
图像—文本多模态指代表达理解研究综述
2023-05-20 07:36王丽安缪佩翰苏伟李玺吉娜烨姜燕冰
中国图象图形学报 2023年5期
王丽安,缪佩翰,苏伟,李玺,吉娜烨,姜燕冰*
1.浙江大学软件学院,宁波 315048;2.浙江大学计算机科学与技术学院,杭州 310007;3.浙江传媒学院媒体工程学院,杭州 310018
0 引 言
指代表达理解(referring expression comprehension,REC)要求根据输入指代表达式在图像中定位目标对象,其中输入表达式是一个完整的关于目标对象的描述性句子。该任务成功地构建起人类语言、机器以及现实场景之间的沟通桥梁,实现了基于复杂文本的视觉定位。因此,REC 在新一代智能设备的视觉理解系统和对话系统中具有广泛的应用前景(王忠民 等,2019),例如导航(Thomason 等,2017)、自动驾驶、视频监控、机器人和早期教育等。其中,在视频监控领域REC 的出现可以代替传统监控网络中的单模态目标定位方法,实现机器对人类复杂语言指令的响应。
随着社会中大规模多模态数据的产生,与REC类似的利用视觉和文本两种模态的数据进行视觉语义理解的相关任务吸引了大量关注,包括视觉定位(visual grounding,VG)(Kazemzadeh 等,2014;Yu 等,2017)、图像和视频描述生成(image and video description generation)(Karpathy 和Li,2015)、视觉问答(visual question answering,VQA)(包 希 港 等,2021)、视觉文本检索(image-text retrieval)(尹奇跃等,2021)等。REC 和短语定位(phrase localization)(Plummer等,2017;Wang等,2019a)可以看做是视觉定位的两个子任务。其关键区别在于:短语定位需要对查询语句中提及的所有对象进行定位,其查询语句可以是单个的词、短语或短从句,甚至可以是完整的句子;而REC 的查询语句则是一个描述特定对象的表达式,其需要根据句子中对象的类别、属性以及与其他对象之间的关系等信息唯一地在图像中定位目标对象。另外,与REC 任务相似的还有指代表达分割任务(referring expression segmentation,RES)(Hu 等,2016a;Li 等,2018),目的是在图像中分割出指代表达式所描述的对象。
作为指代表达理解任务的基石,目标检测(object detection)(Ren 等,2017)可以在预定义了固定类别的数据集上实现对所有目标对象的定位。在过去20 多年中,目标检测作为计算机视觉领域的核心任务不断发展,目前,其性能可以实现在COCO(common objects in context)数据集(Lin 等,2014)上达到平均精度均值(mean average precision,mAP)63.2%(Zhang 等,2022)。区别于传统的目标检测任务,REC 的目标对象没有固定的类别,完全由输入表达式决定。因此,相较于目标检测指代表达理解任务更具有挑战性,其不仅需要理解输入表达式的语义信息,包括对象的属性和关系等;还要对包含多个对象的视觉数据进行推理,最终定位目标对象。如图1 所示,输入的指代表达式“1)man on middle horse wearing black and red”与“2)man on horse red top”的长度以及描述的属性等信息都存在差异,但其指代同一个目标对象(图1 中用红框及蓝框圈出的对象)。而表达式“3)man in the blue jacket on the left white horse”与表达式1)虽然存在很多重复的词汇,如“man”、“horse”,但其所指代的目标对象却不相同(分别在图1 中用橙框和红框圈出)。

图1 指代表达理解任务示例Fig.1 The examples of REC task
本文将REC 的处理流程划分成3 个模块,并在第1 节中对各模块进行详细介绍。现有研究表明视觉—文本多模态特征交互融合是整个流程的关键。此外,很多研究也将关注点放在视觉特征提取模块的设计上,将该模块看做是REC 模型的基础模块。因为相较于文本数据,视觉数据含有更丰富信息的同时也存在更多冗余信息的干扰,提取出完整且有效的视觉特征是后续定位成功的基础。基于上述分析,本文创新性地提出了针对REC 模型的两级分类方法:第1 级分类着眼于视觉特征提取模块,从视觉表征粒度出发划分为3 类;进一步,第2 级分类按照视觉—文本多模态特征融合模块的建模方式进行划分。各种分类方法及其对应模型在第2 节中进行详细介绍。
目前,该领域出现了大量研究性论文,但是综述性的论文更多关注于视觉—语言多模态任务的总体概述(杜鹏飞 等,2021;Summaira 等,2021;Zhang 等,2020a;张浩宇 等,2022)。针对REC 任务,目前仅有1 篇2021 年发表的英文综述(Qiao 等,2021),该论文对当时的REC 方法以及数据集进行了全面总结,但没有对REC 任务进行深入分析。不同于此,本文从REC 任务的处理流程出发,深入分析了各模块的功能以及常用处理方法;基于此,本文创新性地提出了针对REC模型的两级分类架构对当前REC方法进行总结,其中全面地涵盖了近两年流行的基于Transformer(Vaswani 等,2017)的REC 方法;最后,本文总结了现有REC 方法面临的挑战,并从模型设计以及领域发展方两个方面对REC的未来发展进行了全面的展望。
1 指代表达理解处理流程
指代表达理解任务的处理流程可以划分为如图2所示的3 个步骤:文本特征提取、视觉特征提取以及视觉—文本特征融合推理。文本和视觉特征提取器分别对文本、视觉输入数据进行单模态特征提取,视觉—文本特征融合模块进行模态交互。本节分别对上述3个步骤进行详细介绍。

图2 指代表达理解方法的通用处理流程图Fig.2 General processing diagram of the REC method
1.1 文本特征提取
文本特征提取模块用于对输入的指代表达式进行语义理解以获取目标对象的相关信息,进而指导后续的目标定位。早期方法普遍采用单个长短期记忆网络(long short-term memory,LSTM)(Donahue等,2015)直接对整个表达式进行编码,这种方法处理简单但忽略了表达式各部分信息重要程度的差异,对于较长表达式无法提取其关键特征。之后陆续出现了对表达式进行分解建模的方法,包括将表达式分解为三元组或者利用外部解析器对表达式进行分解等,在一定程度上实现了对文本中有效信息更高的注意力。随着大规模预训练任务在自然语言处理领域的发展,大量REC 方法利用预训练的BERT(bidirectional encoder representations from Transformers)模型(Devlin等,2019)对表达式进行特征提取。
1.2 视觉特征提取
REC任务的输入图像通常包含多个同类别以及不同类别的对象。面对复杂的输入表达式,例如图1中的“man on middle horse wearing black and red”,模型需要根据表达式的语义对图像中的对象“man”和“horse”进行关系推理从而定位目标对象,因此对图像进行高级语义理解是REC 任务的重要步骤。现有REC 方法对图像的视觉特征提取存在多种方式,如图4所示,本文根据特征粒度的不同将其分为3类:区域卷积粒度视觉表征、网格卷积粒度视觉表征、图像块粒度视觉表征。
1.2.1 区域卷积粒度视觉表征
区域(region)卷积粒度视觉表征方法将图像输入预训练的目标检测网络,例如Faster R-CNN(faster region-convolutional neural network)(Ren 等,2017)等,得到一系列对象边界框。类比二阶段目标检测模型中的区域提议(region proposal)方法,视觉特征提取模块会在这些对象中筛选出一部分作为对象提议(proposal),并将其对应卷积特征作为输入图像的视觉特征输入到后续的视觉—文本融合模块中,如图3(a)所示。区域卷积粒度视觉表征方法可以有效避免图像中无用背景的干扰,一定程度上有利于最终目标对象的选择。

图3 3种不同粒度的视觉表征方法比较Fig.3 Comparison of three different granularity visual representation methods((a)regional convolution granularity visual representation;(b)grid convolution granularity visual representation;(c)image patch granularity visual representation)
1.2.2 网格卷积粒度视觉表征
一阶段目标检测器最早提出利用图像的整层卷积特征代替二阶段目标检测的区域提议特征:直接将图像的整层卷积特征划分为S×S个网格(grid),每个网格负责检测中心位于该网格内部的物体。一阶段目标检测器的成功表明网格卷积粒度的视觉特征可以用于实现目标定位。因此,现有很多REC 方法直接使用ResNet(He 等,2016)等卷积神经网络输出的整层卷积特征作为图像的视觉表征,如图3(b)所示。网格卷积粒度特征的引入有效缓解了基于区域卷积粒度视觉表征方法使用目标检测网络生成对象提议导致的推理速度缓慢的问题。
1.2.3 图像块粒度视觉表征
上述两类视觉特征提取方法都依赖于复杂的视觉特征提取器,包括区域提议网络以及卷积神经网络等,因此在视觉特征提取步骤需要耗费很多额外的计算资源。Dosovitskiy 等人(2021)在ViT(vision Transformer)中提出将输入图像直接在空间(spatial)维度上划分为一个个图像块(patch),然后将图像块映射成1 维序列后直接作为Transformer 的视觉输入。此类视觉特征处理过程如图3(c)所示。ViT 在图像分类任务上的成功证明了这种无需卷积计算的简单视觉表征作为Transformer的视觉输入是足够有效的。此类图像块粒度表征方法实现了更轻量化、更快速视觉特征提取。
1.3 视觉—文本特征融合推理
视觉—文本特征融合推理部分需要对文本特征以及视觉特征进行融合处理从而筛选出图像中有用的视觉特征,其是REC 任务最核心的模块(Deng 等,2022)。现有方法对于该模块的设计非常多样,包括视觉—文本特征匹配(Mao 等,2016)、基于注意力机制的视觉—文本特征融合(Zhang 等,2018)、基于图网络的特征融合(Yang 等,2019a)、基于滤波的特征融合(Liao 等,2020)以及基于Transformer 的特征融合方法(Deng等,2022)等。
2 方法分类
不同于以往直接根据是否对图像预生成对象候选框,将现有REC 方法直接分类为一阶段方法与二阶段方法(Qiao 等,2021)的分类方式。如图4 所示,本文从REC 任务的处理流程入手,首先关注视觉特征提取模块的设计,从视觉数据的表征粒度出发,将REC 方法分成3 类;更进一步地,根据多模态特征融合模块的建模方法进行了子类别划分。

图4 指代表达理解现有方法分类总结图Fig.4 Classification summary diagram of existing methods of referring expression comprehension
2.1 基于区域卷积粒度视觉表征的方法
基于区域卷积粒度视觉表征的REC 方法以二阶段目标检测思想为参考,在处理流程上将REC 任务分成了对象提议、筛选两大步骤。如第1.2.1 节所述,此类方法使用图像的对象提议卷积特征作为视觉表征,后续多模态融合模块仅需根据输入文本对多个对象进行筛选,最终选取得分最高的一个对象边界框即可。根据视觉—文本特征融合建模方式,本文将该类方法更细粒度地划分为如下5个子类别。
2.1.1 早期方法
指代表达理解任务最早直接采用简单的CNNLSTM 框架(Mao 等,2016),如图5 所示,首先对每个对象区域提议提取卷积视觉特征,LSTM用于提取文本特征,然后将两种模态的特征嵌入到同一特征空间计算每个对象区域提议与整个指代表达式的匹配得分,最终选取匹配得分最高的区域作为目标定位结果。Mao 等人(2016)首次将CNN-LSTM 框架引入到指代表达理解和生成任务中,提出了MMI(maximum mutual information)模型。该模型采用VGGNet(Visual Geometry Group network)(Simonyan 和Zisserman,2015)提取的整体图像特征、单个区域提议特征以及区域提议的位置信息共同作为LSTM 每个时间步的视觉输入。Mao 等人(2016)利用最大互信息的思想设计损失函数用于训练,使得模型在除目标区域以外的区域提议上的匹配得分较低。

图5 早期方法模型结构图Fig.5 Model structure diagram of early fusion method
在MMI(Mao 等,2016)之后,陆续出现了一些改进区域提议卷积视觉表征的方法。Yu 等人(2016)提出Visdif 模型,在视觉特征中添加了同类区域提议特征的差值用于表示物体间的视觉差异。Nagaraja 等人(2016)的MIL(multiple instance learning)模型采用多实例学习思想,LSTM的视觉输入采用区域提议对的形式,模型最终输出目标边界框及其相关对象边界框。Hu 等人(2016b)设计了空间上下文网络(spatial context recurrent ConvNet,SCRC)将区域提议边界框的空间信息聚合到区域提议的视觉特征中。
早期方法直接计算对象区域提议与指代表达式的匹配得分,无需对视觉以及文本特征进行融合处理,模型思想简单,并且在RefCOCO 数据集(Yu 等,2016)上取得了73.33%的准确率(Zhang 等,2018),如表1 所示。然而,此类方法直接将整个表达式编码为一个向量,只考虑了整个输入语句与区域提议之间的相似性,忽略了表达式本身丰富的语义结构信息。因此对于长且复杂的表达式,上述方法通常无法准确定位目标对象。
2.1.2 基于注意力机制的融合
当输入表达式太长,或者图像中存在较多的潜在对象时,上述基于全局表示的早期的方法无法得到较好的效果。结合现实场景中人类的推断行为,研究人员认为指代对象的定位应该是渐进的:如图6所示,注意力模块通过指代表达式的内容逐步修改区域提议的注意力权重,最终选取注意力得分最高的区域提议作为目标对象。

图6 基于注意力机制的融合方法模型结构图Fig.6 Model structure diagram of fusion method based on attention mechanism
Zhuang 等人(2018)提出了一种平行注意(parallel attention,PLAN)方法将自然语言表达式的每个单词看成一个单独部分(unit),并对每个部分分别进行编码。采用图像级和区域级两种级别的注意力机制:图像级注意力机制不断调整图像全局上下文特征的注意力,区域级注意力机制则不断根据输入的文本特征调整每个对象提议框的注意力得分,最终将图像全局特征以及区域提议特征输入匹配模块,计算其匹配概率。这种循环发现目标对象的方式令模型朝着可解释的方向迈出了第1步。Deng等人(2018)则定义了3 个注意力模型,并提出了一个累积注意力机制A-ATT(accumulated attention mechanism)对目标对象进行推理。A-ATT 机制可以循环积累对图像、表达式以及区域提议中有用信息的注意力得分,最终选取注意力得分最高的区域提议作为最终定位结果。A-ATT模型可以在视觉定位的过程中显示图像中高注意力区域以及表达式中的关键单词,进一步实现了模型的可解释性。
如表1 所示,基于注意力机制的融合方法相比早期方法实现了性能的明显提升,其中CM-Att-Erase(cross-modal attention-guided erasing)(Liu 等,2019c)在RefCOCO 数据集的testA 上性能达到了83.14%,相比当时最优的早期方法VaruContext(variational context)(Zhang 等,2018)模型性能提升了近10 个百分点。并且此类方法通过可视化图像的注意力热图可以逐步推断出输入文本与图像中对象之间的匹配关系,推动了模型可解释性的发展。
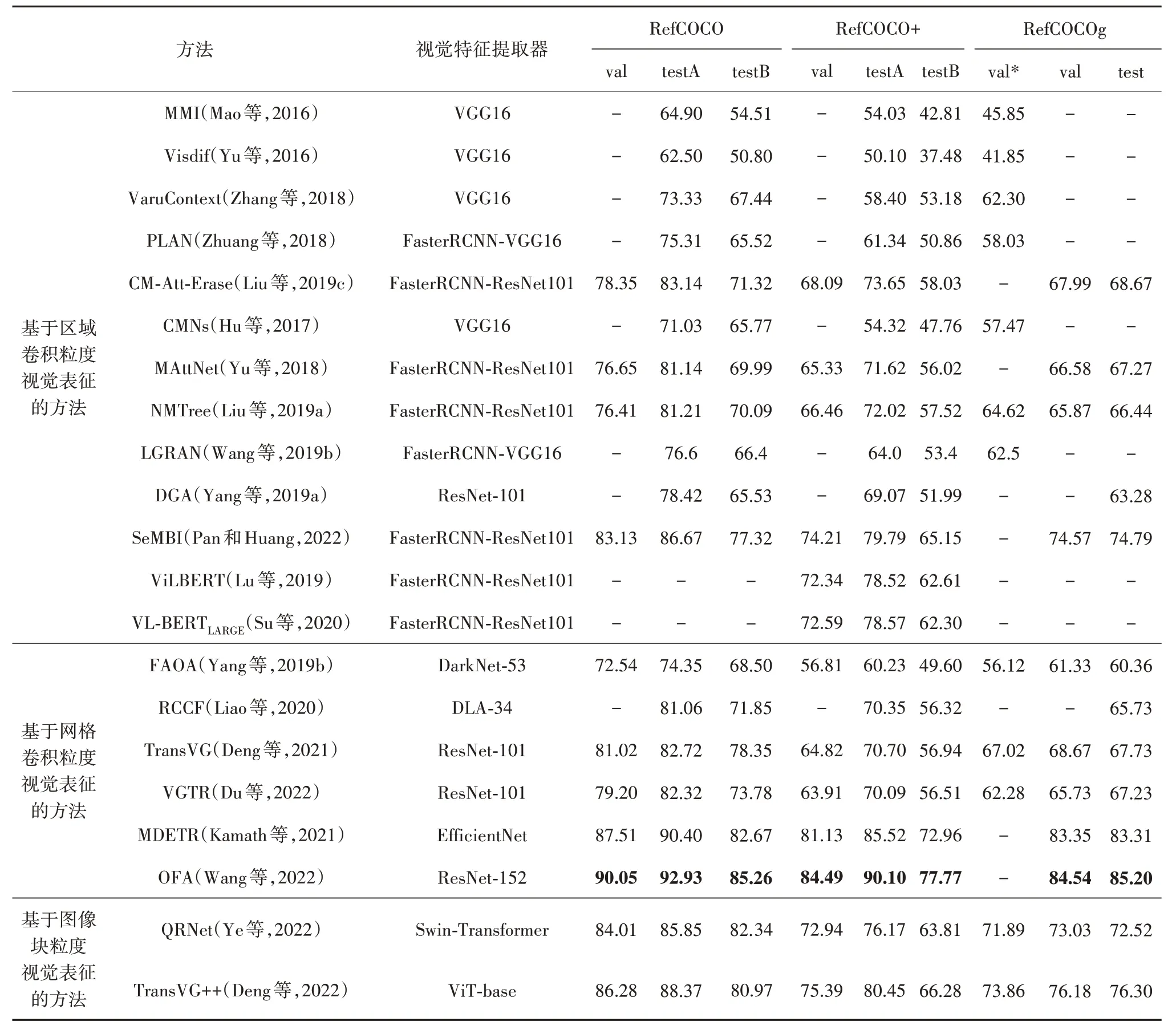
表1 在RefCOCO、RefCOCO+、RefCOCOg数据集上现有REC方法的性能比较Table 1 Performance comparison of existing REC methods on RefCOCO,RefCOCO+,and RefCOCOg datasets/%
2.1.3 基于表达式分解的融合
早期方法将整个表达式直接编码为一个向量的方式不仅没有考虑表达式中各部分的重要程度,还忽略了语言本身的语法结构信息。因此,对表达式进行结构化分解,构建细粒度的文本表征对定位目标对象也非常重要。如图7 所示,本类方法首先对输入表达式进行分解,然后分别计算视觉输入与分解后的每一部分表达式对应的注意力得分,最终将所有的注意力得分进行加权获得最终的视觉注意力得分,从而定位目标对象。

图7 基于表达式分解的融合方法模型结构图Fig.7 Model structure diagram of fusion method based on expression decomposition
Hu 等人(2017)提出了一个端到端的组合模块网络(compositional modular networks,CMNs),通过3 个软注意(soft attention)将表达式解析为主语、关系和宾语3 部分。然后利用定位模块对主语、宾语与图像的区域提议计算匹配得分,利用关系模块对关系与区域提议对计算匹配分数。最后选取两个模块的综合匹配得分最高的区域提议作为目标对象。
上述将表达式分解为三元组的方式过分简化了语言结构,可能会忽略语言中的其他重要信息。为此,Cirik 等人(2018)引入外部解析器以及语法树构建了GroundNet 模型。首先利用外部解析器构建指代表达式的语法树,然后将语法树显式映射到一个同结构的由神经模块组成的计算图(graph)上,该计算图自下而上地定义了目标对象的定位过程。Liu等人(2019a)则设计了一个神经模块树(neural module tree,NMTree)网络,该网络在表达式的依赖解析树(dependency parsing trees,DPT)(Chen和Manning,2014)中自下而上地积累区域置信度从而定位目标区域。NMTree 方法的动态组装以及端到端的训练策略使得模型性能相比GroundNet更加健壮,在Ref-COCOg(Mao等,2016)验证集上高出近10个百分点。
相比早期直接对整个文本进行编码,加入外部解析器对指代表达式进行细粒度解析的方式进一步提升了模型可解释性的同时,使得性能也得到了提升。如表1所示,CMNs 虽然采用弱监督的方式进行训练但是其性能仍旧优于早期的基线方法MMI;此外NMTree 通过引入外部解析器来对文本输入进行更加细粒度的解析,使模型性能达到81.21%。
2.1.4 基于图网络的融合
REC 任务的图像大多包含多个对象,此前的方法大多孤立地处理图像的所有区域提议,忽略了不同区域提议中对象之间的关系信息。现有很多工作表明通过提取文本以及图像中的实体、概念以及关系,并以图结构可视化的表示更有助于发现各实体内部的关系(Sheng等,2019,2020;Zhang等,2020b)。因此,在REC 领域也提出利用图(graph)建模对象之间的关系,其中节点表示对象,边表示对象间的关系。文本特征则用于计算各关系以及对象的注意力得分从而修正初始graph。最终的目标结果由graph中的对象视觉特征以及关系特征的注意力加权得分获得。具体模型结构如图8 所示,图中节点的颜色深浅对应对象的注意力得分,得分越低颜色越浅,边同理。
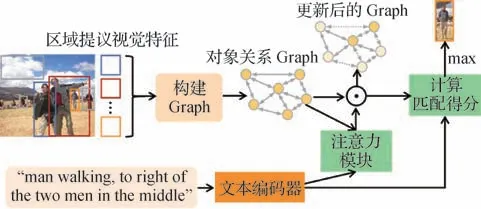
图8 基于图网络的融合方法模型结构图Fig.8 Model structure diagram of fusion method based on graph network
Wang 等人(2019b)提出了一种语言引导的图注意 网 络(language-guided graph attention network,LGRAN)利用图结构建模对象之间的关系。该网络由语言自注意模块、语言引导图注意模块和匹配模块3 个模块组成。语言自注意模块通过将表达式分解为主语、类内关系和类间关系3 部分构建文本表征。然后对输入图像的对象区域提议构造对象关系有向图,每个对象区域提议由对象、类间关系、类内关系3 种特征表示。语言引导图注意模块则通过联合视觉以及语言特征计算节点与边的注意得分。最后的匹配模块利用上述对象区域提议特征对所有的对象提议与指代表达式计算特征相似度。
类似地,Yang 等人(2019a)提出了一种动态图(dynamic graph attention,DGA)注意网络,通过对图像中对象之间的关系和表达式的语言结构进行建模来执行多步迭代推理。Yang 等人(2020b)则提出了一种场景图引导模块化网络(scene graph guided modular network,SGMN)分别将指代表达式和输入图像的对象区域提议都构建为图结构,然后在表达式图的指导下对区域提议图进行推理,计算各个节点的注意力权重,推理过程可以通过图注意力机制明确地解释。Pan 和Huang(2022)则构建了一个多层次交互网络SeMBI(semantic-aware multi-branch interaction),分别利用对象视觉特征、对象间关系信息、对象属性信息以三分支并行的方式构建了隐式关系图、显式关系图以及视觉属性图,从而实现对多级视觉特征的联合建模。
基于图网络的方法可以依据复杂的输入表达式对视觉特征进行推理,从而实现对目标对象的逐步定位。如表1 所示,基于图网络的DGA 方法的性能显著超过了所有同阶段的早期方法。
2.1.5 基于Transformer的融合
Transformer 在计算机视觉领域中的成功应用,体现了其内部注意力机制对视觉特征的强大建模能力(Liu 等,2021b;Chen 等,2020b;Yang 等,2020a;Chen 等,2020c)。此外,以Tokens 序列作为输入使得Transformer 可以兼容各种模态数据的处理(Xu等,2022)。基于以上优势,近年来很多REC 方法直接利用Transformer内部的注意力机制实现视觉—文本特征的融合,其输入是视觉以及文本Tokens 序列,其中视觉Tokens 的可以由1.2 节所述3 类视觉特征分别经过线性映射得到,文本Tokens 一般是输入文本的单词嵌入(embedding)。
现有REC 方法通过改变注意力层中的Q、K、V的输入内容将Transformer的原有自注意力机制改进为多模态融合注意力机制,其具体修改可以分为3类:1)相加融合;2)拼接融合;3)交叉融合。各类注意力机制如图9所示,其具体实现方法在表2中进行了总结。

图9 基于Transformer的多模态融合注意力的分类Fig.9 Classification of Transformer-based multimodal fusion attention mechanisms((a)summation fusion;(b)concatenation fusion;(c)cross fusion)

表2 基于Transformer的多模态融合方法总结Table 2 Summary of Transformer-based multimodal fusion methods
本类以区域卷积特征作为视觉表征的方法的视觉Tokens 由区域提议的卷积特征进过线性映射得到。代表方法有ViLBERT(vision and language BERT)(Lu 等,2019)和VL-BERT(visual-linguistic BERT)(Su 等,2020)。其 中,ViLBERT 采 用 双 流(dual-stream)结构:首先使用两个独立的Transformer 分支分别对视觉和文本输入进行特征提取;然后,将视觉、文本特征经过如图9(c)的交叉注意力层实现视觉—文本特征融合。其中,视觉分支采用Faster RCNN(Ren 等,2017)获取对象候选框的CNN 特征作为视觉Tokens;文本分支的Tokens 为单词嵌入。需要注意的是,ViLBERT 的交叉注意力的实现是将每个模态的键K 和值V 分别传给另一个模态的Q。该模型在成对的图像—文本数据上进行预训练后可以迁移到很多下游任务中,包括视觉问答、指代表达理解等。区别于ViLBERT,Su 等人(2020)提出的VL-BERT 方法则是使用一个单流(singlestream)框架,采用图9(b)的方法将视觉以及文本特征进行拼接(concatenate)之后共同输入到Transformer中进行多模态信息融合处理。如表1所示,上述两个模型的性能都要优于同类别的其他多模态融合方法,实现了在RefCOCO+验证集(val)上准确率达到72.34%以及72.59%。
综上,现有基于区域提议粒度视觉输入的REC方法通过加入注意力机制包括表达式解析器、图网络,有效挖掘了多模态特征之间的关键信息,模型性能提升了近20%,如表1所示。但此类方法仍存在一些问题:1)性能受到对图像生成的对象区域提议质量的影响;2)对于图像的每个区域提议都需要进行特征提取和相似度计算,因此存在大量额外的计算开销。
2.2 基于网格卷积粒度视觉表征的方法
基于网格卷积粒度视觉表征的REC 方法利用图像的整层卷积特征作为后续多模态特征融合模块的视觉输入。如图3(b)所示,此类方法无需预先生成图像的区域候选框,其直接利用输入图像的多层卷积特征分别与文本特征进行融合,模型直接输出目标定位结果。其对于文本数据的处理大多使用BERT 或者LSTM 将指代表达式直接编码为一个向量。此类基于网格卷积粒度特征的方法在获得与区域卷积粒度方法相近准确率的情况下有效实现了模型推理速度的提升。
2.2.1 基于滤波的融合
Yang 等人(2019b)首次提出基于区域卷积粒度视觉输入的方法生成区域提议需要耗费过多的计算量,因此其设计了一种直接采用图像的多级卷积特征作为视觉输入的端到端方法FAOA(fast and accurate one-stage approach)。其利用Darknet 网络(Redmon 和Farhadi,2018)获取图像的多级卷积特征与BERT 获取到的文本特征共同输入融合模块;融合模块首先将视觉文本特征在通道维度进行拼接,然后采用1 × 1 卷积核作为滤波器进行视觉文本特征融合;最终定位模块直接输出目标对象的边界框坐标。虽然FAOA 的模型性能没有超过同期的基于区域卷积粒度方法,但是如表3 所示,其推理速度达到了当时区域卷积粒度特征方法的10倍。
现有REC 方法也提出利用相关滤波(correlation filtering)根据文本信息对视觉特征进行过滤筛选。Liao 等人(2020)提出的实时跨模态相关滤波(real-time cross-modality correlation filtering,RCCF)方法,将REC 任务重新定义为跨模态模板匹配问题。RCCF 首先使用文本特征引导的滤波内核对视觉特征进行相关滤波,在图像中定位目标对象中心点;然后利用回归模块对目标对象的大小和中心点偏移进行预测。该方法在单个Titan Xp GPU 上的推理速度达到了实时的效果约为40 帧/s,约为基于区域卷积特征方法的12~16倍,如表3所示。
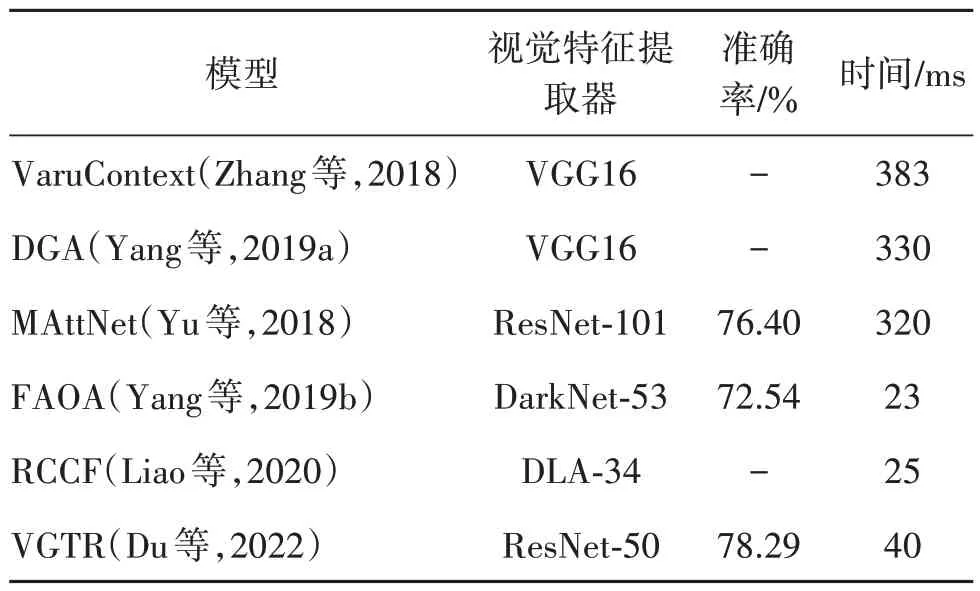
表3 部分REC方法的推理速度比较Table 3 Comparison of inference speed of partial REC methods
2.2.2 基于Transformer的融合
Jiang 等人(2020)最早在VQA 任务中提出将图像的网格卷积特征在空间维度上划分成多个块,将每个块进行线性映射后得到1 维特征作为Transformer 的编码器的输入。此类方法可以有效避免区域提议边界框生成所消耗的时间以及其产生的推理性能上限。
Deng等人(2021)设计的TransVG 采用类似ViLBERT 的双流架构,不同的是TransVG 的视觉分支的输入tokens 为图像网格卷积特征的1 维映射。视觉—文本特征的融合采用如图9(b)所示的拼接融合方式,将视觉和文本Transformer 的输入以及一个REG token 直接进行拼接作为多模态融合Transformer 层的输入。REG Token 对应的输出用于回归计算目标对象的边界框坐标。Du 等人(2022)提出的VGTR(visual grounding with Transformers)模型也采用网格特征划分Tokens 的方式,利用Transformer中的注意力机制进行跨模态特征融合。但是,不同于TransVG,VGTR 采用一种文本指导的视觉编码器,通过将文本编码器的V 传入到视觉编码器的Q中实现,类似图9(c)所示的交叉注意力结构。
视觉—语言联合预训练模型(vision-andlanguage pre-training,VLP)的提出为多模态理解任务提供了统一的处理框架,通过事先从大量对齐的视觉—文本数据中学习通用的多模态表征,然后在下游任务中微调后加以利用(Kamath 等,2021)从而实现了多模态理解任务性能的突破。其中最为代表性的是Wang 等人(2022)提出的多模态预训练全能模型OFA(one for all),分别对图片、文本和位置等数据设计了一种统一的离散化方式,将其全部转换为序列输入,从而利用统一的编码器—解码器架构实现对未知任务的不同模态数据的处理。OFA 采用Seq2Seq(sequence-to-sequence)方式,对于统一的输入,模型利用任务指令区分多种不同的任务。这种采用大规模数据预训练的方式使得OFA 模型在多个下游多模态任务中都取得了较好的性能,分别在视觉文本生成任务(image-to-text generation)以及视觉定位任务上达到了当前最优。如表1 所示,对REC 任务OFA 达到了RefCOCO 验证集上90.05%的准确率,并且Wang 等人(2022)还选取了一些与COCO 数据集图像风格差别较大的漫画图像进行实验,发现模型在此类图像上依旧可以准确定位。OFA在下游任务上的成功进一步预示着大规模多模态预训练模型在处理多模态任务上的优势,也成为今后多模态领域发展的一大趋势。
综上,以网格卷积粒度视觉特征为输入的方法在推理速度上相比区域卷积粒度特征方法有了极大提升。如表3 所示,FAOA 方法以及RCCF 方法是VaruContext 等区域卷积粒度特征的方法10 倍以上。在性能上,摒弃图像区域提议网络的性能局限,直接使用图像的全局特征作为视觉输入,在Transformer建模方法中相比ViLBERT 以及VL-BERT 模型性能提升了超过10%,如表1所示。
2.3 基于图像块粒度视觉表征的方法
前两类REC 方法在视觉特征提取模块的设计上都采用独立的预训练网络:以区域卷积粒度特征作为视觉输入的REC 方法大多采用在固定类别的数据集上预训练的目标检测器,例如Faster R-CNN等;网格卷积特征粒度的REC 方法则广泛采用预训练的图像分类网络,如ResNet(He 等,2016)等。因此,这种预训练的视觉特征提取网络可能无法适用于指代表达理解任务。ViT 模型的提出证明了:将图像块简单地进行线性映射变为1 维视觉向量作为Transformer的输入在图像分类任务中足够有效。受此启发,基于图像块粒度视觉表征的REC 方法的视觉文本融合模块的视觉输入直接采用图像块的1 维映射作为输入,实现了不依赖卷积网络以及目标检测网络的视觉特征提取。并且此类基于图像块粒度的REC 方法,其视觉—文本融合模块的都采用Transformer实现。
为了解决独立视觉特征处理模块导致的视觉特征与REC 任务不匹配的问题,Ye等人(2022)改进了原本独立的视觉特征提取模块,提出了QRNet(query-modulated refinement network)网络用于实现基于本文查询输入的视觉特征提取。QRNet 网络中的查询感知动态注意模块(query-aware dynamic attention)实现了基于文本特征指导的视觉特征细化提取。在视觉—文本特征融合模块,QRNet 采用如图9(b)所示的基于拼接融合注意力的Transformer。QRNet 的设计有效地避免了视觉特征提取与文本输入分离导致的视觉特征与REC 任务不匹配的问题。
同年,Deng 等人(2022)在之前TransVG 模型的基础上,提出了TransVG++模型用于改进TransVG训练难的问题。TransVG++删除了TransVG 中独立的多模态融合模块,对原有视觉编码器进行了改进,令其在实现视觉特征提取的同时进行多模态特征融合处理。该模型本质上是将基于图像块输入的视觉Transformer的最后一层修改为语言指导的视觉编码器。Deng 等人(2022)对文本—视觉融合编码层设计了两种不同的注意力方案,分别为language prompter 和language adapter。Language prompter 的注意力融合方案就是简单拼接方法,如图9(b)所示,将视觉、文本令牌拼接之后输入到多头自注意力层(multi-head self-attention,MHSA)中。Language adapter 则由一个视觉多头自注意层和一个交叉注意 层(multi-head cross-attention,MHCA)组 成:将MHSA 输出的视觉序列传入到MHCA 中作为Q 与文本特征表示的K、V 进行交叉注意力计算,然后将视觉以及文本输出直接相加后作为融合特征输出,该注意力机制的实现可以看成是对交叉融合以及相加融合的改进。Deng 等人(2022)的实验结果表明使用language adapter 的效果相比简单拼接的方式更优。TransVG++相比基于网格卷积视觉输入的TransVG 性能实现了大幅提升:分别在RefCOCO、RefCOCO+以及RefCOCOg 的验证集上提升了5.26%、10.57%和7.51%,如表1所示。
综上,基于图像块粒度视觉表征的方法将REC任务整体模型架构的简化成了纯Transformer 的结构,模型无需依赖预训练的卷积神经网络处理视觉输入。此类方法实现了模型架构更加简洁的同时,在性能上与采用区域卷积特征以及网格卷积特征作为视觉tokens 的Transformer 方法实现了提升,但是仍然以接近4%的差距略落后于多规模预训练的方法OFA,如表1所示。
3 数据集及评估指标
3.1 数据集
随着REC 研究的发展,相关数据集不断完善,本节列举了当前REC 任务的4 个主流数据集,并且在表4中对各数据集进行了比较。
ReferItGame(Kazemzadeh 等,2014)数据集的图像来源于ImageCLEF IAPR 图像检索数据集(Grubinger 等,2006)的20 000 幅图像以及SAIAPR TC-12(segmented and annotated IAPR-TC12)扩展数据集(Escalante 等,2010)的分割相关图像。指代表达式的收集采用Kazemzadeh 等人(2014)设计的双人游戏。由于该数据集中的图像很多只包含给定类别的一个对象,玩家普遍使用简短的语句进行描述,因而如表4 所示该数据集表达式的平均长度偏短。迄今为止,该游戏已经在19 894 幅自然场景照片中生成了一个包含130 525 个表达式的数据集,其中涉及96 654个不同的对象。
RefCOCOg(Mao 等,2016)数据集是在Amazon Mechanical Turk 的非交互式设置中收集的。一组工作人员负责为MS COCO(Lin 等,2014)图像中的对象编写指代表达式,另一组工作人员则需要点击图像中给定指代表达式的指代对象。如表4 所示,该数据集包含26 711 幅图像与85 474 个指代表达式,共计标注了54 822 个对象。RefCOCOg 中的每幅图像中都包含2—4 个同类别的物体,因此如表4 所示其表达式的平均长度较长。RefCOCOg 数据集有两种划分方式:第1 种将对象随机划分为训练集和验证集,验证集用于评估模型的性能,一般将该划分下的验证集表示为“val*”;第2种根据图像将数据集划分为训练集、测试集以及验证集,分别表示为表1 中的“train”、“test”和“val”。

表4 指代表达理解任务主流数据集特点总结Table 4 Summary of characteristics of mainstream datasets of referring expression comprehension
RefCOCO 和RefCOCO+(Yu 等,2016)这两个数据集是使用ReferitGame(Kazemzadeh 等,2014)收集的。如表4 所示,RefCOCO 数据集包含19 994 幅图像和142 209个指代表达式,共计标注了50 000个对象。RefCOCO+数据集不允许在指代表达式中使用位置词,指代表达式的表述纯粹基于目标对象的外观,这种要求使数据集的标注可以不受观察者视角的影响。RefCOCO+数据集则包含19 992幅图像,以及49 856 个对象的141 564 个指代表达式。这两个数据集被划分成训练集、验证集以及测试集A 和测试集B,分别表示为表1中的“train”、“val”、“testA”和“testB”。测试集A 由包含多个人实例的图像构成,测试集B 则由包含除人外的多个物体实例的图像组成。并且一张图像不会重复出现在训练集、测试集以及验证集中。如表4所示,RefCOCO 和RefCOCO+数据集中的表达式相对比较简短。
3.2 评估指标
REC 任务可以理解为一个特殊的目标检测任务,其目的是在图像中定位指代表达式描述的目标对象,因此该任务通常采用预测边界框与真实边界框的交并比(intersection over union,IoU)来衡量预测结果的正确性,计算为
式中,Rgt表示数据集中的人工标注框,Rpr表示算法预测的目标结果的边界框,S为两者的交并比。交并比大于0.5 的预测结果被判定是预测正确,否则判为预测错误。
最终利用交并比计算准确率(accuracy)作为衡量模型性能的指标。
4 挑战及未来发展方向
4.1 挑战
指代表达理解任务作为沟通自然语言处理以及计算机视觉两大领域的桥梁,实现了利用人类文本表述在物理世界的视觉数据中定位目标。该任务近几年受到越来越多的关注,也涌现出了诸多相关算法。但是,目前该领域的研究还面临一定的挑战以及困难,本文对其进行了简单总结:
1)模型的推理速度。REC 领域现有的研究大多关注如何提升模型的推理性能,但是在实际应用中,推理速度也是模型的一个非常重要的衡量指标。如表3 所示,现有基于区域卷积粒度视觉表征的方法因其需要预先生成图像的区域候选框,因此模型的推理速度非常慢。而基于网格卷积粒度视觉表征的方法则将模型的推理速度提升到了实时检测的效果。但是,基于网格卷积特征粒度的方法的性能还有待提高,未来REC 领域的发展需要在兼顾性能的同时尽可能地提升模型推理速度。
2)模型的可解释性。现有研究大多关注于视觉—文本特征融合模块的设计,忽略了模型的可解释性问题(Cirik 等,2018)。模型对于指代表达式中目标对象的描述与图像中的诸多对象的筛选、匹配过程是一个无法可视化的黑盒过程。已经有研究人员开始关注模型的可解释性问题,Deng 等人(2018)利用注意力模型输出指代表达式的各个部分对推理过程的重要程度得分,Cirik 等人(2018)则通过建立语法树以及图像中对象关系图之间节点的关联实现表达式各部分与图像中对象之间的一一对应,未来模型的发展应该向可解释的方向继续努力。
3)模型对表达式的推理能力。现有很多REC方法对表达式的理解仅停留在对象的属性层次,没有实现真正的推理,因此模型对长且复杂的表达式的处理结果不尽人意。此外,当前的主流数据集由于表达式通常较短且图像中的干扰对象较少而无法作为模型推理能力的评估依据(Chen 等,2020d)。目前已经提出了一些更复杂的数据集(Chen 等,2020d;Liu等,2019b)用于对模型的评估能力进行判定。Chen 等人(2020d)在新的数据集Cops-Ref 上对当前最先进的REC 模型进行了实验评估,观察到与传统的REC 任务数据集相比,模型的性能在新的数据集上显著下降。这也表明以往的大多数模型只是实现了在特定数据集上的过拟合,而没有学会真正的推理。因此,开发出具有真正的推理能力的REC模型是研究人员目前面临的重要挑战。
4.2 未来发展方向
本文通过结合现有的研究以及该任务目前面临的挑战,分别从模型设计以及领域发展两个层面对该领域未来发展进行了如下展望:
1)构建大规模预训练通用多模态模型。随着社会中越来越多的各种模态数据的产生,多模态任务相比传统的计算机视觉或者自然语言处理任务具有更广阔的发展前景。以往单一模态任务使用相关的预训练模型参数进行初始化已经成为了一种标准的操作,在有效节省模型和训练时间的同时也带来了更高的性能。因此,使用大规模视觉—语言模态的数据对通用的视觉—语言模型进行预训练,然后在多种下游任务中进行迁移是一种必然的发展趋势。
2)优化基于Transformer 的多模态特征融合方法。基于Transformer的多模态融合方法将成为一段时间内的主流。基于区域卷积粒度视觉表征的方法以及基于网格卷积粒度视觉表征的方法都在尝试使用Transformer中的多个注意力层实现两个模态之间的信息融合,实验效果也要优于此前手工设计的各种多模态融合方法。
3)采用多任务学习的方法提升性能。出现了一些将指代表达理解与指代表达分割或指代表达生成的任务联合学习的模型(Luo 等,2020;Sun 等,2022)。Luo 等人(2020)构建了一个REC 和RES 联合训练模型,与RES 相比REC 本身在目标定位上更有优势;而RES 可以为REC 提供更细粒度的像素级监督。Sun 等人(2022)则构建了一个统一的模型将REC 和REG(referring expression generation)任务合并,从而实现模型在两个任务模型之间的知识共享。Luo 等人(2020)与Sun 等人(2022)方法的实现表明这种多任务学习的方式可以有效实现单一任务的性能提升。
4)构建弱监督模型缓解对标注数据的依赖。全监督的学习方式依赖于输入指代表达式—图像—目标边界框之间的对应标注信息,此类数据集获取非常困难。因此,有效的弱监督模型通过输入未标注的指代表达式和图像,模型输出重建表达式,选取与原表达式距离最近的对象作为最终结果即可缓解模型对复杂标注数据的依赖,同时避免了因为人工标注错误导致的模型效果不理想的情况。
5)深入视频领域以及3D 领域的研究。研究人员开始将视觉定位任务扩展到视频领域(Vasudevan等,2018;Yamaguchi 等,2017)。视频时空定位任务由于缺少相应的边界框注释只能采用弱监督的方法,导致模型的性能不理想。因此,对于后续的视频定位任务的研究不仅需要完善相关的数据集,还需要探索如何在未对齐的视频片段与文本上实现视觉—语言的对应。在3D 空间对机器实现语言—视觉定位是一项非常有现实意义的任务。最近的一些工作(Chen等,2020a;Liu等,2021a)实现了将视觉定位任务扩展到3D 场景下,可以在3D 场景下定位自然语言表达式所指的对象,虽然这些方法取得了一定的成果,但是该领域的研究还需要更加深入,并且3D场景下的相关数据集也需要进一步完善。
5 结 语
指代表达理解作为视觉定位任务中的重要分支,通过在视觉数据中定位表达式指代的目标对象可以实现物理世界、机器与人类语言的有效连接,在现实世界中具有广阔的应用前景。本文从视觉数据的表征粒度出发将现有的REC 方法分为3 大类,包括最早出现的基于区域卷积粒度视觉表征的方法、基于网格卷积粒度视觉表征的方法以及基于图像块粒度视觉表征的方法,并且进一步按照多模态融合模块的设计进行了子类别划分。随着Transformer在计算机视觉任务中的成功应用,基于Transformer 的视觉—语言大规模预训练模型取得了当前最优的性能。最后对REC 领域研究目前面临的主要问题进行了总结,并且从多个角度对REC 未来的发展进行了展望。希望本文可以对该领域未来的模型设计和领域发展起到一定的启发。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2020年2期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
电子制作(2019年11期)2019-07-04
现代计算机(2019年6期)2019-04-08
北京航空航天大学学报(2018年1期)2018-04-20
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
电视技术(2014年19期)2014-03-11
