
渐进式迭代优化的行人属性识别
2023-05-20 07:36:52丁正彦尚岩峰张重阳
中国图象图形学报 2023年5期
丁正彦,尚岩峰,张重阳
1.公安部第三研究所物联网技术研发中心,上海 201204;2.上海交通大学电子信息与电气工程学院,上海 200240
0 引 言
行人属性识别任务一直以来都是智能视频分析领域的研究热点。该任务在行人检测(罗艳 等,2022)的基础上,通过识别行人目标的视觉属性,包括性别、年龄、衣着以及携带物等语义内容,为目标结构化描述与快速检索提供支撑。
随着深度学习技术的不断发展,尤其是卷积神经网络模型在图像分类领域的广泛应用,研究人员提出了许多基于深度网络模型的行人属性识别优化方法。Li 等人(2015)引入多属性联合学习机制,通过单个骨干网络模型得到多属性共享的全局特征,从而有效挖掘属性之间的相互关系。Liu 等人(2017)引入视觉注意机制,采用多方向注意力模块对骨干网络模型的不同语义层提取注意力特征图,并借助多尺度融合模块实现特征优化。Tang 等人(2019)引入属性相关的弱监督定位机制,结合高层语义的指导信息,实现特定属性关注区域的多尺度自适应感知。
另一方面,研究人员通过采集不同场景下的行人目标数据,并标注相关属性信息,构建了多个面向行人属性识别任务的大规模公开数据集,例如PA100K(pedestrian attribute 100K)(Liu 等,2017)、PETA(pedestrian attribute)(Deng 等,2014)、RAPv1(richly annotated pedestrian v1)(Li 等,2016)和RAPv2(richly annotated pedestrian v2)(Li 等,2019),涵盖各种全局目标属性和局部目标属性,其中全局属性主要包括性别、年龄等,局部属性主要包括头部属性、上身属性和下身属性等。
但是,现阶段行人属性识别任务存在的主要问题在于某些属性类别的样本分布严重不均衡,以RAPv2 数据集为例,属性类别总数为54 个,其中正样本所占比例低于10%的属性类别达到34个,占比超过60%(34/54),如图1所示(黄色标注)。

图1 RAPv2数据集的各个属性类别正样本比例统计情况Fig.1 Positive sample ratio for each attribute category of RAPv2 dataset
针对样本分布不均衡的问题,研究人员通常重点关注其中实例数较少的类别(记做少数类),在模型训练过程中引入了多种优化策略。1)数据增广策略。通过对少数类进行数据混合(Zhang 等,2018)或数据噪声(Zhong 等,2020)等操作,随机生成新训练样本,从而增加相关类别的数量比例,该方法在目标实例分割等任务中也广泛使用(Ghiasi 等,2021);2)损失加权策略。在损失函数的设计过程中增加类别自适应的权重,从而选择性地提高少数类的样本重要程度(Jia 等,2020);3)迁移学习策略,在样本均衡的相关数据集上进行模型预训练,并通过特征迁移实现少数类样本数据上的模型泛化(Liu等,2019)。
虽然上述方法能够缓解样本分布不均衡问题,但是如何根据具体任务特点进行多种优化策略的互补融合仍然有待进一步研究。因此,本文针对行人多属性识别任务,提出一种基于渐进式迭代的优化方法,深入融合上述3 种优化策略,具体改进如下:1)数据生成。针对行人目标中的少数类属性,采用马赛克自编码器(masked autoencoder,MAE)(He 等,2022)得到新生成的相关样本数据,通过提高少数类的正样本比例,构建基于属性平衡化的数据生成模型(balanced attributes-data generation model,BADGM),同时实现从MAE 通用大模型到专用小任务的迁移学习和知识增强。2)数据判别。针对新生成的行人目标数据,采用基于原有数据训练的属性判别模型进行数据筛选,根据属性预测的分布一致性剔除异常数据,通过启发式的注意力机制,构建基于特征注意力的数据判别模型(attention features-data discrimination model,AF-DDM),其中判别模型在训练过程中需要根据样本比例自适应调整损失函数的权重,保证数据判别的有效性。3)渐进式迭代。采用数据生成与数据判别相互交替的循环迭代框架,在不增加数据标注代价的情况下,实现行人多属性识别数据的渐进式优化,同时针对均衡后的数据集,通过知识蒸馏机制融合多个不同轮次的数据判别模型,如图2 所示,构建基于渐进式迭代的蒸馏融合模型(progressive iterations-distillation fusion model,PIDFM),在不增加模型复杂度的情况下进一步提升行人属性识别精度。

图2 基于渐进式迭代的行人属性识别优化框架Fig.2 Optimization framework based on progressive iteration for pedestrian attributes recognition
在实际应用过程中,本文所采用的基于渐进式迭代的行人属性识别优化方法能够通过无监督学习机制,在海量无标注的行人属性识别数据集上进行自适应的数据均衡与模型融合,从而有效提升模型的泛化能力。
1 基于属性平衡化的数据生成
针对行人属性识别任务中存在的样本不均衡问题,现有的数据增广策略主要通过数据混合和数据噪声等操作实现。如图3 所示,以常用的随机擦除算法为例,随机掩盖部分图像块进行模拟(掩盖比例为0.3),可以发现随机擦除后的样本数据与真实场景数据存在明显差异,并且可能丢失某些局部属性相关的关键特征信息,导致训练稳定性下降。

图3 随机掩盖部分图像块与复原结果对比Fig.3 Comparison between random masks and restoration results
本文提出引入马赛克自编码器进行图像复原,经过复原后的目标图像与真实场景的目标图像无明显差异(图3),可以作为少数类样本数据的补充,从而实现基于属性平衡化的数据生成。在具体实现过程中,采用一种改进的MAE 算法,如图4 所示。首先按照一定比例随机掩盖原始目标中的部分图像块,然后通过非对称的编码器与解码器结构进行复原操作,其中编码器模块采用基于Transformer 结构的深度网络模型(Dosovitskiy 等,2021)进行特征编码,而解码器模块则采用轻量级模型,MAE 模型预先在海量无标注数据集上进行自监督训练,因此能够很好地实现行人目标的通用特征表示。另一方面,为了进一步优化模型对于行人目标属性特征的表示能力,本文采用大规模行人属性识别数据对MAE 模型进行微调,并引入多个典型的行人属性类别标签作为监督信息,例如性别、年龄和衣着等。
1.1 BA-DGM模型训练
在生成模型的训练过程中,本文采用原始MAE模型作为预训练模型,通过增加行人属性识别相关的监督约束(图4),从而进一步强化模型对于属性相关的常识信息提取,训练阶段马赛克区域所占比例(masking ratio,MR)的随机取值范围记为[MRlow,MRhigh],在保留关键特征信息的情况下增加生成数据的多样性。

图4 针对少数类采用改进的MAE算法进行数据生成Fig.4 Data generation using an improved MAE algorithm for small-amount categories
1.2 BA-DGM模型推理
在生成模型的推理过程中,本文在[MRlow,MRhigh]范围内随机选择MR 值生成马赛克图像并进行复原操作,具体为
式中,E和D分别表示图像编码器和解码器,θ和φ分别为编码器和解码器的模型参数,M⊙为马赛克操作,Iori和Igen分别为原始图像和生成图像。
1.3 少数类数据增广
本文采用上述数据生成策略,针对属性识别任务中存在的少数类数据,通过MAE 模型生成新样本,即每个原始图像得到N幅生成图像,N的取值为
式中,num为属性个数,Nl为第l个属性对应的生成图像个数,pl为第l个属性的训练集正样本比例,yl为原始图像的第l个属性标签,λ为数据增广系数,round(·)为四舍五入操作。在行人多属性识别任务中,每个数据样本对应num个属性标签(y1,y2,…,ynum)。
1.4 从通用大模型迁移到专用小任务
在数据生成过程中,MR 值的大小将对目标图像的复原结果产生影响。如图5所示,随着MR值的不断增加,所生成目标图像的细节特征逐渐减少。从对比结果可以看出,当MR 大于0.9 时,目标马赛克图像的可见部分仅为零散分布的少数局部区域,但是通过MAE 模型仍然能够充分挖掘可见区域的位置关系等深层信息,从潜在特征中恢复出行人的基本样貌图像,同时证明了本文所采用的自编码器模型有效实现了行人目标的通用特征表示,其中包括各个关键部件之间的位置关系等常识特征。

图5 不同MR值的数据生成结果对比Fig.5 Comparison of data generation results for different MR
通过数据生成,本文实现了从通用大模型(MAE 自编码器)到专用小任务(行人属性识别)的迁移学习和知识增强,如图6 所示,其中MAE 模型采用自监督学习机制,从大规模无标注数据中自主获取目标的通用特征表示,包含行人目标姿态等先验知识,即数据背后的目标常识特征,有助于提升行人目标属性识别的准确性和泛化性。
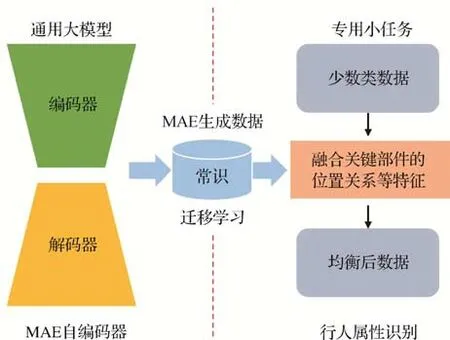
图6 从通用大模型到专用小任务的迁移学习Fig.6 Transfer learning from general big models to dedicated small tasks
2 基于特征注意力的数据判别
针对生成模型得到的新样本数据,由于存在某些细节特征丢失,可能导致相关属性类别发生变化。本文采用基于多标签分类框架的判别模型进行数据筛选,如图7 所示,结合原始图像的属性标签信息,根据预测分布的一致性,从中过滤标签异常的新生成样本。筛选后的数据能够保留与属性相关的关键特征,通过启发式的注意力机制,实现基于特征注意力的数据判别。

图7 针对新生成样本采用多标签分类框架进行数据判别Fig.7 Multi-label classification framework used for data discrimination of newly generated samples
2.1 AF-DDM模型训练
在判别模型的训练过程中,本文基于多标签分类框架,采用50 层的残差网络模型作为骨干网络,在原始的属性识别数据集上进行训练。在训练过程中采用类别自适应的权重(Jia 等,2020),即根据样本比例自适应调整损失函数的权重,从而缓解原始数据不均衡问题对模型精度的影响。
2.2 AF-DDM 模型推理
在判别模型的推理过程(图7)中,本文针对新生成样本进行数据筛选,首先将判别模型输出的多个属性标签分为关键属性标签和其他属性标签两类,分别采用判别条件1 和判别条件2 进行筛选,其中Nl取值参见式(2)。
判别条件1:对于关键属性标签(Nl>0),若判别模型预测的标签与原始标签一致,且输出的相应置信度值高于阈值τ,则满足判别条件,否则不满足;
判别条件2:对于其他属性标签(Nl= 0),若判别模型输出的相应置信度值高于阈值τ,则满足判别条件,否则不满足。
根据上述判别条件对判别模型预测的所有属性标签进行逐一筛选,最后选择每个属性预测结果均满足一致性的新生成样本。
2.3 对抗学习与注意力机制
本文采用上述数据判别策略,针对新生成样本进行数据筛选,如图8 所示,当新生成样本不满足一致性判别条件时,则丢弃该样本,并由生成模型随机得到新样本进行补充。通过生成模型与判别模型的相互对抗机制,使得新生成样本能够在保留属性关键特征的情况下实现样本多样化,同时筛选后的生成数据训练得到的模型将更加易于学习属性相关特征,从而引入启发式的模型注意力机制,进一步提升模型的可解释性与泛化能力。

图8 通过判别模型引入对抗学习与注意力机制Fig.8 Introducing adversarial learning and attention mechanisms through discriminative model
3 基于渐进式迭代的蒸馏融合
为了更好地解决行人属性分类数据的样本不均衡问题,本文在数据生成与数据筛选相互结合的基础上提出渐进式迭代机制,通过两者相互交替的循环迭代,逐步优化得到类别均衡数据集,并通过知识蒸馏框架对不同轮次的判别模型进行有效融合,提升属性识别模型对多种应用场景的适应能力。
3.1 数据生成与数据判别的循环迭代
本文采用循环迭代算法,具体步骤如下:
输入:原始属性识别数据集Dori,迭代轮数T。
输出:类别均衡后的数据集Dnew,不同轮次训练得到的属性判别模型{M1,···,MT}。
1)D0=Dori;
2)fort= 1 toTdo;
3)通过生成模型扩充Dt-1的少数类,得到Gt。根据式(2)每个样本随机生成N个新样本;
4)基于Dt-1训练得到属性判别模型Mt;
5)通过判别模型Mt筛选Gt,得到G*t。若新样本不满足判别条件1和2,则重新生成;
6)更新当前数据集:Dt=Dt-1∪;
7)returnDnew=DT。
3.2 基于知识蒸馏框架实现模型融合
本文采用上述循环迭代策略,经过T轮迭代后,得到多个属性判别模型{M1,···,MT},由于采用不同样本比例的数据集训练,模型之间具有较好的互补性。因此,本文实现了基于渐进式迭代的蒸馏融合 模 型 PI-DFM(progressive iterations-distillation fusion model),如图9 所示,以不同迭代轮次的属性判别模型作为教师模型,并且采用类别均衡后的属性识别数据集Dnew作为训练数据。

图9 基于渐进式迭代实现蒸馏融合模型Fig.9 Achieving distillation fusion model based on progressive iteration
对于每个训练样本Xi,首先通过对不同教师模型的输出结果Mt(Xi)进行加权融合,得到训练监督信息T(Xi),具体为
式中,wt为教师模型Mt所对应的权重,考虑到数据集的类别均衡性随着迭代轮次增加逐步优化,教师模型的准确率也同步实现渐进式提升,因此wt的取值为
然后,针对该样本预测得到学生模型的输出结果S(Xi),其网络结构与教师模型一致,最后通过计算S(Xi)和T(Xi)之间的KL(Kullback-Leibler)散度(Bagherinezhad 等,2018)作为蒸馏损失函数,具体为
在大规模实际应用场景下,测试数据与已有训练数据的样本比例可能存在差异,本文通过知识蒸馏框架,融合不同样本比例数据训练得到的教师模型,能够有效提升模型在开放不确定场景的泛化能力。
4 实验结果分析
4.1 评测数据集及实验参数
实验在目前主流的4 种行人属性识别评测数据集上进行。相关数据集的具体参数情况与常用评测方法(Jia等,2020)一致,如表1所示。

表1 行人属性识别评测数据集的参数情况Table 1 Parameter configuration of benchmark datasets for pedestrian attributes recognition
实验中,采用装有4 张 Nvidia Tesla A100(单张显卡的显存大小为40 GB)的GPU 服务器,并基于Pytorch平台进行模型训练和推理。
1)生成模型。在模型训练阶段,参考MAE 模型的训练超参数(He 等,2022),并增加属性预测机制,如图4 所示,在固定编码器模型参数的情况下微调其他模块,进一步优化嵌入特征表示,同时马赛克区域所占比例MR的取值范围为[0.3,0.7];在模型推理阶段,数据增广系数λ的取值为2。
2)判别模型。在模型训练阶段,与常用评测方法(Jia 等,2020)的模型训练超参数保持一致,以50 层的残差网络模型作为骨干网络,输入图像尺度归一化为H×W= 256 × 192;在模型推理阶段,数据判别阈值τ的取值为0.7。
3)渐进式迭代。迭代轮数T取值为3,通过生成模型与判别模型之间的T次循环迭代优化行人属性识别精度。在迭代过程中,判别模型的训练周期数根据生成数据的增加等比例减少。
在整个训练和推理过程中,本文没有对上述超参数进行调整,即针对不同数据集均采用一致的超参数。
4.2 测试结果对比
实验采用常用评测方法(Jia 等,2020)使用的行人属性识别评测指标。针对不同属性,统计全部属性的平均准确率(mean accuracy,mA);针对不同样本,统计全部样本的平均精度(precision,Prec)、平均召回率(Recall)和平均F1 分数(准确率和召回率的调和平均,记做F1)。
在测试过程中,本文采用50 层的残差网络模型作为基准模型(baseline),并提出基于渐进式迭代的优化方法,与多种目前主流的行人属性识别方法DeepMAR(deep multi attribute recognition)(Li 等,2015)、VAC(visual attention consistency)(Guo 等,2019)和RPAR(rethinking pedestrian attribute recognition)(Jia 等,2020)分别在PA100K、PETA、RAPv1和RAPv2 数据集上进行对比,对比算法均采用与行人属性识别任务常用评测方法(Jia 等,2020)一致的参数配置,实验结果如表2—表5 所示。可以看出,本文方法的mA 和F1 两个指标均有明显提升,表明本文方法能够有效优化行人属性识别结果。在不增加模型复杂度的情况下,mA 和F1 两项指标均优于目前最优的行人属性识别算法RPAR。

表2 不同算法在PA100K数据集上的识别结果Table 2 Test results on PA100K dataset for different algorithms/%

表3 不同算法在PETA数据集上的识别结果Table 3 Test results on PETA dataset for different algorithms/%

表4 不同算法在RAPv1数据集上的识别结果Table 4 Test results on RAPv1 dataset for different algorithms/%

表5 不同算法在RAPv2数据集上的识别结果Table 5 Test results on RAPv2 dataset for different algorithms/%
实验进一步将本文算法与目前主流的引入额外模型复杂度的行人属性识别算法CAS-SAL-FR(cascaded split-and-aggregate learning with feature recombination)(Yang 等,2021)和DBSAN(dual- branch self-attention network)(Liu 等,2022)在PETA 数据集上进行对比,并比较了模型复杂度情况,结果如表6所示。可以看出,本文所提出的算法在模型复杂度最小的情况下得到了较好模型准确率指标,其中F1指标在3种算法中结果最优。

表6 3种算法在PETA数据集上的识别结果Table 6 Test results of three algorithms on PETA
本文提出的迭代优化方法是从属性类别均衡性的角度进行优化,与目前主流的行人属性识别方法具有较好的互补性。本文以RAPv2 数据集为例,针对34 个不均衡类别(正样本所占比例低于10%)的属性识别结果进行统计,如图10 所示,与基准模型结果相比,通过渐进式迭代优化后的属性识别模型能够有效缓解类别不均衡的问题,其中每个类别的平均准确率均有明显提升。

图10 渐进式迭代优化模型与基准模型结果对比Fig.10 Results of progressive iterative optimization model and baseline model
4.3 消融实验
4.3.1 关键子模块选取
本文提出的渐进式迭代算法主要包括BA-DGM数据生成模块(记做模块1)、AF-DDM 数据判别模块(记做模块2)和PI-DFM 蒸馏融合模块(记做模块3)。为了进一步验证各子模块的有效性,本文分别采用第1 轮数据生成后得到的数据(D0+G1)和第1轮数据判别后得到的数据(D0+G*1)在RAPv2 数据集上进行实验,并与经过T轮迭代和蒸馏融合后的最终模型对比,结果如表7 所示,其中平均值表示mA 和F1 指标的平均,反映了针对不同属性和针对不同样本评测指标的综合评价(参见4.2 节)。实验结果表明,3 个主要模块对于属性识别的准确率均有提升作用。

表7 3个改进模块在RAPv2数据集上的识别结果Table 7 Test results of three improvements on RAPv2/%
4.3.2 数据判别阈值τ的参数分析
数据判别阈值的选择需要考虑多个属性的平均准确率和召回率情况,实验分别针对4 个训练集(具体情况参见表1)进行验证,从中随机抽取1/5 的样本数据作为验证集,由其余4/5的样本数据训练得到判别模型,并统计在不同阈值下的属性判别结果平均准确率,结果如图11 所示。实验结果表明,当判别阈值大于0.7 时,属性判别的平均准确率较高(94%~98%),继续增加阈值后准确率的提升较小(小于1%);另一方面,增加判别阈值将导致满足过滤条件的属性样本减少,以RAPv2 数据集为例,当判别阈值由0.7调整为0.8时,样本的平均检出率由77.9%下降至49.8%。因此,根据上述参数分析结果,本文采用判别阈值τ= 0.7,可以同时满足准确率和召回率要求。

图11 不同阈值下的属性判别结果平均准确率Fig.11 Mean accuracy of attribute discrimination results under different thresholds
4.3.3 MR取值范围的参数分析
MR 取值范围的选择需要考虑不同马赛克区域比例下的新样本生成情况,本文以RAPv2 数据集为例,首先分别对比了不同MR 取值下的新生成样本通过数据判别的比例,如图12 所示,当MR 大于0.7时,由于丢失了大量细节特征,导致属性识别结果下降,样本通过数据判别的比例低于5%(图中红色标注),因此MR 取值范围的上限MRhigh可以确定为0.7。

图12 不同MR取值下的新生成样本通过数据判别的比例Fig.12 Passing ratios of data discrimination for newly generated samples under different MR values
进一步地,实验分别针对不同MRlow取值下训练得到的判别模型结果(mA)进行对比分析,结果如表8 所示,经过第1 轮迭代,当MRlow< 0.3 时,由于新样本的多样性下降导致模型结果变差,而当MRlow> 0.3时,由于新样本的低质量比例增加导致模型结果变差,因此MR取值范围的下限MRlow可以确定为0.3。

表8 不同MRlow取值下的模型结果mA对比Table 8 mA comparison of model results under different MRlowvalues
4.3.4 数据增广系数λ的参数分析
数据增广系数的选择需要考虑生成数据集的规模大小和样本均衡性,如表9所示,本文以RAPv2数据集为例,在不同的λ值下,分别针对第1 次迭代后和第T次迭代后的模型结果(mA)进行对比。实验结果表明,当λ< 2 时,由于生成数据集的样本均衡性变差导致模型精度下降,而当λ> 2 时,由于生成数据集的样本规模变大影响模型训练效率,导致经过T轮渐进式迭代优化后的最终模型精度下降。因此,数据增广系数λ的取值可以确定为2。

表9 不同λ值下的模型结果mA对比Table 9 mA comparison of model results under different λvalues/%
4.4 分析与讨论
本文对数据判别的筛选情况进行可视化验证,如图13 所示,以戴帽子、戴眼镜、打电话和穿靴子4 个典型属性为例,首先针对每个正样本图像随机生成N个(N取100)新样本,然后使用判别模型进行筛选,最后对通过筛选的新样本的马赛克区域进行实验分析,统计其中保留的细节特征的空间概率分布。通过实验结果可以发现,数据判别能够较好地保留行人目标关键属性的相关特征,从而引入启发式的注意力机制;另外,通过深入挖掘不同属性的相关特征分布情况,能够进一步提升判别模型的可解释性。

图13 4种典型属性的数据判别筛选情况Fig.13 Filtering results of data discrimination for four typical attributes((a)wearing hat attribute;(b)wearing glasses attribute;(c)phoning attribute;(d)wearing boots attribute)
此外,本文以RAPv2数据集为例,验证T轮迭代后不均衡类别(正样本所占比例低于10%)的个数变化情况,如表10 所示,当T的取值为3 时,经过T轮迭代,不均衡的类别数由34减少到0,最终实现了数据集的渐进式优化。

表10 经过T轮迭代后的不均衡类别的变化情况Table 10 Variation of uneven categories after the Tepochs
5 结 论
围绕行人属性识别任务中存在的样本不均衡问题,本文提出了一种基于渐进式迭代的模型和数据优化方法,通过数据生成与数据判别的相互对抗,引入启发式注意力机制,并构建了从MAE 通用大模型到专用小任务的迁移框架,深入挖掘人体目标的常识特征,有效提升了模型的泛化能力。通过与目前主流的行人属性识别方法进行实验对比,结果表明本文提出的数据均衡化和渐进式迭代方法与现有的改进方法之间具有良好的互补性,并有助于进一步提升模型的准确性指标。
但是,本文方法存在以下不足之处,需要进一步深入研究。1)在实际场景下行人目标存在相互遮挡等问题,影响数据生成和模型迭代效果;2)行人目标的不同属性之间存在相关性,影响行人多属性判别模型的识别效果;3)行人动作姿态的样本多样性对于某些特定属性(如打电话等动作)的识别准确率影响较大,限制了模型精度的进一步提高。
下一步工作将基于MAE 模型的通用特征表示,融合目标质量评价和人体骨架结构等先验知识,优化行人多属性之间的关系建模,进一步提升模型的可解释性。
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
创造(2020年12期)2020-03-17 08:59:20
扬子江(2019年1期)2019-03-08 02:52:34
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
Coco薇(2016年1期)2016-01-11 02:48:05
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
卫生职业教育(2014年24期)2014-05-20 09:05:48
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
