
跨视角步态识别综述
2023-05-20 07:37:30许文正黄天欢贲晛烨曾翌张军平
中国图象图形学报 2023年5期
许文正,黄天欢,贲晛烨*,曾翌,张军平
1.山东大学信息科学与工程学院,青岛 266237;2.复旦大学计算机科学技术学院,上海 200437
0 引 言
步态识别是指通过一个人的行走方式来确定其身份。行走方式可以通过许多传感设备记录,如压力传感器、加速度传感器、陀螺仪和摄像机等。其中,摄像机是日常生活中常见的视觉传感设备,由摄像机拍摄的步态视频可以直接使用,也可以通过前景—背景分割转换为二值化的轮廓图序列。随着公共场所监控摄像头的大规模部署,基于视频的步态识别成为目前主流的步态识别方式。
与人脸、指纹和虹膜等其他生物特征识别方法相比,基于视频的步态识别具有许多独特优势。首先,步态特征可以通过摄像头从远距离以较低的分辨率获取,而人脸、虹膜等特征均需要近距离采集,指纹还需要接触式采集;其次,步态识别不需要被识别者的明确配合,可以以其不易察觉的方式进行,而其他识别方法则可能出现被识别者拒绝配合的情况;最后,步态特征难以伪装或隐藏,而人脸识别系统则很容易被假冒图像或佩戴口罩所欺骗。基于以上独特优势,步态识别在安防监控、调查取证和日常考勤等场景下具有广阔的应用前景。
然而,目前基于视频的步态识别系统的鲁棒性还有待提升,其性能很容易受到视角变化、着装、携物和遮挡等协变量的影响。在这些协变量中,视角的变化在实际应用中经常发生,并会使行人的外观产生很大改变。因此,实现跨视角的步态识别一直是该领域最具挑战性和最重要的任务之一,许多学者对此进行了研究。1994 年,Niyogi 和Adelson(1994)首次将步态特征用于身份识别,但仅研究了步行者的侧视轮廓。2006 年,Han 和Bhanu(2006)提出了步态能量图(gait energy image,GEI),通过对步态周期中的二值轮廓求平均值,将步态中的时空信息聚合到单个图像中,这种表示方法后来得到广泛使用。2015 年,卷积神经网络(convolutional neural network,CNN)首次用于步态识别(Wu 等,2015)。随后的几年中,新的深度神经网络结构不断涌现,步态识别的性能得到大幅提高。
随着近几年步态识别的快速发展,许多综述文献对该领域的进展进行了总结。一些文献(何逸炜和张军平,2018;王科俊 等,2019;Nambiar 等,2020;Sepas-Moghaddam 和Etemad,2023;Santos 等,2023)专注于综述基于视频的步态识别研究,另一些(Connor 和Ross,2018;Wan 等,2019)则同时关注基于视频和其他传感器的方法。2019 年之前的综述没有涵盖近两年最新的深度学习方法,而两篇最新的综述 文 章(Sepas-Moghaddam 和Etemad,2023;Santos等,2023)则只回顾了基于深度学习的方法,没有专门关注步态识别中的跨视角问题。
由于贲晛烨等人(2012)在10 多年前综述了2012 年之前的步态特征表达及识别方法,因此,不同于现有的综述文献,本文重点关注2012 年之后基于视频的跨视角步态识别的重要研究,并且不局限于基于深度学习的方法。
1 跨视角步态数据库
步态数据库是研究步态识别不可或缺的工具,数据库中的数据规模和协变量等因素会影响步态识别算法的性能。表1 按时间顺序总结了几种主流的跨视角步态数据库。其中,CASIA-A(CASIA gait database,dataset A)、CASIA-B 和CASIA-E 数据库由中国科学院自动化研究所建立。CASIA-A 建立时间较早,所含样本和视角数也较少;CASIA-B 是使用最广泛的跨视角步态数据库,包含了相对较多的样本数、视角数和其他协变量,其他数据库很少在这3 方面均占优势;CASIA-E 是新建立的大规模数据库,包含更多的样本和协变量,增加了俯视视角和热红外模态子集,未来具有很好的应用前景。USF(University of South Florida)数据库的协变量较多,但仅有两个视角,在早期跨视角步态识别工作中应用较多。OU-ISIR Speed(OU-ISIR gait database,treadmill dataset A)、OU-ISIR Clothing、OU-ISIR MV、OU-ISIR LP(OU-ISIR gait database,large population dataset)、OU-MVLP(OU-ISIR gait database,multi-view large population dataset)和OU-MVLP Pose 均由日本大阪大学建立。OU-ISIR Speed 和OU-ISIR Clothing 数据库分别包含速度和服装协变量,但所含样本和视角数较少;OU-ISIR MV 包含较多视角数,但样本规模较小且没有其他协变量;OU-ISIR LP和OU-MVLP使用较广泛,其中OU-ISIR LP 视角较少且变化范围小,OU-MVLP 包含最多的样本,但没有其他协变量;OU-MVLP Pose 在OU-MVLP 的基础上提取了姿势序列。Gait3D 是最近提出的数据库,其中采用了39 个摄像头采集的步态信息对人体进行3 维建模。图1给出了常用数据库的采集环境示例。
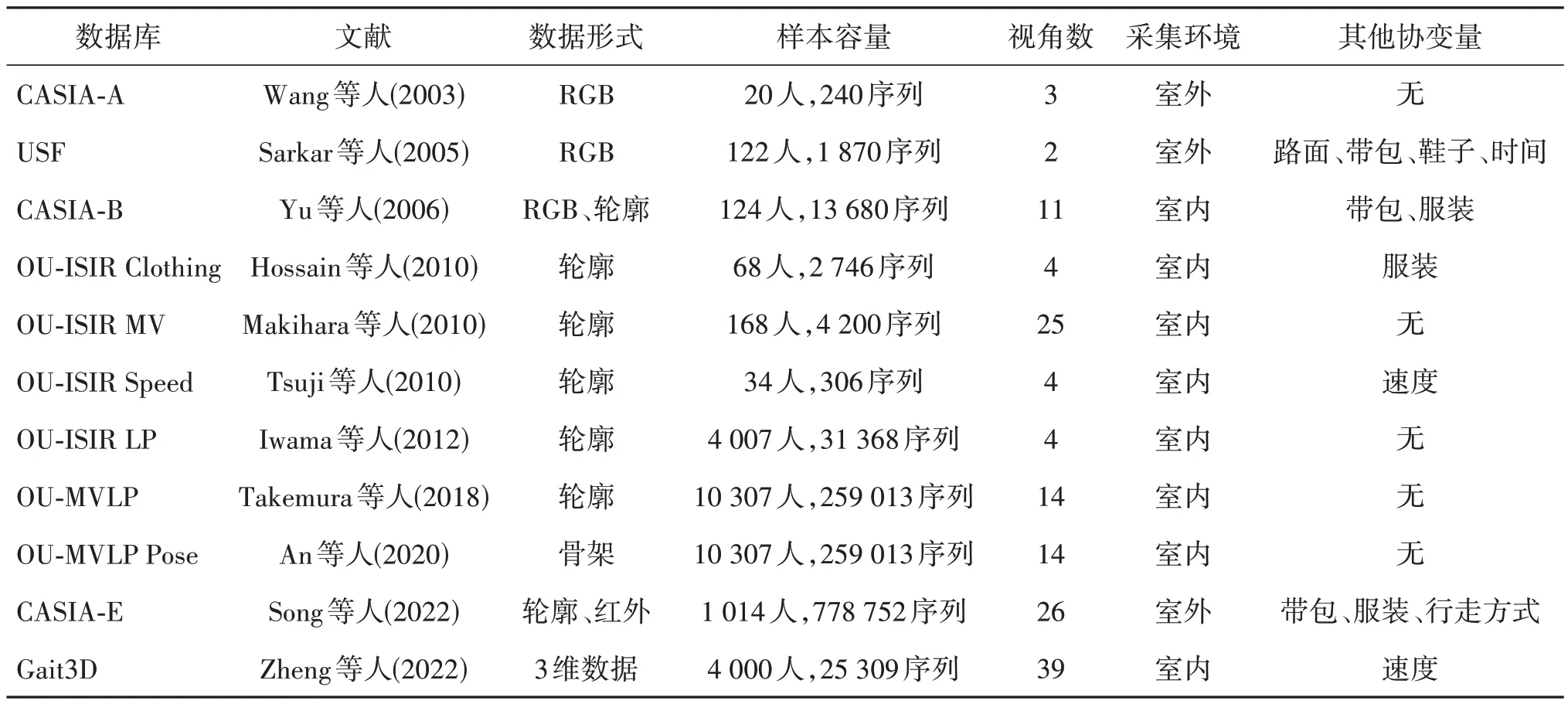
表1 主流的跨视角步态数据库Table 1 Popular cross-view gait databases

图1 常用数据库采集环境示例Fig.1 Examples of commonly used database acquisition environments((a)USF;(b)CASIA-B;(c)OU-ISIR LP;(d)OU-MVLP)
2 跨视角步态识别方法
步态识别通常包括数据采集、特征表示和分类3 个基本步骤,许多综述对此进行详细介绍。本文重点关注基于视频的跨视角步态识别方法,从特征表示和分类的角度介绍针对跨视角问题的解决方案,包括基于3 维步态信息的识别方法、基于视角转换模型的识别方法、基于视角不变特征的识别方法和基于深度学习的识别方法。
2.1 基于3维步态信息的识别方法
3 维步态信息方法从多个拍摄视角的步态视频中提取信息,构建3 维步态模型用于跨视角步态识别。Shakhnarovich 等人(2001)通过4 个静态校准摄像头生成行人的多视角分割轮廓,用于构建3 维视觉外壳模型,并通过最近邻算法进行分类。视觉外壳模型具有可以重建任何3 维形状的通用性优势,但对分割错误非常敏感。另外,大多数视觉外壳算法不会对轮廓形状中的不确定性建模。为了解决以上问题,Grauman 等人(2003)提出了一种用于视觉外壳重建的贝叶斯方法,在视觉外壳重建中使用基于类的先验知识来减少轮廓提取时分割错误的影响。Gu 等人(2010)提出了一种融合姿势恢复和分类的视角无关框架,使用视觉外壳重建体积序列,采用无标记姿势恢复方法从体积数据中获取3 维人体关节,并通过基于样本的隐马尔可夫模型(exemplarbased hidden Markov models,EHMM)对归一化关节位置进行建模,然后采用最大后验(maximum a posteriori,MAP)分类器进行分类。
为了在垂直高倾角和透视失真的情况下跟踪和估计步行者的3 维身体姿势,Rogez 等人(2014)使用低维流形对3 维姿势和相机视角进行建模并学习轮廓的生成模型,通过在场景的水平面和姿势视角流形上联合使用递归贝叶斯采样,进行具有高透视效果的视角不变3 维步态跟踪。然而,这种跟踪必须在人为设置的环境中进行。Luo 等人(2016)提出了基于3 维人体重建和虚拟姿势合成的多协变量步态识别方法(arbitrary view gait recognition based on body reconstruction and virtual posture synthesis,AVGR-BRPS),框架如图2 所示,利用多视角步态轮廓估计的静态形状和运动姿势特征组合形成3 维步态向量,进而构建3 维步态词典。与视觉外壳模型相比,这种参数化的模型更加精确。该方法还引入了基于压缩感知的自遮挡优化同步稀疏表示模型,并通过在稀疏表示中搜索最小重构残差进行分类,步态模型输出Y的最终分类可以表示为
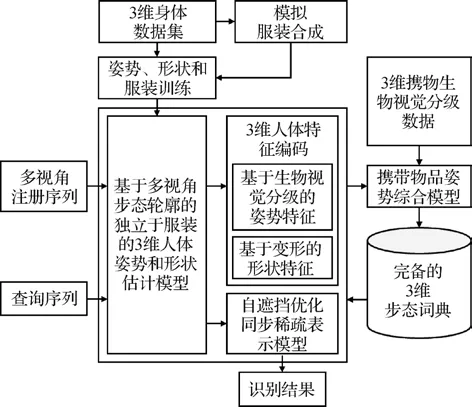
图2 AVGR-BRPS框架(Luo等,2016)Fig.2 The framework of AVGR-BRPS(Luo et al.,2016)
式中,A是训练集词典,是稀疏表示向量,δi是选择第i类相关系数的特征函数。为了解决背景变化、遮挡等造成的轮廓分割不完整问题,Tang 等人(2017)提出了3 维步态局部相似性匹配框架。首先使用水平集能量消耗函数估计3 维姿势,然后使用拉普拉斯形变能量函数实现身体形状变形以修复不完整的步态轮廓,最后通过多线性子空间分类器和多数投票法融合,进行任意视角的步态识别。
基于3 维步态信息的方法对大视角变化具有较好的鲁棒性,但是往往需要昂贵复杂的校准多摄像机系统,或大量的计算和帧同步,这些因素都限制了其在现实监控场景中的应用。
2.2 基于视角转换模型的识别方法
典型的视角转换模型(view transformation model,VTM)利用奇异值分解(singular value decomposition,SVD)将特征矩阵分解为视角无关和对象无关矩阵,设g是受试者m(m= 1,2,…,M)在视角θi(i= 1,2,…,I)下的步态特征。奇异值分解的过程为
式中,向量v是受试者任何视角下的固有步态特征,它构成了视角无关矩阵;对象无关矩阵Pθ是投影矩阵,它可以将v投影为特定视角θ下的步态特征向量。从视角θi到θj的步态特征变换方式为
式中,P是Pθi的伪逆。
Makihara 等人(2006)提出了一种使用频域特征和视角转换模型从不同视角识别步态的方法。通过基于步态周期性的傅里叶分析提取频域特征,即
式中,Ngait是第i个子序列的帧长,g(x,y,n)表示第n帧轮廓坐标(x,y)处的像素值,ω0是对应于Ngait的基角频率,Gi(x,y,k)是g(x,y,n)的离散傅里叶变换。该方法使用多个视角的多人训练集来获得视角转换模型,并在识别阶段将注册特征转换为与输入特征相同的视角方向以进行匹配。
基于SVD(singular value decomposition)的VTM(view transformation model)方法假设步态特征矩阵可以分解为视角无关和对象无关子矩阵,且二者没有重叠元素,但在数学上尚未得到验证。此外,使用全局特征进行视角转换可能会因环境变化而产生噪声和不确定性。为了克服这些局限性,Kusakunniran等人(2010)将VTM 的构造重新表述为一个回归问题,提出了利用支持向量回归(support vector regression,SVR)从不同视角的步态能量图(gait energy images,GEI)建立VTM 的新方法,通过源视角下的局部兴趣区域(region of interest,ROI)预测目标视角下相应的运动信息。设和分别为受试者m在源视角θi和目标视角θj下的GEI,则通过预测的回归模型f定义为
式中,p表示g的第p个像素,ROI表示g上与p相关的局部兴趣区域,<·,·> 表示点积运算,w和b是可学习的参数。由于VTM 的大小仅取决于ROI 的大小和支持向量的数量,计算复杂性可以得到很好的控制,同时系统对噪声更具鲁棒性。随后,Kusakunniran 等人(2012)又提出了另一种基于回归的VTM,采用基于弹性网络的稀疏回归来避免过拟合,为构建VTM提供了更稳定的回归模型。
在利用SVD 或回归训练VTM 时,目标视角与离散的训练视角不一致会导致精度下降。为了解决视角离散性问题,Muramatsu等人(2015)提出了用于跨视角匹配的任意视角转换模型(arbitrary VTM,AVTM),将3 维步态体积投影到目标视角,生成2 维步态轮廓以提取步态特征。尽管使用了3 维步态体积,但不同于视觉外壳方法,该方法只需要独立受试者而不是目标受试者的数据。该方法还将步态特征分为不同身体部分,分别估计每个部分合适的目标视角,并使用转换到估计视角的一对步态特征计算每个部分的匹配分数,从而抑制转换误差并提高识别精度。VTM 方法的另一个问题是不同步态特征对的视角转换质量可能不同,这会产生不均匀偏差的匹配分数。为此,Muramatsu等人(2016)提出了具有质量度量和分数归一化框架的VTM,如图3所示,量化了编码偏差程度的转换质量Qt和相异性边界质量Qb,用于计算两个步态特征来自同一受试者的后验概率以及匹配分数。Qt和Qb的计算式为
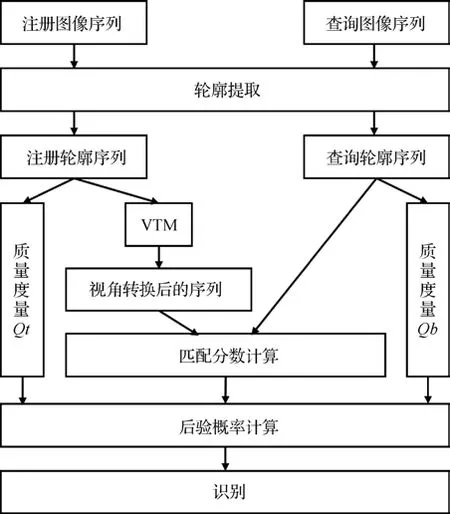
图3 包含质量度量和分数归一化框架的VTM(Muramatsu等,2016)Fig.3 VTM incorporating a score normalization framework with quality measures(Muramatsu et al.,2016)
式中,x为视角θ1下的注册步态特征,x为视角θ2下的查询步态特征,Rθ1和Rθ2为对象无关的投影矩阵,R和R是其对应的伪逆。
基于VTM 的方法不需要多摄像机系统与帧同步,且在测试阶段计算速度快,适合实时应用。但VTM 的参数对用于训练的多视角图像非常敏感,需要足够的训练样本来构建更通用的VTM。另外,虽然VTM 使变换后的步态特征与原始步态特征之间的误差最小化,但其没有考虑区分性因素。
2.3 基于视角不变特征的识别方法
视角不变特征提取的核心思想是从跨视角步态数据中提取不随视角变化的步态特征。早期方法尝试从步态中提取手工制作的视角不变特征。例如,Bobick 和Johnson(2001)恢复了受试者的静态身体和步幅参数,并使用线性回归映射不同视角间的特征。Wang 等人(2003)提出了基于统计形状分析的步态识别算法,使用改进的背景减法提取行人的运动外轮廓,然后将轮廓的时间变化表示为公共坐标系中复向量配置的相关序列,并通过Procrustes 形状分析(Procrustes shape analysis,PSA)获得平均形状作为步态特征,最后采用基于全Procrustes 距离度量的监督模式分类进行识别。Jean等人(2009)使用从轮廓序列中提取的双脚和头部的2 维轨迹作为步态特征,并对其进行视角规范化。Goffredo等人(2010)将无标记运动估计的下肢姿势作为视角不变的步态特征,为了解决特征空间高维性的问题,在识别阶段采用自适应顺序前向浮动选择搜索算法,使用基于验证的评估准则找到分类错误最小化的特征子集,并确保不同类别之间的良好可分性。该方法可以有效地进行大视角变化下的步态识别,但在视角变化较小或正面视角情况下性能较差,且无标记运动估计不具有鲁棒性。Kusakunniran 等人(2013)通过改进的PSA方案从步态轮廓而不是肢体姿势构建视角不变特征,并基于Procrustes 距离连续测量步态相似性,增加了方法的鲁棒性。
视角相关信息往往复杂地嵌入步态中,使得视角不变特征很难准确提取。为此,一些方法将原始步态特征映射到判别子空间,以更好地获得视角不变特征。例如,Cheng 等人(2008)通过高斯过程潜变 量 模 型(Gaussian process latent variable model,GP-LVM)将步态轮廓非线性转化为低维嵌入,并通过隐马尔可夫模型(hidden Markov model,HMM)对步态序列的时间动力学进行建模。Bashir 等人(2010)没有将步态特征投影到一个公共空间,而是通过典型相关分析(canonical correlation analysis,CCA)将每对步态特征投影到两个具有最大相关性的子空间。对于一对步态特征Gx和Gy,CCA 的目标是找到相应的投影矩阵Px和Py,使投影后Gx和Gy间的相关系数ρ最大,即
式中,Cxx和Cyy分别为Gx和Gy的集合内协方差矩阵,Cxy和Cyx为集合间协方差矩阵。Px和Py可由特征值方程求得,具体为
Hu(2014)提出的稀疏局部判别典型相关分析(sparse local discriminant CCA,SLDCCA)采用局部稀疏约束对CCA 进行改进,进一步提出了不相关多线 性SLDCCA(uncorrelated multilinear SLDCCA,UMSLDCCA)框架,直接从多维步态特征中提取不相关的判别特征。Kusakunniran 等人(2014)注意到视角变化对不同部分的步态特征影响不同,并且来自不同视角的局部特征间存在相关性,使用二分图对不同视角特征间的相关性进行建模,通过运动联合聚类将不同视角中最相关的步态片段划分为同一组,并在这些分组上应用CCA,而不是像Bashir 等人(2010)那样使用全局步态特征,其模型框架如图4所示。为了克服CCA 在处理高维特征时计算困难的不足,Xing 等人(2016)提出完全典型相关分析(complete canonical correlation analysis,C3A),将奇异广义特征值计算转化为两个特征值分解问题,以更低的计算成本更精确地计算投影向量。不同于Xing 等人(2016)将向量作为输入,Ben 等人(2020)提出耦合双线性判别投影(coupled bilinear discriminant projection,CBDP),直接将不同视角的原始GEI(而不是向量化GEI)映射到公共矩阵子空间,从而保留了空间信息。另外,与无监督CCA 相比,该方法能最大化类间距离并最小化类内距离。为了解决不同视角间可能共享的步态信息没有得到充分利用的问题,Ben 等人(2019a)提出了耦合块对齐(coupled patch alignment,CPA)算法,首先构建由样本及其类内和类间近邻组成的块,为每个块设计目标函数,然后将所有局部独立的块组合成一个统一的目标函数。不同于CCA 使用全局样本集,CPA 根据类内和类间近邻度量的局部块对集合进行重新排序。上述大多数方法都训练了多个不同视角的映射矩阵,Hu等人(2013)则提出了采用酉线性投影的视角不变判别投影(view-invariant discriminative projection,ViDP),ViDP 的单一性使得跨视角步态识别能够在查询视角未知的情况下进行。Hu(2013)还设计了一种称为增强Gabor 步态(enhanced Gabor gait,EGG)的步态特征,通过非线性映射对统计和结构特征进行编码,并使用正则化局部张量判别分析(regularized locally tensor discriminant analysis,RLTDA)提取对视角变化鲁棒的非线性流形。

图4 Kusakuniran等人(2014)提出的模型框架Fig.4 The framework of the model proposed by Kusakuniran et al.(2014)
一些工作还引入度量学习方法来提取更多有判别力的信息。例如,Martín-Félez和Xiang(2012)将步态识别作为一个二分排序问题。对于一对查询样本q和注册样本g,二分排序旨在学习排序分数函数,即
式中,x是表示(q,g)对的特征向量,ω是权重向量,表示每个特征对排序分数δ的重要性,更高的分数意味着注册g与查询q更相关。通过RankSVM(ranking support vector machines)算法在高维空间中学习排序函数,使得真实匹配和错误匹配比在原始空间中更易分离。Lu 等人(2014)提出了基于稀疏重建的度量学习方法,通过学习距离度量来最小化类内稀疏重建误差,同时最大化类间稀疏重建误差,从而利用有判别力的信息进行识别。Ben 等人(2019b)提出了基于耦合度量学习的通用张量表示框架,从GEI 中提取不同尺度和方向的Gabor 特征,然后通过提出的张量耦合映射准则,将基于Gabor的表示投影到公共子空间进行识别。
在视角差异较大的情况下,这些方法有时很难为特征找到一个鲁棒的视角不变子空间或度量。
2.4 基于深度学习的识别方法
近几年,一些深度学习方法用于提取视角不变步态特征,取得了很好的效果。深度学习通过深度神经网络学习步态特征的深层表示,本节介绍几种常见的深度神经网络结构在提取步态时空特征中的应用。
2.4.1 卷积神经网络
卷 积 神 经 网 络(convolution neural network,CNN)通常是由卷积层、池化层和全连接层组成的前馈神经网络。通过多层卷积和池化操作,CNN 能够学习图像的整体特征而不受局部空间变化的影响。因此常用于从不同视角的步态图像中提取不受视角变化影响的空间步态特征。Wu 等人(2015)从步态序列中随机挑选一些轮廓,并输入CNN 中学习视角不变的特征,这种方法的问题是随机选择的轮廓图像集没有考虑步态特征的有用动态信息。为此,Wu等人(2017)将步态能量图(gait energy image,GEI)作为输入,并对3 种不同深度和结构的深度CNN 进行了广泛评估。GEI的构建方式为
式中,N是图像序列一个完整周期中的帧数,I(x,y,n)表示第n帧轮廓坐标(x,y)处的像素值。通过对步态周期中的轮廓图求平均值,GEI 不仅节省了存储空间和计算时间,而且能在一定程度上反映步态序列的时间信息。Song等人(2019)将轮廓分割、特征提取、特征学习和相似性度量这几个步骤集成到一个框架中,首次提出了用于跨视角步态识别的端到端网络GaitNet。该网络由用于步态分割和分类的两个卷积神经网络组成,这两个网络在联合学习过程中建模,这种策略大幅简化了传统的分步方式,并且每个组件可以在联合学习中显著提高性能。Takemura 等人(2019)详细讨论了用于跨视角步态识别的CNN 的网络结构,指出不同视角输入对间的差异是在经过多层卷积和池化后提取的深层特征上计算的,因此即使在视角变化较大的情况下,CNN 也能够透过类内外观差异学习到更为本质的步态特征;而在视角变化很小时,通过在较浅层上获取细微的空间差异,可以提高网络的类间区分性。受该方法的启发,Xu 等人(2021)提出了一种用于跨视角步态识别的成对空间变换网络(pairwise spatial transformer network,PSTN),首先通过CNN 学习像素级的空间变换参数,将不同视角的输入GEI 转换到它们共同的中间视角,再输入后续基于CNN 的识别网络中,从而减少识别步骤之前由于视角差异而导致的特征对齐错误,进一步提高了基于CNN 的跨视角步态识别精度。
步态能量图简单易实现,但容易丢失细粒度的时空信息,而图像序列的顺序约束可能会使步态识别缺乏灵活性。为了解决这个问题,Chao 等人(2022)提出了GaitSet模型,如图5所示,将步态视为无序的帧集合,使用CNN 从每个轮廓中独立提取帧级特征。该方法不受帧顺序和帧长的影响,并且可以将不同场景下拍摄的不同视频帧进行拼接。同时,该方法还将水平金字塔匹配(horizontal pyramid mapping,HPM)引入步态识别,通过将特征图分割成不同尺度的水平条带,综合利用局部和全局空间特征。Hou 等人(2020)同样将步态轮廓视为无序集,提出了步态横向网络(gait lateral network,GLN),利用深层CNN 中固有的特征金字塔聚合由浅至深的不同卷积层提取的特征来增强步态的区分性表示。GLN 还具有一个紧凑块,使其与GaitSet 相比可以在不影响精度的前提下显著降低步态表示的维数。Han 等人(2022)从度量学习的角度进一步改进 了GaitSet,使 用 角softmax(angular softmax,A-Softmax)损失施加一个角裕度来提取可分离特征,其表达式为

图5 GaitSet框架(Chao等,2022)Fig.5 The framework of GaitSet(Chao et al.,2022)
式中,N表示训练集中的样本数,xi是提取的第i个样本的特征向量,yi表示其对应的标签,ψ(θyi,i)=(-1)kcos (mθyi,i) - 2k,θyi,i是特征向量xi和网络权重Wyi间的夹角,,k∈{0,…,m-1},m是控制角裕度大小的整数超参数。该方法还联合三元组损失(triplet loss)提取更有判别力的特征。三元组损失是步态识别中广泛应用的损失函数,其表达式为
式中,da,p和da,n分别表示相同标签和不同标签样本间的距离,m是用于控制da,n比da,p大多少的超参数,通过适当调整m,可以在保证模型收敛的前提下提高模型的区分度。
为了充分利用步态信息,许多方法将CNN 与1 维卷积等结构相结合,在整体到局部的多尺度时空维度上提取视角不变的步态特征。例如,汪堃等人(2020)利用水平金字塔映射提取多尺度空间特征,并通过对轮廓图特定区域进行随机遮挡,使模型更关注着装和携物等协变量影响范围外的局部步态特征。Fan 等人(2020)提出的GaitPart 将人体分成几个部分,通过基于1 维卷积的微动捕捉模块提取局部短距离时空特征,并使用聚焦卷积层(focal convolution layer,FConv)来增强空间特征的细粒度学习,如图6 所示,图中C、H和W分别为特征图的通道数、高和宽。Wu等人(2021)注意到局部身体部位对识别性能的贡献随着不同的视角和着装条件而变化,提出了一种条件感知比较方案来衡量步态对的相似性,并设计了膨胀时间金字塔卷积(dilated temporal pyramid convolution,DTPC)来提取多时间跨度特征。为了进一步学习灵活、鲁棒的多尺度时间特征,Huang 等人(2021a)提出了一种上下文敏感的时间特征学习网络,将时间特征聚集在帧级、短期和长期3 个尺度上,根据时间上下文信息获得运动表示,并通过显著空间特征学习模块选择有判别力的空间局部特征。Li等人(2022)注意到很多方法以相同的概率从每一帧中提取特征,导致无法充分利用步态序列中包含相邻人体部位最重要信息的关键帧。为此,通过引入残差帧注意力机制关注步态序列的时间重要性以提取关键帧,并通过切片提取器分割和关联相邻的身体部位来增强空间细粒度学习。Hou等人(2022)则试图同时找出序列中的每帧轮廓和轮廓中的每个部分在步态识别中的相对重要性,提出了步态质量感知网络(gait quality aware network,GQAN),通过帧质量块(frame quality block,FQBlock)和部分质量块(part quality block,PQBlock)两个模块评估每帧轮廓和每个部分的质量。
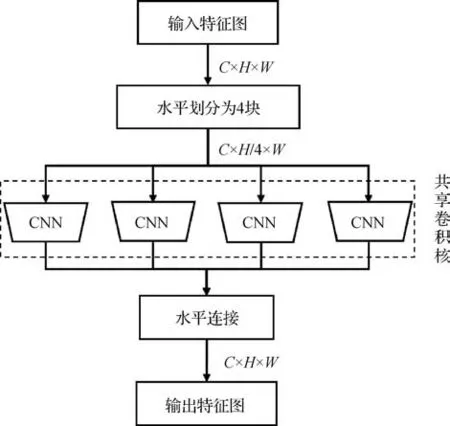
图6 聚焦卷积层Fig.6 The focal convolution layer
除了以上GEI、轮廓图等基于外观的表示方法,近年来基于模型的表示也用做卷积神经网络的输入。基于模型的表示方法对视角、遮挡等协变量具有鲁棒性,但传统模型往往难以准确拟合。基于深度学习的姿势估计方法很好地解决了这个问题。Liao 等人(2020)使用基于CNN 的OpenPose 估计步态的骨架信息,同时融合3 种手工特征,将它们共同作为卷积神经网络的输入。Li 等人(2020c)使用蒙皮多人线性(skinned multi-person linear,SMPL)模型进行人体建模,并使用预训练的人体网格恢复(human mesh recovery,HMR)网络估计其参数,最后使用CNN 或长短期记忆网络(long short-term memory,LSTM)进行识别,其模型框架如图7 所示。与Liao(2020)等人先估计骨架信息再通过CNN提取判别性特征的两步识别不同,Li等人(2020c)提出的整个网络以端到端的方式进行训练。但是,以上两种方法均提取步态模型的整体结构或整体运动,而忽略了其局部模式。为此,Xu 等人(2022)提出了一种局部图骨架描述符(local graphical skeleton descriptor,LGSD)来描述人体步态骨架的局部模式,并采用基于双流CNN 的成对相似网络来最大化真实匹配对的相似度、最小化虚假匹配对的相似度。徐硕等人(2022)将基于外观和模型的表示方法相结合,分别使用GaitSet 网络和5 层卷积网络提取轮廓图像和骨架特征,并通过通道注意力机制对二者进行融合,以结合两种表示方法的优点。

图7 Li等人(2020c)提出的模型框架Fig.7 The framework of the model proposed by Li et al.(2020c)
2.4.2 循环神经网络
循环神经网络(recurrent neural network,RNN)通过带自反馈的神经元来处理时序数据,在跨视角步态识别中常用于从步态序列中提取时间特征。长短期记忆网络(LSTM)和门控循环单元(gated recurrent units,GRU)是两种常用的RNN 变体。LSTM 的循环单元结构如图8(a)所示,上一时刻外部状态ht-1和当前输入Xt经过logistic 激活函数σ(·)和tanh激活函数计算出遗忘门ft、输入门it、输出门ot和候选状态C~t,然后结合ft和it更新记忆单元Ct,最后结合ot更新外部状态ht。GRU 的循环单元结构如图8(b)所示,它直接用更新门zt代替LSTM 的遗忘门和输入门,同时通过重置门rt控制当前候选状态h~t对上一时刻外部状态ht-1的依赖性。
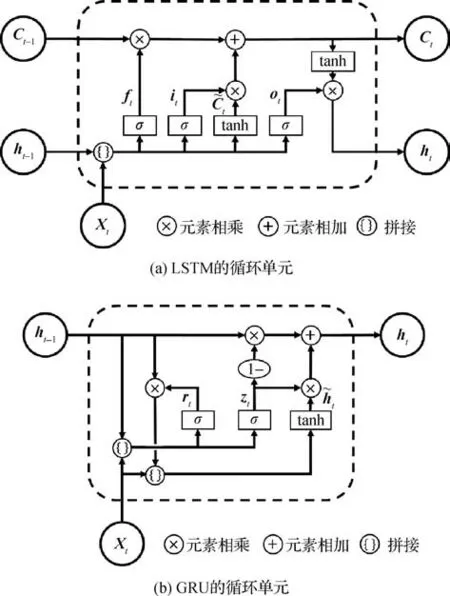
图8 LSTM和GRU的循环单元Fig.8 Recurrent units of LSTM and GRU
RNN 常与CNN 等其他网络结构结合来学习步态序列中的时空信息。例如,Li 等人(2019)通过ResNet-50 模型和空间注意力组件从轮廓图序列中提取与身份相关的空间特征,并将其输入LSTM 单元以学习步态运动特征。同时,针对LSTM 的每个时间步的输出对步态识别有不同的贡献,提出了一种专注时间摘要(attentive temporal summary,ATS)组件来自适应地为LSTM 的输出分配不同的权重,以增强有判别力的时间步并抑制冗余时间步。Zhang 等人(2020)首先通过简化的空间变换网络定位人体轮廓的水平部位,然后利用CNN 提取每个水平部位的步态特征,最后引入LSTM 单元作为时间注意力模型来学习输出特征序列的帧级注意力权重,从而更多地关注具有判别性的帧。此外,提出了称为角中心损失(angle center loss,ACL)的步态相关损失函数,通过为相同身份的每个视角学习多个子中心,更好地实现类内跨视角特征的紧凑性。
除了提取时间特征,RNN 还能用来学习步态图像中局部分块特征间的关系,从而使步态识别系统对视角变化更鲁棒。Sepas-Moghaddam 和Etemad(2021)注意到基于多尺度时空特征表示的方法能有效地学习视角不变的步态特征,但这些学习到的局部特征往往直接连接成特征向量用于识别,忽略了它们之间的关系和位置属性。为了解决这个问题,他们首次使用RNN 学习局部特征间的关系,其模型框架如图9所示。首先通过CNN 和时间池化提取步态帧的卷积能量图(gait convolutional energy maps,GCEM),然后采用双向门控循环单元(bi-directional gated recurrent units,BGRU)学习GCEM 分割块的前向和后向关系,最后使用注意力机制选择性地关注重要的局部特征。

图9 Sepas-Moghaddam和Etemad(2021)提出的模型框架Fig.9 The framework of the model proposed by Sepas-Moghaddam and Etemad(2021)
2.4.3 自编码器
自编码器(auto encoder,AE)通过学习编码器—解码器结构的最小化重建损失来提取输入数据的潜在特征,图10 展示了一个简单的自编码器结构,其中重建损失可以表示为
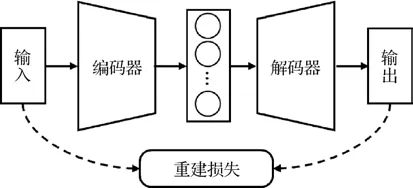
图10 自编码器图示Fig.10 The illustration of the auto encoder
式中,N是一个批量中步态样本的数目,xj和x′j分别表示输入和输出特征。在跨视角步态识别任务中,通过设计合理的损失函数,自编码器能够将行走者的步态特征与视觉外观分离开来,从而利用编码器提取的对外观变化不敏感的步态表示进行识别。
Zhang 等人(2019b)提出了一种自编码器框架,通过交叉重建损失和步态相似性损失从RGB 图像序列中学习姿势特征和姿势无关特征,并将姿势特征输入LSTM 生成基于序列的步态特征。最近,又将姿势无关特征分离为规范特征和外观特征,并通过设计规范一致性损失进一步提高识别的准确性(Zhang 等,2022)。受Zhang 等人(2022)的启发,Li等人(2020b)将解纠缠思想扩展到直接从GEI 中解纠缠身份和协变量特征,因为基于轮廓的表示可以忽略RGB 中的颜色和纹理等无关信息。他们还通过将协变量特征从一个对象转移到另一个对象来合成新的步态模板。Zhai等人(2022)则利用自编码器从GEI 中分离身份和视角特征。如图11 所示,其模型由视角编码器、身份编码器和步态解码器组成。视角和身份编码器分别对原始步态输入的视角和身份特征进行编码,步态解码器使用它们的合并特征来重建输入。为了更好地分离特征,他们使用了多种损失函数,如通过视角回归和身份模糊损失来确保视角特征只包含视角信息、通过不相似性损失来增加身份特征与视角特征间的分布差异。

图11 Zhai等人(2022)提出的模型框架Fig.11 The framework of the model proposed by Zhai et al.(2022)
除了将自编码器用于分离协变量特征,Zhang等人(2021)还提出了一种基于卷积变分自编码器和深度库普曼(Koopman)嵌入的步态动力学框架,将Koopman 算子作为线性化嵌入空间的动力学特征用于跨视角步态识别,为步态识别系统提供了坚实的物理解释能力。
2.4.4 生成对抗网络
生成对抗网络(generative adversarial network,GAN)利用生成器和判别器的对抗性训练,生成符合真实数据分布的样本。在跨视角步态识别任务中,GAN 基于输入样本生成特定视角下的步态图像,可以起到视角转换的效果。例如,Yu 等人(2019)提出GaitGANv2模型,如图12所示,使用类似自编码器的编码器—解码器结构生成侧视视角下的标准GEI,为了在生成的侧视图中保留身份信息,在传统GAN的基础上设计了两个判别器,真假判别器确保生成步态图像的真实性,识别判别器确保生成的步态图像包含身份信息。张红颖和包雯静(2022)在生成器和判别器中引入自注意力机制,以学习更多全局特征的相关性,从而提高生成GEI 的质量。He 等人(2019)提出的多任务生成对抗网络(multi-task generative adversarial networks,MGANs)以基于GEI改进的周期能量图像(period energy image,PEI)作为输入,首先将PEI 编码为潜在空间中特定视角的特征,然后基于视角流形的假设在保持身份信息的同时对视角特征进行转换,再将转换后的特征输入生成器以生成目标PEI,并通过多个子判别器确保生成的PEI 属于特定域(如视角域、身份域或通道域)。不同于GaitGANv2 中两个判别器相互独立,MGANs 中不同的判别器共享网络权重。以上基于GAN 的方法均使用步态序列聚合成的单幅步态图像(GEI 或PEI)作为GAN 的输入和输出,且生成的步态样本直接用于识别阶段而不增加训练数据量。Chen 等人(2021)提出多视角步态生成对抗网络(multiview gait generative adversarial network,MvGGAN),以步态轮廓序列和视角标签作为输入,通过控制视角标签,用一个生成器生成多种视角的虚假步态样本,从而扩展现有步态数据库,解决了基于深度学习的跨视角步态识别方法由于缺少不同视角的样本而性能受限的问题。
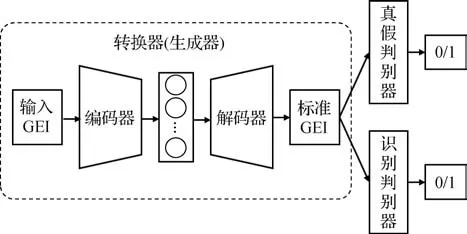
图12 GaitGANv2框架(Yu等,2019)Fig.12 The framework of GaitGANv2(Yu et al.,2019)
2.4.5 3维卷积神经网络
传统的CNN 在用于跨视角步态识别时都是对步态图像的空间维进行操作,而时间维度的帧间运动信息通常需要配合1维卷积或RNN等模块进行提取。3 维卷积神经网络(3D convolution neural network,3D CNN)通过将卷积运算扩展到时域,更好地获取视频图像序列中时空信息间的关联,从而直接学习整个步态序列的时空动力学特征。为了克服3D CNN需要固定长度的帧作为输入,且只关注单个时间尺度的局限性,Lin等人(2020)提出了多时间尺度3 维卷积神经网络(multiple-temporal-scale 3D CNN,MT3D),如图13 所示,使用多时间尺度框架整合小尺度和大尺度时间信息,同时通过引入帧池化操作,打破了3D CNN 输入要求的限制。为了使3D CNN 更好地提取时空特征,他们提出了图13下方所示的两种基础3 维卷积块(BasicBlock3D,B3D),将传统的卷积核大小为(3,3,3)的3 维卷积(3 × 3 × 3 conv)作为主干从步态序列中提取时空特征,而低秩卷积(1 × 3 × 3 conv,3 × 1 × 1 conv,1 × 1 × 1 conv)作为分支以增强主干的特征表示,图中LReLU(leaky-ReLU)指带泄露的ReLU 激活函数。Huang等人(2022)将时空双注意力单元集成到类似B3D的3 种核尺寸并行的3D CNN 中,在保留时空信息相关性的同时解耦时间和空间特征提取。
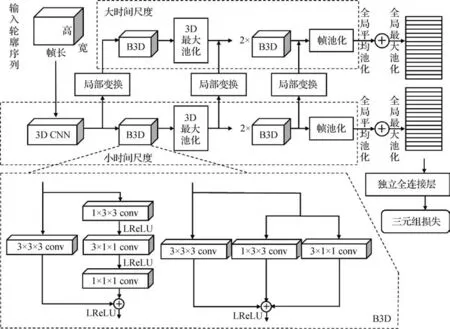
图13 MT3D框架(Lin等,2020)Fig.13 The framework of MT3D(Lin et al.,2020)
考虑到全局特征往往忽略了步态的细节,而局部特征表示可能会丢失全局上下文信息,Lin 等人(2021)在3D CNN 框架中构建了称为全局和局部特征提取器(global and local feature extractor,GLFE)的特征提取模块,通过将全局和局部步态特征相结合来获得更具判别性的特征表示。另外,在CNN 中通常使用空间池化层来降低采样特征分辨率,这会使空间信息逐渐丢失。为此,他们开发了局部时间聚合(local temporal aggregation,LTA)操作来取代传统的空间池化层,并在局部片段中聚合时间信息的同时保留空间信息。他们在提取局部特征时,将全局特征图水平划分为几个部分,这也是许多基于局部特征的模型的通用做法。显然,这些基于水平条带的分割方法无法灵活准确地定位身体部位。为了解决这个问题,Huang 等人(2021b)提出了一种称为3 维局部卷积神经网络的3D CNN 构建块,以自适应的时空尺度、位置和长度从序列中提取局部3 维体积,从而更好地学习身体部位的时空模式。
2.4.6 图卷积网络
首先,注重入门引导。学生对专业的兴趣是建立在专业入门时的引导上,学生刚刚接触专业是培育学生兴趣的最佳时机,因此教师应该在专业入门的引导上下功夫,让每一名学生都能找到自己感兴趣的点,这样才能培养学生的专业兴趣,让学生真的能够“钻进去,学出来”。在学生刚刚接触专业时,应注重学习方法的传授,而不是知识的传授,告诉学生怎么学,学什么,比给学生讲一个知识点重要得多。同时教师要在课程中融入专业的文化,培养学生对专业的责任感和使命感,这也能提高学生对所学专业的兴趣。
在跨视角步态识别领域,基于骨架图的步态表示方法忽略了与外观相关的冗余信息,能够反映更纯粹的步态特征,但骨架图结构中的数据是非欧几里德的,不能在常规的CNN 中操作。2.4.1 节提到的一些方法(Liao 等,2020)利用先验知识设计时空特征形成中间向量,并在CNN 模型中进一步细化。然而,在动态模式中具有实际效果的特征可能会在人工假设中丢失。近几年兴起的图卷积网络(graph convolutional network,GCN)将CNN 扩展到图上,直接处理图结构的数据而不需要对其进行转化,这为基于骨架的步态识别提供了新思路。
Li 等人(2020a)提出一种基于模型的步态识别方法JointsGait,使用步态图卷积网络从2 维骨架中提取时空特征,并通过关节关系金字塔映射(joints relationship pyramid mapping,JRPM)根据人体结构和行走习惯将时空步态特征划分为不同的身体子区域,以获得更具判别力的特征表示。Liu等人(2022)观察到步态特征具有独特的对称性,提出了对称驱动的超特征图卷积网络(symmetry-driven hyper feature graph convolutional network,SDHF-GCN),通过在邻接矩阵中引入基于先验知识的对称连接来增强相关关节之间的联系,并减少联合估计引起的噪声。并且,采用超特征网络来聚合深层的动态特征、中层的结构化特征和浅层的静态特征,通过层次语义特征互补来提高模型的表达和识别能力。Li 和Zhao(2022)受步态周期性的启发,将基于步态周期性的时间特征金字塔聚合器(periodicity-inspired temporal feature pyramid aggregator,PTP)与 空 间GCN 结合,提出了基于骨架的步态识别方法CycleGait,如图14 所示,首先通过设计的不规则步速转换器(irregular pace converter,IPC)将正常步速的骨架序列转换为不规则步速,生成不同周期的步态样本进行数据增强,然后通过GCN-PTP 网络和他们之前提出的JRPM(joints relationship pyramid mapping)(Li等,2020a)分别提取骨架图的时空特征和身体局部特征,最后采用混合损失函数优化步态表示学习。
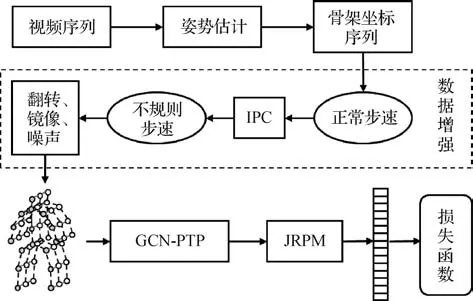
图14 CycleGait框架(Li和Zhao,2022)Fig.14 The framework of CycleGait(Li and Zhao,2022)
3 性能比较和分析
3.1 性能比较
为了进一步了解不同跨视角步态识别方法的性能,本文比较了一些代表性方法的特征表示、采用的识别方法、损失函数和度量函数及在CASIA-B、OUISIR LP 和OU-MVLP 这3 个常用数据库上的识别准确率,如表2 和表3 所示。表3 中结果直接从相应的原始论文中获取。
在CASIA-B数据库上,分别对比了正常、带包和穿外套3 种情况的平均准确率。其中,带下划线结果为在中等样本训练设置下得到,其余结果为在大样本训练设置下得到,两种设置分别以62和74名受试者为训练集,剩下的为测试集。测试集中每个受试者每个视角的前4 次正常行走的步态序列为注册集,其余序列(后2次正常行走序列、2次穿外套行走序列、2 次带包行走序列)为查询集。多数基于轮廓的方法输入图像为64 × 44像素的标准尺寸,部分采用128 × 88 像素或更大输入轮廓尺寸得到的结果以“*”标出。
在OU-ISIR LP 数据库上,主要对比了该数据库两种常用的性能评估方案。第1 种方案将包含1 912 名受试者的子集分为人数相等的2 组,分别用于训练和测试,共进行10次交叉验证实验;第2种方案将所有受试者随机分为5组,进行5次交叉验证实验,每次保留1 组用于测试,剩下的4 组用于训练。有些方法采用了其他评估方案,结果在表3中的OUISIR LP数据库栏中单独列出。
在OU-MVLP 数据库上,分别对比了4 个视角(0°,30°,60°,90°)和全部视角下的平均准确率。在所有的步态序列中,5 153名受试者的序列用于训练,5 154 名受试者的序列用于测试。在测试集中,第1 次和第2 次采集的步态序列分别作为注册集和查询集。
3.2 结果分析
从表2和表3可以看出,轮廓序列和GEI是最常用的两种步态特征,CNN 是最常用的识别方法。多数方法都结合使用了两种或更多的损失函数,其中三元组损失和交叉熵损失最为普遍。对于OU-ISIR LP 数据库,由于其所含视角数较少,且角度变化范围较小,表中方法均达到了90%以上的准确率,其中Ben 等人(2019a)和Wu 等人(2021)提出的方法分别在两种评估方案下实现了最高的性能。对于CASIA-B 数据库,早期基于非深度学习的方法准确率较低,且很多测试没有遵循常规测试协议,随着CNN 等深度学习方法的引入,准确率得到了显著提高。在大样本训练设置下,Huang 等人(2021a)的方法实现了标准输入轮廓尺寸下最高的正常、穿外套和平均准确率。最近,Hou 等人(2022)以128 × 88像素的轮廓图作为输入,在各种条件下的CASIA-B数据库上均达到最高准确率。Huang 等人(2021b)提出的基于3D CNN 的方法在包含全部视角的OUMVLP 数据库上识别效果最好,在CASIA-B 上也取得了较好的效果。Chao 等人(2022)的方法在OUMVLP 数据库4 个视角情况下实现了最好的识别性能。其他几种方法(Huang 等,2022;Lin 等,2021;Chen 等,2021;Li 等,2020c)也在相应数据库上实现了先进的性能。

表2 跨视角步态识别方法比较Table 2 Comparison of cross-view gait recognition methods

表3 跨视角步态识别方法的Rank-1指标对比Table 3 Comparison of Rank-1 metrics for cross-view gait recognition methods/%
结构结合的方法(Wu 等,2021;Huang 等,2021a)在相应数据库上实现了很好的识别效果。值得注意的是,近几年采用人体模型结合深度神经网络的方法(Li等,2020c)在仅视角变化的条件下表现出优异的性能,而当存在服装变化等协变量时,准确率下降比较明显。这可能是因为姿势估计模型大多关注整体特征,使得服装等协变量对其影响相对较大。另外,目前最先进的方法在多数数据库上都达到了90%以上的准确率,但在CASIA-B 穿外套条件下的识别准确率还相对较低(未超过85%)。如何提高跨视角步态识别在复杂条件下的鲁棒性是未来需要进一步解决的问题。
4 未来研究方向
4.1 建立包含复杂协变量的大规模步态数据库
随着深度学习在跨视角步态识别领域的广泛应用,缺少可供深层网络训练的具有复杂协变量条件的大规模步态数据成为亟待解决的问题。现实场景中摄像头通常位于俯视视角拍摄,视频背景复杂,通常包含不止一位行人,且可能存在遮挡情况。饮酒、患病和劳累等特殊状态以及长时间跨度导致的步态特征改变也是需要考虑的因素。然而,现有跨视角步态数据库样本数量普遍较少,且大多是在室内采集,步态序列中仅包含单个受试者,几乎没有遮挡,拍摄背景也较为单一。另外,受试者的步态通常在提前告知的情况下采集,与日常自然行走时的步态相比可能存在差异。因此,未来一个重要的研究方向是建立模拟现实监控场景的大规模步态数据库,同时还要研究鲁棒的分割方法以更好地从复杂背景中分割步态轮廓。此外,还可以通过生成对抗网络等手段生成新的步态图像以解决步态数据采集中的隐私敏感问题。
4.2 跨数据库的步态识别
目前几乎所有的跨视角步态识别任务都在相同的数据集上进行训练和测试,而实际应用时,待识别的步态数据和训练模型使用的数据必然会存在差异。因此,未来有必要通过迁移学习等方法对步态识别模型进行跨数据库训练和测试,从而提高模型在现实场景中的泛化能力。另外,跨数据库识别也能在一定程度上缓解目前可供训练的步态数据不足的问题。
4.3 步态特征的自监督学习方法
实际上,人们很容易通过监控摄像头或网络视频等途径获取大量的步态样本,难点在于获取这些样本对应的身份信息(即标签)。自监督学习可以通过代理任务(pretext task)从大量无标签的样本中学习对下游任务有用的特征,这为利用这些无标签步态样本提供了新思路。然而,对于跨视角步态识别任务,其不同视角的类内差异通常大于相同视角的类间差异,这使得目前流行的基于对比学习的自监督方法很难学习到鲁棒的特征。未来可以针对视角变化设计更有效的数据增强策略和新的代理任务用于视角不变步态特征的自监督学习。
4.4 步态特征的解纠缠表示学习方法
现有的跨视角步态识别方法在实验室环境中已经取得了良好的识别效果,但实际应用中视角、遮挡和光照等复杂协变量互相作用,会显著降低识别准确率。解纠缠表示学习因其能将原始数据空间中互相纠缠的要素分离为互不相关的表示,最近在计算机视觉领域得到了广泛关注。目前一些步态识别方法开始通过解纠缠分离身份和协变量特征,但很少将视角变化考虑在内。未来可以通过优化网络结构和损失函数,设计用于处理包括视角变化在内多种协变量的更全面的解纠缠表示学习方法。
4.5 进一步开发基于模型的步态表示方法
基于外观的步态表示方法因其便于CNN 等神经网络处理而受到了更多关注,然而基于模型的方法在应对视角变化、遮挡等协变量时具有天然的鲁棒性优势。随着各种基于深度学习的姿势估计方法和图神经网络的兴起,步态模型的建立和处理能力都得到了很大提升。基于模型,特别是骨架模型的步态表示方法展现出优良的前景。目前行为识别领域已经对基于骨架的动作表示进行了许多研究,而跨视角步态识别领域的相关工作还较少。未来可以借鉴相关领域的优秀成果,从优化姿势估计算法、开发新的图卷积网络结构、模型与外观表示方法相结合等方面进一步开发基于模型的步态特征表示方法。
4.6 探索新的时间特征提取方法
目前的跨视角步态识别方法在空间特征提取方面取得了更大的突破,而对时间特征的提取仍有待进一步研究。GEI 虽然节省了存储空间,但丢失了步态的时序信息;基于RNN 的方法对步态识别准确率的提升有限;近几年3D CNN 实现了较好的识别效果,但其模型较大,在时空相关性方面可能会引入不必要的冗余或干扰,且在数据量少时容易过拟合。未来可以考虑引入运动学和动力学相关方法对步态序列的时间特征显式建模,以提高步态识别的可解释性和鲁棒性。此外,另一个值得研究的方向是从低帧率视频中提取视角不变步态特征,这对实时步态识别和拥挤人流等低有效帧的识别场景具有重要的应用价值。
4.7 多模态融合步态识别
步态与人脸、指纹和虹膜等其他生物特征相比,具有无需受试者明确配合、无需近距离接触等独特优势,但对视角等协变量鲁棒性较差,而传统生物特征识别目前的准确率通常高于步态识别。很多方法正研究将步态和其他多种生物特征相融合以实现优势互补。另外,将压力传感器、深度传感器等传感设备采集的多模态步态数据相融合,也可弥补视觉传感器易受视角变化影响的局限性,从而提高跨视角步态识别的鲁棒性。
4.8 提高步态识别系统的安全性
一般来说,步态特征不易伪装或隐藏,但随着步态识别技术的快速发展,一些攻击手段可能会对步态识别系统的安全性造成潜在威胁。例如,通过特殊设计的可改变步态的服装等物品进行欺骗,或者通过合成数据进行对抗性攻击。另外,由于视频步态特征容易获得且与年龄、性别、情绪和健康状况等信息有很强的关联性,步态识别中的隐私泄露问题也不容忽视。目前步态识别关于这方面的研究很少,未来可以借鉴人脸识别领域的先进经验,设计适当的安全机制来检测和抵御欺骗攻击,同时设计加密方法来保护步态特征中的隐私信息。
5 结 语
步态识别以其独特优势在安防监控等领域发挥着重要作用。然而,在实际应用中,步态特征往往会受到视角变化等协变量的影响,导致识别性能下降。因此,提高步态识别在跨视角条件下的鲁棒性对推动其实用化意义重大。本文首先介绍了跨视角步态识别数据库,然后从基于3 维步态信息的识别方法、基于视角转换模型的识别方法、基于视角不变特征的识别方法和基于深度学习的识别方法4 个方面对现有的跨视角步态识别方法进行了全面综述。最后,对跨视角步态识别方法的性能进行了对比分析,并提出了几种有价值的未来研究方向。
猜你喜欢
科学大众(2024年5期)2024-03-06 09:40:34
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年18期)2018-11-14 01:48:04
自动化学报(2018年6期)2018-07-23 02:55:42
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
财经(2017年2期)2017-03-10 14:35:35
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
