
面向知识服务的文书档案知识聚合模型构建
2023-06-15 04:05:53于英香姚倩雯
北京档案 2023年3期
于英香 姚倩雯


摘要:文书档案主要以文本形式存储,挖掘这些文本档案潜在的知识价值,是政务服务背景下档案工作的重要任务。论文分析了知识聚合在文书档案知识服务中的价值以及进行预处理的必要性,构建了由文本分解层、关联聚合层和服务应用层组成的文书档案知识聚合模型。依据该模型可实现文书档案由粗粒度的文本分解为细粒度的档案知识元,并由档案知识元聚合为可计算的档案数据集,实现文书档案知识服务的提质增效。
关键词:文书档案 知识聚合 档案知识元 知识服务 档案数据
Abstract:Administrativearchivesaremainly stored in the form of text, and mining the potential knowledge value of these text archives is an impor? tant task of archives work under the background of government services.This paper analyzes the necessi? ty of knowledge aggregation in the knowledge ser? vice of administrative archives, constructs a knowl? edge aggregation model of administrative archives composed of text decomposition layer, association aggregation layer and service application layer.Accord? ing to this model,the administrative archives can be decomposed from coarse- grained text into finegrained archives knowledge elements, and the ar? chive knowledge elements can be aggregated into a computable archives data set, so as to improve the qualityandefficiencyofadministrativearchives knowledge service.
Keywords:Administrativearchives;Knowledge aggregation; Archives knowledge elements; Knowl? edge service; Archives data
档案利用向知识服务发展的趋势,已成为档案界的共识。[1]档案领域的服务经历了从信息服务到知识服务的演变。信息服务以分类法、主题法[2]等信息组织方法作为检索工具实现非结构化档案文本的检索服务;知识服务通过基于关联数据的知识组织方法来实现档案信息的深度挖掘与可视化,是大数据时代档案服务的创新。《“十四五”全国档案事业发展规划》中提出:“积极探索知识管理等技术在档案信息深层加工和利用中的应用。”[3]知识聚合正是基于关联数据技术的一种知识组织方法。电子政务时代,文书档案井喷式增长,“一网通办”背景下政府服务新模式更是加速了这种增长趋势,档案资源的数量和规模越来越庞大,如何将这些档案转变为知识资源,提升政府的知识服务能力,是政务服务背景下档案工作的重要课题。
一、知识聚合应用于文书档案管理的价值
知识聚合起源于“数据聚合”[4],知识聚合通过知识组织技术实现知识元的融聚而产生新的知识元,[5]其本质目的是提供知识服务以满足用户的知识需求。[6]近年来,知识聚合成为领域专家和学者讨论的热门话题,国外学者对知识聚合的研究大多聚焦于计算机科学、数学等领域,国内则以图书情报领域的学者为主力军,[7]近年来成为档案领域的热点。牛力等[8-9]最早提出档案的知识化组织五层架构,并在随后研究中以吴宝康档案资源作为实证构建人物事件为导向的四层知识聚合模型;陈海玉等[10]以“南昌起义”数字档案资源为实证构建抗战档案资源三层知识聚合模型;郝琦[11]将评估层融入了知识聚合实践模型;夏天等[12]利用知识聚合构建由数据提供层、语义描述层和知识聚合层三个核心层次构成的语义化重组模型;魏扣等[13]通過服务平台需求分析和搭建结构化服务平台框架构建档案知识聚合服务平台,基于此平台可实现档案知识聚合检索、定制、导航、推荐服务。
综合已有研究发现,档案学界的知识聚合研究虽从理论层面逐渐延伸到实证层面,但针对文书档案文本模态特性的知识聚合研究较少涉猎。文书档案数量庞大,以文本模态存储,含有大量的知识价值,兼具资政价值、凭证价值和情报价值,无论是政府还是公众都对其有较高的知识需求。传统基于文书档案的服务对象是机关,服务的技术方法和服务模式侧重于减少用户的信息搜寻成本,尚未提升到帮助用户更好地理解和利用知识的层面,[14]然而文书档案内含有大量的隐性知识,早在2007年就有学者指出档案学研究边界的拓展可以以“档案”为中心适当向前(文件流)和向后(知识流)发生位移,研究重点聚焦于新技术环境下政府信息流与知识流梳理与设计以及隐性知识的编码化。[15]张玉芳[16]指出通过整理一份文书档案相关的全部档案,可以了解该档案所记录信息的过程、始末等重要信息。陈慧等[17]将档案资源的隐性知识分为7类共107个代码进行编码。
知识聚合能深入到档案信息资源内部,在挖掘文书档案知识元的基础上进行知识组织,通过对知识元的内容、概念、背景关联,使得档案从数据、信息层次深入到知识层次,无论是在聚合强度还是聚合粒度上都有质的提升,使得原本隐藏在文书档案内部的隐性知识显性化,可向用户提供体系化的、既可横向扩散又可纵向深入的知识内容。由此,本文以文书档案为研究对象,构建知识聚合模型,为知识服务平台提供可计算的档案数据集,为政务服务精准化提质增效。
二、面向深度知识服务的文书档案预处理的必要性
文书档案根据其形成方式可分为纸质文书档案与原生的文书类电子档案,纸质文书档案可通过双层PDF扫描为电子档案,以便后续对文本进行数据化处理。原生的文书类电子档案在归档过程中为达到长期保存目的常常将文件以非结构化版式的形式进行归档存储。[18]非结构化形式的版式文件的知识聚合是指在语义层面挖掘知识的关联性并以此聚合。版式文件由于其原始形式的内在知识元之间的关联并不显性,不能直接进行知识组织,因此,在知識聚合模型构建前需对文书档案进行预处理。
(一)档案文本数据化处理
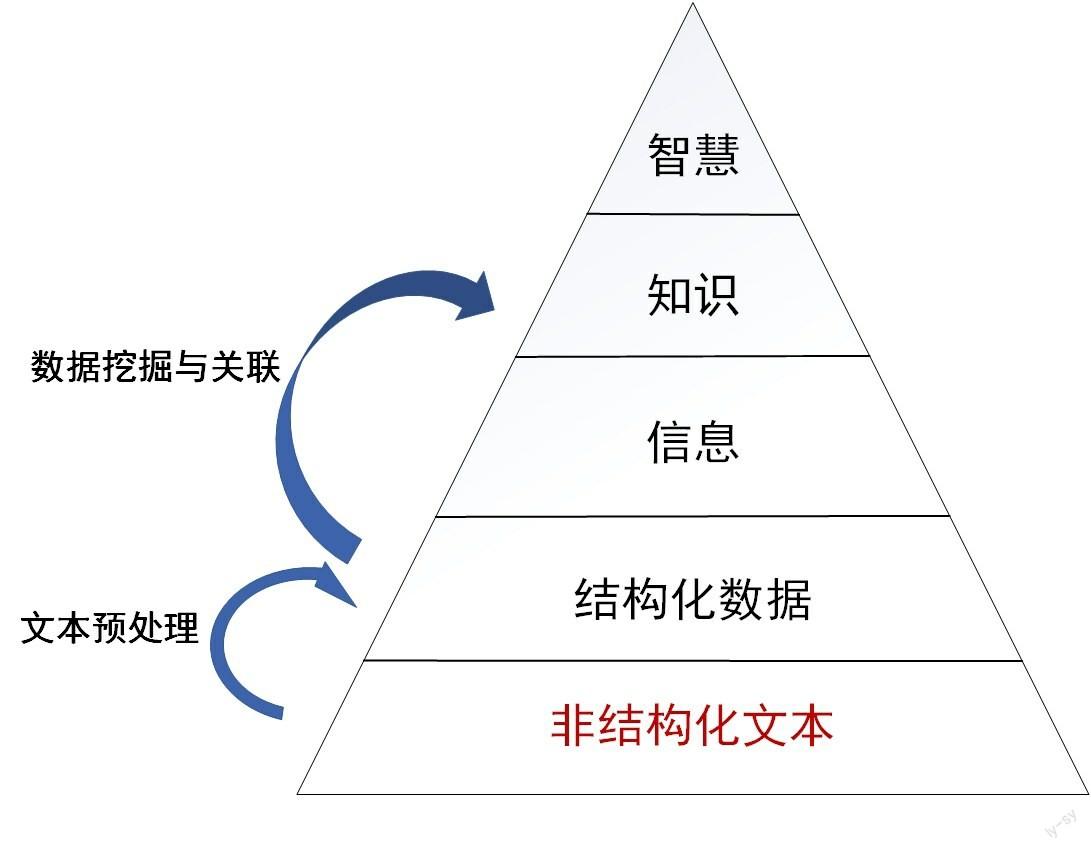
文书档案的非结构化版式形式难以直接为知识服务提供数据化的资源准备。从知识的演进来看,文本形式难以直接演进为知识。DIKW(Data to Information to Knowledge to Wisdom)层次演进体系描述了“数据—信息—知识—智慧”的四重递进关系,数据是信息的载体,信息通过加工和改造后形成了知识,知识是人类认识过程的一种结果形式,在数据时代通过数据挖掘与关联的手段可实现数据到知识的直接演进,无论知识是由哪种形式演进而成,其层次演进的起点都是数据。然而,在档案领域,归档文件为满足长期保存需求往往以非结构化版式形式固化,而非结构化文本需先通过自然语言处理、分词等技术转化为计算机可理解的符号才能进行后续的计算机处理与运算。版式文本须先转化为数据,再通过数据挖掘与关联才能形成知识服务所需要的数据储备(见图1)。
首先,从知识组织的角度看,文书档案的机器可理解性较差。文书档案规模庞大,每一份档案文本篇幅较长,无论是知识服务提供者在提供知识时还是被提供者在获取知识时都需花费大量的时间从中获取信息。其次,人类的语言内涵十分丰富,因此在分析时需要对内容有精准的语义理解,例如,“人大”一词可能存在“中国人民大学”与“人民代表大会”两种语义。最后,在对文本进行理解和得出结论时,阅读者的受教育水平、知识结构和主观认知等外部因素都会对其准确性和质量产生影响。文书档案的文本经过高度概括,缺少详细描述,因此需要具有较高的阅读理解能力才能准确理解其语义。此外,由于文书档案具有较强的领域特征,需要具备一定的领域知识才能更好地理解其含义。
因此,知识聚合需先将档案文本预处理为档案数据,在档案数据的基础上实现知识元的挖掘与关联,而经过知识聚合后的档案数据可直接成为知识服务的数据储备。
(二)档案数据清洗与质量评估
尽管目前已有41.93%的省级行政区提供了数据开放平台,但是约六成平台存在质量问题,[19]数据时代知识服务需要高质量的档案数据支撑,因此,为实现深度知识服务应对档案数据进行清洗与质量评估。
首先,档案数据需是依据统一标准数据化产生的数据。档案从非结构化文本到数据的过程需经过分词、去除停用词、文本表示等数据化过程,而这一过程中数据集构建规则的科学性、系统性和完备性对于整个档案数据化工程的运行都会产生决定性的影响,[20]若不依据统一标准进行数据化,各部门各行其是,会造成数据化质量参差不齐,且在跨机构进行数据关联整合时会产生障碍,不利于国家层面的数据整合共享。然而,这一领域目前尚无国家层面指导性政策文件出台,由此有学者建议我国档案行政机关及时启动国家层面上的《档案数据化工程技术规范》的起草工作。[21]
其次,档案数据应用之前应进行数据清洗。梅宏院士指出政府开放数据存在数据缺失、数据格式不规范不统一、未将数据转换为结构化形式、数据单元名称及含义不一致、错误数据、乱码等质量问题。[22]非结构化档案文本数据转化为结构化数据时也会存在各种数据质量问题,而这些质量参差不齐的数据将会对后续知识服务的精度产生影响。因此,档案数据在应用于知识服务前需先对数据质量进行评估,检测错误数据,并更正、补充或删除错误的数据项,用推测算法补全缺失的数据项,提升数据质量。
最后,档案数据需进行质量评估。数据质量是档案数据赖以生存的生命线,[23]将直接影响知识服务的质量,在知识聚合前有必要评估档案数据的质量。我国《信息技术数据质量评价指标》中将数据质量评估指标归结于规范性、完整性、准确性、一致性、时效性、可访问性六个维度,[24]本文中的档案数据质量评估体系基本参照此标准。
三、文书档案知识聚合模型构建
根据文书档案的特征,本文构建了文书档案知识聚合模型,该模型结构可分解为文本分解层、关联聚合层与服务应用层(见图2)。
(一)文本分解层:档案文本分解为档案知识元
20世纪70年代后期,美国情报学家弗拉基米尔·斯拉麦卡教授在华讲学时提出,知识的单位将从文献深入到其中的数据、公式、事实、结论、日期等最小的独立的“知识元”,当时他把这称为“数据元”。[25]知识元是知识最细粒度的单位,若将档案数据处理为大量的知识元,并将知识元关联,将产生知识增值。文书档案的形式以文本为主,因此文本分解层是构建文书档案知识聚合模型中最为基础的一层,在这一层结构中将文书档案文本进行分解,为知识聚合提供细粒度高质量的档案知识元。文本分解层内含有自顶向下的三个模块,分别是词法分析、清洗与消歧及句法分析。[26]
文本可以看作是词汇的集合,词法分析也是文本分解层的基础,是对档案文本语言的初步处理,其性能将直接影响档案知识服务的质量与深度。首先,在词法分析这个模块中需根据系统内预先收集存储的词典进行分词,并识别出仿词与新词;其次,分词后根据词性知识库对其进行基本词性标注;最后,通过语义角色标注识别出施事、受事、时间、地点、主题等关键实体并标记。[27]在这一模块中,词典库与词性库可根据文书档案的特征进行制作,由此档案从文本分解为档案知识元。
经过分解的档案知识元内含有部分词典库与词性库中不存在的未登录词,以及在分词过程中可能存在的歧义词,由此造成部分知识元不可用,且由于歧义的存在将影响数据集整体的质量,因此,对这一部分的知识元需先根据算法规则识别出新词、仿生词、派生詞,也就是知识元清洗与消歧,如北京大学语料库中就给出了仿词对应的ELUSLex脚本元规则,[28]对算法无法识别的知识元需通过人工处理进行识别,对错误知识元需进行清除。
经过清洗与消歧后可得到相对高质量的档案知识元,但是这些知识元之间并无联系,通过句法分析可识别档案文本内句子之间的依存关系、句法内部可能存在的主谓动宾等核心关系、句内语义依存关系等,将完整的句子根据其结构与语义建立内部档案知识元之间的关联关系,为知识聚合奠定基础。
(二)关联聚合层:档案知识元聚合关联形成档案数据集
文本分解层分解的知识元需按照一定的规则进行聚合形成档案数据集,关联聚合层的聚合规则按照语义化程度由浅到深可分为三个聚合规则。
一是档案知识元来源聚合。档案的原始记录性是区别于其他信息资源的独特性质,体现并维护了档案的本质属性,被认为是档案学中最具学科特色并具有核心地位的基础理论,[29]因此同一来源的档案具有隐性的关联关系,可依据这个关系进行知识聚合。文书档案按照来源归档保存,依据来源可进行档案知识元来源聚合,使得同一来源的文书档案内部知识元及其数量可视化,例如,对同一全宗的文书档案知识元进行来源聚合可较为直观地呈现出该全宗内知识元数量与权重,使用这一聚合规则将便于各单位进行年报统计,但是这一聚合规则仅仅是将知识元进行集合,并无基于知识元自身的语义和关系,因此聚合效果的精细化程度较低。
二是档案知识元关系聚合。经过文本分解层的档案知识元是由关系与知识元两个部分组成,通过关系关联可实现不同知识元之间的聚合。这种聚合规则是依据档案知识元自身已显性化的关系规则进行聚合,尚无根据语义挖掘更为深层次的规则。
三是档案知识元语义聚合。档案知识元语义聚合是最为深层次的、根据知识元的语义概念进行聚合的一种规则,通过语义聚合可实现对于档案文本的知识深度发现。但是在语义聚合时需注意同一概念在不同语义背景下的差异,兼顾知识元的主题及其背景。
(三)服务应用层:档案数据集应用服务
文书档案经过文本分解和关联聚合形成档案数据集,利用这些档案数据集可根据不同用户对象的知识需求提供深度知识服务,服务应用层是知识聚合模型的最顶层。根据文书档案的领域特征,其知识服务的对象主要为政府和社会公众两类群体。从服务形式分析,基于细粒度可计算的档案数据集能提供知识推荐、可视化、知识推理、知识检索等知识服务。
知识推荐服务是面向用户的主动知识服务,从用户数据的获取和整合起始,通过细粒度的算法分析,匹配数据关系,锚定用户个性化偏好,引导和满足用户的知识需求,是满足档案知识服务与用户需求双向匹配的信息过滤服务。[30]知识可视化服务是指相互关联的档案知识元形成了一个类似于知识图谱的知识网络,这个以知识网络形式呈现的档案数据集本身就是可视化的,是“一种基于图论的数据结构”[31]。知识推理服务是指知识网络之间的聚合能够将领域内外的知识单元编织成庞大的知识网络,实现高效的知识问答与推理。[32]通过知识推理可实现非同一来源知识之间的关联,发现新的知识。文书档案在归档时按照预设的来源方案对档案进行管理,其所含知识为隐性知识。通过对每份档案的知识元进行分解、挖掘与关联聚合,可形成一个小型知识网络,而每份档案形成的知识网络可通过同一个知识元进行推理。如在一份档案中挖掘出行为主体A的身份为B单位局长,在另一份档案中挖掘出行为主体A在某一时间于C地发表讲话,将这两个知识网络聚合可推理得到B单位局长在某一时间做了某事这一知识(见图3)。知识检索服务是指用户基于该知识网络进行检索能够获得具有更高精确度和更细粒度的检索结果。此外,服务应用层还可根据用户需求定制知识服务,例如某用户在学术研究时提出探寻两份相关政策法规之间关联的知识需求,为用户提供个性化知识服务。
四、结语
文书档案具备极为重要的知识价值,但文书档案在归档时为满足长期保存的需求常常以版式文件的形式存储和呈现,运用知识聚合模型对版式文书档案进行知识元分解以实现知识关联对于政务服务具有重要意义。
本文构建了一个面向知识服务的文书档案知识聚合模型,该模型分解为文本分解层、关联聚合层与服务应用层。研究表明,依据该模型可实现对文书档案尤其是文本档案知识元的提取与组合,能够为知识服务提供更为细粒度和可计算的档案数据集。
*本文系国家社科基金项目“大数据背景下档案数据管理理论构建、技术选优与实践创新研究”(项目编号:18BTQ092)的阶段性研究成果。
注释及参考文献:
[1][12]夏天,钱毅.面向知识服务的档案数据语义化重组[J].档案学研究,2021(2):36-44.
[2]祁天娇,冯惠玲.档案数据化过程中语义组织的内涵、特点与原理解析[J].图书情报工作,2021,65(9):3-15.
[3]中华人民共和国国家档案局.中办国办印发《“十四五”全国档案事业发展规划》[EB/OL].[2022-06-08].https://www.saac.gov. cn/daj/yaow/202106/899650c1b1ec4c0e9ad3c2ca7310eca4. shtml.
[4]张海涛,宋拓,孙彤,等.知识聚合研究的脉络与展望[J].情报科学,2020,38(4):163-170.
[5][7]赵雪芹.知识聚合与服务研究现状及未来研究建议[J].情报理论与实践,2015,38(2):132-135.
[6]董克,程妮,马费成.知识计量聚合及其特征研究[J].情报理论与实践,2016,39(6):47-51.
[8]牛力,袁亚月,韩小汀.对档案信息知识化利用的几点思考[J].档案学研究,2017(3):26-33.
[9]牛力,展超凡,高晨翔,等.人物事件导向的多模态档案资源知识聚合模式研究[J].档案学通讯,2021(4):36-44.
[10]陈海玉,向前,何剑锋.面向知识服务的抗战档案资源聚合与可视化展现探究[J].档案学研究,2021(2):111-118.
[11]郝琦.社交媒体环境下档案知识聚合服务研究[J].档案学通讯,2018(6):91-94.
[13]魏扣,李子林,金畅.社交媒体环境下档案知识聚合服务实现架构研究[J].档案学通讯,2018(6):61-66.
[14]陈果.面向网络社区的领域知识聚合研究[M].北京:科学技术文献出版社,2019:32.
[15]周毅.变革时期档案学研究边界的适度拓展[J].档案学通讯,2007(4):21-24.
[16]张玉芳.知识管理背景下如何做好档案管理创新[C]//中国档案学会.档案事业发展与青年档案工作者的责任:2010年全国青年档案工作者研讨会论文集.北京:中国档案出版社,2010:460-466.
[17]陈慧,王晓晓,南梦洁,等.数字档案资源整合与服务过程中的隐性知识分类——以赋能思维为视角[J].图书与情报, 2019(6):118-124.
[18]中华人民共和国国家档案局.版式电子文件长期保存格式需求[EB/OL].[2022- 11- 18].https://www.saac.gov. cn/daj/hybz/201806/8602fb7e80bf4efea665a6bd97c984f9/ files/a5bc88a072fb49aa8637df70efd2c96d.pdf.
[19][22]梅宏,杜小勇,吳志刚,等.数据治理之论[M].北京:中国人民大学出版社,2020:268-269.
[20][21]赵生辉,胡莹.档案数据基因系统:概念、机理与实践[J].档案学研究,2021(1):40-48.
[23]金波,周枫,杨鹏.档案数据研究进展与研究题域[J].情报科学,2021,39(11):187-193.
[24]国家市场监督管理总局.信息技术数据质量评价指标:GB/ T36344—2018[S].北京:中国国家标准化管理委员会,2018:6.
[25]徐如镜.开发知识资源发展知识产业服务知识经济[J].现代图书情报技术,2002(S1):4-6.
[26]高凯.文本大数据情感分析[M].北京:清华大学出版社, 2019:7.
[27]CHE WX, LI ZH, LIU T. LTP: a Chinese lan? guage technologyplatform[C]// Proceedings of the 23rd In? ternational Conference on Computational Linguistics: Dem? onstrations.Stroudsburg:Association for Computational Lin? guistics,2010:13-16.
[28]姜维.文本分析与文本挖掘[M].北京:科学出版社,2018:9.
[29]张斌,尹鑫.中国特色档案学基础理论体系的历史发展与当代构建[J].中国图书馆学报,2021,47(6):36-49.
[30]蔡之玲,陆阳.基于DKN算法的档案知识推荐系统模型构建[J].档案学通讯,2021(2):63-71.
[31][32]张斌,高晨翔,牛力.对象、结构与价值:档案知识工程的基础问题探究[J].档案学通讯,2021(3):18-26.
作者单位:1.上海大学文化遗产与信息管理学院
2.中国人民大学电子文件管理研究中心
猜你喜欢
办公室业务(2016年11期)2017-01-09 18:26:06
办公室业务(2016年12期)2017-01-09 16:17:01
青年时代(2016年21期)2017-01-04 18:12:55
环球人文地理·评论版(2016年5期)2017-01-03 04:36:05
现代情报(2016年11期)2016-12-21 23:34:35
现代情报(2016年11期)2016-12-21 23:32:05
现代情报(2016年10期)2016-12-15 11:41:13
考试周刊(2016年91期)2016-12-08 22:46:13
办公室业务(2016年9期)2016-11-23 10:41:35
商情(2016年39期)2016-11-21 09:55:26
