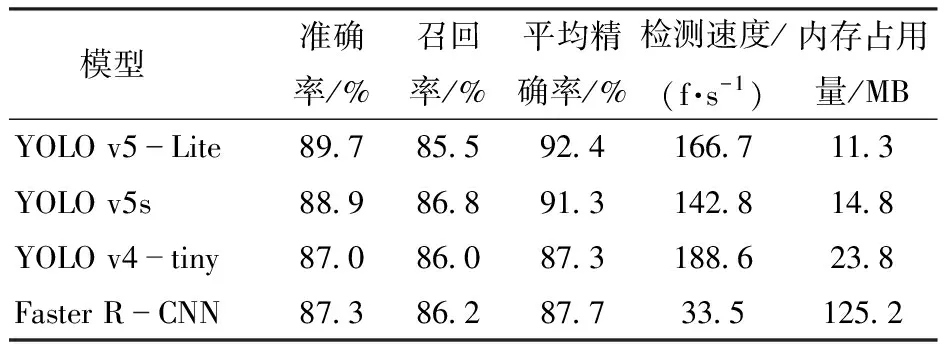
表2 不同训练网络模型的木瓜成熟度检测结果Tab.2 Papaya maturity test results of different training network models
为验证本模型在果园复杂环境下对木瓜成熟度检测的准确性和快速性,以复杂果园为背景对木瓜的成熟度进行了检测。图9为不同模型在不同条件下对木瓜成熟度检测的实验结果。从图9可以发现,在光照条件为弱光,多个木瓜果实重叠在一起时,3种模型检测的准确率都受到影响,这是因为逆光时木瓜的表皮会变得暗沉且不清晰,给木瓜检测增加了难度;另外,由于全绿木瓜的表皮与树干表皮的颜色、纹理和光滑度都具有一定的相似度,当果实数量很多且互相发生重叠,这种情况下在中远距离观察木瓜时,通过人眼对木瓜的成熟度进行区分也存在一定难度,因此在中远距离严重重叠的情况下,模型检测的平均精度会受到一定的影响。但相比于其他模型,YOLO v5-Lite模型能够一定程度上优化其他模型存在的漏检、错检的情况,同时该模型的检测速度也存在很大的优势,其mAP达到92.4%,平均检测时间为7 ms,说明该模型具有更强的鲁棒性与实时性,因此能够实现果园复杂环境下对木瓜成熟度的检测。

图9 不同环境下不同训练网络模型的木瓜成熟度检测效果Fig.9 Effects of different training network models on papaya maturity detection in different environments
同时,为了验证本模型的检测速度,还对不同模型相同数量数据集图像的处理时间进行了比较,如表3所示,YOLO v5-Lite与YOLO v5s、YOLO v4-tiny与Faster R-CNN在对同一批数据进行检测的时间差距逐渐增大,YOLO v5s与Faster R-CNN在检测精度与检测速度上效果均低于YOLO v5-Lite,YOLO v4-tiny虽然在检测速度上稍有领先,但在检测精度上相比YOLO v5-Lite稍有逊色,且模型参数更多,也更加占用内存。由表2与表3可以看出,所训练模型对木瓜成熟度检测具有较好的检测效果与检测速度。
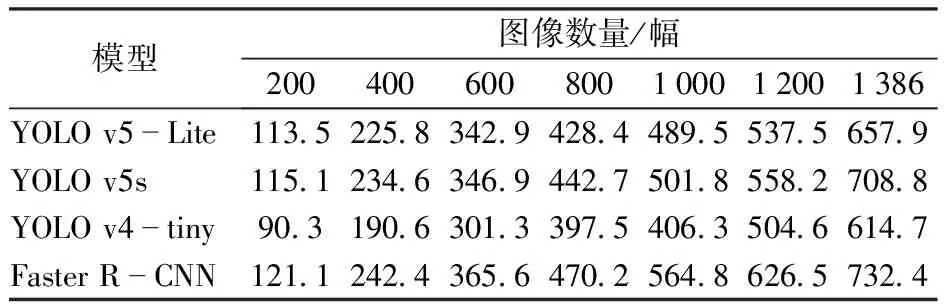
表3 不同训练网络模型检测时间Tab.3 Detection speed of different training network models s
4 结论
(1)基于YOLO v5-Lite目标检测算法,用于复杂果园环境下木瓜成熟度的检测,使用训练完成的模型对测试集进行检测,准确率为89.7%,召回率为85.5%,mAP为92.4%,检测速度为166.7 f/s,实验结果表明网络模型具有较强的鲁棒性,还具有轻量化的特点,同时保证了木瓜成熟度的检测精度和检测速率,满足在复杂环境下对木瓜成熟度的检测。
(2)为验证本模型在实际的果园复杂环境中的检测效果,在相同条件下使用不同模型分别对木瓜的成熟度作了检测。实验结果表明,YOLO v5-Lite模型在不同光照条件以及重叠遮挡情况下,相比于YOLO v5s、YOLO v4-tiny与Faster R-CNN模型,在精度上分别高1.1、5.1、4.7个百分点,检测速度比YOLO v5s和Faster R-CNN分别快23.9、133.2 f/s,即能提供更高的检测精度与更快的检测速度。
(3)在具有较好的检测效果与泛化特性的同时,模型所占内存仅为11.3 MB,易于移植与部署在内存容量较小的设备。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
基层中医药(2021年5期)2021-07-31
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年1期)2020-04-20
电子制作(2019年11期)2019-07-04
学生天地·小学低年级版(2019年1期)2019-03-18
学生天地(2019年3期)2019-03-05
种子(2018年9期)2018-10-15
北京航空航天大学学报(2018年1期)2018-04-20
学苑创造·B版(2018年12期)2018-03-04
