
基于改进生成对抗网络的文本生成模型
2023-05-26 02:05裴志利姜明洋包启明
内蒙古民族大学学报(自然科学版) 2023年2期
熊 露,裴志利,姜明洋,包启明
(1.内蒙古民族大学 数理学院,内蒙古 通辽 028043;2.内蒙古民族大学 计算机科学与技术学院,内蒙古 通辽 028043)
随着互联网、信息技术的发展,人工智能方法在许多不同的领域发挥着重要作用。自然语言处理是人工智能领域的一个重要研究方向,而文本生成是自然语言处理的研究热点之一。文本生成是自然语言处理的一项基础性研究内容,对话系统、机器翻译、图像描述、人工智能诗词写作等应用都依赖于文本生成技术[1-3]。早期用循环神经网络[4](Recurrent Neural Network,RNN)进行文本训练,但对于时间序列的长期依赖问题无法得到有效解决,随后长短时记忆网络[5](Long Short-Term Memory,LSTM)和门控循环单元[6](Gated Recurrent Unit,GRU)的出现解决了长期依赖问题,应用于文本生成任务[7]。2014 年,GOODFEL⁃LOW首次提出了生成对抗网络[8-9](Generative Adversarial Networks,GAN),早期它主要用于处理连续型数据,例如图片的生成;后逐渐用于处理离散型数据,例如文本生成。2016年,杜克大学的ZHANG等[10]提出了TextGAN,通过使用匹配特征分布将句子向量转化为协方差矩阵,使得生成更加真实的句子。YU等[11]提出了SeqGAN,将强化学习与GAN相结合,引入蒙特卡洛搜索方法,解决了序列生成问题。CHE等[12]提出了MaliGAN,通过判别器的输出导出最低方差目标,使得训练过程稳定并降低梯度方差。LIN等[13]提出了RankGAN,判别器通过给出的参考组对真实句子和生成句子进行分析和排序,最后通过排名得分评估生成文本质量。GUO等[14]提出了LeakGAN的新算法框架,通过分层强化学习的方法进行泄露,由判别器泄露的特征对生成器进行指导,以此更好地生成长文本。NIE等[15]提出了RelGAN,生成器采用relational memory,同时利用gumbel-softmax替代强化学习启发式算法,使得生成的文本更具表达力,判别器利用多层次向量表示,使得生成的文本具有多样性。由于生成器输出的结果可以精确到小数点后8位或者更高,但对于文本生成结果要求精确到个位数,造成很多精度的丢失,故笔者提出了一种改进的GAN模型(LFM⁃GAN,Loss Function Mali Generation Adversarial Networks),该模型基于MaliGAN,在此基础上,设计了一种Loss函数,用于解决精度影响问题,其中,生成器采用GPT-2模型[16],判别器采用RoBerta模型[17]作二分类,通过与基础模型、MaliGAN模型和LeakGAN模型以及基线模型MLE对比实验表明,文中所提出的模型在精度、适用性方面要优于其他模型,说明该方法在寻找全局最优、降低离散型变量带来的精度影响方面,具有较好的效果。
1 基于Loss函数的LFMGAN模型
1.1 生成对抗网络 生成对抗网络[8-9]是由判别器D和生成器G两个部分组成。生成器的目标是生成以假乱真的数据;判别器的目标是判断出数据是真实数据还是生成器生成的数据。两者在对抗中不断学习,最终生成器生成的数据越来越接近真实数据,判别器越来越能区分出与真实数据接近的假数据,在不断迭代的过程中,二者能力得到提升。生成对抗网络框架见图1。

图1 生成对抗网络Fig.1 Generative adversarial network
生成对抗网络进行文本生成的目的是尽可能让生成器生成的文本质量高,对生成器来说目的是让判别器无法区别出真实文本和假文本,对判别器来说目的是能够正确区分真实文本和假文本。
设输入生成器的随机噪声为z,噪声的先验分布为pz,该分布符合正态分布或均值分布。生成器用G(z;θg)表示,判别器用D(x;θd)表示,其中,θg为生成器的参数,θd为判别器的参数,假设生成器生成的最终数据样本分布为pg,真实数据样本分布为pdata,生成器就是让pg达到尽量拟合pdata的目的。生成对抗网络优化的目标函数如下:
其中,第一项为判别器对真实数据样本的判别期望,第二项为判别器对生成数据样本的判别期望,V(D,G)表示为判别器判断两分布之间的差距。当数据分布为连续概率分布时,通过概率密度函数与期望之间的关系,可将式(1)转化为:
在生成对抗网络的训练过程中,生成器和判别器交替训练,通过固定生成器的参数,来训练判别器,在判别器能够正确区别生成数据样本和真实数据样本时,V(G,D)取极值,即得判别器的解:
对于不全为0的实数a、b,形如y=alog(y)+blog(1-y)的函数在0与1之间的数取得极大值,判别器的训练过程可看作条件概率P(Y=y|x)的对数似然估计,故有:
其中,KL为KL散度,JS为JS散度。当JSD 函数的值为0时,pdata和pg两个分布相同,此时生成器训练完成,达到最优;当JSD 函数值为log 2 时,pdata和pg两个分布不同。
在生成对抗网络中,通过梯度传播,帮助生成器完成参数更新,同时还能根据生成数据样本以及真实数据样本进行自我更新。
1.2 Sentence-Bert Bert模型需要两个句子同时进入模型进行信息交换来计算语义相似度,但是大量的计算造成了训练速度慢。Sentence-Bert的提出解决了Bert存在的不足,利用孪生网络的结构生成带有语义的句子,把不同句子分别输入到2个Bert模型中,获取每一个句子的embedding向量,语义相似度高的句子其embedding向量距离也就越小。
Regression Objective Function 是将2个句子的句子向量u和v的余弦相似度作为目标函数,随后使用均方误差计算损失并与当前隐藏状态相结合产生目标向量。
余弦相似度是通过计算2个向量夹角之间的余弦值,以此来得到两向量之间的相似度。在二维空间中,将向量坐标值投影到向量空间。余弦相似度通常用来计算词语或句子相似度,将文本编码为embedding向量,计算余弦相似度。余弦相似度的表达式为:
当余弦值为1 时,说明2 个向量重合;当余弦值为-1时,说明2个向量相反;当余弦值为0时,2个向量正交。故2个向量越相似,即余弦值越接近1。
1.3 LFMGAN 模型 文中基于MaliGAN 模型,设计了一种Loss 函数,改进后的模型能够通过寻找全局最优解,同时降低离散型带来精度影响,以此提高文本生成质量。LFMGAN模型结构见图2。

图2 LFMGAN模型Fig.2 LFMGAN model
1.3.1 LFMGAN生成器 生成器包含3层,分别为Embedding层、GPT-2网络层、softmax层。先对数据进行预处理,在Embedding层输入真实文本训练集I转换为映射向量x,将其转化为具有查表操作的词嵌入向量再加上其对应的位置向量。GPT-2网络层包含掩码多头注意力层、批归一化层、多头注意力层、全连接层,经过位置编码后的每一个词向量y产生其相应3 个向量:Query 向量(Q)、Key 向量(K)、Value 向量(V),它们是通过词嵌入矩阵进行变换而得到的,随后计算词向量的分数score:
整个过程会进行多次重复,最后取平均值,这就是多头注意力。
对于掩码机制来说,它是对词库中的一些单词进行随机性的遮掩,防止出现过拟合情况,增加多样性。
对批归一化层作以下处理:
其中,yn为没有经过归一化的词向量,μB为词向量的均值,σ2B为词向量的方差,为第n个词的批归一化后的词向量,ε、β为较小数,防止分母不存在的情况。
在上述过程中通过注意力机制学习了每个单词新表达能力,但体现的表达能力并不是很强,由此希望通过激活函数强化表达能力,加强数值较大部分,抑制数值较小部分;最后加入了dropout和Layer Nor⁃malization层,防止数据过拟合,提高模型泛化能力以及对数据进行归一化。其整个过程的计算公式为:
其中,max为激活函数。
1.3.2 LFMGAN判别器 判别器采用RoBerta模型,将输入的真实数据与生成数据进行真假判断,同时将判别器的反馈结果传至生成器并进行不断优化,因此,判别器可作为一个二分类模型。首先,数据输入特征提取层对数据进行特征提取,然后,输入Embedding层,它主要作用是对数据进行降维,最后,对生成数据进行真假判断。
本实验通过计算Loss值作为指导生成器进行优化,计算公式如下:
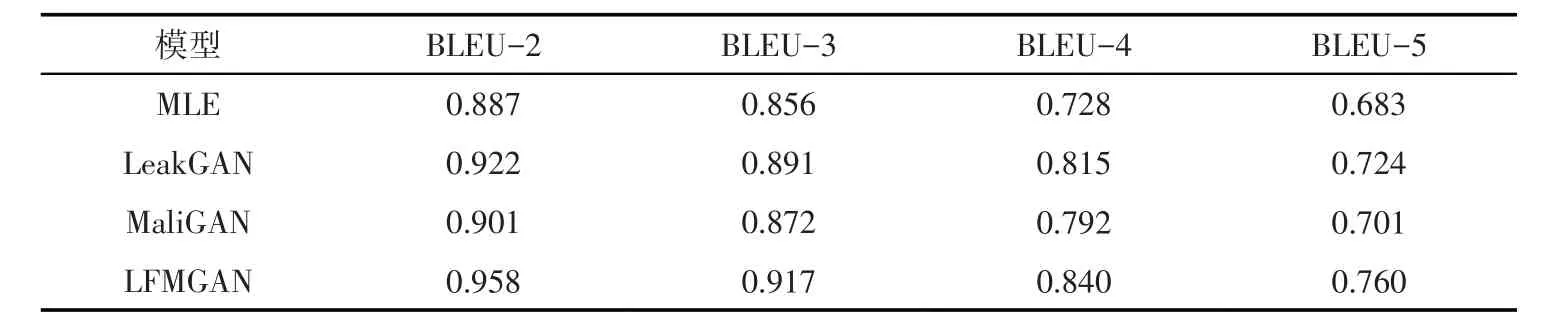
其中,0 其中,pg(x)是生成器的生成分布,pdata(x)为真实分布。 Reward2的公式表达为: 其中,cosine-sim表示生成文本与真实文本之间的语义相似度,是通过Sentence-Bert计算获得。 若Loss值越大,则生成的文本效果越不好;若Loss值越小,则生成的文本效果越好。 本文模型是基于Python语言实现的,实验环境为GPU 12 GB的英伟达GeForce RTX 3080Ti。为了验证提出方法的有效性,与基础模型MaliGAN模型和LeakGAN模型以及基线模型MLE进行了对比。 2.1 数据集 实验采用Image_COCO 数据集和EMNLP2017 WMT News 数据集,在Image_COCO 数据集中,训练集和测试集分别由10 000 个句子组成,单个句子最大长度为37,词汇表大小4 683。在EMN⁃LP2017 WMT News数据集中训练集包含278 586个句子,测试集包含10 000个句子,单个句子最大长度为51,词汇表大小为5 256。 2.2 评价指标 为了评估模型对于生成文本的相似性,本实验采用n元组出现的程度评价方法BLEU[18]评分作为评价指标进行评估。它具有计算速度快、应用范围广的特点。计算公式如下: pn用来评估生成文本与实际文本中n元词组出现的重合度。 对于较短文本来说,使用BLEU会造成分数过高,因此,加入了惩罚因子BP,计算公式如下: 其中,c为生成文本的长度,r为实际文本长度。 最后的BLEU值的计算公式如下: 在本实验中,n取2、3、4、5。BLEU的取值范围为[0,1],数值越接近1,文本生成结果质量越好。 2.3 实验结果及分析 2.3.1 COCO IMAGE CAPTIONS 数据集 通过LFMGAN模型验证在COCO IMAGE CAPTIONS 数据上的文本生成效果,实验结果见表1。本实验的LFMGAN模型在该数据集上的文本生成结果要优于MaliGAN模型和LeakGAN 模型,而LeakGAN 模型的生成效果要优于MaliGAN 模型,LFMGAN 模型对比LeakGAN模型的评价指标(BLEU-2,3,4,5)分别提升了3.9%、2.9%、3.1%、5.0%。MaliGAN模型使得生成器不再聚焦于具体样本的生成效果,转而寻找全局最优解,但是离散型数据带来的精度影响仍未得到解决。而文中保留了MaliGAN模型Reward1的优势,引入的Reward2则更关注于样本的生成效果,计算过程避免了离散型数值带来的精度下降,进而提高了BLEU值。 表1 COCO IMAGE CAPTIONS数据集实验结果Tab.1 Experimental results of COCO IMAGE CAPTIONS data set 2.3.2 EMNLP2017 WMT NEWS 数据集 同时用LFMGAN 模型在EMNLP2017 WMT NEWS 数据集上验证生成文本的性能,实验结果见表2。实验结果表明:在EMNLP2017 WMT NEWS数据集上LFMGAN模型对比LeakGAN 模型的评价指标(BLEU-2,3,4,5)分别提升了4.0%、4.9%、3.5%、3.5%。表明在寻找全局最优解的同时降低了离散型数值所带来的精度影响,同时让BLEU指标有所提升。 表2 EMNLP2017 WMT NEWS数据集实验结果Tab.2 Experimental results of EMNLP2017 WMT NEWS data set 针对离散型数据所带来的精度影响问题,笔者提出了一种改进的生成对抗网络文本生成模型。设计了一种Loss函数,保留了MaliGAN 模型寻找全局最优解的优势,引入的Reward2可促使生成样本的语义分布与原样本一致,避免了离散数值带来的精度下降,提高文本生成效果。实验结果显示,本模型在2个数据集上取得了较好的结果、BLEU评价指标有所提升、模型收敛难度有所降低,但仍然存在无法收敛的情况。因此,接下来可以在生成器上加入语法规则,同时引入情感因素,进一步提高文本的多样性与文本生成质量。2 实验及分析

3 结语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中学数学杂志(高中版)(2016年6期)2017-03-01
高中生学习·高三版(2016年9期)2016-05-14
中国老区建设(2016年1期)2016-02-28
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
