
融合虹膜—眼周特征的非协作身份认证
2023-05-20 07:36陈英吴文强徐亮郭书斌
中国图象图形学报 2023年5期
陈英,吴文强,徐亮,郭书斌
南昌航空大学软件学院,南昌 330063
0 引 言
随着计算机技术理论的不断发展和计算机算力的逐步提升,人工智能技术迅猛发展,并在生物识别领域取得十分优越的表现。生物特征识别是指通过判别个体之间的生理特征和行为特征的差异性进行身份标识的有效方式(孙哲南 等,2021)。虹膜是生物特征中备受关注的模态之一,相比于其他生物识别技术,虹膜识别突出的优势是唯一性、稳定性和非接触性(Lumini 和Nanni,2017)。因此,虹膜识别吸引了各界的广泛关注,并逐年发展壮大且走向成熟,已经部署和应用在国防、金融管理、智慧安防和智能家居等诸多领域(Nirgude和Gengaje,2022)。
Daugman(1993)最早使用Gabor 滤波器对归一化后的虹膜图像进行编码,并转化为相应的相位信息,然后利用二值化转化为可以用于匹配的特征模板IrisCode,最后通过计算特征模板之间的汉明距离进行匹配验证身份信息,该工作奠定了虹膜识别早期研究的基础,有着十分重要的意义。Monro 等人(2007)使用离散余弦对归一化后的虹膜图像进行编码,有效解决了在特征编码中橡胶模型产生的图像重叠块问题。Kumar 和Passi(2010)提出联合使用Haar小波和Log-Gabor滤波器对虹膜图像相位编码,能够有效提升虹膜识别的性能。随着计算机的计算能力几何倍数地增长,越来越多的识别任务更加青睐采用深度学习的方法。Liu 等人(2016)提出使用深度学习的方法挖掘虹膜图像对之间的映射关系,并通过多个成对滤波衡量图像的相似度。Zhao 和Kumar(2017a)设计了基于卷积神经网络的轻量型网络,并提供了基于深度学习的虹膜检测、分割和识别的框架UniNet(Zhao 和Kumar,2019),具有十分重要的意义。Zhao 和Kumar(2018)提出基于卷积神经网络的模型,引入注意力模块使网络能够更多关注眼周图像中重要区域,通过额外的语义区域能够学到更多判别特征,在一定程度上增强了模型的鲁棒性。为了提高非约束环境中虹膜识别的性能,Chen等人(2021b)提出使用基于动态路径搜索的虹膜分割非归一化预处理方法,并采用基于部分卷积算子的深度卷积网络提取虹膜纹理的特征,增强了虹膜识别在复杂场景下的可靠性。Choudhary 等人(2020)提出了3 种基于卷积和残差块集合的模型,取得了不错的效果。Chen 等人(2021a)提出一种基于稠密连接与注意力机制网络对无分割的虹膜图像进行特征提取,取得了令人满意的效果。Yang 等人(2021)提出了基于双空间注意力机制的虹膜识别算法,通过编码器和解码器结构生成多维空间的特征表示,有效提升了低质虹膜图像的识别性能。在虹膜领域的其他研究方向,张志礼等人(2022)通过引入区域注意力机制对虹膜的遮掩部分进行补全以丰富虹膜特征。刘明康等人(2020)提出通过增强虹膜图像的灰度空间进行人体活体检测。王雅丽等人(2018)使用深度学习的方式对虹膜图像进行粗特征提取,然后采用高斯混合模型提取Fisher 向量,并作为最终的虹膜特征表达,以验证使用虹膜图像进行人种分类的可行性。
目前,虹膜识别技术已经在多数场景取得了令人满意的表现,但在远距离、非协作场景下的应用仍然面临较大的局限性。首先,虹膜识别需要受试者站在与传感器相对较近的距离并在相应的提示下密切配合传感完成身份认证,这种限制性和不友好性的采集过程对于大规模的应用部署有很大的局限性。其次,虹膜识别的可靠性受传感器和虹膜之间的距离影响较大,随着传感器与虹膜采集距离的不断增大,虹膜图像质量显著下降,导致虹膜识别效果不佳(Nguyen等,2017)。
为了提高远距离、非限制场景下低质图像的虹膜识别性能,一种有效的方式是使用多种生物特征辅助虹膜识别完成可靠的身份认证(Raffei 等,2019)。毫无疑问,融合多种模态的生物特征信息较基于单一模态的识别显然更有优势。首先,尽管人体自身有多种生物特征,但每种生物特征由于其自身的特点在特定的应用场景中具备独特的优势和劣势,任何一种生物特征都无法适应所有的应用场景,在这种情况下,基于多种模态的生物特征识别能够有效利用各自的优势进行互补以克服其自身缺陷的不足。其次,每个人独特的生物特征是由其自身的生理特征因素随机决定的,例如基因,外部因素的变化无法改变其自身的特征,当存储的生物特征信息遭遇信息泄露时,将面临巨大的风险,安全的认证方式将无法得到有效保障。事实上,在生物特征识别领域,使用多种模态信息进行融合识别已经是大多数人普遍采用的方式。例如,徐硕等人(2022)融合人体的外观特征和姿态特征,不仅能够捕获更丰富的步态特征,而且能够在一定程度上降低因外观特征对步态识别产生的影响。谭等泰等人(2020)通过多种方式融合视频中的高频信息和低频信息,提高了行为识别的可靠精度。
值得注意的是,根据实际场景的需要选择合适的模态和融合方式对虹膜识别具有十分重要的意义。在人脸的眼睛区域中包含丰富的生物特征信息,例如虹膜和眼周(Algashaam 等,2021)。眼周特指眼睛周围的区域,包括眼睑、睫毛、瞳孔等部位(Smereka 等,2015),传感器可以同时捕获眼周图像与虹膜图像,无需进行二次操作。所以,非限制条件下的眼周识别逐渐成为一种颇具热点的生物特征识别方式,相关的研究工作已经证实眼周区域丰富的语义信息具备较好的可辨识性,可以用于身份标识。Park等人(2009)研究了使用纹理点算子方法提取眼周区域全局和局部的特征信息,从而产生可用于匹配的特征集,验证了使用个人眼周图像进行身份认证的可行性,奠定了眼周识别的研究基础。Nie等人(2014)提出使用生成随机神经网络—受限波尔兹曼机(convolutional restricted Boltzmann machines,CRBM)提取眼周图像的语义特征,不仅可以学习输入集的概率分布,而且在适应图像大小的同时降低了计算复杂度。Zhao 和Kumar(2017b)提出使用语义辅助卷积神经网络SCNN(spatial convolutional neural network)提取在较少约束的环境下自动捕获的眼周图像的纹理特征,该网络结合显式语义信息自动恢复全局眼周特征,实现了在相对较少数量的训练样本条件下卓越的匹配精度。Proenca 和Neves(2018)提出使用不同来源的虹膜增强眼周图像的抗干扰性,并使用卷积神经网络对增强后的眼周图像进行训练,使网络在训练过程中降低对虹膜特征的依赖,取得了较为满意的结果。Talreja 等人(2022)提出基于属性的深度眼周识别框架(attribute-based deep periocular recognition,ADPR),将预测的软生物特征和眼周特征融合在一起,提高了整体非约束下眼周识别的性能。Brito 和Proença(2021)提出了一个眼周识别框架,在提取眼周图像特征的同时,能够提供支持决策的特征域的视觉表达,有效解决了解释不匹配问题。Mishra 等人(2022)提出使用thermo-visible 特征和集合子空间网络分类器来改进现有的虹膜识别系统,提高了单一模态眼周识别的精准度。Vyas(2022)旨在通过结合手动特征和基于深度学习的特征表示来增强近红外眼周图像的表示,增强眼周识别的可靠性和稳定性。
尽管眼周识别已经取得了显著效果,但是眼周识别容易受到复杂背景信息的干扰,性能的稳定性无法保障,虹膜纹理特征比较稳定,对虹膜识别的影响力有限。此外,由于景深窄、用户移动不合作以及曝光时间不协调等因素的影响,传感器采集的虹膜纹理图像受噪音影响,图像质量较差,而眼周图像不容易受到上述因素的影响。综上所述,通过融合虹膜与眼周特征的方式能够做到模态之间的优势互补,在非限制性、远距离场景下实现准确、稳定的身份验证。
Tan 和Kumar(2013)加权融合眼周和虹膜的匹配得分,有效提高了远距离、非理想虹膜图像的识别精度。Santos 等人(2015)采用的融合策略与Tan 和Kumar(2013)的方法相类似,与其不同之处是,眼周和虹膜匹配得分的权重由两层神经网络学习得到,该方法在一定程度上提高了移动跨传感器的识别性能。Ahuja 等人(2016)分别采用ROOT SIFI 和基于深度学习的方法生成虹膜和眼周的特征表示,并计算特征向量之间的欧几里得距离和余弦距离,确定图像之间的相似度,得到匹配得分,最后采用平均值和线性回归方法对匹配分数融合。Verma 等人(2016)利用随机决策森林策略有效融合眼周和虹膜的匹配得分,在远距离虹膜识别数据集上取得了较为满意的结果。Algashaam 等人(2021)设计了两个神经网络用于模拟基于变换的分数融合和基于分类的分数融合过程,然后将两个子网络有效组合起来以达到分数融合的目的。Wang 和 Kumar(2021)提出使用UniNet 提取两种不同模态的辨别特征,然后将匹配得分作为神经网络的输入进行动态融合,取得了较好的性能。Zhang 等人(2018)提出使用加权连接的方式,融合两个模态的辨别特征,解决移动设备上低质虹膜图像性能不佳的问题。Luo等人(2021)提出一种端到端深度特征融合的框架,使用通道注意力和空间注意力,能够提取鲁棒的辨别特征,并使用协同注意力机制融合眼周和虹膜的特征信息。但是,这些方法缺乏灵活性和自适应性,更重要的是忽视了各个模态在不同阶段语义特征的特点和优势,无法将不同模态的不同阶段的互补信息有效结合。
1 本文方法
本文通过高效通道注意力学习跨通道间交互信息,并通过特征复用的方法在特征图通道维数上进行拼接,丰富了特征图的语义信息,有效提取虹膜和眼周的判别特征。同时考虑低、中、高层的语义信息的特点和优势,通过引用中间融合表达层,根据不同阶段不同模态特征图对融合产生的有效贡献度自适应地学习相对应的权重,并通过加权融合的方式有效地融合虹膜和眼周的特征。
1.1 图像预处理
虹膜图像和眼周图像的预处理过程如图1 所示,主要分为3 个步骤。首先,在原始的虹膜数据集采集的人脸图像中定位出虹膜所处的区域并进行裁剪;其次,使用分割算法(Chen 等,2022)对裁剪区域逐像素点进行定位和分割;然后,将虹膜图像与其对应的掩码图像进行与操作,使图像中的非虹膜区域的像素值均变为0;最后,找到与真实虹膜区域相切的最小矩阵进行截取。事实上,相关研究(Ahmad 和Fuller,2019)已经证实,在虹膜图像预处理过程中,并不是必须将图像通过归一化形成一个固定尺寸大小的矩阵。一方面,归一化操作会产生图像块重叠的问题;另一方面,基于深度学习的方法是基于数据驱动的,在训练过程中模型能够自动聚焦并学习图像中的虹膜区域,而无效的像素点(黑色区域)将自动忽略。

图1 虹膜图像和眼周图像的预处理过程Fig.1 The preprocessing of iris image and periocular image
眼周区域采用Zhang 等人(2018)提出的归一化方法将眼周区域固定为统一大小的尺寸,具体为
式中,I(x,y)和In(xn,yn)分别指原图像和归一化图像之间的映射关系,x和y代表原来的尺寸,R和Rn分别表示开始的瞳孔中心和归一化后的瞳孔中心,w和h分别表示归一化后尺寸的大小。虹膜图像与眼周图像的输入尺寸设置为160 × 120 像素。同时,在预处理阶段没有对输入图像进行任何数据增强操作。
1.2 眼周—虹膜融合识别框架
虹膜—眼周深度特征融合网络如图2 所示。该网络从整体上可以分为两个子网络层和中间特征融合联合表达层3 部分。子网络层分别用于提取虹膜和眼周图像的辨别特征,主要由卷积层、Block层、全局平均池化层和全连接层等结构构成。首先使用核大小为5 × 5卷积层对输入的2维图像进行粗略的特征提取,然后利用若干个Block层对粗特征进一步提取获得更鲁棒的辨别特征,形成语义信息更丰富的高层特征图。
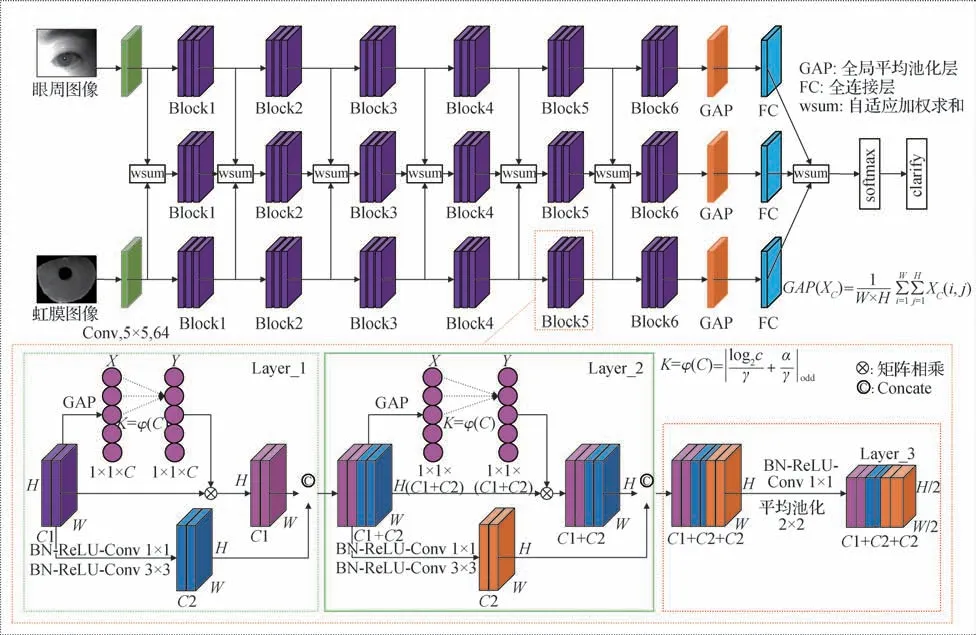
图2 眼周—虹膜深度特征融合网络Fig.2 Periocular-iris depth feature fusion network
Block 层主要由3 个串行部分依次组成,在前向传播中第1个阶段,使用BN(batch-normalization)-ReLUConv 1×1 和BN-ReLU-Conv 3×3 对输入特征X进行特征提取,得到X1;然后利用通道注意力机制学习特征向量通道之间的交互信息,并赋予输入X,得到X2;最后使用Concate 操作,在空间维度上对特征向量X1和X2进行拼接,得到输出特征Y。通过特征复用的方法能够有效减轻在前向传播过程中梯度消失的问题,进一步加深网络的深度。随后,将第1 阶段的输出作为第2阶段的输入,并在第2阶段执行相同的操作,经过Block 层前两个阶段的特征提取操作,特征图在通道维度上急剧增加,为了有效减轻模型的计算复杂度,再使用BN-ReLU-Conv 1×1 和平均池化层将特征图的宽和高减少为原来的一半。在模型的Block 层中大量使用了BN-ReLU-Conv 1×1和BN-ReLU-Conv 3×3 线性整流单元来设计网络,目的是能够在减少模型计算复杂度和不改变特征图尺寸的条件下增加网络的非线性特性,缓解训练过程中模型的过拟合,增加其泛化性。批量归一化的计算过程为
式中,γk和βk分别表示学习的参数,xk和yk表示输入和输出特征图。
高效通道注意力(Wang等,2020)能够在特征图维度不改变的情况下,学习跨通道之间的相关性,具体实现过程为
式中,δ代表非线性激活函数ReLU。
首先,使用全局平均池化层(global average pooling,GAP)将特征图的宽高均转化为1,得到1 × 1 ×C的特征矩阵,其计算过程为
然后,对1 × 1 ×C的矩阵进行1 维卷积操作,学习不同通道之间的交互信息,卷积核大小为K,K值的大小是非静态的,由输入特征图的通道维数决定,其计算过程为
式中,C表示输入特征图的通道维数,α和γ的初始值分别设置为2和1,|·|odd表示向下取整操作。
最后,将学习到的通道注意力值赋予对应维度,得到输出X2。通过使用注意力机制和Concate 操作能够在网络前向传播的过程中达到特征复用的目的,有效减轻梯度消失的问题,提升模型的识别性。
不同模态在不同阶段对融合特征的直接贡献不同,为此,在模型中引入中间融合联合表示层,该层根据虹膜和眼周低、中、高层语义特征对融合产生的贡献赋予不同的权重,如果其中一种模态对识别的贡献更大,则会赋予更大的权重,并通过加权组合的方式融合特征。中间融合联合表达层的具体实现细节为
在前向传播阶段,HCj,HIj,HPj分别表示第j个中间融合层、虹膜以及眼周的特征矩阵,α、β和γ分别表示对应学习的权重值,在训练的初始阶段,α,β,γ的初始值都为1;在反向传播阶段,所有可训练的权重参数利用随机梯度下降算法更新最新权重,直至模型收敛,最终学习到最优权重值,权重更新的实现过程为
经过上述过程提取的高层语义特征能够很好地反映原始图像的纹理信息,但是特征图的维数过高,为了进一步提取高层语义特征的显著信息,采用全局平均池化层,将形状大小为W×H×C的特征矩阵转化为1 × 1 ×C的特征向量,W,H,C分别表示为特征图的宽、高和通道维数。然后,使用全连接层将通道维数转变为N,N为数据集图像的类别数。最后,通过加权融合全连接层的辨别特征,并使用softmax函数将其标准化作为最终输出的辨别特征,其计算过程为
式中,α,β,γ分别表示学习的权重。eIj,ePj,eCj分别表示虹膜、眼周和中间融合层1 × 1 ×N向量的第j个值,在初始阶段,权重值都设置为1;在后向传播阶段,应用随机梯度下降方法更新权重,直至模型收敛,权重更新结束。权重更新过程与式(7)类似。在模型训练阶段,使用交叉熵损失函数衡量预测结果和真正例样本之间的误差大小。误差越大,表示预测结果更偏离真实结果。交叉熵损失函数的计算为
式中,PN表示预测结果,TN表示真实标签。在测试阶段,本文没有使用普遍采用的IrisCode 模板作为特征模板,而是直接使用网络最后一层全连接层使用softmax 将其标准化,并作为实值特征模板。从分类问题上看,该实值特征模板就是图像类别的预测概率,向量中的最大值的下标即为预测的图像类别。模型主要结构如表1所示。

表1 模型的具体结构Table 1 Specific structure of the model
2 实验与结果
2.1 数据集
ND(notre dame)-IRIS-0405(Phillips 等,2010)数据集共288 个受试者的虹膜图像,每个受试者为一类,每类虹膜图像包括25幅左眼虹膜和10幅右眼虹膜图像,虹膜图像总数量共10 080幅,较大的虹膜数据集有效避免了模型在训练中的过拟合问题。每类虹膜图像的前18 幅左眼和前7 幅右眼图像用于训练,后7 幅左眼和3 幅右眼图像用于测试,训练集与测试集的比例为5∶2。因此,测试集共包括12 960个类内得分和4 132 800个类间得分。
CASIA(Institute of Automation,Chinese Academy of Sciences)-Iris-M1-S3(Zhang 等,2018)数据集使用移动设备采集了360 个受试者的人脸图像,每个受试者为一类,每类包含10 幅图像。经裁剪后,每类得到10幅左眼和10幅右眼图像,即该数据集共包含3 600幅左眼和3 600幅右眼图像。左眼图像划分为训练集,右眼图像划分为测试集。因此,测试集共包括16 200个类内得分和6 462 000个类间得分。
CASIA-Iris-Distance(Tan,2018)数据集是中国科学院采集的远距离虹膜图像,共采集了142 个受试者的人脸虹膜图像,每个受试者采集的图像数量不同,但都至少有10 幅,图像数量共2 567 幅。实验中使用所有类别的前10 幅图像作为一个新数据集,共1 420幅。经裁剪得到10幅左眼和10幅右眼图像,左右眼不加以区分,视为同一类。每类的前5幅左眼和前5 幅右眼图像作为训练集,余下部分作为测试集,测试集共6 390 个类内得分和2 008 590 个类内得分。详细参数如表2所示。

表2 使用的数据集详细信息Table 2 The details of used dataset
图3 为使用的数据集的图像示例。ND-IRIS-0405 数据集采集的纹理较为清晰,图像质量较好,数据集数量较大,能够有效避免训练中的过拟合现象。CASIA-Iris-M1-S3 数据集是使用移动端手机短距离(采集距离为20~30 cm)设备采集的人脸图像,虹膜的纹理信息较为模糊,图像质量较差。CASIA-Iris-Distance 数据集在长距离(采集距离为3~4 m)非限制状态下捕获的虹膜纹理区域,容易受到睫毛和眼睑等遮挡因素的干扰,同时由于捕获距离较长,纹理信息比较模糊,类间特征差异较大。

图3 采用的虹膜数据集图像示例Fig.3 Examples of iris dataset images used((a)NDIRIS-0405;(b)CASIA-Iris-M1-S3;(c)CASIA-Iris-Distance)
2.2 实验环境
实验环境的具体参数如表3 所示。学习率的初始 值 为0.001,当 训 练100 个epoch 之 后,每50 个epoch 将减少学习率为原来的1/10,共训练300 个epoch。由于硬件设施的局限性,batch size 最大值只能设为8。

表3 实验环境的具体参数Table 3 Specific parameters of experimental environment
2.3 与其他实验对比结果
与其他实验对比选取的评价指标包括FRR(false reject rate)、TAR(true accept rate)和EER(equal error rate)。FRR 和EER 数值越低说明性能越优越,TAR则反之。图4分别是3个数据集中虹膜识别、眼周识别以及虹膜—眼周融合识别的受试者工作特征曲线(receiver operating characteristic curve,ROC)。

图4 提出的方法在3个公开数据集的ROC曲线Fig.4 The ROC curves of the three public datasets((a)NDIRIS-0405;(b)CASIA-Iris-M1-S3;(c)CASIA-Iris-Distance)
表4 是本文方法与其他方法在ND-IRIS-0405 数据集上的实验结果对比。可以看出,本文方法的EER 和FRR(FAR = 0.1%)分别为0.19%和0.21%,与对比方法表现出的最好的0.37%和0.70%相比有较高程度的性能提升。这是因为,一方面,本文方法能够有效地提取出辨别性更强的特征信息,虹膜和眼周识别的EER 值分别为0.45%和0.60%,均不超过1%,远低于对比方法的1.21%和0.63%。另一方面,深度特征融合方法能够有效地融合虹膜和眼周的特征信息,生成判别性更强的语义特征。

表4 本文方法与其他方法在ND-IRIS-0405数据集上的实验结果对比Table 4 Comparison of experimental results between other methods and ours on ND-IRIS-0405 dataset/%
表5 和表6 分别是本文方法与其他方法基于CASIA-Iris-M1-S3和CASIA-Iris-Distance 两个数据集的单模态和融合方法的实验结果对比,比较的性能指标主要是TAR 和EER。由于这两个公开数据集的图像质量不佳且采集距离较远,对识别算法具有一定的挑战。可以看出,在CASIA-Iris-M1-S3 数据集中,本文方法的TAR(FAR = 0.01%)和EER 值分别表现为97.77%和0.48%,而对比方法中表现最好的TAR 和EER 值分别是97.3%和0.73%。特别是单一的虹膜识别,本文方法的TAR 和EER 值为96.69%和0.67%,均优于对比方法的融合性能,有力地验证了本文方法在模糊导致的图像质量不佳时依然能够充分地提取出鲁棒的辨别特征。作为具有挑战性的虹膜数据集CASIA-Iris- Distance,现有方法表现最好的EER值和TAR 值分别为2.20%(虹膜识别)和87.25%(虹膜识别),尽管该方法在单模态虹膜识别的各项指标均优于本文所提出的单模态虹膜识别,但是本文方法通过融合眼周区域的特征能够弥补虹膜识别的不足,提高整体身份验证的准确度。

表5 本文方法与与其他方法在CASIA-Iris-M1-S3数据集上的实验结果对比Table 5 Comparison of experimental results between other methods and ours on CASIA-Iris-M1-S3 dataset/%

表6 本文方法与其他方法在CASIA-Iris-Distance数据集的实验结果对比Table 6 Comparison of experimental results between other methods and ours on CASAI-Iris-Distance dataset/%
2.4 消融实验
2.4.1 输入图像尺寸的影响
由于计算机硬件条件的限制,模型的输入图像尺寸未与对比方法保持一致(224×224 像素),为了保证实验数据的公平性,避免图像尺寸造成的干扰,设置了相关的一组消融实验。在该实验中,将输入尺寸由160 × 120 像素改变为128 × 64 像素,其他参数保持不变。
图5 显示了不同输入尺寸下识别率曲线和ROC曲线。可以看出,在识别率曲线中,随着训练次数的增加,识别率曲线不断收敛,尺寸的变化并不影响网络收敛的速度,收敛速度保持相对一致。

图5 输入图像尺寸的影响Fig.5 Influence of input image size((a)curves of Rank;(b)curves of ROC)
表7 为输入图像尺寸实验结果对比。从表7 可以看出,随着输入尺寸的不断缩小,识别效果会受其影响导致识别精度相应下降,融合后的EER 值由0.19%上升至0.45%,鲁棒性显著下降。这说明尽管模型输入尺寸小于对比方法,但是由于本文方法获取的特征更具有辨别性,因此性能表现较为优越。

表7 输入图像尺寸实验结果对比Table 7 Comparison of experimental results of input image size/%
2.4.2 数据增强的影响
为了防止模型在训练中模型的输入偏向训练集而导致的过拟合现象,设计了两组实验并分别对数据集添加高斯噪声和椒盐噪声。应该注意到,添加噪声在一定程度上会影响图像质量导致识别性能下降,对特征提取的算法具有一定的考验,从而反映该算法的鲁棒性。图6 和图7 分别是有无高斯噪声和椒盐噪声对比的识别率曲线和受试者工作特征曲线,从图中可以看出,在添加噪音之后,识别率曲线相对抖动较大,最终的收敛速度与未添加噪声保持相对一致。表8是数据增强的实验结果对比。从表8可以看出,添加噪声的EER值均为0.23%,略高于无噪声因素干扰的0.19%,尽管如此,仍然低于对比方法中的0.37%,再次说明了本文方法具有较强的鲁棒性,能够在图像质量不佳时表现出优异的性能。

表8 数据增强的实验结果对比Table 8 Comparison of experimental results of data enhancement/%

图6 高斯噪声的影响Fig.6 Influence of Gaussian noise((a)curves of Rank;(b)curves of ROC)

图7 椒盐噪声的影响Fig.7 Influence of salt and pepper noise((a)curves of Rank;(b)curves of ROC)
2.4.3 注意力机制的影响
为了验证通道注意力机制与特征重用组合模块对模型的性能的影响,移除Block模块中的注意力模块,采用注意力模块的输入进行替代,其他网络结构以及实验中超参数完全保持一致,在3 个数据集上进行消融实验,结果如表9—表11所示。可以看出,移除通道注意力模块并使用注意力模块的输入进行替代会降低匹配精度,这是因为引入通道注意力可以学习到特征图通道之间的交互信息,在一定程度上增强了特征的判别性,语义信息更加丰富。特征向量在通道维度上的拼接又能很好地保留有效的特征,避免在网络传播中有效特征丢失的问题。

表9 在ND-IRIS-0405数据集上通道注意力机制影响的结果对比Table 9 Comparison of experimental results of channel attention on ND-IRIS-0405 dataset/%

表10 在CASIA-Iris-M1-S3数据集上通道注意力机制影响的结果对比Table 10 Comparison of experimental results of channel attention on CASIA-Iris-M1-S3 dataset/%
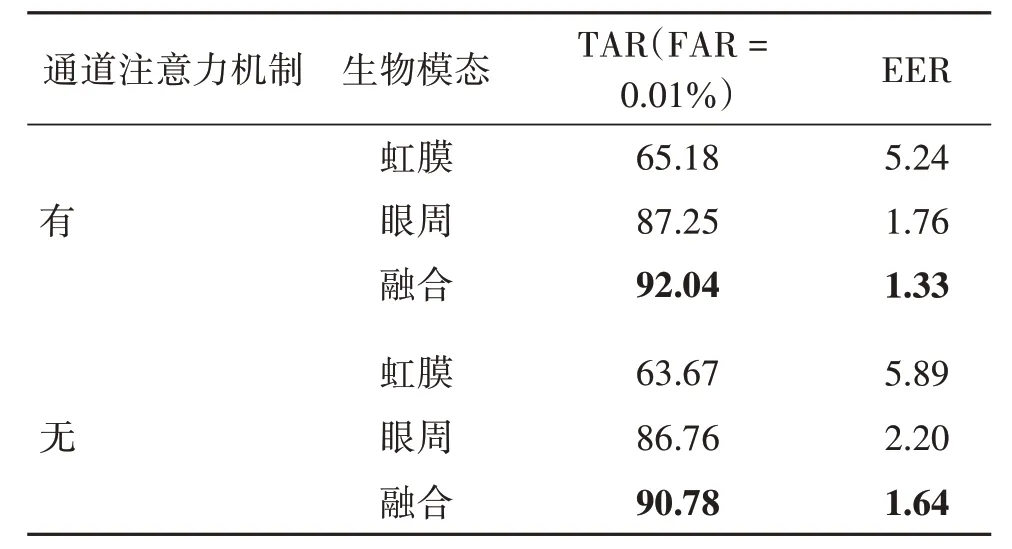
表11 在CASIA-Iris-Distance数据集上通道注意力机制影响的结果对比Table 11 Comparison of experimental results of channel attention on CASIA-Iris-Distance dataset/%
3 结 论
本文提出了一种基于卷积神经网络的网络模型,该网络通过联合使用高效通道注意力机制和特征重用的方法在一定程度上能够减缓模型梯度消失的问题,有助于加深模型的深度,获取鲁棒的辨别特征。同时,通过引入中间融合联合表达层根据不同模态的低、中、高层语义特征产生的贡献程度自适应地学习相对应的权重,并最终通过加权融合的方式有效地将虹膜和眼周特征融合为更具辨别性的特征,提升了远距离、非协作状态下虹膜识别性能。与其他方法相比较,本文方法更加注重不同阶段特征的差异性,而不是仅聚焦于高维语义特征的差异,在一定程度上能够增强融合特征的可辨别性,并且该方法容易实现和训练。但是,应该注意到,该工作没有具体衡量不同阶段对最终融合结果的影响作用的差异性。在下一步工作中,将考虑如何利用不同阶段产生影响的差异性更加高效地融合其语义特征,同时将工作重点聚焦于移动端设备远距离、非协作场景下的虹膜识别,这对于虹膜识别在现实中的大规模部署和应用,具有十分重要的现实意义。
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13
小雪花·成长指南(2022年1期)2022-04-09
文萃报·周二版(2018年51期)2018-08-04
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
警察技术(2015年3期)2015-02-27
计算物理(2014年2期)2014-03-11
电视技术(2014年19期)2014-03-11
