
一种优化的近邻保持嵌入降维算法研究
2023-06-15 08:00李燕燕闫德勤
计算机技术与发展 2023年6期
李燕燕,闫德勤
(1.河北建筑工程学院,河北 张家口 075000;2.辽宁师范大学,辽宁 大连 116081)
0 引 言
大数据环境下的高维数据在人脸识别、图像检索[1-3]等领域有着广泛的应用前景,是数据挖掘和模式识别领域的研究热点。但是高维数据具有冗余度大、空间维数高等特点,难以发现其内在的特征规律。降维是消除高维数据维度上冗余的一种技术手段,目的是克服维数灾难,获取数据本质特征,以实现数据可视化。
降维分为线性降维和非线性降维。线性降维算法主要有主成分分析(principal component analysis,PCA[4])、多维尺度变换(multidimensional scaling,MDS[5])、线性判别分析(linear discriminant analysis,LDA[6])等。这类方法的优势在于处理线性结构的数据集时具有很好的降维效果。但现实生活中大多都是高维非线性数据,例如人脸数据,因此非线性降维方法应运而生。基于特征值的非线性降维方法是其中一个重要研究方向。这类方法是保持高维数据与低维数据的某个“不变特征量”以找到低维特征表示。主要的基于特征值的非线性降维算法有等规度映射(isometric feature mapping,ISOMAP[7)、局部切空间算法(Local tangent space alignment,LTSA[8])、局部线性嵌入(locally linear embedding,LLE[9])、拉普拉斯特征映射(Laplacian eigenmaps,LE[10])、近邻保持嵌入(neighborhood preserving embedding,NPE[11])等。ISOMAP算法保持的不变特征量是测地距离;LTSA算法保持的不变特征量是利用局部PCA投影后的局部线性化;LLE算法和NPE算法类似,保持的不变特征量都是局部重构系数;LE算法保持的不变特征量则是数据邻域关系。
目前,学者们已经在人脸识别[12]、语音识别[13]等众多领域对NPE算法展开了广泛的应用研究。例如,王志强对非控环境下获取的高维人脸图像进行降维研究,期望寻找一种映射或者投影,得到高维复杂数据中的低维本质结构[14];Zhen Ye等人提出了基于稀疏或协同表示的降维方法,将稀疏或协同系数作为图像的权值,有效地减少重建误差[15]。但是在进行线性重构时没有考虑到类间的权值信息以及类内的密度信息,因此在数据降维上仍有局限性。梁春燕等人通过构建邻接图以获得数据的局部邻域结构,同时通过有监督训练对数据进行类别标注[16]。尽管考虑到了数据类间之间的信息情况,进一步提高数据的识别性能,但对数据类内信息欠学习,算法的性能需进一步提高。Sumet Mehta等人[17]提出了一种加权邻域保持嵌入算法(WNPEE),构造了一个相邻图的集合,使得最近邻的数目k的选择是变化的,这种方法对邻域大小参数的敏感性相比NPE要低得多,尽管敏感度有所下降,但没有有效考虑到数据的类别信息,算法的优越性也会有所下降。
上述降维算法都有较强的计算优势,但是在处理局部邻域信息量不足、存在短路以及流形曲率大等稀疏数据时,原始数据的几何拓扑结构损坏严重。基于此,本文对NPE算法中的数据类间信息进行优化,构造类间权值矩阵,在邻域选择中可对数据类间信息进行很好的区分;并在低维局部重建时引入类内密度信息。从数据类内和类间两个维度出发,更好地避免数据在近邻选取方向上的缺失,提出了一种优化的近邻保持嵌入算法(optimal NPE,ONPE)。
为了验证ONPE算法的实用性和有效性,将ONPE算法与LLE、NPE在Coil-20数据库上进行了对比实验,并对实验结果进行了分析,证明了新算法具有较强的鲁棒性。
1 NPE算法
1.1 NPE算法的思想
NPE算法是一种非常重要的子空间学习算法,认为每一个数据点都可以由其近邻点的线性加权组合构造得到。因此,NPE算法的降维原理是试图在降维过程中保持样本局部的线性结构不变,以在低维空间中进行二次特征提取。
假设高维空间RD中有N个样本训练集X=[x1,x2,…,xN],xi∈RD,通过LLE算法寻求一个最优的映射变换矩阵M,将X映射到低维空间Rd中,从而得到低维数据集Y=[y1,y2,…,yN],yi∈Rd,且d≪D。
NPE算法可以归结为三步:
(1)寻找每个样本点的k个近邻点。
NPE算法把xi表示成如公式(1)所示的凸组合形式,也就是xi可由k个最近邻线性表示,所以要求数据所在流形为凸集。
(1)
在高维空间中寻找每个样本点的k近邻点。距离公式通常可以用式(2)表示:

(2)
一般选用P=2,采用欧氏距离表示两点之间的实际距离。
(2)计算出样本点的局部重建权值矩阵。
定义一个误差函数ε(W),其中Wij(i=1,2,…,N)可以存储在N×N的稀疏矩阵W中,这个矩阵并不是对称的,即Wij≠Wji,对于两个近邻的点而言,它们各自的近邻程度是不同的。
(3)
其中,xj(j=1,2,…,k)为xi的k个近邻点;Wij是xi与xj之间的权值,且要满足条件:
(4)
其中,Wi=[Wi1,Wi2,…,WiN]为第i个样本点的局部重建权值。
(3)将所有的样本点映射嵌入到低维空间Rd中。映射嵌入满足如下条件:
(5)
利用权值向量Wij重构数据间的局部几何拓扑结构,并使局部重建损失函数φ(Y)取值最小,从而得到低维嵌入数据集Y=[y1,y2,…,yN]。
NPE算法其实是一个线性重建的过程,利用局部的线性来逼近全局的非线性,通过相互重叠的局部信息提供全局结构的信息。
1.2 NPE算法降维失效的原因
总的来说,NPE算法对局部邻域信息量不足、存在短路以及流形曲率大等稀疏数据降维失效有两个原因:一是NPE算法在k近邻选择时只是单纯利用欧氏距离确定样本点的线性结构,没有考虑到数据间的类别信息,可能使得不同类别的数据交织在一起,影响降维效果。二是稀疏数据间的密度变化较大,仅单纯利用Wij进行低维几何拓扑结构的重建,不能很好地反映k近邻的密度信息。基于上述原因导致局部信息难以正确刻画,难以反映数据间的几何拓扑结构,导致降维失败。
2 改进的近邻保持嵌入(ONPE)
2.1 类间权值的刻画
NPE算法是用两数据点间重构权值Wij来保持数据在低维空间的几何拓扑结构不变。但是NPE算法没有考虑到数据间的类别信息,在近邻选择时,容易把不同类别的数据划分到一个近似线性的局部流形结构中,从而造成在实际应用中无法揭示数据内在的真实结构,如图1所示。

图1 未考虑到类别信息的近邻选择情况

为了解决上述问题,尽量使类内距离最小,而类间距离最大。因此,采取以下解决方案,一是在ONPE算法中引入了类间权值,以增加类间的离散度,使降维后不同类别之间具有最优的分离性。二是在类内引入密度信息,并用密度信息来调整类内权值距离矩阵,以使类内分散度尽量小。
2.2 ONPE算法的基本思想
假设高维空间中有数据集X={x1,x2,…,xN},xi∈RD,将X嵌入映射得到低维空间中的数据集Y={y1,y2,…,yN},yi∈Rd(d≪D)。将训练样本X分成t类,X=(X1,X2,…,Xt),低维嵌入为Y=(Y1,Y2,…,Yt)T,ONPE算法将公式(5)的目标函数定义为:
(6)

将上述公式(6)中的φ(W)函数变化为:
(7)
对公式(7)进行化简:
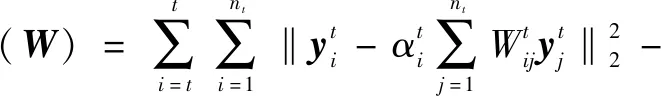
MTS(I-Z)T(I-Z)STM=
MTX(I-Wt)T(I-Wt)XTM-
MTS(I-Z)T(I-Z)STM=
tr(MTB1M-MTB1M)=
tr(MT(B1-B2)M)
(8)
其中,
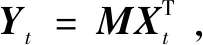
B1=X(I-Wt)T(I-Wt)XT
B2=S(I-Z)T(I-Z)ST
对于公式(8)的限制条件为YYT=NI,结合约束条件,将公式(8)改为:
L(M)=MT(B1-B2)M-λ(YYT-NI)=
MT(B1-B2)M-λ(MTXXTM)
利用Lagrange乘子,则有:
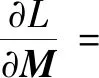
⟹2(B1-B2)M=2λXXTM
根据上式可得M=(a0,a1,…,ad-1),其中a0,a1,…,ad-1为(XXT)-1(B1-B2)的广义特征值λ0,λ1,…,λd-1所对应的特征向量。进而得到低维空间坐标为Y=MTX。
ONPE算法的过程描述如下:

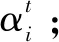
Step3:计算(XXT)-1(B1-B2),将其进行特征分解,得到特征值λ0>λ1>…>λD及其对应的特征向量矩阵U=[a0,a1,…,aD];
Step4:取U的前d个最大特征值所对应的特征向量M=(a0,a1,…,ad-1),得到Y=MTX。
3 实验结果及分析
3.1 图像检索应用
实验采用Columbia object image library的Coil-20数据库作为实验对象, 此数据库共含14类不同的物体,每类都是从72个不同角度拍摄得到的,共1 008幅图像。
利用LLE、NPE和ONPE三种算法对Coil-20数据库进行图像检索。提取图像的Zernike矩作为图像的形状特征,得到基于形状的特征空间。图2是分别利用LLE、NPE和ONPE三种算法对第45号图像作为目标图像进行检索的结果图,并显示前20个图像的返回结果。

图2 Coil-20检索结果对比
采用查准率(Precision)和查全率(Recall)作为图像相似度评价标准来验证ONPE算法的有效性[18]。其中查准率P定义为检索结果队列中检索到的目标图像数与检索结果队列中所有的图像数之比,即P=X/Y,其中X为目标图像数,Y的值等于20,为结果队列中所有的图像数[18]。查全率R定义为检索结果队列中检索到的目标图像数与数据库中全部的目标图像数之比,即R=X/F,F的值等于72,为数据库中全部的目标图像总数[18]。由精确度和查全率的定义可知,P∈[0,1],R∈[0,1]。
对Coil-20数据库中的14类图像分别进行图像检索,并计算出各个图像的查准率和查全率,如表1所示。通过表1的结果可以看出,经过改进后的ONPE算法在查准率和查全率上明显优于LLE和NPE。
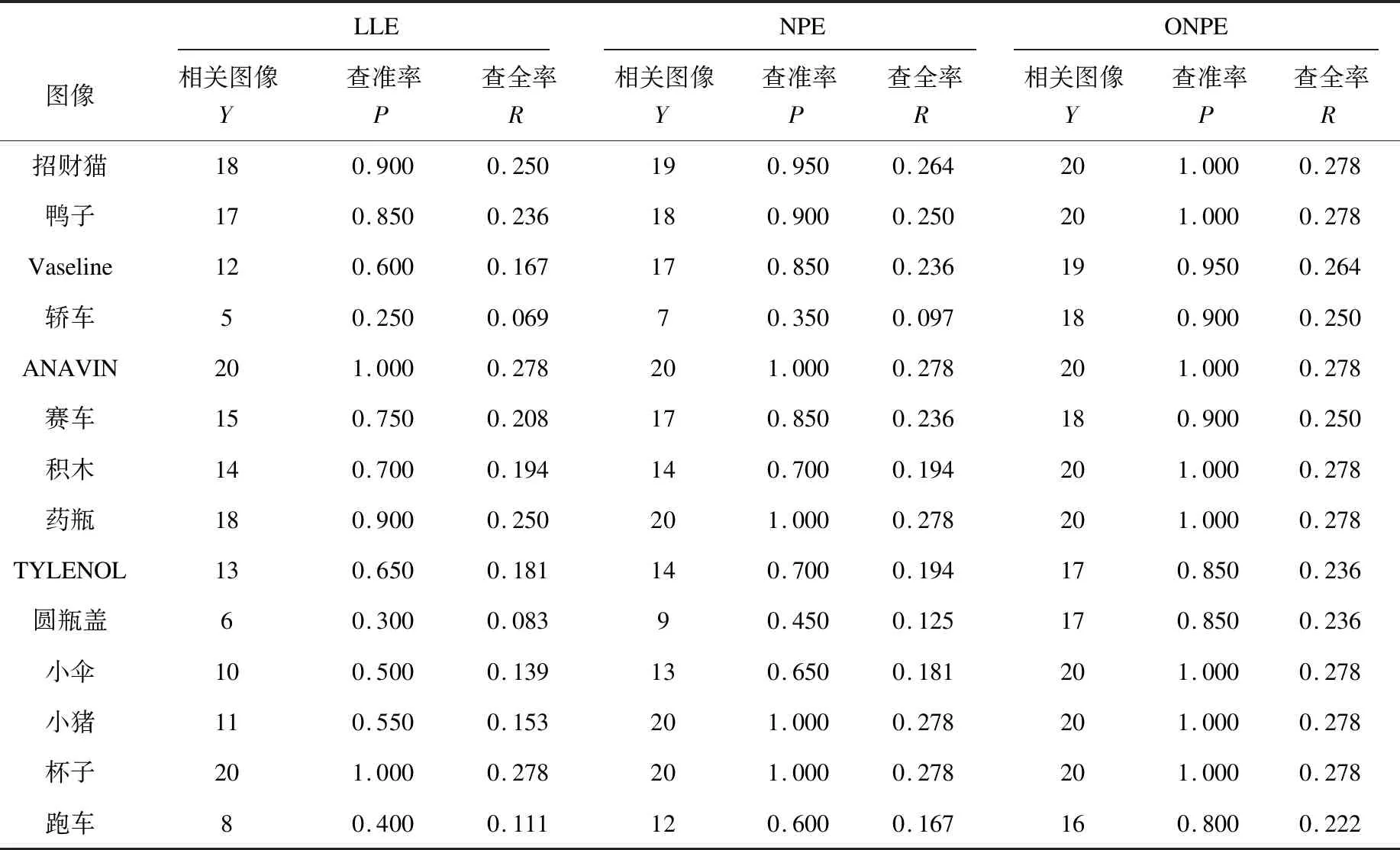
表1 LLE、NPE和ONPE检索结果的查准率和查全率


表2 LLE的检索结果平均排序

表3 NPE的检索结果平均排序

表4 ONPE的检索结果平均排序
最后再做进一步精确判断,由于检索出来的图像的显示顺序(由左到右,由上到下)是按照图像间的相似距离由小到大进行排列的。因此,当越排在前面的图像越与目标图像相似时,说明算法越优。通过图2可见,利用ONPE检索出的20个图像全都是想要得到的目标图像,并且与样本图像相似的图像均排在前19位,只有一个图像与样本图像稍有差别,它则是排在最后一位的。而LLE和NPE均没有这样的优势效果。这也体现出提出的ONPE算法在提取图像的Zernike矩作为图像的形状特征时,有效地保持了Zernike矩的旋转不变性。因此,在检索的精确性上来说相对于LLE和NPE较高。
3.2 实验结果分析
从上述实验可以看出,NPE和LLE作为经典的流形学习算法,均能保持流形的局部结构不变。但ONPE在处理稀疏数据时降维效果却远优于NPE和LLE,其主要原因分析如下:
(1)ONPE算法考虑到数据间的类别信息,引入了类间权值矩阵,类间距离对数据类别的可分性起着重要作用。在特征选择和特征提取时,可确保使得类间分散度尽量大。

3.3 时间复杂度分析
降维算法的时间复杂度主要是由数据点的个数N、原始维数D以及近邻点的个数k进行确定。
LLE和NPE算法的时间复杂度均是o(pN2)(其中p是稀疏矩阵中非零元与零元的比率)。ONPE同NPE在算法执行过程中不同之处在于类间权值矩阵和类内密度信息的构造,计算类间权值矩阵所需时间为o(2DN2),计算类内密度信息所需时间为o(kN)。综上,ONPE的时间复杂度亦是o(pN2),类间权值矩阵和密度信息的计算并没有增加算法总的时间复杂度。
4 结束语
该文对经典的流形学习算法LLE和NPE进行研究,针对处理局部邻域信息量不足、存在短路以及流形曲率大等稀疏数据时失效的问题,提出了一种优化的近邻保持嵌入降维算法ONPE。在ONPE算法中引入了类间权值,以增加类间的离散度,使降维后不同类别之间具有最优的分离性;在类内引入密度信息,并用密度信息来调整类内权值距离矩阵,以使类内分散度尽量小。ONPE算法能够更好地保持稀疏数据的原始几何拓扑结构,具有鲁棒性。通过在手工流形、图像检索、可视化等实际领域中的应用,证明了算法的实用性和有效性。
对于该算法进一步的工作思路,是降低邻域大小参数的敏感性,由于ONPE算法对于每个样本点的k近邻的选取是固定的,因此对于不同类别数据间近邻选取方向上会造成偏差。当处理含有噪声或者局部信息量不足的数据集时,找到一个较恰当的邻域个数对于降维效果的影响还是非常大的。因此,可引入压缩感知技术进行子空间的优化,减少降维过程中由于近邻个数选取的不当带来的误差,从而增加了算法的稳定性。
猜你喜欢
车主之友(2022年4期)2022-08-27
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
无线互联科技(2020年22期)2021-01-11
弹箭与制导学报(2020年2期)2020-09-01
海峡姐妹(2019年12期)2020-01-14
传感器与微系统(2018年7期)2018-08-29
自动化学报(2017年4期)2017-06-15
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
