
基于Bi-LSTM网络的管道异常数据检测方法
2023-06-15 08:03李春生田梦晴张可佳
计算机技术与发展 2023年6期
李春生,田梦晴,张可佳
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163319)
0 引 言
随着物联网技术的发展和普及,传感器、智能仪表等设备已实现了对管道数据的实时采集,并积累了大量复杂、高维的时序数据[1]。异常数据检测就是在时间序列中检测出不符合业务逻辑或规则的事件或行为[2]。为保证异常检测的高检测率,科研人员热衷于研究“如何提高异常数据检测算法的性能”,取得的研究成果已广泛应用在网络安全、金融、医疗、国防军事等多个领域[3-11]。
针对管道数据这种复杂、多维的时序数据,一般的阈值划定、判定方法由于处理速度慢、准确性低,已经无法满足目前的管道异常数据检测的需求。随着人工智能和深度学习技术的飞速发展,逐渐开始用于解决不同领域的异常数据问题,并取得了良好的效果。相关的国内外研究工作如下:刘政等[12]用粒子群算法对神经网络进行优化,建立预测模型,从而进行异常数据的检测。通过深度网络学习时间序列之间的关系建立预测模型,通过预测结果与实际序列的偏差进行异常检测[13-14],但面对复杂数据时会出现特征提取不全等问题。赵文清等[15]利用LSTM网络处理时序数据的优势,同时利用全连接层来检测异常数据。通过研究发现,LSTM网络仅仅考虑正向的时序信息,没有考虑反向的时序信息,从而导致异常数据检测效果有待提高,因而双向长短期记忆网络被提出运用到异常数据检测中。
综上所述,单独采用统计、聚类、神经网络等技术的异常检测方法很难解决“特征提取不全和数据间关系挖掘不充分导致异常检测方法准确率低”的问题。为进一步提高异常数据检测方法的准确率,该文借鉴“分而治之、优势互补”的混合智能算法设计思想,提出一种融合CNN和Bi-LSTM的管道异常数据检测方法。首先,使用CNN对管道数据的局部非相关性信息特征进行提取;其次,利用Bi-LSTM网络处理时序数据的优势,将得到的特征向量输入到Bi-LSTM网络中进行训练并充分挖掘管道数据间的逻辑关系,得到预测模型;再次,使用预测值与实际值的误差来检测异常数据;最后,通过实验论证方法的有效性,并与不同检测方法进行比较得到该方法的准确性较高、误报率较低。
1 相关工作
1.1 相关定义
定义1:取一组管道数据表示为Xt=[x1,x2,…,xm]T,其中X∈Rm×n且t∈[1,m]。xt表示t时刻所有属性值的集合,其中xt∈Rn,xti表示时刻t第i个属性值,即xt=[xt1,xt2,…,xtn]。Xt则为m阶n维向量,展开式如公式(1)所示。
(1)

1.2 异常数据表征分析
在管道运行的过程中,导致管道数据出现异常值的原因较多,其中包括通信故障、通信延迟;管道泄漏造成的相关数据值大幅度下降;高强度、长时间的使用可能使传感器设备不灵敏或者损坏造成的数据不准;阀滤网单向堵造成数据值出现震荡等。
异常检测的目标就是找出样本中的异常点[16]。管道异常数据主要分为点异常和群异常两种情况:点异常也称为突变值异常,指的是管道数据在某一时刻的压力值、流量值、温度值等出现较大程度的升高和降低,过一段时间后又恢复到正常数据的情况。例如通信延迟可能使管道数据产生突变值异常数据。群异常,指的是管道数据普遍升高、降低、不变。例如计量仪器故障、阀滤网单向堵、通信故障、管道泄漏等方面造成的群数据异常。因此,在判断管道数据异常时需要根据具体的情况进行分析。
1.3 相关技术
1.3.1 卷积神经网络
CNN为深层前馈神经网络,由卷积层、池化层构成,每层都有不同的功能,卷积层利用卷积核对输入向量进行卷积,得到特征向量。池化层分为最大池化、均值池化,池化层的作用是减少特征向量和参数的大小。例如,传感器采集的管道数据为时序数据,因此使用一维卷积神经网络对处理后的数据进行特征提取,卷积层计算公式如下所示:
F=f(W×X+b)
(2)
式中,X表示输入数据向量,W表示卷积核权重矩阵,b表示偏置向量,f(·)为激活函数ReLU。
因此,该文采用CNN对管道数据进行特征提取,CNN结构如图1所示。

图1 CNN基本结构
1.3.2 双向长短期记忆网络
长短期记忆神经网络(LSTM)在处理时间序列数据上具有一定的优势,其具有门控结构,能够对细胞信息进行选择性删除和添加,避免出现“梯度消失”和“梯度爆炸”等问题。LSTM神经单元的三个“门”结构包括遗忘门、 输入门和输出门。t时刻的计算表达式如下:
ft=σ(Whfht-1+Wxfxt+af)
(3)
it=σ(Whiht-1+Wxixt+at)
(4)
οt=σ(Whoht-1+Wxoxt+ao)
(5)
(6)
(7)
ht=ot*tanh(Ct)
(8)
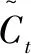
基于LSTM网络,Bi-LSTM网络可以利用过去和未来的数据进行学习,从而预测未来时刻的参数,弥补了LSTM网络的不足。Bi-LSTM的隐藏层由正向LSTM细胞状态和反向LSTM细胞状态两部分组成。Bi-LSTM的网络结构如图2所示。

图2 Bi-LSTM网络结构

(9)
(10)
(11)
2 CNN-BiLSTM网络异常数据检测模型
本章节设计基于CNN-BiLSTM网络异常数据检测模型,主要包括数据预处理阶段、数据预测阶段、异常检测阶段。
2.1 异常数据检测流程设计思路
为进一步提高异常检查方法的准确性,该文提出一种基于CNN-BiLSTM网络的管道异常数据检测方法,该方法主要包含数据预处理、数据预测和异常检测三部分,异常检测流程如图3所示。
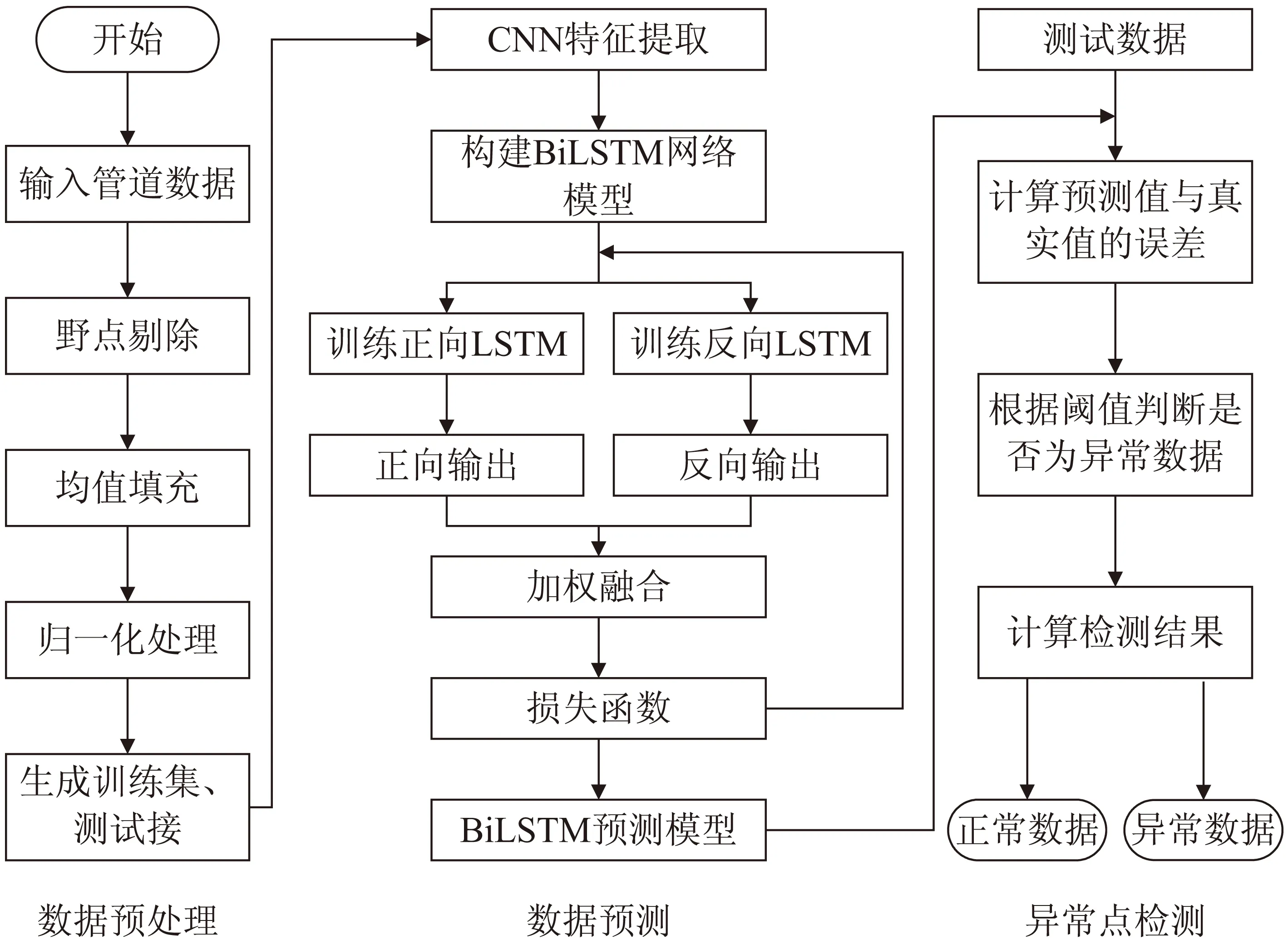
图3 CNN-BiLSTM网络异常检测流程
(1)数据预处理。对输入的管道数据进行野点剔除、均值填充、归一化处理。数据预处理的步骤为:首先是对管道时序数据进行野点剔除操作,由于各种偶然因素导致的个别数据点的值过高或过低(野点),采用53H算法剔除野点;接着对剔除后的数据进行均值填充;然后对填充后的数据进行归一化处理,这是由于管道数据的不同属性数据的量纲也是不同的,差异较大时会影响检测的结果,通过归一化处理,将数据转化为统一量纲,使数据分布在设定的区间[0,1]内。公式如下所示:
(12)

(2)数据预测。将处理后的数据经过CNN网络进行特征提取,然后通过Bi-LSTN网络训练并学习管道数据间的关系,得到预测模型,输出预测值。
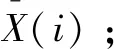
2.2 CNN-BiLSTM网络异常数据检测模型
CNN的优势是利用卷积、池化操作进行特征提取,不仅实现了高维数据的降维,还减少了要训练的参数,降低了全连接神经网络的计算复杂度,减少过拟合现象的出现,实现了输入数据关键特征的提取。Bi-LSTM网络利用其处理时序数据的优势,能够充分挖掘管道数据间的关系,从而提高异常数据检测方法的准确性。因此,利用CNN和Bi-LSTM网络构建预测数据模型,从而得到预测值,具体实现步骤如下:
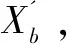
步骤2:模型参数设置。基于理论研究和管道数据特点,CNN卷积层为1层,卷积核大小为2×2。Bi-LSTM隐藏层为2层,Bi-LSTM层设置60个隐藏神经元,优化器选择Adam,迭代次数为3 000,输入层的管道时序数据长度为6,而输出层的输出时间序列长度为1,其学习率为0.006,经过CNN 提取特征后,变量数为1,输入层和输出层维数均为1。模型训练的过程中,为提高模型的预测精度,可以对各项参数值进行适当修改。
步骤3:模型训练。构建CNN-BiLSTM网络异常检测模型,输入有效向量进行训练,损失函数选择均方误差(MSE),如公式(13)所示。通过损失函数的计算,进行反馈调节,调整网络参数设置,MSE最小值时,训练停止,得到最终预测模型。
(13)
由图2可知,正向LSTM网络和反向LSTM网络的运算过程如公式(14)所示:
(14)

结合正向LSTM网络和反向LSTM网络,形成双向神经网络,则可以得出Bi-LSTM网络的输出,公式如下所示:
(15)
式中,g为激活函数;yt为Bi-LSTM网络的输出;V和c分别为相应的权重和偏置。
最后得到历史管道数据与未来管道数据的拟合关系,预测模型为Ytrain=f(w,b)Xtrain。由于输入的数据是归一化处理后的数据,因此,通过模型得到的预测值需要进行反归一化处理,处理过程如公式(16)所示。
Yfg=postmnmx(Yg,min(t),max(t))
(16)
式中,Yfg为Yg反归一化后的输出数据,Yg为预测值。
2.3 动态阈值的确定
传统的异常数据检测方法中大多是采用固定阈值,但是在实际的应用过程中存在灵敏性较低、误报率较高等问题,阈值的选取决定着异常数据检测的准确性。因此,该文引入动态阈值计算方法[17-18]得到不同特征的阈值。初始化阈值β,公式如下所示:
β=μ(se)+qσ(se)
(17)
式中,q为固定范围内的随机数,表示大于μ(se)标准偏差的数量。利用该预测误差序列se分为异常误差序列sa和正常误差序列sn,并计算阈值ε,公式如下所示:
(18)
式中,Mseq表示每个特征中异常序列的数目,且Δμ(se)=μ(se)-μ(sa),Δσ(se)=σ(se)-σ(sa)。
通过不断改变q来计算阈值ε,将ε与上一个阈值比较,若当前的阈值大于上一个阈值则替换q,否则继续保留,从而确定每个特征的目标阈值ε。
3 实 验
3.1 实验环境
实验在Windows10操作系统上运行,CPU为Intel Core i7-1165G7(1.2 GHz/L3 12 M),内存16 GB,显卡为Intel Iris Xe Graphics,固态硬盘为1 TB;在 PyCharm 集成开发环境上编写计算程序 使用的语言是Python3.6。
3.2 数据集
实验数据选取盘锦市某油田管道真实数据作为实验样本,按照7∶3比例分为训练集和测试集。收集10组实验数据,包括5组正常数据和5组异常数据,每一组数据包含不同时间段的管道压力、管道温度、管道流量、环境温度等,异常数据集基本信息如表1所示。

表1 异常数据基本信息
实验的测试数据来自盘锦市某油田2021年11月份的管道运行数据,选择管道温度、管道压力、管道流量、环境温度各600条,测试集基本信息如表2所示。

表2 测试集基本信息
3.3 评价指标
选用准确率(Accuracy)和召回率(Recall)作为评价指标。准确率表示的是检测正常的样本数据占全部检测样本的比值,比值越大,检测的效果越准确、越好。召回率指正确检测出来的异常数据个数与实际异常数据个数的比值,比值越大,表示检测的效果越好。计算公式分别为:
(19)
(20)
式中,TN表示的是实际值为正常且检测也正常的数据个数;FP表示的是实际值为正常且检测为异常的数据个数;FN表示的是实际值为异常且检测为正常的数据个数;TP表示的是实际值为异常且检测为异常的数据个数。
3.4 实验结果分析
为验证所提异常数据检测方法的有效性,选取测试数据集,将所提方法与K-means算法、LSTM网络、Bi-LSTM网络3种方法进行对比,验证基于CNN-BiLSTM网络的异常数据检测方法的效果。
图4为K-Means、LSTM网络、CNN-BiLSTM网络的压力预测值和真实值的对比图,图5为K-Means、LSTM网络、CNN-BiLSTM网络的流量预测值和真实值的对比图。分析可得,CNN-BiLSTM网络异常点数据的预测值与实际数据更加精准、贴近,异常数据基本找出,相比较于其他方法,准确率最高。

图4 不同方法检测压力真实值与预测值对比

图5 不同方法检测流量真实值与预测值对比
图6~图8分别为K-Means算法、LSTM网络、Bi-LSTM网络检测异常数据的效果图。可知K-Means算法、LSTM网络和Bi-LSTM网络均会出现漏检和误检等情况。由此可以得到神经网络比K-Means算法异常检测效果好,是由于神经网络考虑到了管道数据的时序性。由图7、图8对比可得,双向神经网络比单向神经网络的效果好,是因为双向神经网络还考虑到了反向时序信息。
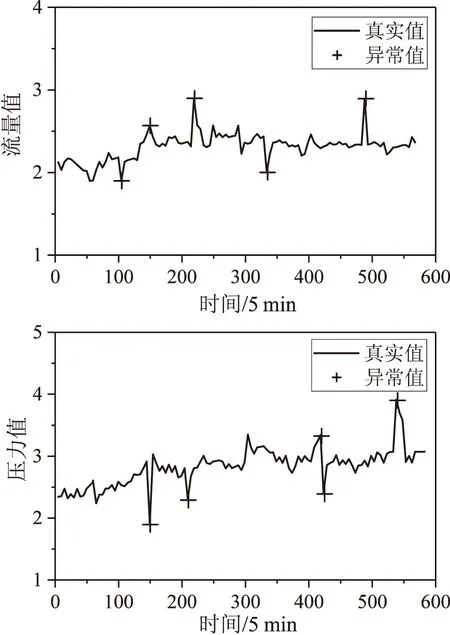
图6 K-Means算法异常数据检测结果

图7 LSTM网络异常数据检测结果

图8 Bi-LSTM网络异常数据检测结果
由表3可知,针对管道异常数据情况,相比较于已有的异常检测算法,CNN-BiLSTM网络优于同类算法,这是由于该方法通过CNN对管道数据进行特征提取和降维,得到有效的特征向量,然后利用Bi-LSTM网络处理管道数据双向时序信息的优势,可以有效检测大量、复杂数据中的正常值和异常值,各项评价指标均较高,证明了该方法的准确性和优越性。
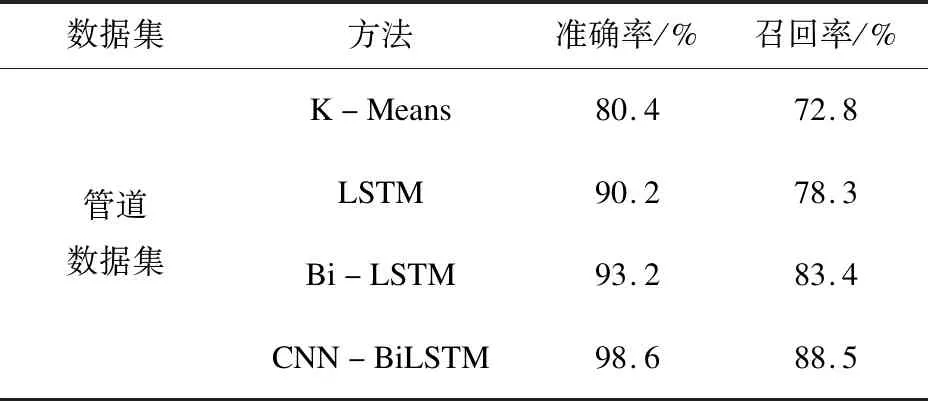
表3 不同评价指标对比
4 结束语
针对特征提取不全、数据间关系挖掘不充分的问题,提出了一种基于CNN和Bi-LSTM网络的异常数据检测方法,进一步提高了异常数据检测方法的准确率,降低了误报率。
实验结果表明,CNN-BiLSTM网络方法相比同类模型在检测速度、检测精度和稳定性方面具有明显优势。CNN能够高效地提取管道数据特征;Bi-LSTM网络利用其记忆功能和处理双向时序信息的优势,极大地提高了预测精度;动态阈值的确定有效地解决了灵敏性差等问题,能够准确地检测异常点,同时还为异常数据填补正常的数值。未来的管道数据异常检测可能还会对异常检测结果的可解释性提出新要求,同时要找到产生异常点的原因,这也是异常检测方法的改进方向。
猜你喜欢
中国农业信息(2021年3期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
制造技术与机床(2019年9期)2019-09-10
电子制作(2019年11期)2019-07-04
西南交通大学学报(2018年6期)2018-12-18
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2017年13期)2017-12-15
河北遥感(2017年2期)2017-08-07
电子制作(2016年15期)2017-01-15
衡阳师范学院学报(2016年3期)2016-07-10
