
一种使用最大均值差异方法的多因子进化算法
2023-06-17 06:51赖玉芳王振友
广东工业大学学报 2023年3期
赖玉芳,王振友
(广东工业大学 数学与统计学院,广东 广州 510520)
与迁移学习(Transfer Learning)[1-4]类似,多任务学习(Multitask Learning)[5]利用来自各种源任务(Source Tasks) 的高质量解来优化目标任务(Target Task)。迁移学习的知识转移(Knowledge Transfer) 是单向进行的,知识从源任务迁移到了目标任务,一次只优化一个目标任务,源任务不可重新优化。因此,迁移学习不能并发地解决多个优化任务。而多任务学习通过促进全方位的知识转移实现更大的协同搜索,从而高效地同时解决多个问题。即所有优化任务在原则上可以相互帮助,使得所有任务互相优化。但是实际中的多任务优化存在任务间的相似性,每个优化任务可能并不总是与所有其他可用任务密切相关,这种情况可能会导致同时解决任何不相关的优化问题的性能降低[6]。这种任务间的差异在多个不同的问题上共享错误的知识,使得问题可能往错误的方向求解,就会产生一种称为负迁移(negative transfer) 的现象[5,7]。
无论在迁移学习还是多任务学习中,如果任务与任务间不按合理的顺序进行知识迁移,那么这些任务可能会产生负迁移的影响。Ball等[8]在多因子进化算法(Multi-Factor Evolutionary Algorithm,MFEA)的基础上改进得到MFEA-II,提出了一种新的数据驱动的多任务处理方法,使有用的知识在多任务环境下的不同优化问题之间转移,很大程度上消除多任务知识迁移的负迁移。
本文主要研究进化算法(Evolutionary Algorithms,EAs)的改进和应用,改进后的算法MFEA-MMD在MFEA-II的在线迁移参数估算(online transfer parameter estimation)的随机分配概率(Random Mating Probability, RMP,下文用Q表示)矩阵优化方法上改进,使用最大均值差异(Maximum Mean Discrepancy, MMD)作为Q矩阵优化的度量准则。使用MMD方法衡量2个数据集之间的差异,计算2个向量(点、矩阵)的距离和相似度,使得算法从概率建模的角度优化了多任务进化框架。贝叶斯优化从不同任务中提取的因子局限于连续搜索空间,不直接应用于组合搜索空间。为解决这一类问题,EAs很好地适应连续搜索空间概率模型,实现了任务间有用知识的互相迁移,以本线迁移参数估算的随机分配概率Q矩阵的方法抑制任务间的消极交互作用,在不需要任何人为干预的情况下,知识转移效率大大提高,充分利用各种任务间可以有效帮助互相优化的有用知识。
1 研究背景与意义
从多任务贝叶斯优化[9]开始,越来越多的学者在优化领域里研究知识迁移。但贝叶斯优化通常局限于相当低或中等维数的问题,EAs则在适应不同的数据方面有更高的灵活性,可以很好地扩展到高维度,解决了许多实际问题以及理论问题。
MFEA具有不同技能因子的个体执行交叉操作,为跨任务的基因迁移提供了机会[10]。MFEA-II算法在MFEA算法的基础上提出了一种新的进化计算框架,使用在线迁移参数估算和利用多任务环境下不同任务之间的相似性(和差异),以增强优化过程,尽量减少任务之间有害的相互作用(负迁移),但知识迁移效率较低。
目前,常用的进化多目标优化算法有Deb[11]提出的基于拥挤度距离度量的NSGA-II算法,Zhang[12]提出的基于分解思想的MOEA/D算法,Seada等[13]在NSGA-II的基础上提出的一种针对2~16个目标函数同时优化高维问题的NSGA-III算法。实验结果表明,种群多样性和基因迁移在MFEA算法中共同发挥重要作用,但基因迁移使得具有较强互补性的多任务种群收敛加速更为明显[14]。Ball等[8]也在MFEA算法的基础上提出了在线迁移参数估算的MFEA-II算法。
MFEA-II算法从父代种群的概率混合系数入手,把混合系数中的随机分配概率标量q替代为在线迁移参数估算混合系数矩阵Q,每个任务的混合系数同时确保父代种群混合迭代最佳,降低了负迁移的影响。即使MFEA-II算法利用在线迁移参数估算的Q矩阵使正向的因子更突出,以达到加速优化和使优化结果更精确的效果,但是对于数据庞大、更新代数多的因子群来说,还是有运算难度大的风险,使得计算资源难以承担庞大的数据量,而且在线迁移参数估算的概率混合系数矩阵难以保证种群的信息在混合分布中得以互相分享。因此,在多任务特征的基础上,基于种群分布特征设计新的编解码方案、高效的进化算子,以实现种群多样性的主动控制和种群搜索方向的自适应调整,提高算法效率。为了降低计算成本,本文用最大均值差异MMD作为MFEAⅡ在线迁移参数估算Q矩阵的度量准则,对混合概率分布的知识迁移框架进行改造。从实验结果上看,本课题把MMD方法运用于多因子进化算法的改进上,实现知识迁移效率更高的同时使有效信息得以充分利用,算法效率得以提升。
2 多因子进化算法原理
MFEA受到多因子遗传模型[15-16]的启发,利用进化个体的单一种群,能够同时求解跨域的多个优化问题,从而独立地提高解决每个任务的性能。它的工作原理是假设在解决某个任务时存在一些共同的有用知识,在解决此任务的过程中获得的有用知识可能有助于解决另一个与其有关联的任务[17]。多因子进化算法的效率和适应性对于算法的应用价值显得尤为关键[18]。
在不同任务之间共享信息和学习所有任务,使任务间的有效信息进行全方位的知识转移,实现更大的协同搜索,从而促进多个问题的同时高效解决以提高整体泛化性能。
多因子进化算法属于多任务多目标算法,一个进化多目标优化(Evolutionary Multi-Objective Optimization, EMOO) 问题只包含一个任务,该任务可以被求解生成一组Pareto最优解。而进化多任务优化(Evolutionary Multi-Tasking Optimization, EMTO)问题包含多个任务(单目标或多目标),可以同时求解这些任务的最优解,即EMTO将解决多个EMOO问题。EMTO的目标是利用基于种群中并行的知识来搜索开发多个任务之间潜在的遗传互补性。
给定一个带有k个分量任务的EMTO问题,第j个子任务定义为Tj,其对应的目标函数为Fj:Xj→R,这里Xj是 一个Dj维 的解空间,R 代表实数域,即
其中,如果对特定任务的解空间施加了某些约束,则会将一些约束函数与该任务的目标函数一起考虑。给出了一个由k个分量任务组成的EMTO问题,MFEA产生n个个体的单个种群p={pi}in=1,同时搜索每个k分量任务的全局最优解。
2015年,新加坡南洋理工大学的Gupta教授在多因子遗传模型的启发下,首次提出多因子化算法MFEA,该算法是多任务多目标优化算法,应用于处理跨域的多因子优化问题[17]。2019年,Gupta教授的团队在MFEA算法的基础上将其改进为MFEA-II算法,利用在线迁移参数估算以及不同任务在多任务设置中的相似性(和差异)增强了优化进程。
2.1 MFEA算法
MFEA 算法基于统一的搜索空间确定候选解的表达方式,对种群中个体的进化产生显著影响,遗传物质能够有效地在各个任务间迁移,从而加速算法的收敛速度,算法自身的效率和适应性仍有待提高[18]。MFEA可以从父母和后代两个方面控制跨任务的知识转移。MFEA的算法结构如下。
算法1 经典多因子进化算法


2.2 MFEA-II算法
在MFEA算法中,不恰当的q可能会导致任务间的消极交互,或者潜在的知识交换损失,减低算法的收敛速度,MFEA收敛速度依赖于q的值。因此为了更好地探究算法里潜在的知识迁移,Ball等[8]在MFEA算法的基础上,提出了一种在线迁移估算Q矩阵中所有q的MFEA-II算法,通过实时动态调整q,从理论上保证最小化不同优化任务之间的负面(有害)交互。
3 多任务优化的知识迁移
初始化知识交换以概率混合分布作为多任务设置的一种方式,从不同任务中提取搜索分布。多任务中转移(知识迁移)有用信息的前提是概率混合分布的所有分布域定义于一个公共/共享空间中,称为统一搜索空间(unified search space)。
3.1 统一搜索空间
搜索空间统一在多任务处理中的重要性,在于它包含了不同优化任务的所有独立搜索空间,相当于一个共享的平台。现有K个最大化任务{T1,T2,···,TK}将被并行求解。每个优化任务的搜索空间维数分别表示为D1,D2,···,DK。定义统一的空间X的维度为Dunified=max{D1,D2,···,DK},这样的设置不是简单地将K个不同的搜索空间连在一起,如Dunified=(D1+D2+···+DK) ,而是使X在多任务设置中有足够的灵活性来包含每个任务。当同时解决多个具有多维搜索空间的任务时,它有助于规避维数诅咒,是获取基于群体搜索力量的有效手段,以高效的方式促进有用遗传材料从一个任务显现或隐性转移到另一个任务。本文将X限制在[0,1]Dunified的范围内,它作为一个连续的统一空间,所有候选解决方案都被映射(编码)到其中。因此,在处理第k个任务时,从候选解决方案x∈X中提取变量Dk的子集,并将其解码(与映射函数相反) 到特定任务的解决方案表示中进行评估。
3.2 混合概率分布的知识迁移
对于所有k∈{1,2,···,K} ,令第K个任务关联的(子) 种群记为Pk。在进化多任务算法中,让每个任务K的子种群在时间步长t>0时产生底层概率分布p1(x,t),p2(x,t),···,pK(x,t)。因此,在促进任务间交互的过程中,第k个任务在第t次迭代中产生的后代种群来自式(2)的混合分布。
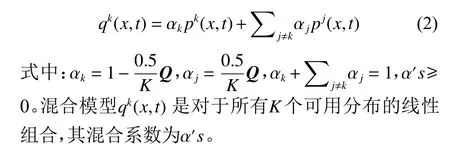
4 多因子进化算法的改进
进化多任务能同时解决多类优化问题,包括离散型、连续型以及多目标优化问题[19-21]。除此之外,进化式多任务也得以应用在机器学习领域,例如从决策树集合[22]训练到基于模块化知识表示的前馈神经网络[23]。现有的进化多任务算法在很大程度上依赖于任务之间存在可利用协同作用的预先假设。在缺乏任务间关系相关知识的情况下难以避免出现负迁移的情况[24-25]。
4.1 多任务优化的知识转移
多任务优化中的知识转移发生在从式(2)的候选解的后续采样过程中(即任务间种群概率qk的混合使多任务存在知识迁移)[26-27]。混合度(知识交换量)由混合系数 α′s决定。在缺乏关于任务间关系的先验知识的情况下,任何不恰当的混合概率分布会使知识迁移偏移到错误的方向,造成负迁移。MFEA-II在线迁移参数估算混合系数矩阵通过促进组分密度的最佳混合,基本消除了负迁移的威胁。但在线迁移参数估算混合系数矩阵不能确保种群的有用信息在混合分布中充分迁移,使得在线迁移参数估算混合系数矩阵数据量大大增加,降低了算法的运算速率。
4.2 混合概率分布知识迁移的应用
多目标优化的知识迁移一般有3个主要的研究问题。
(1) 迁移什么。不同任务之间哪部分知识可以进行迁移,有些知识是一个任务所特有的,但是还有一些知识是多个任务间普遍存在的。利用这种普遍存在的知识就可以提升模型在不同任务上的表现。
(2) 何时迁移。需要考虑在什么情况下可以进行知识迁移,并且在什么情况下知识不应该被迁移。在某些情况下,如果任务与任务间确实没什么关联,强行进行迁移的话效果差,可能还会损害在不同任务上直接学习的性能,造成负迁移。
(3) 怎样迁移。下文将具体展开“怎样迁移”的问题。目前大多数工作一般都假设多个任务间是存在某种关联的,针对式(2),集中精力解决迁移什么与怎样迁移的问题。
式(2)的主要目标是提出一个促进知识转移的策略(q>0),理论上保证最小化不同优化任务之间的负交互(负迁移)。MFEA-II提出了一种新的数据采集方法,用于q值的在线迁移参数估算,从而获得式(2)中最优的混合分布。给定K个优化任务的对称K×K矩阵,表示为
式中:qj,k=qk,j,qj,j=1, ∀j。在第t代,假设gk(x,t)是任意第k个任务真实分布pk(x,t)的概率模型。所以,gk(x,t)是 由子种群Pk(t)的数据集所构建的。用算法学习到的概率模型代替真密度函数,用Q的元素代替标量q,所以式(2)可以写为
gkc(x,t)是 近似分布的后代种群pkc(x,t)的概率混合模型。因此, 对于所有k∈{1,2,···,K},为了使pkc(x,t)更好地进化于pk(x,t),相当于用后代概率模型gkc(x,t)准确模拟父代分布pk(x,t),从而计算得到Q。
4.3 以MMD作为度量准则
为了缓解知识迁移不充分的问题,使用最大均值差异法对Q矩阵新的评价方法来改进混合概率分布的知识迁移。
度量的核心是衡量2个数据集之间的差异,计算2个向量(点、矩阵)的距离和相似度,本文MFEAMMD算法用到的度量准则是最大均值差异。MMD一般用于双样本检测,直观地判断2个数据的分布。假设有一个满足父代种群P分布的数据集X=[x1,···,xn]和 一个满足子代种群Pc分布的数据集Xc=[xc1,···,xcm]。再生希尔伯特空间H(RKHS)存在一个映射函数ϕ (·):X→H表示从原始空间到希尔伯特空间的一个映射,当n,m趋 于无穷时Xx和Xcx的最大均值差异可以表示为
式(5)对每一个种群的数据样本进行投影并求和,利用和的大小表述2个种群的分布差异。
MMD在风格迁移中运用广泛,其神经网络主要是通过最小化两个网络的分布差异而优化,同时有很多关于把MMD作为迁移学习神经网络最后的损失函数的研究。
对式(4)改进,概率混合模型gkc(x,t)与pk(x,t)的MMD为
即求
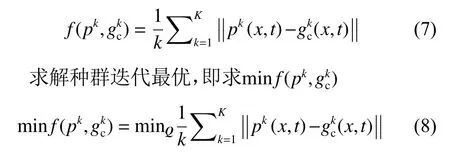
即求
因为概率密度函数pk(x,t)收 敛于Pk(t),所以
因为对于所有任务 {T1,T2,···,Tk,···,TK},gkc(x,t)收敛于pk(x,t) ,给定第k个任务的每个子种群Pk(t)的N/2个父代解,所以
式中:E[·]是 期望值,xik是第k个任务种群Pk(t)数据集的第i个个体,所以式(12)求
MFEA、MFEA-II、MFEA-MMD算法对比框架如图1所示。

图1 MFEA,MFEA-II和MFEA-MMD算法对比框架Fig.1 The framework comparison of MFEA, MFEA-II and MFEA-MMD

5 实验结果与分析
5.1 实验设置与性能指标
本文的实验环境是Mathlab,PC处理器为i7,内存32 GB,Win10操作系统,训练的目标任务函数为trap-5函数。
实验设置:所有算法的每个任务种群大小N都保持相同,以确保一致性。如果单任务算法对这K个任务的每个任务都使用N个种群大小,那么处理相同K个任务的多任务算法的种群大小为NK。
(1) 统一搜索空间,范围[0,1]Dunified。
(2) 概率pc=1,分布指数ηc=15 ;概率PM=1/d,分布指数ηm=15。
(3) MFEA-MMD、MFEA-II和MFEA的概率模型:种群规模(N)100,最大函数评估15 000。
下文以一组最有代表性的二元优化问题作为目标函数(trap-5函数)。当将连续统一空间(X=[0,1]Dunified)的候选解解码到离散/二进制空间时,如果编码后的对应变量≤0.5,则将其赋值为0。否则,它被赋值为1。在这项研究中,研究了文献中3个流行的二元问题,即o nemax、z eromax和具有高度欺骗性的trap-5问题[28]。onemax 的最优值是所有1的字符串,z eromax的最优值是所有0的字符串。在trap-5中,字符串首先被分割成由5个不重叠的位组成的连续组。对每一组应用5位陷阱函数,每一对组合目标函数的值为
5.2 实验结果分析
由图2可以看出MFEA-MMD在40代左右开始收敛,MFEA-Ⅱ在50代左右开始收敛,MFEA-MMD比MFEA-Ⅱ有更快的收敛速度,而且收敛趋势更为平稳。
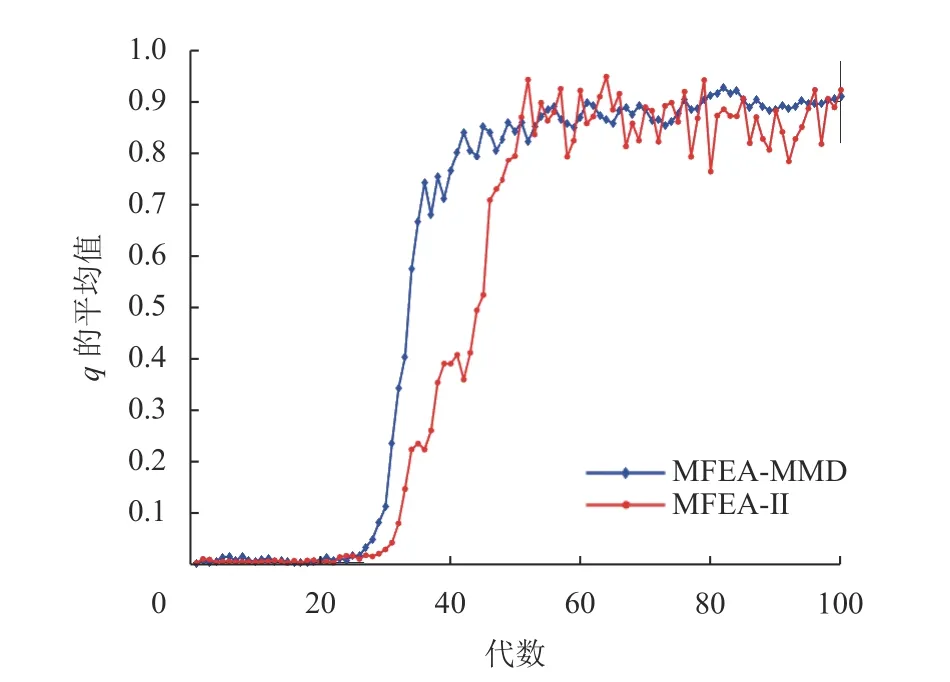
图2 MFEA-MMD和MFEA-Ⅱ连续几代种群在的不同任务之间两两学习的q平均值Fig.2 The pairwise q’s learned between distinct tasks over successive generations of MFEA-MMD and MFEA-Ⅱ
表1展示了MFEA-MMD比MFEA-Ⅱ更能充分学习和利用任务间的协同效应。MFEA-MMD整体q均值比MFEA-II高出6.65%,种群中有用信息的知识迁移率高出35%,算法运算速率高出29%。
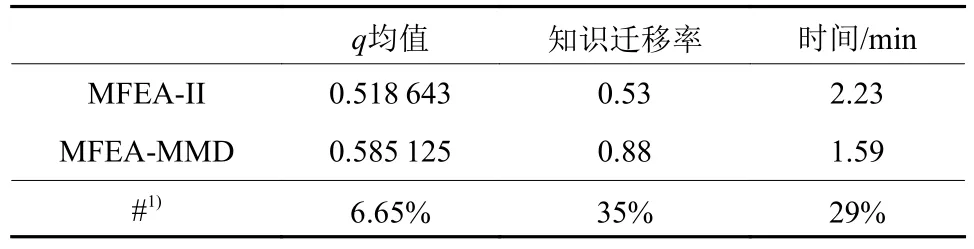
表1 MFEA-MMD和MFEAⅡ的知识转移程度Table 1 The knowledge transfer of MFEA-MMD and MFEA-Ⅱ
为了说明MFEA-MMD的优越性,o nemax 的最优解与trap-5的全局最优解相交,这意味着基于跨任务的遗传物质交换确实是一种合适的转移模式。然而,由于trap-5中存在大量的局部最优,所以两个任务之间不受抑制的任务间交叉是不利的,这可能会阻碍onemax 的收敛特性。此外,z eromax问题显然在解决方案相似性方面与o nemax相冲突,并进一步与trap-5问题相冲突。然而,trap-5最坏的局部最优对应于zeromax的全局最优。因此,使用现有的MFEA-I(手动指定的标量q) 和MFEA-II(自动调节的Q矩阵)同时解决这3个任务将容易受到负迁移的影响。本文求解了rap-5、onemax、zeromax这3个问题共200个变量的多任务变体,由MFEA-I、MFEA-II和MFEA-MMD同时处理这3个任务。
超过30次独立测试的实验结果总结包含在图3中,给出了高度欺骗性trap-5问题的收敛趋势。总的来说,可以观察到多任务优化(MFEA-I,MFEAII和MFEA-MMD) 的遗传物质转移范围是有益的,但是MFEA-I相比MFEA-II的收敛性差很多,而MFEA-MMD的收敛性和稳定性都比MFEA-II更强。另外,MFEA-I并不总是收敛到全局最优。这主要是由于MFEA-I基因的无种群间交换,使其容易受到负迁移的影响。然而,MFEA-II和MFEA-MMD能利用从任务数据集学习到的关系来优化命令知识转移(在优化阶段的不同阶段),MFEA-MMD的任务间知识迁移比MFEA-II更为充分,知识迁移程度大约高出35%。在初始阶段,当3个任务之间的转移不太可能有帮助时,知识迁移程度都比较低。逐步地,一旦有高质量的遗传物质可以从 onemax 和z eromax问题转移到trap-5问题(大约经过40代),在线参数估算方案就开始规定相应任务间q的更高值。如图2所示,q值较高时,o nemax的正向转移引导trap-5持续(且快速) 收敛到全局最优。结果表明,3种多任务变体相比,MFEA-II优于MFEA-I,MFEA-MMD收敛速度最快最平稳,后者在3个算法当中最有优势,MFEA-II和MFEA-MMD成功地识别并利用了正迁移,同时绕过了困扰MFEA-I的负迁移(见图3)。
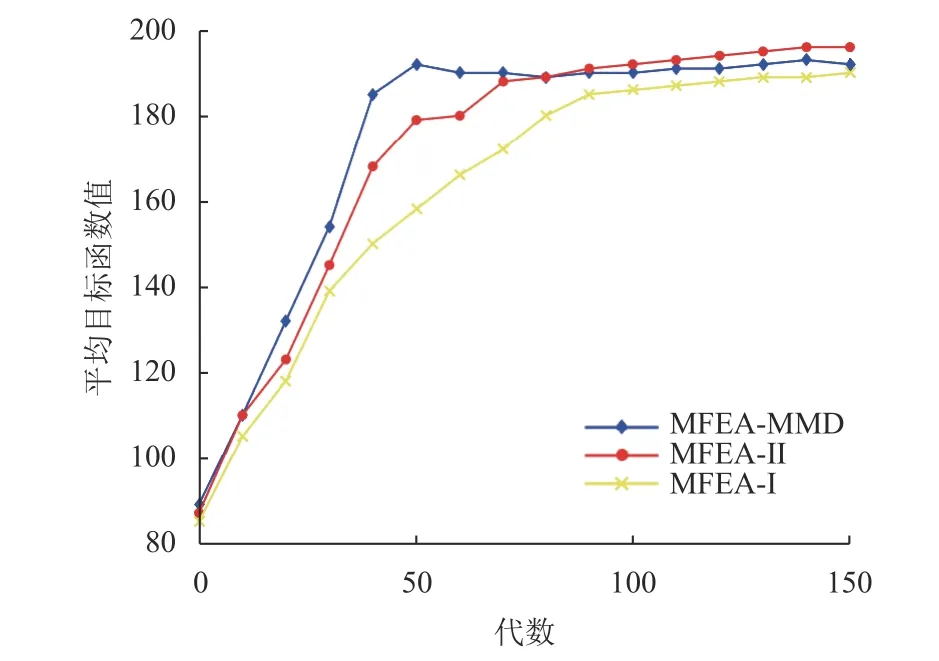
图3 所有算法在trap-5问题上求解的收敛趋势(平均超过30次独立运行)Fig.3 Convergence trends of trap-5 (averaged over 30 independent runs) achieved by all the algorithms on the trap-5 problem
上述任务提供了一个理想的案例来展示MFEAMMD知识转移方案相比于MFEA-Ⅱ的优势:(1) MFEA-MMD的知识迁移效率比MFEA-Ⅱ平均高出29%,知识迁移程度大约高出35%;(2) 前者求解函数结果的收敛比MFEA-Ⅱ和MFEA-Ⅰ更快更高效;(3) MFEA-MMD比MFEA-Ⅱ运算速率更快,占用的计算机资源更少。
6 结论
本文提出了一个使用MMD方法的多任务传输参数估算方案,能够实时充分学习和利用任务间的协同效应。首先从理论上分析了现有进化多任务框架MFEA-I对负迁移的敏感性。然后测试在线传输参数估算MFEA-II,动态控制任务间的知识交换程度。为了以纯数据驱动的方式在线捕获任务间的相似性,引入了以MMD方法为多因子进化的算法种群混合概率模型度量准则,基于概率模型的最优混合模型来调整知识迁移范围,使有用信息充分迁移。MFEA-MMD的算法贡献可以从2个方面进行总结。(1) 传输参数采用对称矩阵的形式,以便在2个以上任务之间有效地进行多任务处理。(2) 在多任务搜索过程中,实时调整传递参数矩阵和充分迁移知识。MFEA-MMD的实用性在一系列综合优化和实际优化问题上得到了实验验证。实验结果表明,该算法善于在多任务优化过程中利用任务之间的相似性和差异性,MMD的方法是自动的,排除人为干预调控参数,MFEA-MMD与MFEA-II相比更有优越性。
展望未来,云计算、物联网等新兴平台将提供大规模数据存储和无缝通信设施,从而使嵌入式优化求解器能够利用相关任务提供的知识(数据)。期望多任务处理算法能在更有效率和更有效的同时,在解决多个任务中发挥关键作用。
猜你喜欢
今日农业(2022年15期)2022-09-20
水利规划与设计(2020年1期)2020-05-25
大经贸(2020年2期)2020-05-08
中国生物医学工程学报(2019年6期)2019-07-16
红土地(2018年7期)2018-09-26
电子技术与软件工程(2017年10期)2017-06-02
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
计算机工程(2014年6期)2014-02-28
当代畜禽养殖业(2014年10期)2014-02-27
