
建模交互关系和类别依赖的视频动作检测
2023-05-20 07:36:52贺楚景刘钦颖王子磊
中国图象图形学报 2023年5期
贺楚景,刘钦颖,王子磊,*
1.中国科学技术大学大数据学院,合肥 230027;2.中国科学技术大学自动化系,合肥 230027
0 引 言
随着电子拍摄设备的普及,产生了海量的视频数据,绝大部分包含以人为主体的动作。这些视频已经广泛应用于智能机器人、安防监控和自动驾驶等多个领域(罗会兰 等,2019)。如何对海量视频中的内容进行理解和分析成为热点课题。视频动作检测是其中的一项关键技术,是指给定一段视频,需要检测出视频中所有人员的空间位置,并确定其对应的动作类别,在现实场景下具有极大的应用价值与研究意义。
针对视频动作检测,大部分研究工作分两步进行。首先对动作执行者进行帧级的目标检测,获取关键帧中一系列检测框的位置坐标和动作性分数;然后使用I3D(inflated 3d convnet)(Carreira 和Zisserman,2017)等3 维卷积神经网络处理以关键帧为中心的视频片段,提取全局的时空表征,再基于检测框对应的区域特征进行动作分类。上述流程中,针对图像的目标检测已经非常成熟,可以达到理想的性能,因此该任务的主要难点在于动作识别部分。时序信息对于动作的识别起着至关重要的作用,为了充分地利用时序信息以及更好地提取视频表征,SlowFast(Feichtenhofer 等,2019)是一种新型的骨干网络,对视频的空间维度和时间维度分别进行处理,即以两种不同的帧率运行的单流体系结构。其中,具有低帧率、低时间分辨率的 Slow pathway 用于捕捉空间语义,而高帧率、高时间分辨率的 Fast pathway 能够以精细的时间分辨率捕捉运动信息,该网络显著提高了一般场景下视频动作检测的性能。
然而,在实际应用中,由于很多动作类别具有交互性质,即参与动作的主体不只有动作执行者,还包括周围环境上下文,所以仅根据动作执行者本身的区域特征进行动作推断是不准确的。最近很多方法致力于对动作执行者(actor)与其周围上下文(context)之间的交互作用进行建模,例如场景、其他人和物体等。ACRN(actor-centric relation network)(Sun等,2018)是以动作执行者为中心的关系网络,从全局场景中生成成对关系特征。VAT(video action transformer network)(Girdhar 等,2019)将Transformer网络(Vaswani 等,2017)引入到视频动作检测任务上,通过注意力机制(attention mechanism)关注与动作执行者相关的周围时空上下文。为了利用时序上的全局信息,LFB(long-term feature banks)(Wu 等,2019)建立长期特征库为模型提供长期时间支持,以计算动作执行者之间的远程交互。AIA(asynchronous interaction aggregation network)(Tang 等,2020)构造了一种异步交互聚合网络,试图聚合多个类型的交互作用,利用不同类型交互块之间的深度嵌套来增强目标特征。ACAR-Net(actor-context-actor relation network)(Pan等,2021)提出捕捉间接的高阶支持信息,从而有效地推理人物在复杂场景中的行为。这些方法的基本研究思路都是围绕动作执行者对潜在的交互关系进行建模,没有针对性地处理空间交互和时间交互,忽略了空间维度和时间维度的异质性。具体来说,空间交互往往体现在肢体动作的互动上,强调交互对象之间的空间相对位置关系;而时间交互注重的是短期时间内同一个动作的连续性,以及长期时间内不同动作的关联性。因此,本文对动作执行者之间的空间交互、短期时间交互和长期时间交互分别建模。
此外,在现实场景中,一个动作执行者可能同时执行多种类别的动作。针对多标签分类问题,现有模型通常使用二元交叉熵(binary cross entropy loss,BCELoss)组合作为损失函数,操作简单且效果较好,获得了广泛应用。但是这种实现方式意味着直接将多标签分类问题视作多个类上的二分类问题,最终预测时各个类别是独立进行的,没有考虑动作类之间的内在关联。对本文的数据集AVA v2.1(atomic visual actions version 2.1)(Gu 等,2018)而言,有些动作对的共现概率非常高,例如hug和kiss、stand 和watch a person 等,说明对应的动作类之间可能存在较强的语义相关性。反之,有些动作对的共现概率非常低,例如hand shake和kick、swim 和drink等,则对应动作类别之间的相关性也较低。基于这种现象,本文认为考虑不同动作类之间的依赖关系可以对多标签分类起到一定的辅助作用。
为了解决上述问题,本文提出了一种同时考虑交互关系和类别依赖的视频动作检测方法,对动作执行者之间的交互作用以及动作类别之间的语义相关性进行建模。本文方法的大致流程如下:首先提取动作执行者对应的区域特征;然后短期交互模块使用两层图注意力网络(graph attention network,GAT)(Velickovic 等,2018)分别对空间交互和短期时间交互进行建模,获取局部上下文信息;同时在长期交互模块中引入长期特征库(long-term feature banks,LFB)(Wu 等,2019),与短期特征进行融合,提取与之相关的全局上下文信息;最后设计类别关系模块(class relationship module,CRM),计算不同动作类之间的语义相关性对原始的类别特征进行加权,得到增强后的各个类表征,并提出一种双阶段分数融合(two-stage score fusion,TSSF)策略更新最终的概率得分。本文的主要贡献如下:1)针对性地对动作执行者之间的空间交互、短期时间交互和长期时间交互进行建模,以增强目标特征的表达能力,提升交互类动作的识别效果,既考虑了空间维度和时间维度的异质性,又兼顾了时序上的局部信息和全局信息;2)对于多标签问题,设计类别关系模块挖掘不同动作类之间的依赖关系,并利用这种关系对原始类别表征进行融合,使得学习到的表征具有更强的鲁棒性和区分度,进一步提高了多标签分类的准确性;3)在数据集AVA v2.1 上实验评估了本文方法,定量和定性分析说明了本文方法的先进性,消融实验验证了各个模块的有效性。
1 相关方法
1.1 视频中的关系推理
关系推理在视频理解领域扮演着十分重要的角色,因为在一些复杂场景中,要想精确地识别一个动作执行者的行为往往需要考虑其与其他对象之间的关系。Sun 等人(2018)提出以动作执行者为中心的关系网络ACRN(actor-centric relation network),模型从动作执行者和全局场景特征中聚合成对关系信息,生成用于动作分类的关系特征。Wu等人(2019)提出LFB(long-term feature banks)为视频模型提供长达 60 s 的时间支持,用于计算动作执行者之间的远程交互,可以获得很大的性能增益。Girdhar 等人(2019)重 新 利 用Transformer 网 络(Vaswani 等,2017),通过使用高分辨率的、特定于人的与类无关的查询,模型可以自动地学习每两个动作执行者之间的成对关系,并从他人的动作中提取出相关的语义上下文信息。AIA(asynchronous interaction aggregation network)(Tang 等,2020)通过多个类型的交互模块串行堆叠,将在前一个交互模块中得到增强的目标特征传递给后续模块,旨在对不同类型的交互作用进行融合,而不只是关注单一类型的交互。上述方法都是对动作执行者(actor)与周围上下文(context)之间直接的低阶交互关系进行建模,Pan等人(2021)提出显式建模间接的高阶交互关系,从而有效地推理人物在复杂场景中的行为,特别是在两个actor 并非直接进行交互,而是通过context 作为媒介产生关联的情况下。王东祺和赵旭(2022)构建了一个简洁有效的时序关联模块,借助门控循环单元建立了当前时刻与过去未来时刻的全局时序关联。
1.2 视频中的Attention机制
注意力机制(attention mechanism)最初起源于对人类的视觉研究,为了合理利用有限的视觉处理资源,人类会选择性地关注一部分信息,同时忽略其他可见信息。Transformer(Vaswani 等,2017)将注意力机制引入到机器翻译任务中,缓解了源序列与目标序列的长距离依赖问题。该模型是由一些堆叠的自注意 力 层(self-attention layer)和 全 连 接 层(fullyconnected layer)组成的,自注意力模块通过关注所有位置并在嵌入空间中取它们的加权平均值来计算一个序列中某个位置的响应。Wang等人(2018)提出了Nonlocal模块,将注意力机制拓展为更通用的形式,使其能够在计算机视觉的诸多任务上应用。Non-local操作将某个位置的响应计算为输入特征映射中所有位置的加权和,以捕获长距离的依赖关系。这里的位置集合可以是空间、时间或时空,意味着该操作普遍适用于图像、序列和视频问题。LFB(long-term feature banks)(Wu等,2019)也使用Non-local作为运算符,提取长期特征库内与当前动作相关的全局时序上下文信息。
1.3 图注意力网络
图注意力网络(graph attention network,GAT)(Velickovic 等,2018)常用于关系推理任务中,核心思想是在图算法中引入注意力机制,计算当前节点与邻居节点之间的权重系数,使得图网络能够更加关注重要的节点。算法流程如下:对于输入的所有节点,网络训练生成一个共享的权重矩阵,得到每个邻居节点的权重,然后对邻居节点的特征进行加权求和得到输出特征。它的头结构如图1 所示,其中,邻接矩阵A是一个二值矩阵,Aij代表节点i和节点j之间的邻接关系,若邻接则为1,不邻接则为0,通常邻接矩阵是预先定义好的,在后续特征更新时只需要考虑相邻的节点;相关性矩阵E是对节点两两之间计算互相关系数得到的,Eij代表节点j对节点i的重要性;而权重矩阵W由邻接矩阵A和相关性矩阵E进行点乘后,再通过softmax 函数归一化得到,Wij代表节点i和节点j之间的权重系数。
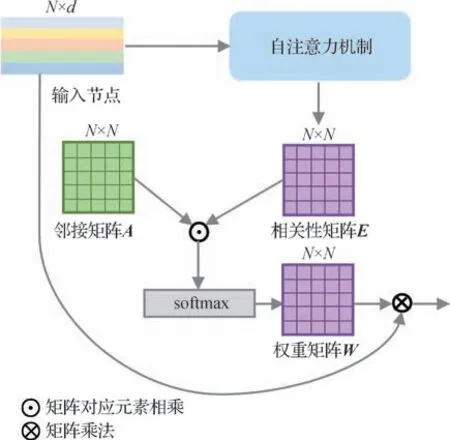
图1 图注意力网络头结构Fig.1 Structure of graph attention heads
2 本文算法
本文的主要思想是通过建模动作执行者之间的交互作用来增强目标特征,提高交互类动作的识别性能,同时利用动作类别之间的依赖关系来增强类别表征,在一定程度上解决多标签分类问题。整体框架由3 部分组成,分别是特征提取部分、长短期交互部分和分类器部分,如图2 所示。其中,特征提取部分包括预训练好的人物检测器和骨干网络,长短期交互部分包括短期交互模块(short-term interaction module,STIM)和长期交互模块(long-term interaction module,LTIM),分类器部分设计类别关系模块(class relationship module,CRM)并采用双阶段分数融合(two-stage score fusion,TSSF)策略。本文算法的具体步骤如下:

图2 本文模型整体架构Fig.2 Overall architecture of the proposed model
1)在视频关键帧上使用微调过的Faster R-CNN(region based convolutional neural network)网络(Ren等,2017)对动作执行者进行目标检测,得到一系列检测框的位置坐标以及动作性分数,再利用预训练好的SlowFast 骨干网络处理以关键帧为中心的视频片段,提取出检测框对应的区域特征;
2)STIM 模块采用两层图注意力网络GAT,针对性地处理空间交互和短期内的时间交互,LTIM 模块引入长期特征库LFB 为模型提供长期时间支持,计算动作执行者之间的远程交互,通过这两个模块对动作执行者本身的区域特征进行增强,提高目标特征的表达能力;
3)设计CRM 模块抽取每个动作类的表征,并通过自注意力机制计算它们之间的语义相关性对原始表征进行加权,得到增强后的各个类表征,最后根据不同模块的互补特性,将第1 阶段的预测分数和新分数融合,更新每一类的概率得分。
2.1 特征提取部分
首先,本文采用在AVA v2.1数据集上微调过的Faster R-CNN 网络作为人物检测器,对视频关键帧中出现的所有动作执行者进行目标检测,得到一系列检测框的位置坐标以及动作性分数,该检测器在AVA v2.1 验证集上的mAP@IoU 0.5(mean average precision@intersection over union 0.5)可 以 达 到93.9%。然后,使用预训练好的SlowFast 骨干网络作为特征提取器,选取动作性分数大于阈值(这里为0.8)的检测框进行RoIAlign(region of interest align)(He等,2017),并执行最大值池化操作,得到2 304维的特征向量。最后,将所有检测框的位置坐标归一化到[0,1]区间,编码后加入对应的原始特征向量中,生成动作执行者的实例级表征,用于后续的动作分类过程。
2.2 长短期交互部分
2.2.1 短期交互模块STIM
STIM 模块旨在建模短期时间内动作执行者两两之间的交互关系。考虑到不同的动作执行者在同一时刻执行的动作具有交互性,而同一个动作执行者在一段短期时间内所执行的动作具有连续性,且空间交互和时间交互本质上是不同的,本文对空间维度和时间维度上的交互作用分别进行建模。如图3所示,STIM模块采用解耦机制,通过两层图注意力网络针对性地处理空间交互作用和时间交互作用,同时也降低了网络的学习难度。
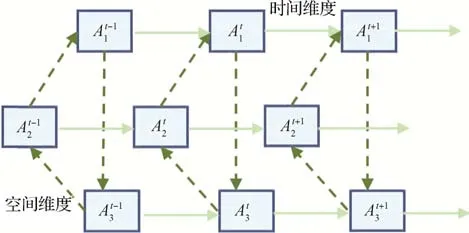
图3 时空解耦机制Fig.3 Spatial-temporal decoupling mechanism
图注意力网络GAT 的头结构如图1 所示。显然,可以通过改变邻接矩阵A的值来调整两两节点之间的邻接关系。例如,对于节点i,若节点j与之相邻,则Aij的值为1,否则为0。基于上述分析,在考虑空间维度上的交互作用时,需要将同一帧内不同动作执行者的节点两两邻接,此时邻接矩阵的分布如图4(a)所示。此外,为了引入不同动作执行者的空间相对位置关系,本文首先计算两两之间的欧氏距离,并用softmax 函数归一化处理,形成一个和邻接矩阵A形状相同的距离矩阵,最后将其与A进行点乘,作为新的邻接矩阵。
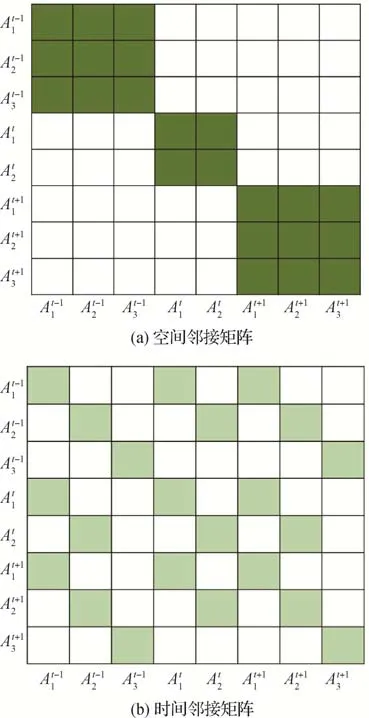
图4 邻接矩阵分布示例Fig.4 Examples of adjacency matrix distribution((a)spatial adjacency matrix;(b)temporal adjacency matrix)
类似地,在考虑时间维度上的交互作用时,由于同一个动作执行者在一段短期时间内所执行的动作具有连续性,所以模型将同一个动作执行者在不同时间步的节点两两邻接,此时邻接矩阵的分布如图4(b)所示,其中表示第t帧的第k个动作执行者节点。本文使用Singh 等人(2017)提出的贪心算法对同一个动作执行者的检测框进行跟踪,采取的贪心策略是匹配时选择下一帧中与当前框交并比(intersection over union,IoU)最大的检测框,且IoU要大于预设阈值(通常为0.5)。
GAT 的特征更新规则具体为:对于输入节点i,假设它的特征向量为hi,邻接节点集合为Ni,则经过GAT之后的节点特征更新为
式中,σ是线性整流函数ReLU(rectified linear unit),wb是一个可学的向量。
2.2.2 长期交互模块LTIM
LTIM 模块旨在提供时序上的长期支持信息,从而帮助模型更好地理解持续时间长且内容复杂的视频,更准确地推断动作执行者在当前时刻的行为状态。如图5 所示,对于目标帧t中发生的 listen(e.g.,to music)动作,如果只考虑短期内时序上与t相邻的前后几帧,将无法确切地得出动作执行者正在listen(e.g.,to music)这个结论。然而,当接收到更长时间范围的信息之后,模型可以自动地捕捉与目标帧中动作相关的时空上下文,大幅提高了模型的置信度。

图5 长期特征库的构建Fig.5 Construction of long-term feature banks
本文在LTIM 模块的设计上遵循LFB(long-term feature banks)(Wu 等,2019)的思想,使用滑动窗口灵活地构建包含历史和未来时刻的长期特征库,缓解了由于GPU(graphics processing unit)内存限制导致视频输入太短的问题。假设当前时刻为t,则第t帧的特征矩阵可表示为Lt∈RNt×d,包含当前帧内共Nt个动作执行者的特征向量,每个特征向量的维数为d。那么第t帧的长期特征库可表示为=[Lt-w,…,Lt+w],即以当前帧t为中心,前后各取w帧的特征矩阵组成,则有∈RN×d,其中代表2w+ 1 长度的特征库内所有动作执行者的数量。
LTIM 模块的算法流程如图6(a)所示。将第t帧内目标经过STIM 模块增强后的特征记做St,再将目标特征St和对应的长期特征库通过算子(operator)进行作用,提取出与之相关的全局时序上下文信息。这里采用的算子是改造后的non-local 模块,具体操作为:首先对St和进行线性变换降至d维,将St作为query,作为key-value 对,在嵌入空间中使用内积计算它们之间的语义相关性。然后对计算结果进行尺度缩放(除以)并通过softmax 函数归一化,尺度缩放的目的在于减小点积值的数量级,避免后续的softmax 函数发生梯度消失问题。接着将归一化之后的系数作为权重,对value 加权求和,再利用LayerNorm 函数使得每个样本内的分布一致,最后提取出时序上的全局信息并更新下一层的输入特征。本文使用了2层non-local的叠加结构(NL),即
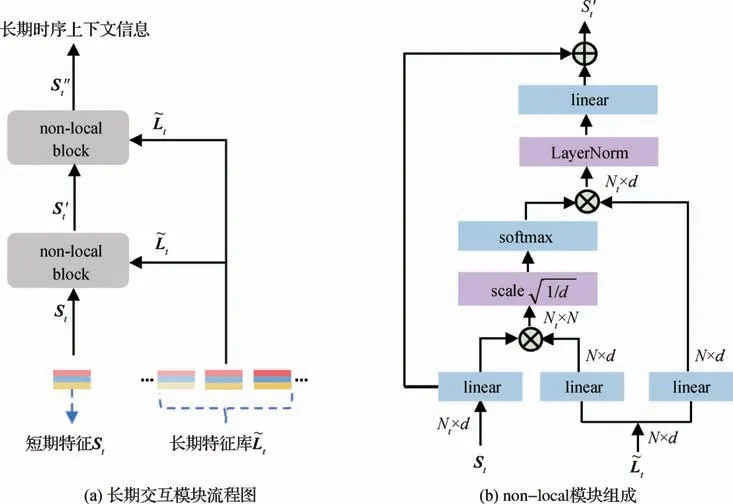
图6 LTIM模块结构Fig.6 Structure of LTIM module ((a)flow chart of long-term interaction module;(b)composition of non-local block)
2.3 分类器部分
2.3.1 类别关系模块CRM
针对多标签分类问题,现有方法普遍采用二元交叉熵(binary cross entropy loss,BCELoss)组合作为模型的代价函数,操作简单且效果较好,因而获得了广泛的应用。但是这种实现方式意味着将多标签分类问题视做多个类上的二分类问题,最终预测时各个类别是独立进行的,忽略了类别之间的内在依赖关系。因此,本文在AVA v2.1训练集上对样本的标签共现信息进行了统计,这里的统计指标为在动作i发生的条件下动作j发生的概率p(j|i)。结果如图7所示,其中颜色越亮的位置表示对应动作对的共现概率越高,横纵坐标轴为该数据集的所有动作类别,此处用数字编号的形式表示。
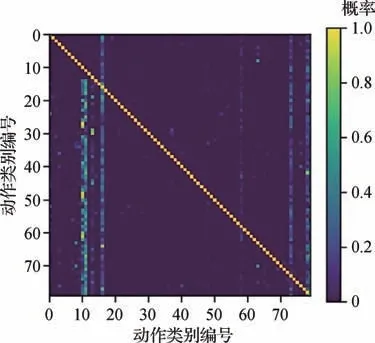
图7 训练样本的标签共现信息Fig.7 Label co-occurrence information of training samples
特别地,本文定义了3 种动作类之间的依赖关系。1)p(j|i) ≈1,说明给定动作j和条件动作i极有可能同时发生,它们之间存在先决条件关系;2)p(j|i) ≈0,说明给定动作j和条件动作i极不可能同时发生,它们之间存在排除关系;3)p(j|i) ∈(0,1),说明给定动作j和条件动作i有一定的概率同时发生,它们之间存在重叠关系。
CRM 模块的目的是使网络自动地学习动作执行者在同一时刻不同动作类之间的语义相关性,自适应地增强各个动作类的表征,从而提升多标签分类的性能。尤其是对正样本数量比较少的动作类而言,网络可能很难学习到有效且鲁棒的类别表征,此时可以利用与之关联性较强或者共现性较高的其他动作类别,通过特征融合的方式增强自身的表征,提高识别准确率。该模块的结构设计如图8 所示,首先对动作执行者的d维特征向量进行C次线性变换(C为动作类别数),分别提取各个动作类别的表征;然后通过自注意力机制建模不同动作类别之间的语义相关性。具体来说,首先对类别特征进行线性变换分别得到对应的query,key 和value,并分别记为QN,KN,和VN。然后,计算QN与KN之间的内积得到类别之间的类别依赖矩阵。再之后,利用该相关性矩阵对VN进行加权,得到增强后的类别特征。最后,将增强后的特征输入到分类器中,预测出每个动作类的概率得分。

图8 CRM模块结构Fig.8 Structure of CRM module
2.3.2 双阶段分数融合策略TSSF
分类器部分设计了CRM 模块,利用不同动作类别之间的依赖关系对特征进行增强,以达到提升多标签分类性能的目的。该模块对动作执行者进行了二次动作分类,对于正样本数量少的动作类别,网络可以更容易地学习到其表征,弥补了第1 阶段特征不够好的缺陷。
由于第1 阶段对少数类样本的区分能力不强,预测分数具有保守性,而CRM 模块在第2 阶段中针对性地改善了该问题,所以提出双阶段分数融合策略对每个动作类的预测分数进行融合,可以采用取最小值、最大值或者平均值的方式得到最终的概率分数,具体为
本文中,第1阶段长短期交互部分和第2阶段分类器部分是联合训练的,模型的总体代价函数为
德国通快集团是全球制造技术领域的领导企业之一,业务范围涵盖机床、电动工具、激光技术、电子和医疗技术等领域,其中激光技术几乎涵盖激光在工业制造技术领域的各种应用范围。通快的卓越表现来自于:开发新工艺和高效率的机床;迅速将技术概念转化到以用户为导向的技术改革之中;高标准的质量和值得信赖的用户服务。
式中,L1和L2分别为第1 阶段和第2 阶段的代价函数,L为这两个阶段的总代价函数,为第i个样本的第j个动作类上的标签,和分别为第1 阶段和第2 阶段在第i个样本的第j个动作类上的预测分数。
3 实验分析
3.1 数据集
本文在AVA v2.1数据集上进行实验,该数据集由从YouTube 中收集的430 个视频组成,其中训练集包含235 个,验证集包含64 个,测试集包含131 个,所占比例分别为55%、15%和30%。对于每个视频,选取15 min的固定长度进行标注,采样频率为1 Hz,即每个视频包含900 个关键帧。标注时,对关键帧中出现的所有动作执行者,逐一确定其空间位置并选择适当数量的动作标签。该数据集的动作标签共80 种,按动作特点分为3 类。第1 类为人体姿势动作,包含14 个子类;第2 类为人—物交互动作,包含49 个子类;第3 类为人—人交互动作,包含17 个子类。每个动作实例最多可分配7 个动作标签,包括1个人体姿势标签、0~3个人—物交互标签和0~3 个人—人交互标签。综上,AVA v2.1 数据集共包含211 k个训练实例、57 k个验证实例和117 k个测试实例,遵循主流方法的设置,本文在训练集上进行模型训练,并在验证集上评估结果。
3.2 评价指标
本文采用阈值取0.5 时的帧级均值平均精度(frame-level mAP@IoU 0.5)作为评价指标,在最终的结果评估时,根据统一的准则,选取了验证集实例数不少于25的60个动作类,忽略了验证集实例数少于25的剩余20个动作类。
3.3 模型设置
实验基于深度学习框架pytorch 1.6.0 部署,模型的训练和测试过程均基于pytorch 完成。本文首先以30 帧/s 的帧率对视频进行抽帧,并将每秒的中间帧定义为关键帧;然后使用微调过的Faster R-CNN 网络在关键帧上对动作执行者进行目标检测,得到一系列检测框的位置坐标和动作性得分;最后利用预训练好的SlowFast 骨干网络提取每个检测框对应的区域特征,训练时选取动作性得分不低于0.9 的检测框以及ground-truth 框,测试时仅使用得分不低于0.8 的检测框。另外,实验在NVIDIA Geforce GTX 1080Ti(11 GB 内存)上完成,模型采用Adam(adaptive moment estimation)优化器加速训练,初始学习率设置为0.000 01,每个训练批次包含16组数据,完成50个训练周期。
3.4 实验结果
为了验证本文模型中各模块的有效性,进行了一系列消融实验,这里以SlowFast 为基准模型,具体为:1)添加STIM 模块;2)添加STIM 模块,分类器部分添加CRM 模块并采用TSSF 策略;3)添加STIM 模块和LTIM 模块;4)添加STIM 模块和LTIM 模块,分类器部分添加CRM 模块并采用TSSF 策略。同时在AVA v2.1 数据集上进行定量和定性分析。然后将本文方法与其他视频动作检测方法进行对比,验证本文方法的先进性。
3.4.1 定量分析
首先对本文模型进行消融实验,分析模型的各个组成部分对最终性能的影响,结果如表1 所示。然后为了更深入地分析模型,分别评估了各模块在人体姿势类别、人—物交互类别和人—人交互类别上的性能,结果如表2 所示。此外,表3中列出了各参数不同取值的组合,并计算每种组合下本文模型在验证集上的指标。最后在表4 中给出了各个模块的参数量和推理阶段每个关键帧的检测时间。

表1 不同的模块组合在AVA v2.1验证集上的性能Table 1 Performance of different module combinations on the validation set of AVA v2.1

表2 人体姿势、人—物交互和人—人交互类别的消融分析(mAP)Table 2 Ablation analysis on Human Pose,Human-Object Interaction and Human-Human Interaction categories in terms of mAP/%
表1 展示了模型各组成部分对最终性能的影响。可以看出,STIM 模块利用图注意力网络显式建模动作执行者之间的短期交互关系,以聚合与动作相关的局部时空信息,有助于模型更好地学习表征,平均精度均值(mean average precision,mAP)比基准模型的结果提升了1.6%。LTIM 模块通过提供长期的时间支持信息,计算动作执行者之间的远程依赖,有助于更精确地推断当前时刻的动作状态,兼顾了时序上的全局信息利用,mAP 在STIM 模块的基础上提升了0.8%。而分类器部分的CRM 模块与TSSF 策略结合,利用动作类别之间的标签依赖关系增强特征,同时针对不同模块的互补性进行分数融合。CRM 模块具有通用性,无论是添加到STIM 模块上(+ 0.3%mAP),还是添加到最终的模型上(+ 0.4% mAP),都能在一定程度上解决多标签分类问题,提升模型的准确率。
除了给出模型在60 个测试子类上的均值平均精度外,本文分别评估了各模块在人体姿势、人—物交互和人—人交互类别上的结果,如表2 所示。与基准相比,最终模型在人体姿势、人—物交互和人—人交互类别上的均值平均精度分别增加了2.0%,2.6%,3.6%,这表明本文方法对建模交互作用和类别依赖都是有效的。同时,本文计算了各个动作类的指标用于对比,如图9 所示。可以看到,本文模型在sing to(e.g.,self,a person,a group)、play musical instrument、cut等动作类上均有明显的性能改进,可能是因为这些动作类的识别需要对动作执行者之间的交互关系进行推理,或者动作本身具有很强的长期时序依赖性。

图9 在AVA v2.1验证集上本文模型和基准模型的各类别指标Fig.9 Per-category results for the proposed model and the baseline on the validation set of AVA v2.1
表3 展示了不同参数组合对模型性能的影响。这里Heads 指的是STIM 模块中图注意力网络GAT的头数目,而Dim 和Layers 分别指的是CRM 模块中类别表征的维数以及注意力层的数目。不难发现,随着GAT 头数目的增加,模型性能进一步提升,这是因为在注意力机制中采用多头的设置可以将输入映射到多个不同的语义空间中,使模型获取的信息更为丰富,也能起到集成的作用,在一定程度上降低了网络发生过拟合的风险。而CRM 模块中类别表征的维数并不是越大越好,过大的特征维数会包含许多冗余信息,也会增加不必要的模型复杂度。寻找最优的参数配置实际上就是追求一种模型复杂度和模型性能之间的平衡。本文最终采用的设置是取Heads = 8,Dim = 32,Layers = 3,对所有的实验统一。此外,本文对模型的参数量和推理速度进行了分析。表4 中的数据体现了各模块之间存在的显著差异,在参数量方面,LTIM < CRM < STIM;在检测时间方面,STIM < LTIM < CRM。所以,在设计模块时不能仅参考某一项指标的值,而应该综合考虑,优化模型的整体性能。

表3 考虑不同参数组合时AVA v2.1验证集上的结果Table 3 Results on the validation set of AVA v2.1 considering different parameter combinations
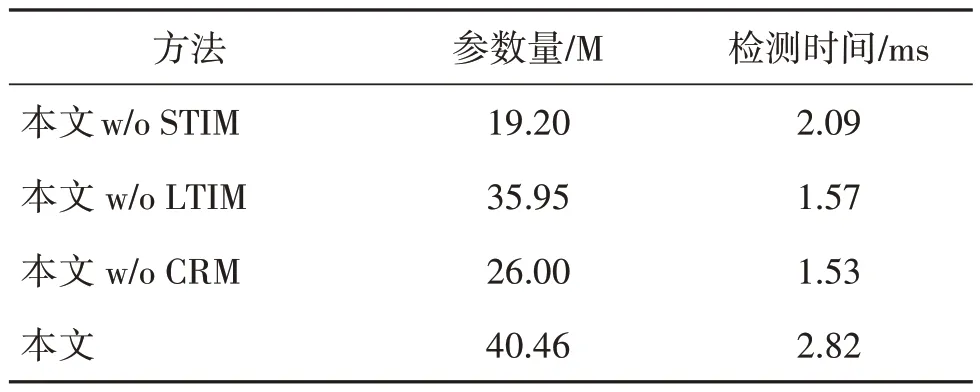
表4 本文模型的参数量和推理速度Table 4 The parameters and inference speed of our model
3.4.2 定性分析
为了定性地评估本文模型,将视频关键帧的动作检测结果可视化,对几个具有挑战性的示例进行性能比较,如图10 所示。在这些示例中,动作参与者所执行的动作具有长期时序依赖性并且涉及到与其他对象的交互。图10(a)(b)分别为基准模型和本文模型的检测结果。第1 行的动作参与者正在执行sing to(e.g.,self,a person,a group)这个动作,该动作的建模不仅需要考虑交互对象(即听众),还需要整合时域上的全局信息。本文模型针对动作执行者特别融合了交互对象的表征,并且精准捕捉了与动作相关的长期时序上下文信息,在该样例中实现了准确的预测。而基准模型只利用到动作执行者本身的区域特征,也没有考虑到动作在时序上的全局依赖性,很容易造成误判。从第2 行可以看到一个男人正在切割木板,这同样也需要利用时序上的长期特征来辅助动作推断。第3 行展示的是两个人打架的场景,建模二者之间的交互作用显然对模型性能的提升大有裨益。

图10 基准模型和本文模型在AVA v2.1验证集的可视化结果Fig.10 Visualization results for the proposed model and the baseline on the validation set of AVA v2.1((a)baseline model;(b)ours)
本文对CRM 模块中间过程的类别依赖注意力图进行了可视化,如图11 所示。图11(a)为选取的两个动作示例及其真实标注。第1 个示例的动作执行者标签为“听某人说话”,第2 个示例为“看手机”。图11(b)为生成的类别依赖注意力图,颜色越亮的位置表示响应越强,即对应的两个动作类之间的依赖性高,颜色越暗的位置表示响应越弱,即对应的两个动作类之间的依赖性低。图11(c)为进一步提取的10 × 10 子注意力图,其中与当前动作相关的动作往往具有较强的响应。例如“听某人说话”、“拿走”和“看着某人”通常与“和某人交谈”同时发生,而不相关的动作普遍响应较弱,例如“拍手”和“抬起某人”没有明显的关联关系,说明了CRM 模块对类别依赖建模的合理性和可靠性。

图11 在AVA v2.1验证集上类别依赖注意力图的可视化示例Fig.11 Visualization examples of class dependency attention maps on the validation set of AVA v2.1((a)ground-truth;(b)class dependency attention map;(c)10 × 10 subset of the attention map)
3.4.3 与其他方法的性能比较
为了更全面地验证本文方法的性能,与ACRN(actor-centric relation network)(Sun 等,2018)、VAT(video action transformer network)(Girdhar等,2019)、LFB(Wu 等,2019)、Context-Aware RCNN(Wu 等,2020)、SlowFast(Feichtenhofer 等,2019)、ACAR-Net(actor-context-actor relation network)(Pan 等,2021)、LSTC(long-short term context)(Li 等,2021)和IGMN(identity-aware graph memory network)(Ni 等,2021)等方法在AVA v2.1数据集上进行比较,实验结果如表5 所示。可以看出,本文方法的mAP@IoU 0.5 指标分别提高了13.6%,6.0%,3.6%,3.0%,2.8%,1.0%,1.0%,0.8%。

表5 不同方法在AVA v2.1验证集上的实验结果Table 5 Experimental results of different methods on the validation set of AVA v2.1
ACRN 通过网络自动挖掘场景中与动作执行者相关的时空元素,生成用于动作分类的关系特征,但没有显式地对实体之间的交互作用进行建模。VAT对Transformer网络进行改造并应用于视频动作检测任务,但同样也是隐式地提取与动作执行者相关的周围上下文信息。LFB 为模型提供长期的时间支持,通过计算实体之间的远程交互来建模全局时序依赖关系,但没有强调利用动作在时序上的局部关联性。Context-Aware RCNN 在提取动作执行者的区域特征之前,对周围图像块进行裁剪和调整,避免空间细节的损失,但在融合上下文信息方面缺少相应设计,只是简单地进行特征拼接。ACAR-Net提出了高阶交互关系的概念,除了动作执行者之间直接的一阶关系之外,还考虑了间接的二阶交互关系,但没有针对性地处理这两种关系。LSTC 利用视频信号之间的时间依赖性进行动作识别,将其分解为短期依赖和长期依赖独立推断,但同样忽视了空间维度和时间维度的异质性。此外,上述方法均没有考虑AVA v2.1 数据集本身存在的多标签问题。本文以时空解耦的方式显式建模动作执行者之间的短期交互作用,同时引入长期特征库兼顾了时序上的局部信息和全局信息,在分类器部分利用类别依赖关系增强表征,且根据不同模块的互补性分阶段预测并对分数进行融合,显著提升了动作检测的效果。
4 结 论
本文提出了一种同时考虑交互关系和类别依赖的视频动作检测方法,试图去建模动作执行者之间的交互作用以及动作类别之间的语义相关性。与对比算法相比,本文在建模交互关系时充分利用了视频信号独有的时空特性,以时空解耦的方式显式建模动作执行者之间的短期交互作用,并引入长期特征库计算远程交互以提取长期时序上下文信息,兼顾了时序上的局部关联和全局依赖。此外,在处理多标签数据集时,本文进行了针对性的设计,通过类别关系模块提取特定于类别的表征,并使用注意力机制计算动作类之间的语义相关性以增强表征。最后根据不同模块的互补特性,提出双阶段分数融合策略更新最终的概率得分。本文方法在一定程度上克服了对比算法存在的局限性,在AVA v2.1数据集上的定量和定性分析结果表明了本文方法的有效性和鲁棒性。相较于其他的视频动作检测方法,本文方法大幅提升了交互类动作的识别效果,同时以较低的计算代价解决了多标签问题。后期研究将进一步优化网络结构,例如改进目标特征与长期特征库的作用机制,以使mAP指标得到更显著的提升。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
电子制作(2018年17期)2018-09-28 01:56:44
当代陕西(2018年9期)2018-08-29 01:20:56
通信电源技术(2018年5期)2018-08-23 01:15:36
中学教学参考·文综版(2017年2期)2017-03-18 08:23:49
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
现代防御技术(2014年6期)2014-02-28 18:26:29
食品科学(2013年8期)2013-03-11 18:21:31
