
面向跨模态文本到图像行人重识别的Transformer网络
2023-05-20 07:36姜定叶茫
中国图象图形学报 2023年5期
姜定,叶茫
武汉大学计算机学院,武汉 430072
0 引 言
文本到图像行人重识别(text-to-image person re-identification)是行人重识别和跨模态图像检索的子问题,旨在利用自然语言描述从大规模图像或视频库中检索最符合文本描述形容的行人,如图1 所示。相比于基于属性的行人重识别,文本描述需要的专业知识和先验知识更少,且可以提供比属性更全面的描述。此外,文本到图像行人重识别技术可以很好地弥补传统的基于图像的行人重识别技术至少需要一幅行人图像的局限性。

图1 文本到图像行人重识别示例Fig.1 Example of text-to-image person re-identification
自Li 等人(2017b)首次提出使用文本描述检索对应的行人图像以来,人们提出了许多探索文本到图像行人重识别任务的方法。虽然这些方法取得了一定成功,但是检索性能还不足以应对真实世界应用场景。造成文本到图像行人重识别任务检索准确率不高的主要原因是图像和文本两个模态之间的差异,由于图像和文本的表现形式不一致,两个模态的语义信息之间很难做到精准的细粒度匹配。而且现有方法的图像骨干网络都采用了卷积神经网络(convolutional neural network,CNN)结构,而CNN 的下采样操作会导致细粒度的特征丢失,从而影响跨模态的细粒度匹配。现有文本到图像行人重识别方法可以分成全局特征匹配和局部特征匹配两类。全局特征匹配方法主要集中在全局视觉和文本表征的学习上,通过优化目标将图像和文本特征映射到统一的特征空间。现有的全局特征匹配方法使用的CNN 和LSTM/GRU(long short-term memory/gated recurrent unit)骨干网络无法有效提取有辨识度的全局特征。近年来,在基于图像的行人重识别方法中,提出了越来越多的局部特征匹配方法(郑鑫 等,2020)。一些局部特征匹配的方法在全局特征的基础上,引入了额外的局部特征对行人图像和文本描述进行细粒度的匹配,这种局部特征匹配配合全局特征匹配可以取得一定的检索性能提升,但其中一些方法引入了额外的外部模型,如人体姿势估计、语义分割或自然语言工具包,带来了额外的计算花销和不确定性,并且使网络无法进行端到端的学习。局部特征匹配方法需要提取存储图像或文本全局特征和多个局部特征,检索时需计算全局和局部相似度,消耗了额外存储空间和计算时间,不利于模型的实际部署。缺乏足够的训练数据是文本到图像行人重识别任务长期以来面临的一大挑战,一直缺乏有效的解决方案。为了减轻缺乏数据造成的影响,现有方法通常使用在单一模态大规模数据集如ImageNet(Deng等,2009)上进行预训练的主干网络来增强模型的特征提取能力,例如ResNet(residual network)(He 等,2016)和BERT(bidirectional encoder representations from transformers)(Devlin 等,2019),但是这种基于单模态数据预训练的主干网络只能学习到图像或文本两个模态内部的信息,无法学习到图像文本跨模态匹配和语义对齐的信息。
针对上述文本到图像行人重识别领域面对的挑战,本文提出了一种仅使用全局特征的基于Transformer(Vaswani 等,2017)的双流文本到图像行人重识别框架。由于基于CNN 的算法无法挖掘长距离的关系,且会因为下采样操作丢失细粒度信息,因此本文算法采用Transformer作为视觉骨干网络。为了解决文本到图像行人重识别任务中缺少高质量标注数据的问题,本文使用了CLIP(contrastive languageimage pre-training)(Radford 等,2021)模型权重对主干网络参数进行初始化。CLIP是一个在包含4亿个图像文本对的WIT(WebImageText)数据集上训练得到的视觉语言预训练模型。相比使用在单一模态的大规模数据集上进行预训练的主干网络,使用CLIP能够利用预训练模型的图像文本跨模态匹配能力,从而获得更好的图像和文本语义表征。本文的主要贡献如下:1)提出一个端到端的双流Transformer 网络来学习文本到图像行人重识别任务中行人图像和描述文本的表征,仅使用全局特征就可以超过目前使用全局特征+局部特征的最先进算法。2)设计了一个温度缩放跨模态投影匹配(temperature-scaled cross modal projection matching,TCMPM)损失函数。在TCMPM 中,温度参数τ通过控制softmax 函数内跨模态投影数值的分布,使模型更新的重点聚焦到难分负样本上,并对它们施加相应的惩罚,从而使模型学习到更有区分度的图像文本特征。本文将温度参数τ设置为一个可学习参数,直接通过训练阶段进行更新,避免将其视为一个超参数进行手动调参。3)本文方法在CUHK-PEDES(CUHK person discription)(Li 等,2017b)和ICFG-PEDES(identity-centric and fine-grained person discription)(Ding 等,2021)数据集进行了大量实验,文本到图像的检索结果大幅领先目前的SOTA(state-of-the-art)模型。
1 相关工作
1.1 文本到图像行人重识别
Li 等人(2017b)第1 个提出文本到图像行人重识别这个任务,并提出了GNA-RNN(recurrent neural network with gated neural attention)框架,其包含了一个用于提取视觉特征的VGG-16(Visual Geometry Group 16-layer network)网络和一个用于提取文本特征的LSTM网络。Li等人(2017a)又提出了一个身份可知的两阶段网络架构,通过两阶段网络联合最小化图像和文本特征的身份间距离和跨模态距离。Zheng 等人(2020)提出了一个双路视觉CNN+文本CNN 网络架构,使用了标准的Ranking 损失函数和提出的Instance 损失函数来联合优化图像和文本特征。Zhang 和Lu(2018)提出了一个跨模态投影匹配损失和一个跨模态投影分类损失。Sarafianos 等人(2019)提出通过对抗性学习在一个共享空间中学习模态不变的视觉和文本表征。Han 等人(2021)设计了一个迁移学习方法从大规模粗粒度通用图像文本对数据集预训练的CLIP 模型中迁移知识,并设计了一个跨模态动量对比学习框架,更好地利用数据量有限的文本到图像行人重识别数据集。
还有一些方法采用了局部特征对齐的方法为全局特征对齐提供补充信息,学习图像区域与文本描述中的短语或单词之间的语义相关性。Aggarwal 等人(2020)从行人文本描述中自动抽取属性词作为行人图像属性识别的类别,通过学习到的属性空间局部特征和潜在空间全局特征共同完成检索,提出了一个基于姿态的多粒度注意网络。Jing 等人(2020)使用人类姿势估计工具分割出行人图像的人体局部特征,提出了一个由姿势指导的图像文本特征对齐网络。Wang 等人(2020)同时使用了自然语言分词和语义分割工具提取文本和图像局部特征,设计了一个跨模态对齐网络来匹配图像文本全局特征和属性局部特征。Chen 等人(2021)使用了在基于图像的行人重识别方法中流行的PCB(part-based convolutional baseline)(Sun 等,2018)策略进行局部特征提取,提出了一个多阶段跨模态匹配策略对双流网络中低层特征和高层特征进行多模态匹配,最后检索时只使用全局图像文本特征进行相似度计算。Ding等人(2021)收集了一个新的文本到图像行人重识别数据集ICFG-PEDES,基于非局部注意力机制提出了一个多视角非局部网络,学习人体各个部位之间的关系,检索时使用局部特征、非局部特征和全局特征一起计算相似度。
国内最早出现的文本到图像行人重识别研究是李晟嘉(2019)提出的基于注意力机制的跨模态融合行 人 检 索DSFA-Net(description-strengthened and fusion-attention network)。随后,霍昶伟(2020)提出了基于截断式注意力机制和堆叠损失函数的网络框架。王玉煜(2020)提出了一个多连接分类损失函数来优化模型。张鹏(2021)专注于设计有效的损失函数,提出了基于乘性角度余量的损失函数和基于样本对权重赋值的损失函数。殷雪朦(2021)为了实现细粒度的特征匹配,采用局部特征对齐方法,提出了一个结合全局和局部特征匹配的文本到图像行人重识别网络框架。
这些局部匹配方法有的需要使用额外的外部模型如人类姿势估计、语义分割或自然语言分词,带来了大量的计算复杂度且无法实现端到端训练。这些模型都采取了粗粒度全局特征加多个细粒度局部特征匹配的做法,大部分在实际检索阶段需要重复计算多次图像文本局部特征之间的相似度,这些方法由于过高的复杂度无法满足现实场景的要求。Han等人(2021)虽然设计了一个迁移学习和动量对比学习方法,从CLIP 预训练模型中转移跨模态对齐的知识,仅使用全局特征就超过现有的局部特征对齐方法,但是没有充分利用预训练模型的强大跨模态匹配知识。相比而言,本文提出的双路Transformer 网络方法简单又有效,并且能够进行端到端的训练,在检索时仅需计算全局特征余弦相似度即可快速从文本检索行人图像。
1.2 视觉语言预训练
基于Transformer 的大规模预训练语言模型BERT 在自然语言处理(natural language processing,NLP)领域取得了巨大成功。而在计算机视觉领域,预训练的大模型如ResNet 和ViT(vision Transformer)(Dosovitskiy 等,2021)也已广泛用做图像分类和分割等任务的骨干网络。受到NLP和计算机视觉中大规模预训练模型取得成功的启发,近年来视觉语言预训练(vision language pre-training,VLP)在多模态任务中成为了学习多模态表征的主流。在图文检索(Kiros 等,2014)和视觉回答(Antol 等,2015)等任务上取得了巨大成功。VLP模型结构可以分为单流结构和双流结构两种。单流模型采取单个Transformer 同时处理多模态输入,使用注意力机制来融合多模态特征。代表性工作有Oscar(Li 等,2020)和UNITER(universal image-text representation)(Chen 等,2020)等。双流模型使用单独的两个Transformer 分别提取图像和文本特征,两者之间权重不共享。虽然单流模型效果很好,但是单流模型的跨模态注意力机制在训练和推理时都不可避免地需要大量的计算时间。而双流模型所提取的图像文本特征在推理阶段仅需要简单的点乘计算余弦相似度,所以双流模型更适合图文检索任务。
本文方法在文本到图像行人重识别中引入了双流结构模型,在大规模图像文本对数据集上使用对比学习预训练的CLIP 模型,并设计了一个新的对比学习损失函数,使模型学到更强大的跨模态图像文本特征对齐能力,极大地减少了图像文本间的跨模态差异。
2 本文方法
本文提出了一个基于双流Transformer 的文本到图像行人重识别方法网络模型,整体框架如图2所示,实现了端到端的方式同时学习视觉和文本表征,且保证文本检索图像时的检索速度。与其他行人重识别方法一样,本文框架也由特征提取和监督学习两个阶段组成。特征提取阶段包括一个用于处理图像输入的视觉Transformer 和一个用于处理文本描述句子的文本Transformer。整个网络直接接受数据集中原始图像和文本描述对{Ii,Ti}1作为输入,其中,N表示小批量中图像文本对的个数,无需使用其他现有的图像分割模型或BRRT 模型对图像或文本进行预处理。相比现有方法,端到端的微调学习策略在学习跨模态对齐关系时更有优势。

图2 基于双流Transformer的文本到图像行人重识别方法框架图Fig.2 The framework of the proposed dual-stream Transformer baseline
2.1 视觉表征学习
本文采用了视觉Transformer(ViT)作为图像特征提取器。如图2 所示,给定一幅行人图像I∈RH×W×C,其中H,W,C分别表示图像的高度、宽度和通道数,将图像均分成N个16 × 16像素的不重叠的图像块{|i= 1,2,…,N}。之后将N个图像块通过一个线性投影层投影得到N个D维的图像块向量,并且在输入图像块向量序列前插入一个可学习的 [CLS]嵌入向量。为了学习到各图像块向量之间的相对位置关系,输入图像块向量序列会加上一个位置嵌入P∈R(N+1)×D。最终输入到ViT网络的图像块向量序列可以表示为
由于文本到图像行人重识别任务所使用数据集的图像分辨率和WIT数据集上原始图像的分辨率不匹配,预训练的CLIP的ViT模型中的位置嵌入不能直接导入。本文采用了TransReID(Transformer-based object re-identification)(He 等,2021)中使用的线性2D插值法来调整位置嵌入的尺寸以适应不同的图像分辨率。
2.2 文本表征学习
文本特征提取器是一个由Radford 等人(2019)修改过的12 层文本Transformer。与CLIP 中的文本特征提取器保持一致,输入的文本描述T,采用了词库为49 152 的小写字节对编码(byte pair encoding,BPE)(Sennrich 等,2016)进行分词和编码处理。如图2 所示,分词后的文本描述在开头和结尾分别插入了 [SOS]和 [EOS]嵌入向量来标识文本描述句子的开头和结尾。且为了保证计算效率,最大的文本描述序列长度设置为77。为了学习句子中的单词相对位置关系,位置嵌入P∈R77×D也会加到单词向量输入序列中。最终输入到文本Transformer的序列可以表示为

2.3 损失函数设计
为了最小化文本模态到图像模态之间的距离,受到跨模态投影匹配(cross-modal projection matching,CMPM)损 失(Zhang 和Lu,2018)和InfoNCE(information noise contrastive estimation)(van den Oord 等,2019)损失函数的启发,本文设计了一个温度缩放跨模态投影匹配(temperature-scaled cross modal projection matching,TCMPM)损失函数。给定一个由N个行人图像和描述文本表征向量对组成的小批量,对每个图像表征vi,这个小批量可以表示为,其中yi,j= 1 表示vi和tj属于同一个行人,yi,j= 0表示这个图像文本对不匹配。vi和tj匹配的概率可以定义为

式中,qi,j表示真实标签的分布概率,τ是和上面计算图像文本对投影值比率中共用的温度参数。相比原始的CMPM 损失函数使用的线性函数归一化方法,使用softmax 函数这种非线性的归一化方法可以起到标签平滑的作用。
通过计算图像到文本的投影概率和真实匹配概率的KL(Kullback-Leibler)散度,可以得到一个小批量的图像到文本的匹配损失函数,具体为
式中,ε是一个非常小的数用来防止出现数值溢出问题。通过最小化KL(pi‖qi),可以使pi分布曲线的形状接近qi分布曲线的形状,从而使匹配的图像文本对的投影值最大,不匹配的图像文本对投影值最小。
图像到文本的匹配损失函数LI2T在图像模态到文本模态的这个方向上拉近视觉表征与其匹配的文本表征之间的距离。在一般的图像文本表征学习过程中,图像文本匹配函数需要考虑两个方向。由于损失函数的对称性,通过计算文本表征到图像表征上的投影,拉近文本表征与其匹配的视觉表征之间距离的文本到图像匹配损失LT2I可以通过将式(3)中的v和t交换后代入式(5)进行计算。最后,双向的TCMPM损失函数可以表示为
3 实 验
3.1 数据集
CUHK-PEDES 数据集包含13 003 个行人的40 206 幅图像和80 440 个文本描述,大部分图像都有两个文本描述。每个文本描述中平均单词长度为23.5,最大单词长度为96,最小单词长度为12。数据集划分为训练集、验证集和测试集。训练集包括11 003 个行人的34 054 幅图像和68 126 个文本描述。测试集包含1 000 个行人的3 074 幅图像和6 156个文本描述,剩下的属于验证集。测试集的文本描述和行人图像分别作为查询集和图像库。
ICFG-PEDES数据集包含4 102个行人的54 522幅图像描述文本对,即每幅图像有一个对应的文本描述。ICFG-PEDES 中所有的图像来源于MSMT17(multi-scene multi-time)(Wei 等,2018)数据集。数据集划分为训练集和测试集。训练集包含3 102 个行人的34 674 个图像文本对,测试集包含剩下的1 000个行人的19 848个图像文本对。
3.2 评估指标
本文遵循文本到图像行人重识别的标准评估指标,通过Rank-K(K= 1,5,10)准确率来评估模型性能。具体来说,给定一个文本描述的查询,计算图库中所有图像与这个文本描述的相似度,然后根据相似度值进行排序。Rank-K是指真实匹配图像在相似度排序表中出现在前K个的概率。
3.3 实现细节
在实验中,遵循文本到图像行人重识别工作的实验设置(Han 等,2021),所有的行人图像分辨率都重新调整到384 × 128 像素,并且在训练阶段使用了随机水平翻转、随机裁剪和随机擦除的图像数据增广方法。最大文本长度设置为77。视觉表征向量fv与文本表征向量ft的维度为512。使用Adam优化器进行模型优化,基础学习率为1E-5,权重衰减为4E-5。模型训练60 轮,在开始的5 轮中采用warmup 策略使学习率从1E-6 线性增长到1E-5。学习率在20~50 轮中每10 轮衰减为原值的0.1。LTCMPM中的τ和ε的初始值分别设置为0.07和1E-8。
所有实验均在单张NVIDIA GeForce RTX 3090 GPU 上进行,使用了Pytorch 深度学习平台进行半精度训练。视觉Transformer和文本Transformer的初始化使用了CLIP(ViT-B/16)预训练模型。
3.4 实验结果分析
3.4.1 定量分析
表1 和表2 给出了本文算法和现有的文本到图像行人重识别算法的在CUHK-PEDES 数据集和ICFG-PEDES 数据集上的实验结果。表中列出的所有算法结果都没有包括使用重排序在内的后处理方法。所有的仅使用全局特征匹配的方法在表格的类型列中标注为“G”,使用了局部特征匹配的方法则标注为“L”。此外,表中特征维度标注了算法所使用的特征维度大小。
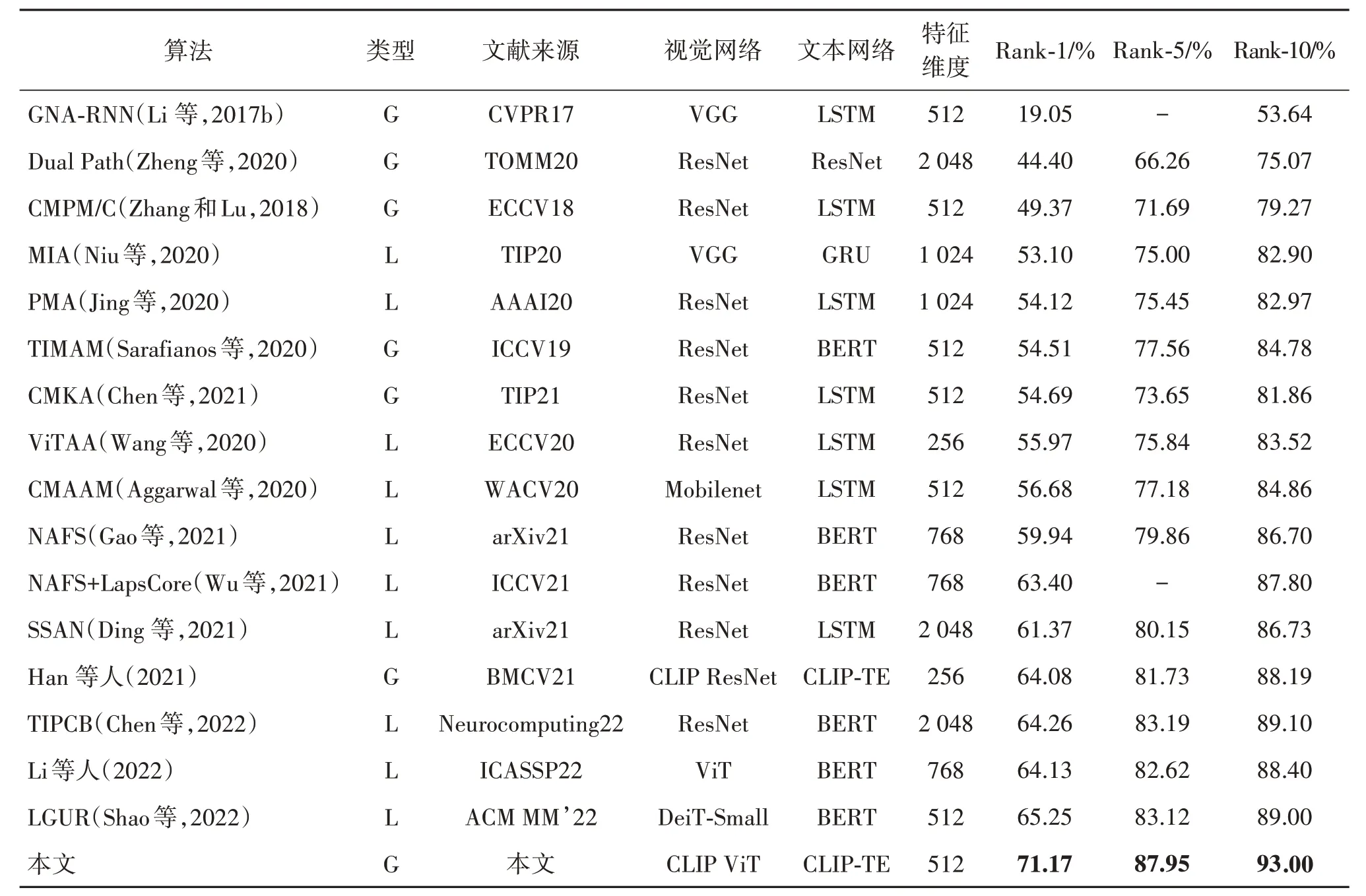
表1 本文算法与其他文本到图像行人重识别算法在CUHK-PEDES数据集上的实验结果对比Table 1 Comparison with state-of-the-art text-to-image Re-ID methods on CUHK-PEDES dataset

表2 本文算法与其他文本到图像行人重识别算法在ICFG-PEDES数据集上的实验结果对比Table 2 Comparison with state-of-the-art text-to-image Re-ID methods on ICFG-PEDES dataset
从表1 可以看出,文本到图像行人重识别的关注重点在于使用局部特征匹配,并且取得了相对较好的性能,但是也可以看出局部特征匹配方法已经处于瓶颈期。在CUHK-PEDES 数据集上,本文算法大幅超过了现有的文本到图像行人重识别方法,特别是对于最重要的指标Rank-1 来说,本文算法相比现有最好的局部匹配方法和全局匹配方法分别提升了5.92%和7.09%。在ICFG-PEDES 数据集上,本文算法也取得了同样的检索性能提升。相比目前最好的局部特征匹配方法提升了1.21%。
除了优越的检索性能,本文算法由于仅使用了全局特征匹配和较小的特征维度,相比现有的局部特征匹配方法,在训练效率、检索效率和离线特征存储方面均有巨大优势。
3.4.2 消融实验
为了验证本文提出的温度缩放跨模态投影匹配(TCMPM)损失函数的有效性,在CUHK-PEDES 和ICFG-PEDES 数据集上进行验证TCMPM 有效性的消融实验,对比完整的TCMPM、原始的CMPM、原始的CMPM + CMPC(cross-modal projection classification)、在原始的CMPM 中的softmax 中加入温度参数、多模态自监督学习中常使用的infoNCE 这5组损失函数,并且加入了不使用损失函数的CLIP 预训练模型做零样本学习(无损失函数)的对照组。
表3 给出了在CUHK-PEDES 和ICFG-PEDES 数据集上进行消融实验的结果。可以看出,相比原始的CMPM 损失函数,使用其他3 种加入温度参数的损失函数可以显著提升模型的跨模态特征匹配能力,从而大幅增强文本到图像的检索能力。为了更好地分析温度参数的作用,图3 给出了可学习的温度参数随着训练轮数的变化曲线。可以看出,温度参数τ从初始值0.07 开始的20 轮中快速增长并在20轮之后趋于稳定。

图3 温度参数τ随训练轮数变化图Fig.3 The temperature τcurve with training epoch
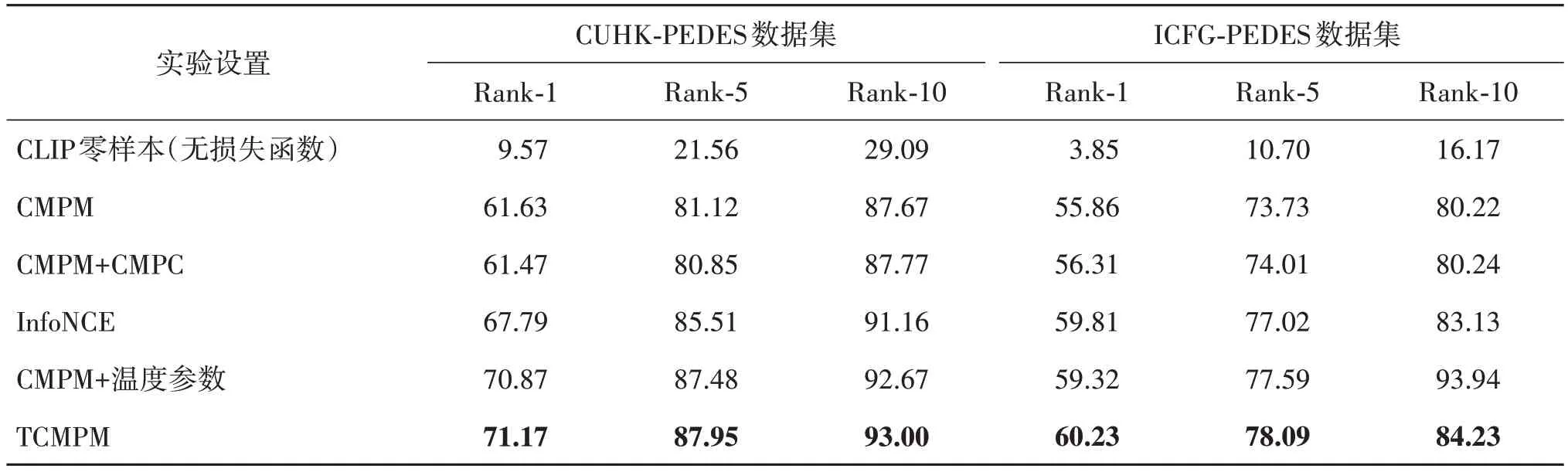
表3 不同损失函数的消融实验结果对比Table 3 Comparison results of different loss ablation studies/%
CLIP零样本在CUHK-PEDES和ICFG-PEDES数据集上的文本到图像检索结果不理想,但是经过使用和CLIP训练时一样的infoNCE 损失函数进行微调之后的效果已经超过了现有的所有文本到图像行人重识别方法,说明了文本到图像行人重识别这种细粒度的检索任务也可以有效地从CLIP这种通用图像文本跨模态大模型中迁移图像文本跨模态对齐知识。
为了验证本文算法在不同特征提取能力的视觉骨干网络中的效果,在CUHK-PEDES 数据集上进行CLIP ResNet50,CLIP ResNet101,CLIP ViT-B/32,CLIP ViT-B/16这4个特征提取能力越来越强的视觉骨干网络的消融实验,结果如表4 所示。可以看出,在使用同等特征提取能力的视觉骨干网络时,本文算法已经超过Han 等人(2021)方法,并且在方法简洁性上更是远超目前所有文本到图像行人重识别方法。随着视觉骨干网络的特征提取能力增强,本文算法在文本到图像检索的Rank-1,Rank-5,Rank-10值都有提升。

表4 不同视觉骨干网络消融实验结果对比Table 4 Comparison results of ablation studies/%
3.4.3 定性分析
图4展示了本文算法在CUHK-PEDES测试集上文本到图像检索的可视化结果。图4 左边为输入的文本描述,右边为根据相似度从高到低排序检索出的行人图像。黑色边框为真实标签图像,绿色边框为检索出的正确匹配的行人图像,红色边框为检索出的不正确匹配的行人图像。从图4 第1 行的结果可以看出,本文算法成功检索出了满足“black and white striped top”、“khaki pants”和“black backpack”条件的行人图像,且在检索出所有的正确匹配行人后,检索出了满足这些条件的其他行人的图像。第2 行的检索结果也满足了其文本查询的“tan coat with a hood”、“black backpack”、“jeans”和“white sneakers”条件,成功检索出了正确匹配的行人图像。证明了本文算法可以利用文本描述中的细粒度信息检索出符合描述的目标行人图像。第3、4 行是同一个行人图像标注的不同的两个文本描述的检索结果。第3行是一个失败检索案例,从第3行的文本描述的属性可以看出,描述都是很粗粒度的形容短语,文本描述过于模糊。第3 行的检索结果虽然都符合文本描述,但是文本描述不具备独特性,无法准确地匹配目标行人图像。而第4 行的文本描述标注相比第3行有着更细粒度的属性信息,使用第4行的文本描述进行检索,能够检索出正确匹配的行人图像。从图4 可以得到两个结论:1)本文算法可以区分给定文本查询中的细粒度属性信息并匹配到具体的图像信息。2)当文本描述信息比较模糊时,本文方法仍然可以给出符合文本描述的结果。

图4 本文提出的文本到图像行人重识别算法检索结果可视化图Fig.4 Visualization of text-to-image person re-identification results by our method
4 结 论
本文提出一种新的文本到图像行人重识别方法,从通用图像文本对数据集大规模预训练的CLIP模型中迁移通用跨模态特征对齐能力,弥补了文本到图像行人重识别可使用数据不足的问题。同时本文融合了CMPM 和infoNCE 损失函数的优点,提出了TCMPM 损失函数来更好地对齐图像文本特征到共有特征空间。本文算法在两个公开的平均数据集上与现有的先进方法LGUR(learning granularityunified representations)相比都有明显提升,在CUHK-PEDES 和ICFG-PEDES 数据集上的Rank-1值分别提升了5.92%和1.21%。此外,最近的文本到图像行人重识别方法都采取了手动分割多个局部图像和文本特征进行多层次匹配的做法,这种做法虽然会带来一定的性能提升,但也会破坏模态内信息的完整性,并且多层次匹配会降低检索速度。本文算法采用全局特征匹配,仅采用强大的特征提取骨干网络和设计的TCMPM 损失函数,就超越了近年的局部匹配方法,成为新的先进的文本到图像行人重识别方法。在两个数据集上文本方法优秀的检索准确率充分证明了本文方法的有效性。值得注意的是,本文工作采取Transformer作为骨干网络,因此无法采用近期行人重识别领域流行的基于CNN 的局部特征匹配策略,未考虑在细粒度的跨模态特征上进行对齐。因此,设计一种细粒度的基于Transformer 局部特征匹配文本到图像行人重识别方法,使模型可以更精准地对齐图像和文本模态之间的细粒度特征,将是文本到图像行人重识别的主要研究方向之一。
猜你喜欢
意林(2021年5期)2021-04-18
意林图解作文(小学版)(2019年6期)2019-07-16
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
专利代理(2016年1期)2016-05-17
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
上海理工大学学报(2012年2期)2012-03-20
质量与标准化(2010年5期)2010-05-03
