
融合半监督学习与RoBERTa多层表征的中文医学命名实体识别
2023-05-29 10:19高晓苑
软件导刊 2023年5期
张 帅,高晓苑,杨 涛,刘 杰
(1.南京中医药大学 人工智能与信息技术学院,江苏 南京 210023;2.中国科学院大学南京学院,江苏 南京 211135)
0 引言
命名实体识别(Named Entity Recognition,NER)是指从文本中检测并识别命名实体,并划分为预定义的语义类型的过程[1]。NER 是一项重要且基础的任务,是多种自然语言处理下游任务的前置[2]。医疗信息化水平不断提升,随之产生了海量的医疗数据,然而这些数据很多是非结构化的文本数据,无法直接进行分析和利用,如何通过NER技术进行医疗文本结构化已成为一个重要的研究课题[3]。
目前,深度学习因其特有的特征表示优势[4],在NER任务应用中已经成为主流,特别是双向长短期记忆网络后接条件随机场[5](Bidirectional Long Short-Term Memory with Conditional Random Field,BiLSTM-CRF)和BERT[6](Bidirectional Encoder Representation from Transformers),识别效果明显优于传统识别方法。基于深度学习的NER 需要大量的已标注数据,而在医疗领域,数据标注过程需要许多领域内的专家,耗时而且昂贵,导致高质量的标注数据往往难以获取。如何在小样本情境下取得优异的识别效果,已经成为当前研究的热点。
近年来,研究人员提出了伪标签(Pseudo Label,PL)方法,这是一种简单而有效的半监督学习(Semi-Supervised Learning,SSL)方法,其在对未加标注的数据分配标签后,与标注数据共同参与训练。该方法最初被应用于图像领域,并取得了一些成果[7]。一些学者将伪标签应用于医学NER 中[8],但在使用过程中忽略了伪标签数据中存在的错误标注,直接将这些数据追加到训练集中将影响模型的识别性能。
BERT 模型在中文命名实体识别任务中已经取得了优异的成绩,但仍然存在一些问题。首先,中文BERT 模型在训练过程中是以字为粒度划分的,因此只能获得字级别的特征,RoBERTa-wwm-ext 模型[9]在训练过程中使用全词掩码,因而能够获得词级别的表征;其次,预训练语言模型无法在单一的Transformer 层学习到全面的信息,因此使用多层表征融合(Multi-layer Representation Fusion,MLRF)方法,根据任务将不同层的表征融合后输出,能够获得更好的特征表示。
本文提出一种基于半监督学习与RoBERTa 多层表征融合的医学命名实体识别方法,以减少现有的深度NER 模型对高质量标注数据集的依赖。该方法在RoBERTawwm-ext-BiLSTM-CRF 多层表征融合模型基础上,利用伪标签法扩充数据集,并设计了一种基于权重分配(Weight Allocation,WA)的机制来减弱伪标签数据中存在的噪声。最后在CCKS 2021 医疗命名实体识别数据集和CBLUE CMeEE 数据集上,评估了该方法的实用性和可行性。本文在GitHub 网站上开源了相关代码,网址为:https://github.com/charfeature/NER。
1 相关工作
命名实体识别任务的主要方法可分为两种:传统的NER 方法和基于深度学习的NER 方法[10]。其中,基于深度学习的NER 方法由于其在捕获输入语句特征上的优势,已成为当前的研究热点,Panchendrarajan 等[11]使用BiLSTM-CRF 进行实体识别,相比传统NER 方法效果更佳。基于深度学习的模型需要大规模的标注数据参与训练,但在特定领域的NER 任务中,数据标注过程需要相关专家参与,耗时耗力。因此,学者们尝试使用半监督学习,利用较为容易获得的未标注数据来改进模型。Liu 等[12]在金融实体识别任务中构建一种基于BERT 和Bootstrapping 的半监督模型,有效改善了领域实体识别任务中标注数据集匮乏的问题。近年来,有学者提出伪标签法,这是一种简单、有效的半监督学习方法。Li 等[8]将伪标签方法应用于医学命名实体识别任务中,其选取概率最大的标注作为伪标签,然后加入到训练集中与标注数据一同参与训练。然而,由于伪标签数据中存在错误标注,可能会影响后续模型的性能。因此,本文在伪标签框架基础上,设计一种基于权重分配的噪音减弱方法,以减少伪标签数据中错误标注对模型识别效果的影响。
BERT 模型[13]是一种在大规模无标注数据上进行无监督学习得到的预训练语言表征模型,目前在众多的NER 任务上都取得了优异的成绩。其优越性在于对于不同任务,只需要作出微调即可将其作为特征提取器。Li 等[14]构建BERT-BiLSTM-CRF 模型用于医学NER 任务,通过BERT模型结合外部特征来提高模型识别效果。然而,Google 所发布的中文BERT 模型中,用字作为粒度划分中文,所以经过BERT仅能获得字级别的特征表示。RoBERTa-wwm-ext模型在BERT 模型基础上使用全词掩码技术,将输入文本进行分词后,对同属一词的全部汉字进行掩码,以此学习词级别的语义表示[9],相较于BERT更适用于中文医学实体识别任务。同时,相关研究发现,预训练语言模型无法在一个Transformer 层全面地学习到文本中的语言学信息,每一层对应的信息各有侧重[15-16]。相较于只选择最后一层的输出,针对不同任务将特定层的输出融合后作为最终表征,往往能取得更好的效果[17]。因此,本文选择RoBERTa-wwmext 作为预训练语言模型,并且使用多层表征融合方法,以全面利用RoBERTa-wwm-ext所包含的语言学信息。
2 本文方法
2.1 模型框架
将NER 视为序列标注任务,给定文本序列x=[x1,...,xi,...,xn]。其中,xi表示序列中第i个字符,n是序列长度。将序列x作为输入,其对应的标签序列是y=[y1,...,yi,...,yn],yi表示序列中第i个字符的标签。根据任务特点,本文在预训练模型RoBERTa-wwm-ext 后接BiLSTM-CRF 模块作为基础框架。
本文所用模型框架如图1所示。
使用RoBERTa-wwm-ext 作为预训练语言模型,输入的文本序列x通过预训练模型层,获得相应的向量表示序列e,如式(1)所示:
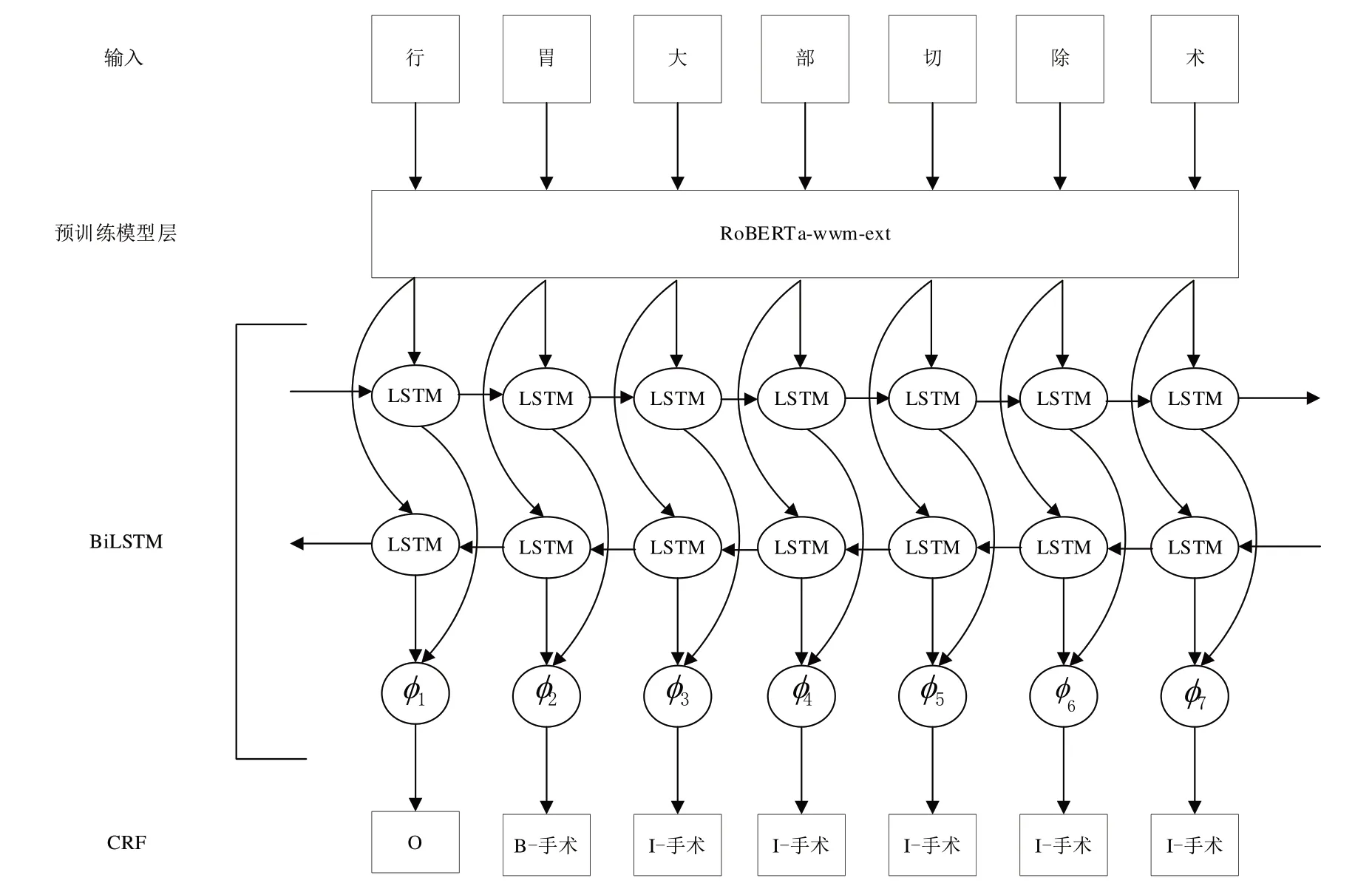
Fig.1 Model framework图1 模型框架
其中,ei是字符xi对应的向量表示。同时,本文使用多层表征融合方法,在RoBERTa-wwm-ext 中选取若干层参与表征融合,并为这些层生成的向量表示赋予一个动态可学习的权重α,如式(2)所示:
其中,hi是融合后字符xi对应的向量表示,ei,j是第j层Transformer 生成的字符xi对应的向量表示,αj是第j层输出的权重值,m是预训练模型中参与融合的层数。
BiLSTM[18]可以充分利用上下文信息,更适用于文本数据,在实体识别领域内取得了很好的效果。本文使用BiLSTM 作为上下文编码器,将向量表示输入到BiLSTM,如式(3)所示:
其中,Φ是序列x对应的BiLSTM 输出,h是融合层的输出。
CRF 是一种概率图模型,可以有效减少不符合语法的标注出现的可能性。本文在BiLSTM 模型后接CRF 作为标签解码器,其概率定义如式(4)所示:
2.2 伪标签方法
本文设计的伪标签框架分为3 个阶段。第一阶段使用标注数据作为训练集,训练得到基准NER 模型;第二阶段利用基准NER 模型预测未标注数据,得到带有伪标签的文本;第三阶段将伪标签数据加入到训练集中,训练得到最终的NER 模型。伪标签框架如图2所示。
虽然伪标签方法能够提高模型的识别效果,但错误的伪标签会为模型引入噪声,如果不加以处理,将会误导模型的学习。为了减少伪标签方法中的噪声,本文设计了一种基于权重分配的噪音减弱方法。最终NER 模型的总体损失函数L如式(5)所示:
其中,k是标注数据的文本序列数,k'是伪标签数据的文本序列数,pi是标注数据中文本序列i对应的CRF 概率,是伪标签数据中文本序列j对应的CRF 概率,β是固定的伪标签权重系数。
3 实验与结果分析
3.1 数据集
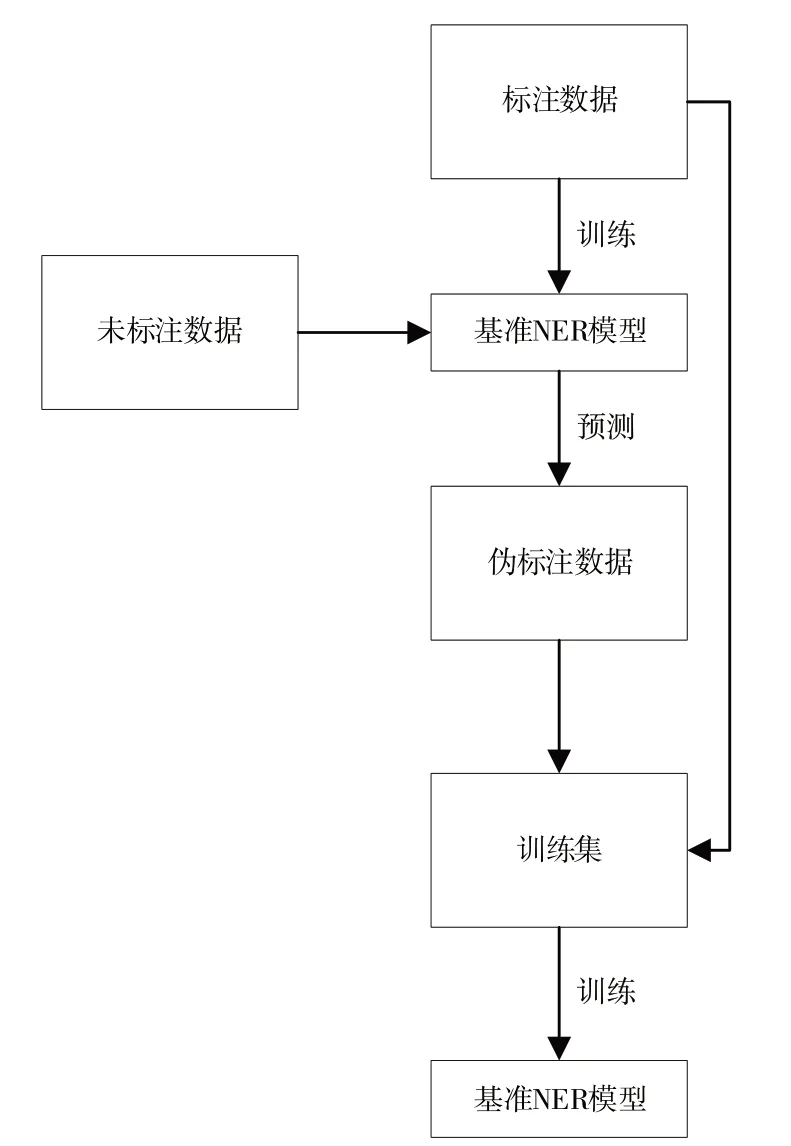
Fig.2 Pseudo label framework图2 伪标签框架
本文采用CCKS 2021 医疗命名实体识别数据集和CBLUE CMeEE 数据集进行实验。CCKS 2021 医疗命名实体识别数据集来源于真实的临床电子病历数据,单个病人的单个就诊记录为一个条目,提供了1 500 条标注数据和1 000 条未标注数据,预定义的实体类型包括疾病和诊断、手术、药物、影像检查、解剖部位、实验室检验共6 类。本文将标注数据随机划分为训练集、验证集和测试集,划分比例为6:2:2。CBLUE CMeEE 数据集来源于医学教科书和专家指南,提供了20 000 条训练数据和3 000 条测试数据,预定义的实体类型包括疾病、临床表现、医疗程序、医疗设备、药物、医学检验项目、身体、科室、微生物类共9类,本文将训练数据按照3:2 的比例随机划分为标注数据和未标注数据,对测试结果采用CBLUE CMeEE 提供的线上评测网站(https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414)进行评价,其中训练集、验证集和测试集比例为6:2:2。
3.2 数据预处理
本文将实体识别表示为序列标注任务,根据数据集的标签,使用BIO 标注法为每一个字符进行标记。例如“因胃癌行胃大部切除术”的标注如图3所示。
预训练语言模型对于输入文本序列的长度有一定限制,同时过长的输入序列也会影响BiLSTM 的性能,而如果直接截取文本,则会损害输入信息的完整性。因此,本文首先根据标点符号对输入文本进行分割,然后利用动态规划将分割后的文本按顺序进行组合,使得文本在满足约束条件的情况下,冗余度最小,而且交叉最为均匀。
3.3 实验设置
在实验中采用Colab pro Tesla P100(16G),由于硬件限制,预训练语言模型使用base版本的RoBERTa。
由于使用的数据集数据量少,实验过程中过拟合现象较为突出,所以本文设计了早停机制:设置一个耐心阈值,当验证集的损失函数值或F1 值若干轮次没有优化,而且持续轮次大于阈值,则训练停止,同时设置最小训练轮数,防止训练不充分。为了能全面利用预训练语言模型中包含的信息,选择所有的Transformer 层进行融合。模型中使用的参数如表1所示。

Table 1 Model parameters表1 模型参数
3.4 评价指标
本文在实验过程中采用准确率P、召回率R和F1 值作为评测指标来评估实验结果。计算公式如式(6)-式(8)所示:
其中,TP是所有正样本被正确识别的数量,FP是负样本被识别为正样本的数量,FN是正样本被识别为负样本的数量。
3.5 实验结果及分析
为了验证模型不同模块的有效性,本文设计了模型消融实验,实验结果如表2所示。
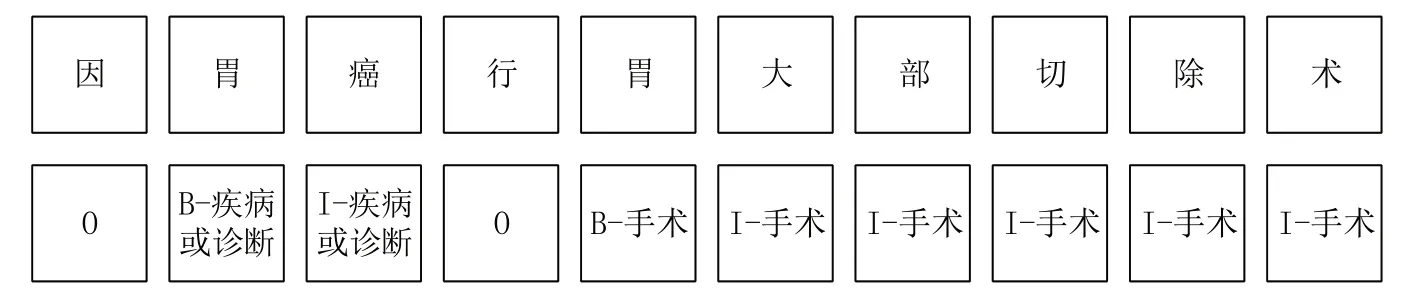
Fig.3 Example of tagging图3 标注举例
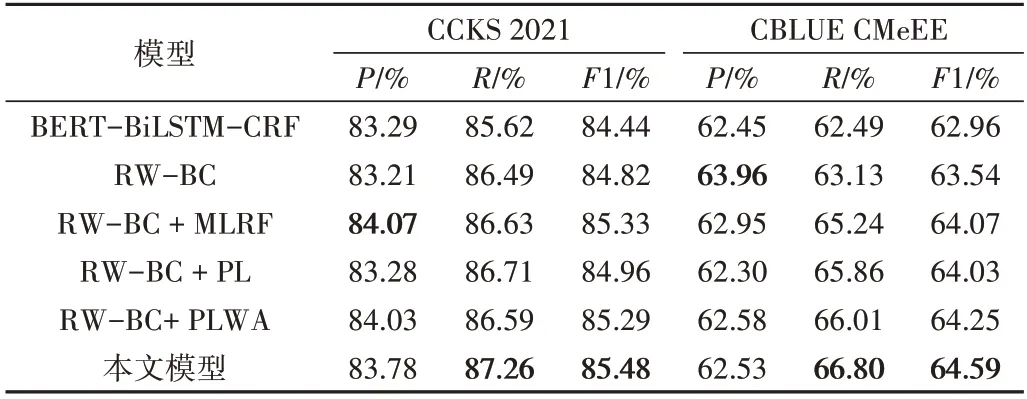
Table 2 Result of ablations experiment表2 消融实验结果
(1)BERT-BiLSTM-CRF。这是NER 领域的经典模型,在许多任务上都取得了优异的识别效果。
(2)RoBERTa-wwm-ext-BiLSTM-CRF(RW-BC)。在模型(1)基础上使用RoBERTa-wwm-ext 作为预训练语言模型,RoBERTa-wwm-ext 是一种按照RoBERTa 训练方式训练出的BERT 模型,相较于BERT 扩展了训练数据,并使用了全词掩码[9]。
(3)RoBERTa-wwm-ext-BiLSTM-CRF+Multi-layer Representation Fusion(RW-BC+MLRF)。在模型(2)基础上使用多层表征融合方法,可以充分利用不同Transformer层的输出。
(4)RoBERTa-wwm-ext -BiLSTM-CRF+Pseudo Label(RW-BC+PL)。在模型(2)的基础上使用伪标签方法扩展了训练集。
(5)RoBERTa-wwm-ext-BiLSTM-CRF+Pseudo Label with Weight Allocation(RW-BC+PLWA)。在模型(4)的基础上加入了基于权重分配的噪音减弱机制。
从表2 可以看出,本文模型与其他模型相比,识别效果更加优异,相较于BERT-BiLSTM-CRF 模型,在CKKS 2021 数据集上F1 值提升了1.14%,在CBLUE CMeEE 数据集上F1 值提升了1.63%,验证了使用半监督学习和Ro-BERTa 多层表征融合方法的实体识别模型的有效性。
第1 组实验:RoBERTa-wwm-ext 模型的有效性分析。将BERT-BiLSTM-CRF 模型和RoBERTa-wwm-ext-BiLSTM-CRF 模型进行对比,可以看出RoBERTa-wwm-ext 预训练语言模型优于BERT,这是因为RoBERTa-wwm-ext 使用了全词掩码技术,能够学习到词级别的语言学信息,同时将训练语料在中文维基百科数据基础上作进一步扩展。实验结果证明,RoBERTa-wwm-ext 模型更适用于中文医疗实体识别任务。
第2 组实验:多层表征融合的有效性分析。从表2 可以看出,加入了多层表征融合的RW-BC+MLRF 模型的F1 值高于未使用多层表征融合的RW-BC 模型,这是因为在BERT 及其改进模型中,每一层Transformer 所学习到的语言学信息各不相同,RW-BC 模型仅使用最后一层Transformer 作为表征输出,没有利用模型所学习到的低层特征和中层特征,而RW-BC+MLRF 模型通过多层表征融合模块,将各层Transformer 层的输出动态融合后作为最终输出,可以全面地利用RoBERTa-wwm-ext 每一层的特征。实验结果充分验证了多层表征融合机制能够有效提升模型的识别效果。
第3 组实验:伪标签方法的有效性分析。从表2 可以看出,使用了伪标签方法的RW-BC+PL 模型,结果优于未使用伪标签方法的RW-BC 模型,表明通过伪标签法引入的未标注数据对模型性能具有一定的提升效果。为了验证基于权重分配的噪声减弱机制的有效性,将添加了噪声减弱模块的RW-BC+PLWA 模型与RW-BC+PL 模型进行比较。从比较结果可以看出,噪声减弱模块能够提升模型的识别效果,这是因为该模块可以使模型在学习到伪标签数据中蕴含信息的同时,更加专注于标注数据,以此缓解噪声干扰。
为了进一步验证本文模型的有效性,与现有的其他NER 方法进行比较,实验结果如表3所示。
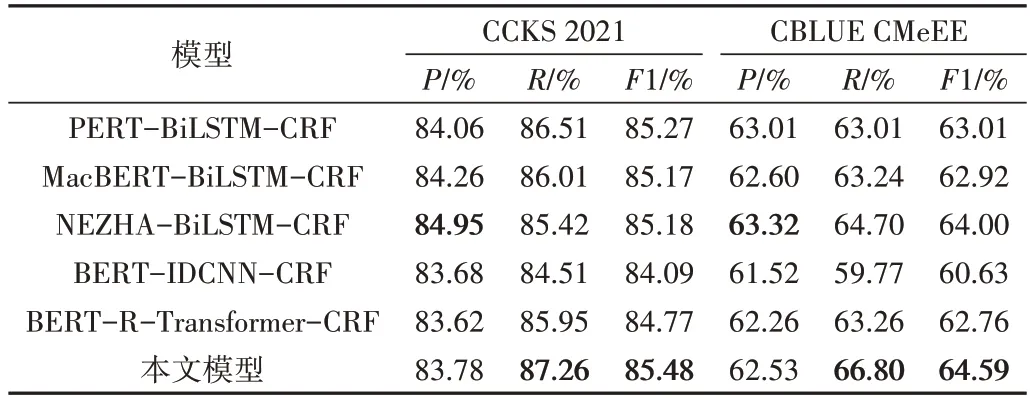
Table 3 Performance comparison between the proposed model and other NER methods表3 本文模型与其他NER方法性能比较
(1)PERT-BiLSTM-CRF。使用PERT 作为预训练语言模型层。PERT 是一种基于乱序语言模型的预训练模型,能够在不引入掩码标记的情况下学习文本中的语义信息,相较于BERT,在部分自然语言处理任务上取得了更好的性能。
(2)MacBERT-BiLSTM-CRF。使用MacBERT 作为预训练语言模型。MacBERT 是BERT 的改进版本,在预训练过程中使用相似词取代掩码标记,同时也引入全词掩码和N-gram 掩码技术,在许多自然语言处理任务上都取得了优异的成绩。
(3)NEZHA-BiLSTM-CRF。使用NEZHA 作为预训练语言模型,NEZHA 与BERT 模型相比使用了函数相对位置编码、全词掩码、混合精度训练和LAMB 优化器,在一些具有代表性的中文自然语言处理任务中取得了良好的性能。
(4)BERT-IDCNN-CRF。使用IDCNN(Iterated Dilated Convolutional Neural Networks)替换BiLSTM。IDCNN 相较于传统的卷积神经网络(Convolutional Neural Network,CNN),能够捕获更长的上下文信息,相较于BiLSTM 可以实现GPU 的并行性,训练速度更快。
(5)BERT-R-Transformer-CRF。使 用R-Transformer(Recurrent Neural Network Enhanced Transformer)替换BiLSTM。R-Transformer 同时克服了RNN 和Transformer 的缺点,能够在不使用位置编码的情况下,有效捕获序列中的局部结构和长距离依赖关系。
从表3 可以看出,本文模型与上述模型相比,F1 值均有不同程度的提升,进一步验证了本文所提出模型的有效性。同时,CCKS 2021 和CBLUE CMeEE 两个数据集虽然同属于医学文本,但因为文本来源不同,在语言风格、实体分布等方面存在较大差距。能够在两种数据集上都取得优异的结果,说明了本文模型具有较强的泛化能力。
为了探究本文模型在不同医学实体上的表现,同时对BERT-BiLSTM-CRF、RW-BC 和本文模型在CCKS 2021 数据集上每种实体类型的F1值进行比较,结果如表4所示。
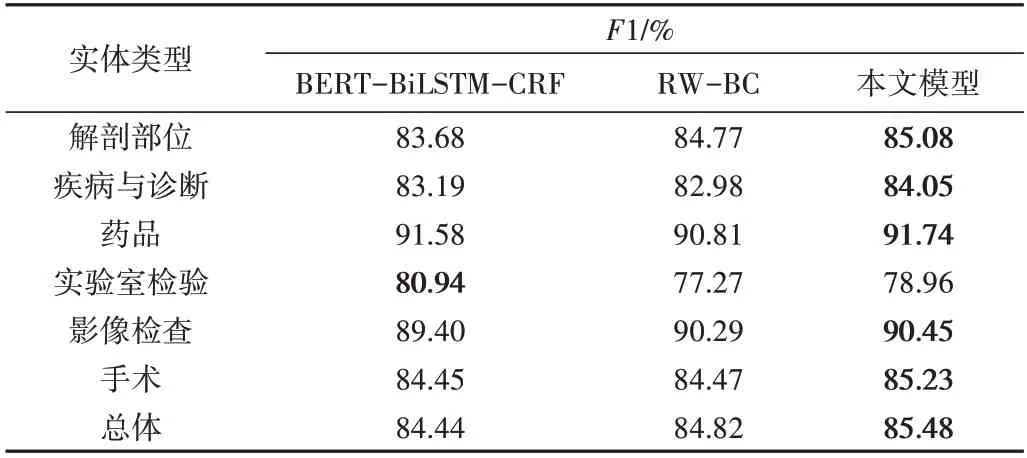
Table 4 Comparison of the F1 values for each entity on CCKS 2021表4 模型在CCKS 2021数据集上各实体的F1值比较
从表4 可以看出,本文模型与RW-BC 模型相比,各实体的识别效果均有不同程度的提升,特别是对“疾病与诊断”和“实验室检验”两种实体的识别效果提升较多;本文模型与BERT-BiLSTM-CRF 模型相比,除“实验室检验”外,其他实体的F1 值均高于BERT-BiLSTM-CRF 模型,其中对“解剖部位”和“影像检查”两种实体的识别效果提升较多,显示出本文方法在医学实体识别任务上的优越性。从结果还可以看出,虽然BERT-BiLSTM-CRF 模型的总体识别效果比RW-BC 模型和本文模型差,但在识别“实验室检验”实体上取得了最好成绩,这也证明了BERT-BiLSTM-CRF 模型在某些特定实体识别上仍具有优势。
4 结语
本文针对医学命名实体识别任务中标注数据稀缺、BERT 无法获取词级别信息及最后一层表征输出单一的问题,提出一种基于半监督学习与RoBERTa 多层表征融合的医学命名实体识别模型。该模型将RoBERTa-wwm-ext 不同Transformer 层融合后作为最终的表征,同时使用伪标签方法,利用未标注数据扩充了数据集,并为伪标签数据设计了噪声减弱模块。在CCKS 2021 医疗命名实体识别数据集和CBLUE CMeEE 数据集上进行实验,结果验证了本文方法的有效性。此外,本文提出的方法并不局限于医学实体识别任务,在未来的工作中,希望能探索该方法在其他医学自然语言处理任务中的表现。
猜你喜欢
中国外汇(2019年18期)2019-11-25
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
公民与法治(2016年10期)2016-05-17
小学教学参考(2015年20期)2016-01-15
