
基于一致性约束和标签优化的无监督域适应行人重识别
2023-05-20 07:36吴禹航桑农
中国图象图形学报 2023年5期
吴禹航,桑农
华中科技大学人工智能与自动化学院图像信息处理与智能控制教育部重点实验室,武汉 430074
0 引 言
随着经济和社会的发展,我国的视频监控和海量数据检索等计算机技术得到了飞速发展。通过对监控视频数据进行分析处理,可以检索出特定的行人,提升城市的治理水平。目前,由于安全城市和智慧城市的建设需要,视频监控的设备数量和数据规模迅速增加,使得依靠人力手动进行数据处理和行人检索的方法的成本和难度大幅提高,已经无法适应视频监控系统的更大规模推广。行人重识别(pedestrians’re-identification,Re-ID)是一项在视频监控系统中通过计算机视觉技术在监控视频数据中进行跨摄像头行人检索的技术。给定一幅由摄像头采集的待查询行人图像,行人重识别从其他摄像头采集的行人图像库里检索出属于该行人的所有图像。由于行人重识别主要依靠计算机算法程序自动检索,相比人工检索的方式,可以很大程度上减少视频监控系统中的人工成本和检索难度,具有重要的实际应用价值。
目前,在一个具有大量标注数据的应用场景(源域)下,基于深度学习的行人重识别算法(史维东等,2020;郑鑫 等,2020)可以使用有监督的方式训练一个模型,使该模型在该场景下能达到应用水平。然而,将这个模型直接应用目标域(即新的应用场景)上时,由于场景之间存在着领域偏移(domain shift),其在目标域上的性能会急剧下降。在实际应用中,仍存在着大量的目标域需要应用行人重识别以解决实际需求,然而为每个目标域人工标注训练数据费时费力,使得行人重识别的大规模推广受到限制。全面推广行人重识别,需要解决算法对目标域标注数据的依赖问题。使用目标检测算法(Ren等,2015;Tian等,2019)对目标域场景图像进行行人检测可以容易地得到大量无标注的行人图像。如何利用这些无标注数据来帮助模型在目标域取得良好性能成为了行人重识别领域在实际应用中亟待解决的问题。本文研究的无监督域适应行人重识别(unsupervised domain adaptive Re-ID,UDA Re-ID)算法旨在利用已有的有标记源域行人图像和无标记目标域行人图像训练模型,使模型在目标域上取得较好的泛化性能。相比于有监督训练的方法,无监督域适应的方法不需要额外的人工标注成本,具有更重要的实际意义。
现有无监督域适应行人重识别方法主要分为两类,即基于域转换的方法(Deng 等,2018;Wei 等,2018)和基于聚类的方法(Ge 等,2020b;Wu 等,2022)。基于域转换的方法通常借助生成对抗网络(generative adversarial network,GAN)(Goodfellow 等,2014)转换源域图像的风格到目标域,然后在源域标签的监督下,使用原始图像特征和风格转换后的图像特征计算损失函数并优化模型。为了提升风格转换的图像质量,保留相似性的生成对抗网络(similarity preserving GAN,SPGAN)引入语义分割来约束风格迁移过程中人体区域的一致性,行人转换生成对抗网络(person transfer GAN,PTGAN)(Wei等,2018)考虑了图像风格转换前后的自相似性,也考虑了目标域图像与转换后的源域图像之间的差异性。然而,这类方法生成的图像质量仍不够高。此外,真实场景的目标域风格复杂而多变,通过GAN 获得的生成图像并不能真正服从目标域的真实数据分布,对模型的学习帮助有限,使得这类方法难以取得较好的性能表现,所以目前学术界主要研究基于聚类的方法。基于聚类的方法,如自步学习网络(selfpaced contrastive learning,SpCL)(Ge 等,2020b)和多中心表征网络(multi-centroid representation network,MCRN)(Wu 等,2022),采用准备阶段和优化阶段的两阶段交替训练。在准备阶段(每个epoch 的初始时刻),这类方法使用聚类算法将无标记目标域训练样本聚类为若干簇,为每个簇分配一个one-hot 编码的伪标签。在优化阶段(每个epoch 的剩余时刻),这类方法将伪标签作为监督信号,计算损失函数并优化模型。这类方法取得了不错的效果,但存在一些问题有待改进。1)由于模型的表征能力有限,实例特征在训练过程中并不稳定(特别在网络训练的早期),现有方法常常使用数据增强策略学习一个鲁棒的特征,但很少从实例自身挖掘有用信息;2)同一行人在不同相机下拍摄的图像的特征存在较大差异,若不对其进行约束,模型对相机的变化不鲁棒,难以学习到一个类内紧凑性较好的特征空间;3)one-hot 编码的伪标签噪声过拟合问题。由于聚类的结果并不可靠,伪标签中存在噪声,即属于相同行人的实例可能被聚到不同簇中而被分配不同的伪标签,或者属于不同行人的实例被聚到同一个簇里而被分配相同的伪标签。在模型的训练过程中,使用这种one-hot 编码的伪标签作为特征学习(如对比学习)的监督信号容易使模型对噪声过拟合。
为此,本文提出了实例一致性约束、相机一致性约束和基于标签集成的标签优化这3 个模块,可以分别解决行人的实例特征不稳定问题、行人特征对相机变化的不鲁棒问题以及伪标签噪声的过拟合问题,并将这3 个模块用于基于聚类的方法MCRN(Wu 等,2022)中,得到具有一致性约束的多中心表征网络(multi-centroid representation network with consistency constraints,MCRNCC)。本文的主要贡献如下:1)针对行人的实例特征不稳定问题,在现有方法MCRN 的基础上,引入实例一致性约束。实例一致性约束通过约束同一实例在不同增广下的特征相近,从实例内部挖掘更丰富的信息,学习到更鲁棒的特征表达。2)针对行人特征对相机变化的不鲁棒问题,进一步引入相机一致性约束。相机一致性约束以跨相机的正样本对和同相机的负样本对构建难例三元组,提升了行人在不同相机下的特征稳定性。3)针对伪标签噪声的过拟合问题,引入了基于标签集成的标签优化。基于标签集成的标签优化引入了额外的标签估计,通过将多组额外的标签与聚类生成的one-hot 编码伪标签集成,减少了伪标签噪声的过拟合风险。
1 多中心表征网络
本文的基准网络MCRN(Wu 等,2022)的整个训练过程采用两阶段(准备阶段和优化阶段)交替进行的策略。
1.1 准备阶段


1.2 优化阶段
MCRN 在优化阶段的网络框架如图1 所示。在每个优化阶段(每个epoch 的剩余时间)的每次迭代(iteration)中,MCRN 首先分别从源域和目标域各采样B=P×K个查询样本构成训练批,其中P代表类别数,K代表每个类别的样本数,设置其等于每个类别的中心数。然后,对于每个训练批中的查询样本,MCRN 从多中心记忆体中的K个正类中心中,选择与查询样本中相似度排在中间的中心作为后续对比学习中的正样本,选择每个负类的K个负类中心的平均特征作为后续对比学习中的负样本。此外,MCRN使用二阶近邻插值为目标域的查询样本,生成λ个额外的难负样本{si,l|}。最后,MCRN使用域分离对比学习(domain-specific contrastive learning,DSCL)优化网络。具体为
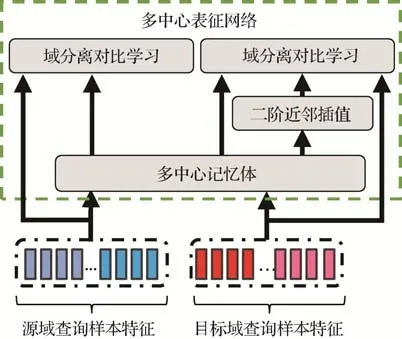
图1 MCRN框架(优化阶段)Fig.1 The framework of MCRN in optimization stage
式中,ns和nt分别为源域类别数和目标域簇数,和分别为源域训练批和目标域训练批的第i个查询样本,τ为温度系数。
在每次迭代结束后,MCRN 计算训练批中每个采样类别的K个查询样本和多中心记忆体中对应的K个正类中心之间的相似度,根据整体相似度最高的查询样本—正类中心对的排列σ^ 更新中心。具体为
式中,m为动量系数,cσ^(i)为处于排列σ^ 的第i个正类中心。
2 具有一致性约束的多中心表征网络
本文在基准网络的基础上,提出了具有一致性约束的多中心表征网络MCRNCC,其在优化阶段的网络框图如图2 所示,包含实例一致性约束、相机一致性约束和基于标签集成的标签优化等3 个模块。图2中sg代表中断梯度反传(stop gradient)。
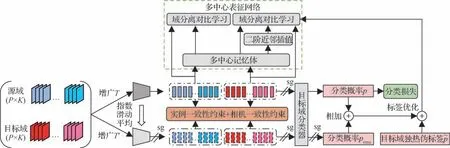
图2 MCRNCC框架(优化阶段)Fig.2 The framework of MCRNCC (optimization stage)
2.1 实例一致性约束
由于网络本身的表达能力有限,图像的实例特征在训练过程中并不稳定,尤其在网络训练的前期,目标在图像上的一点偏移也会在特征上产生波动。行人重识别任务中通常使用了随机擦除(Zhong 等,2020)、随机翻转和随机裁剪等数据增广策略提高特征的鲁棒性,但未从实例自身挖掘有用的信息。
基于自监督的表征学习研究(Chen 等,2020;He 等,2020;Grill 等,2020)通过挖掘实例内部信息以学习容易泛化到下游任务的特征表达。这些方法通常会将同一实例在不同增广下的多幅图像的特征构成实例级别的正样本对,然后通过损失函数约束正样本间的距离相近,以从实例内部挖掘语义信息。由于在自监督学习中没有额外的学习目标,仅使用正样本对的约束会导致网络塌陷。为了避免这一问题,SimCLR(simple framework for contrastive learning of visual representation)(Chen 等,2020)和MoCO(momentum contrast)(He 等,2020)等考虑了将不同实例的样本作为负样本,即同时考虑实例级别的正样本对和负样本对的约束。BYOL(bootstrap your own latent)(Grill等,2020)则引入了一个非对称映射头(多层感知机)以引入非对称性避免网络塌陷问题,这样就仅需考虑正样本对的约束。为了从实例正样本对内部挖掘语义信息,提升实例特征的稳定性,本文借鉴自监督方法,提出了实例一致性约束,并将其应用于MCRN网络中。与已有自监督学习方法不同的是,由于MCRN 的损失函数部分已经包含了区分类别级别的负样本对的部分,所以本文在不引入非对称映射头的条件下仅考虑实例级别正样本对的约束,也不会有网络坍塌的问题。
2.1.1 指数滑动平均模型
与MoCO和BYOL相同,引入了一个指数滑动平均(exponential moving average,EMA)模型Mema,该EMA模型Mema的参数θema不根据梯度优化,而是由原模型Mema的参数θ通过指数滑动平均得到,即
式中,φ是控制参数移动的超参数,通常设置为0.99。通过引入EMA 模型,可以得到两个参数不一样的网络,使得输出的特征具有多样性,同时EMA模型由于在时间上集成了不同时期的模型参数,相对于普通的模型,参数过渡得更平滑,性能通常更好,因此可以在测试阶段使用EMA模型进行测试。
2.1.2 实例一致性约束损失函数
实例一致性(instance consistency,IC)约束如图3 所示,将训练批中的实例(即查询样本)在不同增广下的特征距离进行约束,即实例I经增广T和T′后得到T(I)和T′(I),再分别经模型M和EMA 模型Mema后得到的特征q和qema的距离要小。具体的损失函数为
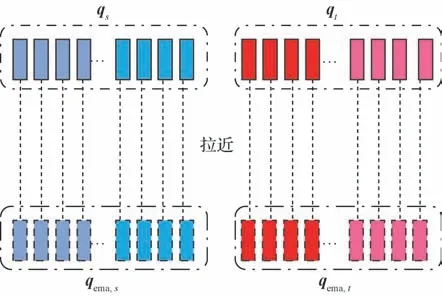
图3 实例一致性约束Fig.3 Instance consistency constraint
通过实例一致性约束,模型可以挖掘更丰富的语义信息,提升模型的性能,后续实验验证了实例一致性约束的有效性。
2.2 相机一致性约束
由于行人在不同相机下拍摄的图像往往存在较大的变化,这些差异由光照、遮挡、分辨率和视角等场景因素决定。此外,由于模型的表征能力有限,同一行人在不同相机下的实例特征可能相差较大,而不同行人在同一相机下的实例特征可能相差较小。为了提升行人特征对相机变化的鲁棒性,本文提出了相机一致性(camera consistency,CC)约束,即约束同一行人在不同相机下的实例特征距离近,而不同行人在同一相机下的实例特征距离远。
相机一致性约束依次选取当前训练批中模型M提取的实例特征作为锚点a,然后根据伪标签和相机标签,构建a的难样本三元组损失来优化网络。由于在实例一致性约束中,EMA 模型已经额外产生了训练批大小的特征,为了充分利用多样的特征,在构建三元组时,每个锚点a会按2 批次,分别从模型M的训练批同域特征集合{qi|1}中和EMA 模型Mema的训练批同域特征集合{ema|1}中构建一次三元组。图4 展示了一个锚点a构建难样本三元组的示例。锚点a的正样本选取为当前批次的特征集合中与锚点a伪标签相同、但相机标签不同的样本中距离最远的样本,而负样本选取为当前批次的特征集合中与锚点a标签不同、但相机标签相同的样本中距离最近的样本。若无法找到满足条件的正样本或负样本,则认为在这一批次中的这个锚点无效,放弃该三元组的构建。相机一致性约束的具体损失函数为

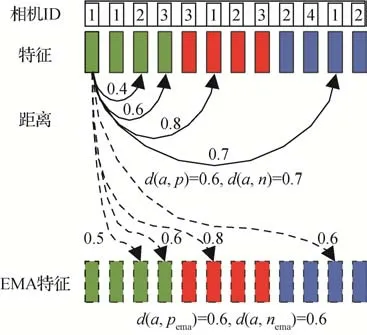
图4 相机一致性中的三元组示例Fig.4 An example of triplet in camera consistency

通过相机一致性约束同相机和跨相机下的行人的特征关系,可提升行人特征对相机变化的鲁棒性,并学习到一个具有良好类内紧凑性和类间可分性的特征空间。后续实验验证了相机一致性约束的有效性。
2.3 基于标签集成的标签优化
SpCL(Ge 等,2020b)和MCRN(Wu 等,2022)等方法使用了在目标域上聚类得到的one-hot 编码伪标签作为监督信号,指导模型通过对比学习(式(2))优化特征空间。正如前文所提及,由于模型的表征能力有限以及聚类算法的不完美,聚类生成的onehot编码伪标签中存在噪声,即一些属于不同行人的图像被赋予了相同的伪标签,而一些属于相同行人的图像被赋予了不同的伪标签。在网络训练过程中,模型的表征能力会不断提升,本可以自我矫正一部分聚类错误,但由于每个训练周期的监督信号是这个训练周期初期聚类得到的伪标签,模型仍会根据有噪声的监督信号继续拟合,从而阻止了模型的性能提升。为了减少模型对伪标签噪声的过度拟合,本文提出了一种基于标签集成(label ensemble,LE)的标签优化(label refinery,LR)方法,通过将多组预测标签与one-hot 编码的伪标签集成,使硬的one-hot 编码伪标签转化为鲁棒的软标签,进一步改善特征学习过程。
2.3.1 额外的预测标签
为了获得预测标签,一个自然的想法是引入一个新的分类器,用分类器的分类概率作为预测标签。这里分类器用一个去掉偏置向量的全连接(fully connected,FC)层实现,其权重可以看做是一组可学习的类中心。
由于分类器需要固定的类别数,而目标域的类别数是由每个训练周期的聚类结果决定,其在不同的训练周期数量不一样。为了解决这个问题,在每个训练周期聚类完成后重新生成一个分类器(分类数为簇的数量),然后用每个簇的均值初始化分类器的权重。
对于训练批中第i个目标域查询样本特征,其估计的标签为pi,具体为
式中,τ为温度系数,FC()为分类器输出。设置与对比学习中的温度系数一致。为了使分类器的权重能跟随网络训练的变化,分类器会通过一个交叉熵(cross entropy,CE)损失训练,其分类的监督信号为聚类得到的伪标签。具体为
2.3.2 标签优化
在得到将估计的两个预测标签后,求得它们的平均,再与查询样本的one-hot编码伪标签p~i相加后,求平均得到最终的标签。具体为
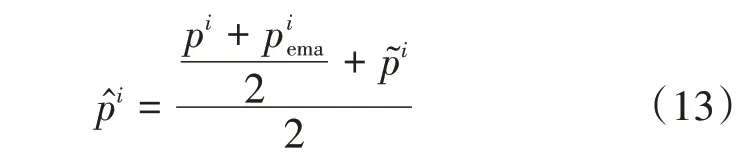
通过上述基于标签集成的标签优化方法,得到了鲁棒的软标签,减少了伪标签噪声的过拟合风险。在后续实验中,验证了该方法的有效性。
2.4 优化目标
网络最终的优化目标为
式中,LDSCL,Ds为源域域分离对比损失,LLR,Dt为标签优化过的目标域域分离对比损失,LIC,Ds和LIC,Dt为源域和目标域的实例一致性损失,LCC,Ds和LCC,Dt分别为源域和目标域的相机一致性损失,LCE为目标域分类器损失。
3 实验结果与分析
3.1 实验数据集与评估标准
实验所采用的数据集为Market-1501(Zheng 等,2015)、DukeMTMC-reID(Duke multi-tracking multicamera reIDentification)(Ristani等,2016)和MSMT17(multi-scene multi-time)(Wei 等,2018),并以一个数据集为源域(如Market),另一个数据集作为目标域(如Duke),构建域适应任务(如Market→Duke)。在目标域上测试的平均精度均值(mean average precision,mAP)和CMC(cumulative match characteristic)曲线的R1(rank-1)指标用来评价无监督域适应模型的性能。
3.2 实验设置
为了验证所提算法的有效性,在4 个常用的无监督域适应行人重识别(UDA Re-ID)任务,即Duke→Market、Market→Duke、Duke→MSMT 和Market→MSMT上进行实验,包括实例一致性约束、相机一致性约束和基于标签集成的标签优化的相关消融实验。除MCRNCC 中提出的模块外,实验的网络结构、训练过程和测试过程与MCRN保持一致。
3.2.1 网络结构
主干网络为在ImageNet(Deng 等,2009)上预训练过的ResNet-50(residual neural network)(He 等,2016),并使用DSBN(domain-specific batch normalization)(Chang 等,2019)缩小域之间的差异。主干网络将最后一层输出的特征图依次通过全局平均池化、批归一化和L2 归一化后得到的2 048 维特征作为行人的特征。
3.2.2 训练过程
在每个训练周期的准备阶段,采用DBSCAN 算法对目标域无标注图像聚类,并使用了自步学习(Ge等,2020b)改善聚类过程。
在每个训练周期的优化阶段,每个训练批由64 幅源域图像(16 个源域行人,每个行人4 幅图像)和64 幅目标域图像(16 个目标域簇,每个簇4 幅图像)构成。所有的训练图像会调整至256 × 128像素,并会通过多种数据增强策略对图像进行增广,包括随机裁剪、随机翻转和随机擦除(Zhong 等,2020)。总训练周期(epoch)数设置为50,每个训练周期的迭代次数在目标域为Market 和Duke 时设置为400,而在目标域为MSMT 时设置为800。采用Adam 优化器优化网络,权重衰减设置为0.000 5。初始学习率设置为0.000 35,每隔20 个训练周期衰减为原来的1/10。记忆体更新时的动量系数m设置为0.2,对比损失中的温度系数τ设置为0.05,λ设置为0.003 与目标域簇数的乘积。MCRNCC 的EMA 模型的控制参数移动的超参数φ设置为0.99,相机一致性约束的阈值γ设置为0.3。网络使用Pytorch 实现,并用4个NVIDIA RTX-2080TI GPU并行训练。
3.2.3 测试过程
在测试阶段,使用训练好的EMA 模型在目标域的测试集上测试,采用的评判标准为mAP和R1。在训练过程中,每隔5个训练周期测试一次,以mAP最高的模型的结果作为模型的性能表现。
3.3 消融实验
本文开展了关于实例一致性约束、相机一致性约束以及基于标签集成的标签优化方法的有效性的多组消融实验,其中不同消融实验方法中涉及的相同的损失函数权重保持一致。实验结果如表1 所示。从表1 可以看出,1)在实例一致性约束的有效性方面,在多个无监督域适应行人重识别任务上探究了行人的实例一致性(IC)约束的有效性。在MCRN 网络上,加入实例一致性约束后,性能有了普遍提升。在4 个任务上,实例一致性约束的mAP 性能分别提升了0.6%,0.2%,0.7%,0.8%,这是由于实例一致性约束通过拉近同一实例在不同增广下的特征,从实例内部挖掘了更丰富的语义信息,使得性能得到了提升。2)在相机一致性约束的有效性方面,探究了相机一致性(CC)的有效性。在加入实例一致性后,进一步加入相机一致性约束增广实例中跨相机的正样本的距离小于同相机的负样本距离,网络在4 个任务上性能有了进一步提升。其中,在Duke→MSMT和Market→MSMT上,mAP性能分别提升了3.5%和5.3%,R1 分别提升了3.2%和4.7%,这是因为MSMT 数据集有15 个相机,相机数目比较多,相机拍摄的图像间差异较大,通过相机一致性约束,可以很好地约束类内不同相机的距离,从而学习到一个更加紧凑的类内空间。3)在基于标签集成的标签优化的有效性方面,探究了基于标签集成的标签优化方法的有效性。在一致性约束的基础上进一步加入标签优化后,得到本文提出的完整网络MCRNCC,其在4 个任务上,mAP 分别提升了0.6%,0.6%,1.4%,0.4%,这是因为通过多组标签集成得到的软标签会在训练过程中反映模型的变化,比原来在每个训练周期中固定不变的one-hot 编码伪标签更鲁棒,可以减少模型对噪声的过度拟合。
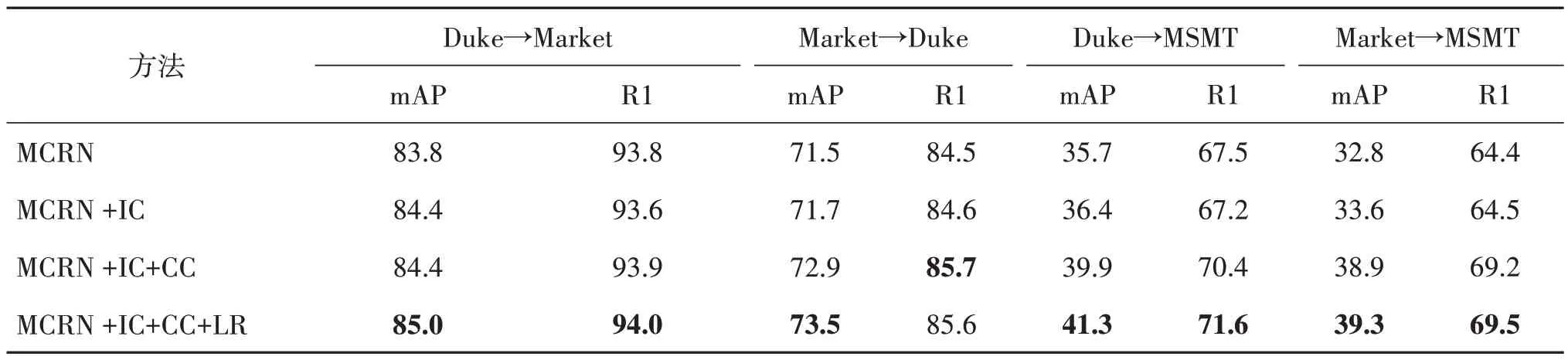
表1 MCRNCC中的消融实验Table 1 Ablation study on MCRNCC/%
本文将使用相机一致性约束前后的所有行人构成的特征空间进行了可视化,并在图5 中展示了多个不同行人的特征可视化对比示例,其中数字代表真实ID,不同颜色代表不同相机。由图5(a)(b)可以观察到,相机一致性约束使得相同行人在不同相机下的距离变近,而由图5(c)可以看到,相机一致性约束使得不同行人在相同相机下的特征距离变远。以上实验说明了相机一致性约束可以使网络的特征空间类内更加紧凑,类间更具可分性。
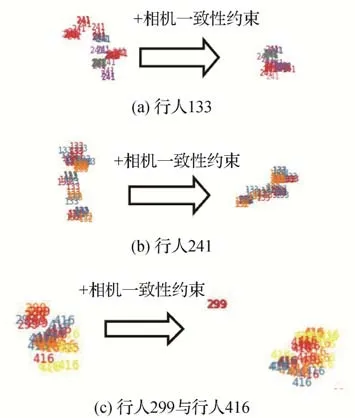
图5 相机一致性的有效性的可视化示例Fig.5 Visual examples of the effectiveness of camera consistency((a)pedestrian ID 133;(b)pedestrian ID 241;(c)pedestrian ID 299 and ID 416)
表2为标签集成(LE)的标签优化方式与传统的标签软化(label smooth,LS)的标签优化方法的比较结果。其中,LR(LE)代表基于标签集成的标签优化,LR(LS)代表基于标签软化的标签优化方法。这里的标签软化是将N维的one-hot标签中数值为1的维度的数值设置为0.8,将其他N- 1 维度的数值设置为0.8/(N- 1)。由实验结果可见,若用简单的标签软化进行伪标签的优化,性能反而变差,在Duke→Market 和Market→Duke 上的mAP 分别下降了0.6%和1.7%,R1 分别下降了0.3%和1.6%,进一步说明标签集成的标签优化方式的有效性。
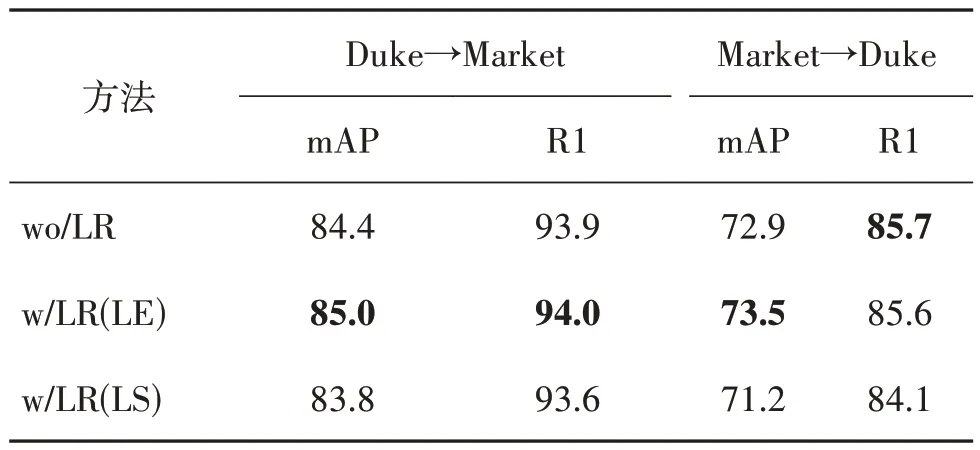
表2 不同标签优化方式的对比Table 2 The comparisons between different label refinery methods/%
3.4 与现有方法的对比
表3为基于MCRN 改进的MCRNCC 与现有的其他无监督域适应行人重识别方法在4 个任务上的性能比较结果。比较的方法包括MMT(mutual meanteaching)(Ge 等,2020a)、MEB-Net(multiple expert brainstorming)(Zhai 等,2020)、SpCL(Ge 等,2020b)、UNRN(uncertainty-guided noise resilient network)(Zheng 等,2021a)、GCL(generative and contrastive learning)(Chen 等,2021)、GLT(group-aware label transfer)(Zheng 等,2021b)、OPLG(online pseudo label generation)(Zheng 等,2021c)、IDM(intermediate domain module)(Dai等,2021)、TDRL(Isobe等,2021)和MCRN(Wu等,2022)。可以看出,MCRNCC在4个任务上都取得了最佳的性能,显著优于其他方法,mAP 分别为85.0%,73.5%,41.3%,39.3%;R1 分别为94.0%,85.6%,71.6%,69.5%。特别地,在Duke→MSMT 和Market→MSMT 任务上,与MCRN 相比,MCRNCC的mAP分别超越了5.6%和6.5%,R1分别超越了4.1%和5.1%。为了使学习过程更鲁棒,MMT使用了4个网络进行标签软化,MEB-Net使用了6个网络进行集成学习,而MCRNCC只使用了2个网络,并通过充分挖掘2个网络的特征进行实例一致性约束、相机一致性约束和基于标签集成的标签优化,取得了更好的性能。
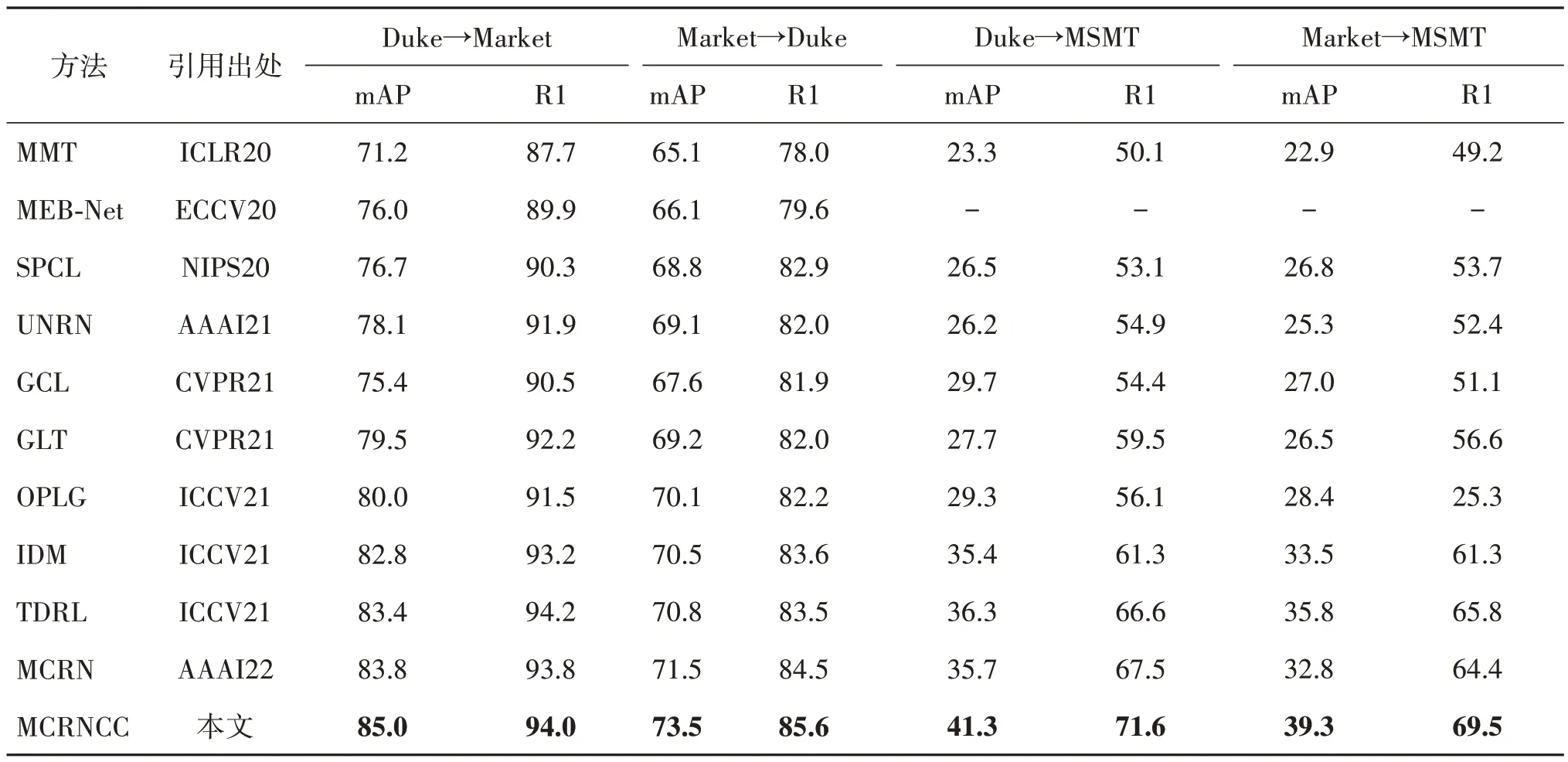
表3 与先进的 UDA Re-ID方法的比较Table 3 Comparison with state-of-the-art UDA Re-ID methods/%
4 结 论
针对无监督域适应行人重识别问题,本文提出一种具有一致性约束的方法MCRNCC。其中,设计了实例一致性约束、相机一致性约束和基于标签集成的标签优化方法等3 个模块,以分别解决现有方法中存在的行人实例特征不稳定问题、行人特征对相机变化的不鲁棒问题以及伪标签噪声的过拟合问题。实例一致性约束通过约束同一实例在不同增广下的特征相近,从实例内部挖掘丰富的信息,学习到更鲁棒的特征表达;相机一致性约束对跨相机的正样本对和同相机的负样本对构建难例三元组,提升了行人在不同相机下的特征稳定性;基于标签集成的标签优化引入了额外的伪标签估计,通过将标签估计与原来聚类生成的one-hot 编码伪标签集成,减少了伪标签噪声的过拟合风险。本文通过大量消融实验验证了MCRNCC 中各模块设计的有效性。与其他现有方法的比较表明MCRNCC 取得了先进的性能。
本文方法主要针对的是单源域的域适应问题,对于多个源域的域适应问题尚未探究。通常,由于源域之间存在域差异,将多个源域简单地一起训练并不能有效提升性能。而在实际应用中,已有很多标注好的源域数据集,这些丰富的数据集已经使用了大量的人力物力,如何充分利用这些数据集,将各个源域通用的知识有效地传递到目标域上,进一步提升模型的性能,具有非常高的实用价值。
猜你喜欢
公民与法治(2022年5期)2022-07-29
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
燕山大学学报(2015年4期)2015-12-25
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
上海理工大学学报(2012年2期)2012-03-20
