
基于广义神经网络的网络攻击检测与分类方法
2023-06-10 04:44:36张明明李贤慧许梦晗顾颖程张见豪程环宇王永利
信息安全研究 2023年6期
张明明 刘 凯 李贤慧 许梦晗 顾颖程 张见豪 程环宇 王永利
1(国网江苏省电力有限公司信息通信分公司 南京 210024)
2(江苏瑞中数据股份有限公司 南京 210012)
3(国网电力科学研究院有限公司 南京 211106)
4(南京理工大学计算机科学与工程学院 南京 210094)
异常行为检测是入侵检测系统(intrusion detection system, IDS)的重要内容,负责监控、分析和调查用户在整个网络环境中的行为.仅通过用户名和密码检查和获取用户权限是不够的,目前网络攻击和新出现的安全威胁正通过渗透网络、影响服务器以及破坏企业和金融账户等手段而逐步增加.因此,需要开发有效的入侵检测模型全面地观察网络活动,阻止恶意行为.
在过去10年中,各种研究文献提出了不同类型的入侵检测系统.
在对行为进行定性时,可以将用户的一般行为分解为子行为,并搜集分析子行为的证据,最终确定一个行为是恶意行为还是正常行为,利用恶意行为检测方法可以在大量的正常行为中快速地区分出恶意行为.
Miao等人[1]提出了一种双层行为表征技术,可用于提取基于API调用序列的判别行为模式.行为特征基于2层提取,低层分析敏感资源,高层分析活动.此外,他们提出了一种名为OC-SVM-Neg(one class-support vector machine-negative)的高级支持向量机,以有效利用可用的良性软件样本,然后利用共享最近邻相似度(spiking neural network, SNN)方法计算所有实例间的差异.与本文提出的方法相比,OC-SVM-Neg算法在遇到新出现的恶意行为类型,如泛型和shellcode时就会无能为力.
Zhao等人[2]提出了一种基于软件控制流构造特征的未知行为识别方法,该方法以长操作码序列作为软件特征,从不同的序列中捕获操作码序列,并使用向量空间模型分析属性.随后,应用数据挖掘算法从软件特征中寻找分类规则,利用规则区分恶意样本和正常样本.该方法的主要缺点是针对恶意软件的分类规则较混乱.
何红艳等人[3]使用K-means聚类算法在真实流量数据集UNSW-NB15中提取典型数据,随后在该数据集上分别使用9种不同策略的入侵检测模型进行网络入侵检测实验,分类精度高于其他机器学习算法,然而该方法在深度学习特征工程方面的性能有待提升.
为了改进入侵检测性能,本文提出了一种基于观察用户行为的恶意检测方法,设计出一种基于广义回归神经网络(GRNN)的恶意行为检测模型.系统将用户行为转换为可理解的格式,通过在NSL-KDD数据集上的恶意检测实验结果表明,该系统能够对NSL-KDD数据集中的4种攻击类型进行识别和分类.本文提出的方法可以应用于入侵检测系统的安全监控.
1 GRNN-based IDS模型
由于广义回归神经网络(generalized regression neural networks, GRNN)可以通过由相似神经元组成的完全并行架构执行训练和预测,因此GRNN被称为通用回归模型,随着训练样本向量的数量接近无穷大,GRNN接近真实回归水平[4].因此本文引入广义回归神经网络,提出一种基于广义回归神经网络的恶意行为检测模型GRNN-based IDS.
GRNN-based IDS模型框架如图1所示,由数据预处理、恶意行为检测识别2个阶段组成.其中:数据预处理由网络特征生成、特征约简、特征归一化、特征向量配置组成;恶意行为检测识别由GRNN最优化学习、GRNN训练、GRNN平滑参数(σ)估计、恶意行为检测识别模块组成.GRNN-based IDS模型接收网络包形成的特征向量,输出网络行为的类别.
1.1 数据预处理模块
数据预处理和特征提取模块负责处理原始网络数据的特征,获取观察结果并生成特征向量,特征向量是机器学习技术的合适输入.
1) 网络特征生成.在异常行为检测和识别系统中,从原始网络流量中创建相关且有价值的特征是最重要的问题之一.为了从网络流量中收集这些特征,可以使用入口路由器、网关或交换机在目标节点收集网络流,以收集相关数据包.可以使用各种收集工具提取网络流量特征,如Netmate,BRO-IDS,Argus,Netflow,Tcptrace.
2) 特征约简.网络特征约简在特征提取过程中起着重要作用,它能够去除重复和冗余的特征.在收集网络特征时,有一些输入特征相互关联,它们携带相似的信息.在IDS数据集中,2个有高度相关特征的特征列会使整个系统的性能下降.因此可以消除其中1个特征列,而不会明显减少信息量.
3) 特征归一化.这一步需要对特征值进行归一化,并将其缩放到1个合适的区间.特征归一化的主要优点是在不丢失统计特性的情况下消除原始网络实例的偏差.在应用的数据集中,由于真实的特征分布是未知的,因此使用统计特征归一化技术,采用归一化的特征向量训练机器学习系统.
统计归一化:一种特征调用技术,对每个特征进行归一化,去除其均值并将该特征的方差缩放为1.统计归一化的定义为
(1)
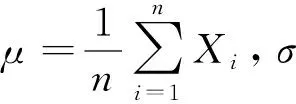
(2)
统计归一化并没有将特征值转化为[0,1],而是将99.9%的特征值转换为[-3,3].
4) 特征向量配置.在机器学习中,特征向量以一种易于分析的方式表示对象的数值或符号特征(以下简称为特征).为了给所提出的神经网络系统提供数据,需要对原始收集的数据进行人工分类并进行特征描述.为此,将收集到的数据分为正常行为和异常行为,所有的正常行为数据被归为正常行为一类,而异常行为数据则被归为不同类型的攻击等异常行为一类.
从数据集NSL-KDD中收集了42个不同分类角度的特征,如流量特征、基本特征、内容特征、时间特征和附加特征等,这些特征暗含于不同类型的定性和定量数据中,包括38个整数特征和4个字符串特征.由于对人工神经网络(ANN)有用的信息形式是1个包含数值数据的向量,因此必须将其他类型的数据转换为1个整数,以便机器进行处理.
在所提取的特征向量中,协议类型的实例有各种类型的标称数据,例如arp,esp,icmp,igmp,ospf,rtp,tcp,udp,udt,很容易为它们分配1个等价的数值.因此规定arp=1,esp=2,icmp=3,igmp=4,ospf=5,rtp=6,tcp=7,udp=8,udt=9,相似地,可以将其他类型的数据转换为数值.
用户特征向量包括42个特征,对于所有正常/异常的用户都收集了相同数量的特征,为系统训练提供足够的样本.
1.2 GRNN的最优学习模块
本模型中的GRNN利用单带宽核心函数带宽调整实现最优学习.许多径向基函数均等地放置在每个训练向量位置,然后与任意输出值相关联.调整单个径向基函数a的带宽,使得MSE值最低,表示最优学习[4].与Nadaraya和Watson的方程相似的GRNN方程的标准版本如式(3)所示:
(3)
其中xi表示第i类训练输入向量,yi表示与xi相关的输出,σ表示神经网络训练期间选择的单个学习或平滑参数,L表示训练对(xi→yi)的数量.
如果将yi视为个体实值尺度,则式(3)表示Specht提出的GRNN.在这种情况下,将训练向量(xi,yi)成对输入网络结构中.xi是输入空间中的单个训练向量,yi是所期望的比例的输出.在GRNN体系结构中,fi(x)表示任意径向基函数.式(4)利用式(3)定义的高斯径向基函数fi(x)表示:
(4)
径向基函数通常根据最小计算来选择[4].GRNN可以简单发展为多维输出,并将其转化为一种完全通用的映射回归方法.GRNN采用多维输出向量,通过正确定义输出向量,其可用于时间序列分析或模式分类.例如,在K分类问题中,K类模式可以由下一个K指令定义(式(5)),或由向量输出测试定义.如果网格输出的网格单元产生了最高尺度,经过训练,输入向量x将被归为第k类向量:
yi=[yi1,yi2,yi3,…,yik,…,yiK]T,
(5)
其中:对于k类向量xi,yik=1.0;对于其余的向量元素,yik=0.0.当使用1.0和0.0进行输出训练时,GRNN与其他概率神经网络紧密匹配进行模式分类.
假设给定1组测试样本向量((xq,yqk)|q=1,2,…,NUM,k=1,2,…,K),使其独立于训练样本向量((xi,yik)|i=1,2,…,L,k=1,2,…,K).对于输出节点多于1个的网络,其总均方误差(MSE)的估计由式(6)定义:
(6)
输出误差方差有3种类型,用MSE表示.Eint等于插值误差(函数映射误差),Equant等于yik量化产生的误差,Enoise等于输出处残留的随机噪声误差.输出总误差Etotal是这些误差的总和,即Etotal=Eint+Equant+Enoise.如果值yik具有无限精度,则插值误差是训练向量数量L的函数.因此如果L足够大,则Eint可以被忽略.一旦yi被量化,为了实际目的,量化误差将趋向于占主导地位.
根据本文提出的基于GRNN技术的数学特性,利用该方法检测正常模式下的恶意实例对所检测异常的类型进行分类.为此,从NSL-KDD数据集中提取训练数据集和独立测试数据集,通过选择单一平滑参数σ,即共同球面或径向基函数核带宽,对式(4)进行训练和优化.在许多问题中,σ与输入模式的误差或噪声分布密切相关.然而,对于非线性问题,根据噪声分布计算σ过于复杂.由于σ和MSE之间的关系通常是平稳的,并且有一个明显的最小MSE截面,因此利用递归抛物线曲线拟合的收敛优化算法也可以很快求出σ.
1.3 GRNN训练模块
使用GRNN算法检测恶意行为,需要使用训练数据集对网络进行训练,GRNN经过训练后,已具备对测试数据集中的每个输入样本进行检测和进一步分类的能力.为了训练GRNN网络,输入的权值是训练数据集中的特征向量.在GRNN网络中,训练样本的数量等于隐藏神经元的数量,输出权重为2类恶意行为检测的结果和4类恶意行为识别的结果.然而,当训练样本数量非常大时,训练过程往往效率不高且误报率较高.在这种情况下,降维技术可以减少训练数据集中的特征数量.
在算法1中,引入一种基于误差的算法对GRNN进行增强,这是一种有效的降维技术.在训练GRNN之前,根据预测误差来判断是否需要将某个输入特征纳入训练阶段,当不包括该输入特征的预测误差超过一定的水平,那么GRNN就需要纳入该输入特征进行训练.
算法1.GRNN训练算法.
输入:归一化训练数据集Strain(用于训练GRNN)、测试数据集Stest(用于测试).
① 利用Strain中的所有特征对GRNN网络的输入层进行训练;
② fori≤ifinaldo
③ 用式(4)计算输入i的GRNN(yi)的输出;
④ 利用式(6)计算MSE误差;
⑤ ifMSE≥阈值 then
⑥ 利用输入特征i训练GRNN;
⑦ else 不用输入特征i训练GRNN并忽略它;
⑧ endif
⑨ endfor
1.4 GRNN平滑参数(σ)估计模块
优化σ是GRNN算法的一个重要问题,而σ是GRNN结构中唯一的自由参数,因此优化σ可以提高GRNN算法的性能和输出精度.由于σ没有最优解析解,可以采用数值方法来解决这个问题.为此,首先从Strain中随机选择部分数据集并剔除,然后使用简化的数据集Sreduced训练GRNN网络,并计算输出.随后,计算GRNN输出和Sreduced之间的MSE误差.
对不同的σ值重复这个过程,并根据最小的MSE误差之和确定最佳的平滑参数(σ).算法2解释了整个计算过程:
算法2.计算平滑参数σ算法.
输入:初始化参数(σ)和矢量[σlow,σavg,σup].
① fori≤ifinaldo
② forj≤jfinaldo
③ 随机选择一部分训练数据集从Strain中剔除;
④ 使用新数据集训练GRNN网络
(Sreduced);
⑤ 使用式(4)计算Sreduced的输出(yj);
⑥ 利用式(6)计算yj与Sreduced之间的
MSEj误差;
⑦ endfor
⑧ 计算MSE误差的总和;
⑨ 根据最小均方误差之和计算参数σ;
⑩ endfor
1.5 恶意行为检测模块
当恶意检测系统利用NSL-KDD数据集检测出输入样本与系统训练信息之间存在相似性时,访问用户将被安全管理捕获.恶意检测模型将异常行为作为一个二元问题进行判断.表1示出了NSL-KDD数据集中的攻击类型和相关子类别攻击:

表1 NSL-KDD数据集的属性
1.6 恶意行为识别模块
在异常行为检测之后,异常类型就成为一个新问题,需要确定以特征向量的形式自动记录的恶意行为在多大程度上可以被正确归类为属于各种类型的攻击.这个问题涉及到对不同异常行为的识别和分类,关注的是攻击类型.
在本节中,将使用GRNN技术解释如何根据攻击在NSL-KDD数据集中的分布情况,将异常行为分类为不同类型的攻击.识别部分是一个多类分类问题,输入的特征向量被归类为NSL-KDD数据集中的4种攻击之一.识别和分类原理在前面阐述的训练阶段获得,本文提出的GRNN网络在训练期间使用训练数据集中的实例进行学习.最终,系统能够对异常行为的潜在特征有较强的认识.图2示出如何将恶意行为识别系统的功能进行合并,以及如何对异常行为或不同类型的攻击进行分类.算法3解释了如何将NSL-KDD数据集中不同类型的恶意实例分类为相应的攻击.包括DoS攻击、R2L攻击、U2R攻击和探针攻击等主要攻击类型.
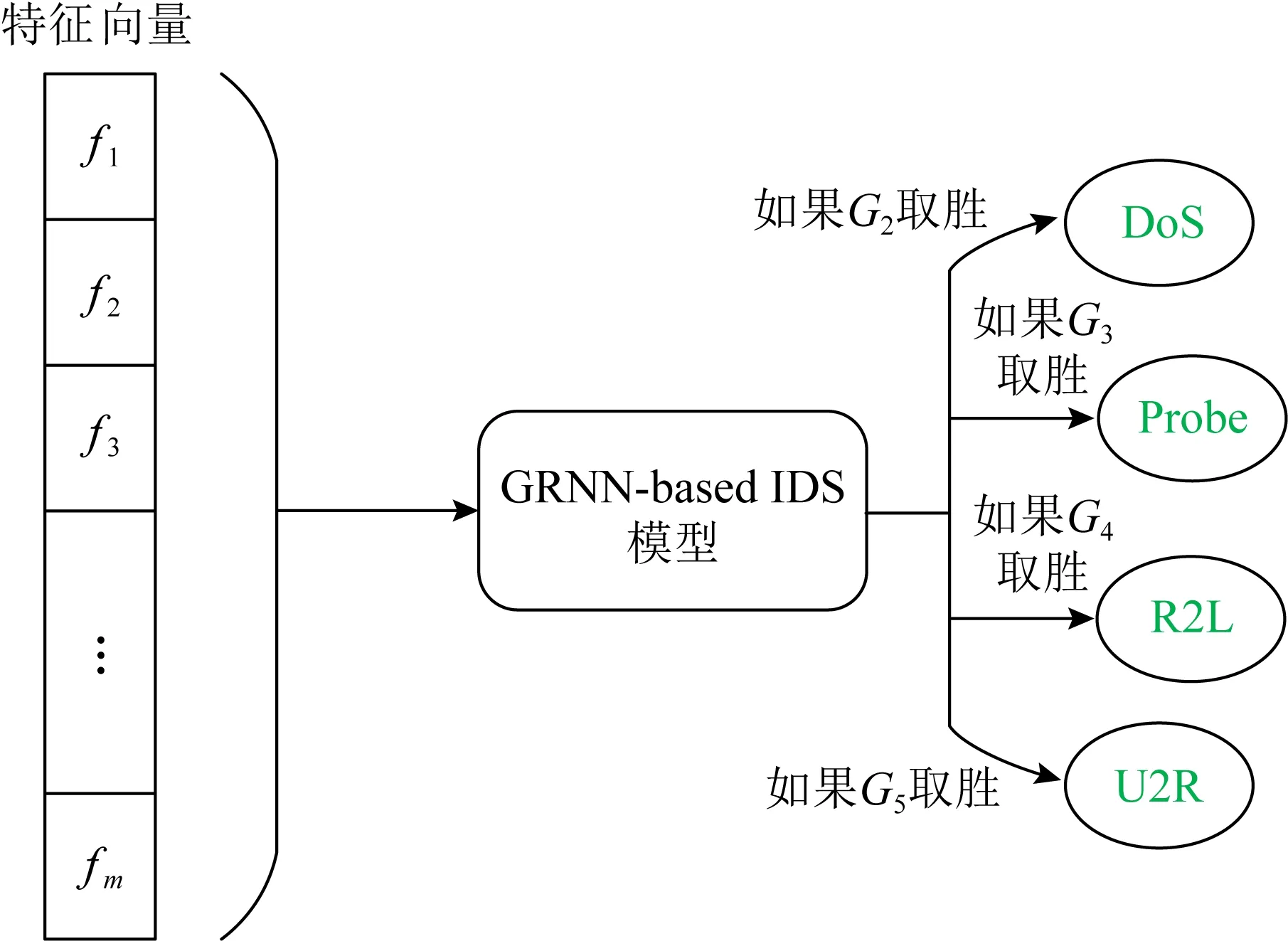
图2 基于GRNN-based IDSd的NSL-KDD数据集恶意行为识别说明
算法3.利用NSK-KDD数据集进行恶意行为检测和识别的GRNN算法.
输入:从NSK-KDD数据集中提取的标准化训练数据集Strain和测试数据集Stest;
输出:识别行为的类型.
① 基于算法1,使用Strain中的所有数据训练GRNN网络;
② 加载Stest中的所有特征向量;
③ 根据GRNN算法的输出,编写获胜的神经元;
④ ifG1取胜 then
⑤ 被访问用户的行为很正常;
⑥ else if 从G2到G5的任意神经元取胜 then
⑦ 被访问的用户行为是恶意的;
⑧ ifG2取胜 then
⑨ 被访问用户的行为是DoS;
⑩ else ifG3取胜 then
2 实验结果与评价
为了评估本文提出的技术在检测和识别用户恶意行为方面的有效性和效率,在NSL-KDD数据集上实现了本文提出的方法.NSL-KDD数据集是目前最完备的网络入侵检测数据集,包含目前网络中的4种恶意数据和正常数据,广泛用于评估网络异常检测系统.
采用NSL-KDD数据集评估本文方法的性能,该基准数据集由麻省理工学院林肯实验室开发,在美国军方的空军局域网环境中创建了1个包含大量正常和恶意样本的模拟.NSL-KDD数据集有42种特征向量,包括连接持续时长、连接协议、映射到服务的DST端口等[5].
2.1 评价指标
基于机器学习技术方法的性能通过计算混淆矩阵评估决策引擎的性能和有效性.
真阳性TP、真阴性TN、假阴性FN和假阳性FP是常用的评估元素,常见评估指标如假阳性率FPR、真阳性率TPR、精度、召回率和F-度量.在异常检测场景中,使用这些术语生成以下恶意行为评估指标:
1) 混淆矩阵.比较预测的类标签与实际的类标签.对角线单元格(TNs和TPs)代表正确的预测类,而FNs和FPs在左右2侧.混淆矩阵的大小取决于预定义的类的数量.IDS的混淆矩阵可以是二元检测矩阵,对正常的恶意实例进行分类,或通过多类分类识别网络攻击的类型.
2) 真阳性率TPR.也称为召回率,是在测试数据集中正确检测到的恶意观测值占恶意观测值总数的比例.计算方法如式(7)所示:
(7)
3) 真阴性率TNR.也称为特异性,是在测试数据集中检测到的恶意观察错误占正常观测值的比例.计算方法如式(8)所示:
(8)
4) 假阳性率FPR.是被错误检测为正常的恶意观察占测试数据集中正常观察总数的比例.计算方法如式(9)所示:
(9)
5) 假阴性率FNR.是被错误检测为恶意的正常观测值与测试数据集中正常观测值总数的比例.计算方法如式(10)所示:
(10)
6) 精度.是正确检测到的恶意观测的数据占测试数据集中检测到的观测总数的比例.计算方法如式(11)所示:
(11)
7)F-度量.混合了准确率和召回率的属性,是这2个指标的调和平均值.计算方法如式(12)所示:
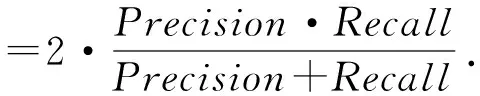
(12)
当问题包含不平衡的类或目标值时,F-度量是异常检测的有效度量.
采用异常检测系统和IDS技术,可以评估这些检测恶意观察方法的精确性.实现100%DR和0%FPR的理想检测结果表明,所有恶意活动都能够被正确识别.然而,由于流量包的复杂性、当代网络系统的大规模和高速度,这种理想的检测系统在实时网络流量环境中是很难实现的.当设计的系统以高FPR和FNR为代价时,保持灵敏度就变得更重要;当系统的准确性值[6]很低时,保持特异性(TNR)就更重要.
2.2 评价目标
关于评估标准和本文方法在识别正常和恶意用户行为方面的性能,本文从以下2个方面进行考察和研究:
1) RQ1(检测).GRNN技术能在多大程度上检测到NSL-KDD数据集中用户的恶意行为.
2) RQ2(识别和分类).以特征向量的形式自动记录的恶意行为,可以在多大程度上正确分类为属于NSL-KDD数据集中的各种类型的攻击.
RQ1解决了检测恶意行为与正常行为的问题.安全级别的第1个重点是当前观察的实体是否为正常用户.在此级别上,管理员可以检测到异常或观察部分异常用户,并对其采取行动.
RQ2是指对NSL-KDD数据集中不同异常行为的识别和分类.因此在这个阶段,一旦恶意行为被识别出来,将根据表1中描述的攻击类型对异常的类型进行分类.
2.3 评价结果
在NSL-KDD数据集上进行实验,以真阳性率TPR、假阳性率FPR、精度、召回率和F-度量为评价指标,评估GRNN技术在NSL-KDD数据集上的性能和有效性.
关于RQ1的评价,需要考虑正常行为和恶意行为这2种类型.因此,为了训练GRNN模型,使用了1个包含4000个样本的数据集,其中包括2000个正常样本和2000个恶意样本.为了使用本文所提出的GRNN技术来评估获得的模型,通过随机选择1000个恶意模式和1000个正常模式,生成1个包含2000个模式的测试数据集.表2所示的混淆矩阵表明分类结果是有效的.

表2 在NSL-KDD数据集中使用GRNN的RQ1的混淆矩阵
使用NSL-KDD数据集的基于GRNN技术的RQ1的性能测量如表3所示:

表3 在NSL-KDD数据集中使用GRNN的RQ1的性能度量 %
为了评估RQ2,排除了正常的样本,重点关注已被识别为网络攻击的恶意模式.实验的目标是评估文本所提出的GRNN技术在给定特征向量的情况下对4种不同类型的攻击进行分类的能力.
本文从NSL-KDD数据集中提取2000个恶意模式作为评估GRNN技术的训练集.随后,来自NSL-KDD数据集的400个恶意行为被视为测试集.
表4所示为在NSL-KDD数据集中使用GRNN获得的所有攻击的混淆矩阵,表5所示为在NSL-KDD数据集中使用GRNN技术的相应性能度量.从混淆矩阵可以清楚地看出,本文方法能够在NSL-KDD 数据集中以较高性能识别不同类型的攻击.
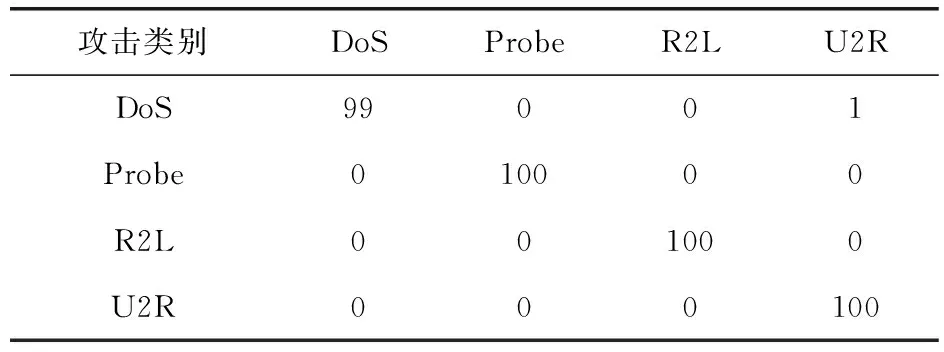
表4 在NSL-KDD数据集中使用GRNN的RQ2的混淆矩阵 %
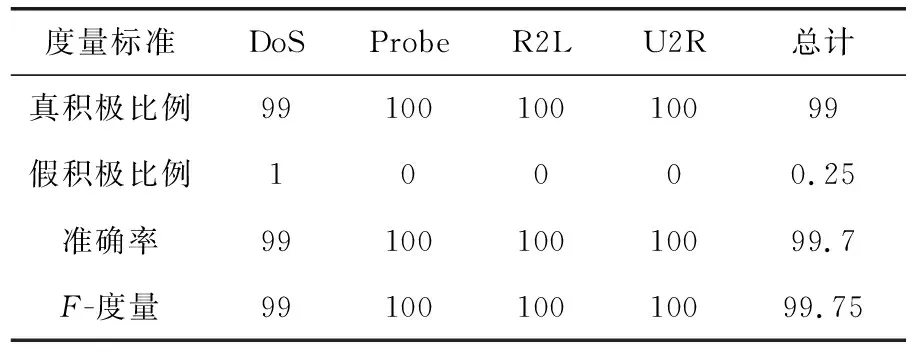
表5 在NSL-KDD数据集中使用GRNN的RQ2的性能度量 %
2.4 与其他技术的比较分析
在本节中,将本文技术与最先进的网络恶意行为检测技术进行了性能比较.比较研究包括多个方面:本文技术是只针对特定攻击还是针对多种攻击行为;本文技术仅具有检测恶意实例的能力还是具有对异常类型进行分类的能力;本文技术在检出率DR、误报率FAR、精度和F-度量等方面的性能.
1) 技术检测特定攻击的能力比较.
在近10年的研究中,许多技术只能检测某些特定的攻击,而不能检测其他类型的恶意行为.如:文献[7-8]提出的技术只适用于检测DoS攻击,而不具备检测其他攻击的能力;文献[9]的方法只能检测勒索软件;文献[10]提出的方法只能检测僵尸网络.当检测技术仅使用于一种特定类型的异常行为时对于安全系统来说是一个很大的弱点.
本文提出的GRNN技术能够检测到多种恶意行为.此外,关于检测阶段的其他性能指标,表6示出了本文方法在多重恶意行为检测方面的优越性.
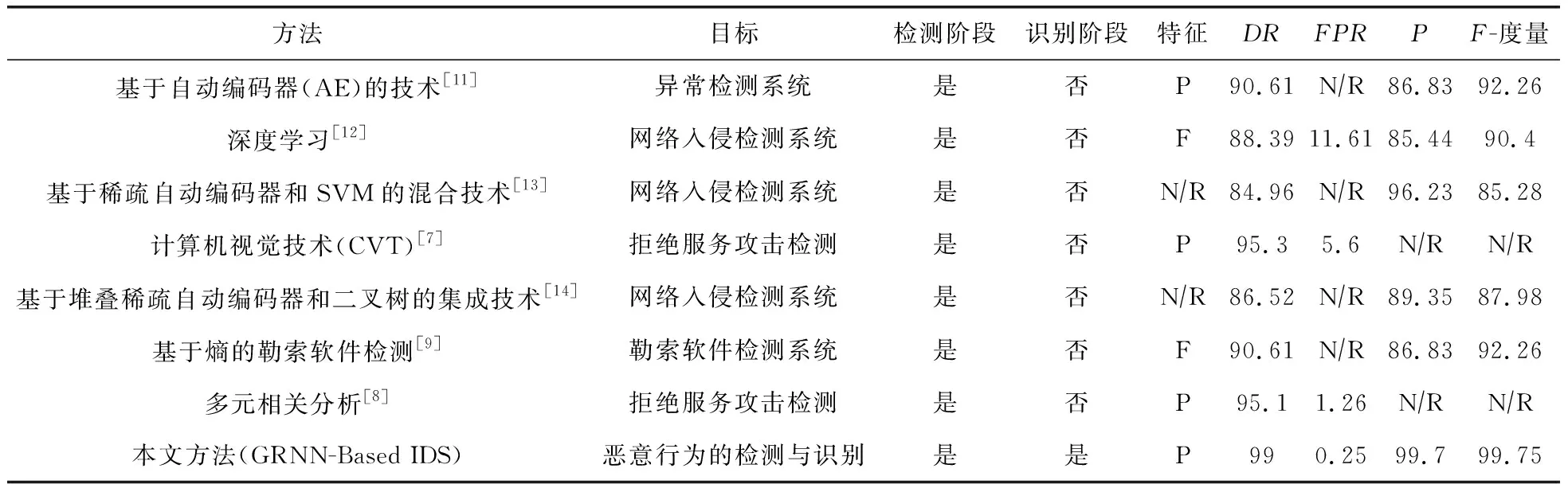
表6 现有检测技术在各方面的比较结果 %
2) 现有检测技术在恶意分类方面的能力比较.
本节比较了恶意行为检测技术的能力,包括这些技术是否只检测恶意行为,还是能够识别恶意行为的类型.
在本文方法中,GRNN技术能够识别出NSL-KDD数据集中的攻击行为,并对异常类型进行分类.上述技术依赖于通过估计正常和异常实例之间的相关性进而获得接近度,而间谍攻击等几种恶意行为会伪装成正常行为,它们会干扰正常样本的检测并降低检测引擎的准确性.FSVM方法基于规则学习的概念,从正常和恶意观察中学习.在这种方法中,系统总是需要大量的观察来准确理解正常和异常模式之间的差异,而这在实时网络流量中是难以实现的.通过对这些方法的评估结果表明,它们计算出的DoS和Probe攻击检测率高于使用本文方法实现的检测率,但对于其他类型的攻击则不然.
表6示出了现有检测技术与应用的评价指标,通过对召回率、精度和F-度量等方面进行比较,本文方法相比其他方法能够更有效地区分正常行为和恶意行为.
3 结 论
本文提出了一种新的基于广义回归神经网络GRNN的入侵检测方法,可以有效检测恶意实例和正常实例.相比其他异常检测和识别方法,通过在召回率、精度和F-度量等方面进行比较,本文方法能够更有效地区分正常行为和恶意行为.
广义回归神经网络GRNN是一个具有高度并行结构的传递学习算法.使用这种技术能够识别用户的行为并将其分类为正常活动或各类攻击.实验结果表明,即使在多维测量空间中使用稀疏数据,该算法也能提供从一个观测值到另一个观测值的平滑过渡.神经网络策略遵循贝叶斯参数估计技术,本质上是一种特殊的神经网络结构,适用于存在噪声的数据实例.GRNN的网络中心是由训练数据向量决定的,而不是最适合优化的人工中心,这赋予了网络的稳定性,并确保了它不会被过度训练,这是与其他方法的最大区别.下一步工作拟改进GRNN-based IDS针对大数据集预测速度慢的问题.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
新高考·高一数学(2022年3期)2022-04-28 07:02:46
保定学院学报(2022年2期)2022-04-07 02:26:50
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
许昌学院学报(2018年4期)2018-05-02 12:27:37
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
中华建设(2017年1期)2017-06-07 02:56:14
