
一种改进的TextRank多文档文摘自动抽取模型
2023-05-29 10:19曾曼玲
软件导刊 2023年5期
王 楠,曾曼玲
(1.吉林财经大学 管理科学与信息工程学院;2.吉林财经大学 经济信息管理研究所,吉林 长春 130117)
0 引言
当用户通过搜索引擎查询某个主题信息时,会有数以千计的文章涌入,导致人们无法从不同媒体的同质文章中快速甄别与提炼有价值的信息。人的精力及对信息的处理能力有限,因此,如何迅速而准确地获取领域知识信息变得尤为重要。多文档自动文摘抽取是利用自然语言处理技术压缩和提炼多篇同一个主题信息的方法,这种方法不仅可以帮助人们快速理解文本中心内容,还能使人们摆脱繁杂和无用的信息,有效降低用户的信息负载,对提高信息资源利用率有着重要的现实意义。
目前,对自动文摘的研究以英文语料库为主,较少涉及中文文本,因此本文针对中文文本特点,基于TextRank算法构建了一个多文档文摘自动抽取模型。为解决传统图模型文本语义上的不足,在对语句间的相似性进行度量时,打破以往TextRank 基于句子间共现词频率的方法,引入基于平滑逆频率(Smooth Inverse Frequency,SIF)的句向量表示,计算句向量间的余弦相似度,在提高TextRank 算法边值精确性的同时,使模型性能得到进一步提升。
1 相关研究
1.1 自动文摘提取
目前,自动文摘技术可大致分为抽取式文摘和生成式文摘两大类。抽取式文摘模型主要包括以下4 种方法:①基于统计特征的文摘提取方法[1-2]。该类方法根据文本的统计信息特征对句子进行抽取,简单易于实现,但是对于词句的研究大多停留在字面,缺乏对实际语义的深层考虑;②基于图模型的文摘提取方法。这类方法将文本表示成一个图,在全局上确定文本单元的重要度,对词句进行排序。例如,Mihalcea 等[3]提出的TextRank 算法将文本中的语句视为图中的顶点,用语句间的相似度来表示无向有权边,不断迭代节点值直到收敛,最后选择分数最高的N 个节点作为文摘句;③基于主题模型的文摘提取方法。该方法通过潜在语义挖掘词句隐藏信息,例如张明慧等[4]在传统特征组合的框架下引入隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)主题特征,对句子联合打分,最后按照句子的分值抽取文摘句;④基于神经网络的文摘提取方法。例如,Liu[5]提出了一个简单的BERT(Bidirectional Encoder Representation from Transformers)变 体——BERT-SUM 模型,通过修改BERT 模型的输入序列和嵌入,微调摘要层实现文摘句提取。
抽取式文摘按照原文单元进行提取,在语法上有一定保障,但也面临着不够连贯、灵活性差等问题。生成式文摘可以在句子中产生新的词汇,使句子更加灵活。近年来随着深度学习的发展,Seq2Seq 模型在生成式文摘中得到广泛应用。例如,Rush 等[6]提出一种将神经语言模型与编码器相结合的生成式文摘模型,其编码中加入了Attention机制,解码时用集束搜索来寻找概率最大的句子;王玮[7]对深度学习模型进行研究,提出一种复合文摘模型C-R,该模型将卷积神经网络(Convolutional Neural Network,CNN)与循环神经网络(Recurrent Neural Network,RNN)编码器结合生成中间向量,RNN 解码器提取向量重要信息,以实现生成式文摘的抽取。
抽取式和生成式自动文摘技术的交叉使用已成为一种新的研究趋势。例如,张乐等[8]对中文专利文本提出了一种STNLTP 文摘模型,其借鉴集成策略,运用3 种抽取方法对专利说明书抽取关键句,然后将去重的最优关键句送入基于Transformer 的指针生成网络得到生成文摘;郭继峰等[9]通过LDA 主题模型融合生成对抗网络和指针生成网络,对生成式文摘模型进行改进,提升了句子的可读性和准确性。
1.2 多文档文摘提取
多文档自动文摘与单文档自动文摘具有相同的特点,均需对文本特征进行分析,但二者之间还存在一些差异。与从单篇文档中提取关键信息不同,多文档文摘需从同一主题的若干文件中提取信息,因此多文档文摘的难点在于文本之间的冗余过滤和信息之间的组织排序。自动文摘在日常生活中有着广泛应用,如单文档文摘在问答、会议纪要、语音播报等方面有着重要表现,而多文档文摘可以看作单文档文摘技术的延伸,其不仅能面向新闻查询,还可以跟踪热点专题,生成事件的线索报告。
从目前研究成果来看,多文档自动文摘技术还不够成熟,但仍有许多学者加入到这一研究领域。例如,张波飞[10]在TextRank 算法计算图节点的权重时加入基于LDA主题模型的主题词概率分布,与单一算法相比准确率明显提高;龚永罡等[11]在传统统计特征模型的基础上加入两个长短期记忆网络(Long Short-Term Memory,LSTM)计算文本相似度,并采用去除停用词的方法改进模型以提升效率;唐晓波等[12]针对复杂长文本与多文档文摘信息的冗余和不全面特点,提出混合机器学习模型,使用聚类方法划分句群减低冗余度,句子重组过程采用基于改进的PageRank 算法对句子重要性打分;曾昭霖等[13]在研究面向查询的多文档文摘过程中提出了一种基于层级BiGRU+Attention 的模型,通过融合基于神经网络的句子打分模型和文本表面特征对句子的重要性进行计算,最后利用最大边缘相关(Maximal Marginal Relevance,MMR)算法选择文摘句。
在多文档文摘中,句子相似度的计算是其关键技术之一,也是最重要和最基本的步骤[14],其在文摘句抽取时具有重要作用。例如,仇丽青等[15]利用高频词的作用,计算测试集合所包含词汇的频率,根据词频对句子赋予权重。采用词频统计确定句子之间的相似度方法,较少考虑句子中语义信息,句子间的联系较弱,缺乏对句子的真正理解,有一定的局限性。为克服文本特征表达上的不足,吴世鑫等[16]将句子的词汇、相对位置、长度和基于SIF 句嵌入的句间相似度4个特征引入到自动文摘模型中,构建特征加权函数进行文摘句抽取,提高了抽取的质量;罗飞雄[17]围绕经典的TextRank 算法进行自动文摘分析时,发现传统算法只是简单的利用文本间的共现词次数来度量句子相似度,诸多语义方面的重要信息被忽略。为了改进传统的图算法,事先训练词向量,然后对每个句子的词向量求和平均,以求出相应的句子向量,并计算句子向量的相似度,此方法提高了词向量语义上的准确度,从而提高句子的表达。但使用词向量直接累加求平均值的方法不能很好地表示句子,其缺陷是把所有词在传达句子含义中的重要性同等对待;黄波等[18]将Word2Vec 融入TextRank 算法,构建高维词库集合R,将文本信息映射到高维词库中,计算句子之间的相似度,此方法改善了传统稀疏矩阵的维数灾难和传统图模型共同词频率对句子权重的影响,但削弱了共现词的加权作用。
可以看出,目前在与自动文摘相关的句子相似度研究中大多是对句子表层特征统计分析,并且传统图模型只侧重词语之间的关联,忽视了语义方面的问题,缺少对文本特征的深入研究。基于SIF 的方法在提取文本数据特征、进行跨模态相似性度量中展现出优越性[19],因此本文在多文档文摘研究中引入SIF 句嵌入方法,提出一种改进的基于TextRank 算法的多文档文摘抽取模型,模型可以获得更加精准的文本特征和更高的句子间相似度,进而提取更高质量的多文档文摘。
2 模型构建
本文构建的多文档文摘模型主要涉及文本预处理、文本向量化和文摘句抽取3 个方面。模型首先对多篇相同主题的新闻文本合并进行文本预处理;然后运用Word2Vec 算法在中文维基百科语料库中训练词向量,在此基础上引入SIF 算法将句子向量化,将语句特征转化成向量之间的联系;接着利用余弦相似度算法衡量向量之间的相似程度,以表示TextRank 关联图的边值;再次,通过TextRank 算法抽取候选文摘句;最后,为了确保句子的全面性和多样化,采用MMR 算法作冗余处理,提高最终文摘的质量。模型流程如图1所示。
2.1 文本预处理
文摘句是由文档中选取多个能够概括文本主题的句子而得到的,因此根据中文的文本特点,以分隔符列表[“。”,“!”,“;”,“?”]作为句子结尾的标记,依次识别文中的分隔符,对文章语句进行分句形成句群,并且对文档进行分词和去停用词操作。
2.2 文本向量化
2.2.1 基于Word2Vec的词向量训练
Word2Vec 是由Mikolov 等[20]提出的一种通过语境学习语义信息的神经网络模型,其通过对海量语料库的训练获得低维向量映射词汇之间的语义关系,结构如图2 所示。该模型只包含输入层、映射层和输出层,依据输入和输出的不同,模型框架分为连续词袋模型(Continuous Bagof-Words,CBOW)和Skip-gram 模型两种。CBOW 根据词wt的上下文wt-2、wt-1、wt+1、wt+2来预测当前词wt;而Skip-gram则是在已知词wt的情况下对词wt的上下文wt-2、wt-1、wt+1、wt+2进行预测。本文利用Word2vec 在中文维基百科语料库上进行训练得到预训练的词向量,便于后续句向量的生成。
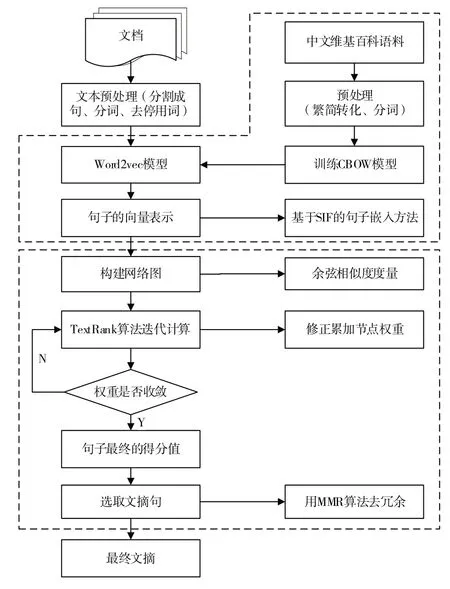
Fig.1 Automatic extraction model process of multi-document summarization图1 多文档文摘自动抽取模型流程
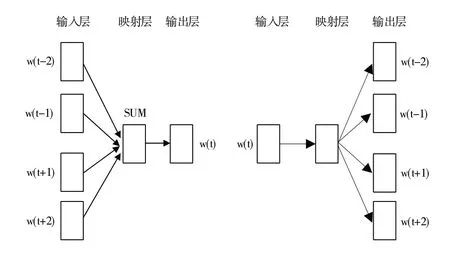
Fig.2 Word2Vec model structure图2 Word2Vec模型结构
2.2.2 基于SIF的句向量表示方法
SIF 是由Arora 等[21]提出的一种完全无监督的句向量生成方法,该算法首先对句子的词向量加权平均,然后找出第一奇异向量,减去由词向量组合而成的句向量矩阵的第一主向量上的投影,即去除共有部分中的词向量,保留每个词向量所具有的特性。每个词的权重表示为:
式中,a为超参数,p(w)表示词w对应的词频。
句子表示方法如式(2)所示,其中∣s∣为句中词的数量,vw为词w的词向量。对于文本中所有句子组成的矩阵X,采用主成分分析法求出第一主成分上平均向量的投影,并采用式(3)对句向量进行修正,其中u为第一奇异向量。
本文使用上述训练的Word2Vec 模型获得句子中对应的词向量,然后根据SIF 句向量生成方法,应用单句词嵌入将包含词向量的句子列表转换为一组句子向量。
2.3 文摘句抽取
2.3.1 TextRank算法
TextRank 算法是一种适用于文本的图排序方法[22],该算法受到知名PageRank 的启迪,用于无监督地抽取关键词与文摘句。TextRank 算法与PageRank 有相似之处,其以文本中的词句作为图的顶点,将词句之间的边值作为权值,从而评估词句的重要程度。
TextRank 算法常用带边权的图G=(V,E)描述,其中V为图的顶点集合,E为边的集合,E为V×V的一个子集,wij为图中两点Vi和Vj的边权值,对于指定点Vi,In(Vi)表示指向该点的集合,Out(Vi)为点Vi指向的集合,点Vi的计算公式为:
式中,d为阻尼系数,表示图中任意两点的指向概率,其取值在0~1 之间,通常取0.85。在对图模型的每个顶点求分数时,首先要给各点赋予任意初值,然后进行迭代直至收敛,即当图中任何一个点的误差率低于某个极限值时达到收敛,便可得到每个节点的最终得分,极限值通常取0.000 1。
传统TextRank 只是简单地利用文本之间的共现词次数来表示句子相似度。为提升模型性能,在传统边的权值上进行改进,本文引入SIF 句嵌入方法对句子向量化,将句子作为图的顶点,以各语句间的相似关系作为边,构建TextRank 模型。采用余弦相似度对句子边值进行计算,由式(5)所示。通过迭代式(4)计算句子在图中的最终权值,最后按得分值大小进行排序。
2.3.2 候选句群的冗余处理
在不去除冗余的情况下,得分较高的几个句子之间的相似度也较高。MMR 算法采用关联度与新颖度的线性结合进行度量,本文将这一原理运用到文摘句的抽取中,使所选择的文摘句之间的相似性最小化,从而达到文摘的相关性和多样化。该计算方法表示为:
式中,i表示候选文摘句;score(i)表示候选文摘句得分;j表示选定的文摘句;sim(i,j)表示候选语句i和所选择文摘句j之间的相似性;λ×score(i)表示候选语句与主题内容的关联程度,在负号右侧的因式是指候选语句和所有被选中的文摘句的相似度最大值,公式中的第一个负号表示两个句子的相似度尽可能小。score(i)为TextRank 算法之后的句子得分,在第一轮中将得分最高的句子作为被选择的文摘句,其余句子按照式(6)计算对应的值,i从2 开始,相似度sim(i,j)仍然使用余弦相似度进行计算。在抽取时,每一轮添加一个句子,直至完成所需文摘句数量。
3 实验分析
3.1 数据集
目前,中文多文档自动文摘缺乏大量实验语料用于研究,而微博的信息量非常庞大,是用户获取信息资讯的重要媒介,因此本文从微博中爬取了相关新闻报道,构建了中文多文档自动文摘的实验语料。该语料共包含30 个国内外的热点事件,主题涵盖时事、军事、社会、政治、卫生及突发新闻方面,每个事件下有5~10 篇来自各大主流媒体对同一新闻的不同报道。以数据集中“巴黎圣母院遭遇火灾”事件为例,分别从修复工程、安全隐患、后期处理、事故原因方面列举其中4 家媒体对该主题事件进行的不同角度的新闻报道,如表1所示。
3.2 模型参数设置
在词向量训练中,Word2vec 的相关参数如表2 所示,其中size 为输出的词向量维度;sg 为模型框架,0 即对应CBOW 算法;min_count 表示对字典作截断,即一个单词在文本中的频率低于阈值,那么这个单词就会被删除;windows 表示训练窗口。在去除文摘句冗余MMR 算法中,阈值λ设置为0.8。
3.3 评价指标与结果分析
ROUGE 是由Chin-Yew Lin[23]提出的一种评估自动文摘方法,是当前衡量自动文摘生成中最普遍的一种。其将计算机自动生成的文摘与人工编写的参考文摘进行比对,并根据它们之间的重叠基本单元(n 元语法、词序列和词对)数量进行统计。ROUGE 的计算为:
式中,N表示元词的长度;分子表示抽取的文摘与参考文摘共现的n-gram数量,分母表示标准参考文摘中共包含的n-gram数量。本文以ROUGE-1、ROUGE-2、ROUGE-L 作为评价多文档文摘模型的指标,其中ROUGE-L 是基于最长公共子串的统计。
本文实验结果按原文档句子15%的比例对文摘句进行抽取。为确保评价的准确性,使用多个对照组对实验数据进行文摘句提取,比较结果如表3 所示,各模型在示例主题中所获取的最终文摘如图3 所示。其中TextRank 模型采用textrank4zh 库对目标文档抽取;Word2vec+TextRank+MMR 模型采用实验样本语料训练词向量,通过对词向量求平均值获得句子的向量表示,然后利用余弦相似度计算句间的相似性,使用TextRank 算法对文摘句抽取,并融合MMR 算法去除冗余。

Table 1 Example data set表1 数据集示例

Table 2 Word2vec model parameter setting表2 Word2vec模型参数设置
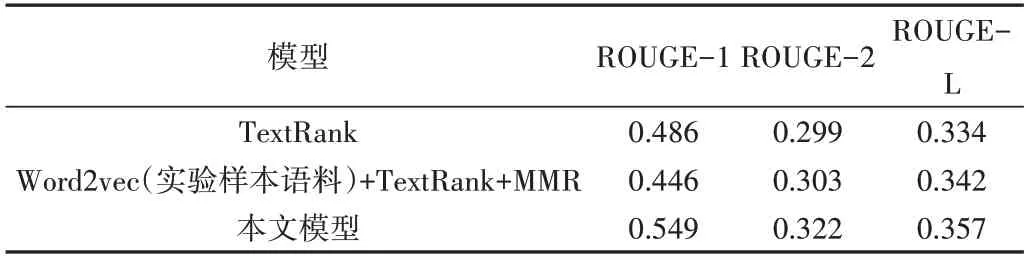
Table 3 Comparison of experimental results表 3 实验结果比较
由表3 可以看出,与传统TextRank 模型和基于实验样本语料的TextRank 融合模型相比,本文模型在3 个评价指标上均有所提升,这是由于本文模型是在大规模语料库上训练词向量,同时引入SIF 句向量方法更好地表示向量空间中的信息,可以进一步深入挖掘文本的语义特征。而单一的TextRank 算法与小规模实验样本语料的Word2Vec 词向量对文本特征提取能力非常有限。此外,本文模型考虑到多文档文摘在语义重复上的问题,加入了MMR 算法,在保证全面性的同时降低冗余度,提高了最终文摘句的质量。
由图3 可以看出,使用传统TextRank 模型虽然可以很好地提炼事件主旨内容,但是模型本身侧重将得分高的句子作为文摘输出,使得最终文摘句子间具有相似性,存在语义重复问题;基于实验样本语料的TextRank 融合模型有效降低了语句的冗余,然而由于语料库的局限性对句中词训练造成一定的影响,最终文摘达不到好的效果;本文模型所得到的文摘既含有图3(a)中铅污染和火灾损毁信息又包括图3(b)中健康安全隐患和修复信息,文摘内容更加完整多样。

Fig.3 Example of summarization results from different models图3 不同模型所得示例文摘结果
4 结语
针对文本语义上的不足,本文通过结合SIF 句嵌入方法对句子语义特征进行向量化表示,提出一种基于TextRank 改进的多文档文摘自动抽取模型,并将其用于中文多文档文摘的自动生成。通过与对照组的比较,验证了所提模型的有效性。然而,该模型在抽取过程中仍然存在一些缺陷,需要进一步完善:①Word2Vec 模型对特征的提取能力有限,无法解决多义词的问题,未来会尝试采用更多算法进行提取效果对比,如BERT;②由于抽取式自动文摘是从原文中提取文章主题的中心句,在追求准确率的同时忽略了文摘句之间的衔接、连贯性。后续工作将重点考虑文摘句排序部分,以及最终文摘语句的连贯性和可阅读性;③本文研究的文摘以抽取式为基础,今后可将其与生成式文摘相结合,从而提高文摘质量,拓展文摘模型。
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
环境影响评价(2020年2期)2020-12-02
宝藏(2017年2期)2017-03-20
信息安全研究(2016年4期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
